Gestionnaire de données Amazon SageMaker réduit le temps nécessaire pour agréger et préparer les données pour l'apprentissage automatique (ML) de quelques semaines à quelques minutes dans Amazon SageMaker Studio. Data Wrangler vous permet d'accéder aux données d'une grande variété de sources populaires (Amazon S3, Amazone Athéna, Redshift d'Amazon, Amazon DME et Snowflake) et plus de 40 autres sources tierces. Dès aujourd'hui, vous pouvez vous connecter à Amazon DME Hive en tant que moteur de requête Big Data pour importer de grands ensembles de données pour le ML.
L'agrégation et la préparation de grandes quantités de données constituent une partie essentielle du flux de travail ML. Les data scientists et les ingénieurs de données utilisent Apache Spark, Apache Hive et Presto exécutés sur Amazon EMR pour le traitement de données à grande échelle. Ce billet de blog expliquera comment les professionnels des données peuvent utiliser l'interface visuelle de SageMaker Data Wrangler pour localiser et se connecter aux clusters Amazon EMR existants avec des points de terminaison Hive. Pour se préparer à la modélisation ou à la création de rapports, ils peuvent analyser visuellement la base de données, les tables, le schéma et créer des requêtes Hive pour créer l'ensemble de données ML. Ensuite, ils peuvent rapidement profiler les données à l'aide de l'interface visuelle de Data Wrangler pour évaluer la qualité des données, repérer les anomalies et les données manquantes ou incorrectes, et obtenir des conseils sur la façon de traiter ces problèmes. Ils peuvent tirer parti d'analyses intégrées plus populaires et alimentées par ML et de plus de 300 transformations intégrées prises en charge par Spark pour analyser, nettoyer et concevoir des fonctionnalités sans écrire une seule ligne de code. Enfin, ils peuvent également former et déployer des modèles avec Pilote automatique SageMaker, planifier des tâches ou opérationnaliser la préparation des données dans un pipeline SageMaker à partir de l'interface visuelle de Data Wrangler.
Vue d'ensemble de la solution
Avec les configurations SageMaker Studio, les professionnels des données peuvent rapidement identifier et se connecter aux clusters EMR existants. De plus, les professionnels des données peuvent découvrir les clusters EMR à partir de SageMaker Studio utilisant des modèles prédéfinis à la demande en quelques clics. Les clients peuvent utiliser le bloc-notes universel SageMaker Studio et écrire du code dans Apache Spark, Ruche, Presto or PySparkName pour effectuer la préparation des données à grande échelle. Cependant, tous les professionnels des données ne sont pas familiarisés avec l'écriture de code Spark pour préparer les données, car la courbe d'apprentissage est abrupte. Ils peuvent désormais se connecter rapidement et simplement à Amazon EMR sans écrire une seule ligne de code, grâce à Amazon EMR en tant que source de données pour Amazon SageMaker Data Wrangler.
Le diagramme suivant représente les différents composants utilisés dans cette solution.

Nous démontrons deux options d'authentification qui peuvent être utilisées pour établir une connexion au cluster EMR. Pour chaque option, nous déployons une pile unique de AWS CloudFormation modèles.
Le modèle CloudFormation effectue les actions suivantes lorsque chaque option est sélectionnée :
- Crée un domaine Studio en mode VPC uniquement, ainsi qu'un profil utilisateur nommé
studio-user. - Crée des blocs de construction, y compris le VPC, les points de terminaison, les sous-réseaux, les groupes de sécurité, le cluster EMR et d'autres ressources requises pour exécuter les exemples avec succès.
- Pour le cluster EMR, connecte le catalogue de données AWS Glue en tant que metastore pour EMR Hive et Presto, crée une table Hive dans EMR et la remplit avec les données d'un Ensemble de données sur les aéroports américains.
- Pour le modèle LDAP CloudFormation, crée un Cloud de calcul élastique Amazon (Amazon EC2) pour héberger le serveur LDAP afin d'authentifier l'utilisateur Hive et Presto LDAP.
Option 1 : protocole d'annuaire d'accès léger
Pour le modèle d'authentification LDAP CloudFormation, nous provisionnons une instance Amazon EC2 avec un serveur LDAP et configurons le cluster EMR pour utiliser ce serveur pour l'authentification. C'est TLS activé.
Option 2 : Aucune autorisation
Dans le modèle CloudFormation d'authentification sans authentification, nous utilisons un cluster EMR standard sans authentification activée.
Déployer les ressources avec AWS CloudFormation
Effectuez les étapes suivantes pour déployer l'environnement:
- Connectez-vous à la Console de gestion AWS en tant que Gestion des identités et des accès AWS (IAM), de préférence un utilisateur administrateur.
- Selectionnez Lancer la pile pour lancer le modèle CloudFormation pour le scénario d'authentification approprié. Assurez-vous que la région utilisée pour déployer la pile CloudFormation n'a pas de domaine Studio existant. Si vous avez déjà un domaine Studio dans une région, vous pouvez choisir une autre région.
LDAP 
Pas d'authentification - Selectionnez Suivant.
- Pour Nom de la pile, entrez un nom pour la pile (par exemple,
dw-emr-hive-blog). - Laissez les autres valeurs par défaut.
- Pour continuer, choisissez Suivant à partir de la page des détails de la pile et des options de la pile.
La pile LDAP utilise les informations d'identification suivantes.- nom d'utilisateur:
david - mot de passe:
welcome123
- nom d'utilisateur:
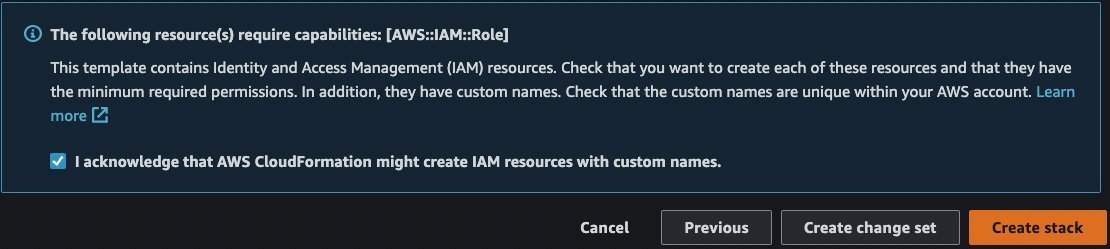
- Sur la page de révision, cochez la case pour confirmer qu'AWS CloudFormation peut créer des ressources.
- Selectionnez Créer une pile. Attendez que l'état de la pile passe de
CREATE_IN_PROGRESSàCREATE_COMPLETE. Le processus prend généralement 10 à 15 minutes.
Configurer Amazon EMR en tant que source de données dans Data Wrangler
Dans cette section, nous abordons la connexion au cluster Amazon EMR existant créé via le modèle CloudFormation en tant que source de données dans Data Wrangler.
Créer un nouveau flux de données
Pour créer votre flux de données, procédez comme suit :
- Sur la console SageMaker, cliquez sur Domaines, puis cliquez sur StudioDomaine créé en exécutant au-dessus du modèle CloudFormation.
- Sélectionnez utilisateur de studio profil utilisateur et lancez Studio.
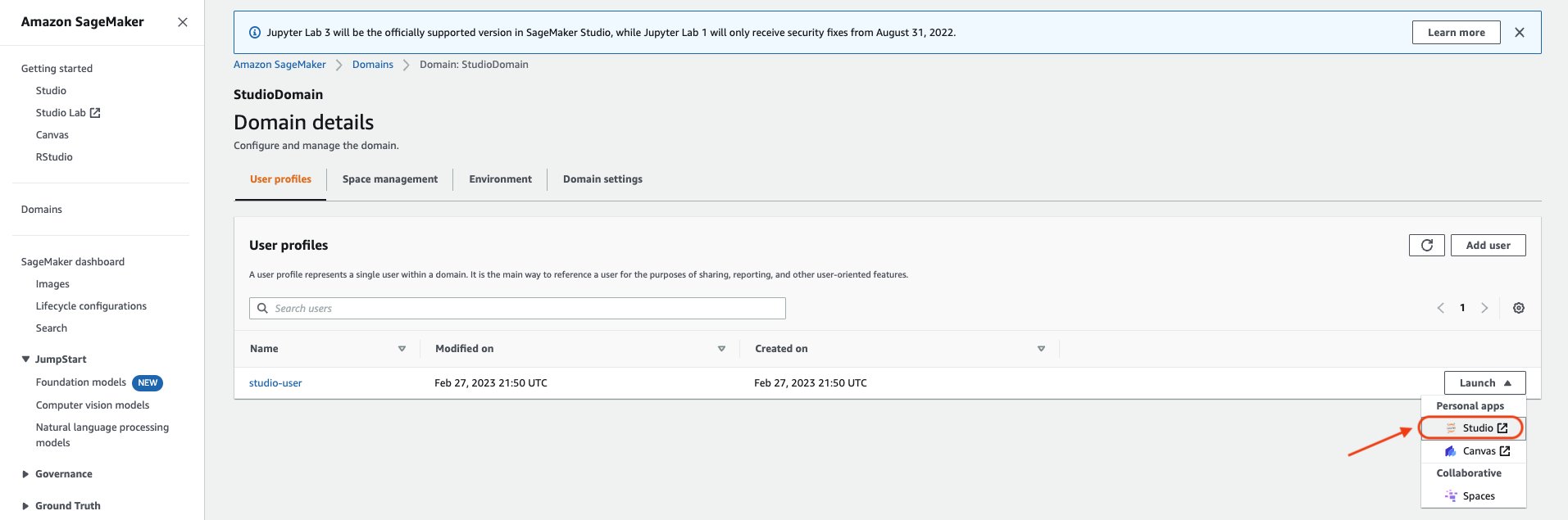
- Selectionnez Atelier ouvert.
- Dans la console Studio Home, choisissez Importer et préparer visuellement les données. Alternativement, sur le Déposez votre dernière attestation menu déroulant, choisissez Nouveauté, Puis choisissez Flux de Wrangler de données.
- La création d'un nouveau flux peut prendre quelques minutes. Une fois le flux créé, vous voyez le Importer des dates .

- Ajoutez Amazon EMR en tant que source de données dans Data Wrangler. Sur le Ajouter une source de données menu, choisissez Amazon EMR.
