607 8
| SEO | - 13 min read - | 2 janvier 2024 |


L'API Serpstat possède de nombreux points de terminaison englobant pratiquement toutes les facettes du flux de travail SEO, de la recherche de mots clés à l'analyse des backlinks. Le point de terminaison Domain Keywords peut être utilisé non seulement pour extraire les données brutes sur votre client et ses concurrents, mais également pour utiliser des techniques de science des données pour générer des informations. Ci-dessous, nous montrerons comment procéder en utilisant Python.
Les informations pourraient être utilisées dans le cadre d'un pipeline de données de cloud computing pour alimenter vos rapports de tableau de bord SEO tels que Looker, Power BI, etc.
Obtenez votre jeton API
Vous aurez besoin d'un jeton API avant de pouvoir interroger l'API SERPSTAT, qui apparaîtra sur n'importe quelle page de documentation, telle que la page principale de l'API, comme indiqué ci-dessous:

Une fois que vous avez copié votre jeton API, vous pouvez l'utiliser lorsque vous démarrez votre notebook Jupyter iPython.
Démarrez votre bloc-notes Jupyter iPython
Tout le code Python sera exécuté dans l'environnement de notebook Jupyter iPython. De même, le code s'exécutera dans un notebook COLABs si telle est votre préférence. Une fois que cela est opérationnel, importez les fonctions contenues dans les bibliothèques :
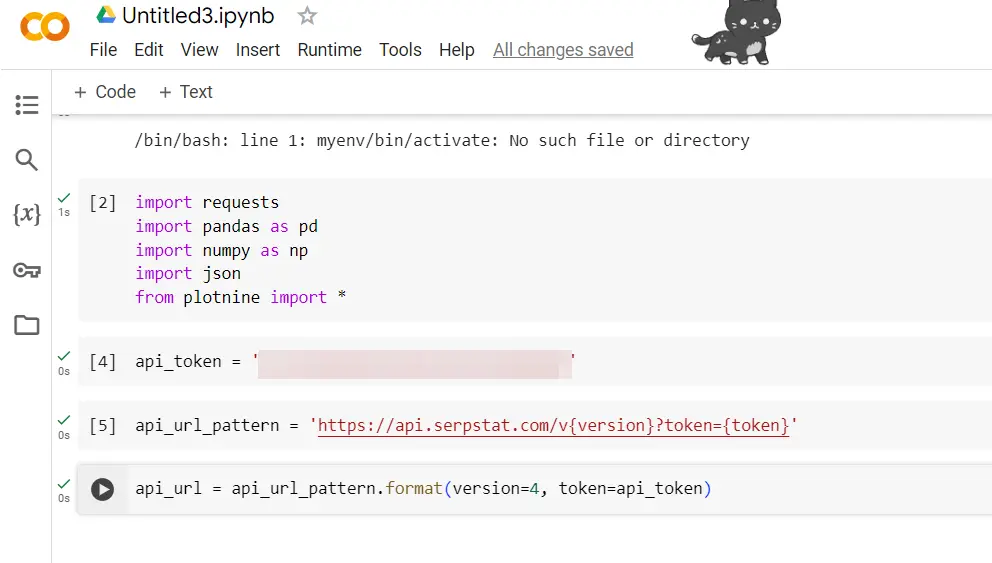
demandes d'importation
importer des pandas en tant que pd
importer numpy en tant que np
importer json
à partir de l'importation de plotnine *
Pour effectuer des appels API, vous aurez besoin de la bibliothèque de requêtes.
Pour gérer les trames de données, comme Excel en Python, nous utiliserons Python et attribuerons « pd » comme alias abrégé, simplifiant ainsi l'utilisation des fonctions pandas. Nous utiliserons également Numpy, en abrégé « np », pour manipuler les données dans des trames de données.
Les données des API sont souvent au format dictionnaire, le JSON nous aidera donc à décompresser les résultats dans des structures de données que nous pouvons transmettre à un bloc de données.
api_token = 'votre clé API'
Cela a été obtenu plus tôt (voir ci-dessus).
api_url_pattern = 'https://api.serpstat.com/v{version}?token={token}»
Nous définirons un modèle d'URL qui nous permettra d'interroger différents points de terminaison de l'API Serpstat. La version actuelle est APIv4. Étant donné que vous appellerez l'interface de programmation d'application plusieurs fois, cela évitera la saisie de code répétitif.
api_url = api_url_pattern.format(version=4, token=api_token)
Définissez l'URL de l'API pour incorporer la version de l'API et votre jeton API.
