La semaine dernière, nous avons annoncé le disponibilité générale de l'intégration entre Zone de données Amazon ainsi que Formation AWS Lake mode d'accès hybride. Dans cet article, nous expliquons comment cette nouvelle fonctionnalité vous aide à simplifier la façon dont vous utilisez Amazon DataZone pour permettre un partage sécurisé et gouverné de vos données dans le Colle AWS Catalogue de données. Nous expliquons également comment les producteurs de données peuvent partager leurs tables AWS Glue via Amazon DataZone sans avoir besoin de les enregistrer au préalable dans Lake Formation.
Présentation de l'intégration d'Amazon DataZone avec le mode d'accès hybride de Lake Formation
Amazon DataZone est un service de gestion de données entièrement géré permettant de cataloguer, découvrir, analyser, partager et gérer les données entre les producteurs de données et les consommateurs de votre organisation. Avec Amazon DataZone, les producteurs de données remplissent le catalogue de données d'entreprise avec des ressources de données provenant de sources de données telles que AWS Glue Data Catalog et Redshift d'Amazon. Ils enrichissent également leurs actifs avec un contexte commercial pour faciliter la compréhension des consommateurs de données. Une fois les données disponibles dans le catalogue, les consommateurs de données tels que les analystes et les data scientists peuvent rechercher et accéder à ces données en demandant des abonnements. Lorsque la demande est approuvée, Amazon DataZone peut automatiquement fournir l'accès aux données en gérant les autorisations dans Lake Formation ou Amazon Redshift afin que le consommateur de données puisse commencer à interroger les données à l'aide d'outils tels que Amazone Athéna ou Amazon Redshift.
Pour gérer l'accès aux données dans le catalogue de données AWS Glue, Amazon DataZone utilise Lake Formation. Auparavant, si vous souhaitiez utiliser Amazon DataZone pour gérer l'accès à vos données dans le catalogue de données AWS Glue, vous deviez d'abord intégrer vos données à Lake Formation. Désormais, l'intégration du mode d'accès hybride Amazon DataZone et Lake Formation simplifie la façon dont vous pouvez démarrer votre parcours Amazon DataZone en supprimant la nécessité d'intégrer d'abord vos données à Lake Formation.
Formation du lac mode d'accès hybride vous permet de commencer à gérer les autorisations sur vos bases de données et tables AWS Glue via Lake Formation, tout en continuant à conserver toutes les autorisations existantes. Gestion des identités et des accès AWS (IAM) sur ces tables et bases de données. Le mode d'accès hybride de Lake Formation prend en charge deux voies d'autorisation vers les mêmes bases de données et tables Data Catalog :
- Dans la première voie, Lake Formation vous permet de sélectionner des mandataires spécifiques (mandataires opt-in) et de leur accorder les autorisations Lake Formation pour accéder aux bases de données et aux tables en s'inscrivant.
- La deuxième voie permet à tous les autres mandataires (qui ne sont pas ajoutés en tant que mandataires opt-in) d'accéder à ces ressources via les stratégies de principal IAM pour Service de stockage simple Amazon (Amazon S3) et actions AWS Glue
Grâce à l'intégration entre Amazon DataZone et le mode d'accès hybride de Lake Formation, si vous disposez de tables dans le catalogue de données AWS Glue qui sont gérées via des stratégies basées sur IAM, vous pouvez publier ces tables directement sur Amazon DataZone, sans les enregistrer dans Lake Formation. Amazon DataZone enregistre l'emplacement de ces tables dans Lake Formation à l'aide du mode d'accès hybride, qui permet de gérer les autorisations sur les tables AWS Glue via Lake Formation, tout en continuant à conserver les autorisations IAM existantes.
Amazon DataZone vous permet de publier tout type d'actif dans le catalogue de données métier. Pour certains de ces actifs, Amazon DataZone peut gérer automatiquement les autorisations d'accès. Ces actifs sont appelés actifs gérés, et incluent les tables Data Catalog gérées par Lake Formation et les tables et vues Amazon Redshift. Avant cette intégration, vous deviez effectuer les étapes suivantes avant qu'Amazon DataZone puisse traiter la table Data Catalog publiée comme un actif géré :
- Identifiez l'emplacement Amazon S3 associé à la table Data Catalog.
- Enregistrez l'emplacement Amazon S3 auprès de Lake Formation en mode d'accès hybride à l'aide d'un rôle de l' avec les autorisations appropriées.
- Publiez les métadonnées de la table dans le catalogue de données métier Amazon DataZone.
Le diagramme suivant illustre ce flux de travail.
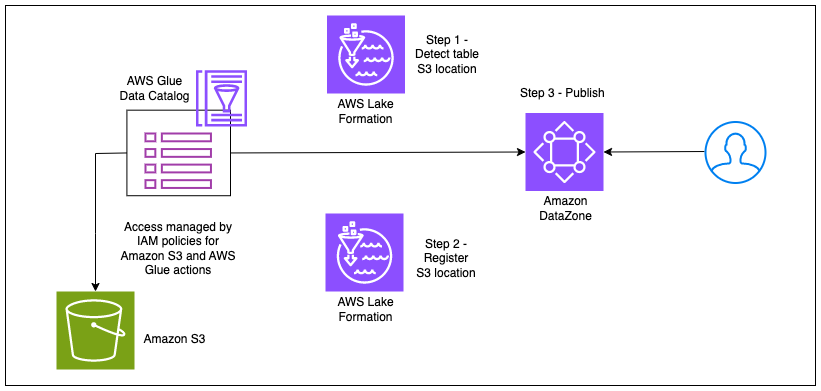
Grâce à l'intégration d'Amazon DataZone avec le mode d'accès hybride de Lake Formation, vous pouvez simplement publier vos tables AWS Glue sur Amazon DataZone sans avoir à vous soucier de l'enregistrement de l'emplacement Amazon S3 ou de l'ajout d'un principal opt-in dans Lake Formation en déléguant ces étapes à Amazon DataZone. . L'administrateur d'un compte AWS peut activer le paramètre d'enregistrement de l'emplacement des données sous l'onglet DefaultDataLake plan sur la console Amazon DataZone. Désormais, un propriétaire ou un éditeur de données peut publier sa table AWS Glue (gérée via les autorisations IAM) sur Amazon DataZone sans les étapes de configuration supplémentaires. Lorsqu'un consommateur de données s'abonne à cette table, Amazon DataZone enregistre les emplacements Amazon S3 de la table en mode d'accès hybride, ajoute le rôle IAM du consommateur de données en tant que principal opt-in et accorde l'accès au même rôle IAM en gérant les autorisations sur le table à travers Lake Formation. Cela garantit que les autorisations IAM sur la table peuvent coexister avec les autorisations Lake Formation nouvellement accordées, sans perturber les flux de travail existants. Le diagramme suivant illustre ce flux de travail.

