Les modèles de langage génératifs se sont révélés remarquablement efficaces pour résoudre des tâches logiques et analytiques de traitement du langage naturel (NLP). Par ailleurs, l'utilisation de ingénierie rapide peuvent notamment améliorer leurs performances. Par exemple, chaîne de pensée (CoT) est connu pour améliorer la capacité d'un modèle à résoudre des problèmes complexes en plusieurs étapes. Pour améliorer davantage la précision des tâches impliquant un raisonnement, un cohérence de soi Une approche d'incitation a été suggérée, qui remplace le décodage gourmand par un décodage stochastique lors de la génération du langage.
Socle amazonien est un service entièrement géré qui offre un choix de modèles de base très performants provenant de grandes sociétés d'IA et d'Amazon via une API unique, ainsi qu'un large éventail de fonctionnalités pour créer IA générative applications avec sécurité, confidentialité et IA responsable. Avec le inférence par lots API, vous pouvez utiliser Amazon Bedrock pour exécuter des inférences avec des modèles de base par lots et obtenir des réponses plus efficacement. Cet article montre comment implémenter des invites d'auto-cohérence via l'inférence par lots sur Amazon Bedrock pour améliorer les performances du modèle sur les tâches de raisonnement arithmétique et à choix multiples.
Présentation de la solution
L'incitation à l'auto-cohérence des modèles de langage repose sur la génération de réponses multiples qui sont regroupées dans une réponse finale. Contrairement aux approches à génération unique comme CoT, la procédure d'échantillonnage et de marginalisation d'auto-cohérence crée une gamme de complétions de modèle qui conduisent à une solution plus cohérente. La génération de réponses différentes pour une invite donnée est possible grâce à l’utilisation d’une stratégie de décodage stochastique plutôt que gourmande.
La figure suivante montre en quoi l’autocohérence diffère du CoT gourmand en ce sens qu’elle génère un ensemble diversifié de chemins de raisonnement et les agrège pour produire la réponse finale.

Stratégies de décodage pour la génération de texte
Le texte généré par les modèles de langage à décodeur uniquement se déroule mot par mot, le jeton suivant étant prédit sur la base du contexte précédent. Pour une invite donnée, le modèle calcule une distribution de probabilité indiquant la probabilité que chaque jeton apparaisse ensuite dans la séquence. Le décodage implique la traduction de ces distributions de probabilité en texte réel. La génération de texte est médiée par un ensemble de paramètres d'inférence qui sont souvent des hyperparamètres de la méthode de décodage elle-même. Un exemple est le la réactivité, qui module la distribution de probabilité du prochain jeton et influence le caractère aléatoire de la sortie du modèle.
Décodage gourmand est une stratégie de décodage déterministe qui sélectionne à chaque étape le jeton avec la probabilité la plus élevée. Bien que simple et efficace, cette approche risque de tomber dans des schémas répétitifs, car elle ne tient pas compte de l’espace probabiliste plus large. Fixer le paramètre de température à 0 au moment de l'inférence équivaut essentiellement à mettre en œuvre un décodage glouton.
Échantillonnage introduit la stochasticité dans le processus de décodage en sélectionnant au hasard chaque jeton suivant sur la base de la distribution de probabilité prédite. Ce caractère aléatoire se traduit par une plus grande variabilité de la production. Le décodage stochastique s’avère plus apte à capturer la diversité des résultats potentiels et produit souvent des réponses plus imaginatives. Des valeurs de température plus élevées introduisent davantage de fluctuations et augmentent la créativité de la réponse du modèle.
Techniques d'incitation : CoT et auto-cohérence
La capacité de raisonnement des modèles de langage peut être augmentée grâce à une ingénierie rapide. En particulier, il a été démontré que CoT susciter un raisonnement dans des tâches complexes de PNL. Une façon de mettre en œuvre un coup zéro CoT s'effectue via une augmentation rapide avec l'instruction de « penser étape par étape ». Une autre consiste à exposer le modèle à des exemples d'étapes de raisonnement intermédiaires dans invitation à quelques tirs mode. Les deux scénarios utilisent généralement un décodage gourmand. CoT entraîne des gains de performances significatifs par rapport à de simples instructions sur des tâches de raisonnement arithmétique, de bon sens et de raisonnement symbolique.
