Aujourd'hui, nous sommes ravis d'annoncer que le Garde de lama le modèle est maintenant disponible pour les clients utilisant Amazon SageMaker JumpStart. Llama Guard fournit des protections d'entrée et de sortie dans le déploiement d'un modèle de langage étendu (LLM). C’est l’un des composants de Purple Llama, l’initiative de Meta proposant des outils et des évaluations ouverts de confiance et de sécurité pour aider les développeurs à construire de manière responsable avec des modèles d’IA. Purple Llama rassemble des outils et des évaluations pour aider la communauté à construire de manière responsable avec des modèles d'IA génératifs. La version initiale met l'accent sur la cybersécurité et les protections d'entrée et de sortie LLM. Les composants du projet Purple Llama, y compris le modèle Llama Guard, sont sous licence permissive, permettant à la fois la recherche et l'utilisation commerciale.
Vous pouvez désormais utiliser le modèle Llama Guard dans SageMaker JumpStart. SageMaker JumpStart est la plateforme d'apprentissage automatique (ML) de Amazon Sage Maker qui donne accès aux modèles de base en plus des algorithmes intégrés et des modèles de solution de bout en bout pour vous aider à démarrer rapidement avec ML.
Dans cet article, nous expliquons comment déployer le modèle Llama Guard et créer des solutions d'IA générative responsables.
Modèle de Garde Lama
Llama Guard est un nouveau modèle de Meta qui fournit des garde-corps d'entrée et de sortie pour les déploiements LLM. Llama Guard est un modèle ouvertement disponible qui fonctionne de manière compétitive sur des benchmarks ouverts courants et fournit aux développeurs un modèle pré-entraîné pour les aider à se défendre contre la génération de résultats potentiellement risqués. Ce modèle a été formé sur un mélange d'ensembles de données accessibles au public pour permettre la détection de types courants de contenu potentiellement risqué ou violant qui peuvent être pertinents pour un certain nombre de cas d'utilisation des développeurs. En fin de compte, la vision du modèle est de permettre aux développeurs de personnaliser ce modèle pour prendre en charge des cas d'utilisation pertinents et de faciliter l'adoption des meilleures pratiques et l'amélioration de l'écosystème ouvert.
Llama Guard peut être utilisé comme un outil supplémentaire que les développeurs peuvent intégrer dans leurs propres stratégies d'atténuation, comme pour les chatbots, la modération de contenu, le service client, la surveillance des médias sociaux et l'éducation. En transmettant le contenu généré par les utilisateurs via Llama Guard avant de le publier ou d'y répondre, les développeurs peuvent signaler un langage dangereux ou inapproprié et prendre des mesures pour maintenir un environnement sûr et respectueux.
Explorons comment nous pouvons utiliser le modèle Llama Guard dans SageMaker JumpStart.
Modèles de fondation dans SageMaker
SageMaker JumpStart donne accès à une gamme de modèles provenant de hubs de modèles populaires, notamment Hugging Face, PyTorch Hub et TensorFlow Hub, que vous pouvez utiliser dans votre flux de travail de développement ML dans SageMaker. Les progrès récents du ML ont donné naissance à une nouvelle classe de modèles connus sous le nom de modèles de fondation, qui sont généralement formés sur des milliards de paramètres et sont adaptables à une large catégorie de cas d'utilisation, tels que le résumé de texte, la génération d'art numérique et la traduction linguistique. La formation de ces modèles étant coûteuse, les clients souhaitent utiliser des modèles de base pré-entraînés existants et les affiner si nécessaire, plutôt que de former ces modèles eux-mêmes. SageMaker fournit une liste organisée de modèles parmi lesquels vous pouvez choisir sur la console SageMaker.
Vous pouvez désormais trouver des modèles de base auprès de différents fournisseurs de modèles dans SageMaker JumpStart, ce qui vous permet de démarrer rapidement avec les modèles de base. Vous pouvez trouver des modèles de base basés sur différentes tâches ou fournisseurs de modèles, et consulter facilement les caractéristiques des modèles et les conditions d'utilisation. Vous pouvez également essayer ces modèles à l’aide d’un widget d’interface utilisateur de test. Lorsque vous souhaitez utiliser un modèle de base à grande échelle, vous pouvez le faire facilement sans quitter SageMaker en utilisant des blocs-notes prédéfinis provenant de fournisseurs de modèles. Étant donné que les modèles sont hébergés et déployés sur AWS, vous pouvez être assuré que vos données, qu'elles soient utilisées pour évaluer ou utiliser le modèle à grande échelle, ne sont jamais partagées avec des tiers.
