Avec Bases de connaissances pour Amazon Bedrock, vous pouvez connecter en toute sécurité des modèles de fondation (FM) dans Socle amazonien aux données de votre entreprise pour la génération augmentée de récupération (RAG). L'accès à des données supplémentaires aide le modèle à générer des réponses plus pertinentes, plus spécifiques au contexte et plus précises sans recycler les FM.
Dans cet article, nous discutons de deux nouvelles fonctionnalités des bases de connaissances pour Amazon Bedrock spécifiques au RetrieveAndGenerate API : configuration du nombre maximum de résultats et création d'invites personnalisées avec un modèle d'invite de base de connaissances. Vous pouvez désormais les choisir comme options de requête à côté du type de recherche.
Présentation et avantages des nouvelles fonctionnalités
L'option du nombre maximum de résultats vous permet de contrôler le nombre de résultats de recherche à récupérer du magasin de vecteurs et à transmettre au FM pour générer la réponse. Cela vous permet de personnaliser la quantité d'informations générales fournies pour la génération, donnant ainsi plus de contexte pour les questions complexes ou moins pour les questions plus simples. Il vous permet de récupérer jusqu'à 100 résultats. Cette option contribue à améliorer la probabilité d'un contexte pertinent, améliorant ainsi la précision et réduisant l'hallucination de la réponse générée.
Le modèle d'invite de base de connaissances personnalisé vous permet de remplacer le modèle d'invite par défaut par le vôtre afin de personnaliser l'invite envoyée au modèle pour la génération de réponses. Cela vous permet de personnaliser la tonalité, le format de sortie et le comportement du FM lorsqu'il répond à la question d'un utilisateur. Avec cette option, vous pouvez affiner la terminologie pour mieux correspondre à votre secteur ou domaine (comme la santé ou le droit). De plus, vous pouvez ajouter des instructions personnalisées et des exemples adaptés à vos flux de travail spécifiques.
Dans les sections suivantes, nous expliquons comment utiliser ces fonctionnalités avec le Console de gestion AWS ou SDK.
Pré-requis
Pour suivre ces exemples, vous devez disposer d’une base de connaissances existante. Pour obtenir des instructions pour en créer un, voir Créer une base de connaissances.
Configurer le nombre maximum de résultats à l'aide de la console
Pour utiliser l'option du nombre maximum de résultats à l'aide de la console, procédez comme suit :
- Sur la console Amazon Bedrock, choisissez Bases de connaissances dans le volet de navigation de gauche.
- Sélectionnez la base de connaissances que vous avez créée.
- Selectionnez Tester la base de connaissances.
- Choisissez l'icône de configuration.
- Selectionnez Synchroniser la source de données avant de commencer à tester votre base de connaissances.

- Sous Configurations, Pour Type de recherche, sélectionnez un type de recherche en fonction de votre cas d'utilisation.
Pour cet article, nous utilisons la recherche hybride car elle combine la recherche sémantique et textuelle pour offrir une plus grande précision. Pour en savoir plus sur la recherche hybride, consultez Les bases de connaissances pour Amazon Bedrock prennent désormais en charge la recherche hybride.
- Développer vous Nombre maximum de fragments sources et définissez votre nombre maximum de résultats.

Pour démontrer la valeur de la nouvelle fonctionnalité, nous montrons des exemples de la manière dont vous pouvez augmenter la précision de la réponse générée. Nous avons utilisé Document Amazon 10K pour 2023 comme données sources pour créer la base de connaissances. Nous utilisons la requête suivante à des fins d'expérimentation : « En quelle année le chiffre d'affaires annuel d'Amazon est-il passé de 245 milliards de dollars à 434 milliards de dollars ? »
La réponse correcte à cette requête est « Le chiffre d'affaires annuel d'Amazon est passé de 245 milliards de dollars en 2019 à 434 milliards de dollars en 2022 », d'après les documents de la base de connaissances. Nous avons utilisé Claude v2 comme FM pour générer la réponse finale basée sur les informations contextuelles extraites de la base de connaissances. Claude 3 Sonnet et Claude 3 Haiku sont également soutenus en tant que génération FM.
Nous avons exécuté une autre requête pour démontrer la comparaison de la récupération avec différentes configurations. Nous avons utilisé la même requête d'entrée (« En quelle année le chiffre d'affaires annuel d'Amazon est-il passé de 245 milliards de dollars à 434 milliards de dollars ? ») et avons fixé le nombre maximum de résultats à 5.
Comme le montre la capture d'écran suivante, la réponse générée était « Désolé, je ne peux pas vous aider avec cette demande. »

Ensuite, nous fixons le nombre maximum de résultats à 12 et posons la même question. La réponse générée est « Le chiffre d’affaires annuel d’Amazon passe de 245 milliards de dollars en 2019 à 434 milliards de dollars en 2022 ».

