Générateur d'images Amazon Titan G1 est un modèle texte-image de pointe, disponible via Socle amazonien, capable de comprendre les invites décrivant plusieurs objets dans divers contextes et de capturer ces détails pertinents dans les images qu'il génère. Il est disponible dans les régions AWS USA Est (Virginie du Nord) et USA Ouest (Oregon) et peut effectuer des tâches avancées d'édition d'images telles que le recadrage intelligent, l'in-painting et les modifications d'arrière-plan. Cependant, les utilisateurs souhaitent adapter le modèle à des caractéristiques uniques dans des ensembles de données personnalisés sur lesquels le modèle n'est pas déjà formé. Les ensembles de données personnalisés peuvent inclure des données hautement exclusives qui sont cohérentes avec les directives de votre marque ou des styles spécifiques tels qu'une campagne précédente. Pour répondre à ces cas d'utilisation et générer des images entièrement personnalisées, vous pouvez affiner Amazon Titan Image Generator avec vos propres données en utilisant modèles personnalisés pour Amazon Bedrock.
De la génération d'images à leur édition, les modèles de conversion texte-image ont de nombreuses applications dans tous les secteurs. Ils peuvent améliorer la créativité des employés et offrir la possibilité d'imaginer de nouvelles possibilités simplement avec des descriptions textuelles. Par exemple, il peut faciliter la conception et la planification des étages pour les architectes et permettre une innovation plus rapide en offrant la possibilité de visualiser diverses conceptions sans le processus manuel de création. De même, il peut faciliter la conception dans divers secteurs tels que la fabrication, le design de mode dans la vente au détail et la conception de jeux en rationalisant la génération de graphiques et d'illustrations. Les modèles de synthèse texte-image améliorent également votre expérience client en permettant des publicités personnalisées ainsi que des chatbots visuels interactifs et immersifs dans les cas d'utilisation des médias et du divertissement.
Dans cet article, nous vous guidons tout au long du processus de réglage fin du modèle Amazon Titan Image Generator pour découvrir deux nouvelles catégories : Ron le chien et Smila le chat, nos animaux de compagnie préférés. Nous expliquons comment préparer vos données pour la tâche de réglage fin du modèle et comment créer une tâche de personnalisation de modèle dans Amazon Bedrock. Enfin, nous vous montrons comment tester et déployer votre modèle affiné avec Débit provisionné.
 |
 |
| Ron le chien | Smila le chat |
Évaluation des capacités du modèle avant d'affiner un travail
Les modèles Foundation sont formés sur de grandes quantités de données, il est donc possible que votre modèle fonctionne suffisamment bien dès le départ. C'est pourquoi il est recommandé de vérifier si vous avez réellement besoin d'affiner votre modèle pour votre cas d'utilisation ou si une ingénierie rapide est suffisante. Essayons de générer quelques images de Ron le chien et de Smila le chat avec le modèle de base Amazon Titan Image Generator, comme indiqué dans les captures d'écran suivantes.