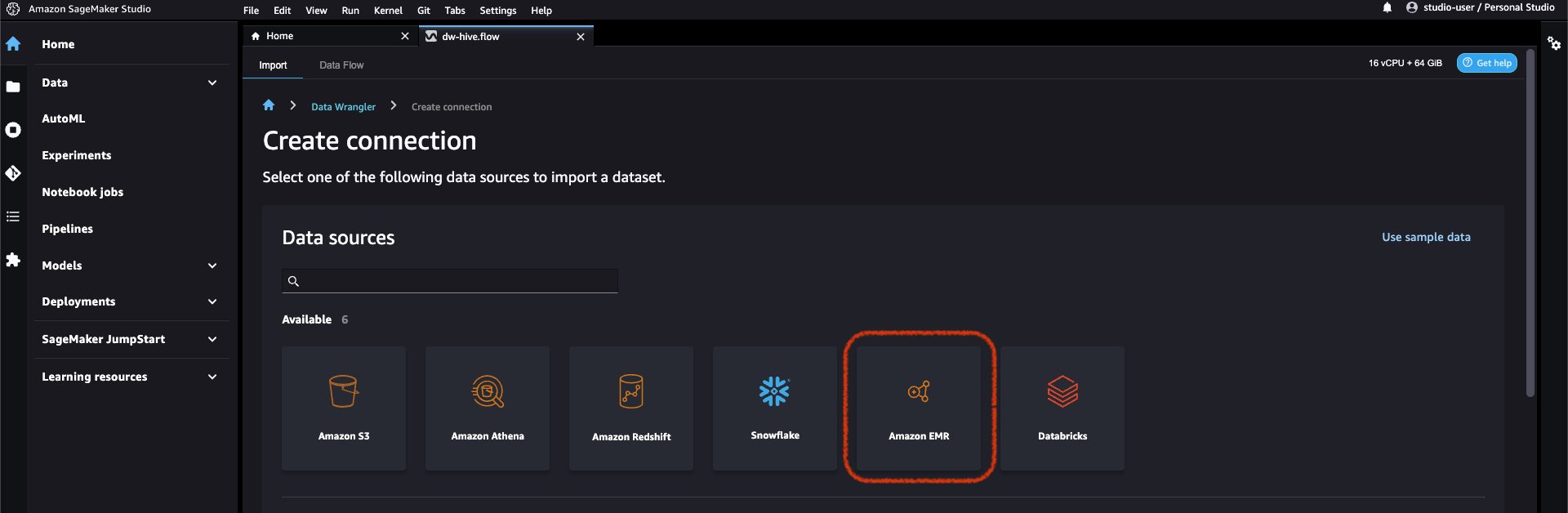
Vous pouvez parcourir tous les clusters EMR que votre rôle d'exécution Studio est autorisé à voir. Vous avez deux options pour vous connecter à un cluster ; l'une est via l'interface utilisateur interactive, et l'autre consiste à d'abord créer un secret à l'aide d'AWS Secrets Manager avec l'URL JDBC, y compris les informations de cluster EMR, puis fournissez l'ARN secret AWS stocké dans l'interface utilisateur pour vous connecter à Hive. Dans ce blog, nous suivons la première option.
- Sélectionnez l'un des clusters suivants que vous souhaitez utiliser. Cliquez sur Suivant, et sélectionnez les points de terminaison.

- Sélectionnez Ruche, connectez-vous à Amazon EMR, créez un nom pour identifier votre connexion, puis cliquez sur Suivant.
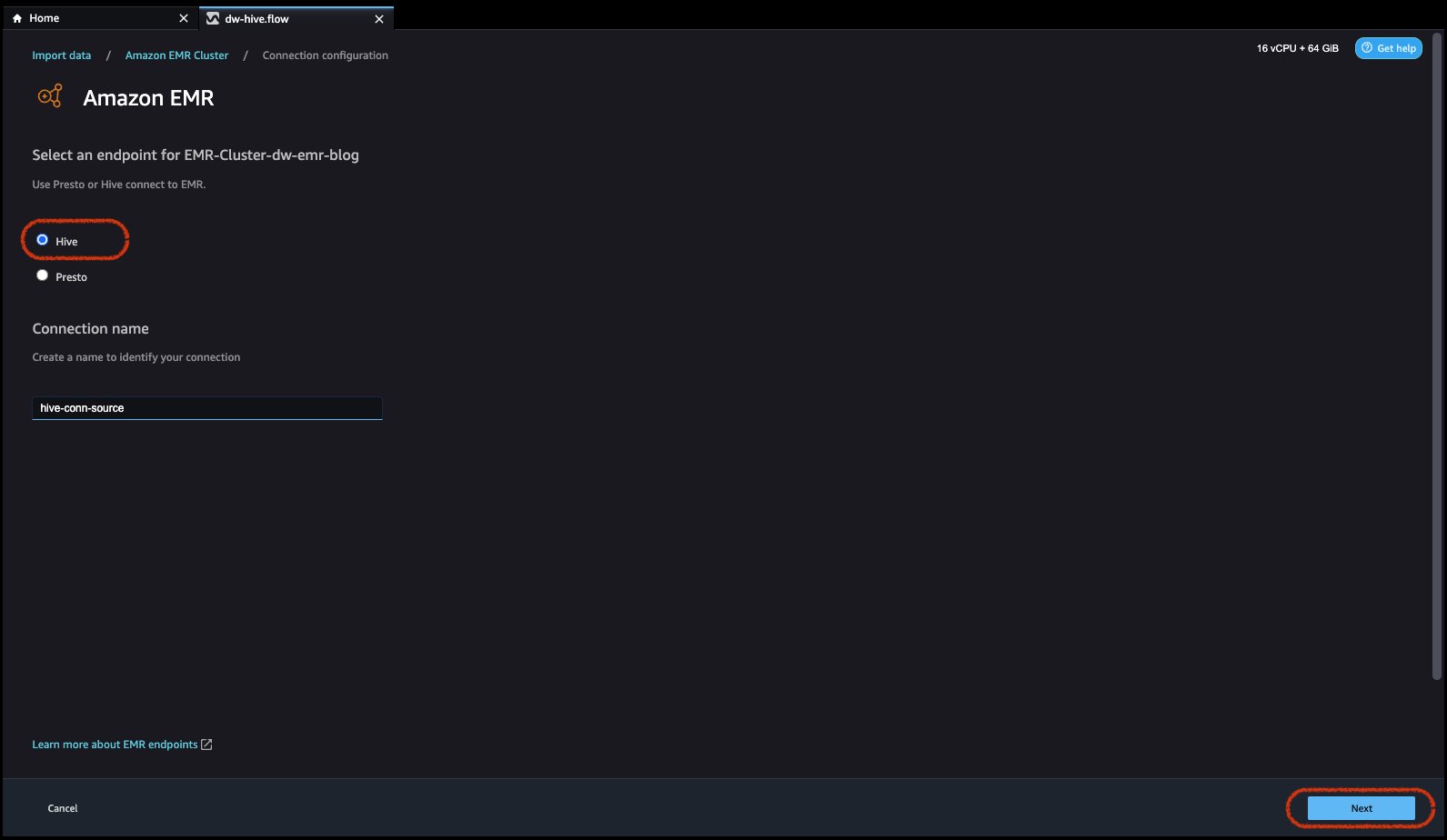
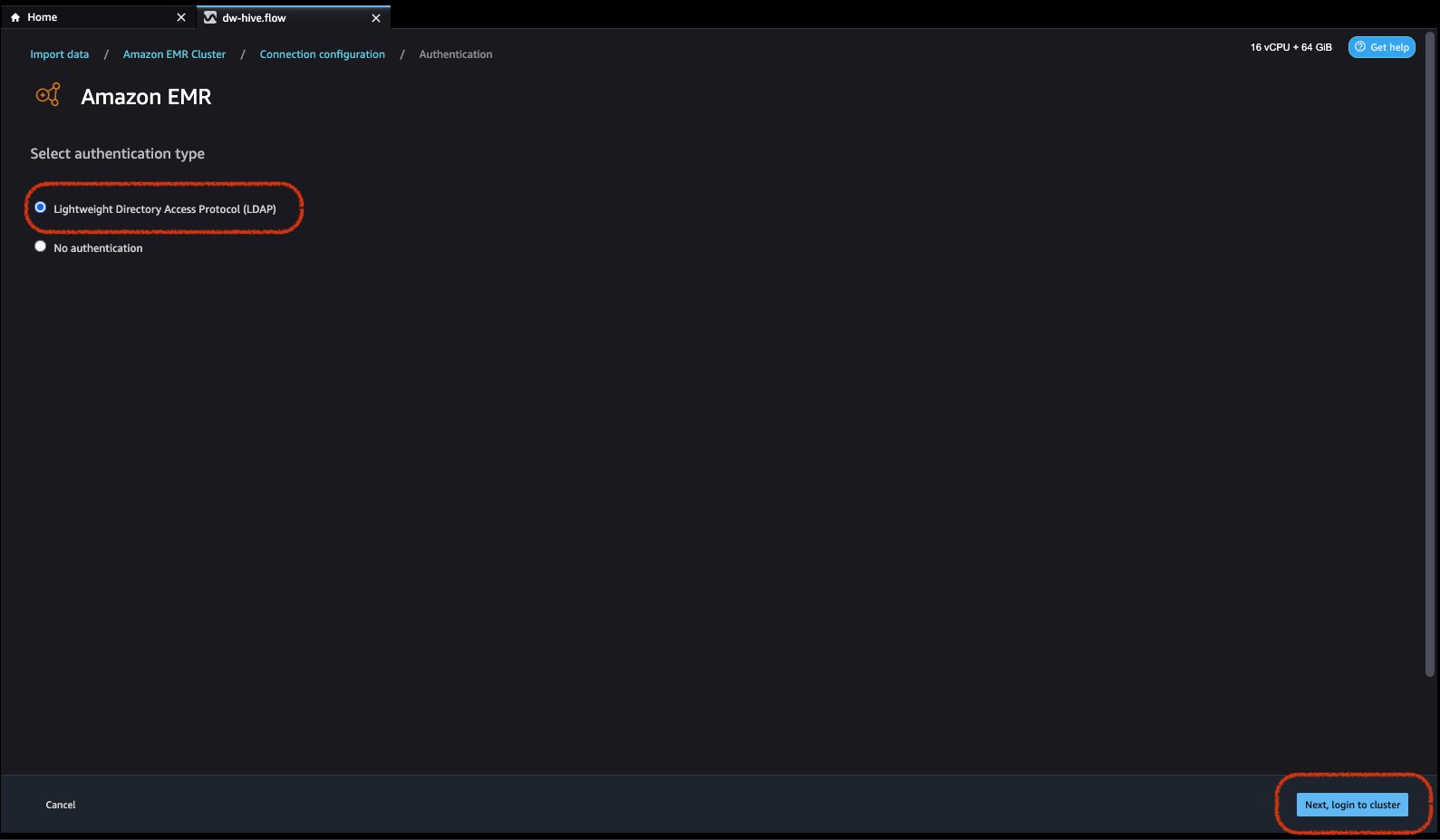
- Sélectionnez le type d'authentification, soit Protocole LDAP (Lightweight Directory Access Protocol) or Pas d'authentification.
Pour LDAP (Lightweight Directory Access Protocol), sélectionnez l'option et cliquez sur Ensuite, connectez-vous au clusterr, puis indiquez le nom d'utilisateur et le mot de passe pour vous authentifier et cliquez sur Connecter.
