Introduction
La récupération augmentée-génération (RAG) a pris le monde d'assaut depuis sa création. RAG est ce qui est nécessaire pour que les grands modèles linguistiques (LLM) fournissent ou génèrent des réponses précises et factuelles. Nous résolvons la factualité des LLM par RAG, où nous essayons de donner au LLM un contexte contextuellement similaire à la requête de l'utilisateur afin que le LLM fonctionne avec ce contexte et génère une réponse factuellement correcte. Pour ce faire, nous représentons nos données et la requête de l'utilisateur sous la forme d'intégrations vectorielles et effectuons une similarité cosinus. Mais le problème est que toutes les approches traditionnelles représentent les données dans une seule intégration, ce qui n'est peut-être pas idéal pour de bon. systèmes de récupération. Dans ce guide, nous examinerons ColBERT qui effectue une récupération avec une meilleure précision que les modèles bi-encodeurs traditionnels.
Objectifs d'apprentissage
- Comprendre comment fonctionne la récupération dans RAG à un niveau élevé.
- Comprendre les limites de l'intégration unique lors de la récupération.
- Améliorez le contexte de récupération avec les intégrations de jetons de ColBERT.
- Découvrez comment l'interaction tardive de ColBERT améliore la récupération.
- Apprenez à travailler avec ColBERT pour une récupération précise.
Cet article a été publié dans le cadre du Blogathon sur la science des données.
Table des matières
Qu’est-ce que le RAG ?
Les LLM, bien que capables de générer un texte à la fois significatif et grammaticalement correct, ces LLM souffrent d'un problème appelé hallucination. Hallucination dans les LLM est le concept dans lequel les LLM génèrent en toute confiance de mauvaises réponses, c'est-à-dire qu'ils inventent de mauvaises réponses d'une manière qui nous fait croire qu'elles sont vraies. Cela constitue un problème majeur depuis l’introduction des LLM. Ces hallucinations conduisent à des réponses incorrectes et factuellement fausses. C'est pourquoi la génération augmentée de récupération a été introduite.
Dans RAG, nous prenons une liste de documents/morceaux de documents et encodons ces documents textuels dans une représentation numérique appelée incorporations vectorielles, où une incorporation vectorielle unique représente un seul morceau de document et les stocke dans une base de données appelée magasin de vecteur. Les modèles requis pour coder ces morceaux dans des intégrations sont appelés modèles de codage ou bi-encodeurs. Ces encodeurs sont formés sur un vaste corpus de données, ce qui les rend suffisamment puissants pour encoder des morceaux de documents dans une seule représentation d'intégration vectorielle.
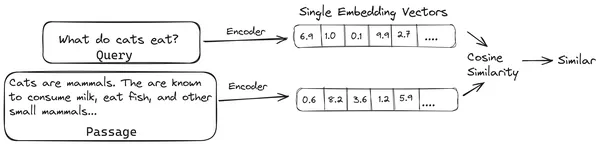
Désormais, lorsqu'un utilisateur pose une requête au LLM, nous transmettons cette requête au même encodeur pour produire une intégration vectorielle unique. Cette intégration est ensuite utilisée pour calculer le score de similarité avec diverses autres intégrations vectorielles des morceaux de document afin d'obtenir le morceau le plus pertinent du document. Le fragment le plus pertinent ou une liste des fragments les plus pertinents ainsi que la requête de l'utilisateur sont transmis au LLM. Le LLM reçoit ensuite ces informations contextuelles supplémentaires, puis génère une réponse alignée sur le contexte reçu de la requête de l'utilisateur. Cela garantit que le contenu généré par le LLM est factuel et peut être retracé si nécessaire.
Le problème avec les bi-encodeurs traditionnels
Le problème avec les modèles d'encodeurs traditionnels comme le tout-miniLM, OpenAI Le modèle d'intégration et d'autres modèles d'encodeur sont qu'ils compressent l'intégralité du texte en une seule représentation d'intégration vectorielle. Ces représentations d'incorporation de vecteur unique sont utiles car elles facilitent la récupération efficace et rapide de documents similaires. Cependant, le problème réside dans la contextualité entre la requête et le document. L'intégration d'un seul vecteur peut ne pas être suffisante pour stocker les informations contextuelles d'un morceau de document, créant ainsi un goulot d'étranglement d'informations.