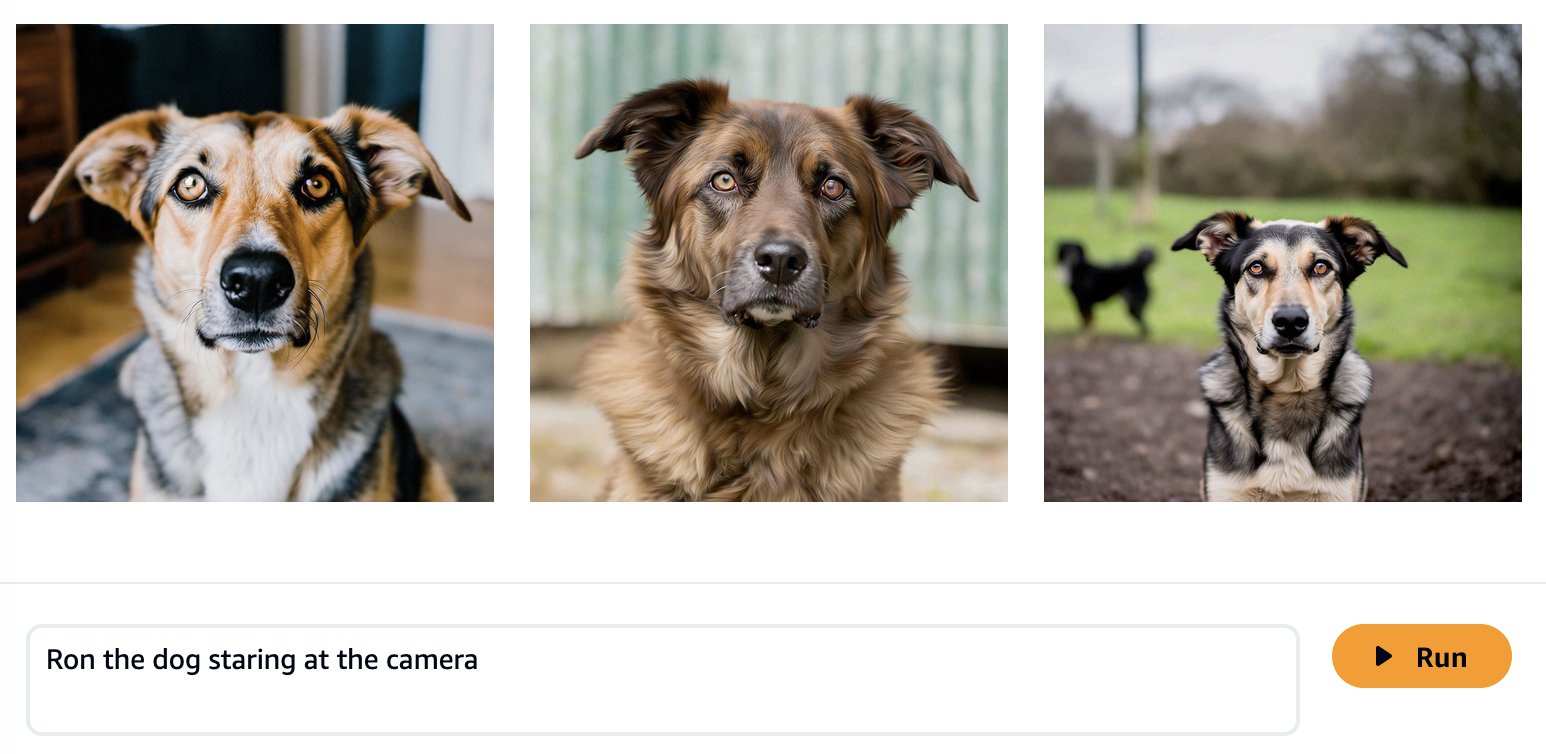

Comme prévu, le modèle prêt à l'emploi ne connaît pas encore Ron et Smila, et les sorties générées montrent différents chiens et chats. Avec une ingénierie rapide, nous pouvons fournir plus de détails pour nous rapprocher de l’apparence de nos animaux préférés.


Bien que les images générées ressemblent davantage à Ron et Smila, nous constatons que le modèle n'est pas capable de reproduire toute leur ressemblance. Commençons maintenant un travail de mise au point avec les photos de Ron et Smila pour obtenir des résultats cohérents et personnalisés.
Affiner le générateur d'images Amazon Titan
Amazon Bedrock vous offre une expérience sans serveur pour affiner votre modèle Amazon Titan Image Generator. Il vous suffit de préparer vos données et de sélectionner vos hyperparamètres, et AWS se chargera du gros du travail à votre place.
