2023 a été une année chargée pour Service Amazon OpenSearch! Apprenez-en davantage sur les versions lancées par OpenSearch Service dans le première moitié de 2023.
Au second semestre 2023, OpenSearch Service a ajouté la prise en charge de deux nouveaux Opensearch versions : 2.9 et 2.11. Ces deux versions introduisent de nouvelles fonctionnalités dans l'espace de recherche, l'espace de recherche d'apprentissage automatique (ML), les migrations et le côté opérationnel du service.
Avec la sortie de l'intégration zéro ETL avec Service de stockage simple Amazon (Amazon S3), vous pouvez analyser vos données contenues dans votre lac de données à l'aide d'OpenSearch Service pour créer des tableaux de bord et interroger les données sans avoir besoin de déplacer vos données depuis Amazon S3.
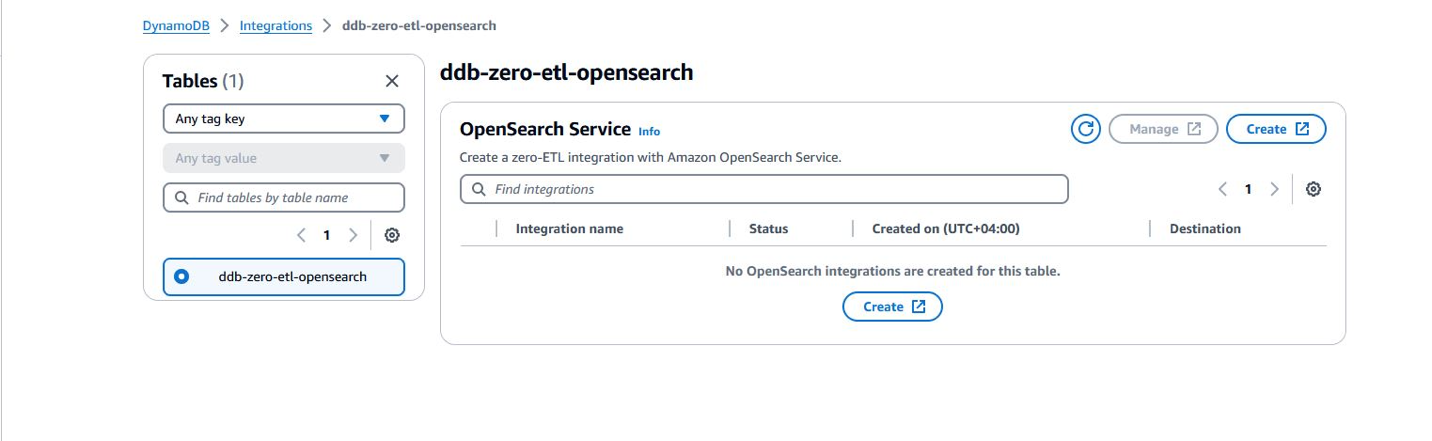
OpenSearch Service a également annoncé une nouvelle intégration zéro ETL avec Amazon DynamoDB via le plugin DynamoDB pour Ingestion d'Amazon OpenSearch. OpenSearch Ingestion s'occupe du démarrage et diffuse en continu les données de votre source DynamoDB.
OpenSearch Serverless a annoncé la disponibilité générale du Moteur vectoriel pour Amazon OpenSearch sans serveur ainsi que d'autres fonctionnalités pour améliorer votre expérience avec les collections de séries chronologiques, gérer vos coûts pour les environnements de développement et faire évoluer rapidement vos ressources pour répondre aux exigences de votre charge de travail.
Dans cet article, nous discutons des nouvelles versions d'OpenSearch Service pour permettre à votre entreprise de bénéficier de recherches, d'observabilité, d'analyses de sécurité et de migrations.
Créez des solutions rentables avec OpenSearch Service
Avec l'intégration zéro ETL pour Amazon S3, OpenSearch Service vous permet désormais d'interroger vos données sur place, réduisant ainsi les coûts de stockage. Le déplacement des données est une opération coûteuse car vous devez répliquer les données dans différents magasins de données. Cela augmente votre empreinte de données et entraîne des coûts. Le déplacement des données ajoute également à la surcharge liée à la gestion des pipelines pour migrer les données d'une source vers une nouvelle destination.
OpenSearch Service a également ajouté de nouveaux types d'instances pour les nœuds de données (Im4gn et OR1) pour vous aider à optimiser davantage vos coûts d'infrastructure. Avec un maximum de disques SSD (SSD) à mémoire non volatile (NVMe) de 30 To, l'instance Im4gn offre un stockage dense et de meilleures performances. Les instances OR1 utilisent la réplication de segments et le stockage sauvegardé à distance pour augmenter considérablement le débit des charges de travail lourdes d'indexation.
Zéro-ETL de DynamoDB vers OpenSearch Service
En novembre 2023, DynamoDB et OpenSearch Ingestion ont introduit une intégration zéro ETL pour OpenSearch Service. Les domaines OpenSearch Service et les collections OpenSearch Serverless offrent des fonctionnalités de recherche avancées, telles que la recherche en texte intégral et vectorielle, sur vos données DynamoDB. En quelques clics sur Console de gestion AWS, vous pouvez désormais charger et synchroniser en toute transparence vos données de DynamoDB vers OpenSearch Service, éliminant ainsi le besoin d'écrire du code personnalisé pour extraire, transformer et charger les données.