Obtenir des mots-clés de domaine
La partie passionnante. Nous pouvons désormais extraire des mots-clés pour n'importe quel domaine visible en interrogeant le Mots-clés du domaine point final. Cela affichera tous les mots-clés qu'un domaine classe dans le top 100 pour un moteur de recherche donné.
Nous commençons par définir les paramètres d'entrée requis par l'API :
domain_keyword_params = {
"id": "1",
"method": "SerpstatDomainProcedure.getDomainKeywords",
"params": {
"domain": "deel.com",
"se": "g_uk",
"withSubdomains": False,
"sort": {
"region_queries_count": "desc"
},
"minusKeywords": [
"deel", "deels"
],
"size": "1000",
"filters": {
"right_spelling": False
}
}
}
Une chose à noter : le point de terminaison des mots-clés de domaine est accessible en définissant la méthode sur « SerpstatDomainProcedure.getDomainKeywords »
Vous devrez définir votre nom de domaine "domaine" ci-dessous et votre moteur de recherche sous "g_uk".
Dans notre cas, nous allons examiner les mots-clés de deel.com dans Google UK. Une liste complète des moteurs de recherche est disponible ici qui couvre les régions du monde entier de Google et de Bing US.
Les options supplémentaires incluent les mots-clés négatifs (correspondance négative). Dans notre cas, nous ne nous intéressons qu'aux mots-clés sans marque pour comprendre d'où vient le trafic organique.
Nous avons également fixé le "Taille" paramètre à 1,000 XNUMX, ce qui correspond à la sortie maximale de lignes possible.
Il existe d'autres paramètres intéressants comme pouvoir restreindre l'API à inclure certains mots-clés ("mots clés") ou les URL de sites dans le domaine ("URL").
Avec le paramètre défini, nous pouvons faire la demande en utilisant le code ci-dessous :
domain_keyword_resp = requests.post(api_url, json=domain_keyword_params)
if domain_keyword_resp.status_code == 200:
domain_keyword_result = domain_keyword_resp.json()
print(domain_keyword_result)
else:
print(domain_keyword_resp.text)
Les résultats de l'appel API sont stockés dans domaine_mot-clé_resp. Nous lirons la réponse à l'aide de la fonction json, en stockant les données dans domaine_keyword_result.
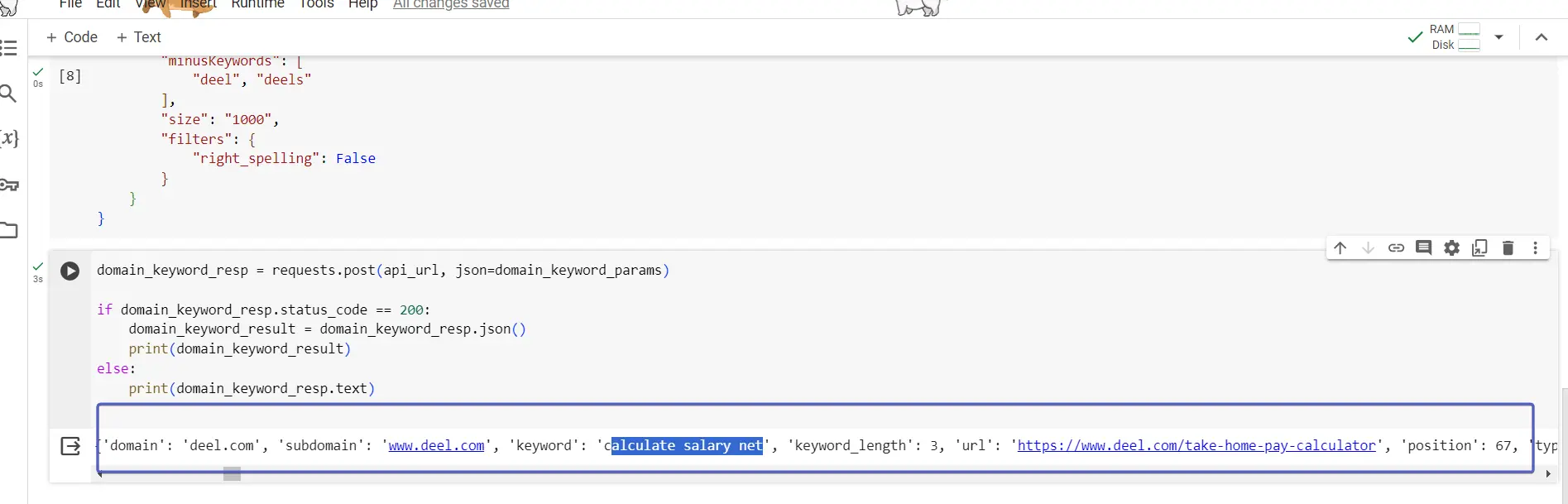
La structure if else est utilisée pour vous donner des informations au cas où l'appel d'API ne fonctionnerait pas comme prévu, vous montrant quelle est la réponse de l'API s'il n'y a pas de données ou une erreur lors de l'appel.
