Aujourd'hui, nous sommes ravis d'annoncer la possibilité d'affiner les modèles Code Llama par Meta en utilisant Amazon SageMaker JumpStart. La famille Code Llama de grands modèles de langage (LLM) est un ensemble de modèles de génération de code pré-entraînés et affinés allant de 7 à 70 milliards de paramètres. Les modèles Code Llama affinés offrent une meilleure précision et une meilleure explicabilité par rapport aux modèles Code Llama de base, comme le montrent ses tests par rapport aux modèles Code Llama de base. HumanEval et les ensembles de données MBPP. Vous pouvez affiner et déployer des modèles Code Llama avec SageMaker JumpStart à l'aide de l'outil Amazon SageMakerStudio UI en quelques clics ou en utilisant le SDK SageMaker Python. Le réglage fin des modèles de Lama est basé sur les scripts fournis dans le dépôt GitHub de recettes de lama à partir de Meta en utilisant les techniques de quantification PyTorch FSDP, PEFT/LoRA et Int8.
Dans cet article, nous expliquons comment affiner les modèles pré-entraînés Code Llama via SageMaker JumpStart via une interface utilisateur et un SDK en un clic disponibles dans les versions suivantes. GitHub référentiel.
Qu'est-ce que SageMaker JumpStart
Avec SageMaker JumpStart, les praticiens du machine learning (ML) peuvent choisir parmi une large sélection de modèles de base accessibles au public. Les praticiens du ML peuvent déployer des modèles de base sur des sites dédiés. Amazon Sage Maker instances à partir d'un environnement isolé du réseau et personnalisez les modèles à l'aide de SageMaker pour la formation et le déploiement des modèles.
Qu'est-ce que Code Lama
Code Llama est une version spécialisée en code de Llama 2 qui a été créé en formant davantage Llama 2 sur ses ensembles de données spécifiques au code et en échantillonnant plus de données de ce même ensemble de données pendant plus longtemps. Code Llama offre des capacités de codage améliorées. Il peut générer du code et du langage naturel sur le code, à partir d'invites de code et de langage naturel (par exemple, « Écrivez-moi une fonction qui génère la séquence de Fibonacci »). Vous pouvez également l'utiliser pour la complétion du code et le débogage. Il prend en charge la plupart des langages de programmation les plus populaires utilisés aujourd'hui, notamment Python, C++, Java, PHP, Typescript (JavaScript), C#, Bash, etc.
Pourquoi affiner les modèles Code Llama
Meta a publié des tests de performance de Code Llama sur HumanEval et MBPP pour les langages de codage courants tels que Python, Java et JavaScript. Les performances des modèles Code Llama Python sur HumanEval ont démontré des performances variables selon les différents langages de codage et tâches allant de 38 % sur le modèle Python 7B à 57 % sur les modèles Python 70B. De plus, les modèles Code Llama affinés sur le langage de programmation SQL ont montré de meilleurs résultats, comme en témoignent les tests d'évaluation SQL. Ces références publiées mettent en évidence les avantages potentiels d’un réglage fin des modèles Code Llama, permettant de meilleures performances, personnalisation et adaptation à des domaines et tâches de codage spécifiques.
Ajustement sans code via l'interface utilisateur de SageMaker Studio
Pour commencer à affiner vos modèles Llama à l'aide de SageMaker Studio, procédez comme suit :
- Sur la console SageMaker Studio, choisissez Début de saut dans le volet de navigation.
Vous trouverez des listes de plus de 350 modèles allant des modèles open source aux modèles propriétaires.
- Recherchez des modèles Code Llama.

Si vous ne voyez pas les modèles Code Llama, vous pouvez mettre à jour votre version de SageMaker Studio en arrêtant et en redémarrant. Pour plus d'informations sur les mises à jour de version, reportez-vous à Arrêter et mettre à jour les applications Studio. Vous pouvez également trouver d'autres variantes de modèles en choisissant Explorez tous les modèles de génération de code ou recherchez Code Llama dans la zone de recherche.
SageMaker JumpStart prend actuellement en charge le réglage fin des instructions pour les modèles Code Llama. La capture d'écran suivante montre la page de réglage fin du modèle Code Llama 2 70B.
- Pour Emplacement du jeu de données d'entraînement, vous pouvez pointer vers le Service de stockage simple Amazon (Amazon S3) contenant les ensembles de données de formation et de validation pour un réglage précis.
