Les organisations doivent souvent gérer un volume élevé de données qui croît à un rythme extraordinaire. Dans le même temps, elles doivent optimiser les coûts opérationnels pour libérer la valeur de ces données et obtenir des informations opportunes, et ce, avec des performances constantes.
Avec cette croissance massive des données, la prolifération des données dans vos magasins de données, entrepôts de données et lacs de données peut devenir tout aussi difficile. Avec un architecture de données moderne sur AWS, vous pouvez créer rapidement des lacs de données évolutifs ; utiliser une collection large et approfondie de services de données spécialement conçus ; assurer la conformité via un accès, une sécurité et une gouvernance unifiés aux données ; faites évoluer vos systèmes à faible coût sans compromettre les performances ; et partagez facilement des données au-delà des frontières organisationnelles, vous permettant ainsi de prendre des décisions avec rapidité et agilité à grande échelle.
Vous pouvez extraire toutes vos données de divers silos, les regrouper dans votre lac de données et effectuer des analyses et du machine learning (ML) directement sur ces données. Vous pouvez également stocker d'autres données dans des magasins de données spécialement conçus pour analyser et obtenir rapidement des informations à partir de données structurées et non structurées. Ce mouvement de données peut s'effectuer de l'intérieur vers l'extérieur, de l'extérieur vers l'intérieur, autour du périmètre ou être partagé à travers le périmètre.
Par exemple, les journaux d'applications et les traces des applications Web peuvent être collectés directement dans un lac de données, et une partie de ces données peut être déplacée vers un magasin d'analyse de journaux comme Amazon OpenSearch Service pour une analyse quotidienne. Nous considérons ce concept comme à l'envers mouvement des données. Les données analysées et agrégées stockées dans Amazon OpenSearch Service peuvent à nouveau être déplacées vers le lac de données pour exécuter des algorithmes de ML pour la consommation en aval des applications. Nous appelons cette notion dehors dans mouvement des données.
Examinons un exemple de cas d'utilisation. Exemple Corp. est une entreprise leader du Fortune 500 spécialisée dans le contenu social. Ils disposent de centaines d'applications générant des données et des traces à raison d'environ 500 To par jour et répondent aux critères suivants :
- Avoir des journaux disponibles pour une analyse rapide pendant 2 jours
- Au-delà de 2 jours, disposez de données disponibles dans un niveau de stockage pouvant être mis à disposition à des fins d'analyse avec un SLA raisonnable.
- Conserver les données au-delà d'une semaine en chambre froide pendant 1 jours (à des fins de conformité, d'audit et autres)
Dans les sections suivantes, nous discutons de trois solutions possibles pour répondre à des cas d'utilisation similaires :
- Stockage hiérarchisé dans Amazon OpenSearch Service et gestion du cycle de vie des données
- Ingestion à la demande de journaux à l'aide de Ingestion d'Amazon OpenSearch
- Requêtes directes Amazon OpenSearch Service avec Amazon Simple Storage Service (Amazon S3)
Solution 1 : stockage hiérarchisé dans OpenSearch Service et gestion du cycle de vie des données
OpenSearch Service prend en charge trois niveaux de stockage intégrés : stockage à chaud, UltraWarm et froid. En fonction de vos exigences en matière de conservation des données, de latence des requêtes et de budgétisation, vous pouvez choisir la meilleure stratégie pour équilibrer les coûts et les performances. Vous pouvez également migrer des données entre différents niveaux de stockage.
Le stockage à chaud est utilisé pour l'indexation et la mise à jour et offre l'accès le plus rapide aux données. Le stockage à chaud prend la forme d'un magasin d'instances ou Boutique de blocs élastiques Amazon (Amazon EBS) attachés à chaque nœud.
UltraWarm offre des coûts par Gio nettement inférieurs pour les données en lecture seule que vous interrogez moins fréquemment et qui ne nécessitent pas les mêmes performances que le stockage à chaud. Les nœuds UltraWarm utilisent Amazon S3 avec des solutions de mise en cache associées pour améliorer les performances.
Le stockage à froid est optimisé pour stocker des données rarement consultées ou historiques. Lorsque vous utilisez le stockage froid, vous détachez vos index du niveau UltraWarm, les rendant ainsi inaccessibles. Vous pouvez rattacher ces index en quelques secondes lorsque vous devez interroger ces données.
Pour plus de détails sur les niveaux de données dans OpenSearch Service, reportez-vous à Choisissez le niveau de stockage adapté à vos besoins dans Amazon OpenSearch Service.
Vue d'ensemble de la solution
Le flux de travail de cette solution comprend les étapes suivantes :
- Les données entrantes générées par les applications sont diffusées vers un lac de données S3.