Requête directe (zéro ETL pour les données Amazon S3, en version préliminaire)
OpenSearch Service a annoncé une nouvelle façon d'interroger les journaux opérationnels dans les lacs de données Amazon S3 et S3 sans avoir besoin de basculer entre les outils pour analyser les données opérationnelles. Auparavant, vous deviez copier les données d'Amazon S3 vers OpenSearch Service pour profiter des riches fonctionnalités d'analyse et de visualisation d'OpenSearch afin de comprendre vos données, d'identifier les anomalies et de détecter les menaces potentielles.
Cependant, la réplication continue des données entre services peut s’avérer coûteuse et nécessite un travail opérationnel. Grâce à la fonctionnalité de requête directe d'OpenSearch Service, vous pouvez accéder aux données des journaux opérationnels stockées dans Amazon S3, sans avoir à déplacer les données elles-mêmes. Vous pouvez désormais effectuer des requêtes et des visualisations complexes sur vos données sans aucun mouvement de données.
Prise en charge d'Im4gn avec le service OpenSearch
Les instances Im4gn sont optimisées pour les charges de travail qui gèrent de grands ensembles de données et nécessitent une densité de stockage élevée par vCPU. Les instances Im4gn sont disponibles dans des tailles allant de 16xlarge à 30xlarge, avec jusqu'à 4 To de taille de disque SSD NVMe. Les instances ImXNUMXgn sont construites sur Système AWS Nitro Les SSD, qui offrent un accès disque à haut débit et à faible latence pour de meilleures performances. Les instances OpenSearch Service Im4gn prennent en charge toutes les versions d'OpenSearch et les versions d'Elasticsearch 7.9 et supérieures. Pour plus de détails, reportez-vous à Types d'instances pris en charge dans Amazon OpenSearch Service.
Présentation d'OR1, une famille d'instances optimisées OpenSearch pour l'indexation de charges de travail lourdes
En novembre 2023, OpenSearch Service a lancé OR1, la famille d'instances optimisées OpenSearch, qui offre jusqu'à 30 % d'amélioration du rapport prix-performance par rapport aux instances existantes dans les tests de référence internes et utilise Amazon S3 pour fournir 11 9s de durabilité. Un domaine avec des instances OR1 utilise Boutique de blocs élastiques Amazon (Amazon EBS) pour le stockage principal, avec des données copiées de manière synchrone sur Amazon S3 dès leur arrivée. Les instances OR1 utilisent OpenSearch fonctionnalité de réplication de segments pour permettre aux partitions de réplique de lire les données directement à partir d'Amazon S3, évitant ainsi le coût des ressources lié à l'indexation dans les partitions principales et de réplique. La famille d'instances OR1 prend également en charge la récupération automatique des données en cas de panne. Pour plus d'informations sur les options de type d'instance OR1, reportez-vous à Types d'instances de la génération actuelle dans le service OpenSearch.
Offrez à votre entreprise des fonctionnalités d'analyse de sécurité
Le plug-in Security Analytics dans OpenSearch Service prend en charge des fonctionnalités prêtes à l'emploi types de journaux préemballés et fournit des règles de détection de sécurité (règles SIGMA) pour détecter les incidents de sécurité potentiels.
Dans OpenSearch 2.9, le plug-in Security Analytics a ajouté la prise en charge des types de journaux client et la prise en charge native de Cadre de schéma de cybersécurité ouvert (OCSF) format de données. Avec ce nouveau support, vous pouvez créer des détecteurs avec des données OCSF stockées dans Lac de sécurité Amazon pour analyser les résultats de sécurité et atténuer tout incident potentiel. Le plugin Security Analytics a également ajouté la possibilité de créer vos propres types de journaux personnalisés et de créer des règles de détection personnalisées.
Créez des solutions de recherche basées sur le ML
En 2023, OpenSearch Service a investi dans l’élimination des tâches lourdes nécessaires à la création d’applications de recherche de nouvelle génération. Avec des fonctionnalités telles que des pipelines de recherche, des processeurs de recherche et des connecteurs AI/ML, OpenSearch Service a permis le développement rapide d'applications de recherche alimentées par la recherche neuronale, la recherche hybride et les résultats personnalisés. De plus, les améliorations apportées au plugin kNN ont amélioré le stockage et la récupération des données vectorielles. Les plugins facultatifs récemment lancés pour OpenSearch Service permettent une intégration transparente avec des analyseurs de langage supplémentaires et Amazon Personnaliser.
Rechercher des pipelines
Rechercher des pipelines fournir de nouvelles façons d'améliorer les requêtes de recherche et d'améliorer les résultats de recherche. Vous définissez un pipeline de recherche, puis lui envoyez vos requêtes. Lorsque vous définissez le pipeline de recherche, vous spécifiez processeurs qui transforment et augmentent vos requêtes, et reclassent vos résultats. Les processeurs de requêtes prédéfinis incluent la conversion de date, l'agrégation, la manipulation de chaînes et la conversion de type de données. Le processeur de résultats dans le pipeline de recherche intercepte et adapte les résultats à la volée avant de passer à la phase suivante. Le traitement des requêtes et des réponses pour le pipeline est effectué sur le nœud coordinateur, il n'y a donc pas de traitement au niveau de la partition.
