Les grands modèles linguistiques (LLM) sont généralement formés sur de grands ensembles de données accessibles au public et indépendants du domaine. Par exemple, Le lama de Meta les modèles sont formés sur des ensembles de données tels que CommonCrawl, C4, Wikipédia et ArXiv. Ces ensembles de données englobent un large éventail de sujets et de domaines. Bien que les modèles résultants donnent des résultats étonnamment bons pour des tâches générales, telles que la génération de texte et la reconnaissance d'entités, il est prouvé que les modèles entraînés avec des ensembles de données spécifiques à un domaine peuvent encore améliorer les performances du LLM. Par exemple, les données de formation utilisées pour BloombergGPT Il s'agit de 51 % de documents spécifiques à un domaine, y compris des actualités financières, des documents déposés et d'autres documents financiers. Le LLM résultant surpasse les LLM formés sur des ensembles de données non spécifiques à un domaine lorsqu'il est testé sur des tâches spécifiques à la finance. Les auteurs de BloombergGPT ont conclu que leur modèle surpasse tous les autres modèles testés pour quatre des cinq tâches financières. Le modèle a fourni des performances encore meilleures lorsqu'il a été testé avec une large marge pour les tâches financières internes de Bloomberg – jusqu'à 60 points de mieux (sur 100). Bien que vous puissiez en apprendre davantage sur les résultats complets de l'évaluation dans le papier, l'échantillon suivant capturé à partir du BloombergGPT L'article peut vous donner un aperçu des avantages de la formation des LLM à l'aide de données spécifiques au domaine financier. Comme le montre l'exemple, le modèle BloombergGPT a fourni des réponses correctes alors que d'autres modèles non spécifiques à un domaine ont eu des difficultés :
Cet article fournit un guide pour former des LLM spécifiquement pour le domaine financier. Nous couvrons les domaines clés suivants :
- Collecte et préparation des données – Conseils sur la recherche et la conservation des données financières pertinentes pour une formation efficace des modèles
- Pré-formation continue ou mise au point – Quand utiliser chaque technique pour optimiser les performances de votre LLM
- Une pré-formation continue efficace – Stratégies pour rationaliser le processus continu de pré-formation, économisant du temps et des ressources
Ce poste rassemble l'expertise de l'équipe de recherche en sciences appliquées d'Amazon Finance Technology et de l'équipe mondiale de spécialistes AWS pour le secteur financier mondial. Une partie du contenu est basée sur l'article Pré-formation continue efficace pour la création de grands modèles de langage spécifiques à un domaine.
Collecte et préparation des données financières
La pré-formation continue dans le domaine nécessite un ensemble de données à grande échelle, de haute qualité et spécifiques au domaine. Voici les principales étapes de la curation des ensembles de données de domaine :
- Identifier les sources de données – Les sources de données potentielles pour le corpus de domaines incluent le Web ouvert, Wikipédia, les livres, les médias sociaux et les documents internes.
- Filtres de données de domaine – Étant donné que l'objectif ultime est de gérer le corpus du domaine, vous devrez peut-être appliquer des étapes supplémentaires pour filtrer les échantillons qui ne sont pas pertinents pour le domaine cible. Cela réduit le corpus inutile pour une pré-formation continue et réduit les coûts de formation.
- Prétraitement – Vous pouvez envisager une série d'étapes de prétraitement pour améliorer la qualité des données et l'efficacité de la formation. Par exemple, certaines sources de données peuvent contenir un bon nombre de jetons bruyants ; la déduplication est considérée comme une étape utile pour améliorer la qualité des données et réduire les coûts de formation.
Pour développer des LLM financiers, vous pouvez utiliser deux sources de données importantes : News CommonCrawl et les dépôts auprès de la SEC. Un dépôt auprès de la SEC est un état financier ou un autre document formel soumis à la Securities and Exchange Commission (SEC) des États-Unis. Les sociétés cotées en bourse sont tenues de déposer régulièrement divers documents. Cela crée un grand nombre de documents au fil des années. News CommonCrawl est un ensemble de données publié par CommonCrawl en 2016. Il contient des articles d'actualité provenant de sites d'actualités du monde entier.
