Aujourd'hui, nous sommes heureux d'annoncer que Zone de données Amazon est désormais en mesure de présenter des informations sur la qualité des données pour les actifs de données. Ces informations permettent aux utilisateurs finaux de prendre des décisions éclairées quant à l'utilisation ou non d'actifs spécifiques.
De nombreuses organisations utilisent déjà Qualité des données AWS Glue de définir et faire respecter des règles de qualité des données sur leurs données, valider les données par rapport à des règles prédéfinies, suivre les mesures de qualité des données et surveiller la qualité des données au fil du temps grâce à l’intelligence artificielle (IA). D'autres organisations surveillent la qualité de leurs données via des solutions tierces.
Amazon DataZone s'intègre désormais directement à AWS Glue pour afficher les scores de qualité des données pour les actifs AWS Glue Data Catalog. De plus, Amazon DataZone propose désormais des API pour importer des scores de qualité des données à partir de systèmes externes.
Dans cet article, nous discutons des dernières fonctionnalités d'Amazon DataZone pour la qualité des données, de l'intégration entre Amazon DataZone et AWS Glue Data Quality et de la façon dont vous pouvez importer des scores de qualité des données produits par des systèmes externes dans Amazon DataZone via l'API.
Défis
L'une des questions les plus courantes que nous recevons des clients concerne l'affichage des scores de qualité des données dans le Catalogue de données d'entreprise Amazon DataZone pour permettre aux utilisateurs professionnels d'avoir une visibilité sur la santé et la fiabilité des ensembles de données.
Alors que les données deviennent de plus en plus cruciales pour prendre des décisions commerciales, les utilisateurs d'Amazon DataZone souhaitent vivement fournir les normes les plus élevées en matière de qualité des données. Ils reconnaissent l'importance de disposer de données précises, complètes et actualisées pour permettre une prise de décision éclairée et favoriser la confiance dans leurs processus d'analyse et de reporting.
Les ressources de données Amazon DataZone peuvent être mises à jour à différentes fréquences. À mesure que les données sont actualisées et mises à jour, des changements peuvent survenir via des processus en amont, ce qui les expose au risque de ne pas maintenir la qualité souhaitée. Les scores de qualité des données vous aident à comprendre si les données ont maintenu le niveau de qualité attendu pour les consommateurs de données (grâce à l'analyse ou aux processus en aval).
Du point de vue du producteur, les gestionnaires de données peuvent désormais configurer Amazon DataZone pour importer automatiquement les scores de qualité des données d'AWS Glue Data Quality (programmé ou à la demande) et inclure ces informations dans le catalogue Amazon DataZone pour les partager avec les utilisateurs professionnels. De plus, vous pouvez désormais utiliser les nouvelles API Amazon DataZone pour importer les scores de qualité des données produits par des systèmes externes dans les actifs de données.
Avec la dernière amélioration, les utilisateurs d'Amazon DataZone peuvent désormais effectuer les opérations suivantes :
- Accédez à des informations sur les normes de qualité des données directement depuis le portail Web Amazon DataZone
- Afficher les scores de qualité des données sur divers KPI, notamment l'exhaustivité, l'unicité et l'exactitude des données.
- Assurez-vous que les utilisateurs ont une vision globale de la qualité et de la fiabilité de leurs données.
Dans la première partie de cet article, nous passons en revue l'intégration entre AWS Glue Data Quality et Amazon DataZone. Nous expliquons comment visualiser les scores de qualité des données dans Amazon DataZone, activer AWS Glue Data Quality lors de la création d'une nouvelle source de données Amazon DataZone et activer la qualité des données pour un actif de données existant.
Dans la deuxième partie de cet article, nous expliquons comment importer des scores de qualité des données produits par des systèmes externes dans Amazon DataZone via l'API. Dans cet exemple, nous utilisons Amazon EMR sans serveur en combinaison avec la bibliothèque open source Pydeequ agir comme un système externe pour la qualité des données.
Visualisez les scores de qualité des données AWS Glue dans Amazon DataZone
Vous pouvez désormais visualiser les scores AWS Glue Data Quality dans les actifs de données qui ont été publiés dans le catalogue professionnel Amazon DataZone et qui sont consultables via le portail Web Amazon DataZone.
Si AWS Glue Data Quality est activé sur l'actif, vous pouvez désormais visualiser rapidement le score de qualité des données directement dans le volet de recherche du catalogue.

En sélectionnant l'asset correspondant, vous pouvez comprendre son contenu grâce au readme, termes du glossaireet métadonnées techniques et métiers. De plus, l'indicateur de niveau de qualité global est affiché dans le Détails de l'actif .