Explorons comment nous pouvons utiliser le modèle Llama Guard dans SageMaker JumpStart.
Découvrez le modèle Llama Guard dans SageMaker JumpStart
Vous pouvez accéder aux modèles de base Code Llama via SageMaker JumpStart dans l'interface utilisateur de SageMaker Studio et le SDK SageMaker Python. Dans cette section, nous expliquons comment découvrir les modèles dans Amazon SageMakerStudio.
SageMaker Studio est un environnement de développement intégré (IDE) qui fournit une interface visuelle Web unique où vous pouvez accéder à des outils spécialement conçus pour effectuer toutes les étapes de développement ML, de la préparation des données à la création, la formation et le déploiement de vos modèles ML. Pour plus de détails sur la façon de démarrer et de configurer SageMaker Studio, reportez-vous à Amazon SageMakerStudio.
Dans SageMaker Studio, vous pouvez accéder à SageMaker JumpStart, qui contient des modèles, des blocs-notes et des solutions prédéfinis, sous Solutions prédéfinies et automatisées.
Sur la page de destination de SageMaker JumpStart, vous pouvez trouver le modèle Llama Guard en choisissant le hub Meta ou en recherchant Llama Guard.

Vous pouvez choisir parmi une variété de variantes de modèles Llama, notamment Llama Guard, Llama-2 et Code Llama.
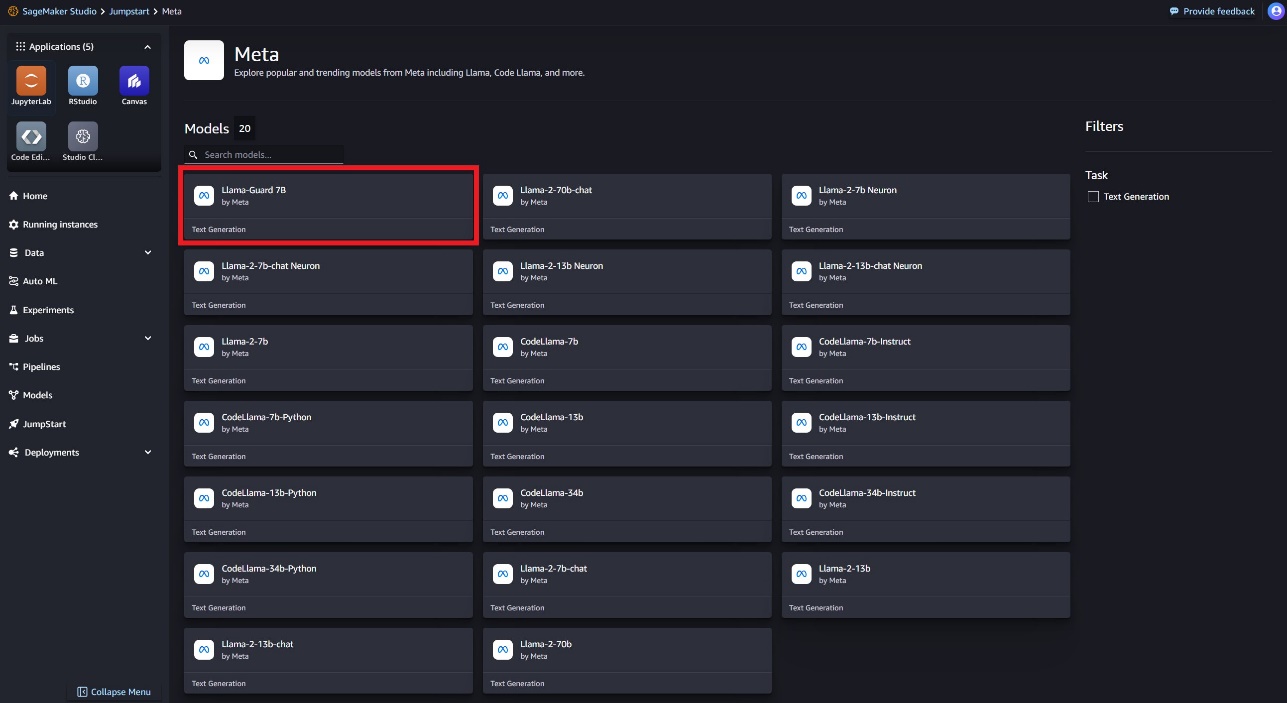
Vous pouvez choisir la fiche de modèle pour afficher les détails du modèle, tels que la licence, les données utilisées pour l'entraînement et la manière de l'utiliser. Vous trouverez également un Déployer option, qui vous mènera à une page de destination où vous pourrez tester l'inférence avec un exemple de charge utile.