Plugins optionnels
OpenSearch Service vous permet d'associer des fichiers préinstallés plugins OpenSearch facultatifs à utiliser avec votre domaine. Un package de plugin facultatif est compatible avec une version spécifique d'OpenSearch et ne peut être associé qu'à des domaines avec cette version. Les plugins disponibles sont répertoriés sur le Formules sur la console OpenSearch Service. Le plug-in facultatif inclut le plug-in Amazon Personalize, qui intègre OpenSearch Service à Amazon Personalize, ainsi que de nouveaux analyseurs de langage tels que Nori, Sudachi, STConvert et Pinyin.
Prise en charge de nouveaux analyseurs de langage
OpenSearch Service a ajouté la prise en charge de quatre nouveaux plugins d'analyseur de langage: Nori (coréen), Sudachi (japonais), Pinyin (chinois) et STConvert Analysis (chinois). Ceux-ci sont disponibles dans toutes les régions AWS sous forme de plugins facultatifs que vous pouvez associer à des domaines exécutant n'importe quelle version d'OpenSearch. Vous pouvez utiliser le Formules sur la console OpenSearch Service pour associer ces plugins à votre domaine, ou utilisez l'API Associate Package.
Fonction de recherche neuronale
Recherche neuronale est généralement disponible avec OpenSearch Service version 2.9 et ultérieure. La recherche neuronale vous permet d'intégrer des modèles ML hébergés à distance à l'aide du framework de diffusion de modèles. Lorsque vous utilisez une requête neuronale pendant la recherche, la recherche neuronale convertit le texte de la requête en intégrations vectorielles, utilise la recherche vectorielle pour comparer la requête et l'intégration du document et renvoie les résultats les plus proches. Lors de l'ingestion, la recherche neuronale transforme le texte du document en intégration vectorielle et indexe à la fois le texte et ses intégrations vectorielles dans un index vectoriel.
Intégration avec Amazon Personalize
OpenSearch Service a introduit un plugin facultatif à intégrer à Amazon Personalize dans les versions OpenSearch 2.9 ou ultérieures. Le plug-in OpenSearch Service pour Amazon Personalize Search Ranking vous permet d'améliorer l'engagement et la conversion des utilisateurs finaux à partir de la recherche de votre site Web et de vos applications en tirant parti des capacités d'apprentissage en profondeur offertes par Amazon Personalize. En tant que plugin optionnel, le le package est compatible avec OpenSearch version 2.9 ou ultérieure, et ne peut être associé qu'à des domaines avec cette version.
Filtrage efficace des requêtes avec k-NN FAISS d'OpenSearch
OpenSearch Service a introduit un filtrage efficace des requêtes avec k-NN FAISS d'OpenSearch dans la version 2.9 et ultérieure. OpenSearch filtres de requêtes vectorielles efficaces Cette fonctionnalité évalue intelligemment les stratégies de filtrage optimales – pré-filtrage avec le voisin le plus proche (ANN) ou filtrage avec le voisin le plus proche (k-NN) exact – afin de déterminer la meilleure stratégie pour fournir des requêtes de recherche vectorielles précises et à faible latence. Dans les versions antérieures d’OpenSearch, les requêtes vectorielles sur le moteur FAISS utilisaient des techniques de post-filtrage, qui permettaient de filtrer les requêtes à grande échelle, mais renvoyaient potentiellement moins que le nombre « k » de résultats demandé. Filtres de requêtes vectorielles efficaces fournir une faible latence et des résultats précis, vous permettant d'utiliser une recherche hybride à travers des techniques vectorielles et lexicales.
Vecteurs quantifiés en octets dans OpenSearch Service
Avec la nouvelle vecteur quantifié en octets introduit avec la version 2.9, vous pouvez réduire les besoins en mémoire d'un facteur 4 et réduire considérablement la latence de recherche, avec une perte de qualité minimale (rappel). Avec cette fonctionnalité, les flottants 32 bits habituels utilisés pour les vecteurs sont quantifiés ou convertis en entiers signés 8 bits. Pour de nombreuses applications, les données vectorielles flottantes existantes peuvent être quantifiées avec peu de perte de qualité. En comparant les benchmarks, vous constaterez que l'utilisation de vecteurs d'octets plutôt que de valeurs flottantes de 32 bits entraîne une réduction significative de l'utilisation du stockage et de la mémoire tout en améliorant le débit d'indexation et en réduisant la latence des requêtes. Un interne référence a montré que l'utilisation du stockage a été réduite jusqu'à 78 % et l'utilisation de la RAM a été réduite jusqu'à 59 % (pour l'ensemble de données Glove-200-Angular). Les valeurs de rappel des ensembles de données angulaires étaient inférieures à celles des ensembles de données euclidiennes.