- Définissez votre configuration de déploiement, vos hyperparamètres et vos paramètres de sécurité pour un réglage précis.
- Selectionnez Train pour démarrer le travail de réglage fin sur une instance SageMaker ML.
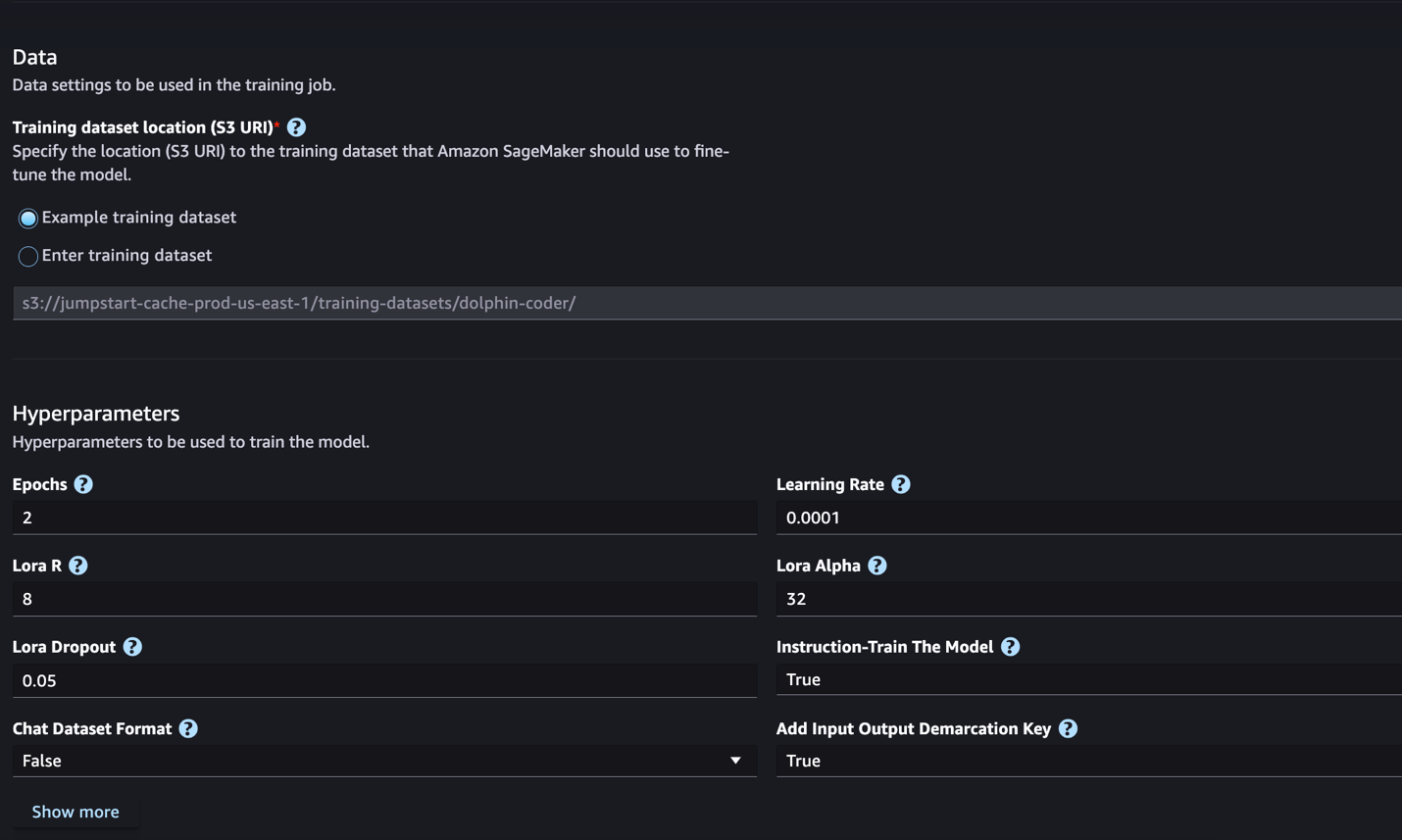
Nous discutons du format d'ensemble de données dont vous avez besoin pour préparer le réglage précis des instructions dans la section suivante.
- Une fois le modèle affiné, vous pouvez le déployer à l'aide de la page de modèle sur SageMaker JumpStart.
L'option permettant de déployer le modèle affiné apparaîtra une fois le réglage fin terminé, comme le montre la capture d'écran suivante.

