De nombreuses organisations dans le monde s'appuient sur l'utilisation d'actifs physiques, tels que des véhicules, pour fournir un service à leurs clients finaux. En suivant ces actifs en temps réel et en stockant les résultats, les propriétaires d'actifs peuvent obtenir des informations précieuses sur la manière dont leurs actifs sont utilisés pour apporter en permanence des améliorations commerciales et planifier les changements futurs. Par exemple, une entreprise de livraison exploitant une flotte de véhicules peut avoir besoin de vérifier l'impact de changements de politique locale indépendants de sa volonté, comme l'expansion annoncée d'un Zone à très faibles émissions (ULEZ). En combinant les données historiques de localisation des véhicules avec des informations provenant d'autres sources, l'entreprise peut concevoir des approches empiriques pour une meilleure prise de décision. Par exemple, l'équipe d'approvisionnement de l'entreprise peut utiliser ces informations pour prendre des décisions sur les véhicules à remplacer en priorité avant que les changements de politique n'entrent en vigueur.
Les développeurs peuvent utiliser le support dans Service de localisation Amazon en publication de mises à jour de position de périphérique à Amazon Event Bridge pour créer un pipeline de données en temps quasi réel qui stocke les emplacements des actifs suivis dans Service de stockage simple Amazon (Amazon S3). De plus, vous pouvez utiliser AWS Lambda pour enrichir les données de localisation entrantes avec des données provenant d'autres sources, telles qu'un Amazon DynamoDB tableau contenant les détails de l’entretien du véhicule. Un analyste de données peut alors utiliser le capacités de requête géospatiale of Amazone Athéna pour obtenir des informations, telles que le nombre de jours pendant lesquels leurs véhicules ont fonctionné dans les limites proposées d'une ULEZ élargie. Étant donné que les véhicules qui ne répondent pas aux normes d'émissions ULEZ sont soumis à des frais quotidiens pour circuler dans la zone, vous pouvez utiliser les données de localisation, ainsi que les données de maintenance telles que l'âge du véhicule, le kilométrage actuel et les normes d'émissions actuelles pour estimer le montant. l'entreprise devrait payer des frais quotidiens.
Cet article montre comment vous pouvez utiliser Amazon Location, EventBridge, Lambda, Amazon Data Firehose, et Amazon S3 pour créer un pipeline de données géolocalisées et utiliser ces données pour générer des informations significatives à l'aide de Colle AWS et Athéna.
Présentation de la solution
Il s'agit d'une solution entièrement sans serveur pour la gestion des actifs basée sur la localisation. La solution se compose des interfaces suivantes :
- IoT ou application mobile – Une application mobile ou un appareil Internet des objets (IoT) permet le suivi d'un véhicule de société pendant son utilisation et transmet en toute sécurité sa position actuelle à la couche d'ingestion de données dans AWS. L’approche d’ingestion n’entre pas dans le cadre de cet article. Au lieu de cela, une fonction Lambda de notre solution simule des exemples de trajets en véhicule et met directement à jour les objets de suivi Amazon Location avec des emplacements aléatoires.
- L'analyse des données – Les analystes commerciaux rassemblent des informations opérationnelles à partir de plusieurs sources de données, y compris les données de localisation collectées à partir des véhicules. Les analystes de données recherchent des réponses à des questions telles que : « Combien de temps un véhicule donné a-t-il passé historiquement à l'intérieur d'une zone proposée et combien auraient coûté les frais si la politique avait été en place au cours des 12 derniers mois ? »
Le diagramme suivant illustre l'architecture de la solution.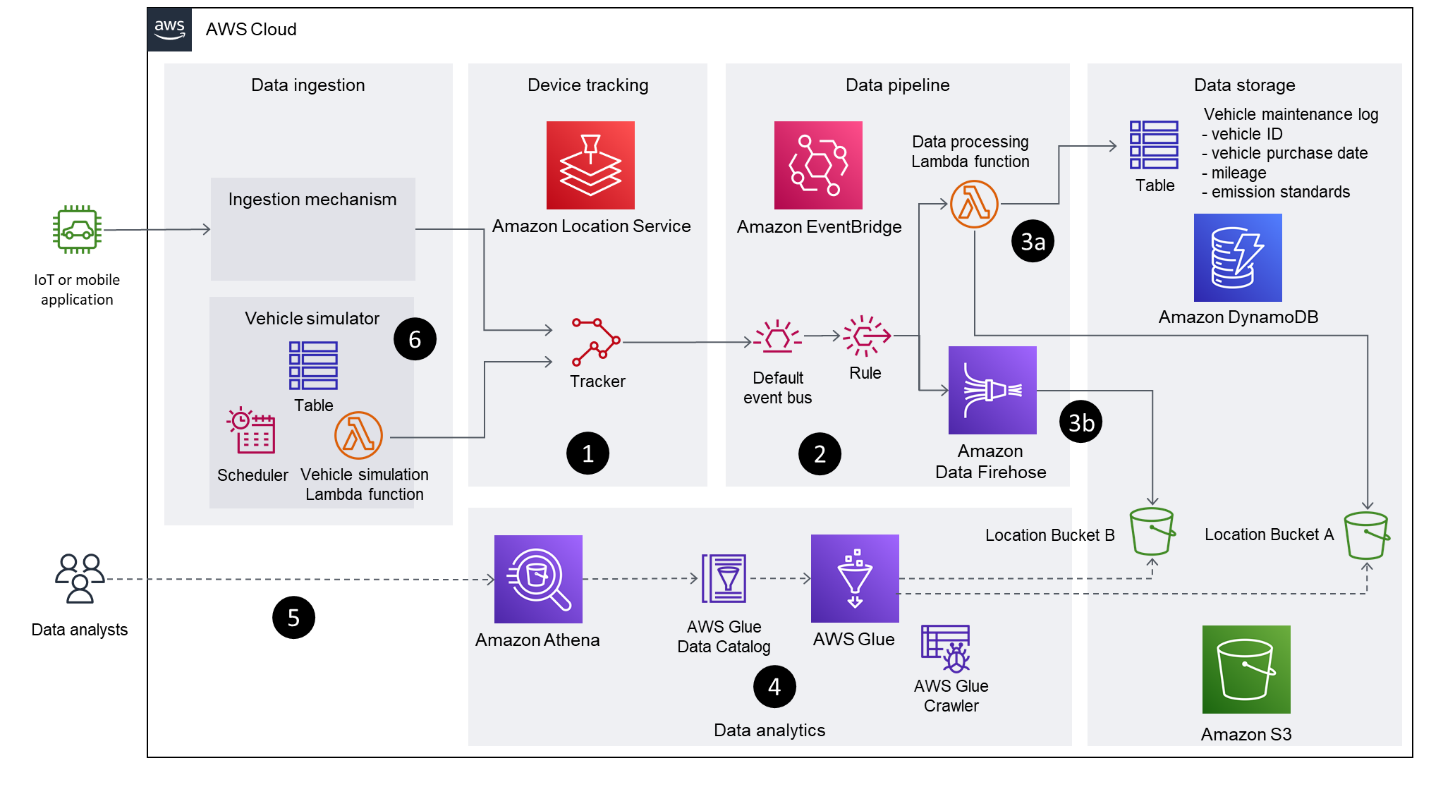
Le flux de travail comprend les étapes clés suivantes :
- La fonctionnalité de suivi d'Amazon Location est utilisée pour suivre le véhicule. Grâce à l'intégration EventBridge, les mises à jour de position filtrées sont publiées sur un bus d'événements EventBridge. Cette solution utilise basé sur la distance filtrage pour réduire les coûts et la gigue. Le filtrage basé sur la distance ignore les mises à jour de localisation dans lesquelles les appareils se sont déplacés de moins de 30 mètres (98.4 pieds).