Exécution des impressions d'appels domaine_keyword_result qui ressemble à ceci :
{'id': '1',
'result':
{'data': [
{'domain': 'deel.com', 'subdomain': 'www.deel.com', 'keyword':
'support for dell', 'keyword_length': 3, 'url': 'https://www.deel.com/',
'position': 73, 'types': ['pic', 'kn_graph_card', 'related_search',
'a_box_some', 'snip_breadcrumbs'], 'found_results': 830000000,
'cost': 0.31, 'concurrency': 3, 'region_queries_count': 33100,
'region_queries_count_wide': 0, 'geo_names': [], 'traff': 0,
'difficulty': 44.02206115387234, 'dynamic': None},
{'domain': 'deel.com', 'subdomain': 'www.deel.com',
'keyword': 'hr and go',
'keyword_length': 3, 'url': 'https://www.deel.com/',
'position': 67, 'types': ['related_search', 'snip_breadcrumbs'],
'found_results': 6120000000, 'cost': 0.18, 'concurrency': 4,
'region_queries_count': 12100, 'region_queries_count_wide': 0,
'geo_names': [], 'traff': 0, 'difficulty': 15.465889053157944,
'dynamic': 3},
Lorsque vous travaillez avec une API, il est important d'imprimer la structure des données afin que vous sachiez comment analyser les données dans un format utilisable. Cela ne produit pas un dictionnaire avec plusieurs clés, où les données souhaitées sont contenues sous les clés de données de résultat. Les valeurs des données se trouvent dans une liste de dictionnaires où chaque dictionnaire représente un mot-clé.
Nous avons produit le code ci-dessous pour extraire les données de domaine_keyword_result et poussez-le vers le domaine_keyword_df trame de données:
domain_keyword_df = pd.DataFrame(domain_keyword_result['result']['data'])
Affichons le dataframe :
affichage (domain_keyword_df)
Qui ressemble à :
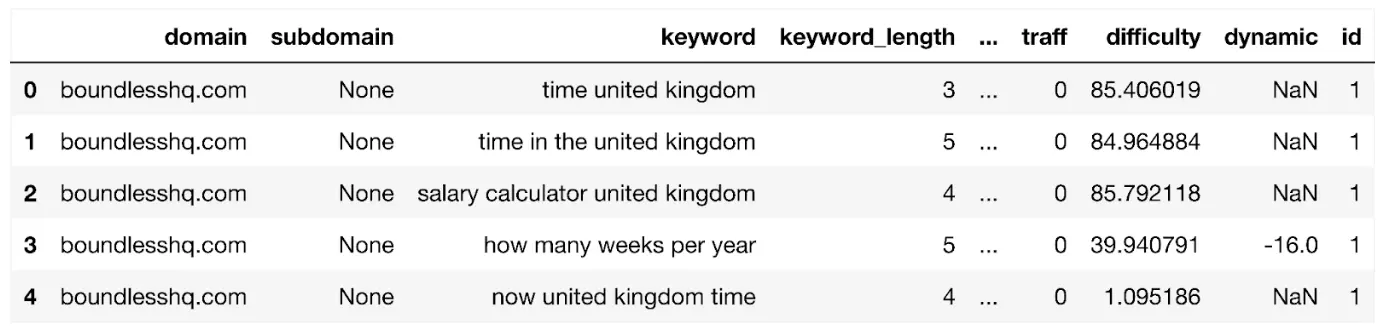
Le dataframe affiche tous les mots-clés du domaine jusqu'à un maximum de 1,000 XNUMX lignes. Il contient des champs de colonnes tels que :
- région_queries_count: volume de recherche dans votre région cible
- url: l'URL de classement du mot-clé
- position: rang SERP
- types: fonctionnalités SERP
- concurrence: le nombre d'annonces de recherche payantes qui peuvent indiquer le niveau d'intention transactionnelle et/ou commerciale.