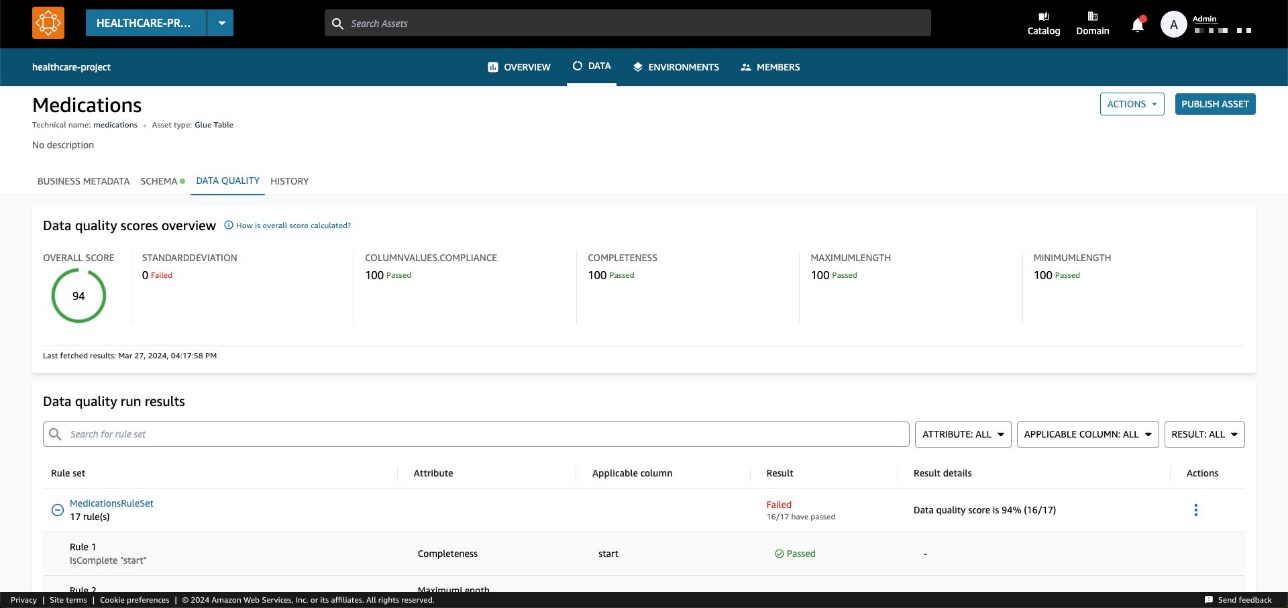
Un score de qualité des données sert d'indicateur global de la qualité d'un ensemble de données, calculé en fonction des règles que vous définissez.
Sur le Qualité des données , vous pouvez accéder aux détails des indicateurs de synthèse de la qualité des données et aux résultats des exécutions de la qualité des données.
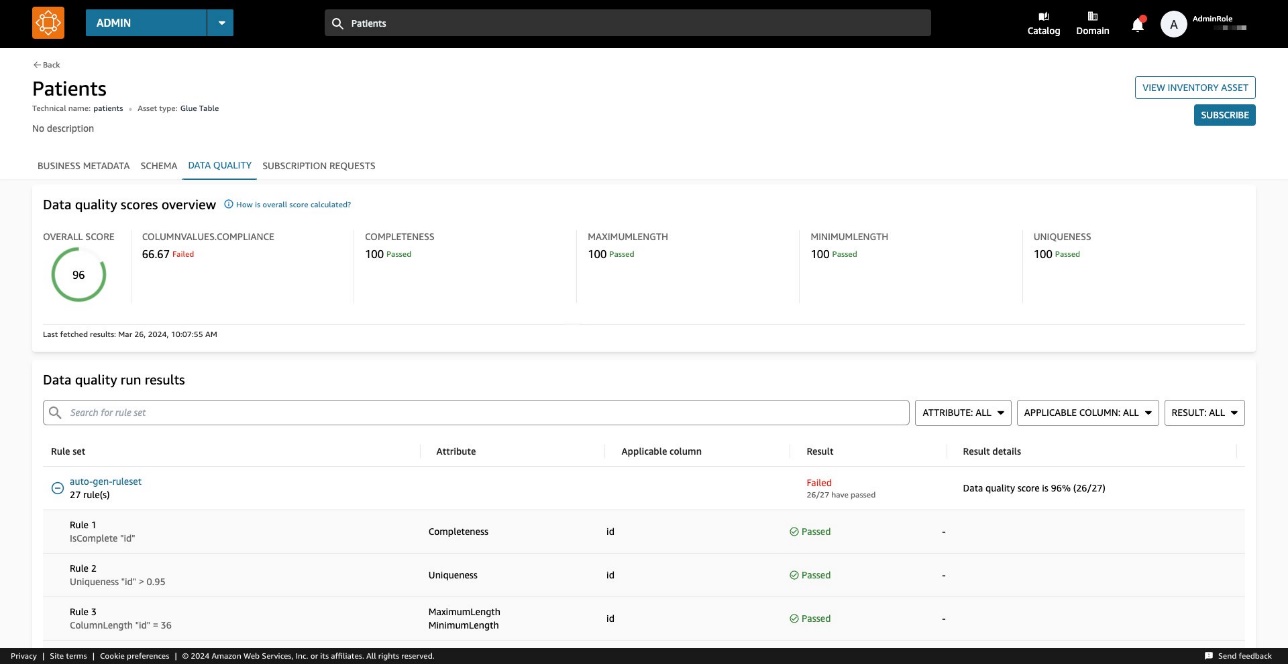
Les indicateurs affichés sur le Vue d’ensemble sont calculés en fonction des résultats des ensembles de règles issus des exécutions de qualité des données.
Chaque règle se voit attribuer un attribut qui contribue au calcul de l'indicateur. Par exemple, les règles qui ont le Completeness l’attribut contribuera au calcul de l’indicateur correspondant sur le Vue d’ensemble languette.
Pour filtrer les résultats de qualité des données, choisissez l'option Colonne applicable menu déroulant et choisissez le paramètre de filtre souhaité.