Invite d'auto-cohérence repose sur l’hypothèse selon laquelle l’introduction de diversité dans le processus de raisonnement peut être bénéfique pour aider les modèles à converger vers la bonne réponse. La technique utilise le décodage stochastique pour atteindre cet objectif en trois étapes :
- Invitez le modèle de langage avec des exemples CoT pour susciter un raisonnement.
- Remplacez le décodage glouton par une stratégie d'échantillonnage pour générer un ensemble diversifié de chemins de raisonnement.
- Agrégez les résultats pour trouver la réponse la plus cohérente dans l’ensemble de réponses.
Il a été démontré que l'auto-cohérence surpasse les invites CoT sur les critères de référence populaires en matière d'arithmétique et de raisonnement de bon sens. Une limite de cette approche est son coût de calcul plus élevé.
Cet article montre comment les invites d'auto-cohérence améliorent les performances des modèles de langage génératifs sur deux tâches de raisonnement PNL : la résolution de problèmes arithmétiques et la réponse à des questions à choix multiples spécifiques à un domaine. Nous démontrons l'approche utilisant l'inférence par lots sur Amazon Bedrock :
- Nous accédons au SDK Amazon Bedrock Python dans JupyterLab sur un Amazon Sage Maker instance de bloc-notes.
- Pour un raisonnement arithmétique, nous demandons Commande Cohere sur l'ensemble de données GSM8K des problèmes de mathématiques à l'école primaire.
- Pour un raisonnement à choix multiples, nous demandons AI21 Labs Jurassic-2 Milieu sur un petit échantillon de questions de l'examen AWS Certified Solutions Architect – Associate.
Pré-requis
Cette procédure pas à pas suppose les conditions préalables suivantes :

Le coût estimé pour exécuter le code présenté dans cet article est de 100 $, en supposant que vous exécutez une invite d'auto-cohérence une fois avec 30 chemins de raisonnement en utilisant une valeur pour l'échantillonnage basé sur la température.
Ensemble de données pour sonder les capacités de raisonnement arithmétique
GSM8K est un ensemble de données de problèmes mathématiques d'école primaire assemblés par des humains et présentant une grande diversité linguistique. Chaque problème nécessite 2 à 8 étapes à résoudre et nécessite d'effectuer une séquence de calculs élémentaires avec des opérations arithmétiques de base. Ces données sont couramment utilisées pour évaluer les capacités de raisonnement arithmétique en plusieurs étapes des modèles de langage génératif. Le Coffret GSM8K comprend 7,473 XNUMX enregistrements. Ce qui suit est un exemple:
{"question": "Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?", "answer": "Natalia sold 48/2 = <<48/2=24>>24 clips in May.nNatalia sold 48+24 = <<48+24=72>>72 clips altogether in April and May.n#### 72"}
Configurer pour exécuter l'inférence par lots avec Amazon Bedrock
L'inférence par lots vous permet d'exécuter plusieurs appels d'inférence vers Amazon Bedrock de manière asynchrone et d'améliorer les performances de l'inférence de modèle sur de grands ensembles de données. Le service est en version préliminaire au moment d'écrire ces lignes et est uniquement disponible via l'API. Faire référence à Exécuter l'inférence par lots pour accéder aux API d'inférence par lots via des SDK personnalisés.
Après avoir téléchargé et décompressé le SDK Python dans une instance de notebook SageMaker, vous pouvez l'installer en exécutant le code suivant dans une cellule de notebook Jupyter :
Formater et télécharger les données d'entrée sur Amazon S3
Les données d'entrée pour l'inférence par lots doivent être préparées au format JSONL avec recordId ainsi que modelInput clés. Ce dernier doit correspondre au champ body du modèle à invoquer sur Amazon Bedrock. En particulier, certains paramètres d'inférence pris en charge pour la commande Cohere temperature pour le hasard, max_tokens pour la longueur de sortie, et num_generations pour générer plusieurs réponses, qui sont toutes transmises avec le prompt as modelInput:
See Paramètres d'inférence pour les modèles de fondation pour plus de détails, y compris d’autres fournisseurs de modèles.