Imaginez que 500 mots soient compressés en un seul vecteur de taille 782. Il se peut que cela ne soit pas suffisant pour représenter un tel morceau avec un seul vecteur incorporé, donnant ainsi des résultats de récupération médiocres dans la plupart des cas. La représentation vectorielle unique peut également échouer dans le cas de requêtes ou de documents complexes. Une de ces solutions serait de représenter le morceau de document ou une requête sous la forme d'une liste de vecteurs d'intégration au lieu d'un seul vecteur d'intégration, c'est là qu'intervient ColBERT.
Qu’est-ce que ColBERT ?
ColBERT (Contextual Late Interactions BERT) est un bi-encodeur qui représente le texte dans une représentation d'intégration multi-vecteur. Il prend en compte une requête ou un morceau de document/un petit document et crée des intégrations vectorielles au niveau du jeton. Autrement dit, chaque jeton obtient sa propre intégration vectorielle et la requête/le document est codé dans une liste d'intégrations vectorielles au niveau du jeton. Les intégrations au niveau du jeton sont générées à partir d'un pré-entraîné BERT modèle d'où le nom BERT.
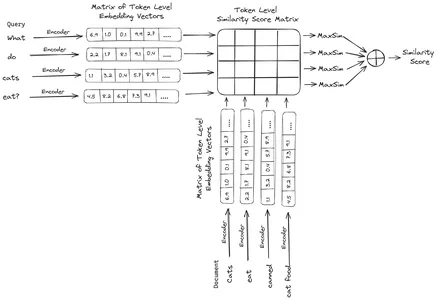
Ceux-ci sont ensuite stockés dans la base de données vectorielles. Désormais, lorsqu'une requête arrive, une liste d'intégrations au niveau du jeton est créée pour elle, puis une multiplication matricielle est effectuée entre la requête de l'utilisateur et chaque document, ce qui aboutit à une matrice contenant des scores de similarité. La similarité globale est obtenue en prenant la somme des similarités maximales entre les jetons de document pour chaque jeton de requête. La formule pour cela peut être vue dans la photo ci-dessous :
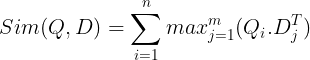
Ici, dans l'équation ci-dessus, nous voyons que nous faisons un produit scalaire entre la matrice de jetons de requête (contenant N intégrations vectorielles de niveau jeton) et la matrice de transposition de jetons de document (contenant M intégrations vectorielles de niveau jeton), puis nous prenons la similarité maximale. croisez les jetons de document pour chaque jeton de requête. On fait ensuite la somme de toutes ces similarités maximales, ce qui nous donne le score final de similarité entre le document et la requête. La raison pour laquelle cela produit une récupération efficace et précise est que nous avons ici une interaction au niveau du jeton, ce qui laisse place à une compréhension plus contextuelle entre la requête et le document.
Pourquoi le nom ColBERT ?
Comme nous calculons la liste des vecteurs d'intégration avant lui-même et effectuons cette opération MaxSim (similarité maximale) uniquement pendant l'inférence du modèle, l'appelant ainsi une étape d'interaction tardive, et comme nous obtenons plus d'informations contextuelles grâce aux interactions au niveau du jeton, cela s'appelle contextuel. interactions tardives. D’où le nom d’Interactions tardives contextuelles BERT ou ColBERT. Ces calculs peuvent être effectués en parallèle et peuvent donc être calculés efficacement. Enfin, une préoccupation concerne l’espace, c’est-à-dire qu’il faut beaucoup d’espace pour stocker cette liste d’intégrations vectorielles au niveau du jeton. Ce problème a été résolu dans ColBERTv2, où les plongements sont compressés grâce à la technique appelée compression résiduelle, optimisant ainsi l'espace utilisé.
ColBERT pratique avec exemple
Dans cette section, nous nous familiariserons avec le ColBERT et vérifierons même ses performances par rapport à un modèle d'intégration classique.
Étape 1 : Télécharger les bibliothèques
Nous allons commencer par télécharger la bibliothèque suivante :
!pip install ragatouille langchain langchain_openai chromadb einops sentence-transformers tiktoken- RAGatouille : Cette bibliothèque nous permet de travailler avec des méthodes de récupération de pointe (SOTA) comme ColBERT d'une manière facile à utiliser. Il fournit des options pour créer des index sur les ensembles de données, interroger dessus et nous permet même de former un modèle ColBERT sur nos données.
- Chaîne Lang : Cette bibliothèque nous permettra de travailler avec les modèles d'intégration open source afin que nous puissions tester le fonctionnement des autres modèles d'intégration par rapport au ColBERT.