Vous pouvez également visualiser la qualité des données au niveau des colonnes à partir du Programme languette.

Lorsque la qualité des données est activée pour l'actif, les résultats de qualité des données deviennent disponibles, fournissant des scores de qualité perspicaces qui reflètent l'intégrité et la fiabilité de chaque colonne de l'ensemble de données.
Lorsque vous choisissez l'un des liens de résultats de qualité des données, vous êtes redirigé vers la page de détails de la qualité des données, filtrée par la colonne sélectionnée.

Résultats historiques de la qualité des données dans Amazon DataZone
La qualité des données peut changer au fil du temps pour de nombreuses raisons :
- Les formats de données peuvent changer en raison de changements dans les systèmes sources
- À mesure que les données s'accumulent au fil du temps, elles peuvent devenir obsolètes ou incohérentes.
- La qualité des données peut être affectée par des erreurs humaines lors de la saisie, du traitement ou de la manipulation des données.
Dans Amazon DataZone, vous pouvez désormais suivre la qualité des données au fil du temps pour confirmer leur fiabilité et leur exactitude. En analysant l'instantané du rapport historique, vous pouvez identifier les domaines à améliorer, mettre en œuvre des changements et mesurer l'efficacité de ces changements.

Activer AWS Glue Data Quality lors de la création d'une nouvelle source de données Amazon DataZone
Dans cette section, nous passons en revue les étapes permettant d'activer AWS Glue Data Quality lors de la création d'une nouvelle source de données Amazon DataZone.
Pré-requis
Pour suivre, vous devez disposer d'un domaine pour Amazon DataZone, d'un projet Amazon DataZone et d'un nouveau Environnement Amazon DataZone (avec un DataLakeProfile). Pour obtenir des instructions, reportez-vous à Démarrage rapide d'Amazon DataZone avec les données AWS Glue.
Vous devez également définir et exécuter un ensemble de règles sur vos données, qui est un ensemble de règles de qualité des données dans AWS Glue Data Quality. Pour mettre en place les règles de qualité des données et pour plus d'informations sur le sujet, reportez-vous aux articles suivants :
Après avoir créé les règles de qualité des données, assurez-vous qu'Amazon DataZone dispose des autorisations nécessaires pour accéder à la base de données AWS Glue gérée via Formation AWS Lake. Pour obtenir des instructions, consultez Configurer les autorisations de Lake Formation pour Amazon DataZone.
Dans notre exemple, nous avons configuré un ensemble de règles par rapport à une table contenant des données patient dans un ensemble de données synthétiques sur les soins de santé généré à l'aide Synthéa. Synthea est un générateur de patients synthétiques qui crée des données réalistes sur les patients et les dossiers médicaux associés pouvant être utilisés pour tester des applications logicielles de santé.
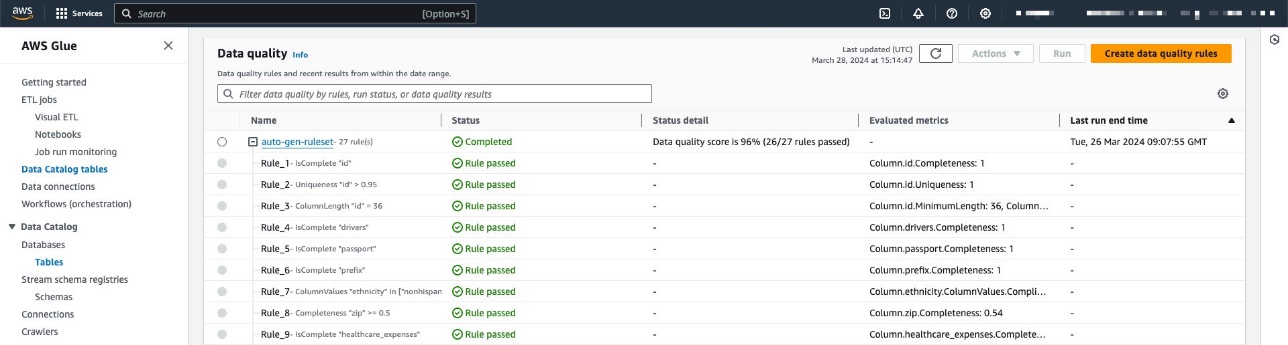
L'ensemble de règles contient 27 règles individuelles (dont une échoue), de sorte que le score global de qualité des données est de 96 %.
Si vous utilisez des stratégies gérées par Amazon DataZone, aucune action n'est nécessaire car celles-ci seront automatiquement mises à jour avec les actions nécessaires. Sinon, vous devez autoriser Amazon DataZone à disposer des autorisations requises pour répertorier et obtenir les résultats AWS Glue Data Quality, comme indiqué dans le Guide de l'utilisateur d'Amazon DataZone.
Créer une source de données avec la qualité des données activée
Dans cette section, nous créons une source de données et activons la qualité des données. Vous pouvez également mettre à jour une source de données existante pour activer la qualité des données. Nous utilisons cette source de données pour importer des informations de métadonnées liées à nos ensembles de données. Amazon DataZone importera également des informations sur la qualité des données liées aux (un ou plusieurs) actifs contenus dans la source de données.
- Sur la console Amazon DataZone, choisissez Les sources de données dans le volet de navigation.
- Selectionnez Créer une source de données.

