Introduction
Affiner un traitement du langage naturel (PNL) Le modèle implique de modifier les hyperparamètres et l'architecture du modèle et généralement d'ajuster l'ensemble de données pour améliorer les performances du modèle sur une tâche donnée. Vous pouvez y parvenir en ajustant le taux d'apprentissage, le nombre de couches dans le modèle, la taille des intégrations et divers autres paramètres. La mise au point est une procédure longue qui nécessite une solide maîtrise du modèle et du travail. Cet article explique comment affiner un modèle de visage câlin.

Objectifs d'apprentissage
- Comprenez la structure du modèle T5, y compris les transformateurs et l'attention personnelle.
- Apprenez à optimiser les hyperparamètres pour de meilleures performances du modèle.
- Maîtrisez la préparation des données texte, y compris la tokenisation et le formatage.
- Savoir adapter des modèles pré-entraînés à des tâches spécifiques.
- Apprenez à nettoyer, diviser et créer des ensembles de données pour la formation.
- Acquérez de l'expérience dans la formation et l'évaluation de modèles à l'aide de mesures telles que la perte et la précision.
- Explorez les applications concrètes du modèle affiné pour générer des réponses ou des réponses.
Cet article a été publié dans le cadre du Blogathon sur la science des données.
Table des matières
À propos des modèles de visages câlins
Étreindre le visage est une entreprise qui fournit une plate-forme pour la formation et le déploiement de modèles de traitement du langage naturel (NLP). La plateforme héberge une bibliothèque de modèles adaptée à diverses tâches de PNL, notamment la traduction de la langue, génération de texte, et réponses aux questions. Ces modèles subissent une formation sur de nombreux ensembles de données et sont conçus pour exceller dans un large éventail d'activités de traitement du langage naturel (NLP).
La plateforme Hugging Face comprend également des outils permettant d'affiner des modèles pré-entraînés sur des ensembles de données spécifiques, ce qui peut aider à adapter les algorithmes à des domaines ou à des langages particuliers. La plate-forme dispose également d'API permettant d'accéder et d'utiliser des modèles pré-entraînés dans des applications et des outils permettant de créer des modèles sur mesure et de les diffuser dans le cloud.
L'utilisation de la bibliothèque Hugging Face pour les tâches de traitement du langage naturel (NLP) présente divers avantages :
- Large choix de modèles : Une gamme importante de modèles PNL pré-entraînés est disponible via la bibliothèque Hugging Face, y compris des modèles formés à des tâches telles que la traduction linguistique, la réponse aux questions et la catégorisation de textes. Cela facilite le choix d’un modèle qui répond exactement à vos exigences.
- Compatibilité entre plates-formes : La bibliothèque Hugging Face est compatible avec la norme l'apprentissage en profondeur des systèmes tels que TensorFlow, PyTorch, et Keras, ce qui simplifie l'intégration dans votre flux de travail existant.
- Mise au point simple : La bibliothèque Hugging Face contient des outils permettant d'affiner les modèles pré-entraînés sur votre ensemble de données, vous permettant ainsi d'économiser du temps et des efforts par rapport à l'entraînement d'un modèle à partir de zéro.
- Communauté active: La bibliothèque Hugging Face dispose d'une communauté d'utilisateurs vaste et active, ce qui signifie que vous pouvez obtenir de l'aide et du soutien et contribuer à la croissance de la bibliothèque.
- Bien documenté: La bibliothèque Hugging Face contient une documentation complète, ce qui facilite son démarrage et apprend à l'utiliser efficacement.
Importer les bibliothèques nécessaires
L'importation des bibliothèques nécessaires est analogue à la construction d'une boîte à outils pour une activité particulière de programmation et d'analyse de données. Ces bibliothèques, qui sont souvent des collections de code pré-écrites, offrent un large éventail de fonctions et d'outils qui contribuent à accélérer le développement. Les développeurs et les data scientists peuvent accéder à de nouvelles fonctionnalités, augmenter la productivité et utiliser les solutions existantes en important les bibliothèques appropriées.
