Le monde en évolution rapide d’aujourd’hui exige des informations et des décisions opportunes, ce qui renforce l’importance du streaming de données. Les données en streaming font référence aux données générées en continu à partir de diverses sources. Les sources de ces données, telles que les événements de parcours de navigation, la capture de données modifiées (CDC), les journaux d'applications et de services et les flux de données de l'Internet des objets (IoT), prolifèrent. Snowflake propose deux options pour importer des données en streaming sur sa plateforme : Snowpipe et Snowflake Snowpipe Streaming. Snowpipe convient aux cas d'utilisation d'ingestion de fichiers (traitement par lots), tels que le chargement de fichiers volumineux à partir de Service de stockage simple Amazon (Amazon S3) vers Snowflake. Snowpipe Streaming, une fonctionnalité plus récente publiée en mars 2023, convient aux cas d'utilisation d'ingestion d'ensembles de lignes (streaming), tels que le chargement d'un flux continu de données à partir de Flux de données Amazon Kinesis or Amazon Managed Streaming pour Apache Kafka (AmazonMSK).
Avant Snowpipe Streaming, les clients AWS utilisaient Snowpipe pour les deux cas d'utilisation : l'ingestion de fichiers et l'ingestion d'ensembles de lignes. Tout d'abord, vous avez ingéré des données en streaming sur Kinesis Data Streams ou Amazon MSK, puis vous avez utilisé Amazon Data Firehose pour agréger et écrire des flux sur Amazon S3, puis vous avez utilisé Snowpipe pour charger les données dans Snowflake. Cependant, ce processus en plusieurs étapes peut entraîner des retards allant jusqu'à une heure avant que les données ne soient disponibles pour analyse dans Snowflake. De plus, cela coûte cher, surtout lorsque vous avez de petits fichiers que Snowpipe doit télécharger sur le cluster client Snowflake.
Pour résoudre ce problème, Amazon Data Firehose s'intègre désormais à Snowpipe Streaming, vous permettant de capturer, transformer et diffuser des flux de données depuis Kinesis Data Streams, Amazon MSK et Firehose Direct PUT vers Snowflake en quelques secondes et à faible coût. En quelques clics sur la console Amazon Data Firehose, vous pouvez configurer un flux Firehose pour transmettre des données à Snowflake. Il n'y a aucun engagement ni investissement initial pour utiliser Amazon Data Firehose, et vous ne payez que pour la quantité de données diffusées.
Certaines fonctionnalités clés d'Amazon Data Firehose incluent :
- Service sans serveur entièrement géré – Vous n'avez pas besoin de gérer les ressources et Amazon Data Firehose s'adapte automatiquement au débit de votre source de données sans administration continue.
- Simple à utiliser sans code – Vous n'avez pas besoin de rédiger des candidatures.
- Livraison de données en temps réel – Vous pouvez transmettre des données à vos destinations rapidement et efficacement en quelques secondes.
- Intégration avec plus de 20 services AWS – Une intégration transparente est disponible pour de nombreux services AWS, tels que Kinesis Data Streams, Amazon MSK, Amazon VPC Flow Logs, les journaux AWS WAF, Amazon CloudWatch Logs, Amazon EventBridge, AWS IoT Core, etc.
- Modèle de paiement à l'utilisation – Vous ne payez que pour le volume de données traité par Amazon Data Firehose.
- Connectivité – Amazon Data Firehose peut se connecter à des sous-réseaux publics ou privés de votre VPC.
Cet article explique comment importer des données en streaming d'AWS vers Snowflake en quelques secondes pour effectuer des analyses avancées. Nous explorons les architectures courantes et illustrons comment mettre en place une solution low-code, sans serveur et rentable pour le streaming de données à faible latence.
Présentation de la solution
Voici les étapes pour mettre en œuvre la solution pour diffuser des données d'AWS vers Snowflake :
- Créez une base de données, un schéma et une table Snowflake.
- Créez un flux de données Kinesis.
- Créez un flux de diffusion Firehose avec Kinesis Data Streams comme source et Snowflake comme destination à l'aide d'un lien privé sécurisé.