- Les données sont ingérées dans Amazon OpenSearch à l'aide Ingestion S3-SQS en temps quasi réel via des notifications mises en place sur les buckets S3.
- Après 2 jours, les données chaudes sont migrées vers le stockage UltraWarm pour prendre en charge les requêtes de lecture.
- Après 5 jours dans UltraWarm, les données sont migrées vers un stockage froid pendant 21 jours et détachées de tout calcul. Les données peuvent être rattachées à UltraWarm si nécessaire. Les données sont supprimées de la chambre froide après 21 jours.
- Les index quotidiens sont conservés pour un roulement facile. Une stratégie ISM (Index State Management) automatise le remplacement ou la suppression des index datant de plus de 2 jours.
Voici un exemple de stratégie ISM qui transfère les données vers le niveau UltraWarm après 2 jours, les déplace vers un stockage froid après 5 jours et les supprime du stockage froid après 21 jours :
Considérations
UltraWarm utilise des techniques de mise en cache sophistiquées pour permettre l'interrogation des données rarement consultées. Bien que l'accès aux données soit peu fréquent, le calcul des nœuds UltraWarm doit être exécuté en permanence pour rendre cet accès possible.
Lors d'un fonctionnement à l'échelle du PB, afin de réduire la zone d'effet de toute erreur, nous recommandons de décomposer l'implémentation en plusieurs domaines OpenSearch Service lors de l'utilisation d'un stockage hiérarchisé.
Les deux modèles suivants suppriment le besoin d'un calcul de longue durée et décrivent des techniques à la demande dans lesquelles les données sont soit importées en cas de besoin, soit interrogées directement là où elles résident.
Solution 2 : Ingestion à la demande des données de journaux via OpenSearch Ingestion
OpenSearch Ingestion est un collecteur de données entièrement géré qui fournit des données de journal et de trace en temps réel aux domaines OpenSearch Service. OpenSearch Ingestion est alimenté par le collecteur de données open source Préparateur de données. Data Prepper fait partie du projet OpenSearch open source.
Avec OpenSearch Ingestion, vous pouvez filtrer, enrichir, transformer et fournir vos données pour une analyse et une visualisation en aval. Vous configurez vos producteurs de données pour envoyer des données à OpenSearch Ingestion. Il transmet automatiquement les données au domaine ou à la collection que vous spécifiez. Vous pouvez également configurer OpenSearch Ingestion pour transformer vos données avant de les livrer. OpenSearch Ingestion est sans serveur, vous n'avez donc pas à vous soucier de la mise à l'échelle de votre infrastructure, de l'exploitation de votre flotte d'ingestion et de l'application de correctifs ou de la mise à jour du logiciel.
Il existe deux manières d'utiliser Amazon S3 comme source pour traiter les données avec OpenSearch Ingestion. La première option est le traitement S3-SQS. Vous pouvez utiliser le traitement S3-SQS lorsque vous avez besoin d'une analyse en temps quasi réel des fichiers après leur écriture dans S3. Cela nécessite un Service Amazon Simple Queue (Amazon S3) qui reçoit Notifications d'événements S3. Vous pouvez configurer les compartiments S3 pour déclencher un événement chaque fois qu'un objet est stocké ou modifié dans le compartiment à traiter.
Vous pouvez également utiliser une analyse planifiée unique ou récurrente pour traiter par lots les données dans un compartiment S3. Pour configurer une analyse planifiée, configurez votre pipeline avec une planification au niveau de l'analyse qui s'applique à tous vos compartiments S3, ou au niveau du compartiment. Vous pouvez configurer des analyses planifiées avec une analyse ponctuelle ou une analyse récurrente pour le traitement par lots.
Pour un aperçu complet d’OpenSearch Ingestion, voir Ingestion d'Amazon OpenSearch. Pour plus d'informations sur le projet open source Data Prepper, visitez Préparateur de données.
Vue d'ensemble de la solution
Nous présentons un modèle d'architecture avec les composants clés suivants :
- Les journaux d'application sont diffusés dans le lac de données, ce qui permet d'alimenter OpenSearch Service en temps quasi réel à l'aide d'OpenSearch Ingestion. Traitement S3-SQS.
- Les politiques ISM au sein d’OpenSearch Service gèrent les rollovers ou les suppressions d’index. Les stratégies ISM vous permettent d'automatiser ces opérations administratives périodiques en les déclenchant en fonction des changements dans l'âge de l'index, la taille de l'index ou le nombre de documents. Par exemple, vous pouvez définir une stratégie qui place votre index en lecture seule après 2 jours, puis le supprime après une période définie de 3 jours.