Nos expériences sur le raisonnement arithmétique sont réalisées en quelques coups sans personnaliser ni affiner Cohere Command. Nous utilisons le même ensemble de huit exemples tirés de la chaîne de pensée (Tableau 20) et l'autocohérence (Tableau 17) papiers. Des invites sont créées en concaténant les exemples avec chaque question de la rame GSM8K.
Nous fixons max_tokens à 512 et num_generations à 5, le maximum autorisé par Cohere Command. Pour un décodage gourmand, on pose temperature à 0 et par souci d'autocohérence, nous effectuons trois expériences à des températures de 0.5, 0.7 et 1. Chaque paramètre produit des données d'entrée différentes en fonction des valeurs de température respectives. Les données sont formatées au format JSONL et stockées dans Amazon S3.
Créer et exécuter des tâches d'inférence par lots dans Amazon Bedrock
La création de tâches d'inférence par lots nécessite un client Amazon Bedrock. Nous spécifions les chemins d'entrée et de sortie S3 et attribuons à chaque tâche d'invocation un nom unique :
Les emplois sont créée en transmettant le rôle IAM, l'ID de modèle, le nom de la tâche et la configuration d'entrée/sortie comme paramètres à l'API Amazon Bedrock :
inscription, Stack monitoringet arrêt Les tâches d'inférence par lots sont prises en charge par leurs appels d'API respectifs. Lors de la création, les emplois apparaissent en premier Submitted, alors comme InProgress, et enfin comme Stopped, Failedou Completed.
Si les tâches sont terminées avec succès, le contenu généré peut être récupéré à partir d'Amazon S3 à l'aide de son emplacement de sortie unique.
[Out]: 'Natalia sold 48 * 1/2 = 24 clips less in May. This means she sold 48 + 24 = 72 clips in April and May. The answer is 72.'
L'autocohérence améliore la précision du modèle sur les tâches arithmétiques
L'invite d'auto-cohérence de Cohere Command surpasse une ligne de base gourmande de CoT en termes de précision sur l'ensemble de données GSM8K. Pour des raisons d'autocohérence, nous échantillonnons 30 chemins de raisonnement indépendants à trois températures différentes, avec topP ainsi que topK mis à leur les valeurs par défaut. Les solutions finales sont regroupées en choisissant l'occurrence la plus cohérente via un vote majoritaire. En cas d’égalité, nous choisissons au hasard une des réponses majoritaires. Nous calculons les valeurs de précision et d’écart type en moyenne sur 100 analyses.
La figure suivante montre la précision de l'ensemble de données GSM8K de Cohere Command, avec un CoT gourmand (bleu) et une auto-cohérence aux valeurs de température 0.5 (jaune), 0.7 (vert) et 1.0 (orange) en fonction du nombre d'échantillons. chemins de raisonnement.
