Service Amazon OpenSearch a récemment introduit la famille OpenSearch Optimized Instance (OR1), qui offre jusqu'à 30 % d'amélioration prix-performance par rapport aux instances optimisées en mémoire existantes dans les tests internes, et utilise Service de stockage simple Amazon (Amazon S3) pour fournir 11 9s de durabilité. Avec cette nouvelle famille d'instances, OpenSearch Service utilise l'innovation OpenSearch et les technologies AWS pour réimaginer la façon dont les données sont indexées et stockées dans le cloud.
Aujourd'hui, les clients utilisent largement OpenSearch Service pour l'analyse opérationnelle en raison de sa capacité à ingérer de gros volumes de données tout en fournissant également des analyses riches et interactives. Afin d'offrir ces avantages, OpenSearch est conçu comme un système distribué à grande échelle avec plusieurs instances indépendantes indexant les données et traitant les demandes. À mesure que la vitesse et le volume de vos données d’analyse opérationnelle augmentent, des goulots d’étranglement peuvent apparaître. Pour prendre en charge durablement un volume d'indexation élevé et assurer la durabilité, nous avons créé la famille d'instances OR1.
Dans cet article, nous expliquons comment le flux de données réinventé fonctionne avec les instances OR1 et comment il peut fournir un débit d'indexation et une durabilité élevés à l'aide d'un nouveau protocole de réplication physique. Nous approfondissons également certains des défis que nous avons résolus pour maintenir l’exactitude et l’intégrité des données.
Concevoir pour un débit élevé avec une durabilité de 11 9 s
OpenSearch Service gère des dizaines de milliers de clusters OpenSearch. Nous avons acquis des informations sur les configurations de cluster typiques que les clients utilisent pour atteindre leurs objectifs de débit et de durabilité élevés. Pour obtenir un débit plus élevé, les clients choisissent souvent de supprimer les copies de réplique afin d'économiser sur la latence de réplication ; cependant, cette configuration entraîne un sacrifice de disponibilité et de durabilité. D'autres clients exigent une durabilité élevée et doivent donc conserver plusieurs copies de réplique, ce qui entraîne pour eux des coûts d'exploitation plus élevés.
La famille d'instances optimisées OpenSearch offre une durabilité supplémentaire tout en réduisant les coûts en stockant une copie des données sur Amazon S3. Avec les instances OR1, vous pouvez configurer plusieurs copies de réplica pour une haute disponibilité en lecture tout en conservant le débit d'indexation.
Le diagramme suivant illustre un flux d'indexation impliquant une mise à jour des métadonnées dans OR1
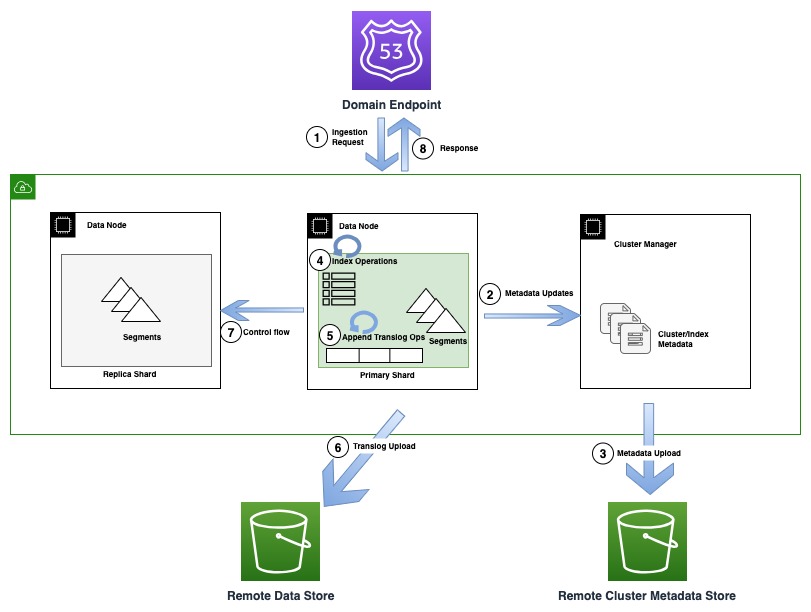
Lors des opérations d'indexation, les documents individuels sont indexés dans Lucene et également ajoutés à un journal d'écriture anticipée également appelé translog. Avant de renvoyer un accusé de réception au client, toutes les opérations de translog sont conservées dans le magasin de données distant soutenu par Amazon S3. Si des copies de réplique sont configurées, la copie principale effectue des vérifications pour détecter la possibilité de plusieurs rédacteurs (flux de contrôle) sur toutes les copies de réplique pour des raisons d'exactitude.