- Les données froides sont disponibles dans le lac de données S3 pour être consommées à la demande dans OpenSearch Service à l'aide d'OpenSearch Ingestion. analyses programmées.
Le diagramme suivant illustre l'architecture de la solution.
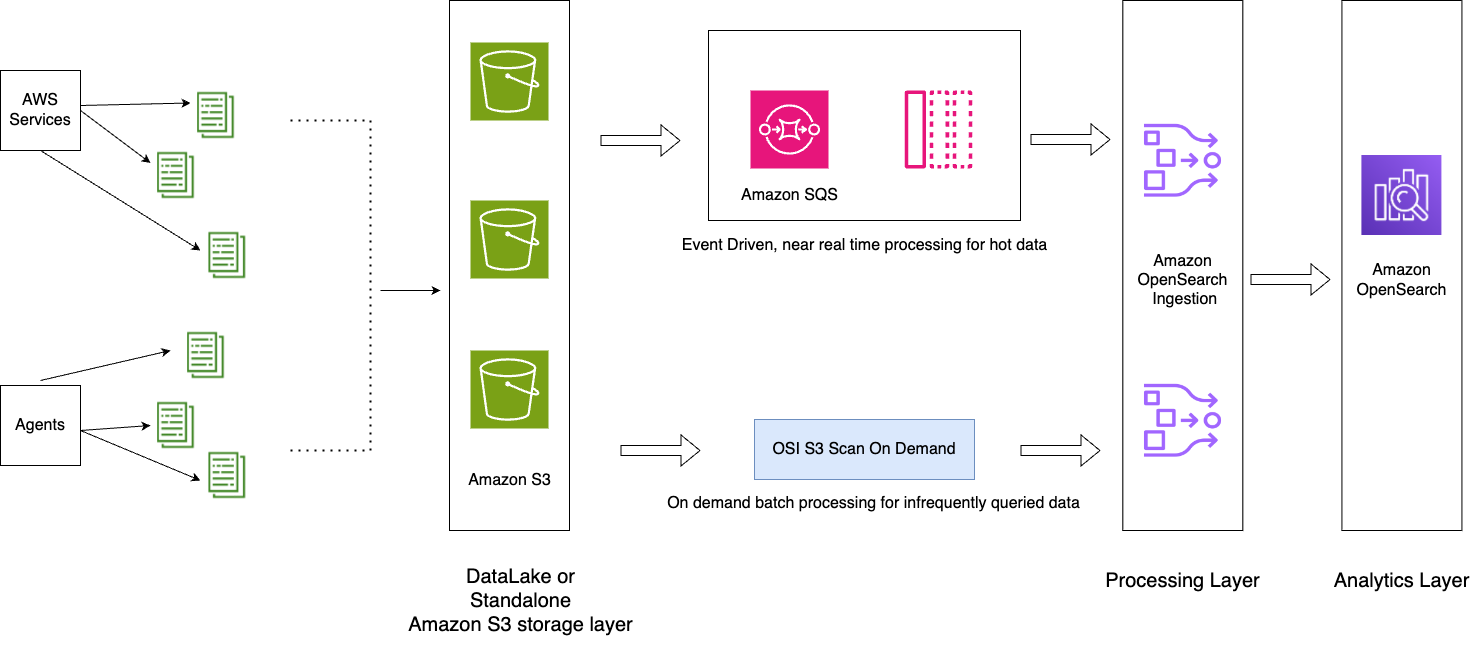
Le workflow comprend les étapes suivantes:
- Les données entrantes générées par les applications sont diffusées vers le lac de données S3.
- Pour la journée en cours, les données sont ingérées dans OpenSearch Service à l'aide de l'ingestion S3-SQS en temps quasi réel via des notifications configurées dans les compartiments S3.
- Les index quotidiens sont conservés pour un roulement facile. Une stratégie ISM automatise le basculement ou la suppression des index datant de plus de 2 jours.
- Si une demande d'analyse des données est faite au-delà de 2 jours et que les données ne font pas partie du niveau UltraWarm, les données seront ingérées à l'aide de la fonction d'analyse unique d'Amazon S3 entre la fenêtre horaire spécifique.
Par exemple, si nous sommes le 10 janvier 2024 et que vous avez besoin de données du 6 janvier 2024 à un intervalle spécifique pour analyse, vous pouvez créer un pipeline d'ingestion OpenSearch avec une analyse Amazon S3 dans votre configuration YAML, avec l'option start_time ainsi que end_time pour spécifier quand vous souhaitez que les objets du compartiment soient analysés :
Considérations
Profitez de la compression
Les données d'Amazon S3 peuvent être compressées, ce qui réduit votre empreinte globale de données et entraîne des économies significatives. Par exemple, si vous générez 15 Po de journaux d'application JSON bruts par mois, vous pouvez utiliser un mécanisme de compression tel que GZIP, qui peut réduire la taille à environ 1 Po ou moins, ce qui entraîne des économies significatives.
