ABBYY est une société technologique mondiale qui fournit des solutions pour le traitement de documents, la capture de données et les technologies basées sur le langage. Elle a été fondée en 1989 par un groupe de linguistes et d'ingénieurs de l'Université d'État de Moscou. Le nom de la société est un acronyme pour « Advanced Business Computer Systems ».
Les premiers produits d'ABBYY étaient des dictionnaires et des logiciels linguistiques pour différents marchés. Dans les années 1990, ABBYY a élargi sa gamme de produits pour inclure des applications de reconnaissance optique de caractères (OCR) et de numérisation de documents. Les produits PDF d'ABBYY sont parmi les plus populaires du marché. Plus de 100 millions de personnes utilisent chaque jour les produits ABBYY PDF. La société s'efforce de fournir des solutions précises, fiables et conviviales que tout le monde peut utiliser, des particuliers aux grandes organisations.
Ce billet de blog présentera leur gamme de produits et certains avantages/inconvénients de travailler ensemble. Nous comparerons également certains de leurs produits avec ceux proposés par d'autres entreprises de premier plan dans ce secteur afin que vous puissiez décider s'ils correspondent à vos besoins.
Plongeons dedans.
Quelles solutions propose ABBYY ?
ABBYY propose une gamme complète de logiciels de conversion et d'édition OCR et PDF faciles à utiliser et fiables. Leurs produits permettent aux utilisateurs de convertir des documents en fichiers PDF interrogeables, de modifier des fichiers PDF et d'extraire des données de formulaires et de tableaux. La société propose également une application mobile pour les appareils iOS et Android qui permet aux utilisateurs de numériser et de convertir des documents papier en formats numériques. Dans cette section, nous allons explorer les différents services qu'ils fournissent.
ABBYY Vantage
ABBYY Vantage est une solution de gestion de documents qui vous permet d'automatiser vos processus métier à l'aide d'algorithmes intelligents et de l'intelligence artificielle. Vous pouvez améliorer l'efficacité de votre flux de travail en utilisant cet outil pour convertir, annoter, traiter et extraire des données de divers documents. Cet outil vous permet également d'utiliser la technologie OCR à diverses fins telles que la classification, l'indexation et la recherche de documents. ABBYY Vantage propose également des fonctionnalités d'analyse de données pour aider les entreprises à suivre les tendances et à obtenir de nouvelles informations sur leur activité.
Chronologie ABBYY
ABBYY Timeline est une application permettant de visualiser des événements historiques à partir de documents texte non structurés tels que des articles de presse ou des e-mails. L'outil permet aux utilisateurs de voir comment les concepts évoluent et d'identifier des tendances dans le temps. Principalement, cette application utilise des techniques de traitement du langage naturel pour identifier les événements à partir de documents texte, puis regroupe ces événements dans des chronologies en fonction du type d'événement.
ABBYY FlexiCapture
ABBYY FlexiCapture est une suite logicielle qui aide les organisations à saisir automatiquement les champs clés des formulaires papier dans leurs bases de données ou leurs systèmes CRM. Cet outil peut facilement extraire des données de divers formulaires, notamment des factures, des bons de commande, des relevés bancaires, des réclamations d'assurance, etc.
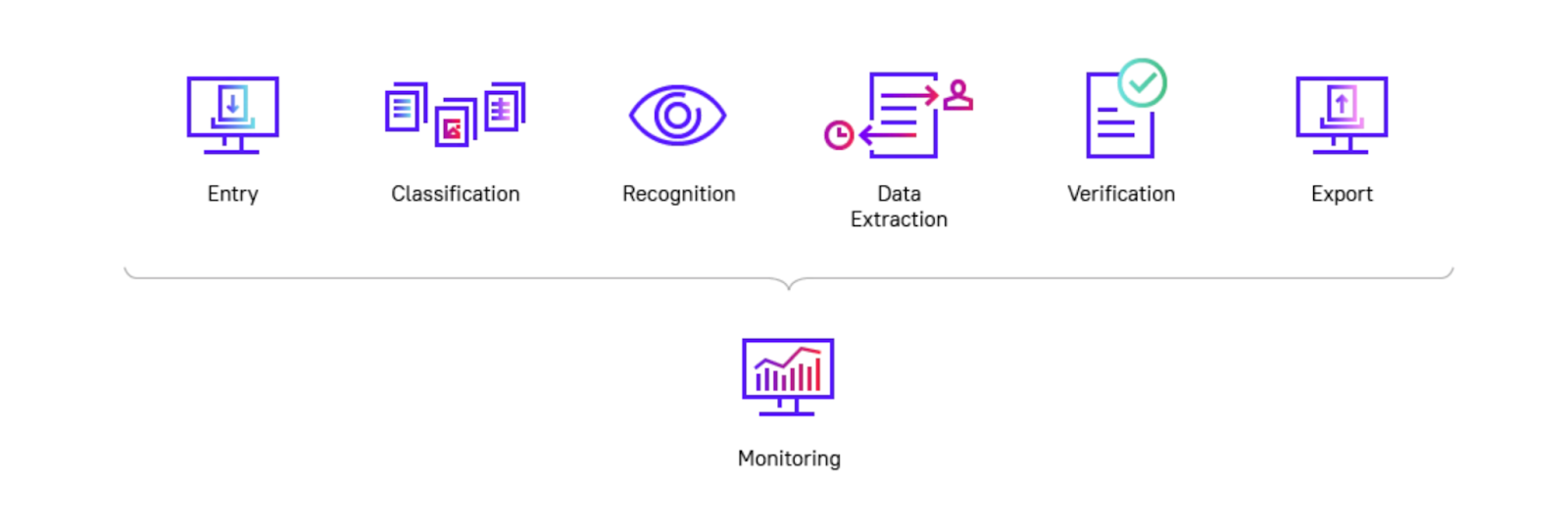
ABBYY FlexiCapture pour les factures
ABBYY FlexiCapture for Invoices est conçu pour aider les entreprises à rationaliser leurs processus de gestion des factures en automatisant les tâches de traitement des factures. Cette solution vous permet de gagner du temps en extrayant, normalisant et enrichissant automatiquement les données des factures avec des informations complémentaires issues de vos bases de données internes et en créant des rapports personnalisés en fonction de vos besoins.