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split import torch from transformers import T5Tokenizer
from transformers import T5ForConditionalGeneration, AdamW import pytorch_lightning as pl
from pytorch_lightning.callbacks import ModelCheckpoint pl.seed_everything(100) import warnings
warnings.filterwarnings("ignore")
Importer un ensemble de données
L'importation d'un ensemble de données est une étape initiale cruciale dans les projets basés sur les données.
df = pd.read_csv("/kaggle/input/queestion-answer-dataset-qa/train.csv")
df.columns
df = df[['context','question', 'text']]
print("Number of records: ", df.shape[0])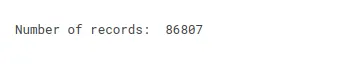
Énoncé du problème
« Créer un modèle capable de générer des réponses basées sur le contexte et les questions. »
Par exemple,
Contexte = « Le regroupement de groupes de cas similaires, par exemple, peut
trouver des patients similaires ou utiliser pour la segmentation de la clientèle dans le
domaine bancaire. La technique d'association est utilisée pour rechercher des éléments ou des événements
qui coexistent souvent, par exemple, des produits d'épicerie qu'un client particulier achète habituellement ensemble. La détection des anomalies est utilisée pour découvrir des anomalies
et cas inhabituels ; par exemple, fraude par carte de crédit
détection."
Question = « Quel est l'exemple de détection d'anomalie ? »
Réponse = ?????????????????????????????????
df["context"] = df["context"].str.lower()
df["question"] = df["question"].str.lower()
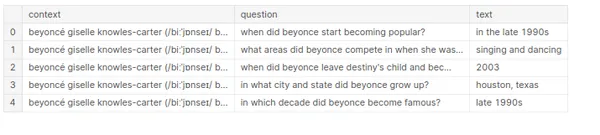
df["text"] = df["text"].str.lower() df.head()
Initialiser les paramètres
- longueur d'entrée : Pendant la formation, nous faisons référence au nombre de jetons d'entrée (par exemple, des mots ou des caractères) dans un seul exemple introduit dans le modèle comme longueur d'entrée. Si vous entraînez un modèle linguistique pour prédire le mot suivant dans une phrase, la longueur saisie correspond au nombre de mots dans la phrase.
- Longueur de sortie : Pendant la formation, le modèle devrait générer une quantité spécifique de jetons de sortie, tels que des mots ou des caractères, dans un seul échantillon. La longueur de sortie correspond au nombre de mots que le modèle prédit dans la phrase.
- Taille du lot de formation : Pendant la formation, le modèle traite plusieurs échantillons à la fois. Si vous définissez la taille du lot d'entraînement sur 32, le modèle gère 32 instances, telles que 32 phrases, simultanément avant de mettre à jour ses pondérations de modèle.
- Validation de la taille du lot : Semblable à la taille du lot de formation, ce paramètre indique le nombre d'instances que le modèle gère pendant la phase de validation. En d’autres termes, il représente le volume de données que le modèle traite lorsqu’il est testé sur un ensemble de données résistantes.
- Époques : Une époque est un voyage unique à travers l’ensemble complet de données d’entraînement. Ainsi, si l'ensemble de données de formation comprend 1000 32 instances et que la taille du lot de formation est de 32, une époque nécessitera 10 étapes de formation. Si le modèle est entraîné pendant dix époques, il aura traité dix mille instances (1000 * XNUMX XNUMX = dix mille).
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu') INPUT_MAX_LEN = 512 # Input length
OUT_MAX_LEN = 128 # Output Length
TRAIN_BATCH_SIZE = 8 # Training Batch Size
VALID_BATCH_SIZE = 2 # Validation Batch Size
EPOCHS = 5 # Number of IterationTransformateur T5
La modèle T5 est basé sur l'architecture Transformer, un réseau neuronal conçu pour gérer efficacement les données d'entrée séquentielles. Il comprend un encodeur et un décodeur, qui incluent une séquence de « couches » interconnectées.