- langchain_openai : Installe le LangChaîne dépendances pour OpenAI. Nous travaillerons même avec le modèle OpenAI Embedding pour vérifier ses performances par rapport au ColBERT.
- ChromaDB : Cette bibliothèque nous permettra de créer un magasin de vecteurs dans notre environnement afin que nous puissions sauvegarder les plongements que nous avons créés sur nos données et effectuer ultérieurement une recherche sémantique entre la requête et les plongements stockés.
- einops : Cette bibliothèque est nécessaire pour des multiplications efficaces de matrices tensorielles.
- transformateurs de phrases et par jeton tiktok La bibliothèque est nécessaire pour que les modèles d'intégration open source fonctionnent correctement.
Étape 2 : Télécharger le modèle pré-entraîné
Dans la prochaine étape, nous téléchargerons le modèle ColBERT pré-entraîné. Pour cela, le code sera
from ragatouille import RAGPretrainedModel
RAG = RAGPretrainedModel.from_pretrained("colbert-ir/colbertv2.0")- Nous importons d'abord la classe RAGPretrainedModel depuis la bibliothèque RAGatouille.
- Ensuite, nous appelons .from_pretrained() et donnons le nom du modèle, c'est-à-dire « colbert-ir/colbertv2.0 ».
L'exécution du code ci-dessus instanciera un modèle ColBERT RAG. Téléchargeons maintenant une page Wikipédia et effectuons la récupération à partir de celle-ci. Pour cela, le code sera :
from ragatouille.utils import get_wikipedia_page
document = get_wikipedia_page("Elon_Musk")
print("Word Count:",len(document))
print(document[:1000])Le RAGatouille est livré avec une fonction pratique appelée get_wikipedia_page qui récupère une chaîne et obtient la page Wikipédia correspondante. Ici, nous téléchargeons le contenu Wikipédia sur Elon Musk et le stockons dans le document variable. Imprimons le nombre de mots présents dans le document et les premières lignes du document.
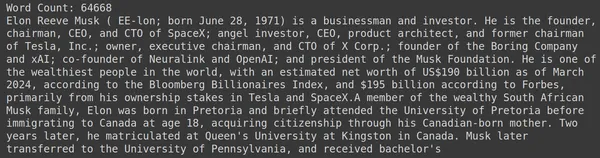
Ici, nous pouvons voir le résultat sur la photo. On constate qu’il y a au total 64,668 XNUMX mots sur la page Wikipédia d’Elon Musk.
Étape 3 : Indexation
Nous allons maintenant créer un index sur ce document.
RAG.index(
# List of Documents
collection=[document],
# List of IDs for the above Documents
document_ids=['elon_musk'],
# List of Dictionaries for the metadata for the above Documents
document_metadatas=[{"entity": "person", "source": "wikipedia"}],
# Name of the index
index_name="Elon2",
# Chunk Size of the Document Chunks
max_document_length=256,
# Wether to Split Document or Not
split_documents=True
)Ici, nous appelons le .index() du RAG pour indexer notre document. A cela, nous passons ce qui suit :
- collection: Il s'agit d'une liste de documents que nous souhaitons indexer. Nous n'avons ici qu'un seul document, donc une liste d'un seul document.
- ID_document : Chaque document attend un identifiant de document unique. Ici, nous lui passons le nom elon_musk car le document concerne Elon Musk.
- document_metadata : Chaque document possède ses métadonnées. Il s'agit à nouveau d'une liste de dictionnaires, où chaque dictionnaire contient des métadonnées de paire clé-valeur pour un document particulier.
- nom_index : Le nom de l'index que nous créons. Appelons-le Elon2.
- max_document_size : Ceci est similaire à la taille du morceau. Nous spécifions la taille de chaque morceau de document. Ici, nous lui donnons une valeur de 256. Si nous ne spécifions aucune valeur, 256 sera prise comme taille de bloc par défaut.
- split_documents : Il s'agit d'une valeur booléenne, où True indique que nous souhaitons diviser notre document en fonction de la taille de bloc donnée, et False indique que nous souhaitons stocker l'intégralité du document en un seul bloc.