- Pour Nom, saisissez un nom pour votre source de données.
- Pour Type de source de données, sélectionnez Colle AWS.
- Pour Environment, choisissez votre environnement.

- Pour Nom de la base de données, entrez un nom pour la base de données.
- Pour Critères de sélection des tableaux, choisissez vos critères.
- Selectionnez Suivant.

- Pour Qualité des données, sélectionnez Activer la qualité des données pour cette source de données.
Si la qualité des données est activée, Amazon DataZone récupérera automatiquement les scores de qualité des données d'AWS Glue à chaque exécution de source de données.
- Selectionnez Suivant.

Vous pouvez maintenant exécuter la source de données.

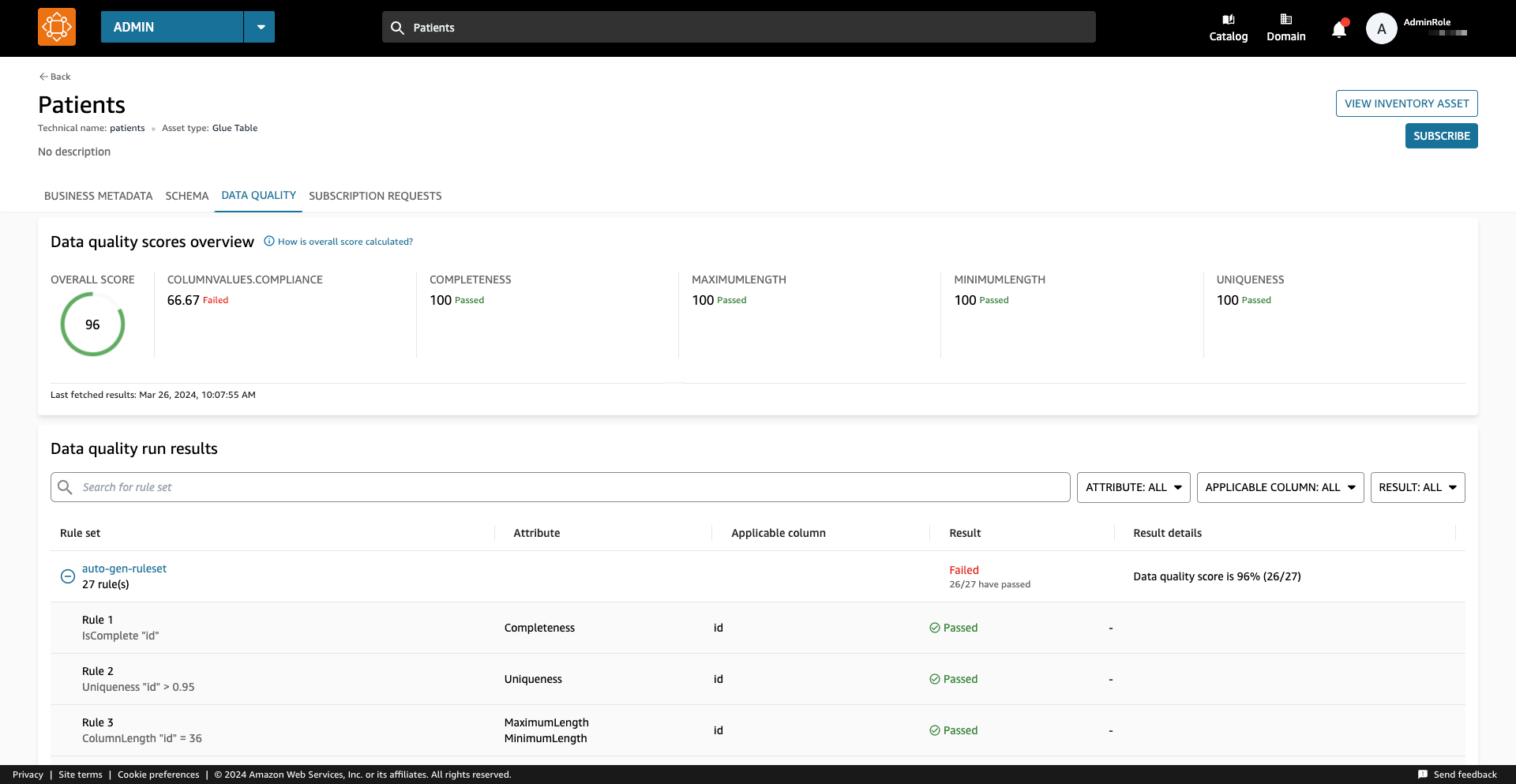
Lors de l'exécution de la source de données, Amazon DataZone importe les 100 derniers résultats d'exécution d'AWS Glue Data Quality. Ces informations sont désormais visibles sur la page de la ressource et seront visibles par tous les utilisateurs d'Amazon DataZone après la publication de la ressource.
Activer la qualité des données pour un actif de données existant
Dans cette section, nous activons la qualité des données pour un actif existant. Cela peut être utile pour les utilisateurs qui disposent déjà de sources de données et souhaitent activer la fonctionnalité par la suite.
Pré-requis
Pour suivre, vous devez déjà avoir exécuté la source de données et produit une ressource de données de table AWS Glue. De plus, vous devez avoir défini un ensemble de règles dans AWS Glue Data Quality sur la table cible du catalogue de données.