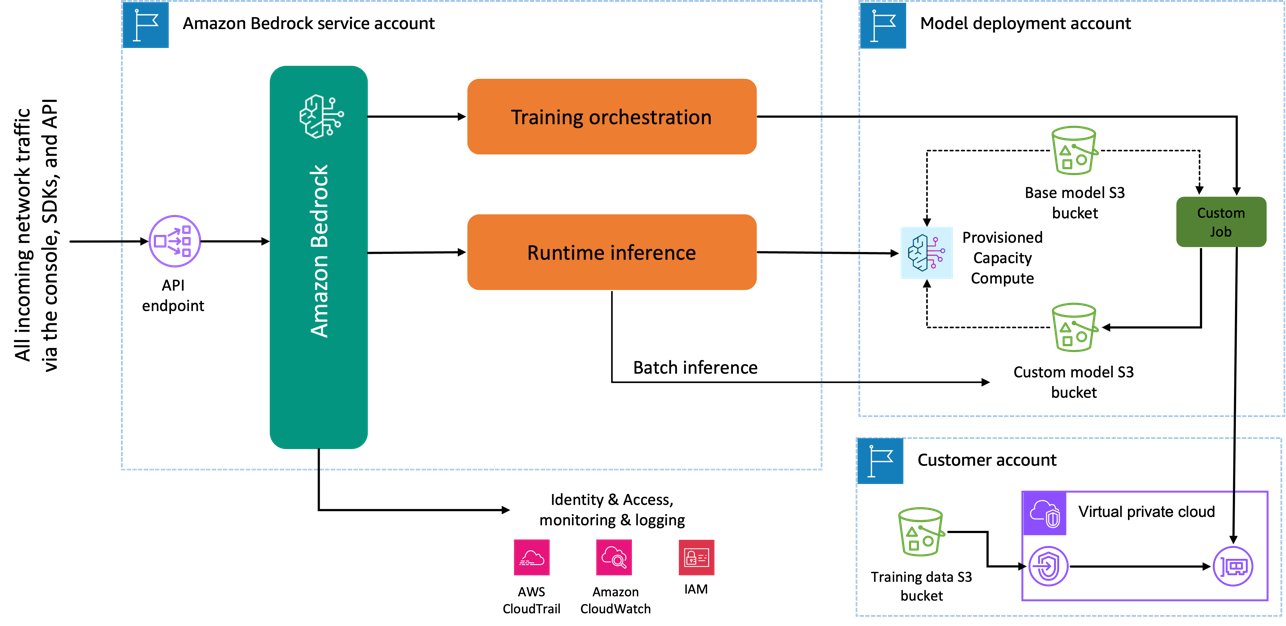
Lorsque vous utilisez le modèle Amazon Titan Image Generator pour effectuer des réglages précis, une copie de ce modèle est créée dans le compte de développement de modèles AWS, détenu et géré par AWS, et une tâche de personnalisation du modèle est créée. Ce travail accède ensuite aux données de réglage fin d'un VPC et le modèle Amazon Titan voit ses poids mis à jour. Le nouveau modèle est ensuite enregistré dans un Service de stockage simple Amazon (Amazon S3) situé dans le même compte de développement de modèle que le modèle pré-entraîné. Il peut désormais être utilisé à des fins d'inférence uniquement par votre compte et n'est partagé avec aucun autre compte AWS. Lors de l'exécution de l'inférence, vous accédez à ce modèle via un calcul de la capacité provisionnée ou directement, en utilisant inférence par lots pour Amazon Bedrock. Indépendamment de la modalité d'inférence choisie, vos données restent dans votre compte et ne sont copiées sur aucun compte appartenant à AWS ni utilisées pour améliorer le modèle Amazon Titan Image Generator.
Le diagramme suivant illustre ce flux de travail.
Confidentialité des données et sécurité du réseau
Vos données utilisées pour le réglage fin, y compris les invites, ainsi que les modèles personnalisés, restent privées dans votre compte AWS. Ils ne sont pas partagés ni utilisés pour la formation de modèles ou l'amélioration des services, et ne sont pas partagés avec des fournisseurs de modèles tiers. Toutes les données utilisées pour le réglage fin sont cryptées en transit et au repos. Les données restent dans la même région où l'appel API est traité. Vous pouvez aussi utiliser Lien privé AWS pour créer une connexion privée entre le compte AWS où résident vos données et le VPC.
Préparation des données
Avant de pouvoir créer une tâche de personnalisation de modèle, vous devez préparez votre ensemble de données d'entraînement. Le format de votre ensemble de données de formation dépend du type de tâche de personnalisation que vous créez (mise au point ou pré-formation continue) et de la modalité de vos données (texte à texte, texte à image ou image à image). intégration). Pour le modèle Amazon Titan Image Generator, vous devez fournir les images que vous souhaitez utiliser pour le réglage fin et une légende pour chaque image. Amazon Bedrock s'attend à ce que vos images soient stockées sur Amazon S3 et que les paires d'images et de légendes soient fournies au format JSONL avec plusieurs lignes JSON.