Connecteurs IA/ML
OpenSearch 2.9 et versions ultérieures prennent en charge intégrations avec des modèles ML hébergés sur des services AWS ou des plateformes tierces. Cela permet aux administrateurs système et aux data scientists d'exécuter des charges de travail ML en dehors de leur domaine OpenSearch Service. Les connecteurs ML sont livrés avec un ensemble pris en charge de modèles ML : des modèles qui définissent l'ensemble de paramètres que vous devez fournir lors de l'envoi de requêtes API à un connecteur spécifique. OpenSearch Service fournit des connecteurs pour plusieurs plates-formes, telles que Amazon SageMaker, Socle amazonien, OpenAI Chat GPTet Adhérer.
Intégrations de la console OpenSearch Service
OpenSearch 2.9 et versions ultérieures ont ajouté une nouvelle fonctionnalité d'intégration sur la console. Les intégrations vous offrent un AWS CloudFormation modèle pour construire votre recherche sémantique cas d'utilisation en vous connectant à vos modèles ML hébergés sur SageMaker ou Amazon Bedrock. Le modèle CloudFormation génère le point de terminaison du modèle et enregistre l'ID du modèle auprès du domaine OpenSearch Service que vous fournissez en entrée du modèle.
Recherche hybride et normalisation de la portée
La processeur de normalisation ainsi que requête hybride s'appuie sur les deux fonctionnalités publiées plus tôt en 2023 :recherche neuronale ainsi que pipelines de recherche. Étant donné que les requêtes lexicales et sémantiques renvoient des scores de pertinence sur différentes échelles, il était difficile d'affiner les requêtes de recherche hybrides.
OpenSearch Service 2.11 prend désormais en charge un processeur de combinaison et de normalisation pour la recherche hybride. Vous pouvez désormais effectuer des requêtes de recherche hybrides, combinant des requêtes de recherche lexicales et vectorielles k-NN basées sur le langage naturel. OpenSearch Service vous permet également d'ajuster vos résultats de recherche hybrides pour une pertinence maximale à l'aide de plusieurs techniques de combinaison de notation et de normalisation.
Recherche multimodale avec Amazon Bedrock
OpenSearch Service 2.11 lance la prise en charge de la recherche multimodale qui vous permet de rechercher des données de texte et d'image à l'aide de modèles d'intégration multimodaux. Pour générer des représentations vectorielles vectorielles, vous devez créer un pipeline d'ingestion contenant un processeur text_image_embedding, qui convertit les binaires de texte ou d'image dans un champ de document en intégrations vectorielles. Vous pouvez utiliser la clause de requête neuronale, soit dans le API du plugin k-NN or Interroger DSL requêtes, pour effectuer une combinaison de recherches de texte et d’images. Vous pouvez utiliser les nouvelles fonctionnalités d'intégration d'OpenSearch Service pour démarrer rapidement avec la recherche multimodale.
Récupération neuronale clairsemée
La recherche neuronale éparse, une nouvelle méthode efficace de récupération sémantique, est disponible dans OpenSearch Service 2.11. La recherche neuronale clairsemée fonctionne selon deux modes : bi-encodeur et document uniquement. Avec le mode bi-encodeur, les documents et les requêtes de recherche passent par des encodeurs profonds. En mode document uniquement, seuls les documents passent par des encodeurs profonds, tandis que les requêtes de recherche sont tokenisées. Un encodeur clairsemé de document uniquement génère un index qui représente 10.4 % de la taille d'un index de codage dense. Pour un bi-encodeur, la taille de l'index est de 7.2 % de la taille d'un index de codage dense. La recherche neuronale clairsemée est activée par des modèles de codage clairsemés qui créent des intégrations vectorielles clairsemées : un ensemble de <token: weight> paires représentant l'entrée de texte et son poids correspondant dans le vecteur clairsemé. Pour en savoir plus sur les modèles pré-entraînés pour la recherche neuronale clairsemée, reportez-vous à Modèles de codage clairsemés.
La recherche neuronale clairsemée réduit les coûts, améliore la pertinence de la recherche et présente une latence plus faible. Vous pouvez utiliser les nouvelles fonctionnalités d’intégration d’OpenSearch Service pour démarrer rapidement avec la recherche neuronale clairsemée.
Mises à jour de l'ingestion OpenSearch
Ingestion OpenSearch est un pipeline d'ingestion entièrement géré et mis à l'échelle automatiquement qui transmet vos données aux domaines OpenSearch Service et aux collections OpenSearch Serverless. Depuis sa sortie en 2023, OpenSearch Ingestion continue d'ajouter de nouvelles fonctionnalités pour faciliter la transformation et le déplacement de vos données. sources prises en charge vers des destinations en aval telles que OpenSearch Service, OpenSearch Serverless et Amazon S3.
Nouvelles fonctionnalités de migration dans OpenSearch Ingestion
En novembre 2023, OpenSearch Ingestion a annoncé la sortie de nouvelles fonctionnalités pour prendre en charge la migration des données des domaines Elasticsearch version 7.x autogérés vers les dernières versions d'OpenSearch Service.
OpenSearch Ingestion prend également en charge la migration des données des domaines gérés par OpenSearch Service exécutant OpenSearch version 2.x vers les collections OpenSearch Serverless.
Découvrez comment utiliser OpenSearch Ingestion pour migrez vos données vers OpenSearch Service.