Si vous en vouliez plus parce que vous travaillez sur un site plus grand, vous pouvez :
2.Exécutez plusieurs appels de mots-clés de domaine en utilisant le code ci-dessus sur ces URL de site dans le cadre d'une boucle for où vous spécifiez l'URL comme paramètre d'entrée pour 'URL'.
Créer des fonctionnalités de données
Pour obtenir des informations, nous souhaiterons créer des fonctionnalités qui aideront à résumer les données brutes. Conformément aux meilleures pratiques, nous allons créer une copie du dataframe et l'enregistrer dans un nouveau dataframe appelé dk_enhanced_df.
dk_enhanced_df = domain_keyword_df.copy()
Définition d'une nouvelle colonne appelée 'compter' nous permettra de compter littéralement les choses comme vous le verrez plus tard.
dk_enhanced_df['count'] = 1
Nous souhaitons également créer une colonne personnalisée appelée « serp » indiquant la catégorie de page SERP qui peut être utile pour voir la répartition des positions du site par SERP et insérée dans les rapports du tableau de bord.
<code data-code="dk_enhanced_df['serp'] = np.where(dk_enhanced_df['position'] dk_enhanced_df['serveur'] = np.où(dk_enhanced_df['positionner'] < 11, «1 ', 'Nulle part') dk_enhanced_df['serveur'] = np.où(dk_enhanced_df['positionner'].entre(11, 20), «2 ', dk_enhanced_df['serveur']) dk_enhanced_df['serveur'] = np.où(dk_enhanced_df['positionner'].entre(21, 30), «3 ', dk_enhanced_df['serveur']) dk_enhanced_df['serveur'] = np.où(dk_enhanced_df['positionner'].entre(31, 99), '4+', dk_enhanced_df['serveur'])
Le SERP a été codé ci-dessus en utilisant le numpy.où fonction, qui ressemble à la version Python de l'instruction if d'Excel plus familière.