Le diagramme suivant illustre le flux de génération et de réplication de segments dans les instances OR1
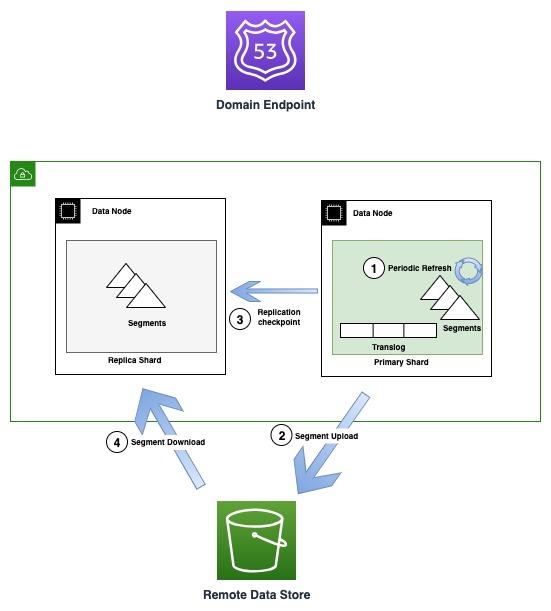
Périodiquement, à mesure que de nouveaux fichiers de segments sont créés, l'OR1 copie ces segments sur Amazon S3. Une fois le transfert terminé, le serveur principal publie de nouveaux points de contrôle sur toutes les copies de réplique, les informant de la disponibilité d'un nouveau segment en téléchargement. Les répliques téléchargent ensuite des segments plus récents et les rendent consultables. Ce modèle dissocie le flux de données qui se produit à l'aide d'Amazon S3 et le flux de contrôle (publication du point de contrôle et validation des termes) qui se produit via la communication de transport inter-nœuds.
Le diagramme suivant illustre le flux de récupération dans les instances OR1
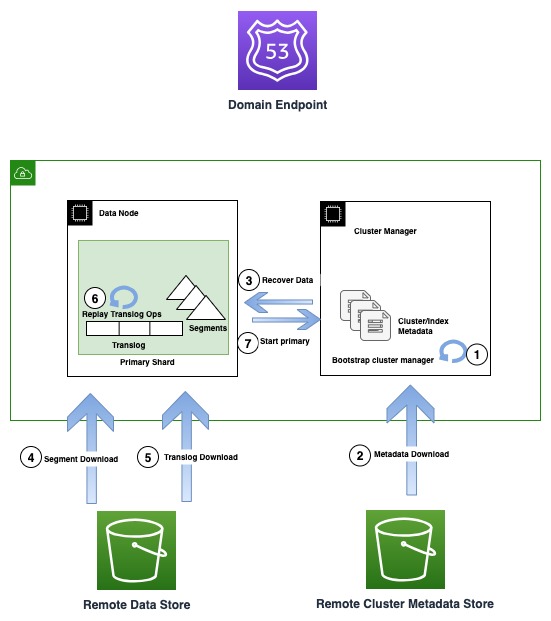
Les instances OR1 conservent non seulement les données, mais également les métadonnées du cluster telles que les mappages d'index, les modèles et les paramètres dans Amazon S3. Cela garantit qu'en cas de perte de quorum du gestionnaire de cluster, qui est un mode de défaillance courant dans les configurations de gestionnaire de cluster non dédiées, OpenSearch peut récupérer de manière fiable les dernières métadonnées reconnues.
En cas de panne d'infrastructure, un domaine OpenSearch peut finir par perdre un ou plusieurs nœuds. Dans un tel cas, la nouvelle famille d'instances garantit la récupération des métadonnées du cluster et des données d'index jusqu'à la dernière opération reconnue. À mesure que de nouveaux nœuds de remplacement rejoignent le cluster, le mécanisme de récupération de cluster interne amorce le nouvel ensemble de nœuds, puis récupère les dernières métadonnées du cluster à partir du magasin de métadonnées du cluster distant. Une fois les métadonnées du cluster récupérées, le mécanisme de récupération commence à hydrater les données de segment manquantes et à effectuer la transconnexion à partir d'Amazon S3. Ensuite, toutes les opérations de translog non validées, jusqu'à la dernière opération reconnue, sont relues pour rétablir la copie perdue.
Le nouveau design ne modifie pas le fonctionnement des recherches. Les requêtes sont traitées normalement par la partition principale ou par la partition de réplique pour chaque partition de l'index. Vous pouvez constater des délais plus longs (de l'ordre de 10 secondes) avant que toutes les copies ne soient cohérentes à un moment donné, car la réplication des données utilise Amazon S3.