Actualités CommonCrawl est disponible sur Service de stockage simple Amazon (Amazon S3) dans le commoncrawl seau à crawl-data/CC-NEWS/. Vous pouvez obtenir la liste des fichiers en utilisant le Interface de ligne de commande AWS (AWS CLI) et la commande suivante :
In Pré-formation continue efficace pour la création de grands modèles de langage spécifiques à un domaine, les auteurs utilisent une approche basée sur des URL et des mots clés pour filtrer les articles d'actualité financière des actualités génériques. Plus précisément, les auteurs maintiennent une liste d’importants organes d’information financière et un ensemble de mots-clés liés à l’actualité financière. Nous identifions un article comme une actualité financière s'il provient de médias financiers ou si des mots-clés apparaissent dans l'URL. Cette approche simple mais efficace vous permet d'identifier les actualités financières non seulement des médias financiers, mais également des sections financières des médias génériques.
Les dépôts auprès de la SEC sont disponibles en ligne via la base de données EDGAR (Electronic Data Gathering, Analysis, and Retrieval) de la SEC, qui fournit un accès ouvert aux données. Vous pouvez récupérer les dépôts d'EDGAR directement ou utiliser des API dans Amazon Sage Maker avec quelques lignes de code, pour n'importe quelle période de temps et pour un grand nombre de tickers (c'est-à-dire l'identifiant attribué par la SEC). Pour en savoir plus, reportez-vous à Récupération de dépôt auprès de la SEC.
Le tableau suivant résume les principaux détails des deux sources de données.
| . | Actualités CommonCrawl | Dépôt SEC |
| Couverture | 2016-2022 | 1993-2022 |
| Taille | 25.8 milliards de mots | 5.1 milliards de mots |
Les auteurs passent par quelques étapes de prétraitement supplémentaires avant que les données ne soient introduites dans un algorithme de formation. Premièrement, nous observons que les documents déposés auprès de la SEC contiennent du texte bruyant en raison de la suppression des tableaux et des figures, de sorte que les auteurs suppriment les phrases courtes considérées comme des étiquettes de tableaux ou de figures. Deuxièmement, nous appliquons un algorithme de hachage sensible à la localité pour dédupliquer les nouveaux articles et dépôts. Pour les dépôts auprès de la SEC, nous dédupliquons au niveau de la section plutôt qu'au niveau du document. Enfin, nous concaténons les documents en une longue chaîne, la tokenisons et fragmentons la tokenisation en morceaux de longueur d'entrée maximale prise en charge par le modèle à entraîner. Cela améliore le débit de la pré-formation continue et réduit le coût de la formation.
Pré-formation continue ou mise au point
La plupart des LLM disponibles sont à usage général et manquent de capacités spécifiques à un domaine. Les LLM de domaine ont montré des performances considérables dans les domaines médical, financier ou scientifique. Pour qu'un LLM acquière des connaissances spécifiques à un domaine, il existe quatre méthodes : la formation à partir de zéro, la pré-formation continue, l'affinement des instructions sur les tâches du domaine et la génération augmentée de récupération (RAG).
Dans les modèles traditionnels, le réglage fin est généralement utilisé pour créer des modèles spécifiques à des tâches pour un domaine. Cela signifie maintenir plusieurs modèles pour plusieurs tâches telles que l'extraction d'entités, la classification des intentions, l'analyse des sentiments ou la réponse aux questions. Avec l'avènement des LLM, la nécessité de maintenir des modèles séparés est devenue obsolète en utilisant des techniques telles que l'apprentissage ou l'incitation en contexte. Cela permet d'économiser les efforts nécessaires pour maintenir une pile de modèles pour des tâches liées mais distinctes.
Intuitivement, vous pouvez former des LLM à partir de zéro avec des données spécifiques à un domaine. Bien que la majeure partie du travail visant à créer des LLM de domaine se soit concentrée sur une formation à partir de zéro, son coût est prohibitif. Par exemple, le modèle GPT-4 coûte plus de $ 100 millions entraîner. Ces modèles sont formés sur un mélange de données de domaine ouvert et de données de domaine. Une pré-formation continue peut aider les modèles à acquérir des connaissances spécifiques au domaine sans encourir le coût d'une pré-formation à partir de zéro, car vous pré-entraînez un LLM de domaine ouvert existant uniquement sur les données du domaine.