Si vous notez la colonne types, les valeurs contiennent une liste des types de résultats de recherche universels affichés sur le moteur de recherche pour le mot-clé.
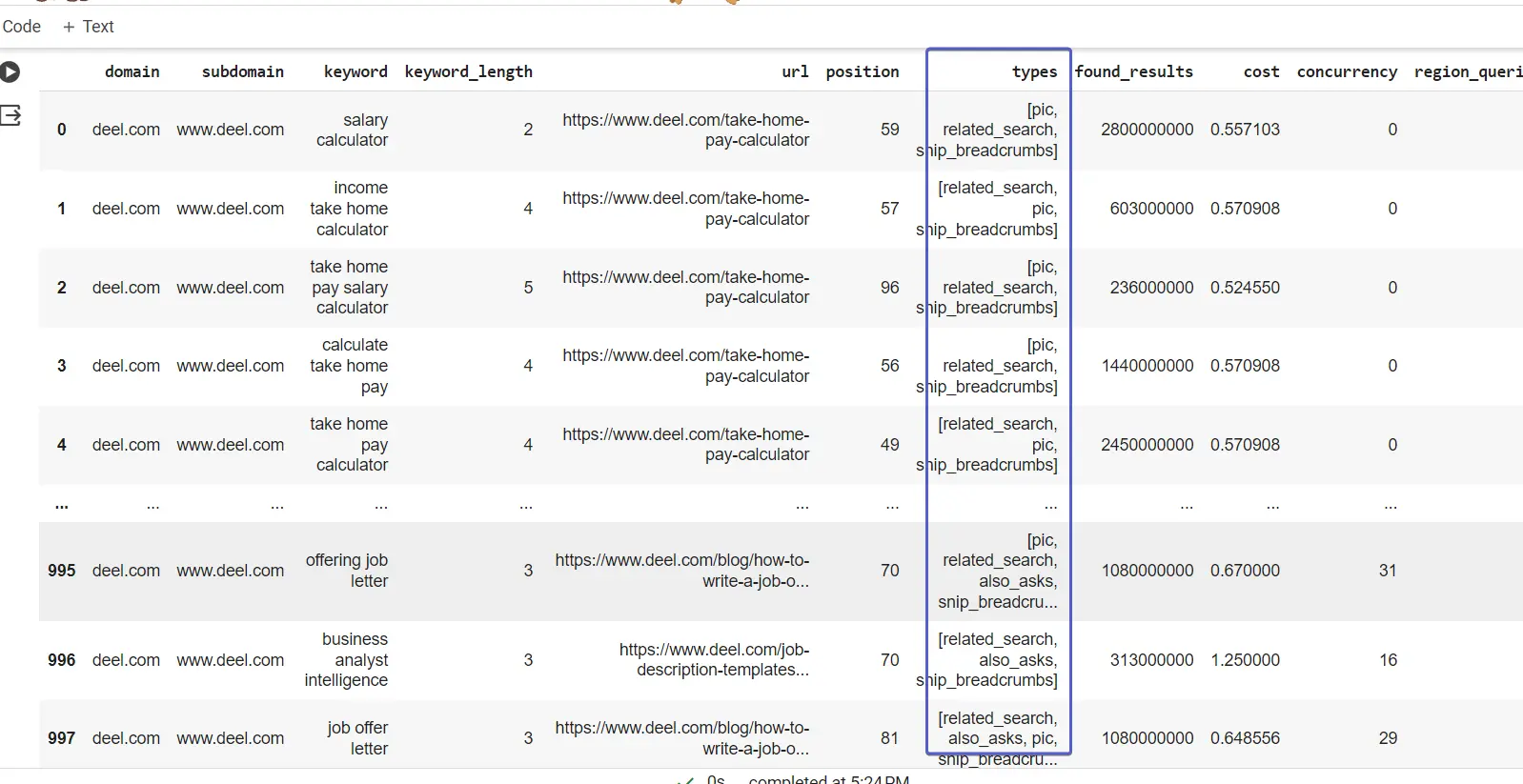
Nous pouvons déballer cela et faciliter l'analyse en utilisant le encodage à chaud (OHE). OHE créera des colonnes pour toutes les valeurs de type de résultat et placera un 1 là où un résultat existe pour le mot-clé :
types_dummies = pd.get_dummies(dk_enhanced_df['types'].apply(pd.Series).stack()).
somme(niveau=0)
Concaténez les colonnes de type de résultats codés à chaud avec le dk_enhanced_df Trame de données
dk_enhanced_df = pd.concat([dk_enhanced_df.drop(columns=['types']), types_dummies], axis=1)
affichage (dk_enhanced_df)

Grâce à OHE et aux autres améliorations, nous disposons désormais d'un cadre de données étendu avec des colonnes qui facilitent l'analyse et la génération d'informations.
Commencez votre parcours SEO en toute confiance !
Inscrivez-vous à notre essai de 7 jours et plongez dans le monde de l'analyse SEO avancée à l'aide de notre API. Aucun engagement, juste une pure exploration.
Explorer les données des mots clés du domaine
Nous commencerons par examiner les propriétés statistiques des données de mots-clés du domaine à l'aide de l'outil décris() fonction:
dk_enhanced_df.describe()
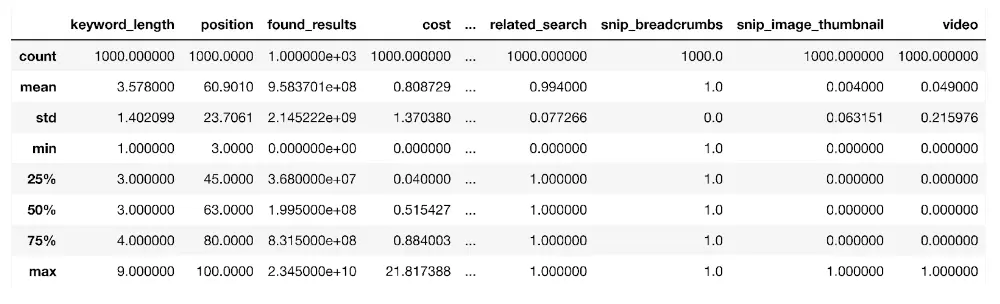
La fonction prend toutes les colonnes numériques d'une trame de données pour estimer leurs propriétés statistiques telles que la moyenne (moyenne), l'écart type (std) qui mesure le taux de dispersion par rapport à la moyenne, le nombre de points de données (compte) et le centiles tels que le 25e (25 %), comme indiqué ci-dessus.