Chaque ligne JSON est un échantillon contenant une référence d'image, l'URI S3 d'une image et une légende qui inclut une invite textuelle pour l'image. Vos images doivent être au format JPEG ou PNG. Le code suivant montre un exemple du format :
{"image-ref": "s3://bucket/path/to/image001.png", "caption": ""} {"image-ref": "s3://bucket/path/to/image002.png", "caption": ""} {"image-ref": "s3://bucket/path/to/image003.png", "caption": ""}
Parce que « Ron » et « Smila » sont des noms qui pourraient également être utilisés dans d'autres contextes, comme le nom d'une personne, nous ajoutons les identifiants « Ron le chien » et « Smila le chat » lors de la création de l'invite pour affiner notre modèle. . Bien que cela ne soit pas une exigence pour le flux de travail de réglage fin, ces informations supplémentaires fournissent plus de clarté contextuelle au modèle lors de sa personnalisation pour les nouvelles classes et éviteront la confusion de « Ron le chien » avec une personne appelée Ron et « » Smila le chat » avec la ville Smila en Ukraine. En utilisant cette logique, les images suivantes montrent un échantillon de notre ensemble de données de formation.
 |
 |
 |
| Ron le chien allongé sur un lit pour chien blanc | Ron le chien assis sur un sol carrelé | Ron le chien allongé sur un siège auto |
 |
 |
 |
| Smila le chat allongé sur un canapé | Smila le chat regarde la caméra allongé sur un canapé | Smila le chat couché dans une cage de transport |
Lors de la transformation de nos données au format attendu par la tâche de personnalisation, nous obtenons l'exemple de structure suivant :
{"image-ref": "/ron_01.jpg", "caption": "Ron le chien allongé sur un lit pour chien blanc"} {"image-ref": "/ron_02.jpg", "caption": "Ron le chien assis sur un sol carrelé"} {"image-ref": "/ron_03.jpg", "caption": "Ron le chien allongé sur un siège auto"} {"image-ref": "/smila_01.jpg", "caption": "Smila le chat allongé sur un canapé"} {"image-ref": "/smila_02.jpg", "caption": "Smila le chat assis près de la fenêtre à côté d'un chat statue"} {"image-ref": "/smila_03.jpg", "caption": "Smila le chat allongé sur une cage de transport"}
Après avoir créé notre fichier JSONL, nous devons le stocker sur un bucket S3 pour démarrer notre travail de personnalisation. Les tâches de réglage fin d'Amazon Titan Image Generator G1 fonctionneront avec 5 à 10,000 60 images. Pour l'exemple évoqué dans cet article, nous utilisons 30 images : 30 de Ron le chien et XNUMX de Smila le chat. En général, fournir davantage de variétés du style ou de la classe que vous essayez d’apprendre améliorera la précision de votre modèle affiné. Cependant, plus vous utilisez d’images pour le réglage fin, plus le travail de réglage fin prendra du temps. Le nombre d’images utilisées influence également le prix de votre travail peaufiné. Faire référence à Tarification du substrat rocheux d’Amazon pour plus d'information.