- Les événements de position de l'appareil Amazon Location arrivent sur EventBridge
defaultautobus avecsource: ["aws.geo"]ainsi quedetail-type: ["Location Device Position Event"]. Une règle est créée pour transmettre ces événements à deux cibles en aval : une fonction Lambda et un flux de diffusion Firehose. - Deux modèles différents, basés sur chaque cible, sont décrits dans cet article pour démontrer différentes approches pour valider les données dans un compartiment S3 :
- Fonction Lambda – La première approche utilise une fonction Lambda pour démontrer comment utiliser le code dans le pipeline de données pour transformer directement les données de localisation entrantes. Vous pouvez modifier la fonction Lambda pour extraire des informations supplémentaires sur le véhicule à partir d'un magasin de données distinct (par exemple, une table DynamoDB ou un système de gestion de la relation client) afin d'enrichir les données, avant de stocker les résultats dans un compartiment S3. Dans ce modèle, la fonction Lambda est invoquée pour chaque événement entrant.
- Flux de livraison de lances à incendie – La deuxième approche utilise un flux de livraison Firehose pour mettre en mémoire tampon et regrouper les mises à jour de position entrantes, avant de les stocker dans un compartiment S3 sans modification. Cette méthode utilise la compression GZIP pour optimiser la consommation de stockage et les performances des requêtes. Vous pouvez également utiliser le transformation de données fonctionnalité de Data Firehose pour appeler une fonction Lambda pour effectuer une transformation de données par lots.
- AWS Glue analyse les deux chemins de compartiment S3, remplit les tables de base de données AWS Glue en fonction des schémas déduits et met les données à la disposition d'autres applications d'analyse via le catalogue de données AWS Glue.
- Athena est utilisé pour exécuter des requêtes géospatiales sur les données de localisation stockées dans les compartiments S3. Le catalogue de données fournit des métadonnées qui permettent aux applications d'analyse utilisant Athena de rechercher, lire et traiter les données de localisation stockées dans Amazon S3.
- Cette solution comprend une fonction Lambda qui met à jour en permanence le tracker Amazon Location avec des données de localisation simulées provenant de trajets fictifs. La fonction Lambda est déclenchée à intervalles réguliers à l'aide d'une règle EventBridge planifiée.
Vous pouvez tester cette solution vous-même en utilisant le Dépôt d'exemples AWS GitHub. Le référentiel contient le Modèle d'application sans serveur AWS (AWS SAM) et code Lambda requis pour essayer cette solution. Reportez-vous aux instructions dans le README fichier pour connaître les étapes à suivre pour provisionner et mettre hors service cette solution.
Les dispositions visuelles de certaines captures d'écran de cet article peuvent être différentes de celles de votre Console de gestion AWS.
Génération de données
Dans cette section, nous discutons des étapes pour générer manuellement ou automatiquement des données de voyage.
Générer manuellement des données de trajet
Vous pouvez mettre à jour manuellement les positions des appareils à l'aide du Interface de ligne de commande AWS (AWS CLI) commande aws location batch-update-device-position. Remplace le tracker-name, device-id, Positionet SampleTime valeurs avec les vôtres, et assurez-vous que les mises à jour successives sont espacées de plus de 30 mètres pour placer un événement sur le default Bus d'événements EventBridge :
Générez automatiquement des données de trajet à l'aide du simulateur
Le fourni AWS CloudFormation Le modèle déploie une règle planifiée EventBridge et une fonction Lambda qui simule les mises à jour du tracker des véhicules. Cette règle est activée par défaut et s'exécute à une fréquence spécifiée par le SimulationIntervalMinutes Paramètre CloudFormation. La fonction Lambda de génération de données met à jour le tracker Amazon Location avec un décalage de position aléatoire par rapport aux emplacements de base des véhicules.
Les noms des véhicules et les emplacements de base sont stockés dans le véhicules.json déposer. La position de départ d'un véhicule est réinitialisée chaque jour et les emplacements de base ont été choisis pour leur donner la possibilité d'entrer et de sortir de l'ULEZ un jour donné afin de fournir une simulation de voyage réaliste.
Vous pouvez désactiver la règle temporairement en accédant aux détails des règles planifiées sur la console EventBridge. Vous pouvez également modifier le paramètre State: ENABLED à State: DISABLED pour la ressource de règle planifiée GenerateDevicePositionsScheduleRule dans l' modèle.yml déposer. Reconstruisez et redéployez le modèle AWS SAM pour que cette modification prenne effet.
Approches du pipeline de données de localisation
Les configurations décrites dans cette section sont déployées automatiquement par le modèle AWS SAM fourni. Les informations contenues dans cette section sont fournies pour décrire les parties pertinentes de la solution.
Événements de position de l'appareil Amazon Location
Amazon Location envoie les événements de mise à jour de la position de l'appareil à EventBridge au format suivant :
Vous pouvez éventuellement spécifier un transformation d'entrée pour modifier le format et le contenu des données d'événement de position de l'appareil avant qu'elles n'atteignent la cible.
Enrichissement des données avec Lambda
L'enrichissement des données dans ce modèle est facilité grâce à l'invocation d'une fonction Lambda. Dans cet exemple, nous appelons cette fonction ProcessDevicePositionet utilisez un runtime Python. Une transformation personnalisée est appliquée dans la définition de cible EventBridge pour recevoir les données d'événement au format suivant :
Vous pouvez appliquer des transformations supplémentaires, telles que la refactorisation de Latitude ainsi que Longitude données en paires clé-valeur distinctes si cela est requis par la logique métier en aval traitant les événements.
Le code suivant illustre la logique d'application Python exécutée par le ProcessDevicePosition Fonction Lambda. La gestion des erreurs a été ignorée dans cet extrait de code par souci de concision. Le code complet est disponible dans le GitHub repo.
Le code précédent crée un objet S3 pour chaque événement de position de périphérique reçu par EventBridge. Le code utilise le DeviceId comme préfixe pour écrire les objets dans le bucket.
Vous pouvez ajouter une logique supplémentaire au code de fonction Lambda précédent pour enrichir les données d'événement à l'aide d'autres sources. L'exemple dans le GitHub repo montre l'enrichissement de l'événement avec les données d'une table de maintenance de véhicule DynamoDB.
En plus du prérequis Gestion des identités et des accès AWS (IAM) autorisations fournies par le rôle AWSBasicLambdaExecutionRole, ProcessDevicePosition la fonction nécessite des autorisations pour exécuter le S3 put_object action et toute autre action requise par la logique d’enrichissement des données. Les autorisations IAM requises par la solution sont documentées dans le modèle.yml fichier.
Pipeline de données utilisant Amazon Data Firehose
Suivez les étapes suivantes pour créer votre flux de diffusion Firehose :
- Sur la console Amazon Data Firehose, choisissez Flux de lance à incendie dans le volet de navigation.
- Selectionnez Créer un flux Firehose.
- Pour Identifier, choisissez comme PUT direct.
- Pour dentaire, choisissez Amazon S3.
- Pour Nom du flux Firehose, entrez un nom (pour ce message,
ProcessDevicePositionFirehose).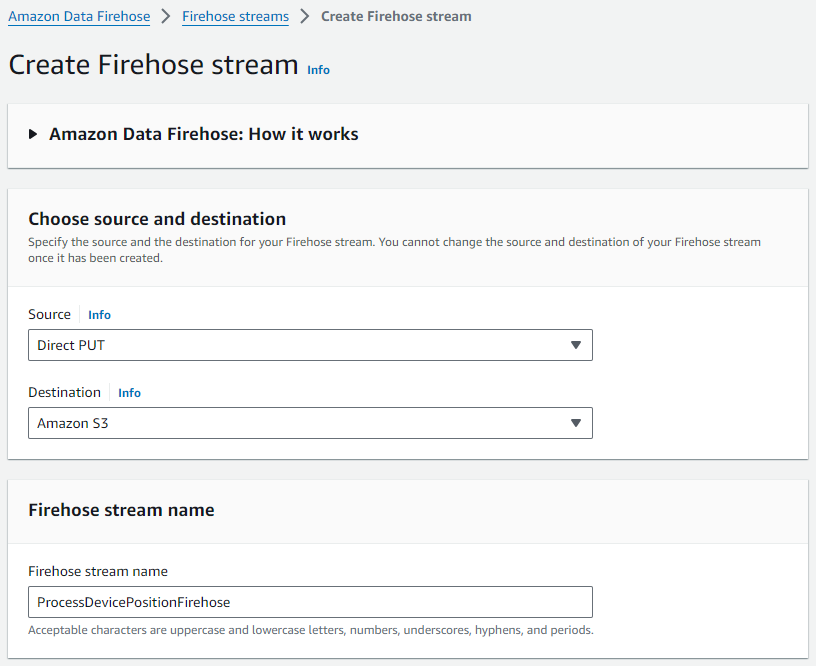
- Configurez les paramètres de destination avec des détails sur le compartiment S3 dans lequel les données de localisation sont stockées, ainsi que la stratégie de partitionnement :
- Utilisez ainsi que pour déterminer les préfixes du compartiment et de l'objet.