Serveur ABBYY FineReader
ABBYY FineReader Server est une solution de conversion, d'indexation et de récupération automatisées des documents côté serveur. Il convertit les documents numérisés en formats modifiables en temps réel à l'aide de la technologie OCR (reconnaissance optique de caractères), permettant ainsi aux utilisateurs de les modifier et de les réutiliser selon leurs besoins. La solution offre également des fonctionnalités avancées telles que l'indexation fine pour la recherche et l'analyse améliorée des documents pour une meilleure compréhension de la structure du contenu, entre autres.
Les solutions d'entreprise d'ABBYY peuvent être intégrées à différents systèmes via des SDK et des outils de développement.
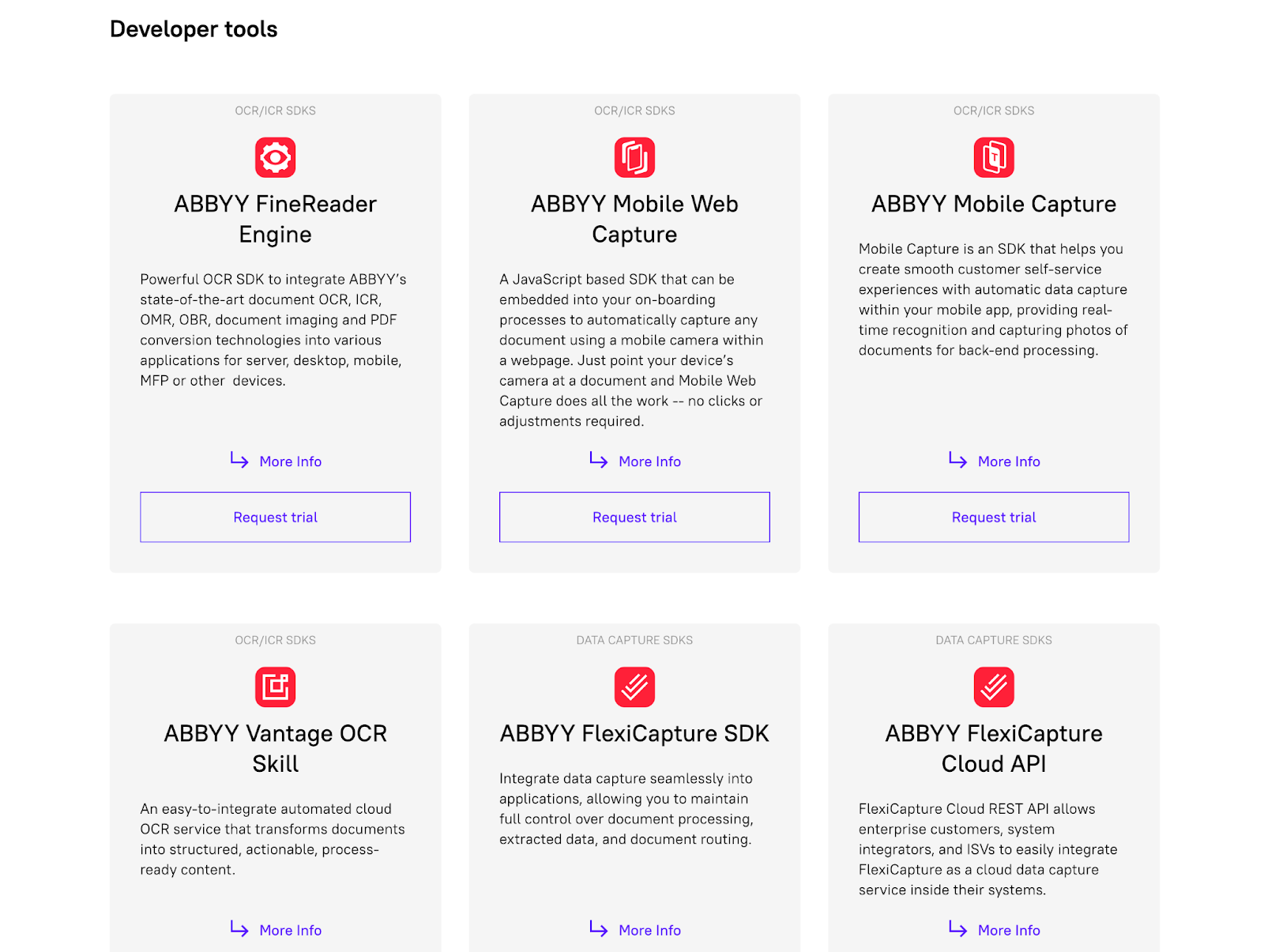
ABBYY FlexiCapture et ABBYY FineReader sont les deux services les plus populaires proposés par ABBYY. Regardons de plus près.