L’un des principaux avantages de cette architecture est qu’elle sert de pierre angulaire aux innovations futures, telles que la séparation des lecteurs et des rédacteurs, et qu’elle permet de séparer les couches de calcul et de stockage.
Comment la redéfinition de la stratégie de réplication augmente le débit d'indexation
OpenSearch prend en charge deux stratégies de réplication : la réplication logique (document) et physique (segment). Dans le cas d'une réplication logique, les données sont indexées sur toutes les copies indépendamment, entraînant des calculs redondants sur le cluster. Les instances OR1 utilisent le nouveau réplication physique modèle, dans lequel les données sont indexées uniquement sur la copie principale et des copies supplémentaires sont créées en copiant les données de la copie principale. Avec un nombre élevé de copies de réplique, le nœud hébergeant la copie principale nécessite une bande passante réseau importante, répliquant le segment sur toutes les copies. Les nouvelles instances OR1 résolvent ce problème en conservant durablement le segment sur Amazon S3, qui est configuré comme un stockage à distance option. Ils facilitent également la mise à l'échelle des répliques sans goulot d'étranglement sur le serveur principal.
Une fois les segments téléchargés sur Amazon S3, le serveur principal envoie une demande de point de contrôle, informant tous les réplicas de télécharger les nouveaux segments. Les copies de réplique doivent ensuite télécharger les segments incrémentiels. Étant donné que ce processus libère des ressources de calcul sur les réplicas, qui sont autrement nécessaires pour indexer de manière redondante les données et la surcharge réseau encourue sur les réplicas principaux pour répliquer les données, le cluster est en mesure de générer davantage de débit. Dans le cas où les répliques ne sont pas en mesure de traiter les segments nouvellement créés, en raison d'une surcharge ou de chemins réseau lents, les répliques au-delà d'un point sont marquées comme ayant échoué pour les empêcher de renvoyer des résultats obsolètes.
Pourquoi une durabilité élevée est une bonne idée, mais difficile à réaliser correctement
Bien que tous les segments validés soient conservés de manière durable sur Amazon S3 à chaque fois qu'ils sont créés, l'un des principaux défis pour atteindre une durabilité élevée consiste à écrire de manière synchrone toutes les opérations non validées dans un journal à écriture anticipée sur Amazon S3, avant d'accuser réception de la demande au client, sans sacrifier débit. La nouvelle sémantique introduit une latence réseau supplémentaire pour les requêtes individuelles, mais nous avons veillé à ce qu'il n'y ait aucun impact sur le débit en regroupant et en drainant les requêtes sur un seul thread pendant un intervalle spécifié, tout en veillant à ce que les autres threads continuent à indexer. demandes. En conséquence, vous pouvez obtenir un débit plus élevé avec davantage de connexions client simultanées en regroupant de manière optimale vos charges utiles en masse.
D'autres défis liés à la conception d'un système hautement durable incluent le respect de l'intégrité et de l'exactitude des données à tout moment. Bien que certains événements tels que les partitions réseau soient rares, ils peuvent perturber le bon fonctionnement du système et celui-ci doit donc être préparé à faire face à ces modes de défaillance. Par conséquent, lors du passage au nouveau protocole de réplication de segments, nous avons également introduit quelques autres modifications de protocole, comme la détection de plusieurs rédacteurs sur chaque réplique. Le protocole garantit qu'un rédacteur isolé ne peut pas accuser réception d'une demande d'écriture, tandis qu'un autre principal nouvellement promu, basé sur le quorum du gestionnaire de cluster, accepte simultanément des écritures plus récentes.
La nouvelle famille d'instances détecte automatiquement la perte d'une partition principale lors de la récupération des données et effectue des vérifications approfondies de l'accessibilité du réseau avant que les données puissent être réhydratées à partir d'Amazon S3 et que le cluster soit ramené à un état sain.
Pour l'intégrité des données, tous les fichiers font l'objet d'une somme de contrôle approfondie pour garantir que nous sommes en mesure de détecter et d'empêcher toute corruption du réseau ou du système de fichiers qui pourrait rendre les données illisibles. De plus, tous les fichiers, y compris les métadonnées, sont conçus pour être immuables, offrant une sécurité supplémentaire contre les corruptions et versionnés pour éviter les modifications accidentelles.
Réinventer la façon dont les données circulent
Les instances OR1 hydratent les copies directement depuis Amazon S3 afin d'effectuer la récupération des fragments perdus lors d'une panne d'infrastructure. En utilisant Amazon S3, nous sommes en mesure de libérer la bande passante réseau, le débit du disque et le calcul du nœud principal, et donc de fournir une mise à l'échelle sur place et une expérience de déploiement bleu/vert plus transparentes en orchestrant l'ensemble du processus avec une coordination minimale du nœud principal.