Comme le montre cet exemple, nous sommes en mesure de récupérer la bonne réponse en fonction du nombre de résultats récupérés. Si vous souhaitez en savoir plus sur l'attribution de la source qui constitue le résultat final, choisissez Afficher les détails de la source pour valider la réponse générée en fonction de la base de connaissances.
Personnaliser un modèle d'invite de base de connaissances à l'aide de la console
Vous pouvez également personnaliser l'invite par défaut avec votre propre invite en fonction du cas d'utilisation. Pour ce faire sur la console, procédez comme suit :
- Répétez les étapes de la section précédente pour commencer à tester votre base de connaissances.
- Activer Générer des réponses.

- Sélectionnez le modèle de votre choix pour la génération de réponses.
Nous utilisons le modèle Claude v2 comme exemple dans cet article. Le modèle Claude 3 Sonnet et Haiku est également disponible en génération.
- Selectionnez Appliquer procéder.

Après avoir choisi le modèle, une nouvelle section appelée Modèle d'invite de base de connaissances apparaît sous Configurations.
- Selectionnez Modifier pour commencer à personnaliser l'invite.
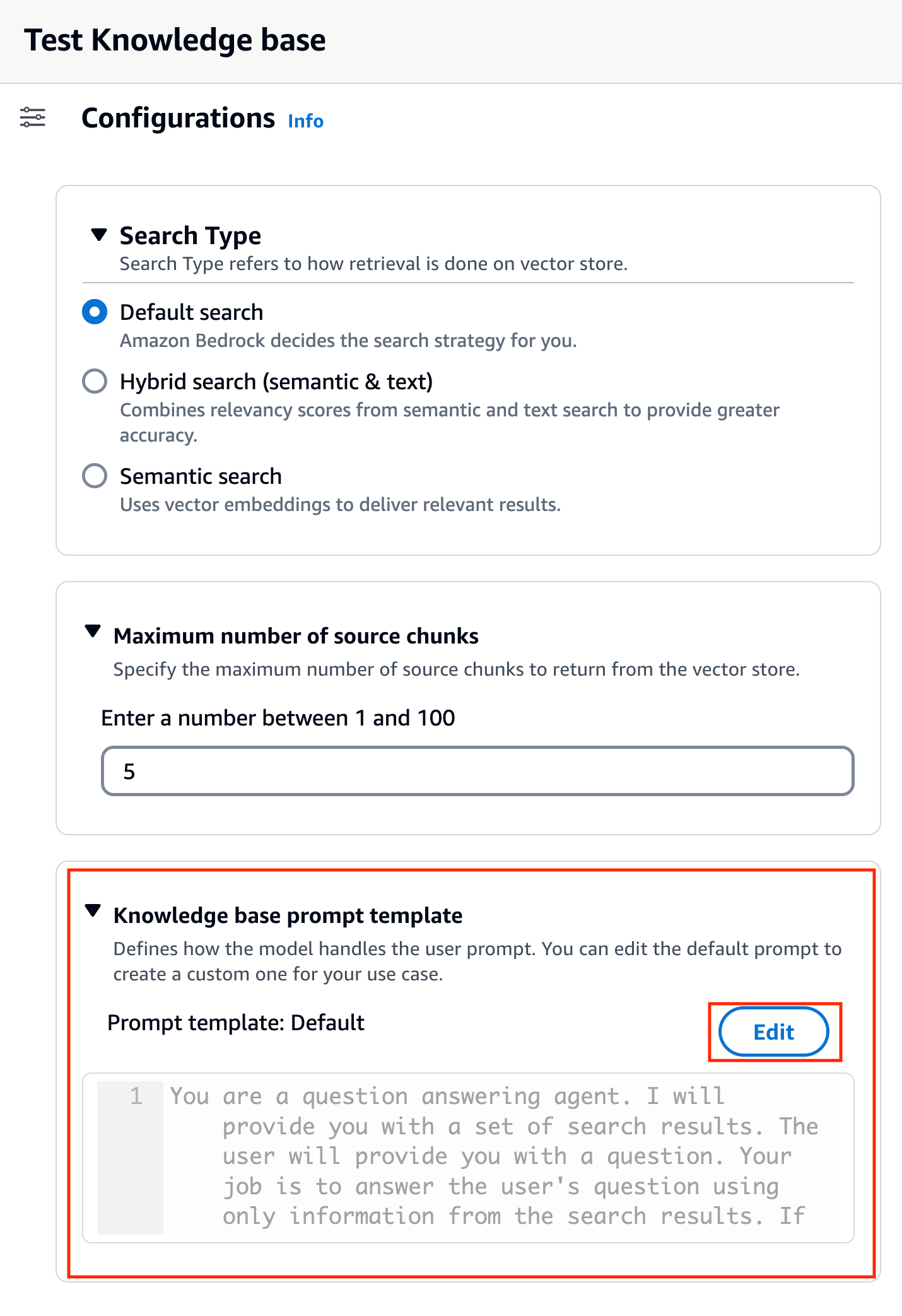
- Ajustez le modèle d'invite pour personnaliser la manière dont vous souhaitez utiliser les résultats récupérés et générer du contenu.
Pour cet article, nous avons donné quelques exemples de création d'un « système d'IA de conseiller financier » à l'aide de rapports financiers Amazon avec des invites personnalisées. Pour connaître les meilleures pratiques en matière d'ingénierie rapide, reportez-vous à Directives d'ingénierie rapides.
Nous personnalisons maintenant le modèle d'invite par défaut de plusieurs manières différentes et observons les réponses.
Essayons d'abord une requête avec l'invite par défaut. Nous demandons « Quels ont été les revenus d'Amazon en 2019 et 2021 ? » Ce qui suit montre nos résultats.