ABBYY FlexiCapture a de nombreuses fonctions en commun avec ABBYY FineReader Server (anciennement connu sous le nom de Recognition Server). Cependant, chaque produit est conçu avec des fonctions uniques, dont les entreprises doivent tenir compte lors de l'évaluation des solutions à leurs exigences de capture de documents et d'OCR. Pour vous aider à comparer les produits plus facilement, nous avons compilé une liste de cas d'utilisation qui vous permettra d'évaluer entre ABBYY FlexiCapture et FineReader Server.
Vous recherchez une solution de reconnaissance de texte intelligente? Dirigez-vous vers nanonets et utilisez la solution avec une précision supérieure à 95%.
Quels sont les cas d'utilisation commerciale d'ABBYY Finereader OCR ?
ABBYY FineReader Server est un programme de conversion de documents utilisé pour convertir des documents et des images dans des formats interrogeables. Le programme fonctionne sur un serveur, permettant la conversion à grande échelle de documents dans le délai de traitement d'une entreprise. Il peut également fournir aux entreprises un moyen rentable de capturer et d'indexer manuellement des documents dans toute l'entreprise, soit en numérisant des documents papier, soit en traitant des fichiers et des images électroniques. Un inconvénient, cependant, est qu'il ne prévoit pas la conversion des valeurs d'écriture manuscrite ou de coche [1].
Dans l'image ci-dessous, vous pouvez voir la relation entre les composants de FineReader Server.
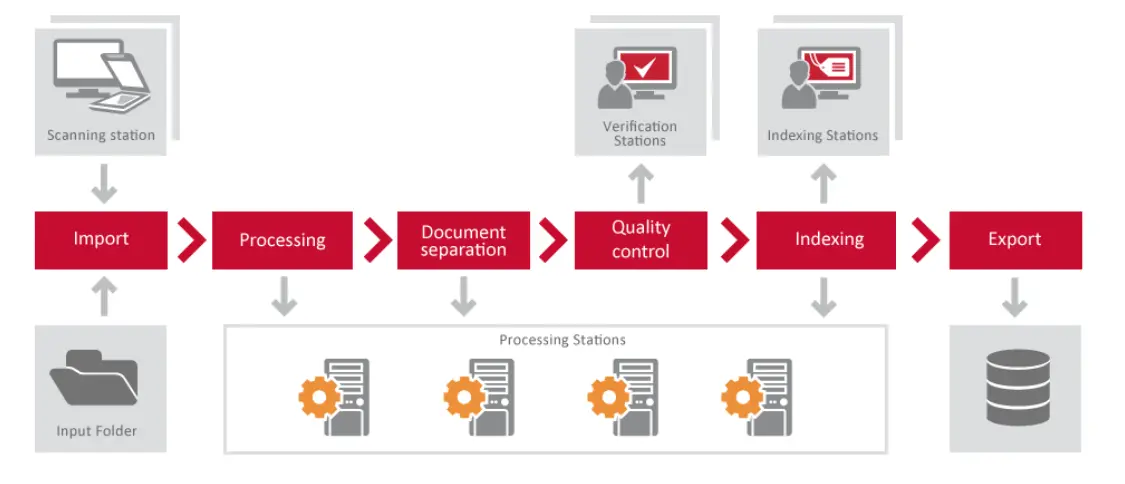
Quelques cas d'utilisation courants
Traitement en masse
Surveillez les dossiers partagés sur un réseau et effectuez des conversions PDF image-texte à partir d'images ou de documents. Lorsqu'un nouveau fichier est ajouté à un dossier, il est converti en une version de recherche textuelle, puis déplacé vers le dossier d'exportation correspondant tout en conservant la désignation de sous-dossier d'origine. Le fichier d'exportation conserverait l'intégrité juridique du fichier image d'origine tout en ajoutant une couche de texte consultable derrière l'image dans le fichier PDF dans les dossiers d'exportation.
Numérisation de documents
Lorsque vous numérisez des documents au format numérique, vous avez l'avantage supplémentaire de pouvoir copier et coller du texte de ces documents dans d'autres documents. Cependant, vous devez retaper manuellement le texte si aucun logiciel OCR n'est disponible. Le temps nécessaire pour le faire peut être important. FineReader OCR permet aux utilisateurs de convertir rapidement des images numérisées en fichiers texte modifiables facilement accessibles et manipulables dans d'autres applications, telles que Word ou Excel. Il en va de même pour les fax, qui sont souvent reçus au format TIFF et ne prennent pas en charge l'édition ou la manipulation. Grâce à FineReader OCR, ces fax peuvent être convertis en fichiers PDF modifiables ou même en documents Word en quelques clics.