Affiner le générateur d'images Amazon Titan
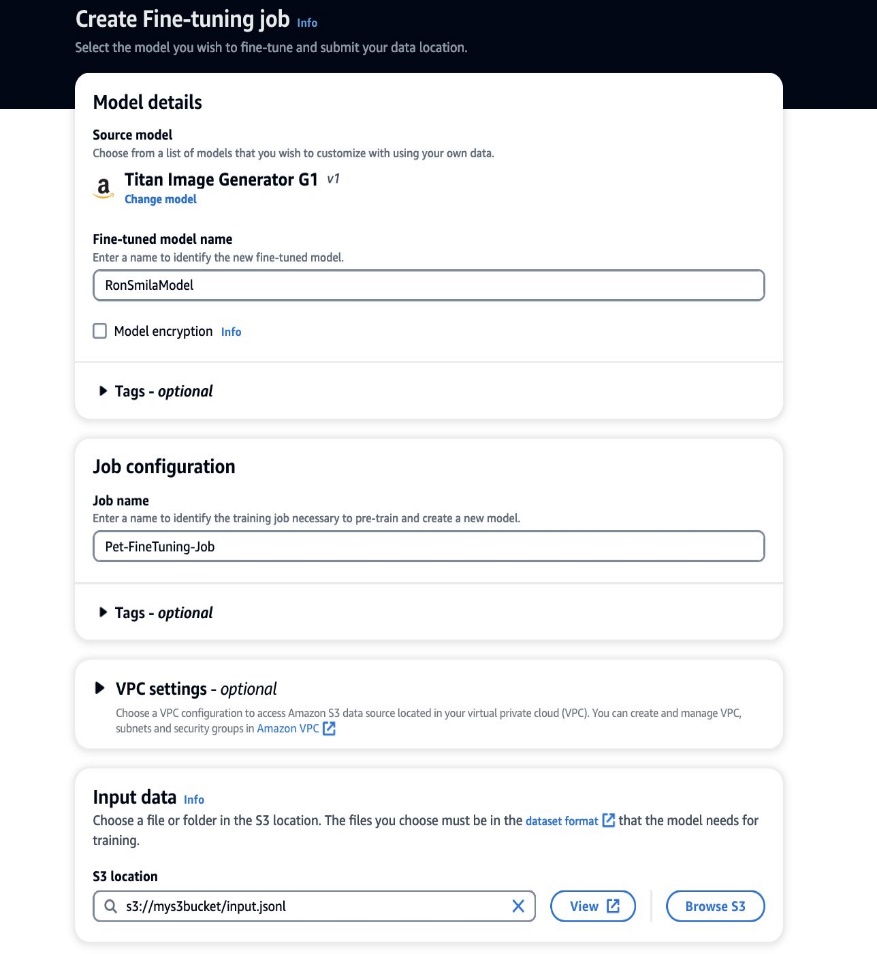
Maintenant que nos données d'entraînement sont prêtes, nous pouvons commencer un nouveau travail de personnalisation. Ce processus peut être effectué à la fois via la console Amazon Bedrock ou via les API. Pour utiliser la console Amazon Bedrock, procédez comme suit :
- Sur la console Amazon Bedrock, choisissez Modèles personnalisés dans le volet de navigation.
- Sur le Personnaliser le modèle menu, choisissez Créer un travail de réglage fin.
- Pour Nom du modèle affiné, saisissez un nom pour votre nouveau modèle.
- Pour Configuration de la tâche, saisissez un nom pour la tâche de formation.
- Pour Des données d'entrée, entrez le chemin S3 des données d'entrée.
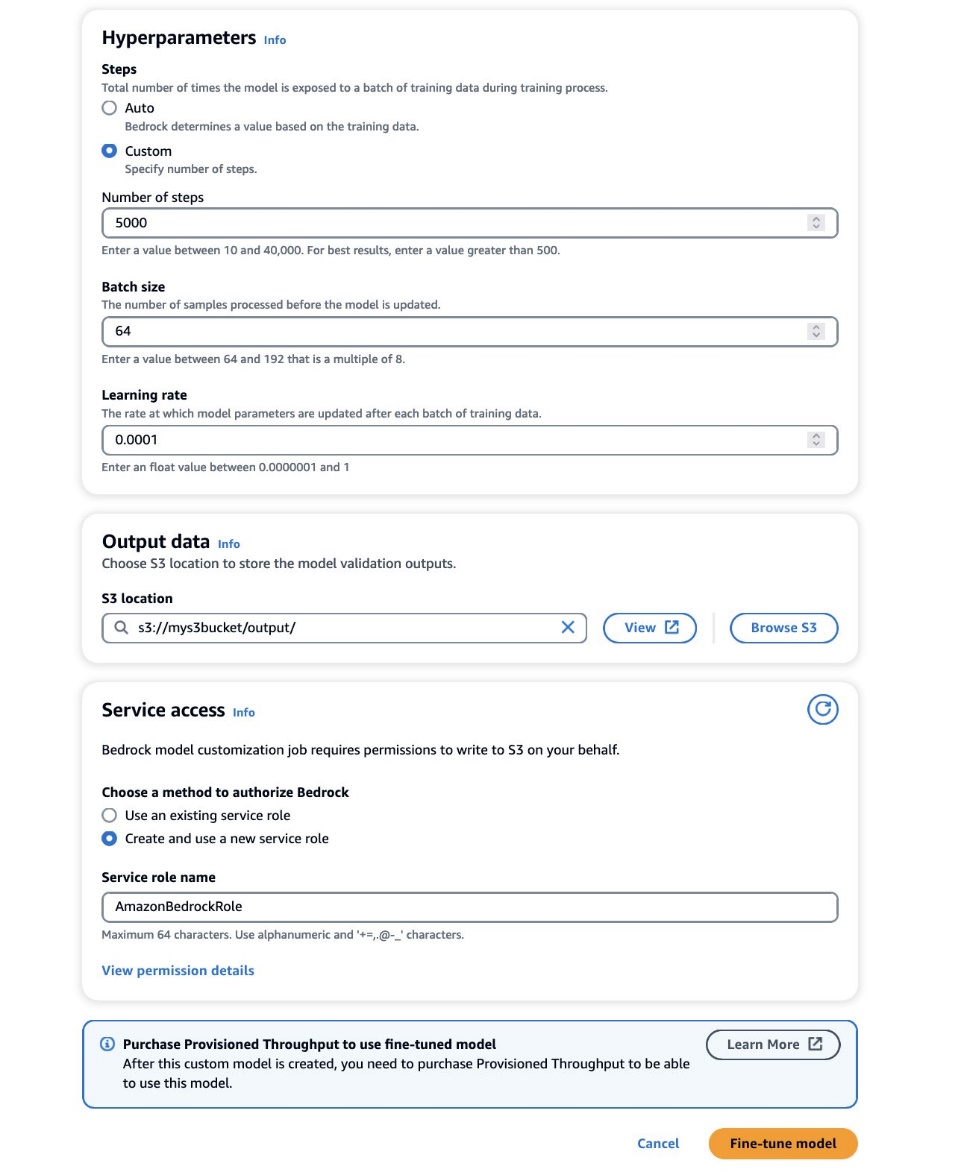
- Dans le Hyperparamètres section, fournissez les valeurs pour les éléments suivants :
- Nombre d'étapes – Le nombre de fois où le modèle est exposé à chaque lot.
- Taille du lot – Le nombre d'échantillons traités avant la mise à jour des paramètres du modèle.
- Taux d'apprentissage – La fréquence à laquelle les paramètres du modèle sont mis à jour après chaque lot. Le choix de ces paramètres dépend d'un ensemble de données donné. De manière générale, nous vous recommandons de commencer par fixer la taille du lot à 8, le taux d'apprentissage à 1e-5, et de définir le nombre d'étapes en fonction du nombre d'images utilisées, comme détaillé dans le tableau suivant.