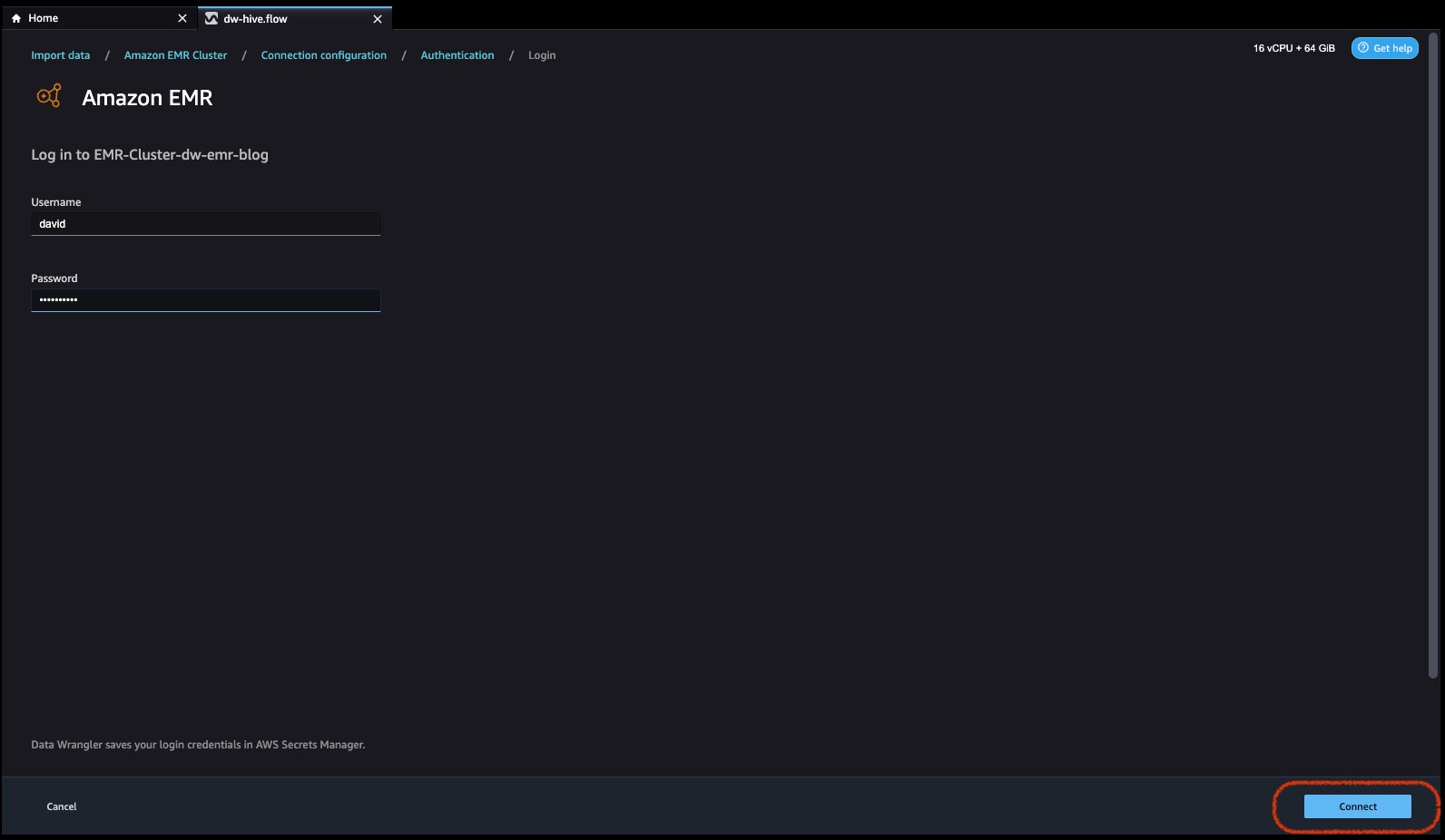
Pour aucune authentification, vous serez connecté à EMR Hive sans fournir d'informations d'identification d'utilisateur dans VPC. Accédez à la page de l'explorateur SQL de Data Wrangler pour EMR.

- Une fois connecté, vous pouvez afficher de manière interactive une arborescence de base de données et un aperçu ou un schéma de table. Vous pouvez également interroger, explorer et visualiser les données d'EMR. Pour l'aperçu, vous verriez une limite de 100 enregistrements par défaut. Une fois que vous avez fourni une instruction SQL dans la zone de l'éditeur de requête et cliquez sur le Courir , la requête sera exécutée sur le moteur Hive d'EMR pour prévisualiser les données.
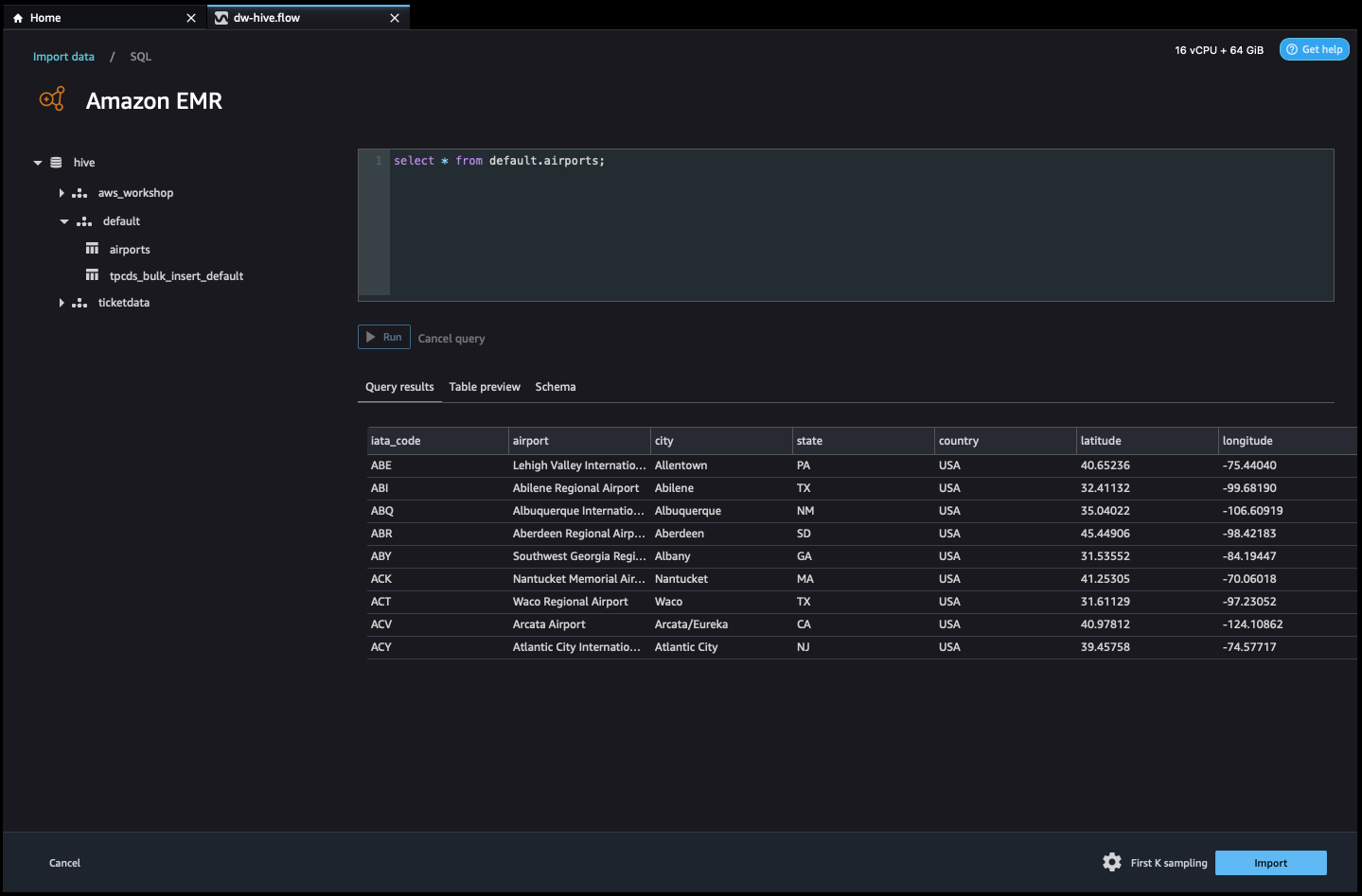
Les Annuler la requête permet d'annuler les requêtes en cours si elles prennent un temps anormalement long.
- La dernière étape consiste à importer. Une fois que vous êtes prêt avec les données interrogées, vous avez la possibilité de mettre à jour les paramètres d'échantillonnage pour la sélection de données en fonction du type d'échantillonnage (FirstK, Random ou Stratified) et de la taille d'échantillonnage pour importer des données dans Data Wrangler.
Cliquez L’. La page de préparation sera chargée, vous permettant d'ajouter diverses transformations et analyses essentielles à l'ensemble de données.
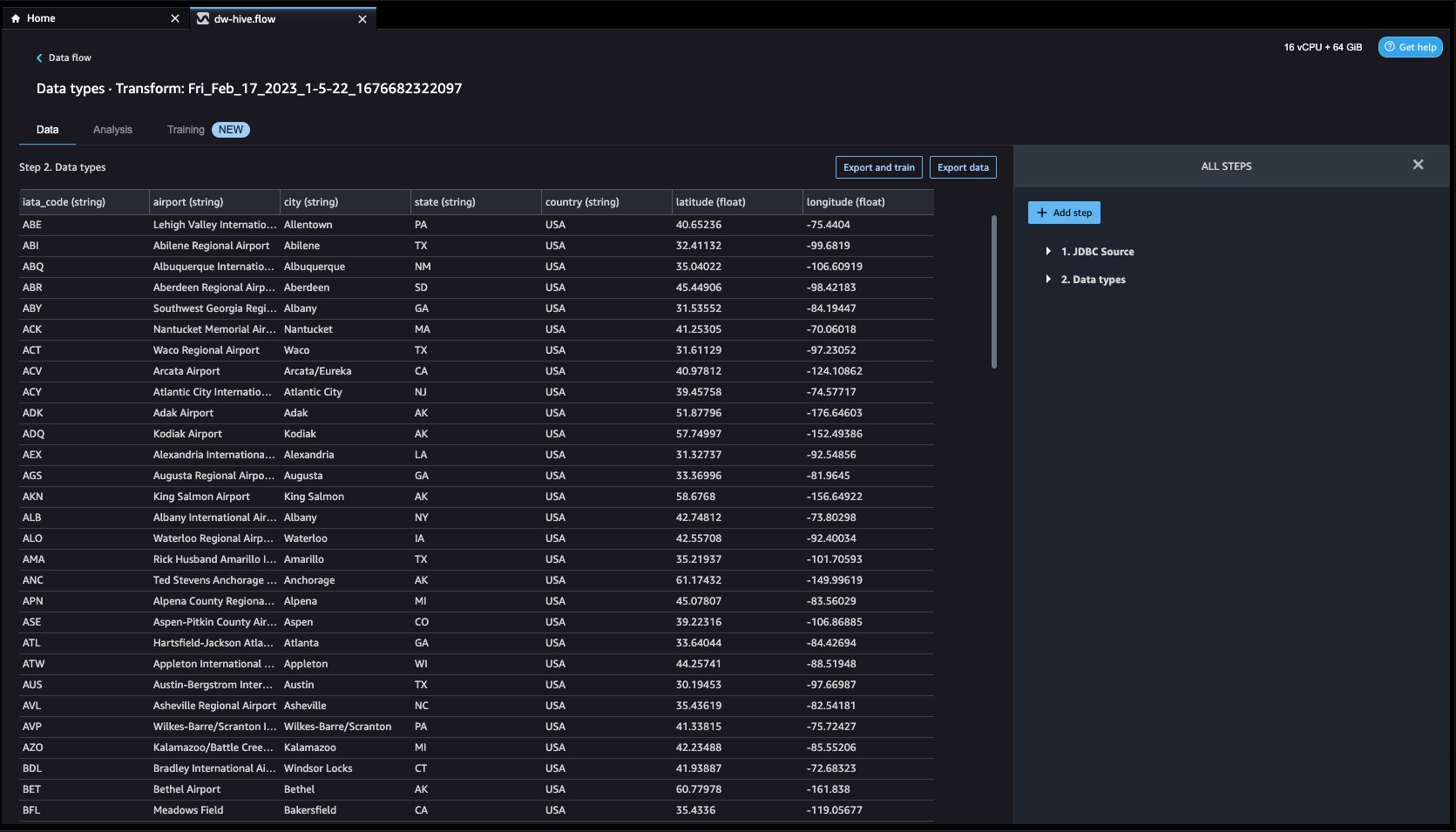
- Accédez à Flux de données à partir de l'écran supérieur et ajoutez d'autres étapes au flux selon les besoins pour les transformations et l'analyse. Vous pouvez exécuter un rapport d'analyse des données pour identifier les problèmes de qualité des données et obtenir des recommandations pour résoudre ces problèmes. Regardons quelques exemples de transformations.