Les couches codeur et décodeur comprennent divers mécanismes « d’attention » et réseaux « feedforward ». Les mécanismes d'attention permettent au modèle de se concentrer sur différentes sections de la séquence d'entrée à d'autres moments. Dans le même temps, les réseaux feedforward modifient les données d’entrée à l’aide d’un ensemble de pondérations et de biais.
Le modèle T5 utilise également « l'auto-attention », qui permet à chaque élément de la séquence d'entrée de prêter attention à tous les autres éléments. Cela permet au modèle de reconnaître les liens entre les mots et les phrases dans les données d'entrée, ce qui est essentiel pour de nombreuses applications PNL.
En plus de l'encodeur et du décodeur, le modèle T5 contient une « tête de modèle de langage » qui prédit le mot suivant dans une séquence basée sur les mots précédents. Ceci est essentiel pour les travaux de traduction et de production de texte, où le modèle doit fournir un résultat cohérent et naturel.
Le modèle T5 représente un réseau neuronal vaste et sophistiqué conçu pour un traitement très efficace et précis des entrées séquentielles. Il a suivi une formation approfondie sur un ensemble de données textuelles diversifié et peut effectuer avec compétence un large éventail de tâches de traitement du langage naturel.
T5Tokeniseur
T5Tokenizer est utilisé pour transformer un texte en une liste de jetons, chacun représentant un seul mot ou un signe de ponctuation. Le tokenizer insère en outre des jetons uniques dans le texte saisi pour indiquer le début et la fin du texte et distinguer diverses phrases.
Le T5Tokenizer utilise une combinaison de tokenisation au niveau des caractères et des mots et une stratégie de tokenisation au niveau des sous-mots comparable au tokenizer SentencePièce. Il sous-mote le texte saisi en fonction de la fréquence de chaque caractère ou séquence de caractères dans les données d'apprentissage. Cela aide le tokenizer à traiter les termes hors vocabulaire (OOV) qui n'apparaissent pas dans les données de formation mais apparaissent dans les données de test.
Le T5Tokenizer insère en outre des jetons uniques dans le texte pour indiquer le début et la fin des phrases et pour les diviser. Il ajoute les jetons s > et / s >, par exemple, pour signifier le début et la fin d'une phrase, et pad > pour indiquer un remplissage.
MODEL_NAME = "t5-base" tokenizer = T5Tokenizer.from_pretrained(MODEL_NAME, model_max_length= INPUT_MAX_LEN)
print("eos_token: {} and id: {}".format(tokenizer.eos_token, tokenizer.eos_token_id)) # End of token (eos_token)
print("unk_token: {} and id: {}".format(tokenizer.unk_token, tokenizer.eos_token_id)) # Unknown token (unk_token)
print("pad_token: {} and id: {}".format(tokenizer.pad_token, tokenizer.eos_token_id)) # Pad token (pad_token)

Préparation du jeu de données
Lorsque vous utilisez PyTorch, vous préparez généralement vos données à utiliser avec le modèle en utilisant une classe d'ensemble de données. La classe d'ensemble de données est responsable du chargement des données à partir du disque et de l'exécution des procédures de préparation requises, telles que la tokenisation et la numérisation. La classe doit également implémenter la fonction getitem, qui est utilisée pour obtenir un seul élément de l'ensemble de données par index.
La méthode init remplit l'ensemble de données avec la liste de textes, la liste d'étiquettes et le tokenizer. La fonction len renvoie le nombre d'échantillons dans l'ensemble de données. La fonction get item renvoie un seul élément d'un ensemble de données par index. Il accepte un index idx et génère l'entrée et les étiquettes tokenisées.