Bien que la fonction soit utile en tant que résumé, d'un point de vue commercial, il est souvent utile d'agréger les données. Par exemple, en utilisant la combinaison de par groupe ainsi que agg fonctions, nous pouvons compter le nombre de mots-clés sur SERP 1 et ainsi de suite en utilisant le code ci-dessous :
serp_agg = dk_enhanced_df.groupby('serp').agg({'count': 'sum'}).reset_index()
La fonction groupby regroupe la trame de données par colonne (un peu comme le fait un tableau croisé dynamique Excel), puis agrège les autres colonnes. Dans notre cas d'utilisation, nous regroupons par SERP pour compter le nombre de mots-clés présents dans chaque SERP, comme indiqué ci-dessous :
affichage (serp_agg)
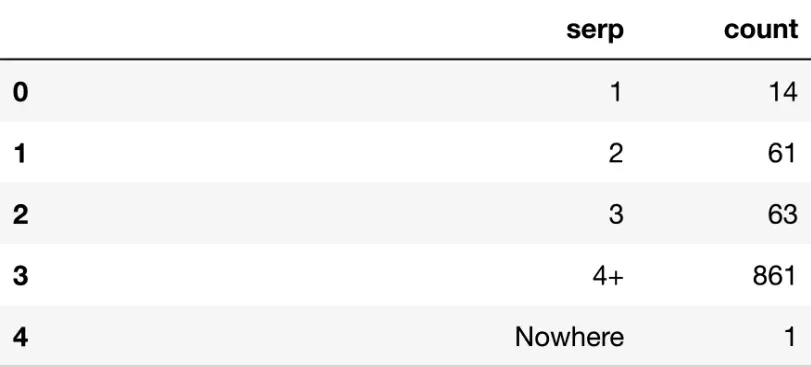
La plupart des mots-clés se trouvent au-delà de la page 3, comme le montre la valeur de 861 pour SERP 4+.
Si nous voulons visualiser les données pour un public non expert en SEO, nous pouvons utiliser les fonctions ggplot de plotnine :
serp_dist_plt = (ggplot(serp_agg,
aes(x = 'serp', y = 'count')) +
geom_bar(stat = 'identity', alpha = 0.8, fill = 'blue') +
labs(y = 'SERP', x = '') +
theme_classic() +
theme(legend_position = 'none')
)
ggplot prenez 2 arguments principaux étant le dataframe et l'esthétique (aes). aes spécifie les parties de la trame de données qui seront mappées sur le graphique. Des couches supplémentaires sont ajoutées au code pour déterminer le type de graphique, les étiquettes des axes, etc. Dans notre cas, nous utilisons geom_bar qui est un graphique à barres.