- Dans le Flux de données vue, vous devriez voir que nous utilisons EMR comme source de données à l'aide du connecteur Hive.
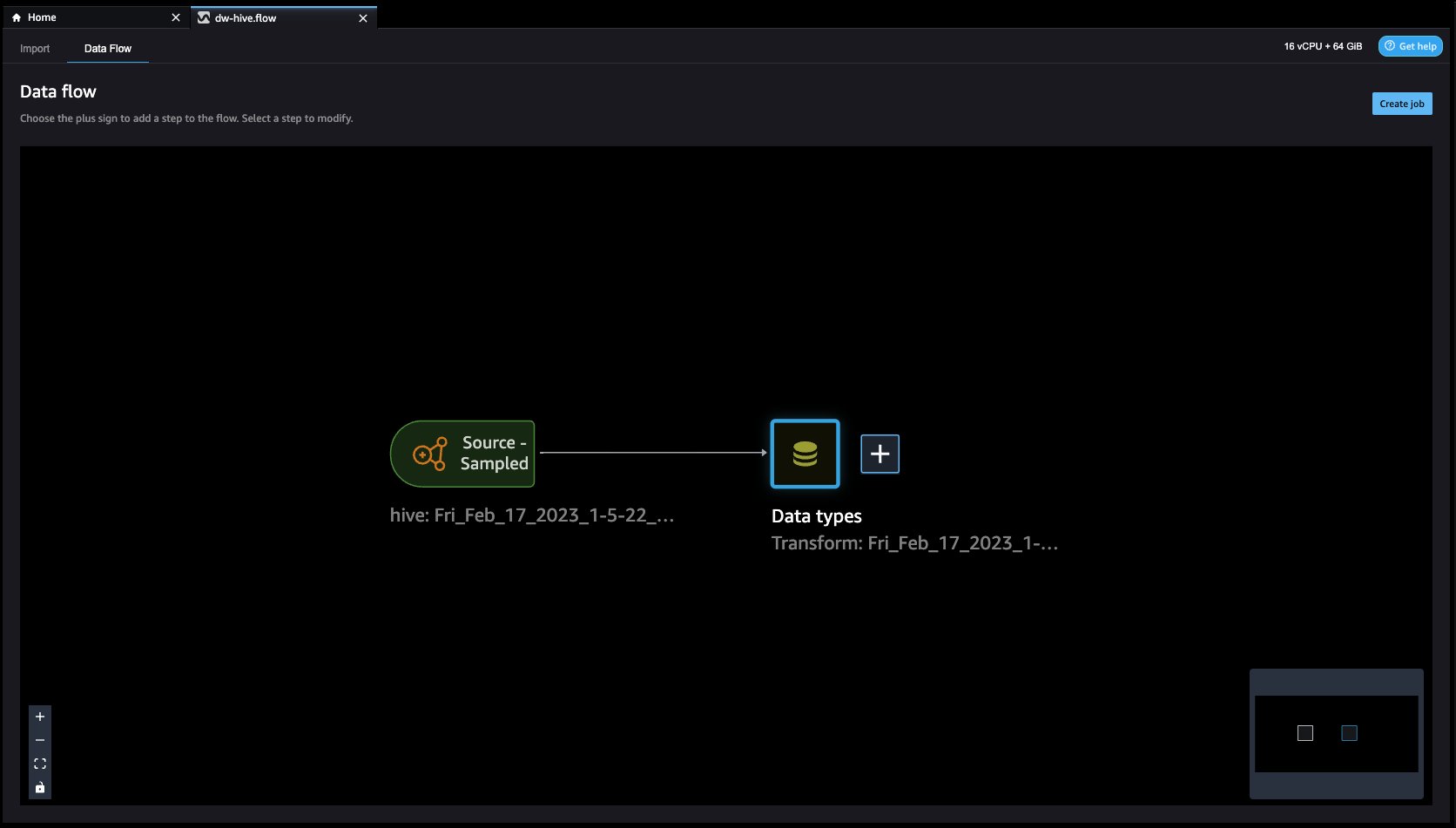
- Cliquons sur le + bouton à droite de Types de données et sélectionnez Ajouter une transformation. Lorsque vous faites cela, vous revenez à la Données vue.
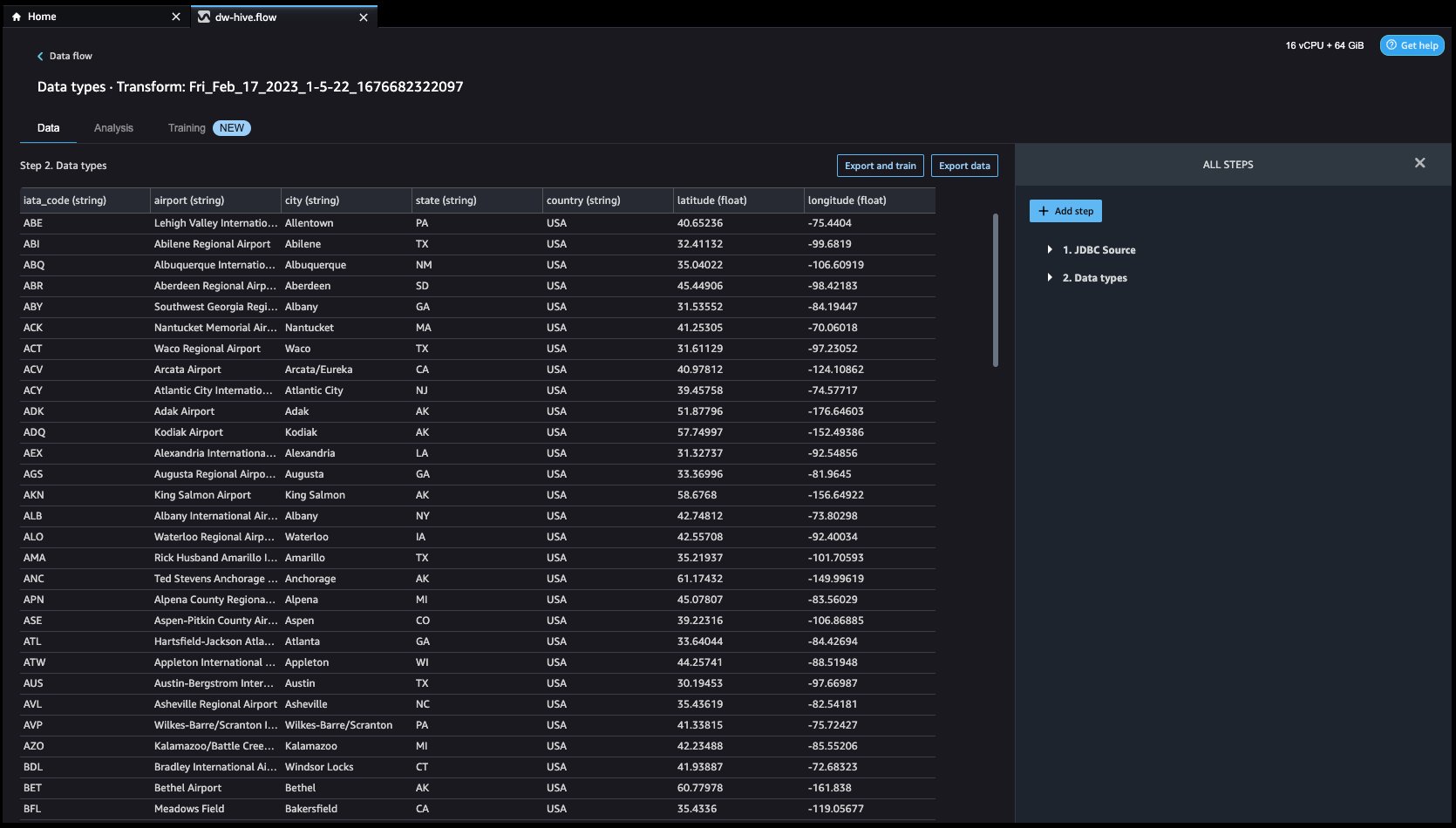
Explorons les données. Nous voyons qu'il a de multiples fonctionnalités telles que code_iata, aéroport, ville, Etat, Pays, latitudeet longitude. Nous pouvons voir que l'ensemble de données est basé dans un seul pays, à savoir les États-Unis, et qu'il manque des valeurs dans latitude ainsi que le longitude. Les données manquantes peuvent entraîner un biais dans l'estimation des paramètres et réduire la représentativité des échantillons. Nous devons donc effectuer certaines imputation et gérer les valeurs manquantes dans notre ensemble de données.