- Utilisez
DeviceIdcomme préfixe supplémentaire pour écrire les objets dans le compartiment.
- Activer Partitionnement dynamique ainsi que Nouveau délimiteur de ligne pour vous assurer que le partitionnement est automatique en fonction de
DeviceId, et que de nouveaux délimiteurs de ligne sont ajoutés entre les enregistrements dans les objets livrés à Amazon S3.
Ceux-ci sont requis par AWS Glue pour analyser ultérieurement les données et pour qu'Athena reconnaisse les enregistrements individuels.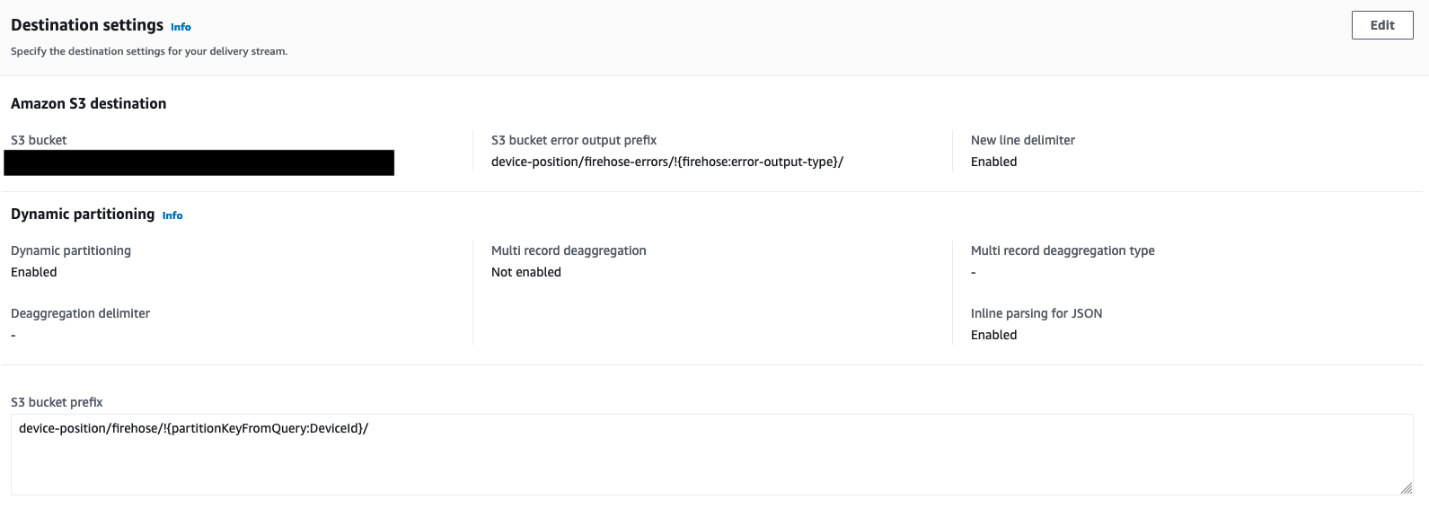
Créer une règle EventBridge et attacher des cibles
La règle EventBridge ProcessDevicePosition définit deux cibles : la ProcessDevicePosition Fonction Lambda, et le ProcessDevicePositionFirehose flux de livraison. Effectuez les étapes suivantes pour créer la règle et attacher des cibles :
- Sur la console EventBridge, créez une nouvelle règle.
- Pour Nom, entrez un nom (pour ce message,
ProcessDevicePosition). - Pour Bus événementiel¸ choisissez défaut.
- Pour Type de règlesélectionner Règle avec un modèle d'événement.
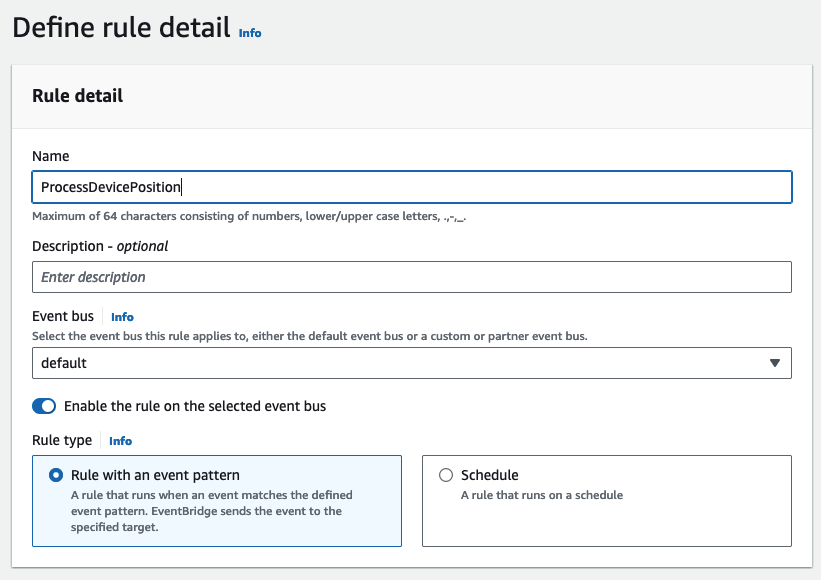
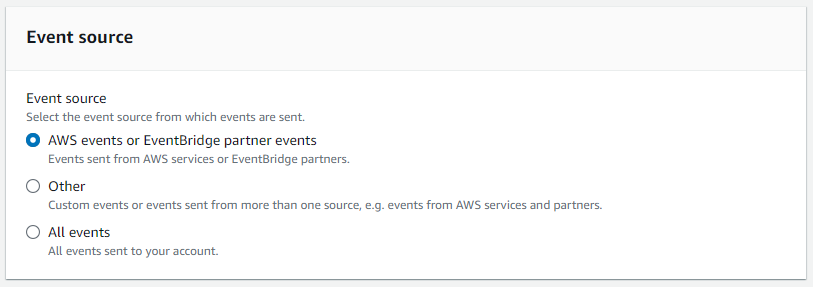
- Pour Source de l'événement, sélectionnez Événements AWS ou événements partenaires EventBridge.
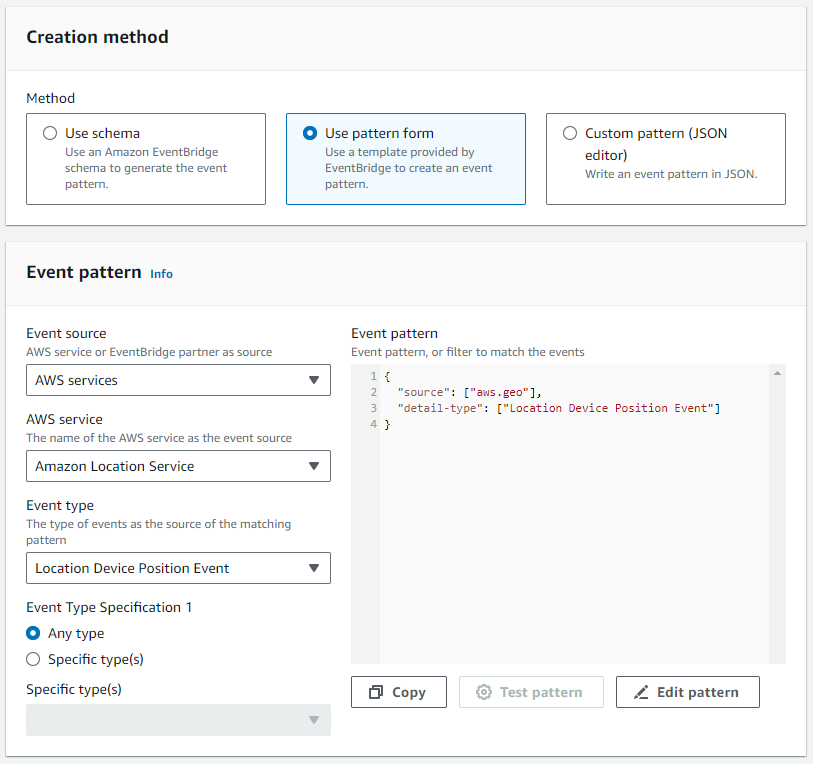
- Pour Method , sélectionnez Utiliser le formulaire de modèle.