Affiner via le SDK SageMaker Python
Dans cette section, nous montrons comment affiner les modèles Code LIama à l'aide du SDK SageMaker Python sur un ensemble de données au format instruction. Plus précisément, le modèle est affiné pour un ensemble de tâches de traitement du langage naturel (NLP) décrites à l'aide d'instructions. Cela permet d'améliorer les performances du modèle pour les tâches invisibles avec des invites zéro tir.
Effectuez les étapes suivantes pour terminer votre travail de réglage fin. Vous pouvez obtenir l'intégralité du code de réglage fin à partir du GitHub référentiel.
Tout d’abord, examinons le format de l’ensemble de données requis pour le réglage fin des instructions. Les données d'entraînement doivent être formatées au format de lignes JSON (.jsonl), où chaque ligne est un dictionnaire représentant un échantillon de données. Toutes les données d'entraînement doivent être dans un seul dossier. Cependant, il peut être enregistré dans plusieurs fichiers .jsonl. Voici un exemple au format de lignes JSON :
Le dossier de formation peut contenir un template.json fichier décrivant les formats d’entrée et de sortie. Voici un exemple de modèle :
Pour correspondre au modèle, chaque échantillon dans les fichiers de lignes JSON doit inclure system_prompt, questionet response des champs. Dans cette démonstration, nous utilisons le Ensemble de données Dolphin Coder de Hugging Face.
Après avoir préparé l'ensemble de données et l'avoir téléchargé dans le compartiment S3, vous pouvez commencer le réglage à l'aide du code suivant :
Vous pouvez déployer le modèle affiné directement à partir de l'estimateur, comme indiqué dans le code suivant. Pour plus de détails, consultez le cahier dans le GitHub référentiel.
Techniques de mise au point
Les modèles linguistiques tels que Llama ont une taille supérieure à 10 Go, voire 100 Go. Le réglage fin de modèles aussi volumineux nécessite des instances dotées d'une mémoire CUDA considérablement élevée. De plus, la formation de ces modèles peut être très lente en raison de la taille du modèle. Par conséquent, pour un réglage fin efficace, nous utilisons les optimisations suivantes :
- Adaptation de bas rang (LoRA) – Il s’agit d’un type de réglage fin efficace des paramètres (PEFT) pour un réglage fin efficace des grands modèles. Avec cette méthode, vous figez l’ensemble du modèle et n’ajoutez qu’un petit ensemble de paramètres ou de calques réglables dans le modèle. Par exemple, au lieu d'entraîner les 7 milliards de paramètres pour Llama 2 7B, vous pouvez affiner moins de 1 % des paramètres. Cela contribue à une réduction significative des besoins en mémoire, car vous n'avez besoin de stocker que les gradients, les états de l'optimiseur et d'autres informations liées à l'entraînement pour seulement 1 % des paramètres. De plus, cela contribue à réduire le temps de formation ainsi que le coût. Pour plus de détails sur cette méthode, reportez-vous à LoRA : Adaptation de bas niveau de grands modèles de langage.
- Quantification Int8 – Même avec des optimisations telles que LoRA, des modèles tels que Llama 70B sont encore trop gros pour être entraînés. Pour réduire l'empreinte mémoire pendant l'entraînement, vous pouvez utiliser la quantification Int8 pendant l'entraînement. La quantification réduit généralement la précision des types de données à virgule flottante. Bien que cela diminue la mémoire requise pour stocker les poids du modèle, cela dégrade les performances en raison de la perte d'informations. La quantification Int8 n'utilise qu'un quart de précision mais n'entraîne pas de dégradation des performances car elle ne supprime pas simplement les bits. Il arrondit les données d'un type à l'autre. Pour en savoir plus sur la quantification Int8, reportez-vous à LLM.int8() : multiplication matricielle 8 bits pour les transformateurs à grande échelle.
- Parallèle de données entièrement partagées (FSDP) – Il s'agit d'un type d'algorithme de formation parallèle aux données qui répartit les paramètres du modèle entre les travailleurs parallèles aux données et peut éventuellement décharger une partie du calcul de formation vers les processeurs. Bien que les paramètres soient répartis sur différents GPU, le calcul de chaque microbatch est local pour le processeur GPU. Il partage les paramètres de manière plus uniforme et obtient des performances optimisées grâce au chevauchement des communications et des calculs pendant l'entraînement.