Il est également habituel d'inclure diverses étapes de prétraitement, telles que le remplissage et la troncature des entrées tokenisées. Vous pouvez également transformer les étiquettes en tenseurs.
class T5Dataset: def __init__(self, context, question, target): self.context = context self.question = question self.target = target self.tokenizer = tokenizer self.input_max_len = INPUT_MAX_LEN self.out_max_len = OUT_MAX_LEN def __len__(self): return len(self.context) def __getitem__(self, item): context = str(self.context[item]) context = " ".join(context.split()) question = str(self.question[item]) question = " ".join(question.split()) target = str(self.target[item]) target = " ".join(target.split()) inputs_encoding = self.tokenizer( context, question, add_special_tokens=True, max_length=self.input_max_len, padding = 'max_length', truncation='only_first', return_attention_mask=True, return_tensors="pt" ) output_encoding = self.tokenizer( target, None, add_special_tokens=True, max_length=self.out_max_len, padding = 'max_length', truncation= True, return_attention_mask=True, return_tensors="pt" ) inputs_ids = inputs_encoding["input_ids"].flatten() attention_mask = inputs_encoding["attention_mask"].flatten() labels = output_encoding["input_ids"] labels[labels == 0] = -100 # As per T5 Documentation labels = labels.flatten() out = { "context": context, "question": question, "answer": target, "inputs_ids": inputs_ids, "attention_mask": attention_mask, "targets": labels } return out Chargeur de données
La classe DataLoader charge les données en parallèle et par lots, ce qui permet de travailler avec de gros ensembles de données qui seraient autrement trop vastes pour être stockées en mémoire. Combinaison de la classe DataLoader avec une classe dataset contenant les données à charger.
Le chargeur de données est chargé d'itérer sur l'ensemble de données et de renvoyer un lot de données au modèle pour la formation ou l'évaluation lors de la formation d'un modèle de transformateur. La classe DataLoader propose divers paramètres pour contrôler le chargement et le prétraitement des données, notamment la taille du lot, le nombre de threads de travail et la nécessité de mélanger les données avant chaque époque.
class T5DatasetModule(pl.LightningDataModule): def __init__(self, df_train, df_valid): super().__init__() self.df_train = df_train self.df_valid = df_valid self.tokenizer = tokenizer self.input_max_len = INPUT_MAX_LEN self.out_max_len = OUT_MAX_LEN def setup(self, stage=None): self.train_dataset = T5Dataset( context=self.df_train.context.values, question=self.df_train.question.values, target=self.df_train.text.values ) self.valid_dataset = T5Dataset( context=self.df_valid.context.values, question=self.df_valid.question.values, target=self.df_valid.text.values ) def train_dataloader(self): return torch.utils.data.DataLoader( self.train_dataset, batch_size= TRAIN_BATCH_SIZE, shuffle=True, num_workers=4 ) def val_dataloader(self): return torch.utils.data.DataLoader( self.valid_dataset, batch_size= VALID_BATCH_SIZE, num_workers=1 )Développement de modèles
Lors de la création d'un modèle de transformateur dans PyTorch, vous commencez généralement par créer une nouvelle classe dérivée de la torche. nn.Module. Cette classe décrit l'architecture du modèle, y compris les couches et la fonction forward. La fonction init de la classe définit l'architecture du modèle, souvent en instanciant les différents niveaux du modèle et en les attribuant comme attributs de classe.
La méthode forward est chargée de transmettre les données à travers le modèle dans le sens direct. Cette méthode accepte les données d'entrée et applique les couches du modèle pour créer la sortie. La méthode forward doit implémenter la logique du modèle, telle que transmettre l'entrée à travers une séquence de couches et renvoyer le résultat.
La fonction init de la classe crée une couche d'intégration, une couche de transformateur et une couche entièrement connectée et les attribue comme attributs de classe. La méthode forward accepte les données entrantes x, les traite via les étapes données et renvoie le résultat. Lors de la formation d'un modèle de transformateur, le processus de formation comporte généralement deux étapes : la formation et la validation.