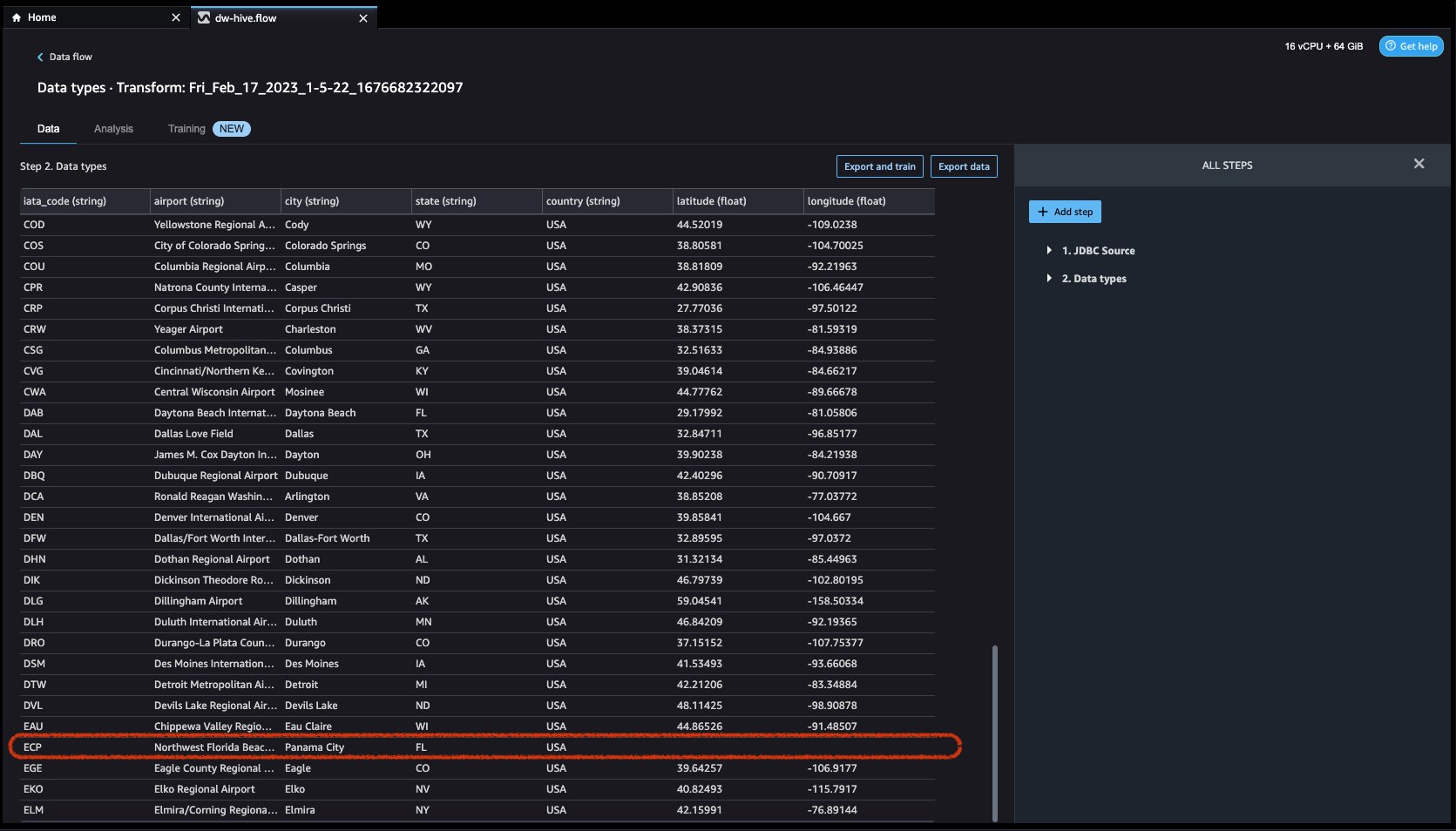
- Cliquons sur le Ajouter une étape sur la barre de navigation à droite. Sélectionner Poignée manquante. Les configurations peuvent être vues dans les captures d'écran suivantes.
Sous Transformer, Sélectionner Imputer. Sélectionnez l' Type de colonne as Numérique ainsi que le Colonne d'entrée noms latitude ainsi que le longitude. Nous imputerons les valeurs manquantes en utilisant une valeur médiane approximative.
Cliquez d'abord sur Aperçu pour afficher la valeur manquante, puis cliquez sur mettre à jour pour ajouter la transformation.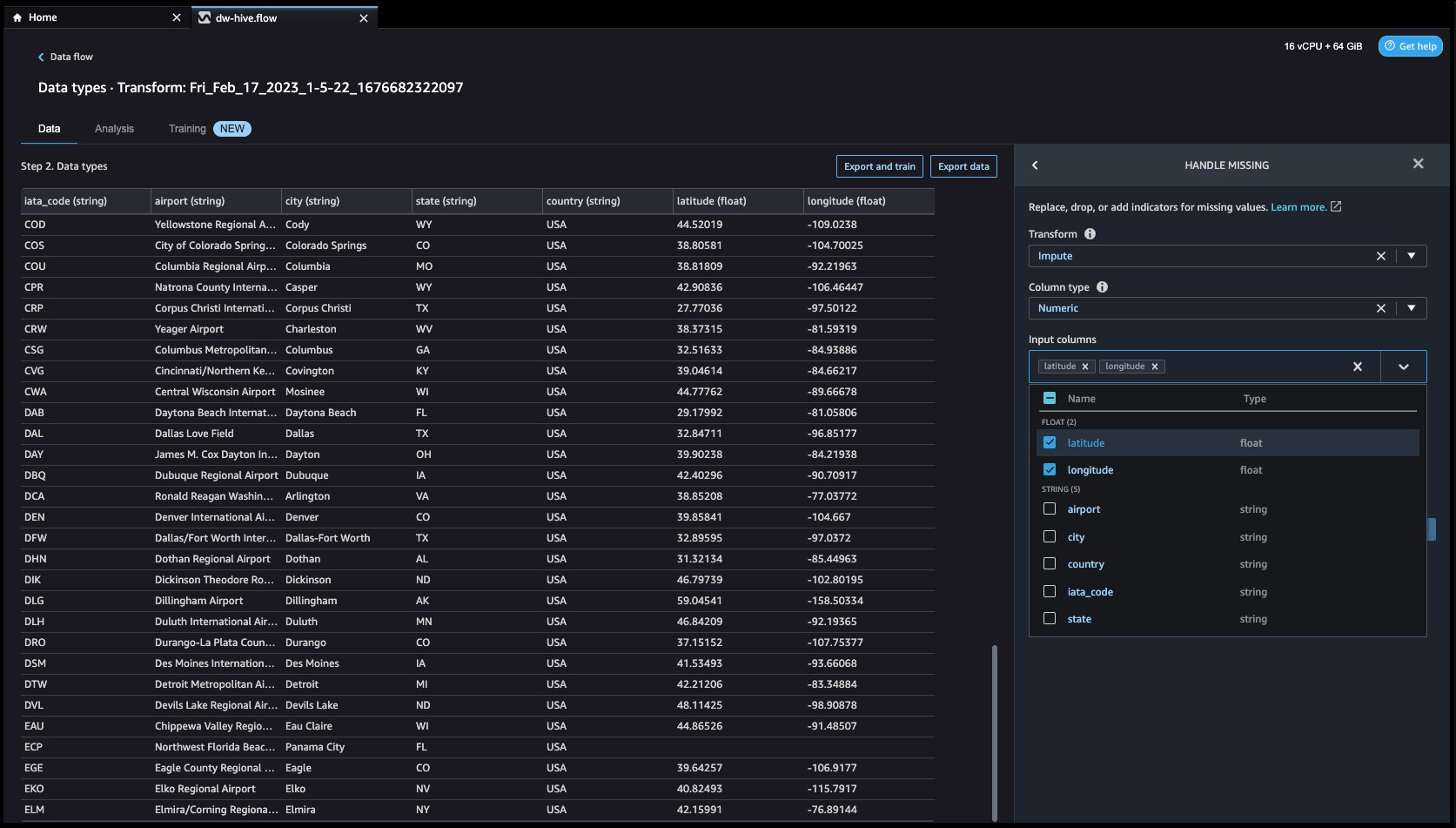

- Regardons maintenant un autre exemple de transformation. Lors de la création d'un modèle ML, les colonnes sont supprimées si elles sont redondantes ou n'aident pas votre modèle. La façon la plus courante de supprimer une colonne consiste à la supprimer. Dans notre jeu de données, la caractéristique Pays peut être supprimé car l'ensemble de données est spécifiquement destiné aux données des aéroports américains. Pour gérer les colonnes, cliquez sur le Ajouter une étape sur la barre de navigation vers la droite et sélectionnez Gérer les colonnes. Les configurations peuvent être vues dans les captures d'écran suivantes. En dessous de Transformer, sélectionnez Déposer la colonne, et sous Colonnes à supprimer, sélectionnez Pays.