- Dans le Modèle d'événement section, précisez Services AWS comme source, Service de localisation Amazon comme service spécifique, et Événement de position du périphérique de localisation comme type d'événement.
- Pour Cible 1, attachez le
ProcessDevicePositionFonction Lambda comme cible.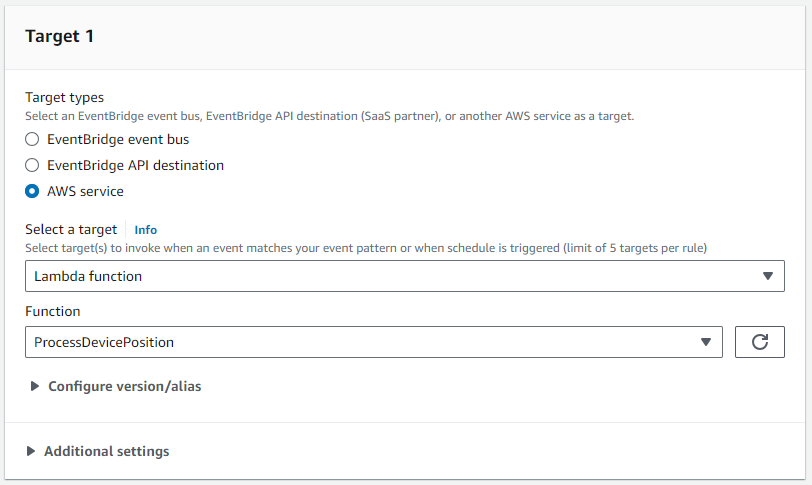
- Nous utilisons Transformateur d'entrée pour personnaliser l'événement validé dans le compartiment S3.
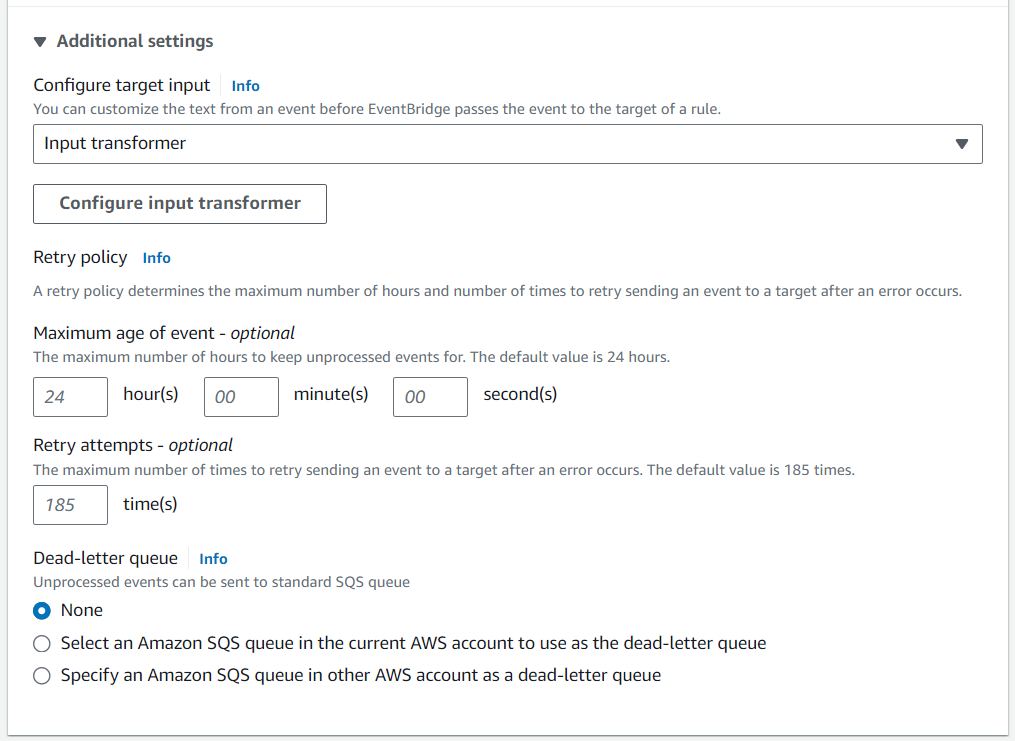
- Configurer Carte des chemins d'entrée ainsi que Modèle de saisie pour organiser la charge utile dans le format souhaité.
- Le code suivant est la carte des chemins d'entrée :
- Le code suivant est le modèle d'entrée :
- Pour Cible 2, choisir la
ProcessDevicePositionFirehoseflux de livraison comme cible.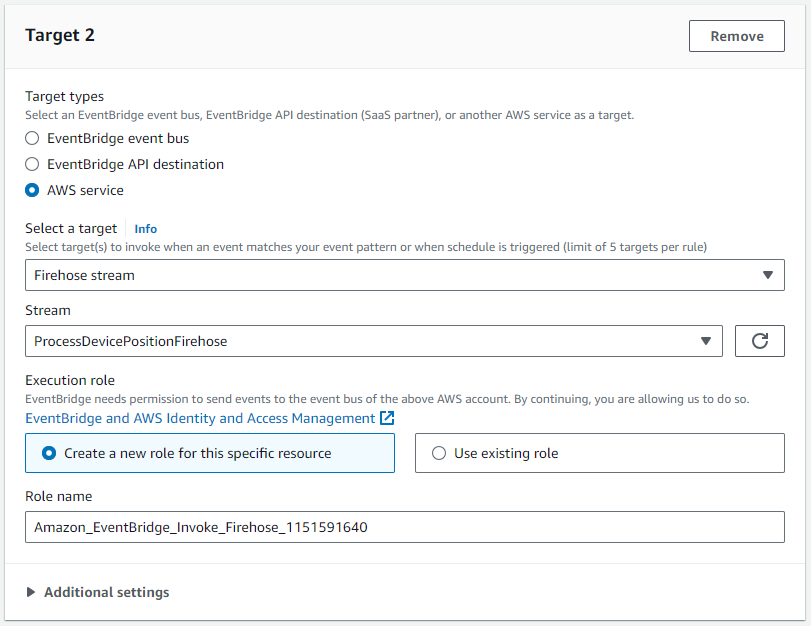
Cette cible nécessite un rôle IAM qui permet d'écrire un ou plusieurs enregistrements dans le flux de diffusion Firehose :
Explorez et cataloguez les données à l'aide d'AWS Glue
Une fois que suffisamment de données ont été générées, procédez comme suit :
- Sur la console AWS Glue, choisissez Rampeurs dans le volet de navigation.
- Sélectionnez les robots qui ont été créés,
location-analytics-glue-crawler-lambdaainsi quelocation-analytics-glue-crawler-firehose. - Selectionnez Courir.