Vue d'ensemble de la solution
Pour démontrer cette nouvelle fonctionnalité, nous utilisons un exemple de scénario client dans lequel l'équipe financière souhaite accéder aux données détenues par l'équipe commerciale à des fins d'analyse et de reporting financiers. L'équipe commerciale dispose d'un pipeline qui crée un ensemble de données contenant des informations précieuses sur les ventes de billets, les événements populaires, les lieux et les saisons. Nous l’appelons l’ensemble de données tickit. L'équipe commerciale stocke cet ensemble de données dans Amazon S3 et l'enregistre dans une base de données du catalogue de données. L'accès à cette table est actuellement géré via des autorisations basées sur IAM. Cependant, l'équipe commerciale souhaite publier ce tableau sur Amazon DataZone pour faciliter le partage de données sécurisé et gouverné avec l'équipe financière.
Les étapes pour configurer cette solution sont les suivantes :
- L'administrateur Amazon DataZone active le paramètre d'enregistrement de l'emplacement du lac de données dans Amazon DataZone pour enregistrer automatiquement l'emplacement Amazon S3 des tables AWS Glue en mode d'accès hybride Lake Formation.
- Une fois l'intégration du mode d'accès hybride activée dans Amazon DataZone, l'équipe financière demande un abonnement à l'actif de données de vente. L'actif apparaît comme un actif géré, ce qui signifie qu'Amazon DataZone peut gérer l'accès à cet actif même si l'emplacement Amazon S3 de cet actif n'est pas enregistré dans Lake Formation.
- L'équipe commerciale est informée d'une demande de souscription émise par l'équipe financière. Ils examinent et approuvent la demande d’accès. Une fois la demande approuvée, Amazon DataZone répond à la demande d'abonnement en gérant les autorisations dans Lake Formation. Il enregistre l'emplacement Amazon S3 de la table souscrite en mode hybride Lake Formation.
- L'équipe financière a accès à l'ensemble de données de ventes requis pour ses rapports financiers. Ils peuvent accéder à leur environnement DataZone et commencer à exécuter des requêtes en utilisant Athena sur leur ensemble de données souscrit.
Pré-requis
Pour suivre les étapes de cet article, vous avez besoin d'un compte AWS. Si vous n'avez pas de compte, vous pouvez créer un. De plus, vous devez disposer des ressources suivantes configurées dans votre compte :
- Un seau S3
- Une base de données et un robot d'exploration AWS Glue
- Rôles IAM pour différents personnages et services
- Un domaine et un projet Amazon DataZone
- Un profil et un environnement d'environnement Amazon DataZone
- Une source de données Amazon DataZone
Si ces ressources ne sont pas déjà configurées, vous pouvez les créer en déployant les éléments suivants AWS CloudFormation empiler:
- Selectionnez Lancer la pile pour déployer un modèle CloudFormation.

- Suivez les étapes pour déployer le modèle et laissez tous les paramètres par défaut.
- Sélectionnez Je reconnais qu'AWS CloudFormation peut créer des ressources IAM, Puis choisissez Envoyer.
Une fois le déploiement CloudFormation terminé, vous pouvez vous connecter au portail Amazon DataZone et déclencher manuellement une exécution de source de données. Cela extrait toutes les métadonnées nouvelles ou modifiées de la source et met à jour les actifs associés dans l'inventaire. Cette source de données a été configurée pour publier automatiquement les ressources de données dans le catalogue.
- Sur la console Amazon DataZone, choisissez Afficher les domaines.
Vous devez être connecté en utilisant le même rôle que celui utilisé pour déployer CloudFormation et vérifier que vous êtes dans la même région AWS.
- Trouver le domaine
blog_dz_domain, Puis choisissez Portail de données ouvertes. - Selectionnez Parcourir tous les projets et choisissez Projet de producteur commercial.
- Sur le Données onglet, choisissez Les sources de données dans le volet de navigation.
- Recherchez et choisissez la source de données que vous souhaitez exécuter.
Cela ouvre la page de détails de la source de données.
- Choisissez le menu d'options (trois points verticaux) à côté de
tickit_datasourceet choisissez Courir.
L'état de la source de données devient En cours d'exécution à mesure qu'Amazon DataZone met à jour les métadonnées de l'actif.
Activer l'intégration du mode hybride dans Amazon DataZone
Au cours de cette étape, l'administrateur Amazon DataZone suit le processus d'activation de l'intégration d'Amazon DataZone avec le mode d'accès hybride de Lake Formation. Effectuez les étapes suivantes :
- Dans un onglet de navigateur distinct, ouvrez la console Amazon DataZone.
Vérifiez que vous vous trouvez dans la même région où vous avez déployé le modèle CloudFormation.
- Selectionnez Afficher les domaines.
- Choisissez le domaine créé par AWS CloudFormation,
blog_dz_domain. - Faites défiler la page des détails du domaine et choisissez le Blueprints languette.
A plan définit quels outils et services AWS peuvent être utilisés avec les ressources de données publiées dans Amazon DataZone. Le DefaultDataLake le plan est activé dans le cadre du déploiement de la pile CloudFormation. Ce modèle vous permet de créer et d'interroger des tables AWS Glue à l'aide d'Athena. Pour connaître les étapes permettant de l'activer dans vos propres déploiements, reportez-vous à Activer les plans intégrés dans le compte AWS propriétaire du domaine Amazon DataZone.
- Choisissez le
DefaultDataLakeplan.
- Sur le Provisioning onglet, choisissez Modifier.