La méthode training_step précise la justification de la réalisation d'une seule étape de formation, qui comprend généralement :
- passage en avant à travers le modèle
- calculer la perte
- calcul des gradients
- Mise à jour des paramètres du modèle
La méthode val_step, comme la méthode training_step, est utilisée pour évaluer le modèle sur un ensemble de validation. Il comprend généralement :
- passage en avant à travers le modèle
- calculer les métriques d'évaluation
class T5Model(pl.LightningModule): def __init__(self): super().__init__() self.model = T5ForConditionalGeneration.from_pretrained(MODEL_NAME, return_dict=True) def forward(self, input_ids, attention_mask, labels=None): output = self.model( input_ids=input_ids, attention_mask=attention_mask, labels=labels ) return output.loss, output.logits def training_step(self, batch, batch_idx): input_ids = batch["inputs_ids"] attention_mask = batch["attention_mask"] labels= batch["targets"] loss, outputs = self(input_ids, attention_mask, labels) self.log("train_loss", loss, prog_bar=True, logger=True) return loss def validation_step(self, batch, batch_idx): input_ids = batch["inputs_ids"] attention_mask = batch["attention_mask"] labels= batch["targets"] loss, outputs = self(input_ids, attention_mask, labels) self.log("val_loss", loss, prog_bar=True, logger=True) return loss def configure_optimizers(self): return AdamW(self.parameters(), lr=0.0001)
Formation modèle
Itérer sur l'ensemble de données par lots, envoyer les entrées via le modèle et modifier les paramètres du modèle en fonction des gradients calculés et d'un ensemble de critères d'optimisation est habituel pour la formation d'un modèle de transformateur.
def run(): df_train, df_valid = train_test_split( df[0:10000], test_size=0.2, random_state=101 ) df_train = df_train.fillna("none") df_valid = df_valid.fillna("none") df_train['context'] = df_train['context'].apply(lambda x: " ".join(x.split())) df_valid['context'] = df_valid['context'].apply(lambda x: " ".join(x.split())) df_train['text'] = df_train['text'].apply(lambda x: " ".join(x.split())) df_valid['text'] = df_valid['text'].apply(lambda x: " ".join(x.split())) df_train['question'] = df_train['question'].apply(lambda x: " ".join(x.split())) df_valid['question'] = df_valid['question'].apply(lambda x: " ".join(x.split())) df_train = df_train.reset_index(drop=True) df_valid = df_valid.reset_index(drop=True) dataModule = T5DatasetModule(df_train, df_valid) dataModule.setup() device = DEVICE models = T5Model() models.to(device) checkpoint_callback = ModelCheckpoint( dirpath="/kaggle/working", filename="best_checkpoint", save_top_k=2, verbose=True, monitor="val_loss", mode="min" ) trainer = pl.Trainer( callbacks = checkpoint_callback, max_epochs= EPOCHS, gpus=1, accelerator="gpu" ) trainer.fit(models, dataModule) run()Prédiction du modèle
Pour faire des prédictions avec un modèle NLP affiné tel que T5 en utilisant une nouvelle entrée, vous pouvez suivre ces étapes :
- Prétraitez la nouvelle entrée : Tokenisez et prétraitez votre nouveau texte de saisie pour qu'il corresponde au prétraitement que vous avez appliqué à vos données d'entraînement. Assurez-vous qu'il est dans le format correct attendu par le modèle.
- Utilisez le modèle affiné pour l'inférence : Chargez votre modèle T5 affiné, que vous avez préalablement entraîné ou chargé à partir d'un point de contrôle.