Arrêtez le pipeline lorsque cela est possible
OpenSearch Ingestion évolue automatiquement entre les OCU minimum et maximum définis pour le pipeline. Une fois que le pipeline a terminé l'analyse Amazon S3 pendant la durée spécifiée mentionnée dans la configuration du pipeline, le pipeline continue de s'exécuter pour une surveillance continue au niveau minimum d'OCU.
Pour l'ingestion à la demande pour des durées passées pour lesquelles vous ne vous attendez pas à ce que de nouveaux objets soient créés, envisagez d'utiliser des métriques de pipeline prises en charge telles que recordsOut.count à créer Amazon Cloud Watch alarmes pouvant arrêter le pipeline. Pour obtenir la liste des métriques prises en charge, reportez-vous à Surveillance des métriques du pipeline.
Les alarmes CloudWatch effectuent une action lorsqu'une métrique CloudWatch dépasse une valeur spécifiée pendant un certain temps. Par exemple, vous souhaiterez peut-être surveiller recordsOut.count être 0 pendant plus de 5 minutes pour lancer une demande de arrêter le pipeline par l'intermédiaire du Interface de ligne de commande AWS (AWS CLI) ou API.
Solution 3 : requêtes directes OpenSearch Service avec Amazon S3
Requêtes directes OpenSearch Service avec Amazon S3 (préversion) est une nouvelle façon d'interroger les journaux opérationnels dans les lacs de données Amazon S3 et S3 sans avoir besoin de basculer entre les services. Vous pouvez désormais analyser les données rarement interrogées dans les magasins d'objets cloud et utiliser simultanément les capacités d'analyse opérationnelle et de visualisation d'OpenSearch Service.
Les requêtes directes OpenSearch Service avec Amazon S3 fournissent intégration zéro ETL pour réduire la complexité opérationnelle liée à la duplication des données ou à la gestion de plusieurs outils d'analyse en vous permettant d'interroger directement vos données opérationnelles, réduisant ainsi les coûts et les délais d'action. Cette intégration sans ETL est configurable dans OpenSearch Service, où vous pouvez profiter de divers modèles de types de journaux, y compris des tableaux de bord prédéfinis, et configurer des accélérations de données adaptées à ce type de journal. Les modèles incluent Journaux de flux VPC, Équilibrage de charge élastique les journaux et les journaux NGINX, et les accélérations incluent le saut d'index, les vues matérialisées et les index couverts.
Avec les requêtes directes OpenSearch Service avec Amazon S3, vous pouvez effectuer des requêtes complexes essentielles à l'investigation de la sécurité et à l'analyse des menaces, et corréler les données de plusieurs sources de données, ce qui aide les équipes à enquêter sur les temps d'arrêt du service et les événements de sécurité. Après avoir créé une intégration, vous pouvez commencer à interroger vos données directement à partir des tableaux de bord OpenSearch ou de l'API OpenSearch. Vous pouvez auditer les connexions pour vous assurer qu’elles sont configurées de manière évolutive, rentable et sécurisée.
Les requêtes directes d'OpenSearch Service vers Amazon S3 utilisent des tables Spark dans le Colle AWS Catalogue de données. Une fois la table cataloguée dans votre catalogue de métadonnées AWS Glue, vous pouvez exécuter des requêtes directement sur vos données dans votre lac de données S3 via les tableaux de bord OpenSearch.
Vue d'ensemble de la solution
Le diagramme suivant illustre l'architecture de la solution.