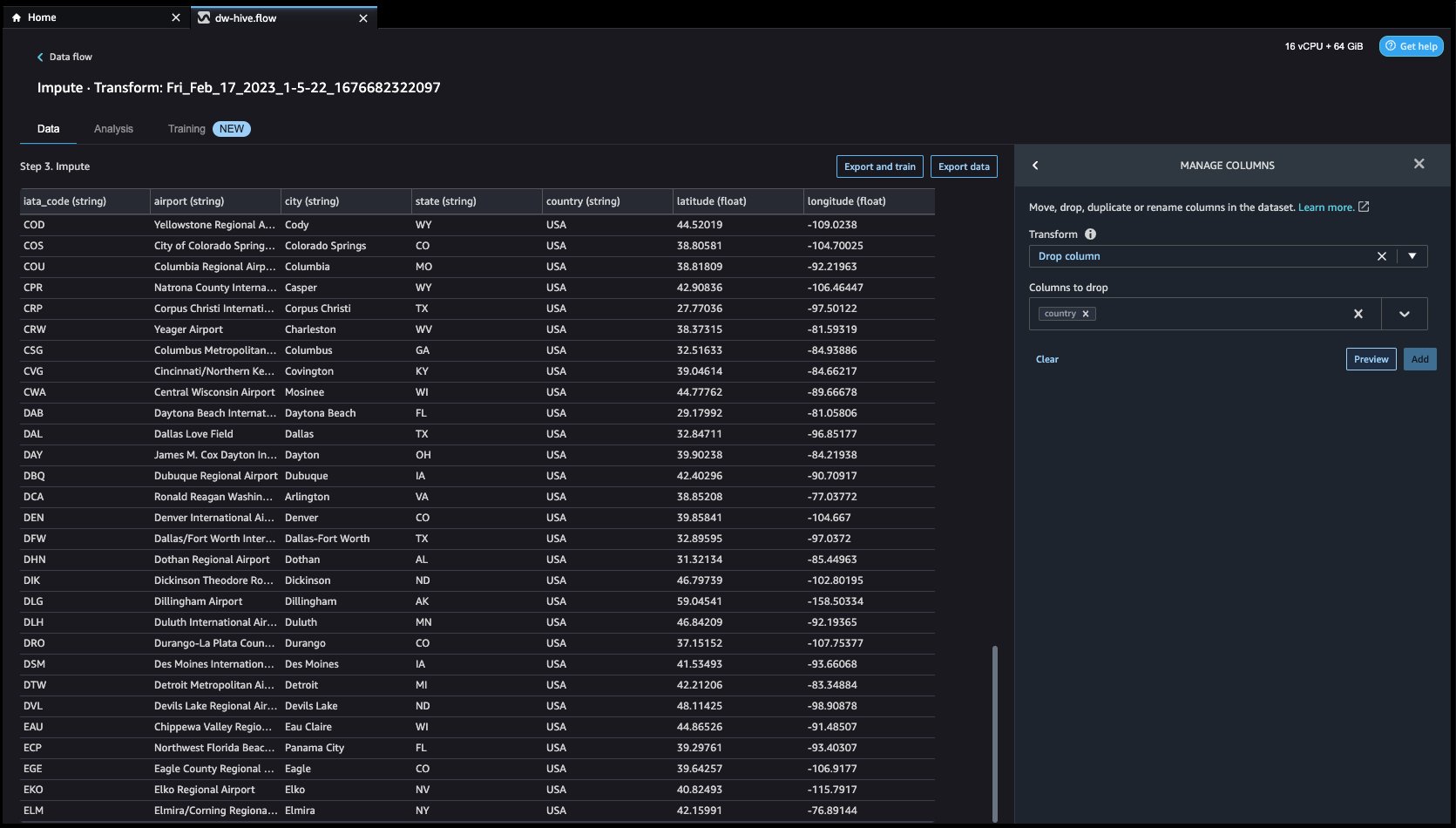
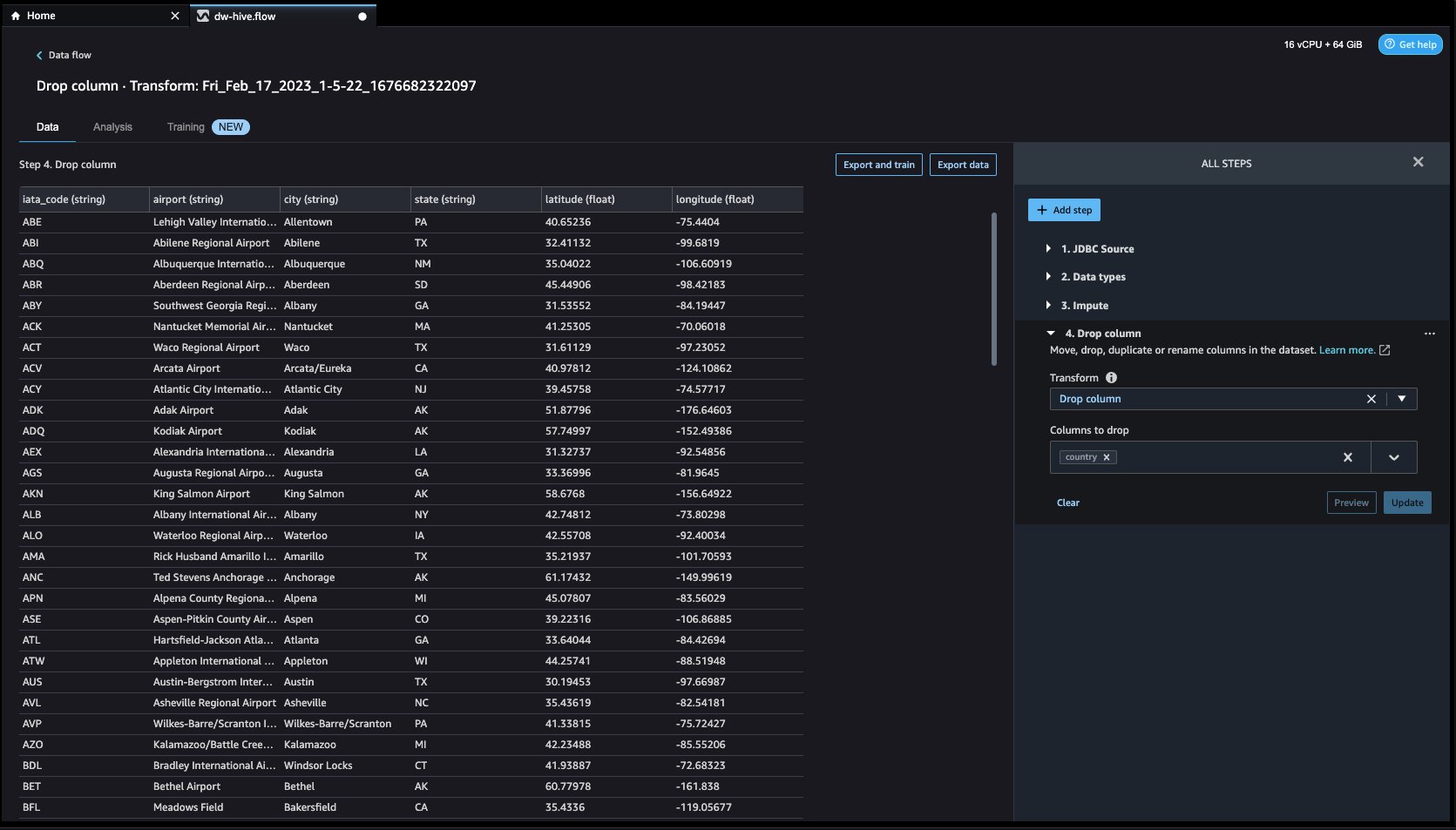
- Cliquez sur Aperçu et alors Mises à jour pour supprimer la colonne.
- Feature Store est un référentiel pour stocker, partager et gérer les fonctionnalités des modèles ML. Cliquons sur le + bouton à droite de Déposer la colonne. Sélectionner Exporter vers et choisissez Magasin de fonctionnalités SageMaker (via le bloc-notes Jupyter).
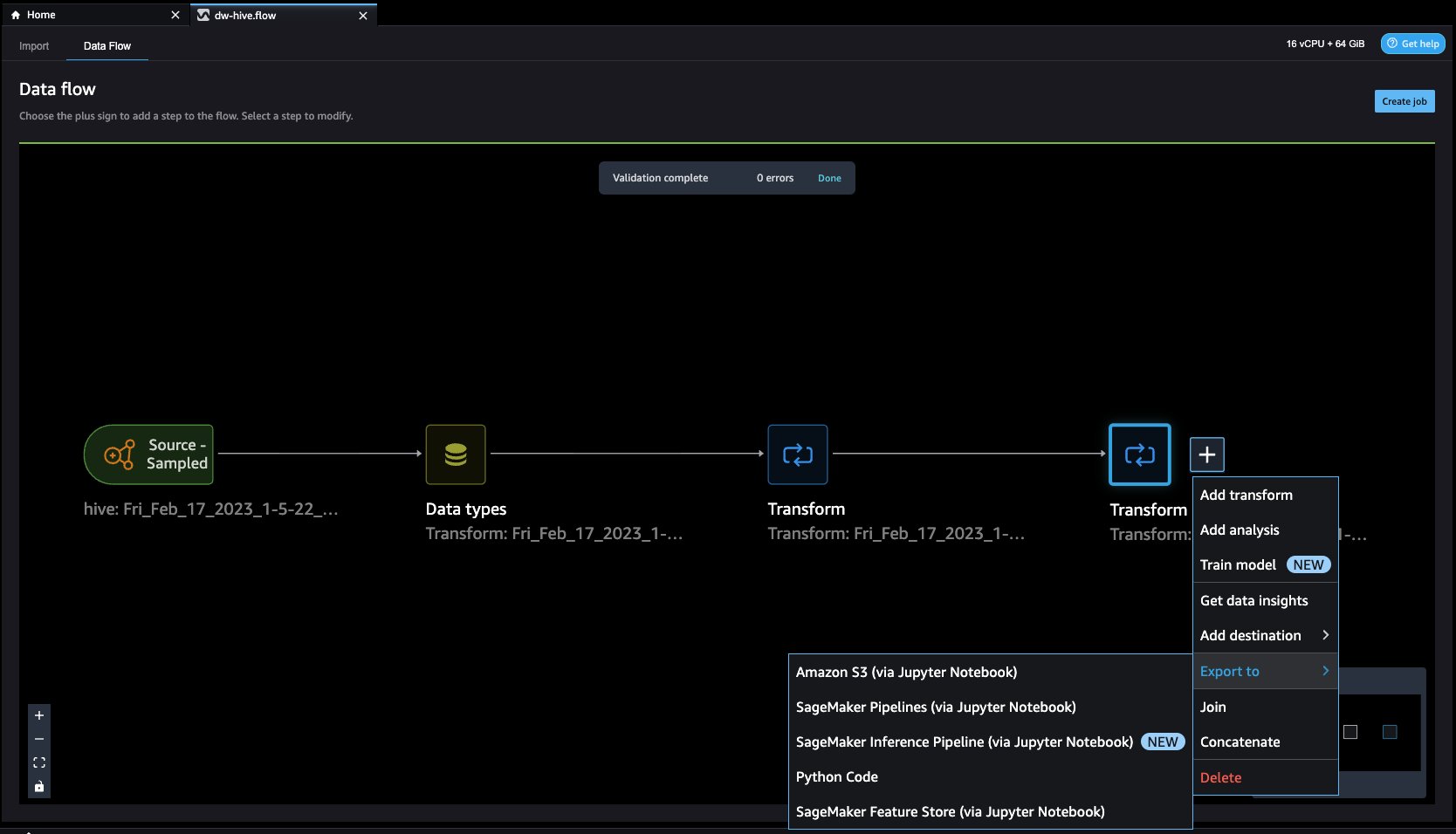
- En sélectionnant Magasin de fonctionnalités SageMaker en tant que destination, vous pouvez enregistrer les fonctionnalités dans un groupe de fonctionnalités existant ou en créer un nouveau.