- Générer des prédictions : Transmettez la nouvelle entrée prétraitée au modèle pour la prédiction. Dans le cas de T5, vous pouvez utiliser la méthode generate pour générer des réponses.
train_model = T5Model.load_from_checkpoint("/kaggle/working/best_checkpoint-v1.ckpt") train_model.freeze() def generate_question(context, question): inputs_encoding = tokenizer( context, question, add_special_tokens=True, max_length= INPUT_MAX_LEN, padding = 'max_length', truncation='only_first', return_attention_mask=True, return_tensors="pt" ) generate_ids = train_model.model.generate( input_ids = inputs_encoding["input_ids"], attention_mask = inputs_encoding["attention_mask"], max_length = INPUT_MAX_LEN, num_beams = 4, num_return_sequences = 1, no_repeat_ngram_size=2, early_stopping=True, ) preds = [ tokenizer.decode(gen_id, skip_special_tokens=True, clean_up_tokenization_spaces=True) for gen_id in generate_ids ] return "".join(preds)Prédiction
générons une prédiction en utilisant le modèle T5 affiné avec une nouvelle entrée :
context = « Regrouper des groupes de cas similaires, par exemple,
peut trouver des patients similaires, ou l'utiliser pour la segmentation de la clientèle dans le
domaine bancaire. Utiliser la technique d'association pour trouver des éléments ou des événements qui
coexistent souvent, par exemple, des produits d'épicerie qui sont habituellement achetés ensemble
par un client particulier. Utiliser la détection d'anomalies pour découvrir des anomalies
et des cas inhabituels, par exemple la détection de fraudes à la carte de crédit.
que = « quel est l’exemple de détection d’anomalies ? »
print(generate_question(context, que))

context = "Classification is used when your target is categorical, while regression is used when your target variable
is continuous. Both classification and regression belong to the category of supervised machine learning algorithms." que = "When is classification used?" print(generate_question(context, que))

Conclusion
Dans cet article, nous nous sommes lancés dans un voyage visant à affiner un modèle de traitement du langage naturel (NLP), en particulier le modèle T5, pour une tâche de réponse à des questions. Tout au long de ce processus, nous avons approfondi divers aspects du développement et du déploiement de modèles NLP.
Principales sorties:
- Explorer la structure du codeur-décodeur et les mécanismes d’auto-attention qui sous-tendent ses capacités.
- L’art du réglage des hyperparamètres est une compétence essentielle pour optimiser les performances du modèle.
- Expérimenter avec les taux d'apprentissage, la taille des lots et la taille des modèles nous a permis d'affiner le modèle efficacement.
- Maîtrise de la tokenisation, du remplissage et de la conversion de données texte brutes dans un format approprié pour la saisie du modèle.
- Plongé dans le réglage fin, y compris le chargement de poids pré-entraînés, la modification des couches de modèle et leur adaptation à des tâches spécifiques.
- J'ai appris à nettoyer et structurer les données, en les divisant en ensembles de formation et de validation.
- Démontré comment il pouvait générer des réponses ou des réponses basées sur le contexte d'entrée et les questions, démontrant son utilité dans le monde réel.
Foire aux Questions
Réponse Le réglage fin du PNL implique la modification des hyperparamètres et de l'architecture d'un modèle pré-entraîné pour optimiser ses performances pour une tâche ou un ensemble de données spécifique.
Réponse L'architecture Transformer est une architecture de réseau neuronal. Il excelle dans la gestion des données séquentielles et constitue la base de modèles comme T5. Il utilise des mécanismes d’auto-attention pour comprendre le contexte.
Réponse Dans les tâches séquence à séquence en PNL, nous utilisons la structure codeur-décodeur. L'encodeur traite les données d'entrée et le décodeur génère des données de sortie.
Réponse Oui, vous pouvez appliquer des modèles affinés à diverses tâches PNL réelles, notamment la génération de texte, la traduction et la réponse à des questions.
Réponse Pour commencer, vous pouvez explorer des bibliothèques telles que Hugging Face. Ces bibliothèques proposent des modèles et des outils pré-entraînés pour affiner vos ensembles de données. L’apprentissage des principes fondamentaux de la PNL et des concepts d’apprentissage profond est également crucial.
Les médias présentés dans cet article n'appartiennent pas à Analytics Vidhya et sont utilisés à la discrétion de l'auteur.
Services Connexes
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://www.analyticsvidhya.com/blog/2023/10/hugging-face-fine-tuning-tutorial/