OpenSearch Service fournit des sauvegardes automatiques de données appelées des instantanés à intervalles horaires, ce qui signifie qu'en cas de modifications accidentelles des données, vous avez la possibilité de revenir à un moment antérieur. Cependant, avec la nouvelle famille d'instances OpenSearch, nous avons évoqué le fait que les données sont déjà conservées de manière durable sur Amazon S3. Alors, comment fonctionnent les instantanés lorsque les données sont déjà présentes sur Amazon S3 ?
Avec la nouvelle famille d'instances, les instantanés servent de points de contrôle, faisant référence aux données de segment déjà présentes telles qu'elles existent à un moment donné. Cela rend les instantanés plus légers et plus rapides, car ils n'ont pas besoin de télécharger à nouveau des données supplémentaires. Au lieu de cela, ils téléchargent des fichiers de métadonnées qui capturent la vue des segments à ce moment précis, que nous appelons instantanés peu profonds. L'avantage des instantanés superficiels s'étend à toutes les opérations, à savoir la création, la suppression et le clonage d'instantanés. Vous avez toujours la possibilité de capturer une copie indépendante avec instantanés manuels pour d'autres opérations administratives.
Résumé
OpenSearch est un logiciel open source piloté par la communauté. La plupart des changements fondamentaux, notamment le modèle de réplication, le stockage sauvegardé à distance et les métadonnées du cluster distant, ont été apportés à l'open source ; en fait, nous suivons un premier modèle de développement open source.
Les efforts visant à améliorer le débit et la fiabilité constituent un cycle sans fin alors que nous continuons à apprendre et à nous améliorer. Les nouvelles instances optimisées OpenSearch servent de pierre angulaire, ouvrant la voie à de futures innovations. Nous sommes ravis de poursuivre nos efforts pour améliorer la fiabilité et les performances et de voir ce que les créateurs de solutions nouvelles et existantes peuvent créer à l'aide d'OpenSearch Service. Nous espérons que cela permettra de mieux comprendre la nouvelle famille d'instances OpenSearch, la manière dont cette offre atteint une durabilité élevée et un meilleur débit, et comment elle peut vous aider à configurer des clusters en fonction des besoins de votre entreprise.
Si vous êtes impatient de contribuer à OpenSearch, ouvrez un Problème GitHub et faites-nous part de vos impressions. Nous serions également ravis de connaître vos réussites en matière d’obtention d’un débit et d’une durabilité élevés sur OpenSearch Service. Si vous avez d'autres questions, veuillez laisser un commentaire.
À propos des auteurs
 Boukhtawar Khan est un ingénieur principal travaillant sur Amazon OpenSearch Service. Il s'intéresse à la construction de systèmes distribués et autonomes. Il est mainteneur et contributeur actif à OpenSearch.
Boukhtawar Khan est un ingénieur principal travaillant sur Amazon OpenSearch Service. Il s'intéresse à la construction de systèmes distribués et autonomes. Il est mainteneur et contributeur actif à OpenSearch.
 Gaurav Bafna est un ingénieur logiciel senior travaillant sur OpenSearch chez Amazon Web Services. Il est fasciné par la résolution de problèmes dans les systèmes distribués. Il est mainteneur et contributeur actif à OpenSearch.
Gaurav Bafna est un ingénieur logiciel senior travaillant sur OpenSearch chez Amazon Web Services. Il est fasciné par la résolution de problèmes dans les systèmes distribués. Il est mainteneur et contributeur actif à OpenSearch.
 Sachin chou frisé est un ingénieur senior en développement logiciel chez AWS travaillant sur OpenSearch.
Sachin chou frisé est un ingénieur senior en développement logiciel chez AWS travaillant sur OpenSearch.
 Rohin Bhargava est chef de produit senior au sein de l'équipe Amazon OpenSearch Service. Sa passion chez AWS est d'aider les clients à trouver la bonne combinaison de services AWS pour atteindre leurs objectifs commerciaux.
Rohin Bhargava est chef de produit senior au sein de l'équipe Amazon OpenSearch Service. Sa passion chez AWS est d'aider les clients à trouver la bonne combinaison de services AWS pour atteindre leurs objectifs commerciaux.
 Ranjith Ramachandra est un directeur principal de l'ingénierie travaillant sur Amazon OpenSearch Service. Il est passionné par les systèmes distribués hautement évolutifs, les systèmes performants et résilients.
Ranjith Ramachandra est un directeur principal de l'ingénierie travaillant sur Amazon OpenSearch Service. Il est passionné par les systèmes distribués hautement évolutifs, les systèmes performants et résilients.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/amazon-opensearch-service-under-the-hood-opensearch-optimized-instancesor1/