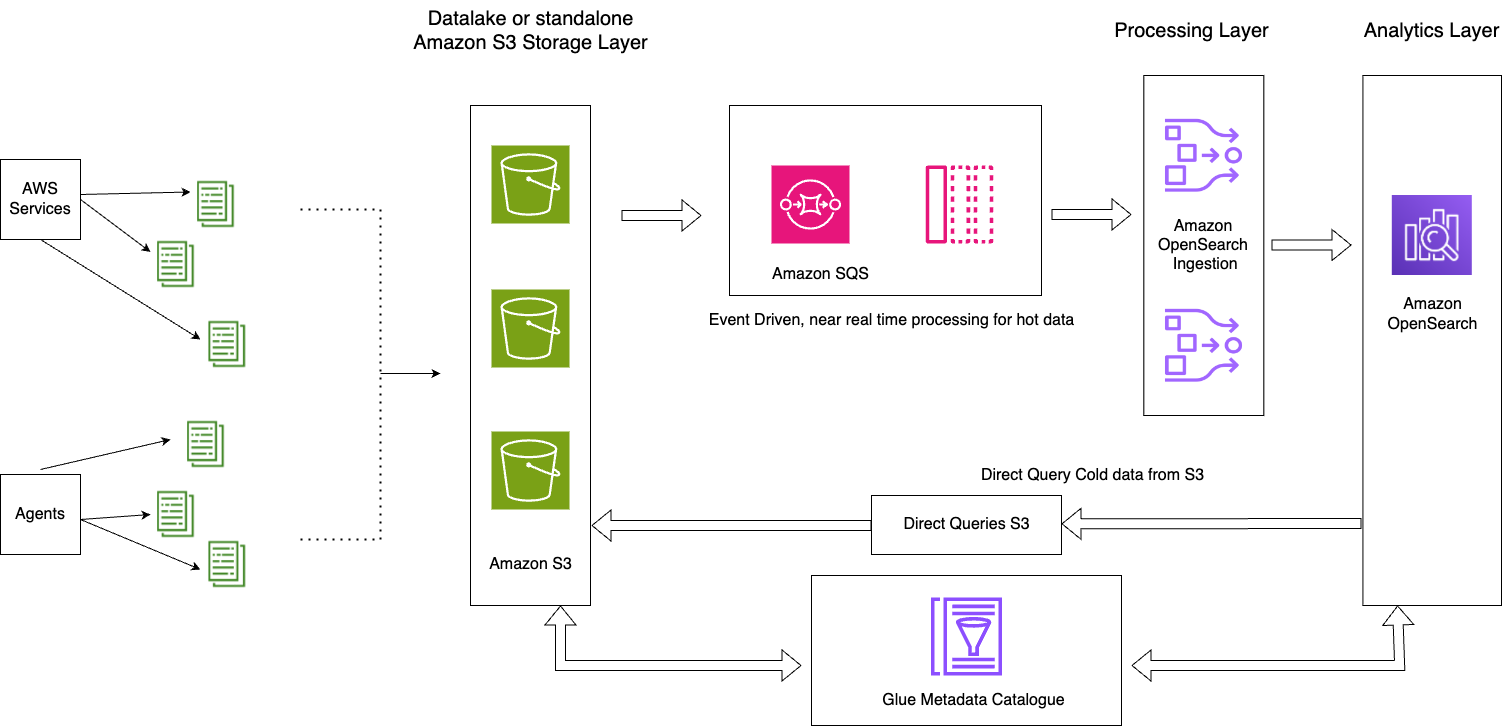
Cette solution se compose des éléments clés suivants :
- Les données chaudes de la journée en cours sont traitées en flux dans les domaines OpenSearch Service via le modèle d'architecture basé sur les événements à l'aide de la fonctionnalité de traitement OpenSearch Ingestion S3-SQS.
- Le cycle de vie des données chaudes est géré via des politiques ISM attachées aux index quotidiens
- Les données froides résident dans votre compartiment Amazon S3 et sont partitionnées et cataloguées
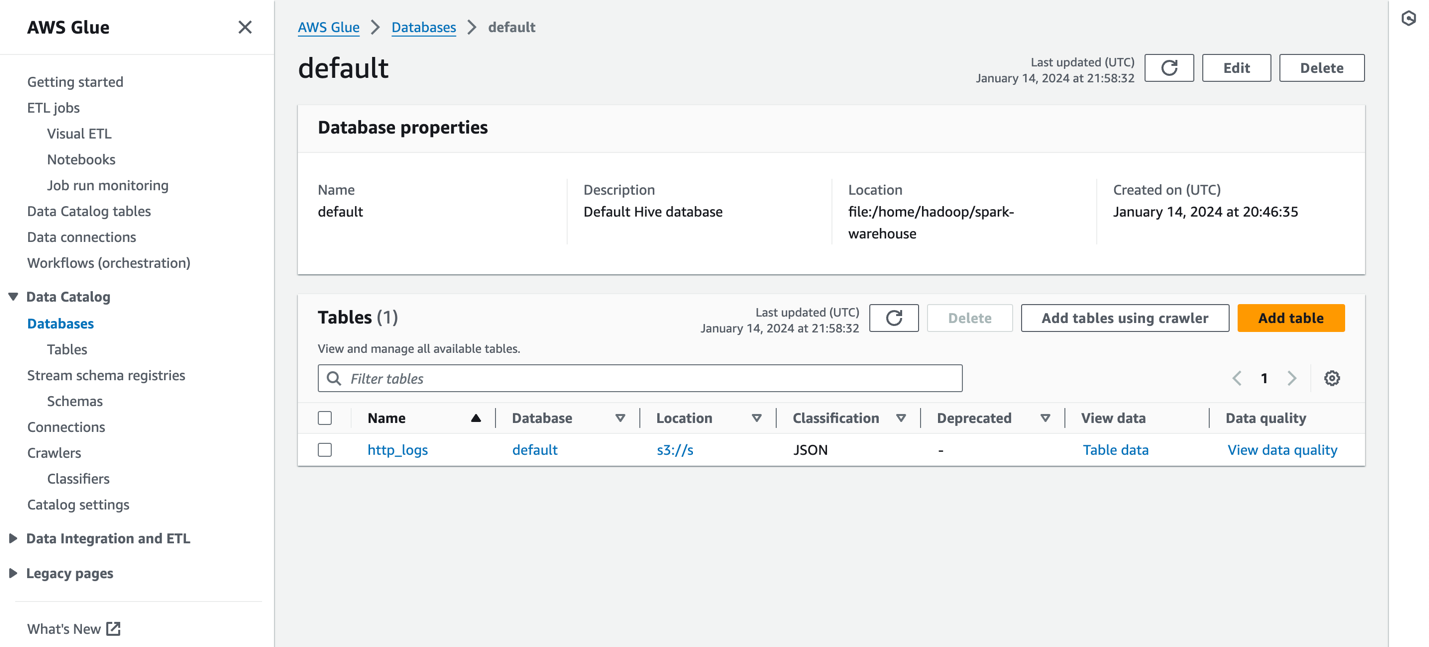
La capture d'écran suivante montre un exemple http_logs table cataloguée dans le catalogue de métadonnées AWS Glue. Pour les étapes détaillées, reportez-vous à Catalogue de données et robots d'exploration dans AWS Glue.
Avant de créer une source de données, vous devez disposer d'un domaine OpenSearch Service avec la version 2.11 ou ultérieure et d'une table S3 cible dans le catalogue de données AWS Glue avec le paramètre approprié. Gestion des identités