Pour cet exemple, nous avons exécuté la tâche de qualité des données plusieurs fois sur la table, produisant les scores de qualité des données AWS Glue associés, comme indiqué dans la capture d'écran suivante.

Importer les scores de qualité des données dans l'actif de données
Effectuez les étapes suivantes pour importer les scores AWS Glue Data Quality existants dans l'actif de données dans Amazon DataZone :
- Dans le projet Amazon DataZone, accédez au Données d'inventaire et choisissez la source de données.
Si vous choisissez le Qualité des données , vous pouvez voir qu'il n'y a toujours aucune information sur la qualité des données, car l'intégration d'AWS Glue Data Quality n'est pas encore activée pour cet actif de données.
- Sur le Qualité des données onglet, choisissez Activer la qualité des données.

- Dans le Qualité des données section, sélectionnez Activer la qualité des données pour cette source de données.
- Selectionnez Épargnez.

Maintenant, de retour dans le volet Données d'inventaire, vous pouvez voir un nouvel onglet : Qualité des données.
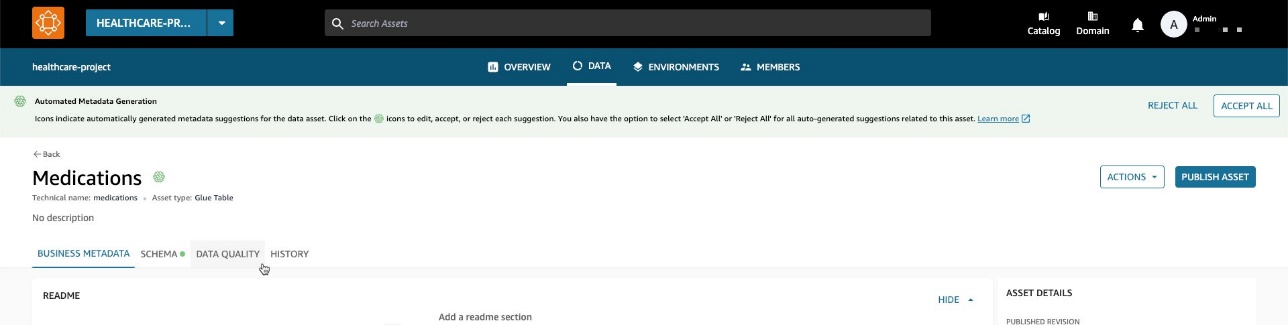
Sur le Qualité des données , vous pouvez voir les scores de qualité des données importés depuis AWS Glue Data Quality.
Ingérer des scores de qualité de données provenant d'une source externe à l'aide des API Amazon DataZone
De nombreuses organisations utilisent déjà des systèmes qui calculent la qualité des données en effectuant des tests et des assertions sur leurs ensembles de données. Amazon DataZone prend désormais en charge l'importation de scores de qualité de données provenant de tiers via API, permettant aux utilisateurs qui naviguent sur le portail Web d'afficher ces informations.
Dans cette section, nous simulons un système tiers poussant les scores de qualité des données dans Amazon DataZone via des API via Boto3 (SDK Python pour AWS).
Pour cet exemple, nous utilisons le même jeu de données synthétique comme précédemment, généré avec Synthéa.
Le diagramme suivant illustre l'architecture de la solution.