Avec le réglage fin des instructions sur une tâche, vous ne pouvez pas faire en sorte que le modèle acquière des connaissances de domaine, car le LLM acquiert uniquement les informations de domaine contenues dans l'ensemble de données de réglage fin des instructions. À moins d’utiliser un très grand ensemble de données pour le réglage fin des instructions, cela ne suffit pas pour acquérir des connaissances dans le domaine. L'obtention d'ensembles de données d'instruction de haute qualité est généralement difficile et c'est la raison pour laquelle il faut utiliser les LLM en premier lieu. En outre, le réglage précis des instructions sur une tâche peut affecter les performances d'autres tâches (comme le montre le présent document). Cependant, l'affinement de l'enseignement est plus rentable que l'une ou l'autre des alternatives de pré-formation.
La figure suivante compare le réglage traditionnel spécifique à une tâche. vs paradigme d'apprentissage en contexte avec les LLM.
 RAG est le moyen le plus efficace de guider un LLM pour générer des réponses ancrées dans un domaine. Bien qu'il puisse guider un modèle pour générer des réponses en fournissant des faits du domaine comme informations auxiliaires, il n'acquiert pas le langage spécifique au domaine car le LLM s'appuie toujours sur un style de langage non-domaine pour générer les réponses.
RAG est le moyen le plus efficace de guider un LLM pour générer des réponses ancrées dans un domaine. Bien qu'il puisse guider un modèle pour générer des réponses en fournissant des faits du domaine comme informations auxiliaires, il n'acquiert pas le langage spécifique au domaine car le LLM s'appuie toujours sur un style de langage non-domaine pour générer les réponses.
La pré-formation continue est un juste milieu entre la pré-formation et la mise au point de l'enseignement en termes de coût, tout en étant une alternative solide à l'acquisition de connaissances et de styles spécifiques à un domaine. Il peut fournir un modèle général sur lequel un réglage plus précis des instructions sur des données d'instruction limitées peut être effectué. La pré-formation continue peut constituer une stratégie rentable pour les domaines spécialisés où l'ensemble des tâches en aval est important ou inconnu et où les données de réglage des instructions étiquetées sont limitées. Dans d’autres scénarios, un réglage fin des instructions ou RAG pourrait être plus approprié.
Pour en savoir plus sur le réglage fin, le RAG et la formation de modèles, reportez-vous à Affiner un modèle de base, Génération augmentée de récupération (RAG)et Former un modèle avec Amazon SageMaker, respectivement. Pour ce poste, nous nous concentrons sur une pré-formation continue et efficace.
Méthodologie de pré-formation continue efficace
La pré-formation continue comprend la méthodologie suivante :
- Pré-formation continue adaptative au domaine (DACP) - Dans le journal Pré-formation continue efficace pour la création de grands modèles de langage spécifiques à un domaine, les auteurs pré-entraînent continuellement la suite de modèles de langage Pythia sur le corpus financier pour l'adapter au domaine financier. L'objectif est de créer des LLM financiers en introduisant des données de l'ensemble du domaine financier dans un modèle open source. Étant donné que le corpus de formation contient tous les ensembles de données conservés dans le domaine, le modèle résultant doit acquérir des connaissances spécifiques à la finance, devenant ainsi un modèle polyvalent pour diverses tâches financières. Il en résulte des modèles FinPythia.
- Pré-formation continue adaptative aux tâches (TACP) – Les auteurs pré-entraînent davantage les modèles sur des données de tâches étiquetées et non étiquetées afin de les adapter à des tâches spécifiques. Dans certaines circonstances, les développeurs peuvent préférer des modèles offrant de meilleures performances sur un groupe de tâches au sein du domaine plutôt qu'un modèle générique de domaine. TACP est conçu comme une pré-formation continue visant à améliorer les performances sur des tâches ciblées, sans exigences de données étiquetées. Plus précisément, les auteurs pré-entraînent continuellement les modèles open source sur les jetons de tâche (sans étiquettes). La principale limitation du TACP réside dans la construction de LLM spécifiques à des tâches au lieu de LLM de base, en raison de la seule utilisation de données de tâches non étiquetées pour la formation. Bien que le DACP utilise un corpus beaucoup plus vaste, son coût est prohibitif. Pour équilibrer ces limitations, les auteurs proposent deux approches qui visent à créer des LLM de base spécifiques à un domaine tout en préservant des performances supérieures sur les tâches cibles :
- DACP efficace similaire à une tâche (ETS-DACP) – Les auteurs proposent de sélectionner un sous-ensemble de corpus financier très similaire aux données de tâches en utilisant la similarité d'intégration. Ce sous-ensemble est utilisé pour une pré-formation continue afin de le rendre plus efficace. Plus précisément, les auteurs pré-entraînent continuellement le LLM open source sur un petit corpus extrait du corpus financier et proche des tâches cibles en distribution. Cela peut contribuer à améliorer les performances des tâches, car nous adoptons le modèle pour la distribution des jetons de tâches même si les données étiquetées ne sont pas requises.