Améliorez la durabilité des données avec OpenSearch Ingestion
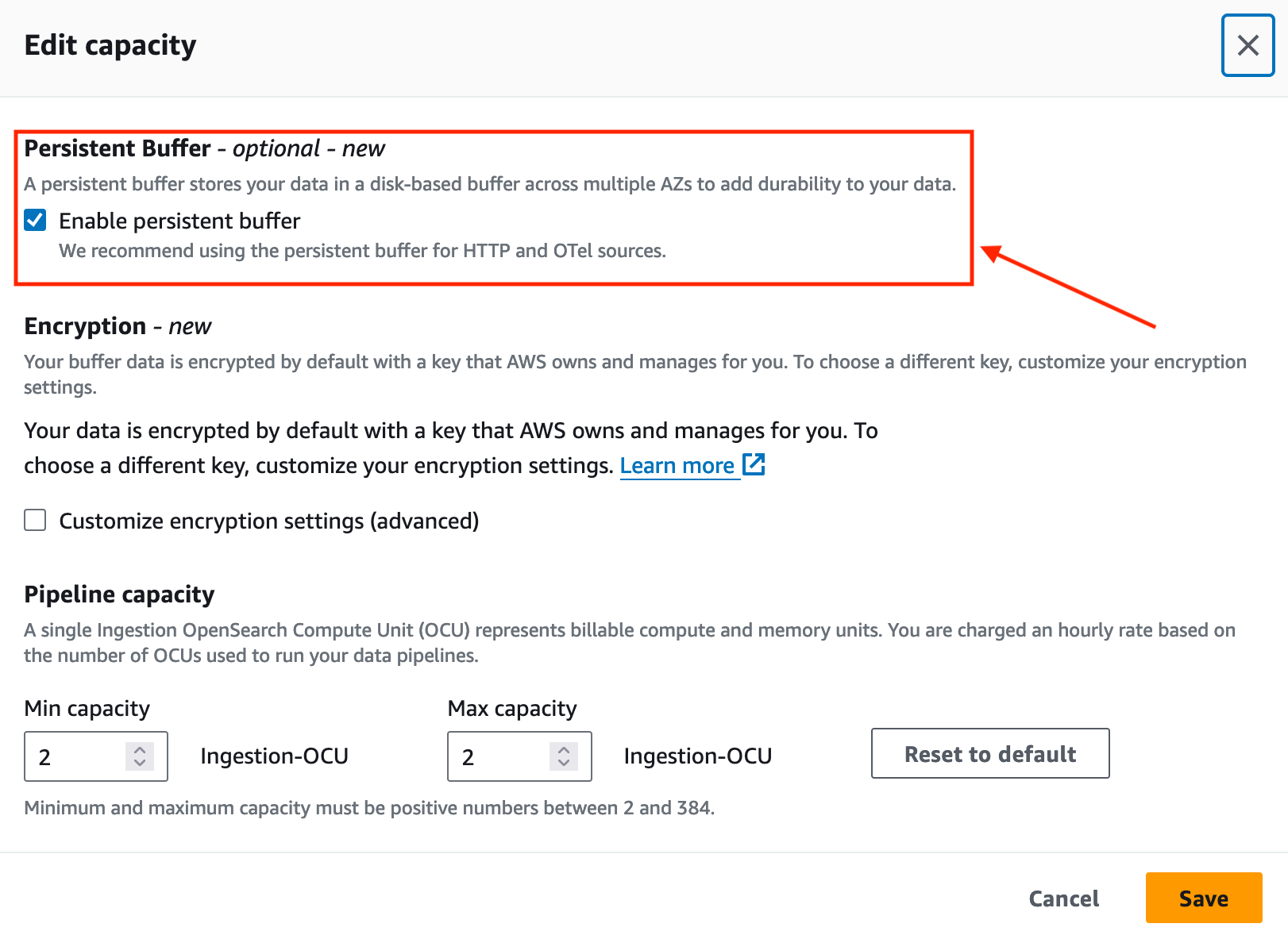
En novembre 2023, OpenSearch Ingestion a introduit la mise en mémoire tampon persistante pour les sources push telles que les sources HTTP (HTTP, Fluentd, FluentBit) et les collecteurs OpenTelemetry.
Par défaut, OpenSearch Ingestion utilise la mise en mémoire tampon en mémoire. Grâce à la mise en mémoire tampon persistante, OpenSearch Ingestion stocke vos données dans un magasin sur disque plus résilient. Si vous disposez de pipelines d'ingestion existants, vous pouvez activer la mise en mémoire tampon persistante pour ces pipelines, comme indiqué dans la capture d'écran suivante.
Prise en charge de nouveaux plugins
Début 2023, OpenSearch Ingestion a ajouté la prise en charge de Amazon Managed Streaming pour Apache Kafka (Amazon MSK). L'ingestion OpenSearch utilise le Plugin Kafka pour diffuser des données d'Amazon MSK vers des domaines gérés par OpenSearch Service ou des collections OpenSearch Serverless. Pour en savoir plus sur la configuration d'Amazon MSK en tant que source de données, consultez Utilisation d'un pipeline d'ingestion OpenSearch avec Amazon Managed Streaming pour Apache Kafka.