Le flux de travail comprend les étapes suivantes :
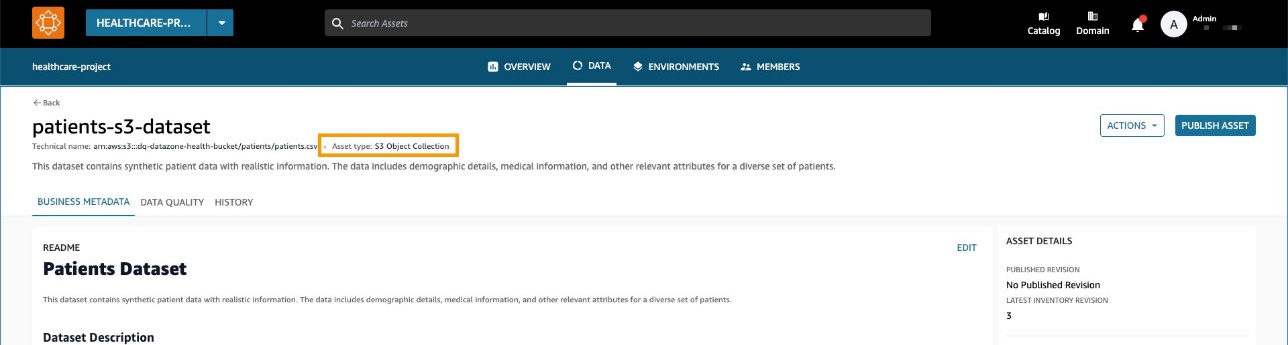
- Lire un ensemble de données de patients dans Service de stockage simple Amazon (Amazon S3) directement depuis Amazon EMR à l'aide de Spark.
L'ensemble de données est créé en tant que collection d'actifs S3 générique dans Amazon DataZone.
- Dans Amazon EMR, appliquez des règles de validation des données sur l'ensemble de données.
- Les métriques sont enregistrées dans Amazon S3 pour avoir une sortie persistante.
- Utilisez les API Amazon DataZone via Boto3 pour transmettre des métadonnées personnalisées sur la qualité des données.
- Les utilisateurs finaux peuvent voir les scores de qualité des données en accédant au portail de données.
Pré-requis
Nous utilisons Amazon EMR sans serveur et Pydeequ pour gérer un système entièrement géré Spark environnement. Pour en savoir plus sur Pydeequ en tant que framework de test de données, consultez Tester la qualité des données à grande échelle avec Pydeequ.
Pour autoriser Amazon EMR à envoyer des données au domaine Amazon DataZone, assurez-vous que le rôle IAM utilisé par Amazon EMR dispose des autorisations nécessaires pour effectuer les opérations suivantes :
- Lire et écrire dans les compartiments S3
- Appeler le
post_time_series_data_pointsaction pour Amazon DataZone :
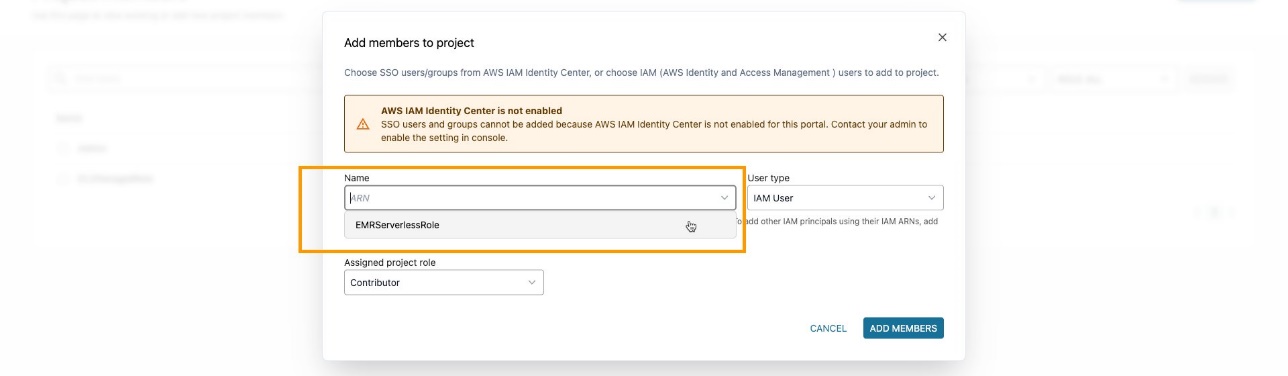
Assurez-vous d'avoir ajouté le rôle EMR en tant que membre du projet dans le projet Amazon DataZone. Sur la console Amazon DataZone, accédez au Membres du projet page et choisissez Ajouter des membres.