Les robots d'exploration classeront automatiquement les données au format JSON, regrouperont les enregistrements dans des tables et des partitions et valideront les métadonnées associées dans le catalogue de données AWS Glue.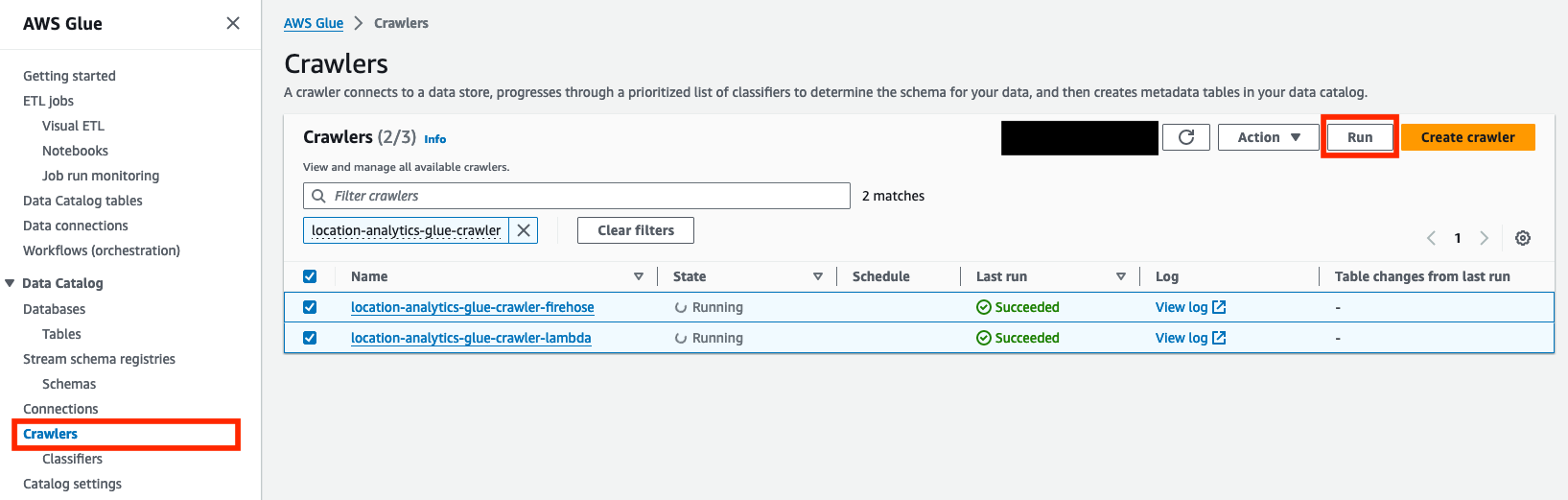
- When the Dernier tour les statuts des deux robots s'affichent comme suit : Réussi, confirmez que deux tables (
lambdaainsi quefirehose) ont été créés sur le Tables .
La solution partitionne les données de localisation entrantes en fonction du deviceid champ. Par conséquent, tant qu’il n’y a pas de nouveaux appareils ou de modifications de schéma, les robots d’exploration n’ont pas besoin de s’exécuter à nouveau. Cependant, si de nouveaux périphériques sont ajoutés ou si un champ différent est utilisé pour le partitionnement, les robots d'exploration doivent être réexécutés.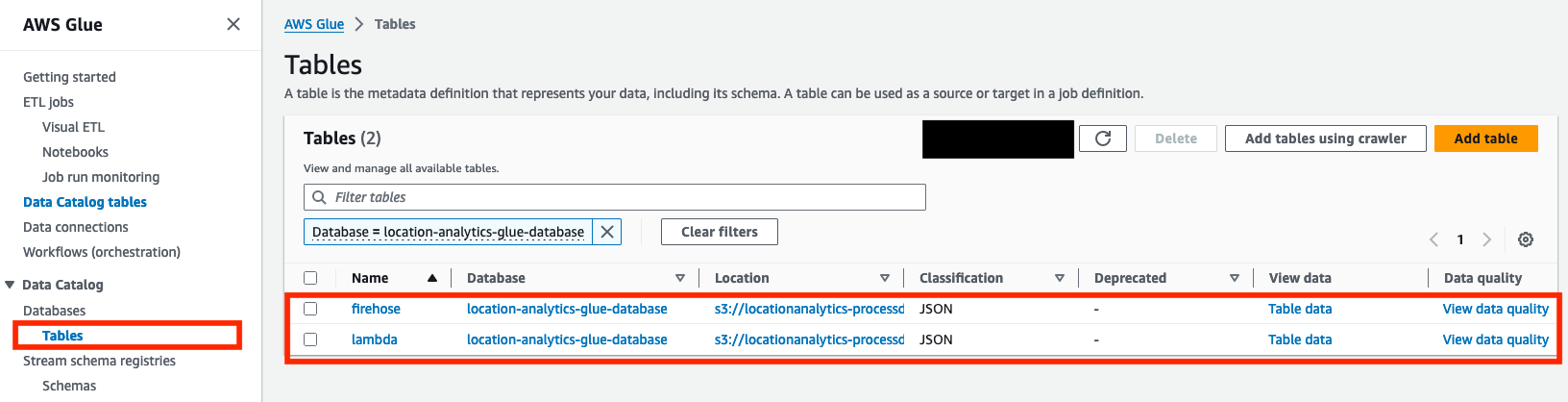
Vous êtes maintenant prêt à interroger les tables à l'aide d'Athena.
Interroger les données à l'aide d'Athena
Athena est un service d'analyse interactif sans serveur conçu pour analyser les données non structurées, semi-structurées et structurées là où elles sont hébergées. Si c'est la première fois que vous utilisez la console Athena, Suivez les instructions pour configurer un emplacement de résultat de requête dans Amazon S3. Pour interroger les données avec Athena, procédez comme suit :
- Sur la console Athena, ouvrez l'éditeur de requête.
- Pour La source de données, choisissez
AwsDataCatalog. - Pour Base de données, choisissez
location-analytics-glue-database. - Dans le menu des options (trois points verticaux), choisissez Aperçu du tableau pour interroger le contenu des deux tables.
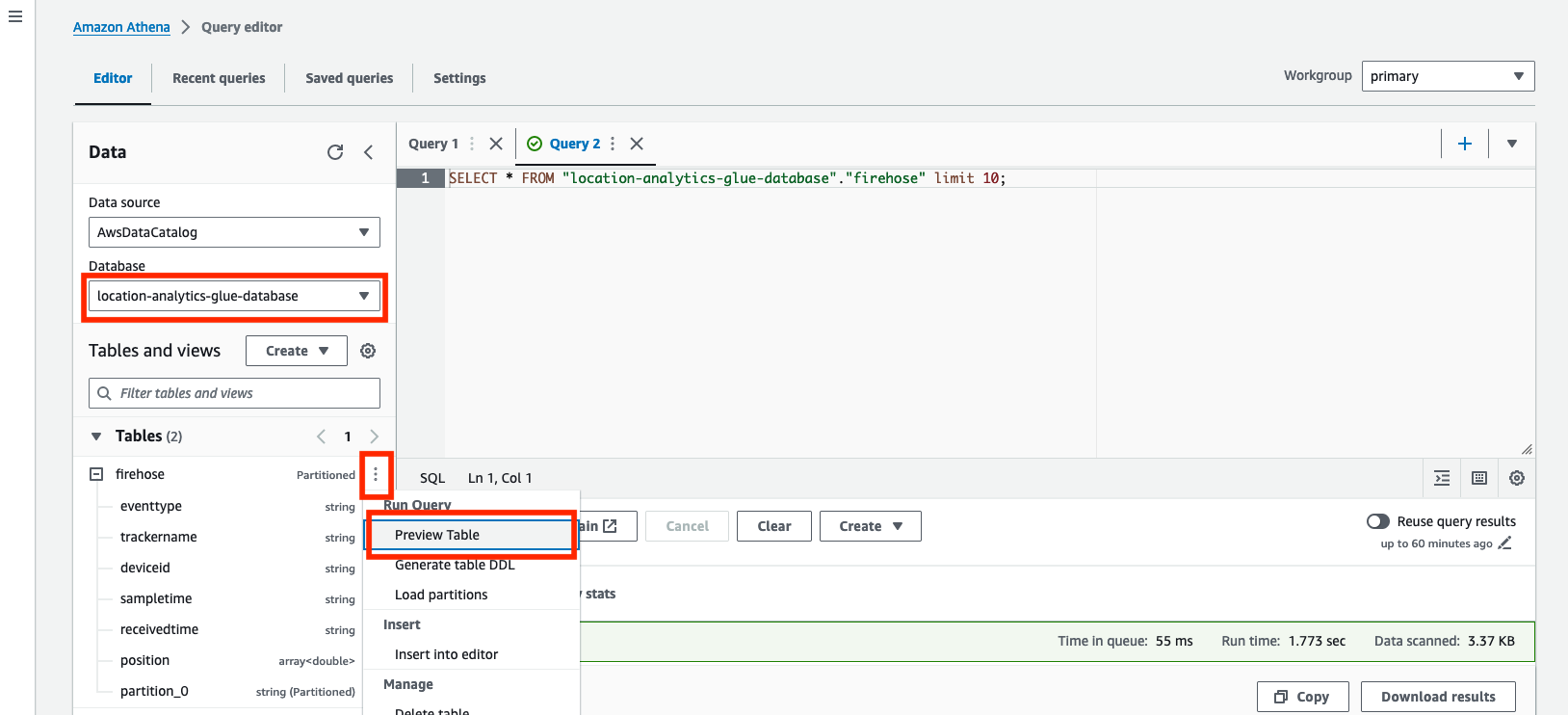
La requête affiche 10 exemples d'enregistrements de position actuellement stockés dans la table. La capture d'écran suivante est un exemple de prévisualisation du firehose tableau. le firehose La table stocke les données brutes et non modifiées du tracker Amazon Location.