À partir du résultat, nous constatons qu’il génère une réponse de forme libre basée sur les connaissances récupérées. Les citations sont également répertoriées à titre de référence.
Disons que nous souhaitons donner des instructions supplémentaires sur la façon de formater la réponse générée, comme la standardiser en JSON. Nous pouvons ajouter ces instructions dans une étape distincte après avoir récupéré les informations, dans le cadre du modèle d'invite :
La réponse finale a la structure requise.

En personnalisant l'invite, vous pouvez également modifier la langue de la réponse générée. Dans l'exemple suivant, nous demandons au modèle de fournir une réponse en espagnol.

Après avoir retiré $output_format_instructions$ à partir de l'invite par défaut, la citation de la réponse générée est supprimée.
Dans les sections suivantes, nous expliquons comment utiliser ces fonctionnalités avec le SDK.
Configurer le nombre maximum de résultats à l'aide du SDK
Pour modifier le nombre maximum de résultats avec le SDK, utilisez la syntaxe suivante. Pour cet exemple, la requête est « En quelle année le chiffre d'affaires annuel d'Amazon est-il passé de 245 milliards de dollars à 434 milliards de dollars ? » La bonne réponse est « Le chiffre d’affaires annuel d’Amazon est passé de 245 milliards de dollars en 2019 à 434 milliards de dollars en 2022 ».
Le 'numberOfResults'option sous 'retrievalConfiguration' vous permet de sélectionner le nombre de résultats que vous souhaitez récupérer. La sortie du RetrieveAndGenerate L'API inclut la réponse générée, l'attribution de la source et les morceaux de texte récupérés.
Voici les résultats pour différentes valeurs de 'numberOfResults' paramètres. Tout d'abord, nous définissons numberOfResults = 5.
Puis nous fixons numberOfResults = 12.
Personnaliser le modèle d'invite de la base de connaissances à l'aide du SDK
Pour personnaliser l'invite à l'aide du SDK, nous utilisons la requête suivante avec différents modèles d'invite. Pour cet exemple, la requête est « Quels étaient les revenus d'Amazon en 2019 et 2021 ? »
Voici le modèle d'invite par défaut :
Voici le modèle d'invite personnalisé :
Avec le modèle d'invite par défaut, nous obtenons la réponse suivante :
![]()
Si vous souhaitez fournir des instructions supplémentaires sur le format de sortie de la génération de réponse, comme standardiser la réponse dans un format spécifique (comme JSON), vous pouvez personnaliser l'invite existante en fournissant plus de conseils. Avec notre modèle d'invite personnalisé, nous obtenons la réponse suivante.