Le tableau suivant résume les détails de chaque modèle avec différents paramètres.
| Modèle | Paramètres par défaut | LORA + FSDP | LORA + Pas de FSDP | Quantification Int8 + LORA + Pas de FSDP |
| Code Lama 2 7B | LORA + FSDP | Oui | Oui | Oui |
| Code Lama 2 13B | LORA + FSDP | Oui | Oui | Oui |
| Code Lama 2 34B | INT8 + LORA + PAS DE FSDP | Non | Non | Oui |
| Code Lama 2 70B | INT8 + LORA + PAS DE FSDP | Non | Non | Oui |
Le réglage fin des modèles de lama est basé sur les scripts fournis par les éléments suivants GitHub repo.
Hyperparamètres pris en charge pour la formation
Le réglage fin de Code Llama 2 prend en charge un certain nombre d'hyperparamètres, dont chacun peut avoir un impact sur les besoins en mémoire, la vitesse d'entraînement et les performances du modèle affiné :
- époque – Le nombre de passages effectués par l'algorithme de réglage fin dans l'ensemble de données d'entraînement. Doit être un entier supérieur à 1. La valeur par défaut est 5.
- taux d'apprentissage – La fréquence à laquelle les pondérations du modèle sont mises à jour après avoir parcouru chaque lot d'exemples de formation. Doit être un flottant positif supérieur à 0. La valeur par défaut est 1e-4.
- instruction_tuned – S’il faut ou non former le modèle à l’instruction. Doit être
TrueorFalse. La valeur par défaut estFalse. - par_device_train_batch_size – La taille du lot par cœur GPU/CPU pour la formation. Doit être un entier positif. La valeur par défaut est 4.
- per_device_eval_batch_size – La taille du lot par cœur GPU/CPU pour évaluation. Doit être un entier positif. La valeur par défaut est 1.
- max_train_samples – À des fins de débogage ou de formation plus rapide, tronquez le nombre d'exemples de formation à cette valeur. La valeur -1 signifie utiliser tous les échantillons d’apprentissage. Doit être un entier positif ou -1. La valeur par défaut est -1.
- max_val_samples – À des fins de débogage ou de formation plus rapide, tronquez le nombre d'exemples de validation à cette valeur. La valeur -1 signifie utiliser tous les échantillons de validation. Doit être un entier positif ou -1. La valeur par défaut est -1.
- max_input_length – Longueur totale maximale de la séquence d’entrée après la tokenisation. Les séquences plus longues seront tronquées. Si -1,
max_input_lengthest défini sur le minimum de 1024 et la longueur maximale du modèle définie par le tokenizer. S'il est défini sur une valeur positive,max_input_lengthest réglé au minimum de la valeur fournie et lemodel_max_lengthdéfini par le tokenizer. Doit être un entier positif ou -1. La valeur par défaut est -1. - validation_split_ratio – Si le canal de validation est
none, le rapport entre la répartition de la validation du train et les données du train doit être compris entre 0 et 1. La valeur par défaut est 0.2. - train_data_split_seed – Si les données de validation ne sont pas présentes, cela corrige la répartition aléatoire des données de formation d'entrée en données de formation et de validation utilisées par l'algorithme. Doit être un entier. La valeur par défaut est 0.
- prétraitement_num_workers – Le nombre de processus à utiliser pour le prétraitement. Si
None, le processus principal est utilisé pour le prétraitement. La valeur par défaut estNone. - lora_r – Lora R. Doit être un entier positif. La valeur par défaut est 8.
- lora_alpha -Lora Alpha. Doit être un entier positif. La valeur par défaut est 32
- lora_dropout – Lora Abandon. doit être un flottant positif compris entre 0 et 1. La valeur par défaut est 0.05.
- int8_quantisation - Si
True, le modèle est chargé avec une précision de 8 bits pour l'entraînement. La valeur par défaut pour 7B et 13B estFalse. La valeur par défaut pour 70B estTrue. - activer_fsdp – Si True, la formation utilise FSDP. La valeur par défaut pour 7B et 13B est True. La valeur par défaut pour 70B est False. Noter que
int8_quantizationn’est pas pris en charge avec FSDP.