Vous pouvez désormais expérimenter des requêtes géospatiales. Fichier GeoJSON pour l'extension ULEZ de Londres 2021 fait partie du référentiel et a déjà été converti en une requête compatible avec les deux tables Athena.
- Copiez et collez le contenu du 1-firehose-athena-ulez-2021-create-view.sql fichier trouvé dans le
examples/firehosedossier dans l’éditeur de requêtes.
Cette requête utilise le ST_Within fonction géospatiale pour déterminer si une position enregistrée se trouve à l'intérieur ou à l'extérieur de la zone ULEZ définie par le polygone. Une nouvelle vue appelée ulezvehicleanalysis_firehose est créé avec une nouvelle colonne, insidezone, qui indique si la position enregistrée existe dans la zone.
Un Python simple utilitaire est fourni, qui convertit les entités surfaciques trouvées dans le fichier GeoJSON téléchargé en ST_Polygon chaînes basées sur le format de texte bien connu qui peut être utilisé directement dans une requête Athena.
- Selectionnez Vue d'aperçu sur le
ulezvehicleanalysis_firehosevue pour explorer son contenu.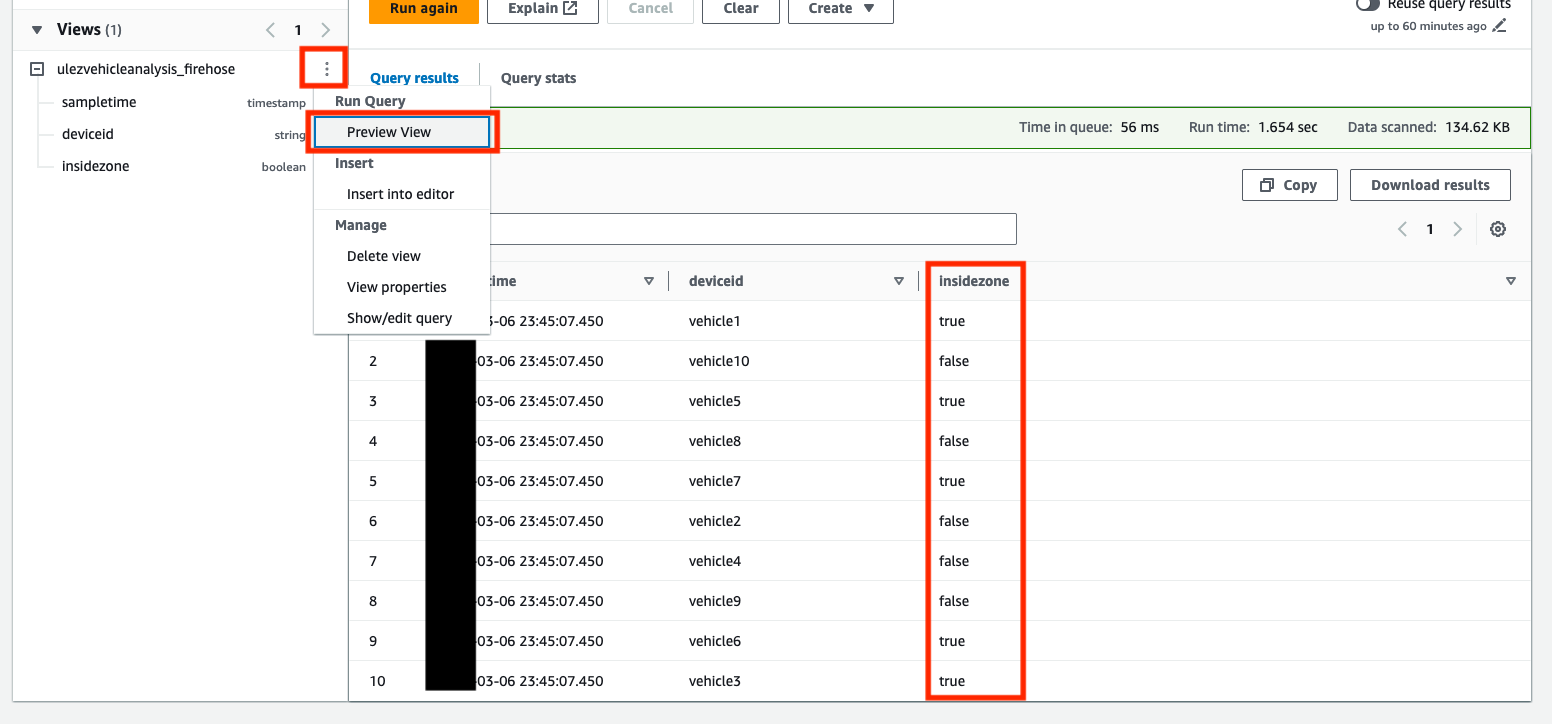
Vous pouvez désormais exécuter des requêtes sur cette vue pour obtenir des informations globales.
- Copiez et collez le contenu du 2-firehose-athena-ulez-2021-query-days-in-zone.sql fichier trouvé dans le
examples/firehosedossier dans l’éditeur de requêtes.
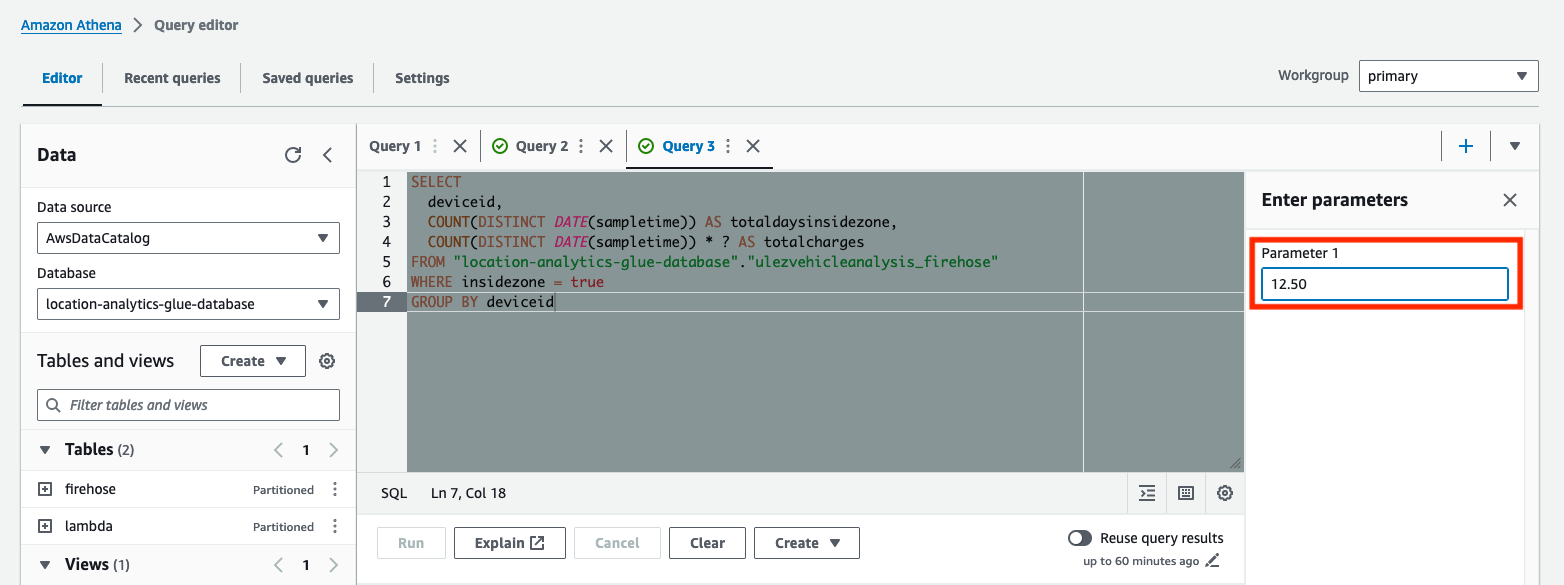
Cette requête établit le nombre total de jours pendant lesquels chaque véhicule est entré dans ULEZ et quel serait le total des frais attendus. La requête a été paramétrée à l'aide du ? caractère d'espace réservé. Requêtes paramétrées vous permettent de réexécuter la même requête avec des valeurs de paramètres différentes.