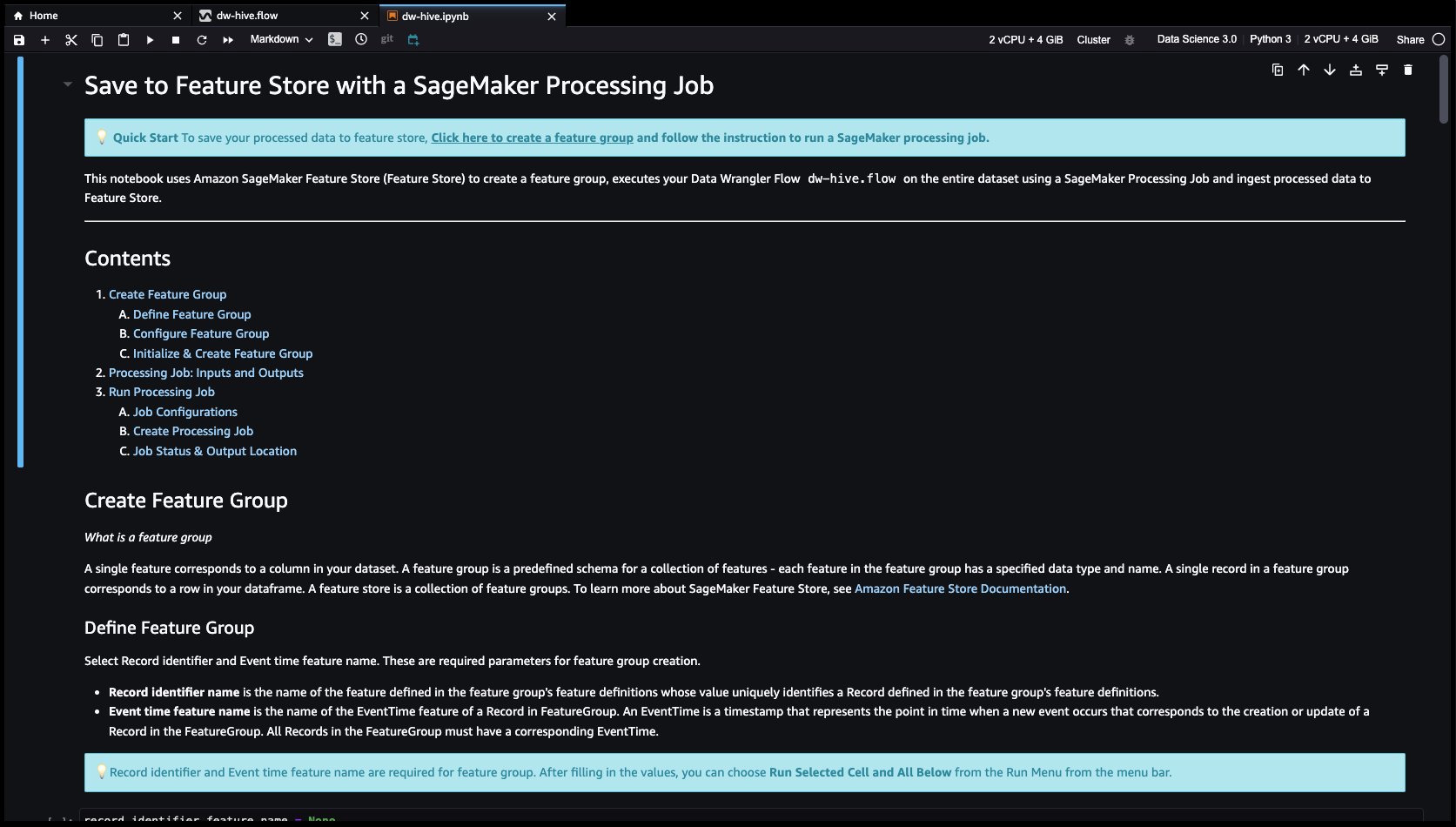
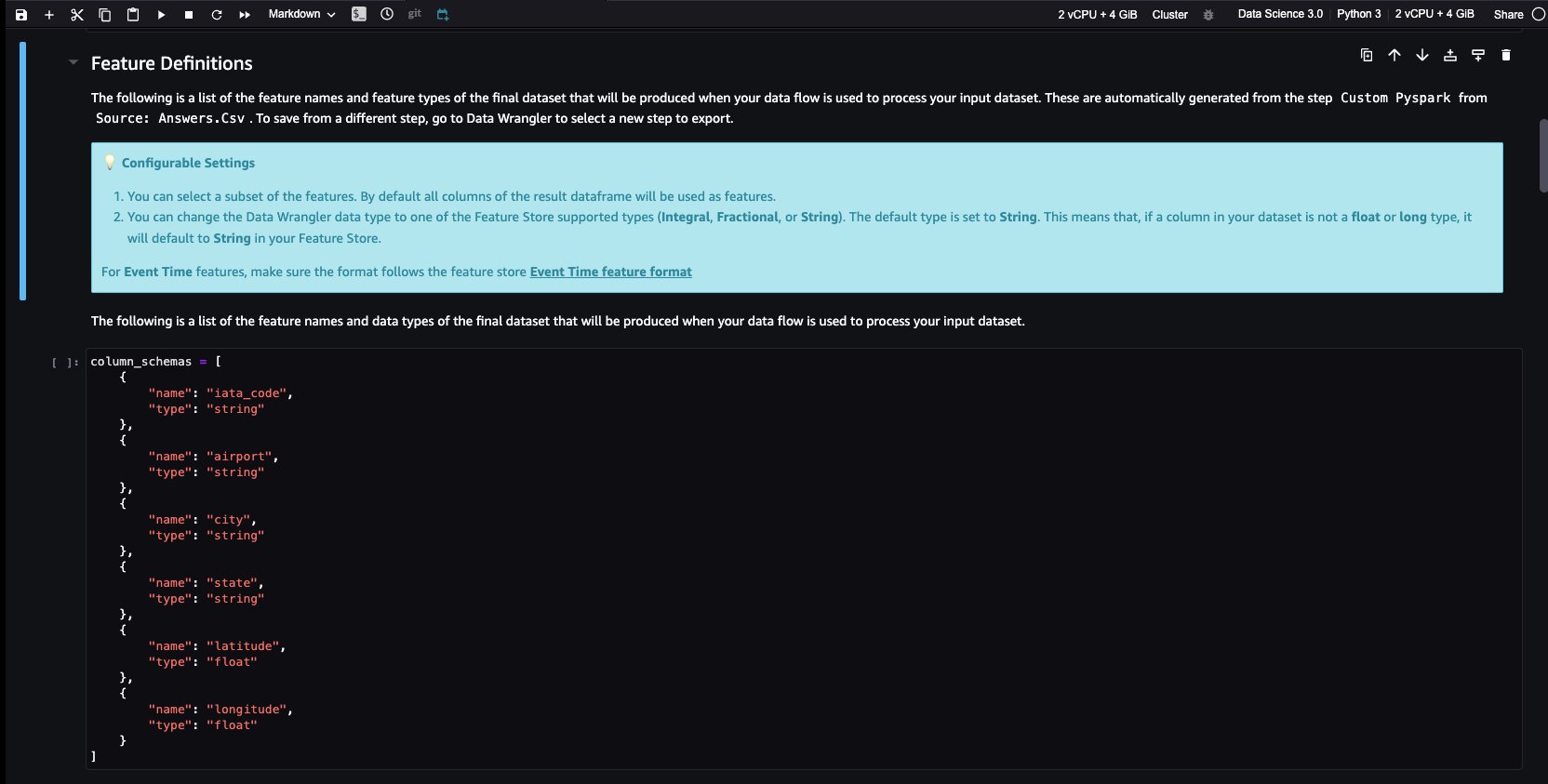
Nous avons maintenant créé des fonctionnalités avec Data Wrangler et stocké facilement ces fonctionnalités dans Feature Store. Nous avons montré un exemple de flux de travail pour l'ingénierie des fonctionnalités dans l'interface utilisateur de Data Wrangler. Ensuite, nous avons enregistré ces fonctionnalités dans le Feature Store directement à partir de Data Wrangler en créant un nouveau groupe de fonctionnalités. Enfin, nous avons exécuté une tâche de traitement pour ingérer ces fonctionnalités dans Feature Store. Data Wrangler et Feature Store nous ont aidés à créer des processus automatiques et reproductibles pour rationaliser nos tâches de préparation des données avec un minimum de codage requis. Data Wrangler nous offre également la flexibilité d'automatiser le même flux de préparation des données à l'aide de tâches planifiées. Nous pouvons aussi automatiquement former et déployer des modèles à l'aide de SageMaker Autopilot à partir de l'interface visuelle de Data Wrangler, ou créez un pipeline de formation ou d'ingénierie de fonctionnalités avec SageMaker Pipelines (via Jupyter Notebook) et déployez-le sur le point de terminaison d'inférence avec le pipeline d'inférence SageMaker (via Jupyter Notebook).

Nettoyer
Si votre travail avec Data Wrangler est terminé, les étapes suivantes vous aideront à supprimer les ressources créées pour éviter des frais supplémentaires.
- Fermez SageMaker Studio.
Dans SageMaker Studio, fermez tous les onglets, puis sélectionnez Déposez votre dernière attestation puis arrêter. Une fois invité, sélectionnez Tout arrêter.
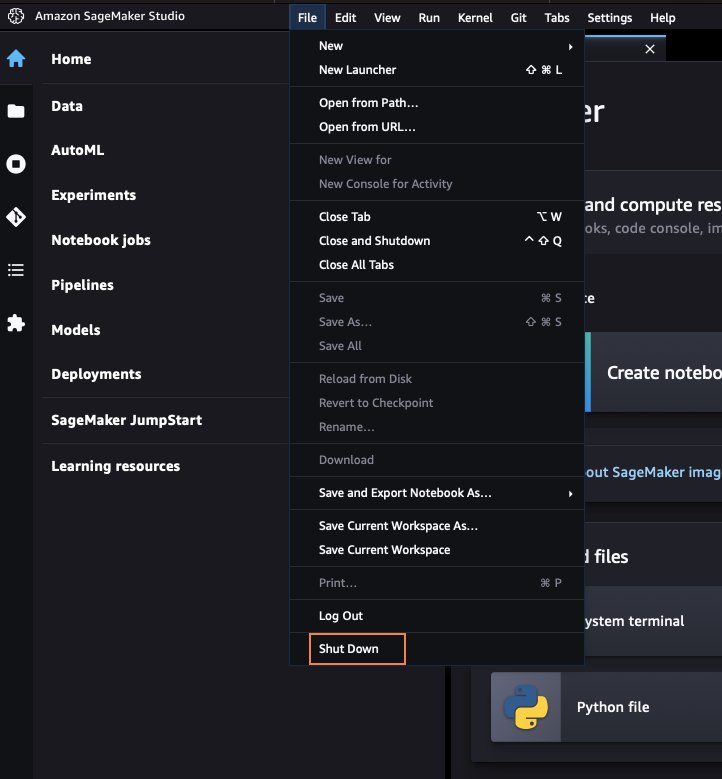

L'arrêt peut prendre quelques minutes en fonction du type d'instance. Assurez-vous que toutes les applications associées au profil utilisateur ont été supprimées. S'ils n'ont pas été supprimés, supprimez manuellement l'application associée sous le profil de l'utilisateur.
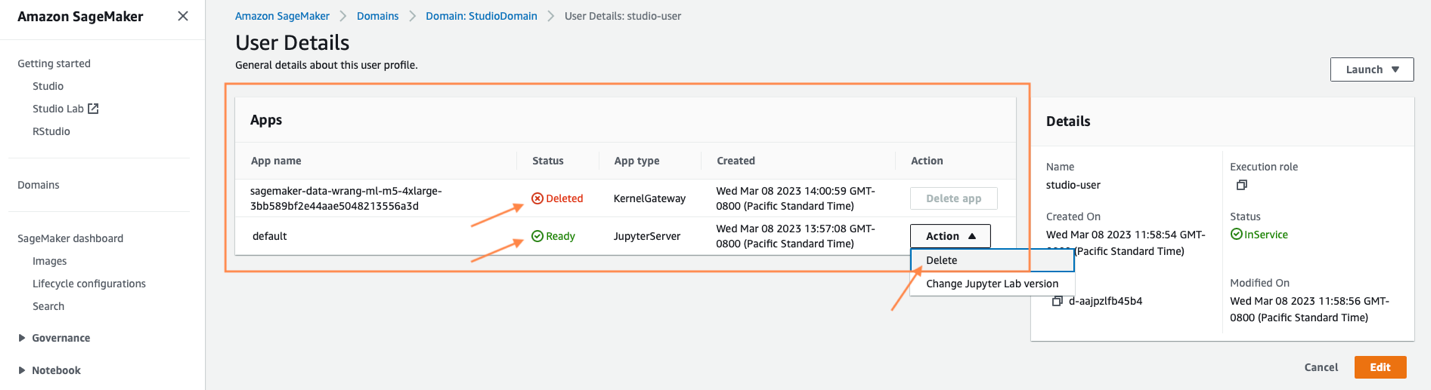
- Videz tous les compartiments S3 qui ont été créés à partir du lancement de CloudFormation.