et des accès AWS (IAM). IAM devra accéder aux compartiments S3 souhaités et disposer d'un accès en lecture et en écriture au catalogue de données AWS Glue. Voici un exemple de rôle et de stratégie de confiance avec les autorisations appropriées pour accéder au catalogue de données AWS Glue via OpenSearch Service :
Voici un exemple de stratégie personnalisée avec accès à Amazon S3 et AWS Glue :
Pour créer une nouvelle source de données sur la console OpenSearch Service, indiquez le nom de votre nouvelle source de données, spécifiez le type de source de données comme suit Amazon S3 avec le catalogue de données AWS Glue, puis choisissez le rôle IAM pour votre source de données.
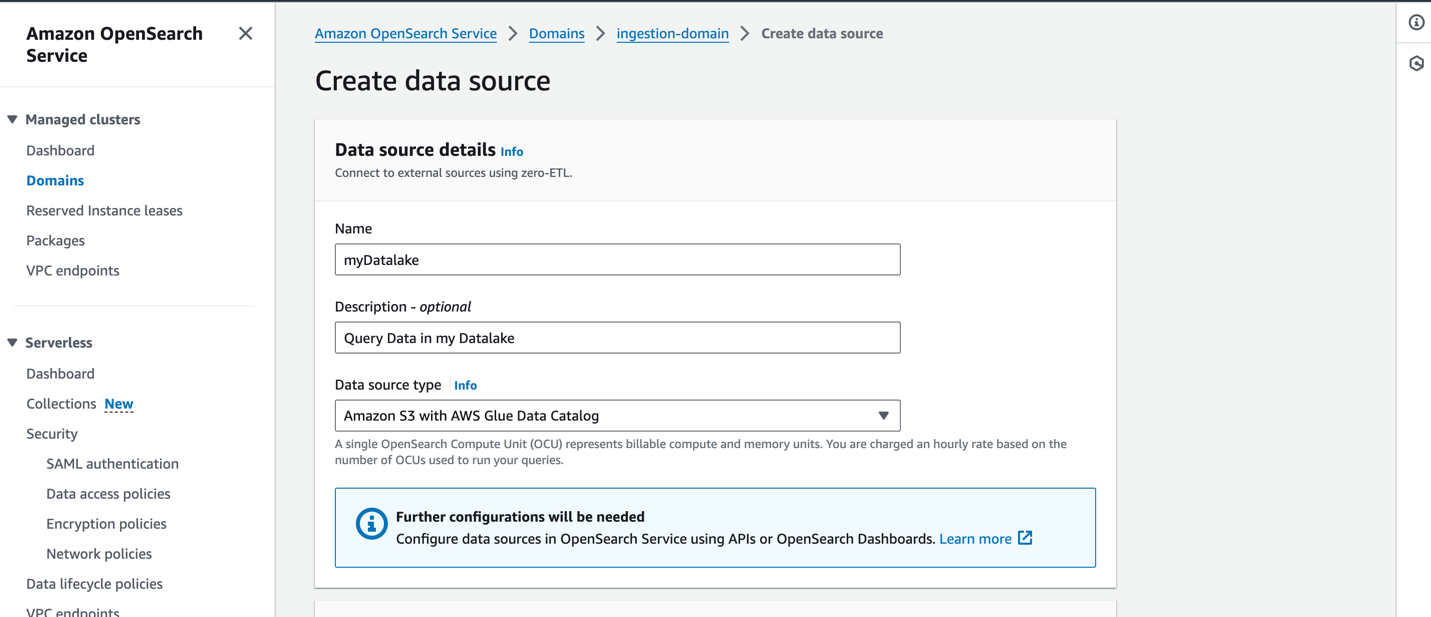
Après avoir créé une source de données, vous pouvez accéder au tableau de bord OpenSearch du domaine, que vous utilisez pour configurer le contrôle d'accès, définir des tables, configurer des tableaux de bord basés sur les types de journaux pour les types de journaux courants et interroger vos données.