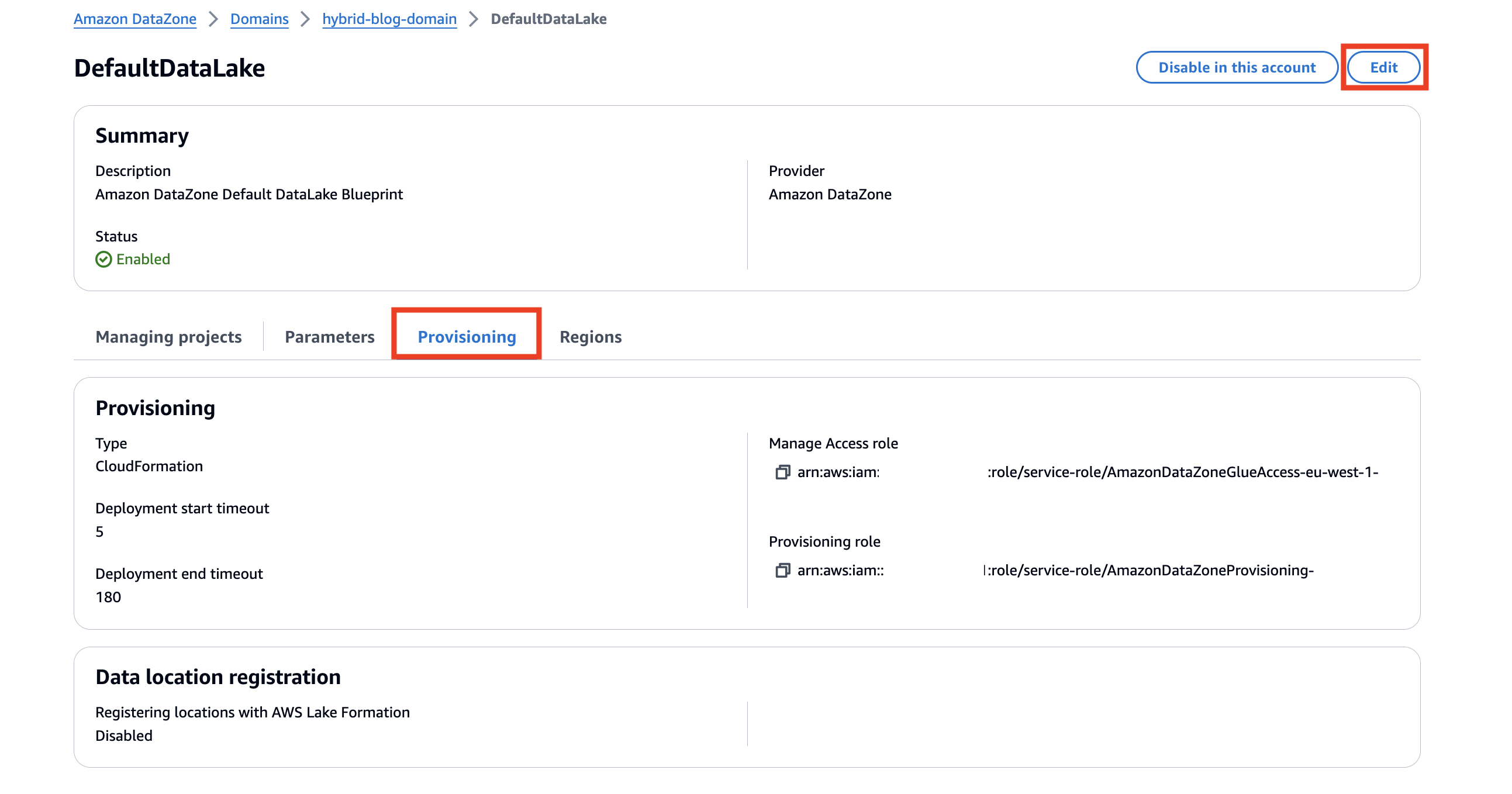
- Sélectionnez Permettre à Amazon DataZone d'enregistrer les emplacements S3 à l'aide du mode d'accès hybride AWS Lake Formation.
Vous avez la possibilité d'exclure des emplacements Amazon S3 spécifiques si vous ne souhaitez pas qu'Amazon DataZone les enregistre automatiquement en mode d'accès hybride Lake Formation.
- Selectionnez Enregistrer les modifications.

Demander l'accès
Au cours de cette étape, vous vous connectez à Amazon DataZone en tant qu'équipe financière, recherchez l'actif de données de vente et vous y abonnez. Effectuez les étapes suivantes :
- Revenez à l'onglet du navigateur de votre portail de données Amazon DataZone.