Le code est enregistré dans l'objet graphique serp_dist_plt qui, une fois exécuté, affiche le graphique :
serp_dist_plt
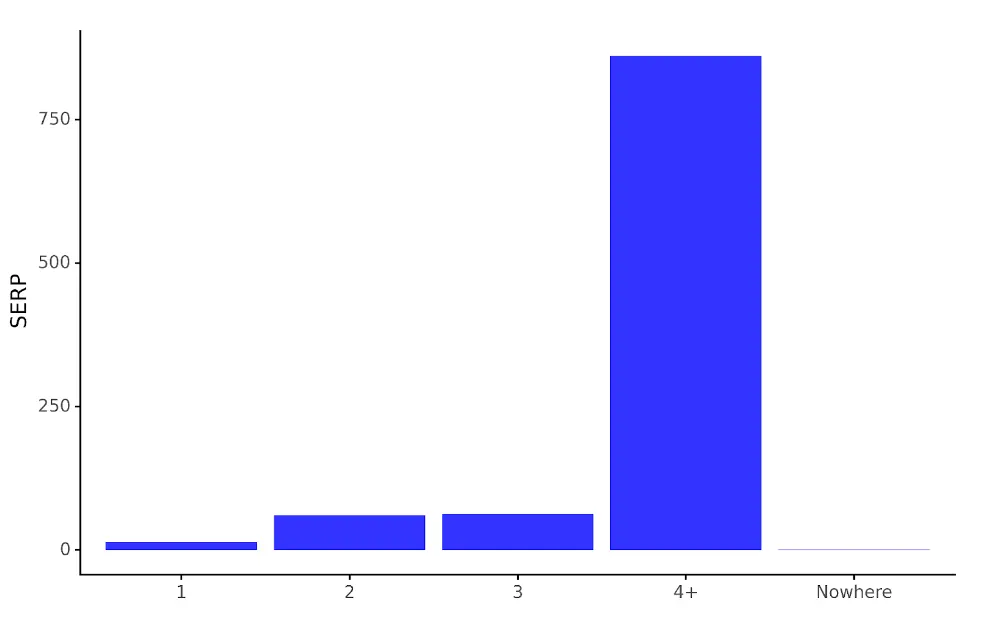
Le graphique produit crée une version visualisée du serp_agg dataframe, ce qui facilite grandement la comparaison du nombre de positions de mots-clés entre les SERP.
Informations sur les concurrents à partir des mots-clés de domaine
Bien que cela soit formidable, les chiffres pour un seul domaine de site Web ne sont pas aussi révélateurs qu’ils le seraient par rapport à d’autres sites concurrents dans le même espace de recherche. Dans l’exemple ci-dessus, deel.com a 14 mots-clés dans SERP 1. Est-ce bien ? Mauvais? Moyenne? Comment pouvons-nous le savoir ?
Les données de domaines concurrents ajoutent ce contexte et cette signification, ce qui constitue un bon cas d'utilisation pour dépenser ces crédits API. En adaptant le code ci-dessus, nous pouvons obtenir des données sur plusieurs domaines, pour obtenir quelque chose de plus significatif.
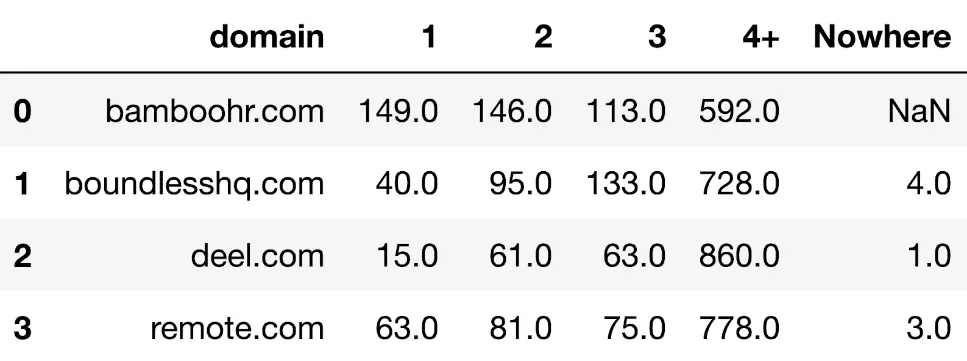
Par exemple, après avoir utilisé le même point de terminaison d'API sur des sites concurrents opérant dans le même espace, nous disposons désormais d'un tableau montrant le nombre de mots-clés par SERP pour chaque domaine :
Dans un format plus visualisé, nous obtenons :
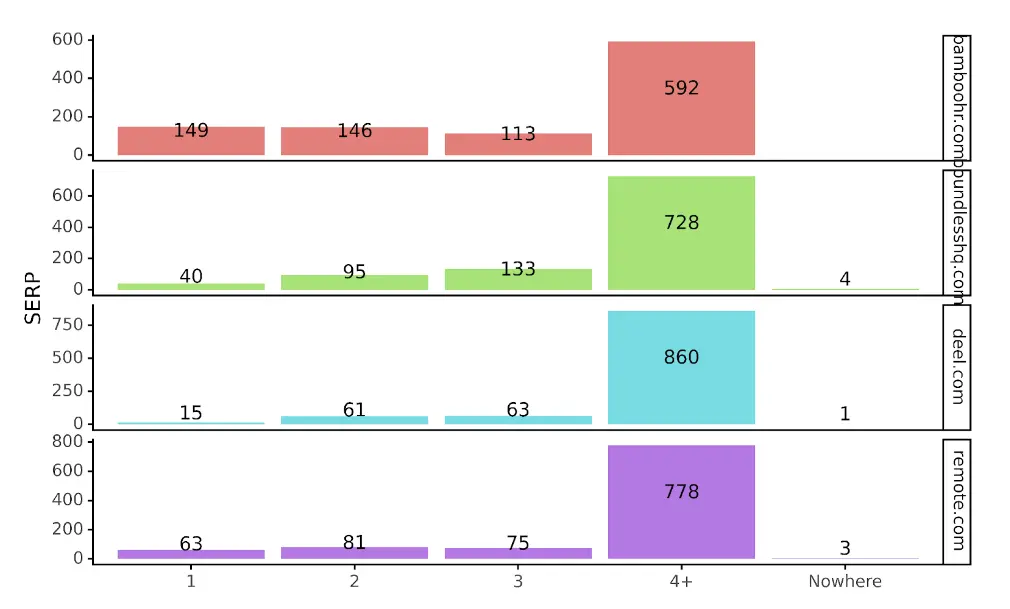
Avec le contexte supplémentaire, nous pouvons voir que deel est peut-être sous-performant sur les SERP 1 par rapport aux autres concurrents. Nous pouvons également voir que Bamboo HR est en tête, suivi de remote.com. En fait, Bamboo est le seul site avec plus de SERP 1 que de SERP 2.
Avec l'API, non seulement nous pouvons distiller les tendances à partir des données, mais nous disposons également des données réelles pour voir quels mots-clés SERP alimentent la visibilité de Bamboo. En Python, cela donnerait :
bambou_serp_1s = mdk_enhanced_df.loc[mdk_enhanced_df['domain'] == 'bamboohr.com'].copy()
Ce qui précède prend la trame de données avec les données API combinées pour les domaines et les filtres pour le domaine qui est bambouhr.com