L'exécution du code ci-dessus divisera notre document en tailles de 256 par bloc, puis les intégrera via le modèle ColBERT, qui produira une liste d'intégrations vectorielles au niveau du jeton pour chaque morceau et enfin les stockera dans un index. Cette étape prendra un peu de temps à s'exécuter et peut être accélérée si vous disposez d'un GPU. Enfin, il crée un répertoire dans lequel notre index est stocké. Ici le répertoire sera « .ragatouille/colbert/indexes/Elon2 »
Étape 4 : Requête générale
Maintenant, nous allons commencer la recherche. Pour cela, le code sera
results = RAG.search(query="What companies did Elon Musk find?", k=3, index_name='Elon2')
for i, doc, in enumerate(results):
print(f"---------------------------------- doc-{i} ------------------------------------")
print(doc["content"])- Ici, nous appelons d’abord la méthode .search() de l’objet RAG
- A cela, nous donnons les variables qui incluent le nom de la requête, k (nombre de documents à récupérer) et le nom de l'index à rechercher.
- Nous fournissons ici la requête « Quelles entreprises Elon Musk a-t-il trouvées ? » Le résultat obtenu sera dans une liste au format dictionnaire, qui contient les clés telles que le contenu, le score, le classement, le document_id, le passage_id et le document_metadata.
- Nous travaillons donc avec le code ci-dessous pour imprimer les documents récupérés de manière soignée
- Ici, nous parcourons la liste des dictionnaires et imprimons le contenu des documents
L'exécution du code produira les résultats suivants :
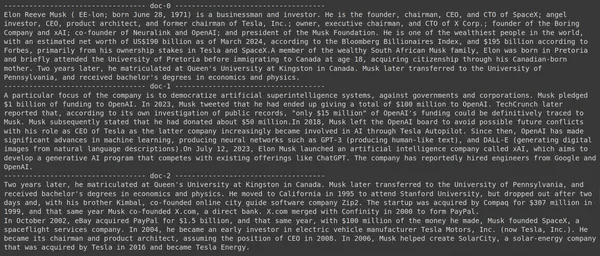
Sur la photo, on peut voir que le premier et le dernier document couvrent entièrement les différentes sociétés fondées par Elon Musk. Le ColBERT a pu récupérer correctement les fragments pertinents nécessaires pour répondre à la requête.
Étape 5 : Requête spécifique
Allons maintenant plus loin et posons-lui une question spécifique.
results = RAG.search(query="How much Tesla stocks did Elon sold in
Decemeber 2022?", k=3, index_name='Elon2')
for i, doc, in enumerate(results):
print(f"---------------
------------------- doc-{i} ------------------------------------")
print(doc["content"])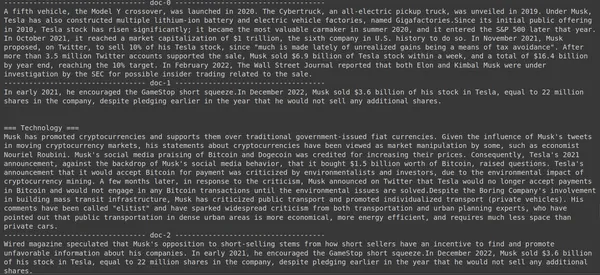
Ici, dans le code ci-dessus, nous posons une question très spécifique sur le nombre d'actions de Tesla Elon vendues au cours du mois de décembre 2022. Nous pouvons voir le résultat ici. Le doc-1 contient la réponse à la question. Elon a vendu pour 3.6 milliards de dollars de ses actions Tesla. Encore une fois, ColBERT a réussi à récupérer le morceau pertinent pour la requête donnée.
Étape 6 : tester d'autres modèles
Essayons maintenant la même question avec les autres modèles d'intégration à la fois open source et fermés ici :
from langchain_community.embeddings import HuggingFaceEmbeddings
from transformers import AutoModel
model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-en', trust_remote_code=True)
model_name = "jinaai/jina-embeddings-v2-base-en"
model_kwargs = {'device': 'cpu'}
embeddings = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
)
- Nous commençons par télécharger le modèle via la classe AutoModel de la bibliothèque Transformers.
- Ensuite, nous stockons le model_name et le model_kwargs dans leurs variables respectives.
- Maintenant, pour travailler avec ce modèle dans LangChain, nous importons les HuggingFaceEmbeddings du LangChaîne et donnez-lui le nom du modèle et le model_kwargs.
L'exécution de ce code téléchargera et chargera le modèle d'intégration Jina afin que nous puissions travailler avec lui.