- Basculez vers le projet Finance Consumer en choisissant le menu déroulant à côté du nom du projet et en choisissant Projet de consommation financière.
À partir de cette étape, vous incarnez un utilisateur financier souhaitant s'abonner à un actif de données publié à l'étape précédente.
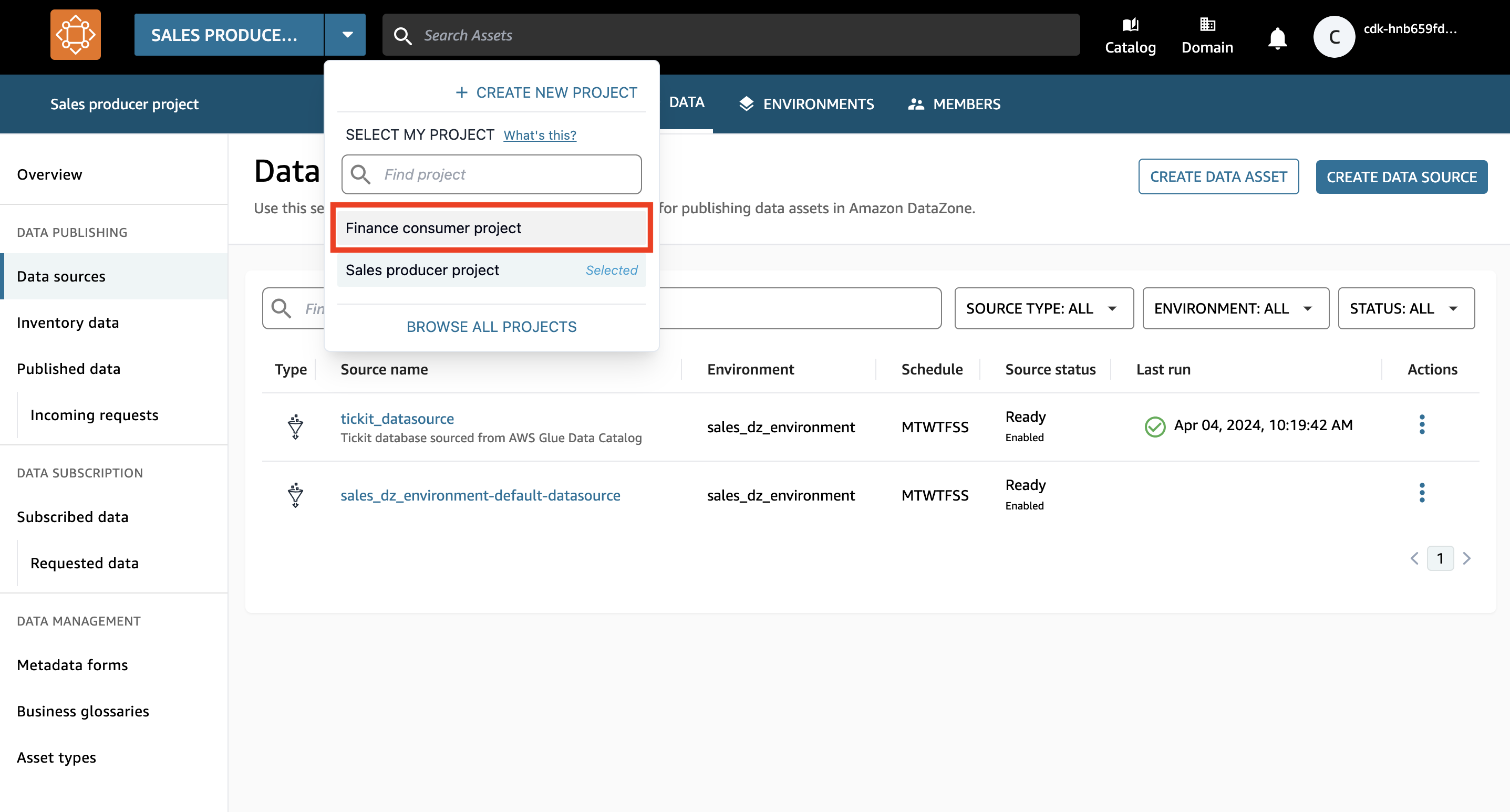
- Dans la barre de recherche, recherchez et choisissez le
salesactif de données.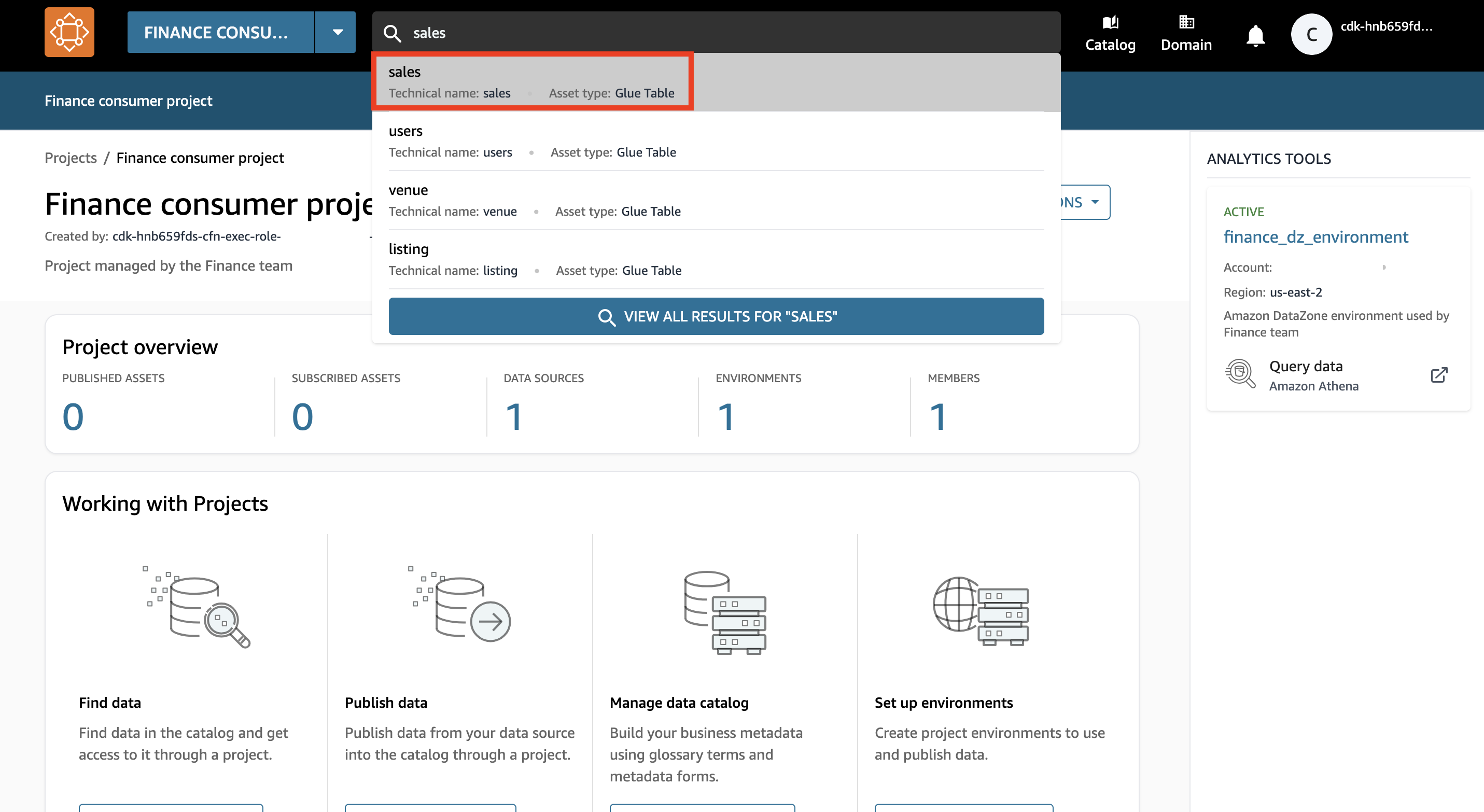
- Selectionnez S'abonner.
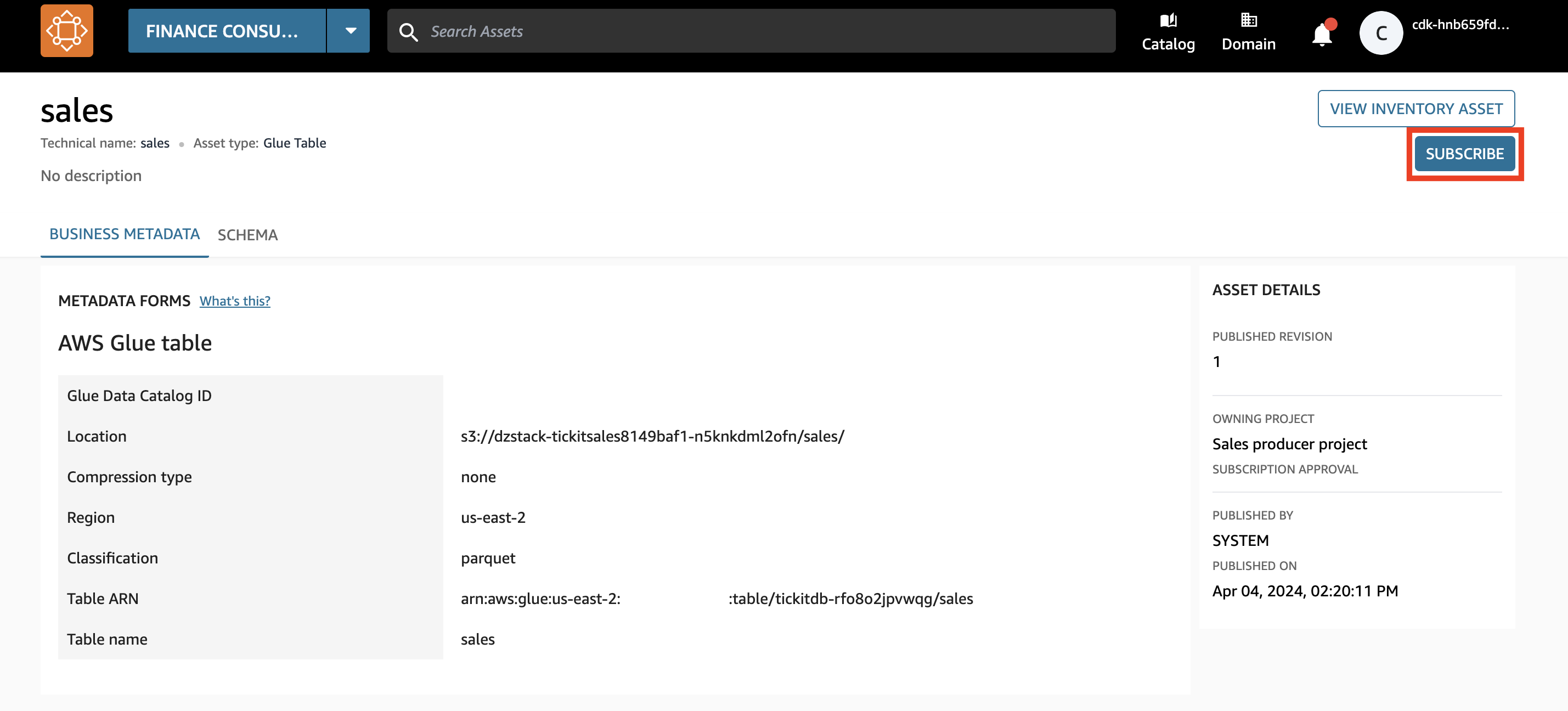
L'actif apparaît comme actif géré. Cela signifie qu'Amazon DataZone peut accorder l'accès à cet actif de données au projet de l'équipe financière en gérant les autorisations dans Lake Formation.