- Pour tester la configuration, générez des exemples de données de flux à partir du Générateur de données Amazon Kinesis (KDG) avec le flux de livraison Firehose comme destination.
- Interrogez la table Snowflake pour valider les données chargées dans Snowflake.
La solution est décrite dans le diagramme d’architecture suivant.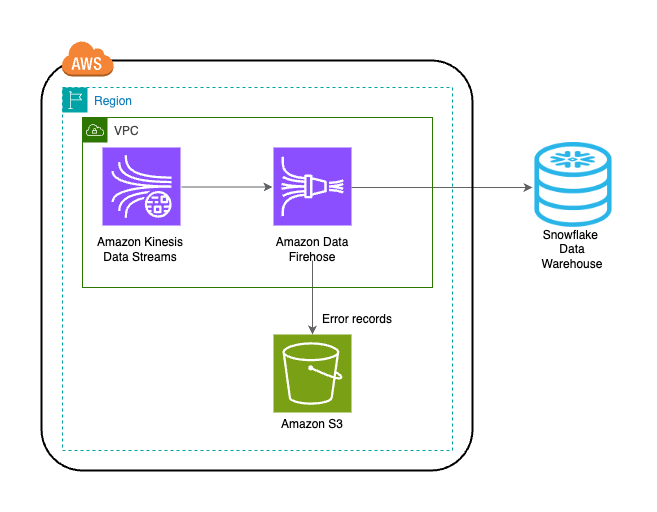
Pré-requis
Vous devez avoir les prérequis suivants :
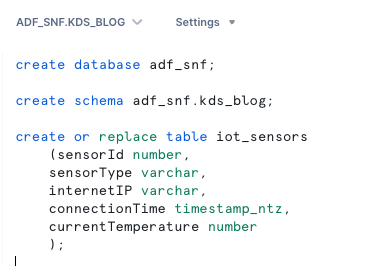
Créer une base de données, un schéma et une table Snowflake
Suivez les étapes suivantes pour configurer vos données dans Snowflake :
- Connectez-vous à votre compte Snowflake et créez la base de données :
- Créez un schéma dans la nouvelle base de données :
- Créez une table dans le nouveau schéma :
Créer un flux de données Kinesis
Effectuez les étapes suivantes pour créer votre flux de données :
- Sur la console Kinesis Data Streams, choisissez Flux de données dans le volet de navigation.
- Selectionnez Créer un flux de données.

- Pour Nom du flux de données, entrez un nom (par exemple,
KDS-Demo-Stream). - Laissez les paramètres restants par défaut.
- Choisissez Créer un flux de données.

Créer un flux de diffusion Firehose
Effectuez les étapes suivantes pour créer un flux de diffusion Firehose avec Kinesis Data Streams comme source et Snowflake comme destination :
- Sur la console Amazon Data Firehose, choisissez Créer un flux Firehose.
- Pour Identifier, choisissez Flux de données Amazon Kinesis.
- Pour dentaire, choisissez Flocon.
- Pour Flux de données Kinesis, accédez au flux de données que vous avez créé précédemment.
- Pour Nom du flux Firehose, laissez le nom généré par défaut ou entrez un nom de votre préférence.