- Saisissez le montant des frais quotidiens pour Paramètre 1, puis exécutez la requête.
Les résultats affichent chaque véhicule, le nombre total de jours passés dans l'ULEZ proposée et le total des frais en fonction du tarif journalier que vous avez saisi.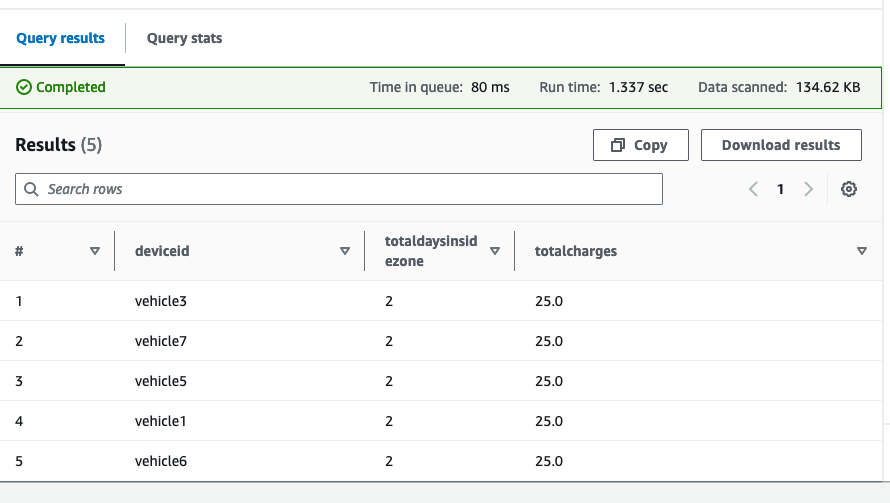
Vous pouvez répéter cet exercice en utilisant le lambda tableau. Les données dans le lambda La table est complétée par des détails supplémentaires sur le véhicule présents dans la table DynamoDB de maintenance du véhicule au moment où elle est traitée par la fonction Lambda. La solution prend en charge les champs suivants :
MeetsEmissionStandards(Booléen)Mileage(Numéro)PurchaseDate(Chaîne, dansYYYY-MM-DDformat)
Vous pouvez également enrichir les nouvelles données au fur et à mesure de leur arrivée.
- Sur la console DynamoDB, recherchez le tableau de maintenance du véhicule sous Tables. Le nom de la table est fourni en sortie
VehicleMaintenanceDynamoTabledans la pile CloudFormation déployée. - Selectionnez Explorer les éléments de table pour visualiser le contenu du tableau.
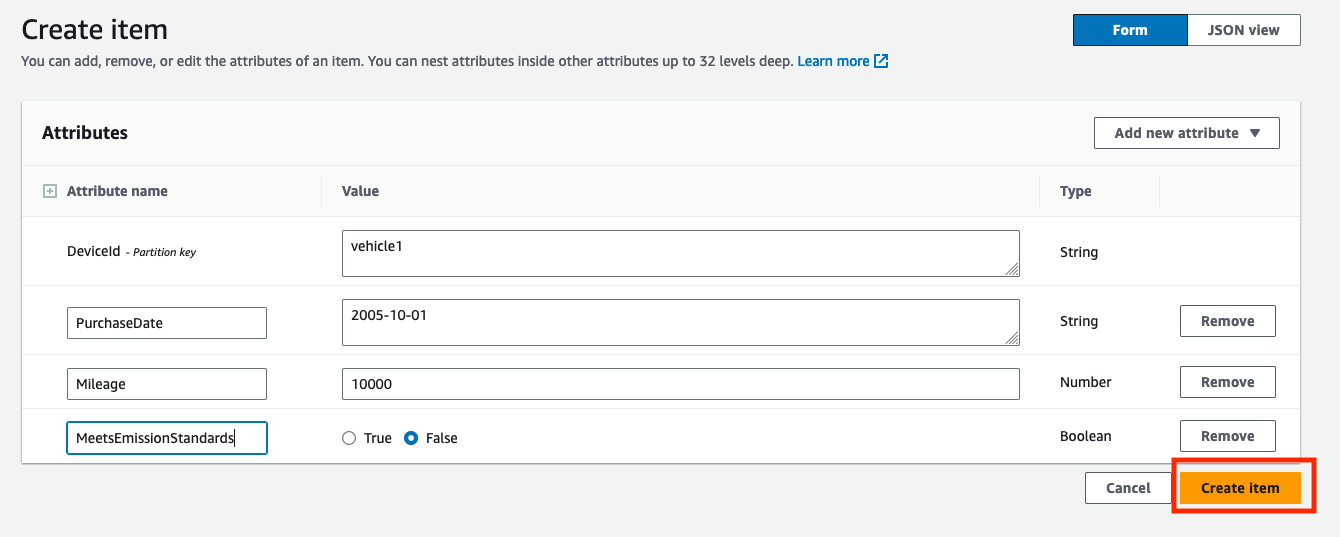
- Selectionnez Créer un article pour créer un nouvel enregistrement pour un véhicule.

- Entrer
DeviceId(Tels quevehicle1comme une chaîne),PurchaseDate(Tels que2005-10-01comme une chaîne),Mileage(Tels que10000sous forme de nombre), etMeetsEmissionStandards(avec une valeur telle queFalsecomme booléen). - Selectionnez Créer un article pour créer l'enregistrement.
- Dupliquez l'enregistrement nouvellement créé avec des entrées supplémentaires pour d'autres véhicules (par exemple pour
vehicle2orvehicle3), en modifiant légèrement les valeurs des attributs à chaque fois. - Réexécutez le
location-analytics-glue-crawler-lambdaAnalyseur AWS Glue après la génération de nouvelles données pour confirmer que la mise à jour du schéma avec les nouveaux champs est enregistrée. - Copiez et collez le contenu du 1-lambda-athena-ulez-2021-create-view.sql fichier trouvé dans le
examples/lambdadossier dans l’éditeur de requêtes. - Aperçu du
ulezvehicleanalysis_lambdavue pour confirmer que les nouvelles colonnes ont été créées.
Si des erreurs telles que Column 'mileage' cannot be resolved s'affichent, l'enrichissement des données n'a pas lieu ou le robot d'exploration AWS Glue n'a pas encore détecté les mises à jour du schéma.