- Saisissez le motif de la demande d'accès et choisissez S'abonner.
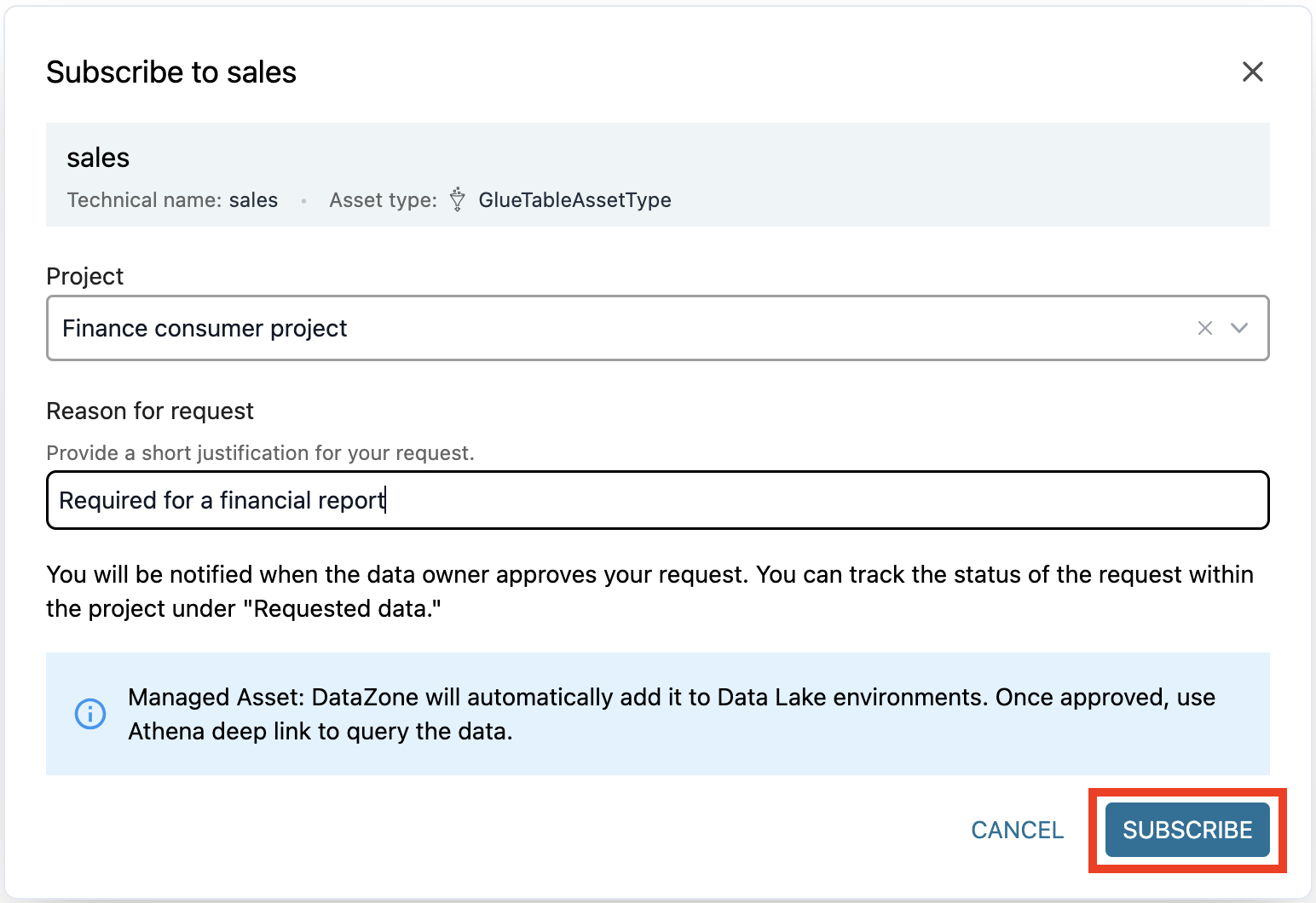
Approuver la demande d'accès
L'équipe commerciale reçoit une notification indiquant qu'une demande d'accès de la part de l'équipe financière est soumise. Pour approuver la demande, procédez comme suit :
- Choisissez le menu déroulant à côté du nom du projet et choisissez Projet de producteur commercial.
Vous incarnez désormais l’équipe commerciale, qui est propriétaire et gestionnaire des actifs de données de vente.
- Choisissez l'icône de notification dans le coin supérieur droit du portail DataZone.
- Choisissez le Demande d'abonnement créée entrée.