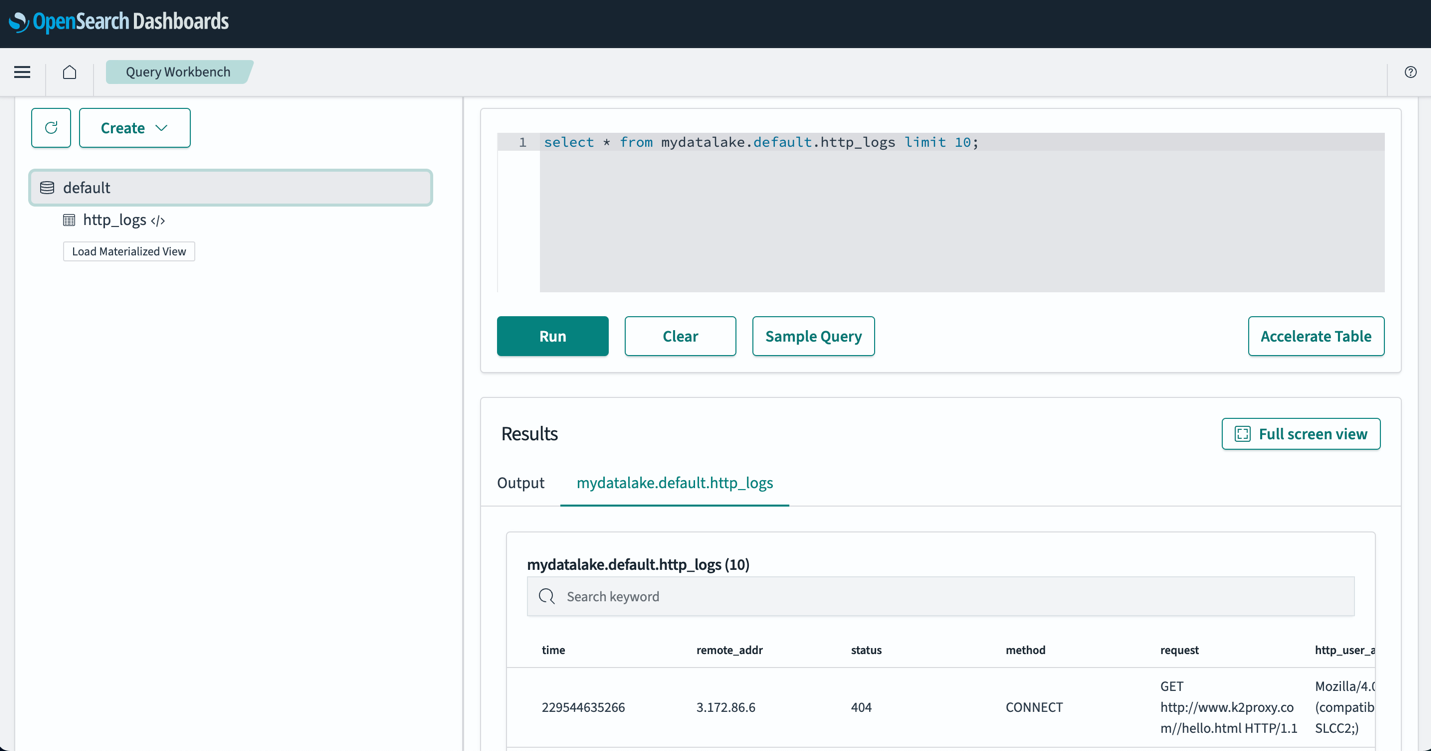
Après avoir configuré vos tables, vous pouvez interroger vos données dans votre lac de données S3 via les tableaux de bord OpenSearch. Vous pouvez exécuter un exemple de requête SQL pour le http_logs table que vous avez créée dans les tables AWS Glue Data Catalog, comme indiqué dans la capture d'écran suivante.