Le 'promptTemplate'option dans 'generationConfiguration' vous permet de personnaliser l'invite pour un meilleur contrôle sur la génération de réponses.
Conclusion
Dans cet article, nous avons introduit deux nouvelles fonctionnalités dans les bases de connaissances pour Amazon Bedrock : l'ajustement du nombre maximum de résultats de recherche et la personnalisation du modèle d'invite par défaut pour le RetrieveAndGenerate API. Nous avons montré comment configurer ces fonctionnalités sur la console et via le SDK pour améliorer les performances et la précision de la réponse générée. L'augmentation des résultats maximaux fournit des informations plus complètes, tandis que la personnalisation du modèle d'invite vous permet d'affiner les instructions du modèle de base afin de mieux les aligner sur des cas d'utilisation spécifiques. Ces améliorations offrent une plus grande flexibilité et un meilleur contrôle, vous permettant de proposer des expériences personnalisées pour les applications basées sur RAG.
Pour obtenir des ressources supplémentaires à mettre en œuvre dans votre environnement AWS, reportez-vous à ce qui suit :
À propos des auteurs
 Sandeep Singh est Senior Generative AI Data Scientist chez Amazon Web Services, aidant les entreprises à innover grâce à l'IA générative. Il se spécialise dans l'IA générative, l'intelligence artificielle, l'apprentissage automatique et la conception de systèmes. Il est passionné par le développement de solutions de pointe basées sur l'IA/ML pour résoudre des problèmes commerciaux complexes pour diverses industries, en optimisant l'efficacité et l'évolutivité.
Sandeep Singh est Senior Generative AI Data Scientist chez Amazon Web Services, aidant les entreprises à innover grâce à l'IA générative. Il se spécialise dans l'IA générative, l'intelligence artificielle, l'apprentissage automatique et la conception de systèmes. Il est passionné par le développement de solutions de pointe basées sur l'IA/ML pour résoudre des problèmes commerciaux complexes pour diverses industries, en optimisant l'efficacité et l'évolutivité.
 Suyin Wang est un architecte de solutions spécialisé en IA/ML chez AWS. Elle possède une formation interdisciplinaire en apprentissage automatique, en services d'information financière et en économie, ainsi que des années d'expérience dans la création d'applications de science des données et d'apprentissage automatique qui ont résolu des problèmes commerciaux réels. Elle aime aider les clients à identifier les bonnes questions commerciales et à créer les bonnes solutions IA/ML. Dans ses temps libres, elle aime chanter et cuisiner.
Suyin Wang est un architecte de solutions spécialisé en IA/ML chez AWS. Elle possède une formation interdisciplinaire en apprentissage automatique, en services d'information financière et en économie, ainsi que des années d'expérience dans la création d'applications de science des données et d'apprentissage automatique qui ont résolu des problèmes commerciaux réels. Elle aime aider les clients à identifier les bonnes questions commerciales et à créer les bonnes solutions IA/ML. Dans ses temps libres, elle aime chanter et cuisiner.
 Xérès Ding est un architecte senior de solutions spécialisées en intelligence artificielle (IA) et en apprentissage automatique (ML) chez Amazon Web Services (AWS). Elle possède une vaste expérience en apprentissage automatique avec un doctorat en informatique. Elle travaille principalement avec des clients du secteur public sur divers défis commerciaux liés à l'IA/ML, les aidant à accélérer leur parcours d'apprentissage automatique sur le cloud AWS. Lorsqu’elle n’aide pas les clients, elle aime les activités de plein air.
Xérès Ding est un architecte senior de solutions spécialisées en intelligence artificielle (IA) et en apprentissage automatique (ML) chez Amazon Web Services (AWS). Elle possède une vaste expérience en apprentissage automatique avec un doctorat en informatique. Elle travaille principalement avec des clients du secteur public sur divers défis commerciaux liés à l'IA/ML, les aidant à accélérer leur parcours d'apprentissage automatique sur le cloud AWS. Lorsqu’elle n’aide pas les clients, elle aime les activités de plein air.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/knowledge-bases-for-amazon-bedrock-now-supports-custom-prompts-for-the-retrieveandgenerate-api-and-configuration-of-the-maximum-number-of-retrieved-results/