Numérisation de documents (images en texte)
ABBYY propose une solution d'extraction de données qui peut être utilisée pour convertir des images de texte imprimé ou manuscrit dans un format modifiable. Il s'agit d'un outil important pour les entreprises et les organisations qui ont besoin de numériser de gros volumes de documents, tels que des documents financiers, juridiques ou médicaux. Le processus d'extraction de données peut extraire automatiquement du texte à partir d'images, qui peuvent ensuite être stockées dans une base de données ou converties en un PDF consultable ou un autre format de document. Cette solution peut faire économiser beaucoup de temps et d'argent aux entreprises et aux organisations en réduisant le besoin de saisie manuelle des données. De plus, le processus d'extraction de données peut être utilisé pour améliorer la précision de la saisie des données en fournissant une méthode cohérente et précise pour convertir les documents papier en format numérique.
Traduction automatique
ABBYY FineReader OCR peut être utilisé comme outil de traduction automatique en convertissant une image en texte dans une autre langue (traduction automatique). Cela peut être utile si vous souhaitez fournir des services de traduction sans avoir à maintenir des traducteurs humains sur place, mais souhaitez tout de même fournir des traductions de qualité à vos clients (ou si vous ne voulez tout simplement pas perdre de temps à traduire quelque chose vous-même).
L'extraction de tableau est un processus d'extraction de données à partir de fichiers PDF ou d'images de documents de tableau grâce à l'utilisation de la reconnaissance optique de caractères (OCR). Il est couramment utilisé pour convertir des documents papier numérisés, tels que des reçus, en format numérique afin que les données puissent être traitées, analysées et stockées plus efficacement. Divers logiciels OCR sont disponibles sur le marché, mais ABBYY FineReader est l'un des choix les plus populaires. La technologie peut reconnaître les lignes et les cellules, et elle peut également détecter les en-têtes et les pieds de page. Il est possible de traiter des documents de plusieurs pages à la fois, ce qui permet de gagner du temps. De plus, ABBYY FineReader prend en charge un large éventail de langues, ce qui le rend idéal pour extraire des données de documents dans différentes langues.
Vous souhaitez automatiser la saisie de données à partir de documents? La solution OCR basée sur l'IA de Nanonets peut aider à extraire des informations clés de documents structurés / non structurés et à mettre le processus en pilotage automatique!
Quels sont les cas d'utilisation commerciale de Flexicapture OCR ?
ABBYY FlexiCapture est principalement une application logicielle d'extraction de données au niveau de l'entreprise qui fournit des fonctions de reconnaissance optique de caractères (OCR). FlexiCapture fournit un moyen d'extraire automatiquement des informations à partir de documents en fonction de l'établissement de règles, y compris des mots-clés et l'emplacement des données sur une page. FlexiCapture est actuellement disponible dans des packages de solutions spéciales prêtes à l'emploi telles que FlexiCapture pour les factures et FlexiCapture pour les salles de courrier. Bien que la solution repose fortement sur l'utilisation de la même technologie OCR que celle trouvée dans FineReader Server et qu'elle puisse exporter une version d'un document avec recherche de texte si nécessaire, ses fonctions principales sont les suivantes :
- Classification des documents (détermination de leur type)
- Faire correspondre ces classes de documents aux règles d'extraction de données correspondantes
- Exporter les données quelque part comme une base de données, un fichier XML ou Microsoft Excel.
Les capacités de classification de documents de FlexiCapture peuvent être utilisées pour extraire puis comparer des valeurs de champ à partir d'ensembles de documents. Par exemple, une demande de prêt peut contenir une demi-douzaine de documents, dont certains contiennent un SSN. Une règle peut facilement être configurée pour comparer les SSN de chaque document contenant une valeur pour ce champ, puis présenter les éventuelles erreurs à l'opérateur lors de la phase de vérification du document.
Dans l'image ci-dessous, vous pouvez voir la relation entre les composants du FlexiCapture Server.