| Nombre d'images fournies | 8 | 32 | 64 | 1,000 | 10,000 |
| Nombre d'étapes recommandées | 1,000 | 4,000 | 8,000 | 10,000 | 12,000 |
Si les résultats de votre travail de réglage ne sont pas satisfaisants, envisagez d'augmenter le nombre d'étapes si vous n'observez aucun signe de style dans les images générées, et de diminuer le nombre d'étapes si vous observez le style dans les images générées mais avec des artefacts ou du flou. Si le modèle affiné ne parvient pas à apprendre le style unique de votre ensemble de données même après 40,000 XNUMX étapes, envisagez d'augmenter la taille du lot ou le taux d'apprentissage.
- Dans le Des données de sortie , entrez le chemin de sortie S3 où les sorties de validation, y compris les mesures de perte de validation et de précision enregistrées périodiquement, sont stockées.
- Dans le Accès au service section, générer un nouveau Gestion des identités et des accès AWS (IAM) ou choisissez un rôle IAM existant avec les autorisations nécessaires pour accéder à vos compartiments S3.
Cette autorisation permet à Amazon Bedrock de récupérer les ensembles de données d'entrée et de validation de votre compartiment désigné et de stocker les sorties de validation de manière transparente dans votre compartiment S3.
- Selectionnez Affiner le modèle.