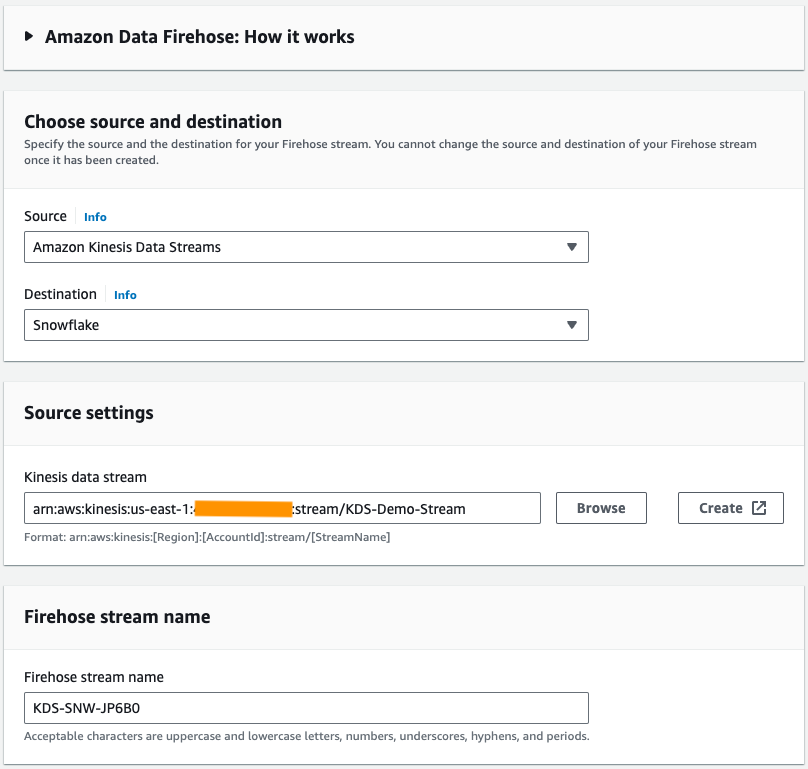
- Sous Paramètres de connexion, fournissez les informations suivantes pour connecter Amazon Data Firehose à Snowflake :
- Pour URL du compte Snowflake, saisissez l'URL de votre compte Snowflake.
- Pour Utilisateur, saisissez le nom d'utilisateur généré dans les prérequis.
- Pour Clé privée, saisissez la clé privée générée dans les prérequis. Assurez-vous que la clé privée est au format PKCS8. Ne pas inclure le PEM
header-BEGINpréfixe etfooter-ENDsuffixe dans le cadre de la clé privée. Si la clé est répartie sur plusieurs lignes, supprimez les sauts de ligne. - Pour Rôle, sélectionnez Utiliser le rôle Snowflake personnalisé et entrez le rôle IAM qui a accès pour écrire dans la table de base de données.
Vous pouvez vous connecter à Snowflake à l’aide d’une connectivité publique ou privée. Si vous ne fournissez pas de point de terminaison de VPC, le mode de connectivité par défaut est public. Pour autoriser la liste des adresses IP Firehose dans votre stratégie réseau Snowflake, reportez-vous à Choisissez un flocon de neige pour votre destination. Si vous utilisez une URL de lien privé, fournissez l'ID VPCE à l'aide de SYSTÈME$GET_PRIVATELINK_CONFIG:
Cette fonction renvoie une représentation JSON des informations du compte Snowflake nécessaires pour faciliter la configuration en libre-service de la connectivité privée au service Snowflake, comme indiqué dans la capture d'écran suivante.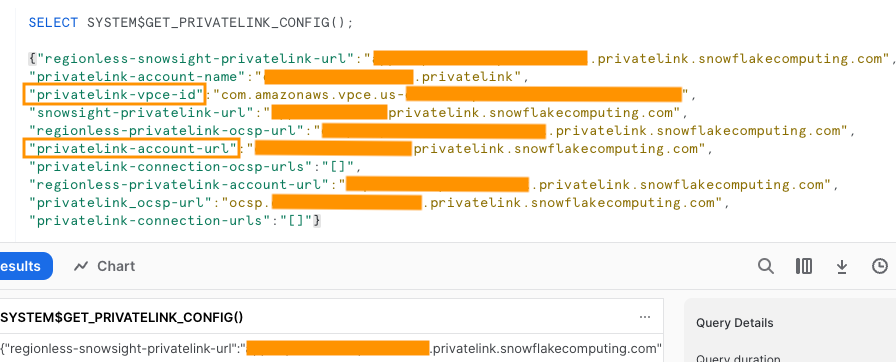
- Pour cet article, nous utilisons un lien privé, donc pour ID VPCE, saisissez l'ID VPCE.