Lors du choix des hyperparamètres, tenez compte des éléments suivants :
- Paramètres
int8_quantization=Truediminue les besoins en mémoire et conduit à un entraînement plus rapide. - Réduction
per_device_train_batch_sizeainsi quemax_input_lengthréduit les besoins en mémoire et peut donc être exécuté sur des instances plus petites. Cependant, définir des valeurs très basses peut augmenter le temps d'entraînement. - Si vous n'utilisez pas la quantification Int8 (
int8_quantization=False), utilisez FSDP (enable_fsdp=True) pour une formation plus rapide et efficace.
Types d'instances pris en charge pour la formation
Le tableau suivant résume les types d'instances pris en charge pour la formation de différents modèles.
| Modèle | Type d'instance par défaut | Types d'instances pris en charge |
| Code Lama 2 7B | ml.g5.12xlarge |
ml.g5.12xlarge, ml.g5.24xlarge, ml.g5.48xlarge, ml.p3dn.24xlarge, ml.g4dn.12xlarge |
| Code Lama 2 13B | ml.g5.12xlarge |
ml.g5.24xlarge, ml.g5.48xlarge, ml.p3dn.24xlarge, ml.g4dn.12xlarge |
| Code Lama 2 70B | ml.g5.48xlarge |
ml.g5.48xlarge ml.p4d.24xlarge |
Lorsque vous choisissez le type d'instance, tenez compte des éléments suivants :
- Les instances G5 offrent la formation la plus efficace parmi les types d'instances pris en charge. Par conséquent, si vous disposez d’instances G5, vous devez les utiliser.
- Le temps de formation dépend en grande partie du nombre de GPU et de la mémoire CUDA disponible. Par conséquent, la formation sur des instances avec le même nombre de GPU (par exemple, ml.g5.2xlarge et ml.g5.4xlarge) est à peu près la même. Par conséquent, vous pouvez utiliser l'instance la moins chère pour la formation (ml.g5.2xlarge).
- Lors de l'utilisation d'instances p3, la formation sera effectuée avec une précision de 32 bits car bfloat16 n'est pas pris en charge sur ces instances. Par conséquent, la tâche de formation consommera le double de la quantité de mémoire CUDA lors de la formation sur des instances p3 par rapport aux instances g5.
Pour en savoir plus sur le coût de la formation par instance, reportez-vous à Instances Amazon EC2 G5.
Evaluation
L'évaluation est une étape importante pour évaluer les performances de modèles affinés. Nous présentons des évaluations qualitatives et quantitatives pour montrer l'amélioration des modèles affinés par rapport aux modèles non affinés. Dans l'évaluation qualitative, nous montrons un exemple de réponse de modèles à la fois affinés et non affinés. En évaluation quantitative, nous utilisons HumanEval, une suite de tests développée par OpenAI pour générer du code Python afin de tester la capacité à produire des résultats corrects et précis. Le référentiel HumanEval est sous licence MIT. Nous avons affiné les variantes Python de tous les modèles Code LIama sur différentes tailles (Code LIama Python 7B, 13B, 34B et 70B sur le Ensemble de données Dolphin Coder), et présente les résultats de l’évaluation dans les sections suivantes.
Évaluation qualitative
Une fois votre modèle affiné déployé, vous pouvez commencer à utiliser le point de terminaison pour générer du code. Dans l'exemple suivant, nous présentons les réponses des variantes Python de base et affinées du Code LIama 34B sur un échantillon de test dans le Ensemble de données Dolphin Coder:
Le modèle Code Llama affiné, en plus de fournir le code de la requête précédente, génère une explication détaillée de l'approche et un pseudo-code.
Code Llama 34b Python Réponse non affinée :
Réponse affinée Python Code Llama 34B
Vérité fondamentale
Fait intéressant, notre version affinée de Code Llama 34B Python fournit une solution basée sur la programmation dynamique pour la sous-chaîne palindromique la plus longue, qui est différente de la solution fournie dans la vérité terrain de l'exemple de test sélectionné. Notre modèle affiné raisonne et explique en détail la solution basée sur la programmation dynamique. D’un autre côté, le modèle non affiné hallucine les résultats potentiels juste après le print instruction (affichée dans la cellule de gauche) car la sortie axyzzyx n'est pas le palindrome le plus long de la chaîne donnée. En termes de complexité temporelle, la solution de programmation dynamique est généralement meilleure que l'approche initiale. La solution de programmation dynamique a une complexité temporelle de O(n^2), où n est la longueur de la chaîne d'entrée. Ceci est plus efficace que la solution initiale du modèle non affiné, qui avait également une complexité temporelle quadratique de O(n^2) mais avec une approche moins optimisée.