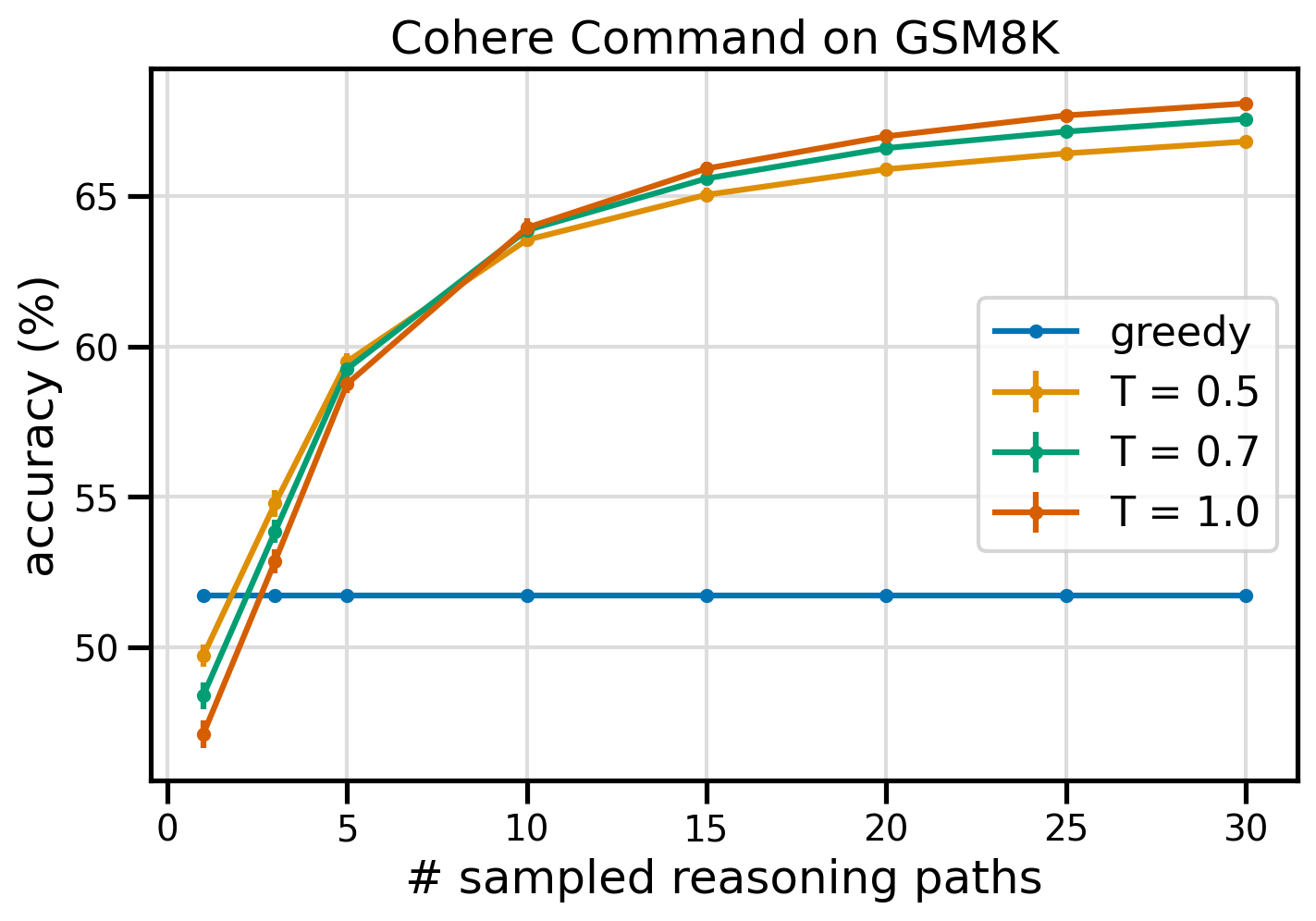
La figure précédente montre que l’auto-cohérence améliore la précision arithmétique par rapport au CoT glouton lorsque le nombre de chemins échantillonnés est aussi faible que trois. Les performances augmentent de manière constante avec d'autres chemins de raisonnement, confirmant l'importance d'introduire de la diversité dans la génération de pensée. Cohere Command résout l'ensemble de questions GSM8K avec une précision de 51.7 % lorsque CoT y est invité, contre 68 % avec 30 chemins de raisonnement auto-cohérents à T=1.0. Les trois valeurs de température étudiées donnent des résultats similaires, les températures plus basses étant comparativement plus performantes sur des trajets moins échantillonnés.
Considérations pratiques sur l’efficacité et le coût
L'auto-cohérence est limitée par l'augmentation du temps de réponse et des coûts liés à la génération de plusieurs sorties par invite. À titre d'illustration pratique, l'inférence par lots pour la génération gourmande avec Cohere Command sur 7,473 8 enregistrements GSM20K s'est terminée en moins de 5.5 minutes. Le travail a nécessité 630,000 millions de jetons en entrée et a généré XNUMX XNUMX jetons en sortie. À l'heure actuelle Prix d’inférence d’Amazon Bedrock, le coût total encouru était d'environ 9.50 $.