Si la Option de prévisualisation du tableau renvoie uniquement les résultats antérieurs à la création des enregistrements dans la table DynamoDB, renvoyez les résultats de la requête par ordre décroissant en utilisant sampletime (par exemple, order by sampletime desc limit 100;).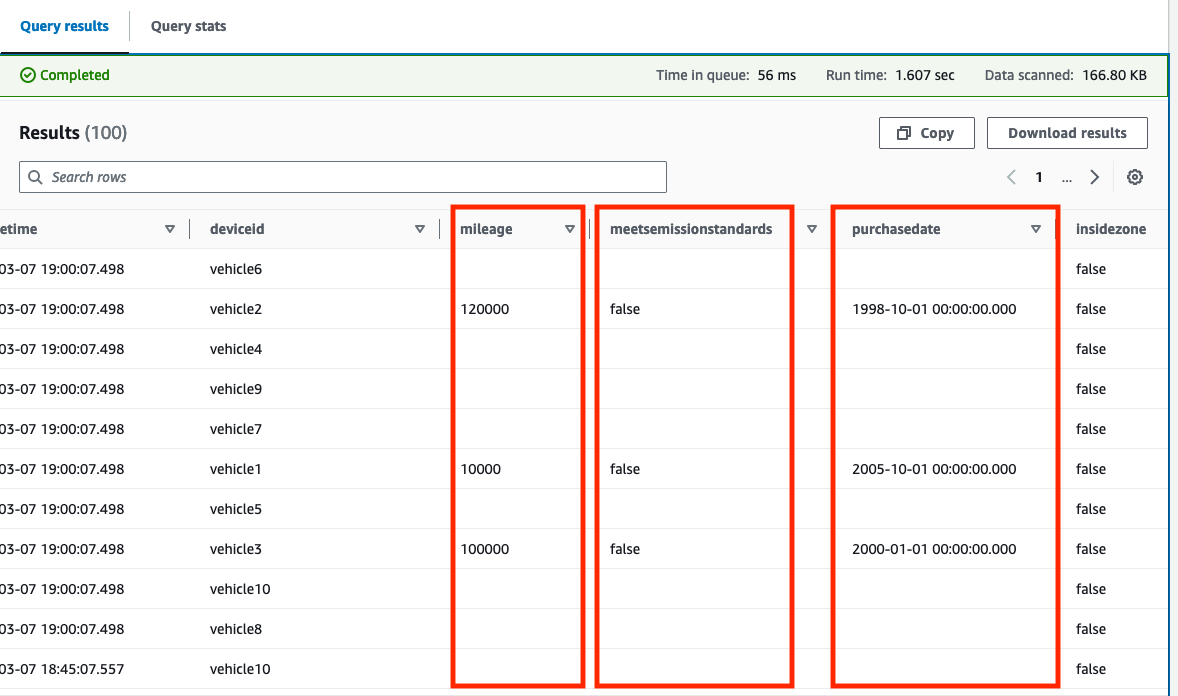
Nous nous concentrons désormais sur les véhicules qui ne répondent pas actuellement aux normes d'émissions et classons les véhicules par ordre décroissant en fonction du kilométrage annuel (calculé en utilisant le dernier kilométrage/âge du véhicule en années).
- Copiez et collez le contenu du 2-lambda-athena-ulez-2021-query-days-in-zone.sql fichier trouvé dans le
examples/lambdadossier dans l’éditeur de requêtes.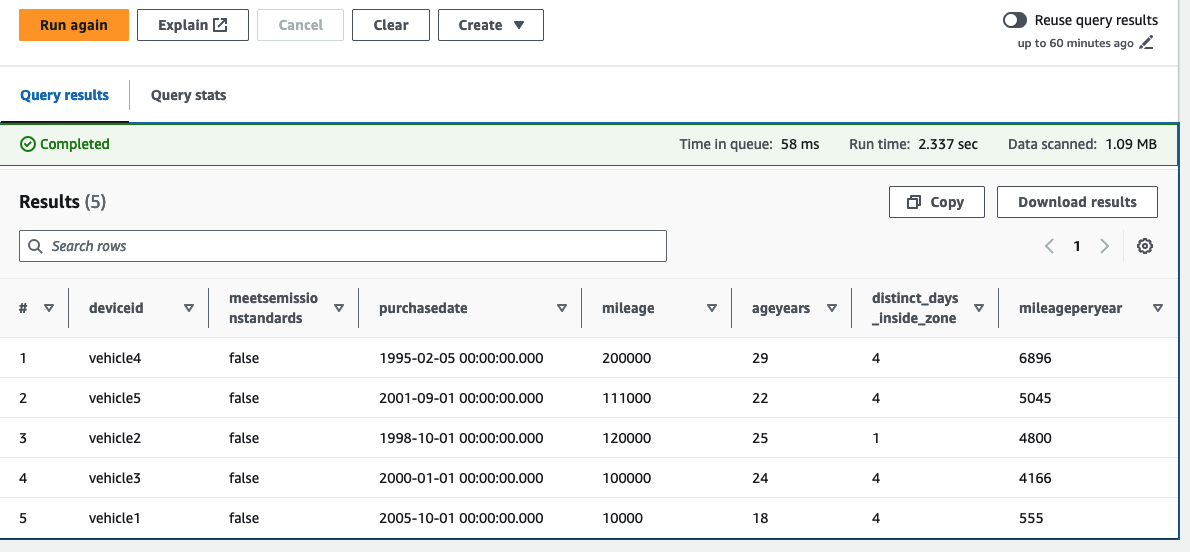
Dans cet exemple, nous pouvons voir que parmi notre flotte de véhicules, cinq ne respectent pas les normes d’émission. Nous pouvons également voir les véhicules qui ont accumulé un kilométrage élevé par an, et le nombre de jours passés dans l'ULEZ proposé. L’exploitant de la flotte peut désormais décider de donner la priorité au remplacement de ces véhicules. Étant donné que les données de localisation sont enrichies avec les données d'entretien du véhicule les plus récentes au moment de leur ingération, vous pouvez faire évoluer ces requêtes pour qu'elles s'exécutent sur une fenêtre de temps définie. Par exemple, vous pouvez prendre en compte les changements de kilométrage au cours de la dernière année.
En raison de la nature dynamique de l'enrichissement des données, toutes les nouvelles données validées dans Amazon S3, ainsi que les résultats de la requête, seront modifiés au fur et à mesure que les enregistrements seront mis à jour dans la table de maintenance des véhicules DynamoDB.
Nettoyer
Reportez-vous aux instructions dans le README fichier pour nettoyer les ressources provisionnées pour cette solution.
Conclusion
Cet article montre comment vous pouvez utiliser Amazon Location, EventBridge, Lambda, Amazon Data Firehose et Amazon S3 pour créer un pipeline de données géolocalisées et utiliser les données de position des appareils collectées pour générer des informations analytiques à l'aide d'AWS Glue et Athena. En suivant ces actifs en temps réel et en stockant les résultats, les entreprises peuvent obtenir des informations précieuses sur l'efficacité de l'utilisation de leurs flottes et mieux réagir aux changements à venir. Vous pouvez maintenant explorer l’extension de cet exemple de code avec vos propres exigences en matière de données de suivi et d’analyse de votre appareil.
À propos des auteurs
 Alan Tourbé est architecte de solutions partenaire senior chez AWS. Alan aide les intégrateurs de systèmes mondiaux (GSI) et les fournisseurs mondiaux de logiciels indépendants (GISV) à résoudre les défis complexes des clients à l'aide des services AWS. Avant de rejoindre AWS, Alan a travaillé comme architecte chez des intégrateurs de systèmes pour traduire les exigences commerciales en solutions techniques. En dehors du travail, Alan est un passionné de l'IoT et un coureur passionné qui adore parcourir les sentiers boueux de la campagne anglaise.
Alan Tourbé est architecte de solutions partenaire senior chez AWS. Alan aide les intégrateurs de systèmes mondiaux (GSI) et les fournisseurs mondiaux de logiciels indépendants (GISV) à résoudre les défis complexes des clients à l'aide des services AWS. Avant de rejoindre AWS, Alan a travaillé comme architecte chez des intégrateurs de systèmes pour traduire les exigences commerciales en solutions techniques. En dehors du travail, Alan est un passionné de l'IoT et un coureur passionné qui adore parcourir les sentiers boueux de la campagne anglaise.
 Parag Srivastava est architecte de solutions chez AWS, aidant les entreprises clientes à réussir leur adoption et leur migration vers le cloud. Au cours de son parcours professionnel, il a été largement impliqué dans des projets complexes de transformation numérique. Il est également passionné par la construction de solutions innovantes autour des aspects géospatiaux des adresses.
Parag Srivastava est architecte de solutions chez AWS, aidant les entreprises clientes à réussir leur adoption et leur migration vers le cloud. Au cours de son parcours professionnel, il a été largement impliqué dans des projets complexes de transformation numérique. Il est également passionné par la construction de solutions innovantes autour des aspects géospatiaux des adresses.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/gain-insights-from-historical-location-data-using-amazon-location-service-and-aws-analytics-services/