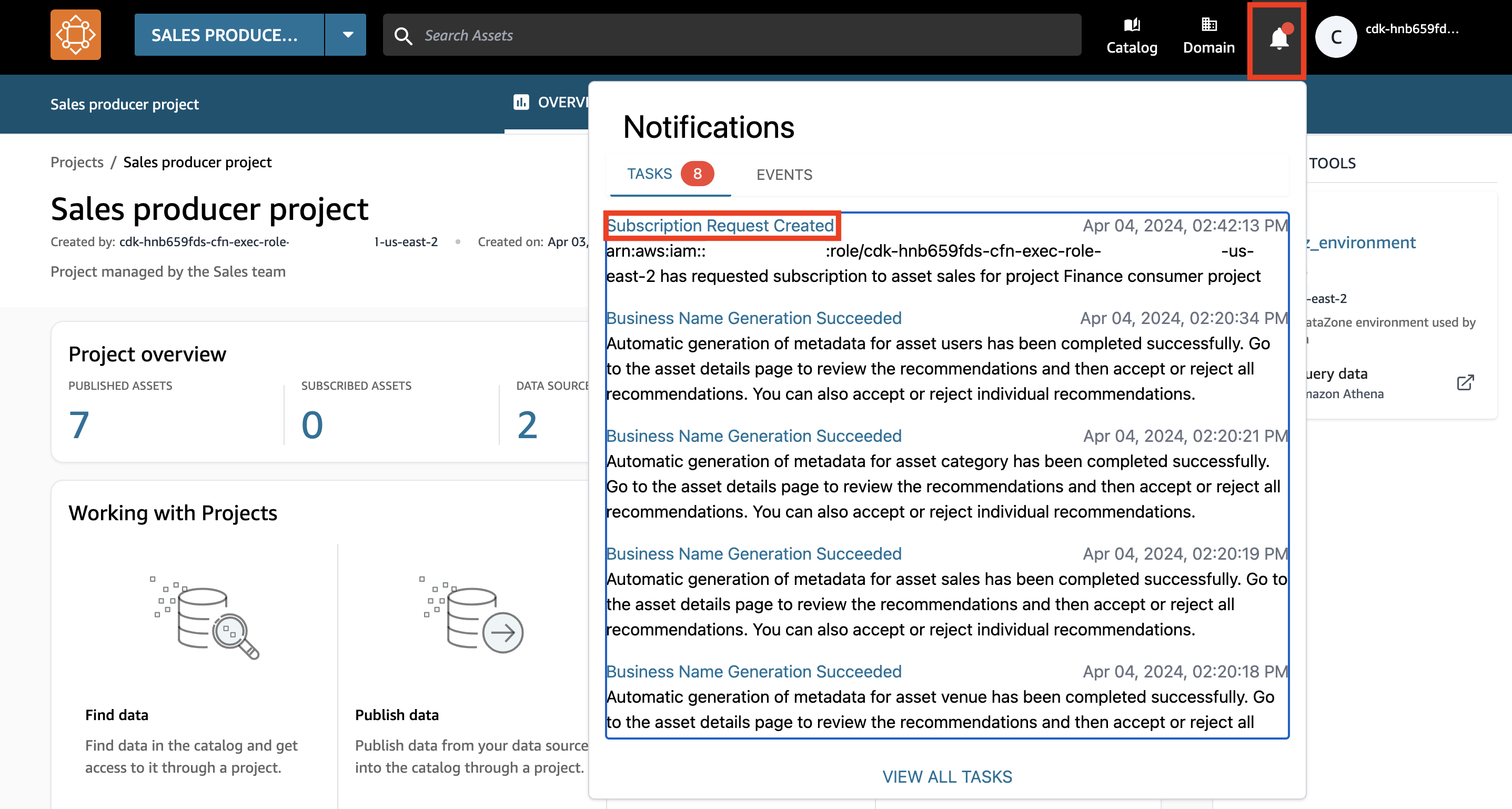
- Accordez l'accès à l'actif de données de vente à l'équipe financière et choisissez Approuver.

Analysez les données
L'équipe financière a désormais accès aux données de vente, et cet ensemble de données a été transféré dans son environnement Amazon DataZone. Ils peuvent accéder à l'environnement et interroger l'ensemble de données de ventes avec Athena, ainsi que tout autre ensemble de données qu'ils possèdent actuellement. Effectuez les étapes suivantes :
- Dans le menu déroulant, choisissez Projet de consommation financière.
Dans le volet droit de l'écran de présentation du projet, vous pouvez trouver une liste des environnements actifs disponibles pour utilisation.
- Choisissez l'environnement Amazon DataZone
finance_dz_environment.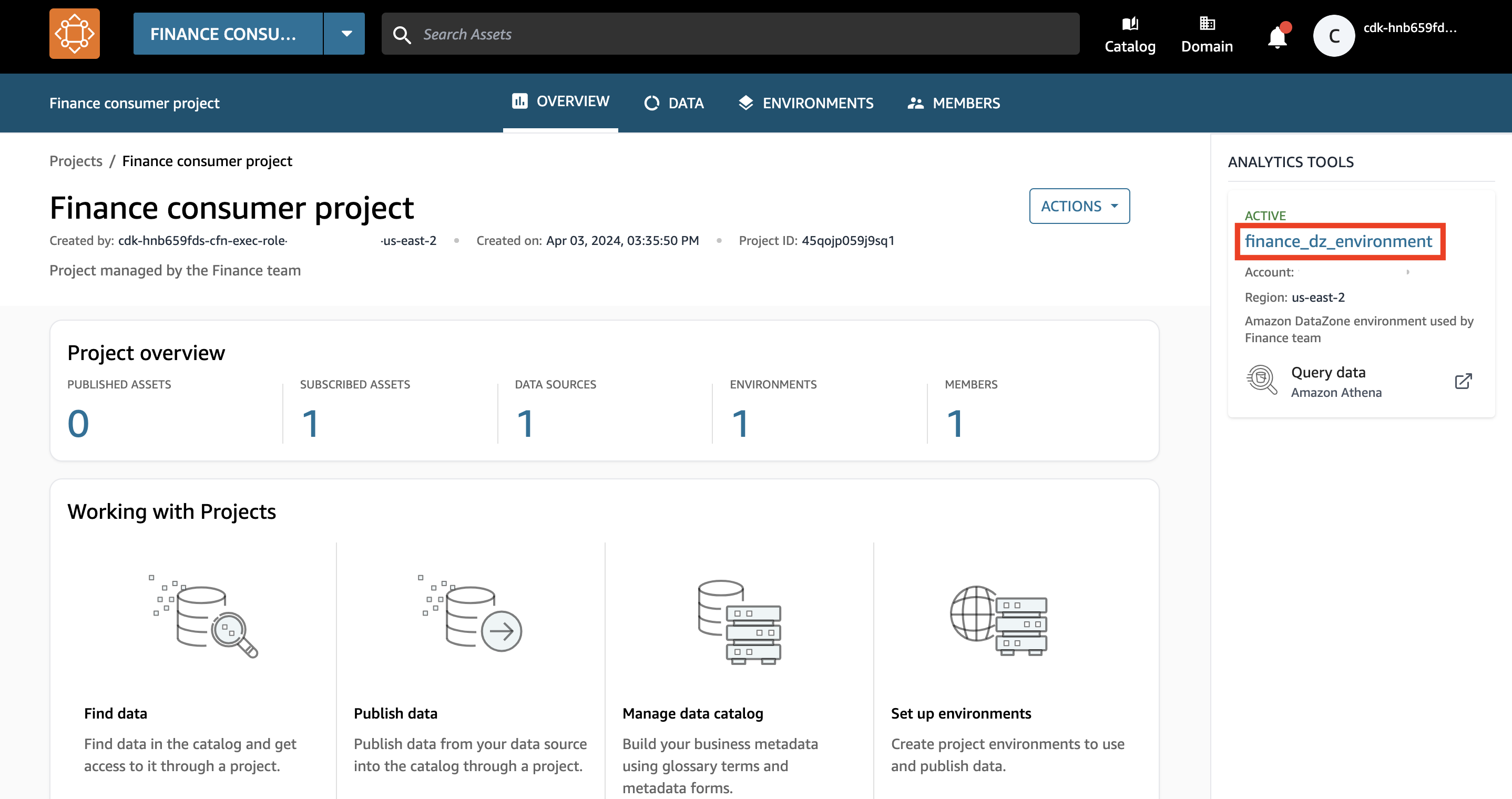
- Dans le volet de navigation, sous Ressources de données, choisissez Inscrit.