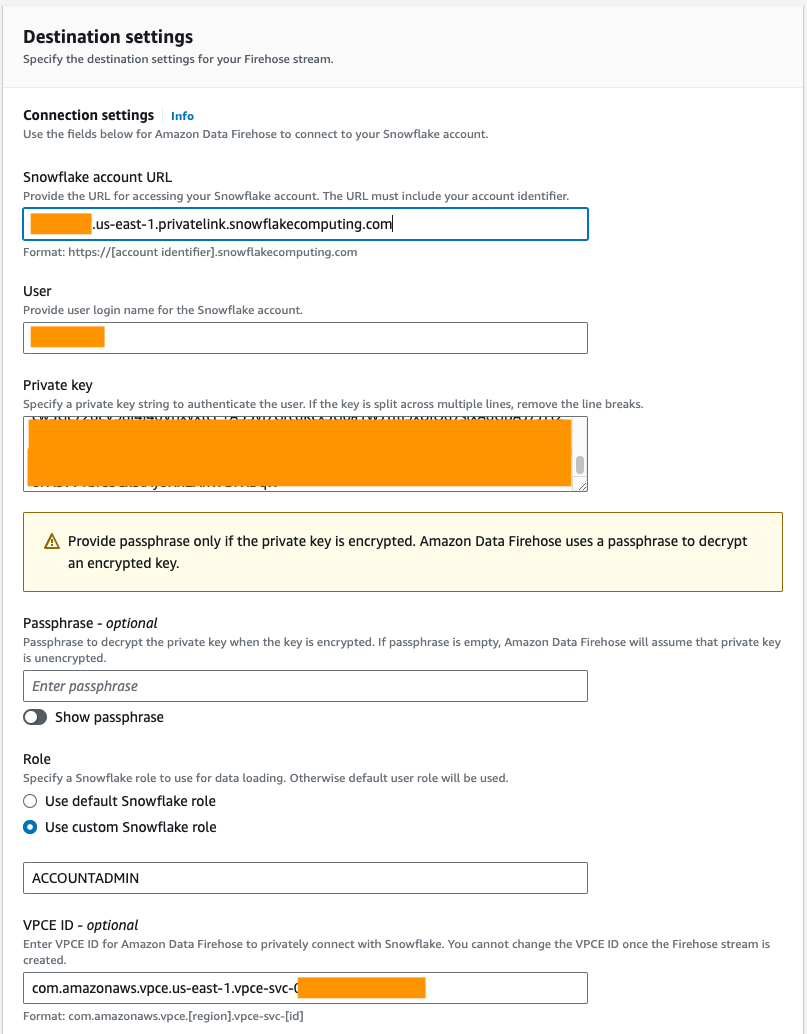
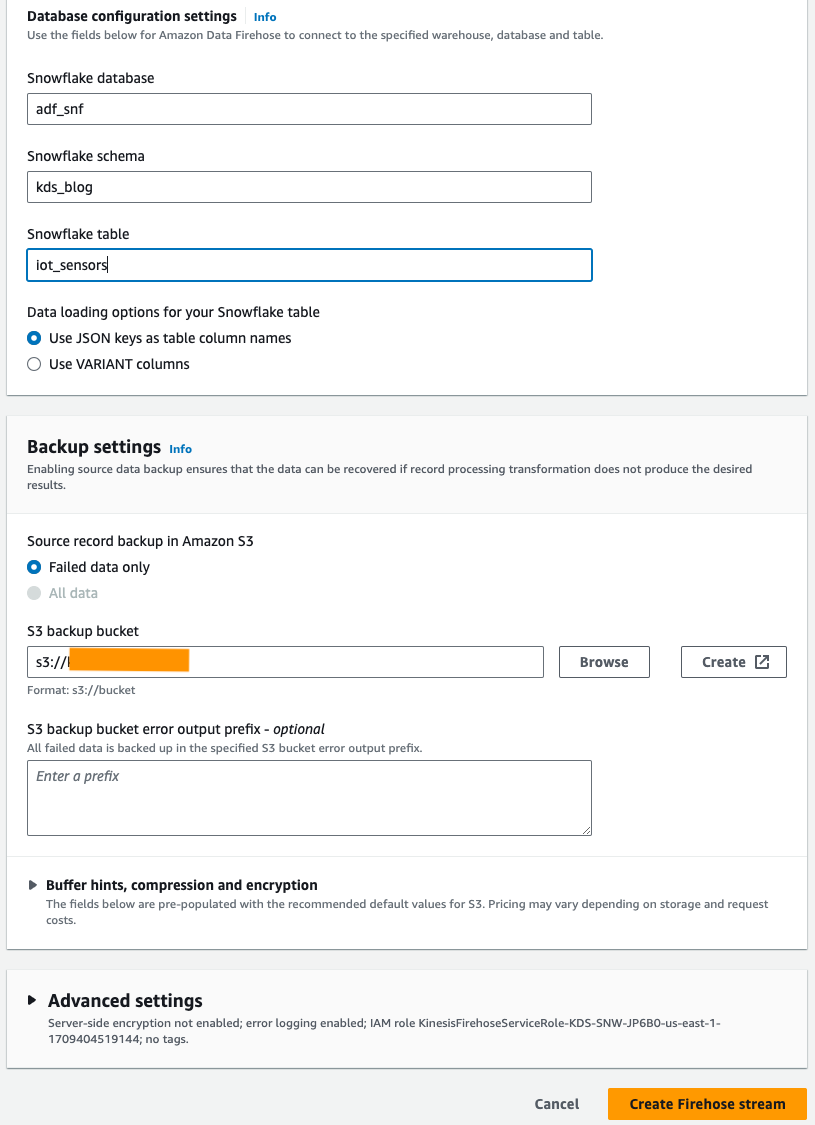
- Sous Paramètres de configuration de la base de données, entrez les noms de votre base de données Snowflake, de votre schéma et de vos tables.
- Dans le Paramètres de sauvegarde section, pour Compartiment de sauvegarde S3, saisissez le compartiment que vous avez créé dans le cadre des conditions préalables.
- Selectionnez Créer un flux Firehose.
Alternativement, vous pouvez utiliser un AWS CloudFormation modèle pour créer le flux de diffusion Firehose avec Snowflake comme destination plutôt que d'utiliser la console Amazon Data Firehose.