affichage (bamboo_serp_1s)

Celui-ci peut ensuite être exporté vers Excel à des fins de planification de contenu.
Autres informations sur les mots clés du domaine
Jusqu'à présent, le code s'est concentré sur l'extraction des données de l'API Domain Keywords et a montré comment une seule colonne peut générer des informations sur un seul domaine et plusieurs domaines.
Combien d'informations supplémentaires pourraient être générées en explorant les autres colonnes et en comparant les domaines concurrents au sein du point de terminaison des mots clés de domaine. C'est avant de commencer à utiliser d'autres points de terminaison mis à notre disposition à partir de l'API SERPSTAT.
Par exemple, quels types de résultats apparaissent le plus ? Certains types de résultats augmentent-ils au fil du temps et pourraient nous aider à comprendre la tendance de Google ? Le code ci-dessus qui a décompressé la colonne des types de résultats devrait vous aider à démarrer.
L'avis des auteurs invités peut ne pas coïncider avec l'avis de la rédaction et des spécialistes de Serpstat.
Vous avez trouvé une erreur ? Sélectionnez-le et appuyez sur Ctrl + Entrée pour nous dire
Découvrez plus d'outils de référencement
Vérificateur de backlink
Vérification des backlinks pour n'importe quel site. Augmentez la puissance de votre profil de backlink
API pour le référencement
Rechercher des données volumineuses et obtenir des résultats à l'aide API de référencement
Postes recommandés
Vous n'avez pas le temps de suivre l'actualité ? Pas de soucis! Notre éditeur choisira des articles qui vous aideront certainement dans votre travail. Rejoignez notre communauté chaleureuse 🙂
En cliquant sur le bouton, vous acceptez nos politique de confidentialité.
Es-tu sûr?
Merci, nous avons enregistré vos nouveaux paramètres de messagerie.
Signaler un bug
Chargement en cours, s'il vous plaît patienter ...
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://serpstat.com/blog/competitor-keywords-api-with-python