- Vérifiez que votre environnement a désormais accès aux données de vente.
L'ajout automatique de l'actif de données à votre environnement peut prendre quelques minutes.
- Choisissez l'icône du nouvel onglet pour Données de requête.
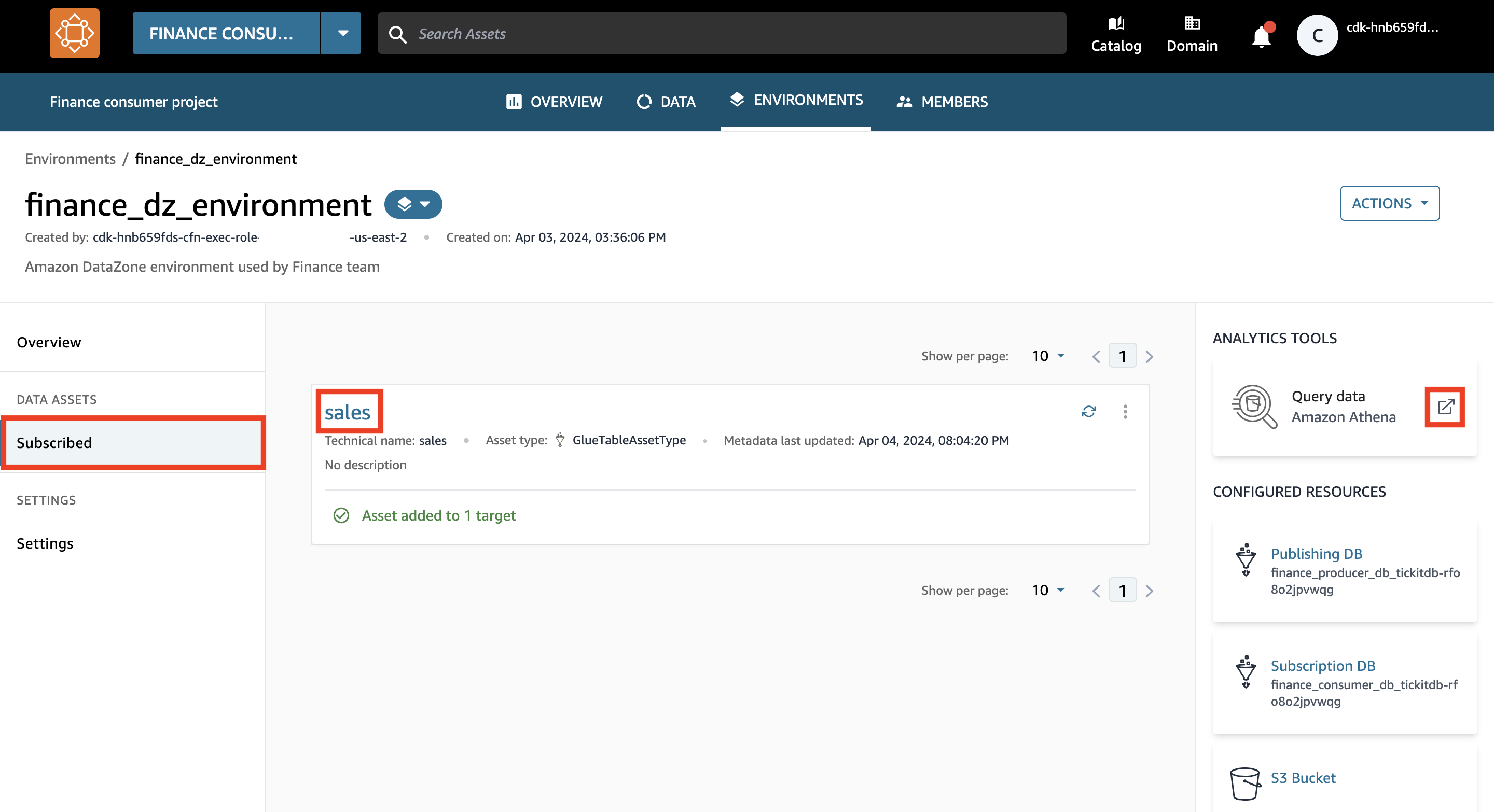
Un nouvel onglet s'ouvre avec l'éditeur de requêtes Athena.
- Pour Base de données, choisissez
finance_consumer_db_tickitdb-<suffix>.
Cette base de données contiendra vos actifs de données souscrits.

- Générez un aperçu du tableau des ventes en choisissant le menu d'options (trois points verticaux) et en choisissant Tableau de prévisualisation.