- DACP efficace et indépendant des tâches (ETA-DACP) – Les auteurs proposent d'utiliser des métriques telles que la perplexité et l'entropie de type jeton qui ne nécessitent pas de données de tâche pour sélectionner des échantillons du corpus financier pour une pré-formation continue et efficace. Cette approche est conçue pour gérer des scénarios dans lesquels les données sur les tâches ne sont pas disponibles ou dans lesquels des modèles de domaine plus polyvalents pour un domaine plus large sont préférés. Les auteurs adoptent deux dimensions pour sélectionner les échantillons de données qui sont importants pour obtenir des informations de domaine à partir d'un sous-ensemble de données de domaine de pré-formation : la nouveauté et la diversité. La nouveauté, mesurée par la perplexité enregistrée par le modèle cible, fait référence aux informations qui n'étaient pas vues auparavant par le LLM. Les données très inédites indiquent des connaissances nouvelles pour le LLM, et ces données sont considérées comme plus difficiles à apprendre. Cela met à jour les LLM génériques avec une connaissance intensive du domaine au cours d'une pré-formation continue. La diversité, quant à elle, capture la diversité des distributions de types de jetons dans le corpus du domaine, ce qui a été documenté comme une caractéristique utile dans la recherche sur l'apprentissage curriculaire sur la modélisation du langage.
La figure suivante compare un exemple d'ETS-DACP (à gauche) et d'ETA-DACP (à droite).

Nous adoptons deux schémas d'échantillonnage pour sélectionner activement des points de données à partir d'un corpus financier organisé : l'échantillonnage dur et l'échantillonnage doux. La première consiste à classer d'abord le corpus financier selon les mesures correspondantes, puis à sélectionner les k meilleurs échantillons, où k est prédéterminé en fonction du budget de formation. Pour ces derniers, les auteurs attribuent des poids d'échantillonnage pour chaque point de données en fonction des valeurs métriques, puis échantillonnent au hasard k points de données pour respecter le budget de formation.
Résultat et analyse
Les auteurs évaluent les LLM financiers résultants sur un éventail de tâches financières afin d’étudier l’efficacité de la pré-formation continue :
- Banque de phrases financières – Une tâche de classification des sentiments sur l’actualité financière.
- FiQA SA – Une tâche de classification des sentiments basée sur les aspects basés sur l’actualité financière et les gros titres.
- Headline – Une tâche de classification binaire visant à déterminer si un titre sur une entité financière contient certaines informations.
- TNS – Une tâche d’extraction d’entités financières nommées basée sur la section d’évaluation du risque de crédit des rapports SEC. Les mots de cette tâche sont annotés avec PER, LOC, ORG et MISC.
Étant donné que les LLM financiers sont des instructions affinées, les auteurs évaluent les modèles dans un contexte de 5 étapes pour chaque tâche dans un souci de robustesse. En moyenne, le FinPythia 6.9B surpasse le Pythia 6.9B de 10 % sur quatre tâches, ce qui démontre l'efficacité de la pré-formation continue spécifique à un domaine. Pour le modèle 1B, l'amélioration est moins profonde, mais les performances s'améliorent tout de même de 2 % en moyenne.
La figure suivante illustre la différence de performances avant et après DACP sur les deux modèles.

La figure suivante présente deux exemples qualitatifs générés par Pythia 6.9B et FinPythia 6.9B. Pour deux questions liées à la finance concernant un gestionnaire d'investisseur et des conditions financières, Pythia 6.9B ne comprend pas le terme ni ne reconnaît le nom, alors que FinPythia 6.9B génère correctement des réponses détaillées. Les exemples qualitatifs démontrent qu'une pré-formation continue permet aux LLM d'acquérir des connaissances dans le domaine au cours du processus.