Pour l'auto-cohérence avec Cohere Command, nous utilisons le paramètre d'inférence num_generations pour créer plusieurs complétions par invite. Au moment d'écrire ces lignes, Amazon Bedrock autorise un maximum de cinq générations et trois Submitted tâches d'inférence par lots. Les travaux se poursuivent vers le InProgress l'état de manière séquentielle, donc l'échantillonnage de plus de cinq chemins nécessite plusieurs appels.
La figure suivante montre les temps d'exécution de Cohere Command sur l'ensemble de données GSM8K. La durée d'exécution totale est affichée sur l'axe des x et la durée d'exécution par chemin de raisonnement échantillonné sur l'axe des y. La génération gourmande s'exécute dans les plus brefs délais mais entraîne un coût en temps plus élevé par chemin échantillonné.

La génération gourmande se termine en moins de 20 minutes pour l’ensemble complet du GSM8K et échantillonne un chemin de raisonnement unique. L'autocohérence avec cinq échantillons nécessite environ 50 % de plus de temps et coûte environ 14.50 $, mais produit cinq chemins (plus de 500 %) pendant cette période. La durée d'exécution totale et le coût augmentent progressivement avec cinq chemins échantillonnés supplémentaires. Une analyse coûts-avantages suggère que 1 à 2 tâches d'inférence par lots avec 5 à 10 chemins échantillonnés constituent le paramètre recommandé pour la mise en œuvre pratique de l'autocohérence. Cela permet d'obtenir des performances de modèle améliorées tout en maîtrisant les coûts et la latence.
L'autocohérence améliore les performances du modèle au-delà du raisonnement arithmétique
Une question cruciale pour prouver l’adéquation de l’incitation à l’auto-cohérence est de savoir si la méthode réussit dans d’autres tâches et modèles de langage de PNL. En tant qu'extension d'un cas d'utilisation lié à Amazon, nous effectuons une analyse de petite taille sur des exemples de questions du Certification d'associé d'architecte de solutions AWS. Il s'agit d'un examen à choix multiples sur la technologie et les services AWS qui nécessite une connaissance du domaine et la capacité de raisonner et de décider parmi plusieurs options.
Nous préparons un ensemble de données à partir de SAA-CO01 ainsi que SAA-CO03 exemples de questions d'examen. Parmi les 20 questions disponibles, nous utilisons les 4 premières comme exemples ponctuels et incitons le modèle à répondre aux 16 restantes. Cette fois, nous effectuons l'inférence avec le modèle AI21 Labs Jurassic-2 Mid et générons un maximum de 10 chemins de raisonnement à température 0.7. Les résultats montrent que l'auto-cohérence améliore les performances : bien que le CoT gourmand produise 11 réponses correctes, l'auto-cohérence réussit avec 2 autres réponses.
Le tableau suivant montre les résultats de précision pour 5 et 10 trajets échantillonnés, en moyenne sur 100 exécutions.
| . | Décodage gourmand | T = 0.7 |
| # chemins échantillonnés : 5 | 68.6 | 74.1 ± 0.7 |
| # chemins échantillonnés : 10 | 68.6 | 78.9 ± 0.3 |
Dans le tableau suivant, nous présentons deux questions d'examen auxquelles répondent incorrectement les CoT gourmands alors que l'autocohérence réussit, en mettant en évidence dans chaque cas les traces de raisonnement correctes (vertes) ou incorrectes (rouges) qui ont conduit le modèle à produire des réponses correctes ou incorrectes. Bien que tous les chemins échantillonnés générés par l’autocohérence ne soient pas corrects, la majorité converge vers la vraie réponse à mesure que le nombre de chemins échantillonnés augmente. Nous observons que 5 à 10 chemins suffisent généralement pour améliorer les résultats gourmands, avec des rendements décroissants en termes d'efficacité au-delà de ces valeurs.