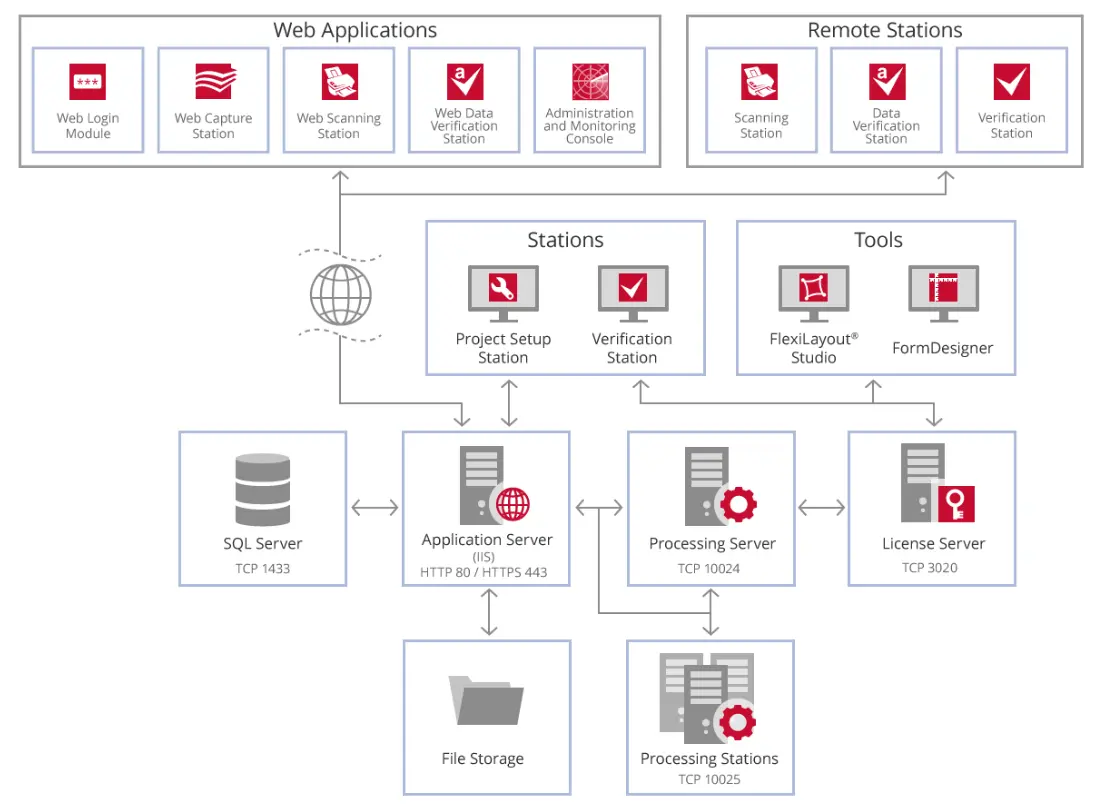
Quelques cas d'utilisation courants
Correspondance à 2 voies
ABBYY FineReader possède des fonctionnalités qui peuvent aider votre service des comptes fournisseurs à fonctionner plus facilement. Ceci comprend:
- Extraction automatique des données de facturation à partir de documents papier et électroniques
- Rapprochement à 2 facteurs des éléments de ligne de facture par rapport à l'achat correspondant dans le système ERP
- Recherche dans les factures avec recherche textuelle
- Approbation des paiements par montant en dollars ou d'autres règles
- Traitement automatisé des bons de commande entrants
Classification du document
- Classez les documents entrants par type et extrayez les données des documents à l'aide de règles préconfigurées.
- Exportez une version PDF avec recherche de texte du document vers un système de gestion de contenu et remplissez les champs avec les données extraites du document.
- Fournissez aux utilisateurs un moyen de corriger les données extraites ainsi que des files d'attente pour gérer les exceptions aux règles préprogrammées dans le processus de workflow de documents.
Meilleures alternatives pour les solutions ABBYY

Amazon Textract est un service qui extrait automatiquement le texte et les données des documents numérisés. Il va au-delà de la simple reconnaissance optique de caractères (OCR) pour identifier également le contenu des champs dans les formulaires et les informations stockées dans les tableaux.
Amazon AWS Textract est un nouvel outil qui gagne en popularité, grâce à son faible coût et sa facilité d'utilisation. Il est idéal pour numériser un grand nombre de documents, bien que ses niveaux de précision ne soient pas aussi élevés qu'ABBYY [2].
La principale différence entre ABBYY et Amazon Textract est que si ABBYY fournit une solution autonome pour extraire du texte à partir d'images à l'aide de la reconnaissance optique de caractères (OCR), Amazon fournit à ses clients une API qu'ils peuvent intégrer dans leurs propres applications. Ils fournissent même différents SDK, ce qui permet aux développeurs d'intégrer plus facilement cette fonctionnalité dans leurs produits ; cependant, cela nécessite des connaissances supplémentaires sur les langages de programmation tels que Java ou Python.
De plus, contrairement à AWS Textract, ABBYY offre un contrôle absolu sur chaque aspect de votre processus OCR (par exemple, il vous permet de personnaliser la segmentation des mots).
ABBYY et AWS Textract fonctionnent très bien en termes de précision et de rapidité dans la plupart des cas.
Avantages du texte
- Vous pouvez utiliser AWS Textract avec n'importe quelle application de traitement de texte avec un SDK.
- AWS Textract prend en charge plus de 25 langues dans 200 pays et territoires. Vous pouvez l'utiliser pour traduire vos fichiers image en temps réel et créer des pipelines de traitement multilingues.
- Cet outil est rentable. Il ne coûte que 0.0025 USD pour 100,000 XNUMX caractères traités, soit moins de la moitié du coût des autres solutions !
- AWS Textract est évolutif, ce qui signifie que vous pouvez l'utiliser à grande ou petite échelle, selon vos besoins.
Inconvénients du texte
- AWS Textract nécessite beaucoup de temps et de ressources pour s'entraîner avec vos données avant de pouvoir les utiliser en production.
- Un logiciel moderne de reconnaissance optique de caractères (OCR) peut identifier si un document téléchargé est un original ou un faux en validant les dates, en trouvant des régions pixélisées et d'autres méthodes. AWS Textract n'a pas cette capacité ; il ne peut extraire que du texte d'un document téléchargé.