Ajoutez le rôle EMR en tant que contributeur.
Ingérer et analyser le code PySpark
Dans cette section, nous analysons le code PySpark que nous utilisons pour effectuer des contrôles de qualité des données et envoyer les résultats à Amazon DataZone. Vous pouvez télécharger l'intégralité Script PySpark.
Pour exécuter entièrement le script, vous pouvez soumettre une tâche à EMR Serverless. Le service se chargera de planifier le travail et d'allouer automatiquement les ressources nécessaires, vous permettant ainsi de suivre le statuts d'exécution du travail tout au long du processus.
Vous pouvez soumettre une tâche à EMR dans la console Amazon EMR à l'aide d'EMR Studio ou par programmation, en utilisant le CLI AWS ou en utilisant l'un des SDK AWS.
Dans Apache Spark, un SparkSession est le point d'entrée pour interagir avec les fonctions intégrées de DataFrames et Spark. Le script commencera à initialiser un SparkSession:
Nous lisons un ensemble de données d'Amazon S3. Pour une modularité accrue, vous pouvez utiliser l'entrée de script pour faire référence au chemin S3 :
Ensuite, nous mettons en place un référentiel de métriques. Cela peut être utile pour conserver les résultats de l'exécution dans Amazon S3.
Pydeequ vous permet de créer des règles de qualité des données à l'aide du modèle de construction, qui est un modèle de conception d'ingénierie logicielle bien connu, concaténant des instructions pour instancier un VerificationSuite objet:
Voici le résultat des règles de validation des données :
À ce stade, nous souhaitons insérer ces valeurs de qualité des données dans Amazon DataZone. Pour ce faire, nous utilisons le post_time_series_data_points fonction dans le client Boto3 Amazon DataZone.
La API DataZone de PostTimeSeriesDataPoints vous permet d'insérer de nouveaux points de données de séries chronologiques pour un actif ou une liste donnée, sans créer de nouvelle révision.
À ce stade, vous souhaiterez peut-être également avoir plus d'informations sur les champs envoyés en entrée pour l'API. Vous pouvez utiliser le Apis pour obtenir la spécification des types de formulaire Amazon DataZone ; dans notre cas, c'est amazon.datazone.DataQualityResultFormType.
Vous pouvez également utiliser l'AWS CLI pour appeler l'API et afficher la structure du formulaire :
Ce résultat permet d'identifier les paramètres d'API requis, y compris les champs et les limites de valeur :
Pour envoyer les données de formulaire appropriées, nous devons convertir la sortie Pydeequ pour qu'elle corresponde au DataQualityResultsFormType contracter. Ceci peut être réalisé avec une fonction Python qui traite les résultats.
Pour chaque ligne DataFrame, nous extrayons les informations de la colonne de contrainte. Par exemple, prenons le code suivant :
Nous le convertissons comme suit :
Assurez-vous d'envoyer un résultat qui correspond aux KPI que vous souhaitez suivre. Dans notre cas, nous ajoutons _custom au nom de la statistique, ce qui donne le format suivant pour les KPI :
Completeness_customUniqueness_custom
Dans un scénario réel, vous souhaiterez peut-être définir une valeur qui correspond à votre cadre de qualité des données par rapport aux KPI que vous souhaitez suivre dans Amazon DataZone.
Après avoir appliqué une fonction de transformation, nous avons un objet Python pour chaque évaluation de règle :
Nous utilisons également le constraint_status colonne pour calculer le score global :
Dans notre exemple, cela se traduit par un pourcentage de réussite de 85.71 %.
Nous fixons cette valeur dans passingPercentage champ de saisie ainsi que les autres informations liées aux évaluations dans la saisie de la méthode Boto3 post_time_series_data_points:
Boto3 invoque le API Amazon DataZone. Dans ces exemples, nous avons utilisé Boto3 et Python, mais vous pouvez choisir l'un des SDK AWS développé dans la langue que vous préférez.
Après avoir défini le domaine et l'ID d'actif appropriés et exécuté la méthode, nous pouvons vérifier sur la console Amazon DataZone que la qualité des données d'actif est désormais visible sur la page de l'actif.