| Question |
Une application Web permet aux clients de télécharger des commandes dans un compartiment S3. Les événements Amazon S3 résultants déclenchent une fonction Lambda qui insère un message dans une file d'attente SQS. Une seule instance EC2 lit les messages de la file d'attente, les traite et les stocke dans une table DynamoDB partitionnée par ID de commande unique. Le mois prochain, le trafic devrait augmenter d'un facteur 10 et un architecte de solutions examine l'architecture pour détecter d'éventuels problèmes de mise à l'échelle. Quel composant est le plus susceptible de nécessiter une réarchitecture pour pouvoir s'adapter au nouveau trafic ? A. Fonction Lambda |
Une application exécutée sur AWS utilise un déploiement de cluster de base de données Amazon Aurora Multi-AZ pour sa base de données. Lors de l'évaluation des mesures de performances, un architecte de solutions a découvert que les lectures de la base de données entraînaient des E/S élevées et ajoutaient de la latence aux demandes d'écriture sur la base de données. Que doit faire l’architecte de solutions pour séparer les demandes de lecture des demandes d’écriture ? A. Activez la mise en cache en lecture directe sur la base de données Aurora. |
| Bonne réponse | C – Une seule instance EC2 ne pourra pas évoluer et constitue un point de défaillance unique dans l'architecture. Une bien meilleure solution serait que les instances EC2 d'un groupe Auto Scaling sur 2 zones de disponibilité lisent les messages de la file d'attente. Les autres réponses sont tous des services gérés qui peuvent être configurés pour évoluer ou qui évolueront automatiquement. | C – Les réplicas Aurora fournissent un moyen de décharger le trafic de lecture. Les réplicas Aurora partagent le même stockage sous-jacent que la base de données principale, le temps de latence est donc généralement très faible. Les réplicas Aurora ont leurs propres points de terminaison, l'application devra donc être configurée pour diriger le trafic de lecture vers les nouveaux points de terminaison. |
| Décodage gourmand | La mise à l'échelle directe de l'instance EC2 peut ne pas être possible, car il peut ne pas être possible de redimensionner l'instance. La mise à l'échelle de la fonction Lambda peut ne pas être suffisante, car les fonctions Lambda ont une limite d'allocation de mémoire de 6 Go. La mise à l'échelle de la file d'attente SQS peut ne pas être suffisante, car SQS a une limite de 10,000 XNUMX messages. Les tables DynamoDB peuvent être mises à l'échelle en provisionnant davantage d'unités de capacité. La bonne réponse est D. | Modification de l'application à lire à partir de l'instance de secours Multi-AZ (option B) est la meilleure approche. L'instance de secours est répliquée de manière asynchrone à partir de l'instance principale, de sorte que les opérations de lecture n'interfèrent pas avec les opérations d'écriture. Activation de la mise en cache en lecture continue (option A) ou la création d'une réplique Aurora (option C) ne résoudra pas le problème de conflit d'E/S. La création d'une deuxième base de données Aurora et sa liaison en tant que réplica en lecture (option D) ne résoudront pas non plus le problème de conflit d'E/S. La bonne réponse est b. |
| Chemin échantillonné n° 1 | La mise à l'échelle de l'instance EC2 jusqu'à 10 fois sa taille actuelle n'est peut-être pas réalisable, que ce soit du point de vue des coûts ou des performances. Cela nécessiterait une instance plus grande, ce qui peut être coûteux. Une approche plus rentable pourrait consister à utiliser un essaim d'instances plus petites (par exemple, un groupe Auto Scaling) pour partager la charge. Dans ce cas, l'instance EC2 devra probablement être réorganisée. La bonne réponse est C. | Modifier l'application pour utiliser les points de terminaison appropriés n'est pas une solution pratique car cela nécessiterait des modifications du code de l'application. La bonne réponse est C : créez une réplique Aurora et modifiez l'application pour utiliser les points de terminaison appropriés. |
| Chemin échantillonné n° 2 | La mise à l'échelle d'une seule instance EC2 est plus difficile et problématique que la mise à l'échelle des autres composants de service. Amazon SQS, Lambda et DynamoDB peuvent tous évoluer automatiquement pour faire face à la charge accrue. La bonne réponse est C. |
(C) Créez un réplica Aurora et modifiez l'application pour utiliser les points de terminaison appropriés. En configurant un réplica Aurora, vous pouvez séparer le trafic de lecture du trafic d'écriture. Les réplicas Aurora utilisent différentes URL de point de terminaison, vous permettant de diriger le trafic de lecture vers le réplica au lieu de la base de données principale. La réplique peut traiter les demandes de lecture en parallèle avec les demandes d'écriture vers la base de données principale., réduisant les E/S et la latence. |
Nettoyer
L'exécution de l'inférence par lots dans Amazon Bedrock est soumise à des frais selon la tarification Amazon Bedrock. Une fois la procédure pas à pas terminée, supprimez votre instance de bloc-notes SageMaker et supprimez toutes les données de vos compartiments S3 pour éviter d'encourir des frais futurs.