Ouvrez la page Amazon S3 en recherchant S3 dans la recherche de la console AWS. Videz tous les compartiments S3 qui ont été créés lors du provisionnement des clusters. Le seau serait de format dw-emr-hive-blog-.
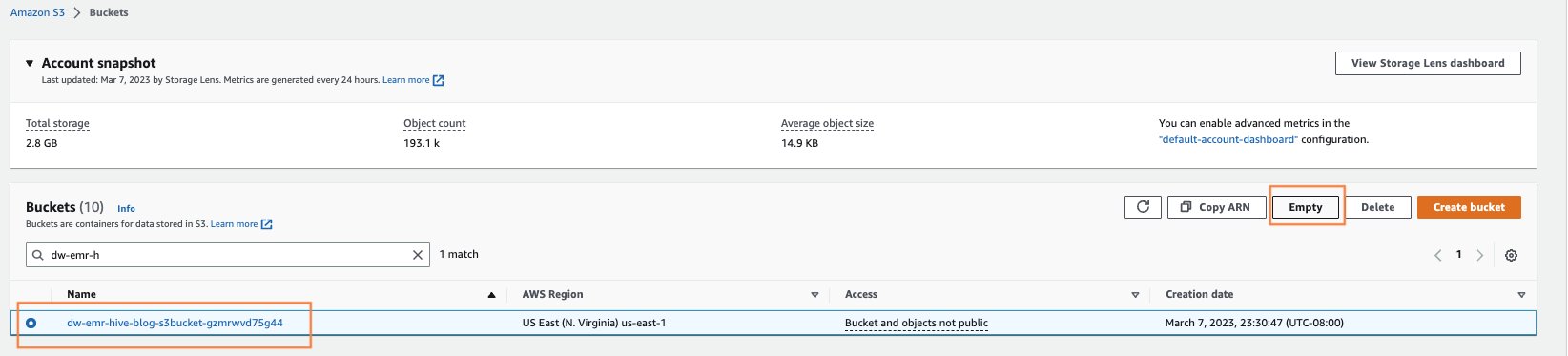
- Supprimez l'EFS de SageMaker Studio.
Ouvrez la page EFS en recherchant EFS dans la recherche de la console AWS.

Localisez le système de fichiers qui a été créé par SageMaker. Vous pouvez le confirmer en cliquant sur le ID du système de fichiers et confirmant l'étiquette ManagedByAmazonSageMakerResource sur le Tags languette.
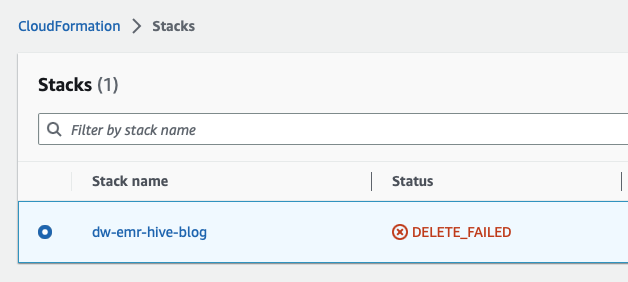
- Supprimez les piles CloudFormation. Ouvrez CloudFormation en recherchant et en ouvrant le service CloudFormation à partir de la console AWS.
Sélectionnez le modèle commençant par dw- comme indiqué dans l'écran suivant et supprimez la pile comme indiqué en cliquant sur le Supprimer .

Ceci est attendu et nous y reviendrons et le nettoierons dans les étapes suivantes.
- Supprimez le VPC après l'échec de la pile CloudFormation. Ouvrez d'abord le VPC à partir de la console AWS.
- Ensuite, identifiez le VPC qui a été créé par SageMaker Studio CloudFormation, intitulé
dw-emr-, puis suivez les invites pour supprimer le VPC.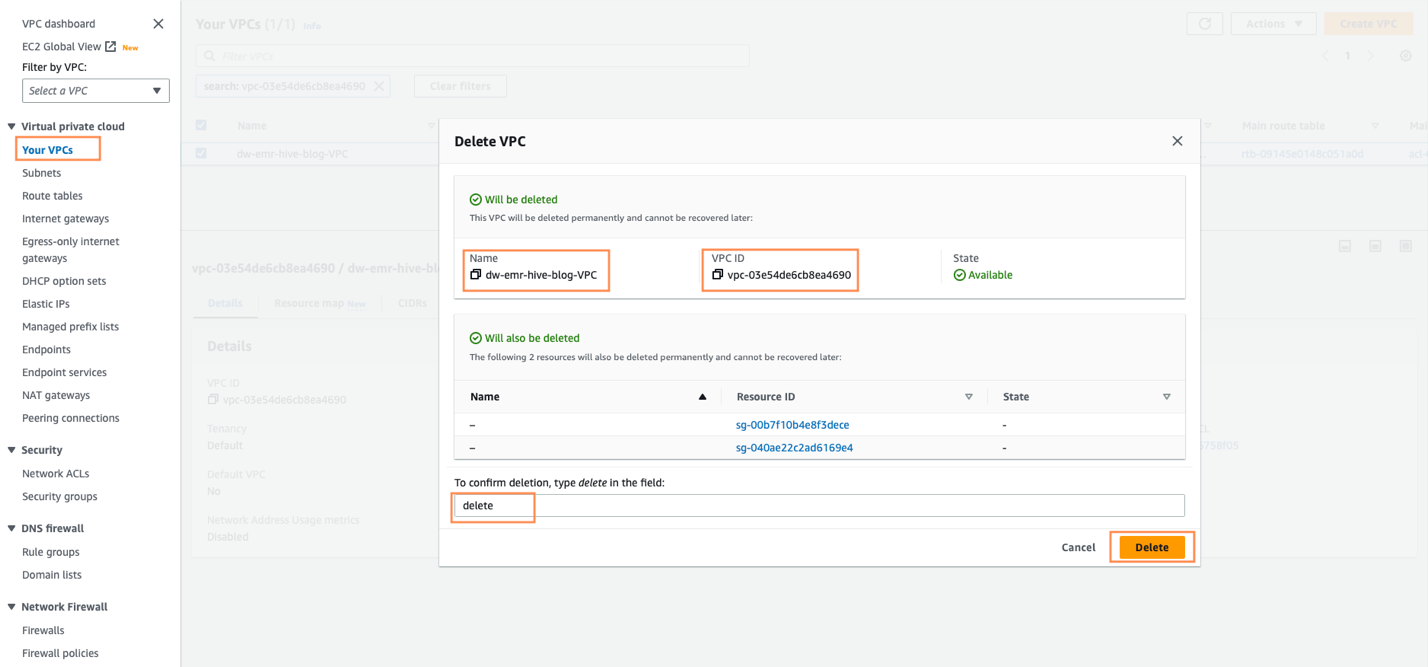
- Supprimez la pile CloudFormation.
Revenez à CloudFormation et réessayez la suppression de la pile pour dw-emr-hive-blog.

Complet! Toutes les ressources provisionnées par le modèle CloudFormation décrit dans cet article de blog seront désormais supprimées de votre compte.
Conclusion
Dans cet article, nous avons expliqué comment configurer Amazon EMR en tant que source de données dans Data Wrangler, comment transformer et analyser un ensemble de données et comment exporter les résultats vers un flux de données à utiliser dans un bloc-notes Jupyter. Après avoir visualisé notre ensemble de données à l'aide des fonctionnalités analytiques intégrées de Data Wrangler, nous avons encore amélioré notre flux de données. Le fait que nous ayons créé un pipeline de préparation de données sans écrire une seule ligne de code est significatif.
Pour démarrer avec Data Wrangler, consultez Préparer les données de ML avec Amazon SageMaker Data Wrangler et voir les dernières informations sur le Page produit Data Wrangler ainsi que le Documents techniques AWS.
À propos des auteurs
 Ajjay Govindaram est architecte de solutions senior chez AWS. Il travaille avec des clients stratégiques qui utilisent l'IA/ML pour résoudre des problèmes commerciaux complexes. Son expérience consiste à fournir une direction technique ainsi qu'une assistance à la conception pour les déploiements d'applications AI/ML à petite et grande échelle. Ses connaissances vont de l'architecture d'application au big data, à l'analyse et à l'apprentissage automatique. Il aime écouter de la musique tout en se reposant, profiter du plein air et passer du temps avec ses proches.
Ajjay Govindaram est architecte de solutions senior chez AWS. Il travaille avec des clients stratégiques qui utilisent l'IA/ML pour résoudre des problèmes commerciaux complexes. Son expérience consiste à fournir une direction technique ainsi qu'une assistance à la conception pour les déploiements d'applications AI/ML à petite et grande échelle. Ses connaissances vont de l'architecture d'application au big data, à l'analyse et à l'apprentissage automatique. Il aime écouter de la musique tout en se reposant, profiter du plein air et passer du temps avec ses proches.
 Isha Doua est un architecte de solutions senior basé dans la région de la baie de San Francisco. Elle aide les entreprises clientes d'AWS à se développer en comprenant leurs objectifs et leurs défis, et les guide sur la manière dont elles peuvent concevoir leurs applications de manière native dans le cloud tout en garantissant la résilience et l'évolutivité. Elle est passionnée par les technologies d'apprentissage automatique et la durabilité environnementale.
Isha Doua est un architecte de solutions senior basé dans la région de la baie de San Francisco. Elle aide les entreprises clientes d'AWS à se développer en comprenant leurs objectifs et leurs défis, et les guide sur la manière dont elles peuvent concevoir leurs applications de manière native dans le cloud tout en garantissant la résilience et l'évolutivité. Elle est passionnée par les technologies d'apprentissage automatique et la durabilité environnementale.
 Varun Mehta est architecte de solutions chez AWS. Il se passionne pour aider les clients à créer des solutions bien architecturées à l'échelle de l'entreprise sur le cloud AWS. Il travaille avec des clients stratégiques qui utilisent l'IA/ML pour résoudre des problèmes commerciaux complexes.
Varun Mehta est architecte de solutions chez AWS. Il se passionne pour aider les clients à créer des solutions bien architecturées à l'échelle de l'entreprise sur le cloud AWS. Il travaille avec des clients stratégiques qui utilisent l'IA/ML pour résoudre des problèmes commerciaux complexes.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Platoblockchain. Intelligence métaverse Web3. Connaissance Amplifiée. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/accelerate-time-to-insight-with-amazon-sagemaker-data-wrangler-and-the-power-of-apache-hive/