Mises à jour d'OpenSearch sans serveur
OpenSearch Serverless a continué d'améliorer votre expérience sans serveur avec OpenSearch en introduisant la prise en charge d'une nouvelle collection de recherches vectorielles de type pour stocker les intégrations et exécuter une recherche de similarité. OpenSearch Serverless prend désormais en charge la mise à l'échelle des répliques de partitions pour gérer les pics de débit des requêtes. Et si vous utilisez une collection de séries chronologiques, vous pouvez désormais configurer votre politique de conservation des données personnalisée pour qu'elle corresponde à vos exigences en matière de conservation des données.
Moteur vectoriel pour OpenSearch sans serveur
En novembre 2023, nous avons lancé le moteur vectoriel pour Amazon OpenSearch Serverless. Le moteur vectoriel facilite la création d'expériences de recherche modernes optimisées par le ML et d'applications d'intelligence artificielle générative (IA générative) sans avoir besoin de gérer l'infrastructure de base de données vectorielles sous-jacente. Il vous permet également d'exécuter une recherche hybride, combinant la recherche vectorielle et la recherche en texte intégral dans la même requête, éliminant ainsi le besoin de gérer et de maintenir des magasins de données séparés ou une pile d'applications complexe.
Environnements de développement et de test OpenSearch Serverless à moindre coût
OpenSearch Serverless prend désormais en charge les charges de travail de développement et de test en vous permettant d'éviter d'exécuter une réplique. La suppression des répliques élimine le besoin de disposer d'OCU redondants dans une autre zone de disponibilité uniquement à des fins de disponibilité. Si vous utilisez OpenSearch Serverless pour le développement et les tests, où la disponibilité n'est pas un problème, vous pouvez réduire vos OCU minimum de 4 à 2.
OpenSearch Serverless prend en charge la suppression automatisée des données basée sur le temps à l'aide de politiques de cycle de vie des données
En décembre 2023, OpenSearch Serverless a annoncé la prise en charge de la gestion de la conservation des données des collections et index de séries chronologiques. Avec la nouvelle fonctionnalité de suppression automatisée des données basée sur le temps, vous pouvez spécifier la durée pendant laquelle vous souhaitez conserver les données. OpenSearch Serverless gère automatiquement le cycle de vie des données en fonction de cette configuration. Pour en savoir plus, reportez-vous à Amazon OpenSearch Serverless prend désormais en charge la suppression automatique des données en fonction du temps.
OpenSearch Serverless a annoncé la prise en charge de la mise à l'échelle des répliques au niveau des partitions
Au lancement, OpenSearch Serverless prenait automatiquement en charge l’augmentation de la capacité en réponse à l’augmentation de la taille des données. Avec le nouvelle mise à l'échelle des répliques de fragments fonctionnalité, OpenSearch Serverless détecte automatiquement les fragments soumis à la contrainte en raison de pics soudains des taux de requêtes et ajoute dynamiquement de nouvelles répliques de fragments pour gérer le débit accru des requêtes tout en maintenant des temps de réponse rapides. Cette approche s'avère plus rentable que la simple ajout de nouveaux réplicas d'index.
Notifications utilisateur AWS pour surveiller votre utilisation de l'OCU
Avec ce lancement, vous pouvez configurer le système pour envoyer des notifications lorsque l'utilisation de l'OCU approche ou a atteint les limites maximales configurées pour la recherche ou l'ingestion. Avec la nouvelle intégration AWS User Notification, vous pouvez configurer le système pour envoyer des notifications chaque fois que le seuil de capacité est dépassé. La fonction de notification utilisateur élimine le besoin de surveiller le service en permanence. Pour plus d'informations, voir Surveillance d'Amazon OpenSearch Serverless à l'aide des notifications utilisateur AWS.
Améliorez votre expérience avec les tableaux de bord OpenSearch
OpenSearch 2.9 dans OpenSearch Service a introduit de nouvelles fonctionnalités pour faciliter l'analyse rapide de vos données dans les tableaux de bord OpenSearch. Ces nouvelles fonctionnalités incluent les nouveaux tableaux de bord préconfigurés prêts à l'emploi avec OpenSearch Integrations et la possibilité de créer des alertes et une détection d'anomalies à partir d'une visualisation existante dans vos tableaux de bord.
Intégrations du tableau de bord OpenSearch
OpenSearch 2.9 a ajouté la prise en charge des intégrations OpenSearch dans les tableaux de bord OpenSearch. Les intégrations OpenSearch incluent des tableaux de bord préconfigurés afin que vous puissiez rapidement commencer à analyser vos données provenant de sources populaires telles que AWS CloudFront, AWSWAF, AWS CloudTrailet Cloud privé virtuel Amazon (Amazon VPC). Journaux de flux.
Alertes et anomalies dans les tableaux de bord OpenSearch
Dans OpenSearch Service 2.9, vous pouvez créer un nouveau moniteur d'alerte directement à partir de votre visualisation d'un graphique linéaire dans les tableaux de bord OpenSearch. Vous pouvez également associer les moniteurs ou détecteurs existants précédemment créés dans OpenSearch à la visualisation du tableau de bord.
Cette nouvelle fonctionnalité permet de réduire les changements de contexte entre les tableaux de bord et les plugins d'alerte ou de détection d'anomalies. Reportez-vous au tableau de bord suivant pour ajouter un moniteur d'alerte afin de détecter les baisses du volume moyen de données dans vos services.