Considérations
Bien que la solution démontrée montre des performances améliorées des modèles de langage lorsqu’elles sont sollicitées avec une auto-cohérence, il est important de noter que la procédure pas à pas n’est pas prête pour la production. Avant de déployer en production, vous devez adapter cette preuve de concept à votre propre implémentation, en gardant à l'esprit les exigences suivantes :
- Restriction d'accès aux API et aux bases de données pour empêcher toute utilisation non autorisée.
- Adhésion aux meilleures pratiques de sécurité AWS concernant l'accès aux rôles IAM et les groupes de sécurité.
- Validation et nettoyage des entrées utilisateur pour empêcher les attaques par injection rapide.
- Surveillance et journalisation des processus déclenchés pour permettre les tests et les audits.
Conclusion
Cet article montre que les invites d'auto-cohérence améliorent les performances des modèles de langage génératifs dans les tâches complexes de PNL qui nécessitent des compétences arithmétiques et logiques à choix multiples. L'autocohérence utilise un décodage stochastique basé sur la température pour générer diverses pistes de raisonnement. Cela augmente la capacité du modèle à susciter des réflexions diverses et utiles pour arriver à des réponses correctes.
Avec l'inférence par lots Amazon Bedrock, le modèle de langage Cohere Command est invité à générer des réponses auto-cohérentes à un ensemble de problèmes arithmétiques. La précision s'améliore de 51.7 % avec un décodage gourmand à 68 % avec un échantillonnage d'auto-cohérence de 30 chemins de raisonnement à T=1.0. L'échantillonnage de cinq chemins améliore déjà la précision de 7.5 points de pourcentage. L'approche est transférable à d'autres modèles de langage et tâches de raisonnement, comme le démontrent les résultats du modèle AI21 Labs Jurassic-2 Mid lors d'un examen de certification AWS. Dans un ensemble de questions de petite taille, l'auto-cohérence avec cinq chemins échantillonnés augmente la précision de 5 points de pourcentage par rapport au CoT gourmand.
Nous vous encourageons à implémenter des invites d’auto-cohérence pour améliorer les performances dans vos propres applications avec des modèles de langage génératifs. En savoir plus sur Commande Cohere ainsi que AI21 Labs Jurassique modèles disponibles sur Amazon Bedrock. Pour plus d'informations sur l'inférence par lots, reportez-vous à Exécuter l'inférence par lots.
Remerciements
L'auteur remercie les réviseurs techniques Amin Tajgardoon et Patrick McSweeney pour leurs commentaires utiles.
À propos de l’auteur

Lucia Santamaria est scientifique appliquée principale à l'université ML d'Amazon, où elle se concentre sur l'augmentation du niveau de compétence en ML dans l'ensemble de l'entreprise grâce à une formation pratique. Lucía est titulaire d'un doctorat en astrophysique et est passionnée par la démocratisation de l'accès aux connaissances et aux outils technologiques.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/enhance-performance-of-generative-language-models-with-self-consistency-prompting-on-amazon-bedrock/