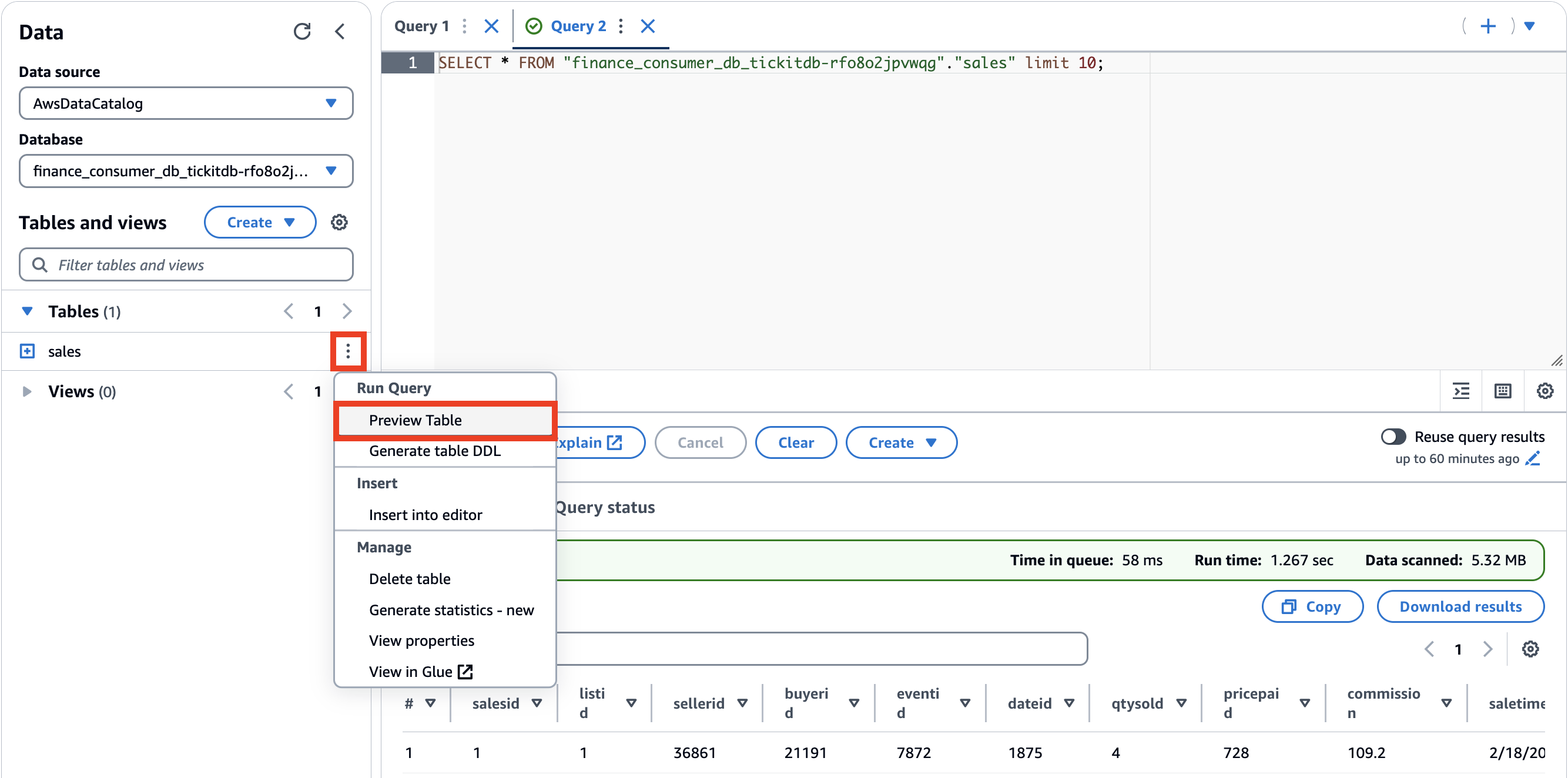
Nettoyer
Pour nettoyer vos ressources, procédez comme suit:
- Revenez au rôle d'administrateur que vous avez utilisé pour déployer la pile CloudFormation.
- Sur la console Amazon DataZone, supprimer les projets utilisé dans ce post. Cela supprimera la plupart des objets liés au projet, tels que les ressources de données et les environnements.
- Sur la console AWS CloudFormation, supprimez la pile que vous avez déployée au début de cet article.
- Sur la console Amazon S3, supprimez les compartiments S3 contenant l'ensemble de données tickit.
- Sur la console Lake Formation, supprimez les administrateurs Lake Formation enregistrés par Amazon DataZone.
- Sur la console Lake Formation, supprimez les tables et bases de données créées par Amazon DataZone.
Conclusion
Dans cet article, nous avons expliqué comment l'intégration entre Amazon DataZone et le mode d'accès hybride Lake Formation simplifie le processus de démarrage d'Amazon DataZone pour la gouvernance de bout en bout de vos données dans le catalogue de données AWS Glue. Cette intégration vous aide à contourner les étapes manuelles d'intégration à Lake Formation avant de pouvoir commencer à utiliser Amazon DataZone.
Pour plus d'informations sur la façon de démarrer avec Amazon DataZone, consultez le Guide de Démarrage. . Check out the Consultez le YouTube playlist pour certaines des dernières démos d'Amazon DataZone et de brèves descriptions des fonctionnalités disponibles. Pour plus d'informations sur Amazon DataZone, consultez Comment Amazon DataZone aide les clients à trouver de la valeur dans les océans de données.
À propos des auteurs
 Utkarsh Mittal est chef de produit technique senior pour Amazon DataZone chez AWS. Il est passionné par la création de produits innovants qui simplifient le parcours analytique de bout en bout des clients. En dehors du monde de la technologie, Utkarsh adore jouer de la musique, la batterie étant sa dernière activité.
Utkarsh Mittal est chef de produit technique senior pour Amazon DataZone chez AWS. Il est passionné par la création de produits innovants qui simplifient le parcours analytique de bout en bout des clients. En dehors du monde de la technologie, Utkarsh adore jouer de la musique, la batterie étant sa dernière activité.
 Praveen Kumar est un architecte principal de solutions d'analyse chez AWS avec une expertise dans la conception, la création et la mise en œuvre de plates-formes de données et d'analyse modernes à l'aide de services centrés sur le cloud. Ses domaines d'intérêt sont la technologie sans serveur, les entrepôts de données cloud modernes, le streaming et les applications d'IA générative.
Praveen Kumar est un architecte principal de solutions d'analyse chez AWS avec une expertise dans la conception, la création et la mise en œuvre de plates-formes de données et d'analyse modernes à l'aide de services centrés sur le cloud. Ses domaines d'intérêt sont la technologie sans serveur, les entrepôts de données cloud modernes, le streaming et les applications d'IA générative.
 Paul Villena est un architecte senior de solutions analytiques chez AWS avec une expertise dans la création de solutions de données et d'analyses modernes pour générer de la valeur commerciale. Il travaille avec les clients pour les aider à exploiter la puissance du cloud. Ses domaines d'intérêt sont l'infrastructure en tant que code, les technologies sans serveur et le codage en Python.
Paul Villena est un architecte senior de solutions analytiques chez AWS avec une expertise dans la création de solutions de données et d'analyses modernes pour générer de la valeur commerciale. Il travaille avec les clients pour les aider à exploiter la puissance du cloud. Ses domaines d'intérêt sont l'infrastructure en tant que code, les technologies sans serveur et le codage en Python.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/amazon-datazone-announces-integration-with-aws-lake-formation-hybrid-access-mode-for-the-aws-glue-data-catalog/