OpenSearch étend la prise en charge des agrégations géospatiales
Avec OpenSearch version 2.9, OpenSearch Service a ajouté la prise en charge de trois types de géoforme agrégation de données via API : limites_géo, géo_hashet géo_tile.
Le type de champ géoforme offre la possibilité d'indexer les données de localisation dans différents formats géographiques tels qu'un point, un polygone ou une chaîne de lignes. Avec les nouveaux types d'agrégation, vous disposez de plus de flexibilité pour agréger des documents à partir d'un index à l'aide d'agrégations géospatiales métriques et multi-compartiments.
Mises à jour opérationnelles du service OpenSearch
OpenSearch Service a supprimé la nécessité d'exécuter un déploiement bleu/vert lors de la modification des nœuds gérés du domaine. De plus, le service a amélioré les événements Auto-Tune avec la prise en charge de nouvelles métriques Auto-Tune pour suivre les modifications au sein de votre domaine OpenSearch Service.
OpenSearch Service vous permet désormais de mettre à jour les nœuds du gestionnaire de domaine sans déploiement bleu/vert
Depuis le début du deuxième semestre 2, OpenSearch Service vous permettait de modifier le type d'instance ou le nombre d'instances des nœuds de gestionnaire de cluster dédiés sans avoir besoin d'un déploiement bleu/vert. Cette amélioration permet des mises à jour plus rapides avec une interruption minimale des opérations de votre domaine, tout en évitant tout mouvement de données.
Auparavant, la mise à jour de vos nœuds de gestionnaire de cluster dédiés sur OpenSearch Service impliquait l'utilisation d'un déploiement bleu/vert pour effectuer la modification. Bien que les déploiements bleu/vert visent à éviter toute interruption de vos domaines, étant donné que le déploiement utilise des ressources supplémentaires sur le domaine, il est recommandé de les effectuer pendant les périodes de faible trafic. Vous pouvez désormais mettre à jour les types d'instances du gestionnaire de cluster ou le nombre d'instances sans nécessiter de déploiement bleu/vert, afin que ces mises à jour puissent s'effectuer plus rapidement tout en évitant toute interruption potentielle des opérations de votre domaine. Dans les cas où vous modifiez à la fois le type et le nombre d'instances du gestionnaire de domaine, OpenSearch Service utilisera toujours un déploiement bleu/vert pour effectuer la modification. Vous pouvez utiliser l'option d'exécution à sec pour vérifier si votre modification nécessite un déploiement bleu/vert.
Expérience de réglage automatique améliorée
En septembre 2023, OpenSearch Service a ajouté de nouvelles métriques Auto-Tune et des événements Auto-Tune améliorés qui vous offrent une meilleure visibilité sur les optimisations de performances de domaine réalisées par Auto-Tune.
Auto-Tune est un système de gestion de ressources adaptatif qui met automatiquement à jour les ressources de domaine OpenSearch Service pour améliorer l'efficacité et les performances. Par exemple, Auto-Tune optimise la configuration liée à la mémoire, telle que la taille des files d'attente, la taille du cache et les paramètres de la machine virtuelle Java (JVM) sur vos nœuds.
Avec ce lancement, vous pouvez désormais auditer l'historique des modifications, ainsi que les suivre en temps réel depuis le Amazon Cloud Watch console.
De plus, OpenSearch Service publie désormais les détails des modifications apportées à Amazon Event Bridge lorsque les paramètres de réglage automatique sont recommandés ou appliqués à un domaine OpenSearch Service. Ces événements de réglage automatique seront également visibles sur le Notifications sur la console OpenSearch Service.
Accélérez votre migration vers OpenSearch Service avec la nouvelle solution Migration Assistant
En novembre 2023, l'équipe OpenSearch a lancé une nouvelle solution open source :Assistant de migration pour Amazon OpenSearch Service. La solution prend en charge la migration des données des domaines Elasticsearch et OpenSearch autogérés vers OpenSearch Service, prenant en charge Elasticsearch 7.x (<=7.10), OpenSearch 1.x et OpenSearch 2.x comme sources de migration. La solution facilite la migration des données existantes et en direct entre la source et la destination.
Conclusion
Dans cet article, nous avons couvert les nouvelles versions d'OpenSearch Service pour vous aider à innover votre entreprise en matière de recherche, d'observabilité, d'analyse de sécurité et de migrations. Nous vous avons fourni des informations sur le moment d'utiliser chaque nouvelle fonctionnalité d'OpenSearch Service, OpenSearch Ingestion et OpenSearch Serverless.
Apprenez-en davantage sur les tableaux de bord OpenSearch et les plugins OpenSearch ainsi que sur le nouvel assistant OpenSearch passionnant utilisant Terrain de jeu OpenSearch.
Découvrez les fonctionnalités décrites dans cet article et nous apprécions que vous nous fournissiez vos précieux commentaires.