Cela semble prometteur ! N'oubliez pas que nous avons uniquement affiné la variante Code LIama Python avec 10 % de la Ensemble de données Dolphin Coder. Il y a beaucoup plus à explorer !
Malgré les instructions détaillées contenues dans la réponse, nous devons encore examiner l'exactitude du code Python fourni dans la solution. Ensuite, nous utilisons un cadre d'évaluation appelé Évaluation humaine exécuter des tests d'intégration sur la réponse générée par Code LIama pour examiner systématiquement sa qualité.
Évaluation quantitative avec HumanEval
HumanEval est un outil d'évaluation permettant d'évaluer les capacités de résolution de problèmes d'un LLM sur des problèmes de codage basés sur Python, comme décrit dans l'article. Évaluation de grands modèles de langage formés au code. Plus précisément, il se compose de 164 problèmes de programmation originaux basés sur Python qui évaluent la capacité d'un modèle de langage à générer du code en fonction des informations fournies telles que la signature de fonction, la docstring, le corps et les tests unitaires.
Pour chaque question de programmation basée sur Python, nous l'envoyons à un modèle Code LIama déployé sur un point de terminaison SageMaker pour obtenir k réponses. Ensuite, nous exécutons chacune des k réponses sur les tests d'intégration dans le référentiel HumanEval. Si une réponse parmi les k réponses réussit les tests d'intégration, nous considérons que ce scénario de test a réussi ; sinon, échec. Ensuite, nous répétons le processus pour calculer le ratio de cas réussis comme score d'évaluation final nommé pass@k. Conformément à la pratique standard, nous définissons k sur 1 dans notre évaluation, pour générer une seule réponse par question et tester si elle réussit le test d'intégration.
Ce qui suit est un exemple de code pour utiliser le référentiel HumanEval. Vous pouvez accéder à l'ensemble de données et générer une réponse unique à l'aide d'un point de terminaison SageMaker. Pour plus de détails, consultez le cahier dans le GitHub référentiel.
Le tableau suivant montre les améliorations des modèles Code LIama Python affinés par rapport aux modèles non affinés dans différentes tailles de modèle. Pour garantir l'exactitude, nous déployons également les modèles Code LIama non affinés dans les points de terminaison SageMaker et exécutons des évaluations Human Eval. Le passer@1 les nombres (la première ligne du tableau suivant) correspondent aux nombres déclarés dans le Document de recherche Code Llama. Les paramètres d'inférence sont systématiquement définis comme "parameters": {"max_new_tokens": 384, "temperature": 0.2}.
Comme nous pouvons le voir d'après les résultats, toutes les variantes affinées de Code LIama Python montrent une amélioration significative par rapport aux modèles non affinés. En particulier, Code LIama Python 70B surpasse le modèle non optimisé d'environ 12 %.
| . | 7BPython | 13BPython | 34M | 34BPython | 70BPython |
| Performances du modèle pré-entraîné (pass@1) | 38.4 | 43.3 | 48.8 | 53.7 | 57.3 |
| Performances du modèle affinées (pass@1) | 45.12 | 45.12 | 59.1 | 61.5 | 69.5 |
Vous pouvez désormais essayer d'affiner les modèles Code LIama sur votre propre ensemble de données.
Nettoyer
Si vous décidez que vous ne souhaitez plus faire fonctionner le point de terminaison SageMaker, vous pouvez le supprimer en utilisant AWS SDK pour Python (Boto3), Interface de ligne de commande AWS (AWS CLI) ou la console SageMaker. Pour plus d'informations, voir Supprimer des terminaux et des ressources. De plus, vous pouvez arrêter les ressources de SageMaker Studio qui ne sont plus nécessaires.
Conclusion
Dans cet article, nous avons discuté du réglage fin des modèles Code Llama 2 de Meta à l'aide de SageMaker JumpStart. Nous avons montré que vous pouvez utiliser la console SageMaker JumpStart dans SageMaker Studio ou le SDK SageMaker Python pour affiner et déployer ces modèles. Nous avons également discuté de la technique de réglage fin, des types d'instances et des hyperparamètres pris en charge. De plus, nous avons formulé des recommandations pour une formation optimisée sur la base de différents tests que nous avons effectués. Comme nous pouvons le voir à partir de ces résultats de réglage fin de trois modèles sur deux ensembles de données, le réglage fin améliore la synthèse par rapport aux modèles non affinés. Dans une prochaine étape, vous pouvez essayer d'affiner ces modèles sur votre propre ensemble de données à l'aide du code fourni dans le référentiel GitHub pour tester et comparer les résultats pour vos cas d'utilisation.