- Textract ne permet pas facilement les intégrations avec les fournisseurs en amont et en aval. Par exemple, nous devrons peut-être créer un pipeline RPA avec un service tiers. Il serait difficile de trouver des plugins appropriés qui conviennent à Textract.
ABBYY contre Tesseract

Tesseract OCR a été conçu pour reconnaître un large éventail de langages écrits en code C++ pur. Il peut également être compilé pour être utilisé sur des appareils mobiles tels que les plates-formes Android et iOS. Le logiciel utilise des fonctionnalités avancées telles que la détection de la disposition verticale du texte, permettant aux utilisateurs de lire le texte sous différents angles sans perdre en précision.
ABBYY et Tesseract fournissent des solutions OCR et affichent des taux de précision élevés et prennent en charge une variété de langues. Cependant, il existe des différences critiques entre les deux. ABBYY offre une interface plus conviviale, idéale pour ceux qui découvrent l'OCR. Il fournit également plus de fonctionnalités, telles que l'exportation de plusieurs formats et l'édition d'images. D'autre part, Tesseract est open source et donc libre d'utilisation. Il dispose également d'un moteur plus précis, ce qui en fait le meilleur choix pour ceux qui ont besoin du niveau de précision le plus élevé possible.
Avantages de Tesseract
- Il fonctionne avec différentes langues dans différentes polices, notamment le roman, le cyrillique, l'écriture idéographique Han, l'hébreu, l'arabe et le thaï.
- Le code source est disponible sous une licence Apache, il est donc libre d'utiliser et de modifier. Il a également une faible empreinte mémoire par rapport aux autres moteurs OCR, de sorte qu'il ne prend pas trop de place sur votre ordinateur ou votre smartphone.
- Tesseract est polyvalent et peut être utilisé pour diverses tâches, de la simple reconnaissance optique de caractères (OCR) à des tâches plus complexes telles que l'apprentissage automatique (ML).
Inconvénients de Tesseract
- Tesseract ne produit pas toujours des résultats parfaits, en particulier avec des textes complexes ou manuscrits.
- Le traitement d'image de Tesseract est rudimentaire ; il faut donc utiliser un préprocesseur ou une image déjà traitée pour obtenir les meilleurs résultats [8].
ABBYY contre Ephesoft

Ephesoft est un autre outil de reconnaissance de documents qui utilise la technologie de reconnaissance optique de caractères (OCR) pour convertir des images en fichiers texte. Ce logiciel est conçu spécifiquement pour les entreprises qui ont besoin d'une solution pour gérer de gros volumes de documents papier tels que des factures ou des reçus. Comme les produits d'ABBYY, Ephesoft peut être utilisé dans de nombreux secteurs, notamment la santé, le gouvernement, la finance et la fabrication.
Les deux suites logicielles offrent une gamme complète de fonctionnalités et d'avantages, mais il existe des différences essentielles entre elles. Par exemple, ABBYY est généralement considéré comme plus précis qu'Ephesoft [6]t, en particulier lors de la reconnaissance de texte dans des documents aux mises en page complexes. Cependant, Ephesoft est généralement plus rapide qu'ABBYY, ce qui en fait un bon choix pour les organisations qui doivent traiter quotidiennement un grand volume de documents. En termes de prix, ABBYY est généralement plus cher qu'Ephesoft, bien que les deux sociétés offrent des remises pour les licences en volume. En fin de compte, le meilleur logiciel OCR pour votre entreprise dépendra de vos besoins et de votre budget spécifiques.
Avantages d'Ephesoft
- Le système dispose d'une fonctionnalité de suivi qui permet de suivre les modifications apportées aux documents de l'utilisateur. Cela peut être utile pour prévenir la fraude et garder un œil sur qui a apporté des modifications lorsque plusieurs utilisateurs travaillent sur un document.
- Ephesoft utilise des techniques d'amélioration de la qualité d'image pour extraire les données des images, telles que l'OCR (Optical Character Recognition), la reconnaissance des codes-barres et la reconnaissance des caractères. Cela augmente considérablement la précision de l'extraction des données par rapport aux méthodes manuelles, où les données peuvent ne pas être entièrement exactes ou complètes en raison d'une mauvaise qualité d'image ou d'autres facteurs.
- Prend en charge les documents dans plusieurs langues, telles que l'anglais, l'espagnol, le français, etc., ce qui le rend adapté à toutes les industries avec des bases de clients diverses qui utilisent différentes langues comme principal mode de communication/documentation.
Inconvénients d'Ephesoft
- Il a besoin d'une formation appropriée avant de l'utiliser. Si vous n'avez pas d'expérience préalable avec ce type de logiciel, vous aurez peut-être du mal à l'utiliser efficacement. Cependant, une fois que vous vous y serez habitué, il vous sera très facile d'utiliser ce produit efficacement dans votre environnement professionnel.
- Le logiciel Ephesoft coûte plus cher que d'autres produits similaires sur le marché. L'investissement initial requis pour acheter Ephesoft peut être élevé, mais le coût peut être réduit en optant pour une version cloud [7].
ABBYY contre Hyperscience

Les modèles d'apprentissage automatique exclusifs d'Hyperscience et la puissante technologie de reconnaissance optique de caractères (OCR) offrent une capacité d'extraction de données inégalée pour les formulaires manuscrits, ainsi que d'autres documents structurés et semi-structurés. La plate-forme offre des rapports de performance supérieurs, une assurance qualité intégrée et une extraction de haut niveau pour une capture et une analyse précises et rapides des documents.