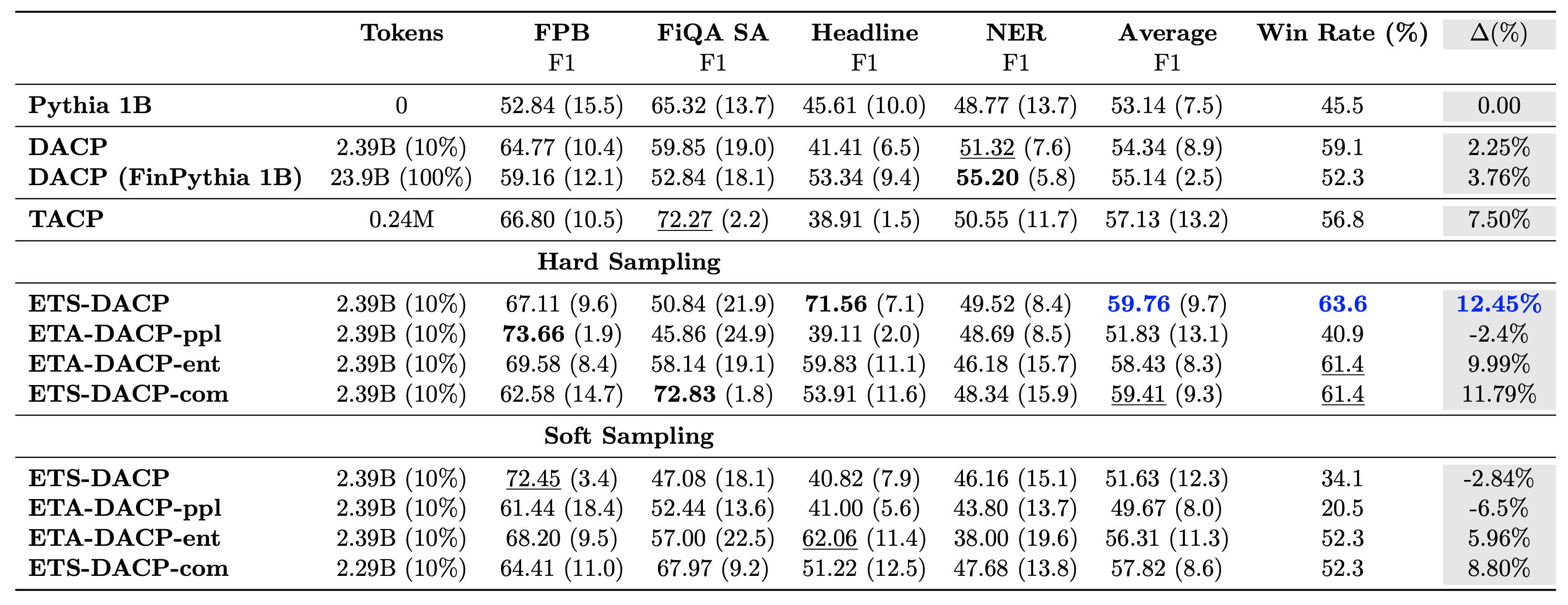
Le tableau suivant compare diverses approches efficaces de pré-formation continue. ETA-DACP-ppl est ETA-DACP basé sur la perplexité (nouveauté), et ETA-DACP-ent est basé sur l'entropie (diversité). ETS-DACP-com est similaire au DACP avec une sélection de données en faisant la moyenne des trois métriques. Voici quelques points à retenir des résultats :
- Les méthodes de sélection des données sont efficaces – Ils dépassent la pré-formation continue standard avec seulement 10 % des données d’entraînement. Une pré-formation continue efficace, y compris le DACP similaire à une tâche (ETS-DACP), le DACP indépendant de la tâche basé sur l'entropie (ESA-DACP-ent) et le DACP similaire à une tâche basé sur les trois métriques (ETS-DACP-com), surpasse le DACP standard. en moyenne malgré le fait qu'ils ne sont formés que sur 10% du corpus financier.
- La sélection de données sensible aux tâches fonctionne mieux en accord avec la recherche de petits modèles de langage – ETS-DACP enregistre la meilleure performance moyenne parmi toutes les méthodes et, sur la base des trois mesures, enregistre la deuxième meilleure performance de tâche. Cela suggère que l’utilisation de données de tâches non étiquetées reste une approche efficace pour améliorer les performances des tâches dans le cas des LLM.
- La sélection de données indépendantes des tâches arrive en deuxième position – ESA-DACP-ent suit les performances de l'approche de sélection de données tenant compte des tâches, ce qui implique que nous pourrions encore améliorer les performances des tâches en sélectionnant activement des échantillons de haute qualité non liés à des tâches spécifiques. Cela ouvre la voie à la création de LLM financiers pour l'ensemble du domaine tout en obtenant des performances de tâche supérieures.