À propos des auteurs
 Jon Gestionnaire est architecte de solutions principal senior chez Amazon Web Services basé à Palo Alto, en Californie. Jon travaille en étroite collaboration avec OpenSearch et Amazon OpenSearch Service, fournissant aide et conseils à un large éventail de clients qui souhaitent migrer des charges de travail de recherche et d'analyse de journaux vers le cloud AWS. Avant de rejoindre AWS, la carrière de Jon en tant que développeur de logiciels comprenait 4 ans de codage d'un moteur de recherche de commerce électronique à grande échelle. Jon est titulaire d'un baccalauréat ès arts de l'Université de Pennsylvanie, ainsi que d'une maîtrise ès sciences et d'un doctorat en informatique et intelligence artificielle de l'Université Northwestern.
Jon Gestionnaire est architecte de solutions principal senior chez Amazon Web Services basé à Palo Alto, en Californie. Jon travaille en étroite collaboration avec OpenSearch et Amazon OpenSearch Service, fournissant aide et conseils à un large éventail de clients qui souhaitent migrer des charges de travail de recherche et d'analyse de journaux vers le cloud AWS. Avant de rejoindre AWS, la carrière de Jon en tant que développeur de logiciels comprenait 4 ans de codage d'un moteur de recherche de commerce électronique à grande échelle. Jon est titulaire d'un baccalauréat ès arts de l'Université de Pennsylvanie, ainsi que d'une maîtrise ès sciences et d'un doctorat en informatique et intelligence artificielle de l'Université Northwestern.
 Hajer Bouafif est un architecte de solutions spécialisé en analyse chez Amazon Web Services. Elle se concentre sur Amazon OpenSearch Service et aide les clients à concevoir et à créer des charges de travail d'analyse bien architecturées dans divers secteurs. Hajer aime passer du temps à l'extérieur et découvrir de nouvelles cultures.
Hajer Bouafif est un architecte de solutions spécialisé en analyse chez Amazon Web Services. Elle se concentre sur Amazon OpenSearch Service et aide les clients à concevoir et à créer des charges de travail d'analyse bien architecturées dans divers secteurs. Hajer aime passer du temps à l'extérieur et découvrir de nouvelles cultures.
 Aruna Govindaraju est un architecte de solutions spécialisé Amazon OpenSearch et a travaillé avec de nombreux moteurs de recherche commerciaux et open source. Elle est passionnée par la recherche, la pertinence et l'expérience utilisateur. Son expertise dans la corrélation des signaux des utilisateurs finaux avec le comportement des moteurs de recherche a aidé de nombreux clients à améliorer leur expérience de recherche.
Aruna Govindaraju est un architecte de solutions spécialisé Amazon OpenSearch et a travaillé avec de nombreux moteurs de recherche commerciaux et open source. Elle est passionnée par la recherche, la pertinence et l'expérience utilisateur. Son expertise dans la corrélation des signaux des utilisateurs finaux avec le comportement des moteurs de recherche a aidé de nombreux clients à améliorer leur expérience de recherche.
 Prashant Agrawal est un architecte de solutions spécialiste de la recherche senior avec Amazon OpenSearch Service. Il travaille en étroite collaboration avec les clients pour les aider à migrer leurs charges de travail vers le cloud et aide les clients existants à affiner leurs clusters pour obtenir de meilleures performances et réduire les coûts. Avant de rejoindre AWS, il a aidé divers clients à utiliser OpenSearch et Elasticsearch pour leurs cas d'utilisation de recherche et d'analyse de journaux. Lorsqu'il ne travaille pas, vous pouvez le trouver en train de voyager et d'explorer de nouveaux endroits. Bref, il aime faire Manger → Voyager → Répéter.
Prashant Agrawal est un architecte de solutions spécialiste de la recherche senior avec Amazon OpenSearch Service. Il travaille en étroite collaboration avec les clients pour les aider à migrer leurs charges de travail vers le cloud et aide les clients existants à affiner leurs clusters pour obtenir de meilleures performances et réduire les coûts. Avant de rejoindre AWS, il a aidé divers clients à utiliser OpenSearch et Elasticsearch pour leurs cas d'utilisation de recherche et d'analyse de journaux. Lorsqu'il ne travaille pas, vous pouvez le trouver en train de voyager et d'explorer de nouveaux endroits. Bref, il aime faire Manger → Voyager → Répéter.
 Musulman Abou Taha est un architecte de solutions spécialiste senior d'OpenSearch qui se consacre à guider les clients à travers des migrations transparentes de la charge de travail de recherche, à affiner les clusters pour des performances optimales et à garantir la rentabilité. Avec une formation de responsable de compte technique (TAM), Muslim apporte une riche expérience dans l'assistance aux entreprises clientes dans l'adoption du cloud et l'optimisation de leurs différents ensembles de charges de travail. Muslim aime passer du temps avec sa famille, voyager et explorer de nouveaux endroits.
Musulman Abou Taha est un architecte de solutions spécialiste senior d'OpenSearch qui se consacre à guider les clients à travers des migrations transparentes de la charge de travail de recherche, à affiner les clusters pour des performances optimales et à garantir la rentabilité. Avec une formation de responsable de compte technique (TAM), Muslim apporte une riche expérience dans l'assistance aux entreprises clientes dans l'adoption du cloud et l'optimisation de leurs différents ensembles de charges de travail. Muslim aime passer du temps avec sa famille, voyager et explorer de nouveaux endroits.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/amazon-opensearch-h2-2023-in-review/