À propos des auteurs
 Dr Xin Huang est un scientifique appliqué senior pour Amazon SageMaker JumpStart et les algorithmes intégrés d'Amazon SageMaker. Il se concentre sur le développement d'algorithmes d'apprentissage automatique évolutifs. Ses intérêts de recherche portent sur le traitement du langage naturel, l'apprentissage en profondeur explicable sur des données tabulaires et l'analyse robuste du clustering spatio-temporel non paramétrique. Il a publié de nombreux articles dans les conférences ACL, ICDM, KDD et Royal Statistical Society: Series A.
Dr Xin Huang est un scientifique appliqué senior pour Amazon SageMaker JumpStart et les algorithmes intégrés d'Amazon SageMaker. Il se concentre sur le développement d'algorithmes d'apprentissage automatique évolutifs. Ses intérêts de recherche portent sur le traitement du langage naturel, l'apprentissage en profondeur explicable sur des données tabulaires et l'analyse robuste du clustering spatio-temporel non paramétrique. Il a publié de nombreux articles dans les conférences ACL, ICDM, KDD et Royal Statistical Society: Series A.
 Vishaal Yalamanchali est un architecte de solutions de démarrage travaillant avec des entreprises en démarrage d'IA générative, de robotique et de véhicules autonomes. Vishaal travaille avec ses clients pour fournir des solutions ML de pointe et s'intéresse personnellement à l'apprentissage par renforcement, à l'évaluation LLM et à la génération de code. Avant AWS, Vishaal était étudiant de premier cycle à l'UCI, spécialisé dans la bioinformatique et les systèmes intelligents.
Vishaal Yalamanchali est un architecte de solutions de démarrage travaillant avec des entreprises en démarrage d'IA générative, de robotique et de véhicules autonomes. Vishaal travaille avec ses clients pour fournir des solutions ML de pointe et s'intéresse personnellement à l'apprentissage par renforcement, à l'évaluation LLM et à la génération de code. Avant AWS, Vishaal était étudiant de premier cycle à l'UCI, spécialisé dans la bioinformatique et les systèmes intelligents.
 Meenakshisundaram Thandavarayan travaille pour AWS en tant que spécialiste IA/ML. Il a une passion pour la conception, la création et la promotion d'expériences de données et d'analyse centrées sur l'humain. Meena se concentre sur le développement de systèmes durables qui offrent des avantages compétitifs mesurables aux clients stratégiques d'AWS. Meena est une penseuse du design et des connecteurs, et s'efforce d'amener les entreprises à adopter de nouvelles façons de travailler grâce à l'innovation, à l'incubation et à la démocratisation.
Meenakshisundaram Thandavarayan travaille pour AWS en tant que spécialiste IA/ML. Il a une passion pour la conception, la création et la promotion d'expériences de données et d'analyse centrées sur l'humain. Meena se concentre sur le développement de systèmes durables qui offrent des avantages compétitifs mesurables aux clients stratégiques d'AWS. Meena est une penseuse du design et des connecteurs, et s'efforce d'amener les entreprises à adopter de nouvelles façons de travailler grâce à l'innovation, à l'incubation et à la démocratisation.
 Dr Ashish Khetan est un scientifique appliqué senior avec les algorithmes intégrés d'Amazon SageMaker et aide à développer des algorithmes d'apprentissage automatique. Il a obtenu son doctorat à l'Université de l'Illinois à Urbana-Champaign. Il est un chercheur actif en apprentissage automatique et en inférence statistique, et a publié de nombreux articles dans les conférences NeurIPS, ICML, ICLR, JMLR, ACL et EMNLP.
Dr Ashish Khetan est un scientifique appliqué senior avec les algorithmes intégrés d'Amazon SageMaker et aide à développer des algorithmes d'apprentissage automatique. Il a obtenu son doctorat à l'Université de l'Illinois à Urbana-Champaign. Il est un chercheur actif en apprentissage automatique et en inférence statistique, et a publié de nombreux articles dans les conférences NeurIPS, ICML, ICLR, JMLR, ACL et EMNLP.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/fine-tune-code-llama-on-amazon-sagemaker-jumpstart/