Une question cruciale concernant la pré-formation continue est de savoir si elle affecte négativement les performances sur les tâches hors domaine. Les auteurs évaluent également le modèle continuellement pré-entraîné sur quatre tâches génériques largement utilisées : ARC, MMLU, TruthQA et HellaSwag, qui mesurent la capacité de réponse, de raisonnement et d'achèvement des questions. Les auteurs constatent que la pré-formation continue n’affecte pas négativement les performances hors domaine. Pour plus de détails, reportez-vous à Pré-formation continue efficace pour la création de grands modèles de langage spécifiques à un domaine.
Conclusion
Cet article offrait un aperçu de la collecte de données et des stratégies de pré-formation continue pour la formation des LLM dans le domaine financier. Vous pouvez commencer à former vos propres LLM pour les tâches financières en utilisant Formation Amazon Sage Maker or Socle amazonien dès aujourd’hui.
À propos des auteurs
 Yong Xie est un scientifique appliqué chez Amazon FinTech. Il se concentre sur le développement de grands modèles de langage et d'applications d'IA générative pour la finance.
Yong Xie est un scientifique appliqué chez Amazon FinTech. Il se concentre sur le développement de grands modèles de langage et d'applications d'IA générative pour la finance.
 Karan Aggarwal est un scientifique appliqué senior chez Amazon FinTech, spécialisé dans l'IA générative pour les cas d'utilisation financiers. Karan possède une vaste expérience dans l'analyse de séries chronologiques et la PNL, avec un intérêt particulier pour l'apprentissage à partir de données étiquetées limitées.
Karan Aggarwal est un scientifique appliqué senior chez Amazon FinTech, spécialisé dans l'IA générative pour les cas d'utilisation financiers. Karan possède une vaste expérience dans l'analyse de séries chronologiques et la PNL, avec un intérêt particulier pour l'apprentissage à partir de données étiquetées limitées.
 Aitzaz Ahmad est responsable des sciences appliquées chez Amazon, où il dirige une équipe de scientifiques qui créent diverses applications d'apprentissage automatique et d'IA générative en finance. Ses intérêts de recherche portent sur la PNL, l'IA générative et les agents LLM. Il a obtenu son doctorat en génie électrique de la Texas A&M University.
Aitzaz Ahmad est responsable des sciences appliquées chez Amazon, où il dirige une équipe de scientifiques qui créent diverses applications d'apprentissage automatique et d'IA générative en finance. Ses intérêts de recherche portent sur la PNL, l'IA générative et les agents LLM. Il a obtenu son doctorat en génie électrique de la Texas A&M University.
 Qingwei Li est spécialiste de l'apprentissage automatique chez Amazon Web Services. Il a obtenu son doctorat. en recherche opérationnelle après avoir brisé le compte de subvention de recherche de son conseiller et échoué à remettre le prix Nobel qu'il avait promis. Actuellement, il aide les clients du secteur des services financiers à créer des solutions d'apprentissage automatique sur AWS.
Qingwei Li est spécialiste de l'apprentissage automatique chez Amazon Web Services. Il a obtenu son doctorat. en recherche opérationnelle après avoir brisé le compte de subvention de recherche de son conseiller et échoué à remettre le prix Nobel qu'il avait promis. Actuellement, il aide les clients du secteur des services financiers à créer des solutions d'apprentissage automatique sur AWS.
 Raghvender Arni dirige l'équipe d'accélération client (CAT) au sein d'AWS Industries. Le CAT est une équipe interfonctionnelle mondiale composée d'architectes cloud, d'ingénieurs logiciels, de scientifiques des données, d'experts et de concepteurs IA/ML en contact avec les clients, qui stimule l'innovation via un prototypage avancé et favorise l'excellence opérationnelle du cloud via une expertise technique spécialisée.
Raghvender Arni dirige l'équipe d'accélération client (CAT) au sein d'AWS Industries. Le CAT est une équipe interfonctionnelle mondiale composée d'architectes cloud, d'ingénieurs logiciels, de scientifiques des données, d'experts et de concepteurs IA/ML en contact avec les clients, qui stimule l'innovation via un prototypage avancé et favorise l'excellence opérationnelle du cloud via une expertise technique spécialisée.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/efficient-continual-pre-training-llms-for-financial-domains/