Déployer le modèle avec le SDK SageMaker Python
Vous pouvez trouver le code montrant le déploiement de Llama Guard sur Amazon JumpStart et un exemple d'utilisation du modèle déployé dans this Carnet GitHub.
Dans le code suivant, nous spécifions l'ID du modèle du hub de modèle SageMaker et la version du modèle à utiliser lors du déploiement de Llama Guard :
Vous pouvez maintenant déployer le modèle à l'aide de SageMaker JumpStart. Le code suivant utilise l'instance par défaut ml.g5.2xlarge pour le point de terminaison d'inférence. Vous pouvez déployer le modèle sur d'autres types d'instances en passant instance_type dans l' JumpStartModel classe. Le déploiement peut prendre quelques minutes. Pour un déploiement réussi, vous devez modifier manuellement le accept_eula argument dans la méthode de déploiement du modèle pour True.
Ce modèle est déployé à l'aide du conteneur d'apprentissage profond Text Generation Inference (TGI). Les requêtes d'inférence prennent en charge de nombreux paramètres, notamment les suivants :
- longueur maximale – Le modèle génère du texte jusqu'à ce que la longueur de sortie (qui inclut la longueur du contexte d'entrée) atteigne
max_length. S'il est spécifié, il doit s'agir d'un entier positif. - max_new_tokens – Le modèle génère du texte jusqu'à ce que la longueur de sortie (à l'exclusion de la longueur du contexte d'entrée) atteigne
max_new_tokens. S'il est spécifié, il doit s'agir d'un entier positif. - nombre_faisceaux – Ceci indique le nombre de faisceaux utilisés dans la recherche gourmande. S'il est spécifié, il doit s'agir d'un nombre entier supérieur ou égal à
num_return_sequences. - no_repeat_ngram_size – Le modèle assure qu'une suite de mots de
no_repeat_ngram_sizen'est pas répété dans la séquence de sortie. S'il est spécifié, il doit s'agir d'un entier positif supérieur à 1. - la réactivité – Ce paramètre contrôle le caractère aléatoire de la sortie. Un plus haut
temperaturese traduit par une séquence de sortie avec des mots à faible probabilité et untemperatureaboutit à une séquence de sortie avec des mots à haute probabilité. Sitemperatureest 0, cela entraîne un décodage gourmand. S’il est spécifié, il doit s’agir d’un flottant positif. - arrêt_précoce - Si
True, la génération du texte est terminée lorsque toutes les hypothèses du faisceau atteignent la fin du jeton de phrase. S'il est spécifié, il doit être booléen. - faire_sample - Si
True, le modèle échantillonne le mot suivant selon la vraisemblance. S'il est spécifié, il doit être booléen. - top_k – À chaque étape de génération de texte, le modèle échantillonne uniquement le
top_kmots les plus probables. S'il est spécifié, il doit s'agir d'un entier positif. - top_p – À chaque étape de génération de texte, le modèle échantillonne à partir du plus petit ensemble de mots possible avec une probabilité cumulative
top_p. S'il est spécifié, il doit s'agir d'un flottant compris entre 0 et 1. - return_full_text - Si
True, le texte d'entrée fera partie du texte généré en sortie. S'il est spécifié, il doit être booléen. La valeur par défaut estFalse. - Arrêtez – Si spécifié, il doit s'agir d'une liste de chaînes. La génération de texte s'arrête si l'une des chaînes spécifiées est générée.