Nous pouvons observer que le score global correspond à la valeur d'entrée de l'API. Nous pouvons également voir que nous avons pu ajouter des KPI personnalisés sur l'onglet de présentation via les valeurs des paramètres de types personnalisés.
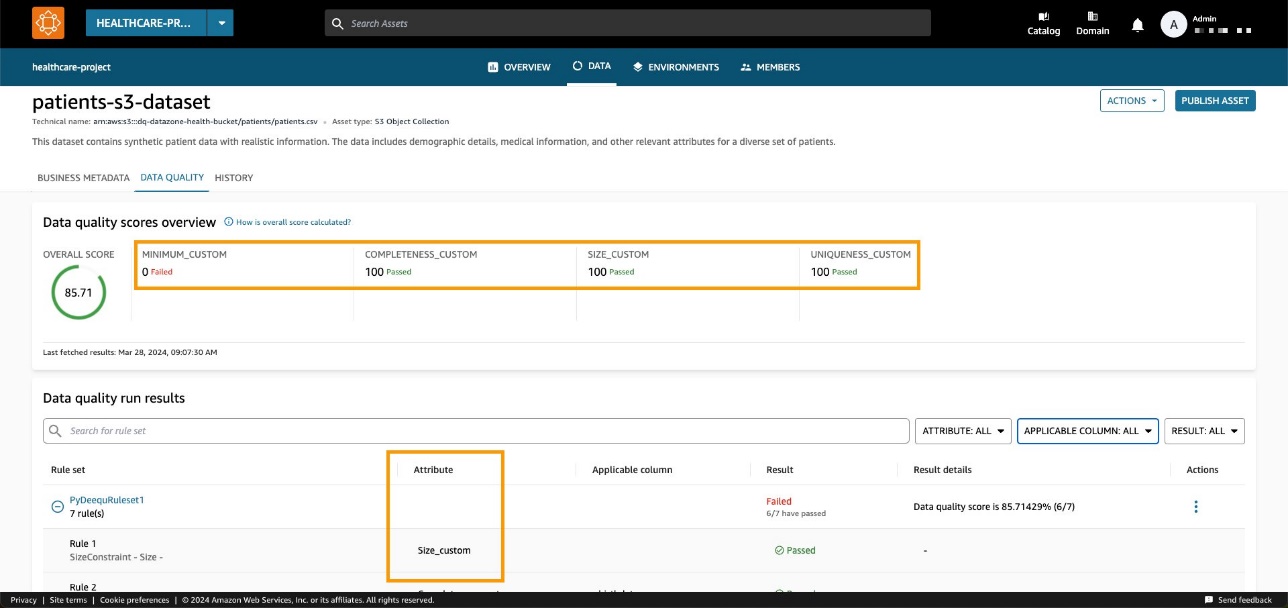
Avec les nouvelles API Amazon DataZone, vous pouvez charger des règles de qualité des données provenant de systèmes tiers dans une ressource de données spécifique. Grâce à cette fonctionnalité, Amazon DataZone vous permet d'étendre les types d'indicateurs présents dans AWS Glue Data Quality (tels que l'exhaustivité, le minimum et l'unicité) avec des indicateurs personnalisés.
Nettoyer
Nous vous recommandons de supprimer toutes les ressources potentiellement inutilisées pour éviter d'engager des coûts inattendus. Par exemple, vous pouvez supprimer le domaine Amazon DataZone et par Demande de DME vous avez créé au cours de ce processus.
Conclusion
Dans cet article, nous avons mis en évidence les dernières fonctionnalités d'Amazon DataZone pour la qualité des données, offrant aux utilisateurs finaux un contexte et une visibilité améliorés sur leurs actifs de données. De plus, nous avons approfondi l'intégration transparente entre Amazon DataZone et AWS Glue Data Quality. Vous pouvez également utiliser les API Amazon DataZone pour intégrer des fournisseurs externes de qualité de données, vous permettant ainsi de maintenir une stratégie de données complète et robuste au sein de votre environnement AWS.
Pour en savoir plus sur Amazon DataZone, consultez le Guide de l'utilisateur Amazon DataZone.
À propos des auteurs
 Andrea Filippo est un architecte de solutions partenaires chez AWS qui soutient les partenaires et les clients du secteur public en Italie. Il se concentre sur les architectures de données modernes et aide les clients à accélérer leur transition vers le cloud grâce aux technologies sans serveur.
Andrea Filippo est un architecte de solutions partenaires chez AWS qui soutient les partenaires et les clients du secteur public en Italie. Il se concentre sur les architectures de données modernes et aide les clients à accélérer leur transition vers le cloud grâce aux technologies sans serveur.
 Emanuele est architecte de solutions chez AWS, basé en Italie, après avoir vécu et travaillé pendant plus de 5 ans en Espagne. Il aime aider les grandes entreprises dans l’adoption des technologies cloud, et son domaine d’expertise se concentre principalement sur l’analyse de données et la gestion des données. En dehors du travail, il aime voyager et collectionner des figurines.
Emanuele est architecte de solutions chez AWS, basé en Italie, après avoir vécu et travaillé pendant plus de 5 ans en Espagne. Il aime aider les grandes entreprises dans l’adoption des technologies cloud, et son domaine d’expertise se concentre principalement sur l’analyse de données et la gestion des données. En dehors du travail, il aime voyager et collectionner des figurines.
 Varsha Velagapudi est chef de produit technique senior chez Amazon DataZone chez AWS. Elle se concentre sur l’amélioration de la découverte et de la conservation des données nécessaires à l’analyse des données. Elle est passionnée par la simplification du parcours IA/ML et analytique des clients pour les aider à réussir dans leurs tâches quotidiennes. En dehors du travail, elle aime la nature et les activités de plein air, la lecture et les voyages.
Varsha Velagapudi est chef de produit technique senior chez Amazon DataZone chez AWS. Elle se concentre sur l’amélioration de la découverte et de la conservation des données nécessaires à l’analyse des données. Elle est passionnée par la simplification du parcours IA/ML et analytique des clients pour les aider à réussir dans leurs tâches quotidiennes. En dehors du travail, elle aime la nature et les activités de plein air, la lecture et les voyages.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/amazon-datazone-now-integrates-with-aws-glue-data-quality-and-external-data-quality-solutions/