Pour utiliser la pile CloudFormation, choisissez
![]()
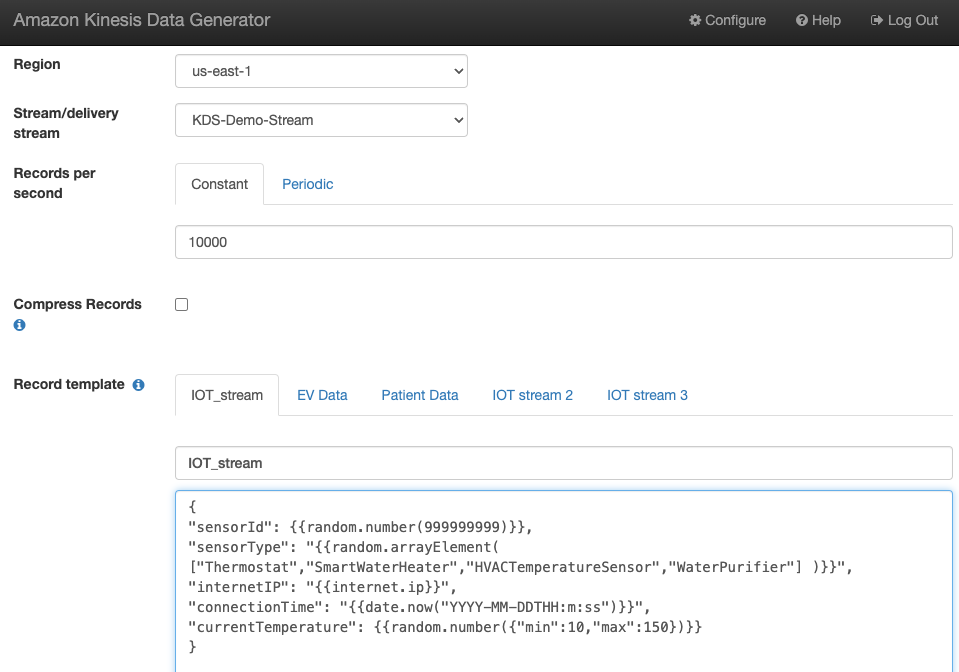
Générer des exemples de données de flux
Générez des exemples de données de flux à partir du KDG avec le flux de données Kinesis que vous avez créé :
Interroger la table Snowflake
Interrogez la table Snowflake :
Vous pouvez confirmer que les données générées par le KDG qui ont été envoyées à Kinesis Data Streams sont chargées dans la table Snowflake via Amazon Data Firehose.