Étape 7 : Créer des intégrations
Maintenant, nous devons commencer à diviser notre document, puis en créer des intégrations et les stocker dans le magasin de vecteurs Chroma. Pour cela, nous travaillons avec le code suivant :
from langchain_community.vectorstores import Chroma
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=256,
chunk_overlap=0)
splits = text_splitter.split_text(document)
vectorstore = Chroma.from_texts(texts=splits,
embedding=embeddings,
collection_name="elon")
retriever = vectorstore.as_retriever(search_kwargs = {'k':3})- On commence par importer le Chroma et le RecursiveCharacterTextSplitter depuis la bibliothèque LangChain
- Ensuite, nous instancions un text_splitter en appelant le .from_tiktoken_encoder du RecursiveCharacterTextSplitter et en lui passant le chunk_size et le chunk_overlap.
- Ici, nous utiliserons le même chunk_size que celui que nous avons fourni au ColBERT
- Ensuite, nous appelons la méthode .split_text() de ce text_splitter et lui donnons le document contenant des informations Wikipédia sur Elon Musk. Il divise ensuite le document en fonction de la taille de fragment donnée et enfin, la liste des fragments de document est stockée dans la variable splits.
- Enfin, nous appelons la fonction .from_texts() de la classe Chroma pour créer un magasin de vecteurs. À cette fonction, nous donnons les fractionnements, le modèle d'intégration et le nom_collection
- Maintenant, nous créons un récupérateur en appelant la fonction .as_retriever() de l'objet de magasin vectoriel. On donne 3 pour la valeur k
L'exécution de ce code prendra notre document, le divisera en documents plus petits de taille 256 par morceau, puis intégrera ces petits morceaux avec le modèle d'intégration Jina et stockera ces vecteurs d'intégration dans le magasin de vecteurs de chrominance.
Étape 8 : Création d'un Retriever
Enfin, nous créons un retriever à partir de celui-ci. Nous allons maintenant effectuer une recherche vectorielle et vérifier les résultats.
docs = retriever.get_relevant_documents("What companies did Elon Musk find?",)
for i, doc in enumerate(docs):
print(f"---------------------------------- doc-{i} ------------------------------------")
print(doc.page_content)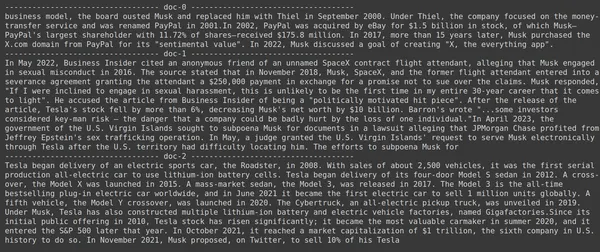
- Nous appelons la fonction .get_relevent_documents() de l'objet retriever et lui donnons la même requête.
- Ensuite, nous imprimons soigneusement les 3 principaux documents récupérés.
- Sur la photo, nous pouvons voir que Jina Embedder, bien qu'il s'agisse d'un modèle d'intégration populaire, la récupération de notre requête est médiocre. Il n'a pas réussi à obtenir les bons morceaux de document.
Nous pouvons clairement repérer la différence entre Jina, le modèle d'intégration qui représente chaque morceau comme une intégration vectorielle unique, et le modèle ColBERT qui représente chaque morceau comme une liste de vecteurs d'intégration au niveau du jeton. Le ColBERT surpasse clairement dans ce cas.
Étape 9 : Test du modèle d'intégration d'OpenAI
Essayons maintenant d'utiliser un modèle d'intégration à source fermée comme le modèle OpenAI Embedding.
import os
os.environ["OPENAI_API_KEY"] = "Your API Key"
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
model_name = "gpt-4",
chunk_size = 256,
chunk_overlap = 0,
)
splits = text_splitter.split_text(document)
vectorstore = Chroma.from_texts(texts=splits,
embedding=embeddings,
collection_name="elon_collection")
retriever = vectorstore.as_retriever(search_kwargs = {'k':3})Ici le code est très similaire à celui que nous venons d'écrire
- La seule différence est que nous transmettons la clé API OpenAI pour définir la variable d'environnement.
- Nous créons ensuite une instance du modèle OpenAI Embedding en l'important depuis LangChain.
- Et lors de la création du nom de la collection, nous donnons un nom de collection différent, de sorte que les intégrations du modèle OpenAI Embedding soient stockées dans une collection différente.