Une fois les configurations correctes définies, Amazon Bedrock va désormais entraîner votre modèle personnalisé.
Déployez le générateur d'images Amazon Titan optimisé avec un débit provisionné
Après avoir créé un modèle personnalisé, Provisioned Throughput vous permet d'attribuer un taux de capacité de traitement prédéterminé et fixe au modèle personnalisé. Cette allocation fournit un niveau constant de performances et de capacité pour gérer les charges de travail, ce qui se traduit par de meilleures performances dans les charges de travail de production. Le deuxième avantage de Provisioned Throughput est le contrôle des coûts, car la tarification standard basée sur des jetons avec un mode d'inférence à la demande peut être difficile à prévoir à grande échelle.
Une fois le réglage fin de votre modèle terminé, ce modèle apparaîtra sur le Modèles personnalisés page sur la console Amazon Bedrock.
Pour acheter le débit provisionné, sélectionnez le modèle personnalisé que vous venez de peaufiner et choisissez Acheter le débit provisionné.
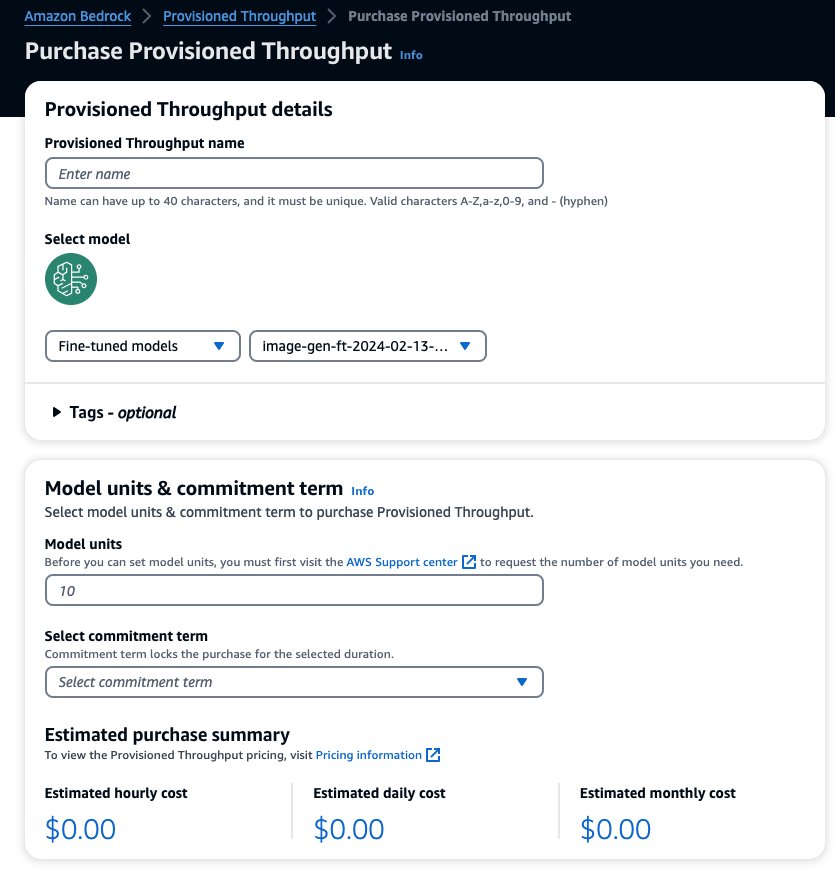
Cela préremplit le modèle sélectionné pour lequel vous souhaitez acheter le débit provisionné. Pour tester votre modèle affiné avant le déploiement, définissez les unités du modèle sur une valeur de 1 et définissez la durée d'engagement sur Pas d'engagement. Cela vous permet rapidement de commencer à tester vos modèles avec vos invites personnalisées et de vérifier si la formation est adéquate. De plus, lorsque de nouveaux modèles affinés et de nouvelles versions sont disponibles, vous pouvez mettre à jour le débit provisionné à condition de le mettre à jour avec d'autres versions du même modèle.