Dépannage
Si les données ne sont pas chargées dans Kinesis Data Steams après que le KDG ait envoyé les données au flux de diffusion Firehose, actualisez et assurez-vous que vous êtes connecté au KDG.
Si vous avez apporté des modifications à la définition de la table de destination Snowflake, recréez le flux de diffusion Firehose.
Nettoyer
Pour éviter de devoir payer des frais futurs, supprimez les ressources que vous avez créées dans le cadre de cet exercice si vous ne prévoyez pas de les utiliser davantage.
Conclusion
Amazon Data Firehose offre un moyen simple de transmettre des données à Snowpipe Streaming, vous permettant ainsi de réaliser des économies et de réduire la latence à quelques secondes. Pour essayer Amazon Kinesis Firehose avec Snowflake, reportez-vous à l'atelier de destination Amazon Data Firehose avec Snowflake.
À propos des auteurs
 Swapna Bandla est architecte de solutions senior au sein de l'équipe AWS Analytics Specialist SA. Swapna a une passion pour la compréhension des besoins des clients en matière de données et d'analyse et pour leur permettre de développer des solutions cloud bien architecturées. En dehors du travail, elle aime passer du temps avec sa famille.
Swapna Bandla est architecte de solutions senior au sein de l'équipe AWS Analytics Specialist SA. Swapna a une passion pour la compréhension des besoins des clients en matière de données et d'analyse et pour leur permettre de développer des solutions cloud bien architecturées. En dehors du travail, elle aime passer du temps avec sa famille.
 Mostafa Mansour est chef de produit principal - Tech chez Amazon Web Services où il travaille sur Amazon Kinesis Data Firehose. Il se spécialise dans le développement d'expériences produit intuitives qui résolvent des défis complexes pour les clients à grande échelle. Lorsqu'il ne travaille pas dur sur Amazon Kinesis Data Firehose, vous trouverez probablement Mostafa sur le court de squash, où il aime affronter des challengers et perfectionner ses amortis.
Mostafa Mansour est chef de produit principal - Tech chez Amazon Web Services où il travaille sur Amazon Kinesis Data Firehose. Il se spécialise dans le développement d'expériences produit intuitives qui résolvent des défis complexes pour les clients à grande échelle. Lorsqu'il ne travaille pas dur sur Amazon Kinesis Data Firehose, vous trouverez probablement Mostafa sur le court de squash, où il aime affronter des challengers et perfectionner ses amortis.
 Bosco Albuquerque est un architecte de solutions partenaire senior chez AWS et a plus de 20 ans d'expérience de travail avec des produits de base de données et d'analyse de fournisseurs de bases de données d'entreprise et de fournisseurs de cloud. Il a aidé des entreprises technologiques à concevoir et à mettre en œuvre des solutions et des produits d'analyse de données.
Bosco Albuquerque est un architecte de solutions partenaire senior chez AWS et a plus de 20 ans d'expérience de travail avec des produits de base de données et d'analyse de fournisseurs de bases de données d'entreprise et de fournisseurs de cloud. Il a aidé des entreprises technologiques à concevoir et à mettre en œuvre des solutions et des produits d'analyse de données.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/uplevel-your-data-architecture-with-real-time-streaming-using-amazon-data-firehose-and-snowflake/