ABBYY et Hyperscience proposent des solutions OCR de bureau et basées sur le cloud. Si vous avez besoin d'OCR un grand volume de documents, ABBYY peut être une meilleure option, car vous pourrez les traiter par lots à l'aide de l'application de bureau.
Le moteur OCR d'ABBYY est basé sur l'intelligence artificielle (IA), tandis que le moteur OCR d'Hyperscience est basé sur l'apprentissage automatique (ML). Cela signifie qu'ABBYY peut apprendre et s'améliorer au fil du temps, tandis que Hyperscience produira toujours des résultats cohérents avec ses données de formation. Donc, si vous avez besoin d'un outil OCR capable de s'adapter aux conditions changeantes (par exemple, différentes polices, images de mauvaise qualité, etc.), ABBYY peut être un meilleur choix. Cependant, si vous avez besoin d'un outil OCR qui produira toujours le même niveau de précision élevé, quel que soit le document d'entrée, Hyperscience peut être une meilleure option.
ABBYY vs. Lire

Readiris est un moteur OCR puissant et précis qui peut être utilisé pour convertir des documents et des images numérisés en texte modifiable et interrogeable. Il offre un large éventail de fonctionnalités et d'options, ce qui en fait une solution OCR polyvalente et puissante pour divers besoins.
Readiris est l'une des alternatives populaires à ABBYY FineReader. C'est aussi un programme OCR avec un large éventail de fonctionnalités et de nombreux utilisateurs.
Avantages de Readiris
- Traitement des documents 20 % plus rapide
- Modifiez les textes intégrés dans vos images avec OCR
- Convertir des documents Microsoft Office en PDF
- Annoter et commenter
- Protégez et signez des PDF
- Intégration avec des imprimantes (scanners Twain) [3]
Inconvénients de Readiris
- La tarification peut être coûteuse lorsque vous travaillez avec des données volumineuses.
- La précision peut être faible lorsque vous travaillez avec des données non structurées par rapport à d'autres outils [4]
ABBYY contre Google Cloud Vision

Google Cloud Vision OCR est une solution cloud de reconnaissance de texte et d'analyse d'images. Le service utilise des algorithmes d'apprentissage en profondeur pour traiter des images et des vidéos, reconnaître des objets, des scènes et des visages, ainsi que détecter du texte dans plus de 100 langues.
Avantages de Google Cloud Vision
- Les résultats sont précis et fiables : Google utilise des modèles d'apprentissage en profondeur pour son service OCR, ce qui signifie qu'il en apprend davantage sur la façon dont votre document spécifique est formaté au fil du temps, améliorant ainsi sa précision au fil du temps.
- Il est compatible avec la plupart des types de fichiers : Google Cloud Vision OCR fonctionne avec les fichiers JPEG, PNG, BMP, TIFF, PDF et les GIF animés ! Vous pouvez même convertir des pages HTML en texte brut à l'aide de Google Cloud Vision OCR (bien que tout le formatage ne soit pas conservé).
- C'est facile à utiliser - il vous suffit de télécharger une image contenant le texte que vous souhaitez convertir et de cliquer sur "Créer du texte" dans la console Google Cloud Vision. Vous n'avez pas besoin d'installer de logiciel ni de télécharger de bibliothèques de logiciels.
- Fournit une interface API à intégrer avec un logiciel personnalisé.
Inconvénients de Google Cloud Vision
- Il nécessite une connexion Internet (ce qui signifie que vous ne pouvez pas l'utiliser hors ligne).
- Il est lent à traiter de gros volumes de données. Vous pouvez l'utiliser pour des quantités de texte petites à moyennes, mais si vous souhaitez effectuer de grandes quantités de traitement de texte en mode batch, cette solution peut ne pas être assez rapide pour vos besoins.
- Dans certains cas, comme l'extraction de table, la précision de Google Cloud Vision OCR n'est pas aussi élevée que celle d'autres outils [5].
Vous souhaitez automatiser la saisie de données à partir de documents? La solution OCR basée sur l'IA de Nanonets peut aider à extraire des informations clés de documents structurés / non structurés et à mettre le processus en pilotage automatique!
ABBYY contre les nanonets

Nanonets est un logiciel OCR basé sur l'IA qui automatise la saisie des données en traitement intelligent des factures, reçus, cartes d'identité, etc. Les nanonets utilisent l'OCR avancé, traitement d'images par apprentissage automatique, et Deep Learning pour extraire des informations pertinentes à partir de données non structurées. Il est rapide, précis, facile à utiliser, permet aux utilisateurs de créer des modèles OCR personnalisés à partir de zéro et propose des intégrations Zapier intéressantes. Numérisez des documents, extrayez des champs de données et intégrez-les à vos applications quotidiennes via des API dans une interface simple et intuitive.