Des résultats affinés
Pour notre tâche de personnalisation du modèle sur Ron le chien et Smila le chat, les expériences ont montré que les meilleurs hyperparamètres étaient de 5,000 8 pas avec une taille de lot de 1 et un taux d'apprentissage de 5e-XNUMX.
Voici quelques exemples d'images générées par le modèle personnalisé.
 |
 |
 |
| Ron le chien portant une cape de super-héros | Ron le chien sur la lune | Ron le chien dans une piscine avec des lunettes de soleil |
 |
 |
 |
| Smila le chat sur la neige | Smila le chat en noir et blanc regardant la caméra | Smila le chat portant un chapeau de Noël |
Conclusion
Dans cet article, nous avons expliqué quand utiliser le réglage fin au lieu de concevoir vos invites pour une génération d'images de meilleure qualité. Nous avons montré comment affiner le modèle Amazon Titan Image Generator et déployer le modèle personnalisé sur Amazon Bedrock. Nous avons également fourni des directives générales sur la façon de préparer vos données pour un réglage précis et de définir des hyperparamètres optimaux pour une personnalisation plus précise du modèle.
Dans une prochaine étape, vous pouvez adapter ce qui suit exemple à votre cas d'utilisation pour générer des images hyper-personnalisées à l'aide d'Amazon Titan Image Generator.
À propos des auteurs
 Maira Ladeira Tanké est un scientifique principal des données en IA générative chez AWS. Forte d'une formation en apprentissage automatique, elle possède plus de 10 ans d'expérience dans l'architecture et la création d'applications d'IA avec des clients de tous secteurs. En tant que responsable technique, elle aide les clients à accélérer la création de valeur commerciale grâce à des solutions d'IA générative sur Amazon Bedrock. Pendant son temps libre, Maira aime voyager, jouer avec son chat Smila et passer du temps avec sa famille dans un endroit chaleureux.
Maira Ladeira Tanké est un scientifique principal des données en IA générative chez AWS. Forte d'une formation en apprentissage automatique, elle possède plus de 10 ans d'expérience dans l'architecture et la création d'applications d'IA avec des clients de tous secteurs. En tant que responsable technique, elle aide les clients à accélérer la création de valeur commerciale grâce à des solutions d'IA générative sur Amazon Bedrock. Pendant son temps libre, Maira aime voyager, jouer avec son chat Smila et passer du temps avec sa famille dans un endroit chaleureux.
 Daniel Mitchell est un architecte de solutions spécialisé en IA/ML chez Amazon Web Services. Il se concentre sur les cas d'utilisation de la vision par ordinateur et aide les clients de la région EMEA à accélérer leur parcours ML.
Daniel Mitchell est un architecte de solutions spécialisé en IA/ML chez Amazon Web Services. Il se concentre sur les cas d'utilisation de la vision par ordinateur et aide les clients de la région EMEA à accélérer leur parcours ML.
 Bharathi Srinivasan est Data Scientist chez AWS Professional Services, où elle adore créer des choses intéressantes sur Amazon Bedrock. Elle est passionnée par la création de valeur commerciale à partir des applications d’apprentissage automatique, en mettant l’accent sur l’IA responsable. En plus de créer de nouvelles expériences d'IA pour ses clients, Bharathi aime écrire de la science-fiction et se mettre au défi avec les sports d'endurance.
Bharathi Srinivasan est Data Scientist chez AWS Professional Services, où elle adore créer des choses intéressantes sur Amazon Bedrock. Elle est passionnée par la création de valeur commerciale à partir des applications d’apprentissage automatique, en mettant l’accent sur l’IA responsable. En plus de créer de nouvelles expériences d'IA pour ses clients, Bharathi aime écrire de la science-fiction et se mettre au défi avec les sports d'endurance.
 Achin Jain est un scientifique appliqué au sein de l'équipe Amazon Artificial General Intelligence (AGI). Il possède une expertise dans les modèles texte-image et se concentre sur la création du générateur d'images Amazon Titan.
Achin Jain est un scientifique appliqué au sein de l'équipe Amazon Artificial General Intelligence (AGI). Il possède une expertise dans les modèles texte-image et se concentre sur la création du générateur d'images Amazon Titan.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/fine-tune-your-amazon-titan-image-generator-g1-model-using-amazon-bedrock-model-customization/