Appeler un point de terminaison SageMaker
Vous pouvez récupérer par programme des exemples de charges utiles à partir du JumpStartModel objet. Cela vous aidera à démarrer rapidement en observant les invites d'instructions préformatées que Llama Guard peut ingérer. Voir le code suivant :
Après avoir exécuté l'exemple précédent, vous pouvez voir comment vos entrées et sorties seront formatées par Llama Guard :
Semblable à Llama-2, Llama Guard utilise des jetons spéciaux pour indiquer les consignes de sécurité au modèle. En général, la charge utile doit suivre le format ci-dessous :
Invite utilisateur affichée comme {user_prompt} ci-dessus, peut en outre inclure des sections pour les définitions de catégories de contenu et les conversations, qui ressemblent à ce qui suit :
Dans la section suivante, nous discutons des valeurs par défaut recommandées pour les définitions de tâches, de catégories de contenu et d’instructions. La conversation doit alterner entre User ainsi que Agent texte comme suit :
Modérer une conversation avec Llama-2 Chat
Vous pouvez désormais déployer un point de terminaison de modèle Llama-2 7B Chat pour le chat conversationnel, puis utiliser Llama Guard pour modérer le texte d'entrée et de sortie provenant de Llama-2 7B Chat.
Nous vous montrons l'exemple des entrées et sorties du modèle de discussion Llama-2 7B modérées via Llama Guard, mais vous pouvez utiliser Llama Guard pour la modération avec n'importe quel LLM de votre choix.
Déployez le modèle avec le code suivant :
Vous pouvez maintenant définir le modèle de tâche Llama Guard. Les catégories de contenu dangereux peuvent être ajustées comme vous le souhaitez pour votre cas d'utilisation spécifique. Vous pouvez définir en texte brut la signification de chaque catégorie de contenu, y compris quel contenu doit être signalé comme dangereux et quel contenu doit être autorisé comme étant sûr. Voir le code suivant :
Ensuite, nous définissons les fonctions d'assistance format_chat_messages ainsi que format_guard_messages pour formater l'invite pour le modèle de chat et pour le modèle Llama Guard qui nécessitait des jetons spéciaux :
Vous pouvez ensuite utiliser ces fonctions d'assistance sur un exemple d'invite de saisie de message pour exécuter l'exemple de saisie via Llama Guard afin de déterminer si le contenu du message est sûr :
La sortie suivante indique que le message est sûr. Vous remarquerez peut-être que l'invite comprend des mots pouvant être associés à la violence, mais, dans ce cas, Llama Guard est capable de comprendre le contexte par rapport aux instructions et aux définitions de catégories dangereuses que nous avons fournies précédemment et de déterminer qu'il s'agit d'une invite sûre et non liés aux violences.
Maintenant que vous avez confirmé que le texte saisi est jugé sûr par rapport à vos catégories de contenu Llama Guard, vous pouvez transmettre cette charge utile au modèle Llama-2 7B déployé pour générer du texte :
Voici la réponse du modèle :
Enfin, vous souhaiterez peut-être confirmer que le texte de réponse du modèle est déterminé comme contenant un contenu sûr. Ici, vous étendez la réponse de sortie LLM aux messages d'entrée et exécutez toute cette conversation via Llama Guard pour vous assurer que la conversation est sûre pour votre application :
Vous pouvez voir le résultat suivant, indiquant que la réponse du modèle de chat est sûre :
Nettoyer
Après avoir testé les points de terminaison, assurez-vous de supprimer les points de terminaison d'inférence SageMaker et le modèle pour éviter d'encourir des frais.
Conclusion
Dans cet article, nous vous avons montré comment modérer les entrées et les sorties à l'aide de Llama Guard et mettre en place des garde-fous pour les entrées et les sorties des LLM dans SageMaker JumpStart.
À mesure que l’IA continue de progresser, il est essentiel de donner la priorité à un développement et un déploiement responsables. Des outils tels que CyberSecEval et Llama Guard de Purple Llama jouent un rôle déterminant dans la promotion d’une innovation sûre, en offrant une identification précoce des risques et des conseils d’atténuation pour les modèles de langage. Ceux-ci doivent être ancrés dans le processus de conception de l’IA afin d’exploiter tout le potentiel des LLM de manière éthique dès le premier jour.
Essayez Llama Guard et d'autres modèles de fondation dans SageMaker JumpStart dès aujourd'hui et faites-nous part de vos commentaires !
Ces conseils sont fournis à titre informatif uniquement. Vous devez toujours effectuer votre propre évaluation indépendante et prendre des mesures pour garantir que vous respectez vos propres pratiques et normes spécifiques de contrôle de qualité, ainsi que les règles, lois, réglementations, licences et conditions d'utilisation locales qui s'appliquent à vous, à votre contenu, et le modèle tiers référencé dans ce guide. AWS n'a aucun contrôle ni autorité sur le modèle tiers référencé dans ce guide et ne fait aucune déclaration ni garantie que le modèle tiers est sécurisé, exempt de virus, opérationnel ou compatible avec votre environnement et vos normes de production. AWS ne fait aucune déclaration, garantie ou garantie que les informations contenues dans ce guide entraîneront un résultat ou un résultat particulier.