Avantages des nanonets
- UI moderne
- Gère de grands volumes de documents
- Prix raisonnable
- Facilité d’utilisation
- Capture cognitive des données – résultant en une intervention minimale
- Ne nécessite aucune équipe interne de développeurs
- L'algorithme / les modèles peuvent être formés / recyclés
- Excellente documentation et assistance
- Beaucoup d'options de personnalisation
- Large choix d'options d'intégration
- Fonctionne avec des langues autres que l'anglais ou plusieurs langues
- Presque aucun post-traitement requis
- Intégration bidirectionnelle transparente avec plusieurs logiciels de comptabilité
- Excellente API OCR pour les développeurs
Inconvénients des nanonets
- Ne peut pas gérer les pics de volume très élevés
- L'interface utilisateur de capture de table peut être meilleure.
Comparez et examinez les tarifs ABBYY
|
Outil |
Équipe de soutien |
Démo |
Prix |
|
|
Adobe Acrobat Pro DC |
Plus de 100 langues |
7 jour(s) |
À partir de 14.99$/mois |
le cloud |
|
LireIRIS |
Plus de 130 langues |
30 jour(s) |
À partir de 129$/mois |
Windows et Mac |
|
ABBY FineReader |
Plus de 198 langues |
7 jour(s) |
117 $ / an |
Windows, iOS, Android et Mac. |
|
Google Cloud Vision |
Plus de 130 langues |
Gratuit |
Version gratuite 1.5 $ pour 1000 XNUMX unités |
Nuage, API |
|
nanonets |
Plus de 100 langues |
Sauvegardes |
Version gratuite Pro : 499 $ / mois |
Nuage, Windows et Mac |
|
Tesseract |
Plus de 120 langues |
Sauvegardes |
Sauvegardes |
Windows |
Pourquoi choisir Nanonets plutôt qu'ABBYY ?
Nanonets est un logiciel OCR qui utilise l'intelligence artificielle pour automatiser l'extraction de tableaux à partir de documents PDF, d'images et de fichiers numérisés. Contrairement à d'autres solutions, il ne nécessite pas de règles et de modèles distincts pour chaque nouveau type de document. Au lieu de cela, il s'appuie sur l'intelligence cognitive pour gérer des documents semi-structurés et invisibles tout en s'améliorant au fil du temps. Vous pouvez également personnaliser la sortie pour extraire uniquement les tables ou les entrées de données qui vous intéressent.
Il est rapide, précis, facile à utiliser, permet aux utilisateurs de créer des modèles OCR personnalisés à partir de zéro et propose des intégrations Zapier intéressantes. Numérisez des documents, extrayez des tableaux ou des champs de données et intégrez-les à vos applications quotidiennes via des API dans une interface simple et intuitive.
Pourquoi Nanonets est-il le meilleur OCR ?
- Les nanonets peuvent extraire des données sur la page tandis que les analyseurs PDF en ligne de commande extraient uniquement des objets, des en-têtes et des métadonnées tels que (titre, pages, état de cryptage, etc.)
- La technologie d'analyse des fichiers PDF de Nanonets n'est pas basée sur des modèles. En plus d'offrir des modèles pré-entraînés pour les cas d'utilisation courants, l'algorithme d'analyse de Nanonets PDF peut également gérer des types de documents invisibles!
- Outre la gestion des documents PDF natifs, les capacités OCR intégrées de Nanonet lui permettent également de gérer les documents numérisés et les images !
- Fonctions d'automatisation robustes avec capacités AI et ML.
- Les nanonets gèrent facilement les données non structurées, les contraintes de données courantes, les documents PDF multipages, les tableaux et les éléments multilignes.
- Nanonets est un outil sans code qui peut continuellement apprendre et se recycler sur des données personnalisées pour fournir des sorties ne nécessitant aucun post-traitement.
Analyse automatisée des factures avec Nanonets - créant des flux de travail de traitement des factures complètement sans contact.
Intégrez vos outils existants aux nanonets et automatisez la collecte de données, le stockage des exportations et la comptabilité.
Les nanonets peuvent également aider à automatiser les workflows d'analyse des factures en :
- Importation et consolidation des données de facturation à partir de plusieurs sources - e-mail, documents numérisés, fichiers/images numériques, stockage dans le cloud, ERP, API, etc.
- Capturer et extraire intelligemment les données de facturation à partir des factures, reçus, factures et autres documents financiers.
- Catégoriser et coder les transactions en fonction des règles métier.
- Configuration de workflows d'approbation automatisés pour obtenir des approbations internes et gérer les exceptions.
- Concilier toutes les transactions.
- Intégration transparente avec les ERP ou les logiciels de comptabilité tels que Quickbooks, Sage, Xero, Netsuite, etc.
Bibliographie
Puis-je reconnaître du texte manuscrit dans ABBYY FineReader ? - Centre d'aide
ABBYY FineReader VS Amazon Textract - comparer les différences et les avis ?
7 meilleurs logiciels OCR de 2022 (gratuits et payants)
Top 10 des logiciels OCR en 2022 | Meilleures solutions OCR
Ephesoft contre FineReader PDF pour Windows et Mac 2022 | G2
21 meilleurs logiciels OCR en 2022
Tesseract OCR en Python avec Pytesseract & OpenCV
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Platoblockchain. Intelligence métaverse Web3. Connaissance Amplifiée. Accéder ici.
- La source: https://nanonets.com/blog/abbyy-reviews-compare-competitors-alternatives/