L'exécution de ce code prendra à nouveau nos documents, les divisera en documents plus petits de taille 256, puis les intégrera dans une représentation d'intégration vectorielle unique avec le modèle d'intégration OpenAI et enfin stockera ces intégrations dans le Chroma Vector Store. Essayons maintenant de récupérer les documents pertinents pour l'autre question.
docs = retriever.get_relevant_documents("How much Tesla stocks did Elon sold in Decemeber 2022?",)
for i, doc in enumerate(docs):
print(f"---------------------------------- doc-{i} ------------------------------------")
print(doc.page_content)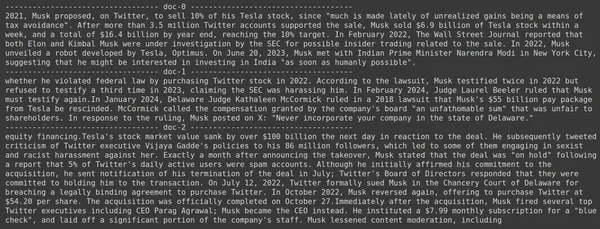
- Nous constatons que la réponse que nous attendons ne se trouve pas dans les fragments récupérés.
- Le premier morceau contient des informations sur les actions Tesla en 2022 mais ne parle pas de leur vente par Elon.
- La même chose peut être constatée avec les deux morceaux de documents restants, où les informations qu'ils contiennent concernent Tesla et ses actions, mais ce ne sont pas les informations que nous attendons.
- Les morceaux récupérés ci-dessus ne fourniront pas le contexte permettant au LLM de répondre à la requête que nous avons fournie.
Même ici, nous pouvons voir une nette différence entre la représentation d'intégration à vecteur unique et la représentation d'intégration multi-vecteur. Les représentations multi-intégration capturent clairement les requêtes complexes, ce qui aboutit à des récupérations plus précises.
Conclusion
En conclusion, ColBERT démontre une avancée significative dans les performances de récupération par rapport aux modèles bi-encodeurs traditionnels en représentant le texte sous forme d'intégrations multi-vecteurs au niveau du jeton. Cette approche permet une compréhension contextuelle plus nuancée entre les requêtes et les documents, conduisant à des résultats de récupération plus précis et atténuant le problème des hallucinations couramment observées dans les LLM.
Faits marquants
- RAG aborde le problème des hallucinations dans les LLM en fournissant des informations contextuelles pour la génération de réponses factuelles.
- Les bi-encodeurs traditionnels souffrent d'un goulot d'étranglement en matière d'informations en raison de la compression de textes entiers en intégrations vectorielles uniques, ce qui entraîne une précision de récupération inférieure à la moyenne.
- ColBERT, avec sa représentation d'intégration au niveau du jeton, facilite une meilleure compréhension contextuelle entre les requêtes et les documents, conduisant à de meilleures performances de récupération.
- L'étape d'interaction tardive dans ColBERT, combinée aux interactions au niveau du jeton, améliore la précision de la récupération en tenant compte des nuances contextuelles.
- ColBERTv2 optimise l'espace de stockage grâce à la compression résiduelle tout en maintenant l'efficacité de la récupération.
- Des expériences pratiques démontrent la supériorité de ColBERT en termes de performances de récupération par rapport aux modèles d'intégration traditionnels et open source comme Jina et OpenAI Embedding.
Foire aux Questions
R. Les bi-encodeurs traditionnels compressent des textes entiers en intégrations vectorielles uniques, ce qui risque de perdre des informations contextuelles. Cela limite leur efficacité dans les tâches de récupération, notamment avec des requêtes ou des documents complexes.
A. ColBERT (Contextual Late Interactions BERT) est un modèle bi-encodeur qui représente le texte à l'aide d'incorporations vectorielles au niveau du jeton. Il permet une compréhension contextuelle plus nuancée entre les requêtes et les documents, améliorant ainsi la précision de la récupération.
A. ColBERT génère des intégrations au niveau des jetons pour les requêtes et les documents, effectue une multiplication matricielle pour calculer les scores de similarité, puis sélectionne les informations les plus pertinentes en fonction d'une similarité maximale entre les jetons. Cela permet une récupération efficace avec une compréhension contextuelle.
R. ColBERTv2 optimise l'espace grâce à la méthode de compression résiduelle, réduisant ainsi les besoins de stockage pour les intégrations au niveau des jetons tout en maintenant la précision de la récupération.
R. Vous pouvez utiliser des bibliothèques comme RAGatouille pour travailler facilement avec ColBERT. En indexant les documents et les requêtes, vous pouvez effectuer des tâches de récupération efficaces et générer des réponses précises et adaptées au contexte.
Les médias présentés dans cet article n'appartiennent pas à Analytics Vidhya et sont utilisés à la discrétion de l'auteur.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://www.analyticsvidhya.com/blog/2024/04/colbert-improve-retrieval-performance-with-token-level-vector-embeddings/