À propos des auteurs
 Dr Kyle Ulrich est un scientifique appliqué avec le Algorithmes intégrés d'Amazon SageMaker équipe. Ses intérêts de recherche comprennent les algorithmes d'apprentissage automatique évolutifs, la vision par ordinateur, les séries chronologiques, les processus bayésiens non paramétriques et gaussiens. Son doctorat est de l'Université Duke et il a publié des articles dans NeurIPS, Cell et Neuron.
Dr Kyle Ulrich est un scientifique appliqué avec le Algorithmes intégrés d'Amazon SageMaker équipe. Ses intérêts de recherche comprennent les algorithmes d'apprentissage automatique évolutifs, la vision par ordinateur, les séries chronologiques, les processus bayésiens non paramétriques et gaussiens. Son doctorat est de l'Université Duke et il a publié des articles dans NeurIPS, Cell et Neuron.
 Evan Kravitz est ingénieur logiciel chez Amazon Web Services, travaillant sur SageMaker JumpStart. Il s'intéresse à la confluence de l'apprentissage automatique et du cloud computing. Evan a obtenu son diplôme de premier cycle de l'Université Cornell et sa maîtrise de l'Université de Californie à Berkeley. En 2021, il a présenté un article sur les réseaux de neurones adverses lors de la conférence ICLR. Pendant son temps libre, Evan aime cuisiner, voyager et courir à New York.
Evan Kravitz est ingénieur logiciel chez Amazon Web Services, travaillant sur SageMaker JumpStart. Il s'intéresse à la confluence de l'apprentissage automatique et du cloud computing. Evan a obtenu son diplôme de premier cycle de l'Université Cornell et sa maîtrise de l'Université de Californie à Berkeley. En 2021, il a présenté un article sur les réseaux de neurones adverses lors de la conférence ICLR. Pendant son temps libre, Evan aime cuisiner, voyager et courir à New York.
 Rachna Chadha est architecte principal de solutions AI/ML dans les comptes stratégiques chez AWS. Rachna est une optimiste qui croit qu'une utilisation éthique et responsable de l'IA peut améliorer la société à l'avenir et apporter la prospérité économique et sociale. Dans ses temps libres, Rachna aime passer du temps avec sa famille, faire de la randonnée et écouter de la musique.
Rachna Chadha est architecte principal de solutions AI/ML dans les comptes stratégiques chez AWS. Rachna est une optimiste qui croit qu'une utilisation éthique et responsable de l'IA peut améliorer la société à l'avenir et apporter la prospérité économique et sociale. Dans ses temps libres, Rachna aime passer du temps avec sa famille, faire de la randonnée et écouter de la musique.
 Dr Ashish Khetan est un scientifique appliqué senior avec les algorithmes intégrés d'Amazon SageMaker et aide à développer des algorithmes d'apprentissage automatique. Il a obtenu son doctorat à l'Université de l'Illinois à Urbana-Champaign. Il est un chercheur actif en apprentissage automatique et en inférence statistique, et a publié de nombreux articles dans les conférences NeurIPS, ICML, ICLR, JMLR, ACL et EMNLP.
Dr Ashish Khetan est un scientifique appliqué senior avec les algorithmes intégrés d'Amazon SageMaker et aide à développer des algorithmes d'apprentissage automatique. Il a obtenu son doctorat à l'Université de l'Illinois à Urbana-Champaign. Il est un chercheur actif en apprentissage automatique et en inférence statistique, et a publié de nombreux articles dans les conférences NeurIPS, ICML, ICLR, JMLR, ACL et EMNLP.
 Karl Albertsen dirige les produits, l'ingénierie et la science pour les algorithmes Amazon SageMaker et JumpStart, le centre d'apprentissage automatique de SageMaker. Il est passionné par l'application de l'apprentissage automatique pour libérer de la valeur commerciale.
Karl Albertsen dirige les produits, l'ingénierie et la science pour les algorithmes Amazon SageMaker et JumpStart, le centre d'apprentissage automatique de SageMaker. Il est passionné par l'application de l'apprentissage automatique pour libérer de la valeur commerciale.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/llama-guard-is-now-available-in-amazon-sagemaker-jumpstart/