des pratiques d’excellence;
Ingérez uniquement les données dont vous avez besoin
Travaillez à rebours à partir des besoins de votre entreprise et établissez les ensembles de données appropriés dont vous aurez besoin. Évaluez si vous pouvez éviter d’ingérer des données bruitées et ingérer uniquement des données organisées, échantillonnées ou agrégées. L'utilisation de ces ensembles de données nettoyés et organisés vous aidera à optimiser les ressources de calcul et de stockage nécessaires pour ingérer ces données.
Réduire la taille des données avant l'ingestion
Lorsque vous concevez vos pipelines d'ingestion de données, utilisez des stratégies telles que la compression, le filtrage et l'agrégation pour réduire la taille des données ingérées. Cela permettra de transférer des données de plus petite taille sur le réseau et de les stocker dans votre couche de données.
Conclusion
Dans cet article, nous avons discuté de solutions permettant d'analyser les journaux à l'échelle du pétaoctet à l'aide d'OpenSearch Service dans une architecture de données moderne. Vous avez appris à créer un pipeline d'ingestion sans serveur pour fournir des journaux à un domaine OpenSearch Service, à gérer des index via des stratégies ISM, à configurer les autorisations IAM pour commencer à utiliser OpenSearch Ingestion et à créer la configuration du pipeline pour les données de votre lac de données. Vous avez également appris à configurer et à utiliser les requêtes directes OpenSearch Service avec la fonctionnalité Amazon S3 (préversion) pour interroger les données de votre lac de données.
Pour choisir le modèle d'architecture adapté à vos charges de travail lorsque vous utilisez OpenSearch Service à grande échelle, tenez compte de la croissance des performances, de la latence, des coûts et du volume de données au fil du temps afin de prendre la bonne décision.
- Utilisez une architecture de stockage hiérarchisée avec des politiques de gestion de l'état d'index lorsque vous avez besoin d'un accès rapide à vos données chaudes et que vous souhaitez équilibrer le coût et les performances avec des nœuds UltraWarm pour les données en lecture seule.
- Utilisez l'ingestion à la demande de vos données dans OpenSearch Service lorsque vous pouvez tolérer des latences d'ingestion pour interroger vos données non conservées dans vos nœuds actifs. Vous pouvez réaliser d'importantes économies en utilisant des données compressées dans Amazon S3 et en ingérant des données à la demande dans OpenSearch Service.
- Utilisez la requête directe avec la fonctionnalité S3 lorsque vous souhaitez analyser directement vos journaux opérationnels dans Amazon S3 avec les riches fonctionnalités d'analyse et de visualisation d'OpenSearch Service.
Comme étape suivante, reportez-vous au Guide du développeur Amazon OpenSearch pour explorer les journaux et les pipelines de métriques que vous pouvez utiliser pour créer une solution d'observabilité évolutive pour vos applications d'entreprise.
À propos des auteurs
 Jagadish Kumar (Jag) est un architecte de solutions spécialisé senior chez AWS, axé sur Amazon OpenSearch Service. Il est profondément passionné par l'architecture des données et aide les clients à créer des solutions d'analyse à grande échelle sur AWS.
Jagadish Kumar (Jag) est un architecte de solutions spécialisé senior chez AWS, axé sur Amazon OpenSearch Service. Il est profondément passionné par l'architecture des données et aide les clients à créer des solutions d'analyse à grande échelle sur AWS.
 Muthu Pitchamani est un architecte de solutions spécialisé senior chez Amazon OpenSearch Service. Il crée des applications et des solutions de recherche à grande échelle. Muthu s'intéresse aux thèmes des réseaux et de la sécurité et est basé à Austin, au Texas.
Muthu Pitchamani est un architecte de solutions spécialisé senior chez Amazon OpenSearch Service. Il crée des applications et des solutions de recherche à grande échelle. Muthu s'intéresse aux thèmes des réseaux et de la sécurité et est basé à Austin, au Texas.
 Sam Selvan est un architecte de solutions spécialisé principal chez Amazon OpenSearch Service.
Sam Selvan est un architecte de solutions spécialisé principal chez Amazon OpenSearch Service.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/petabyte-scale-log-analytics-with-amazon-s3-amazon-opensearch-service-and-amazon-opensearch-ingestion/

