Image par auteur
L'analyse exploratoire des données (ou EDA) constitue une phase essentielle du processus d'analyse des données, mettant l'accent sur une enquête approfondie sur les détails et les caractéristiques internes d'un ensemble de données.
Son objectif principal est de découvrir des modèles sous-jacents, de saisir la structure de l'ensemble de données et d'identifier toute anomalie potentielle ou relation entre les variables.
En effectuant une EDA, les professionnels des données vérifient la qualité des données. Par conséquent, cela garantit que l’analyse ultérieure repose sur des informations précises et pertinentes, réduisant ainsi le risque d’erreurs dans les étapes ultérieures.
Essayons donc de comprendre ensemble quelles sont les étapes de base pour réaliser une bonne EDA pour notre prochain projet Data Science.
Je suis presque sûr que vous avez déjà entendu la phrase :
Déchets à l'entrée, déchets à la sortie
La qualité des données d’entrée est toujours le facteur le plus important pour la réussite de tout projet de données.
Malheureusement, la plupart des données sont au début sales. Grâce au processus d’analyse exploratoire des données, un ensemble de données presque utilisable peut être transformé en un ensemble entièrement utilisable.
Il est important de préciser qu’il ne s’agit pas d’une solution magique pour purifier un ensemble de données. Néanmoins, de nombreuses stratégies EDA sont efficaces pour résoudre plusieurs problèmes typiques rencontrés dans les ensembles de données.
Alors… apprenons les étapes les plus élémentaires selon Ayodele Oluleye dans son livre Exploratory Data Analysis with Python Cookbook.
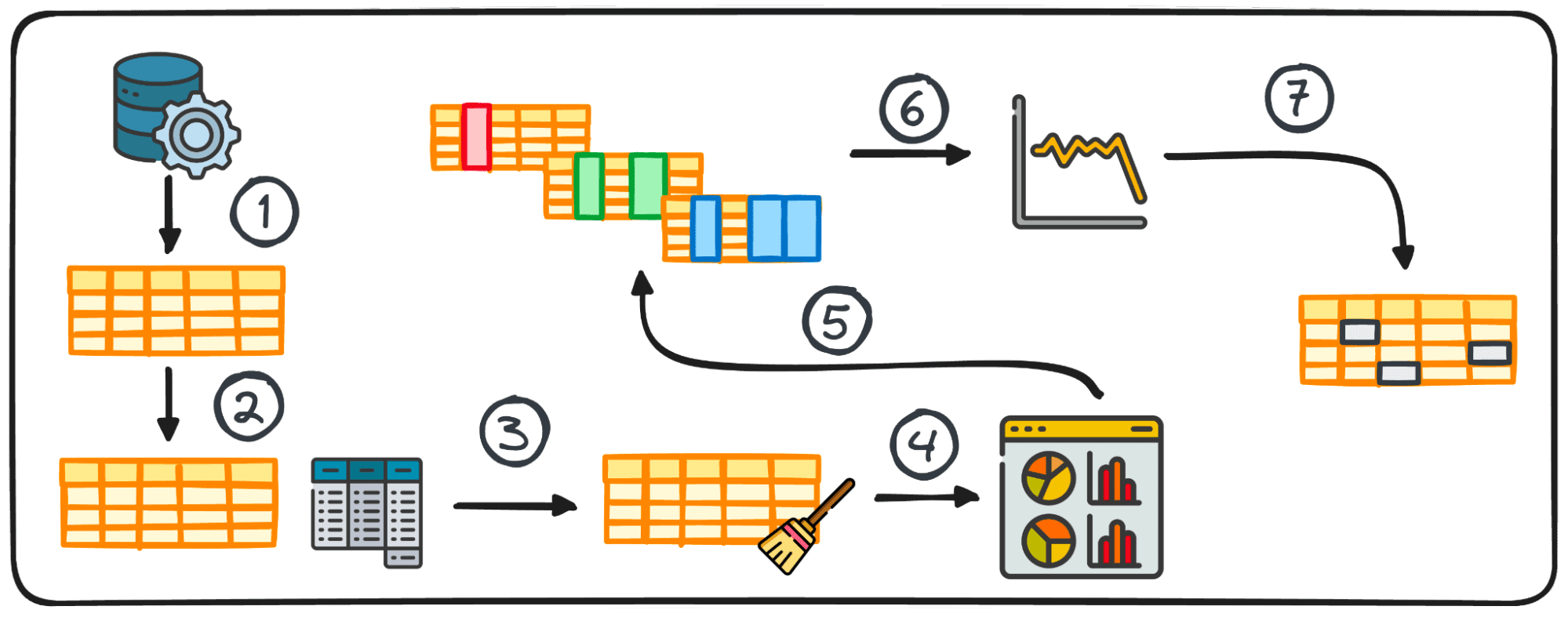
Étape 1: collecte de données
La première étape de tout projet de données consiste à disposer des données elles-mêmes. Cette première étape consiste à collecter des données à partir de diverses sources pour une analyse ultérieure.
2. Statistiques récapitulatives
Dans l'analyse des données, la gestion des données tabulaires est assez courante. Lors de l'analyse de ces données, il est souvent nécessaire d'obtenir des informations rapides sur les modèles et la distribution des données.
Ces premières informations servent de base à une exploration plus approfondie et à une analyse approfondie et sont connues sous le nom de statistiques récapitulatives.
Ils offrent un aperçu concis de la distribution et des modèles de l'ensemble de données, encapsulés par des mesures telles que la moyenne, la médiane, le mode, la variance, l'écart type, la plage, les centiles et les quartiles.
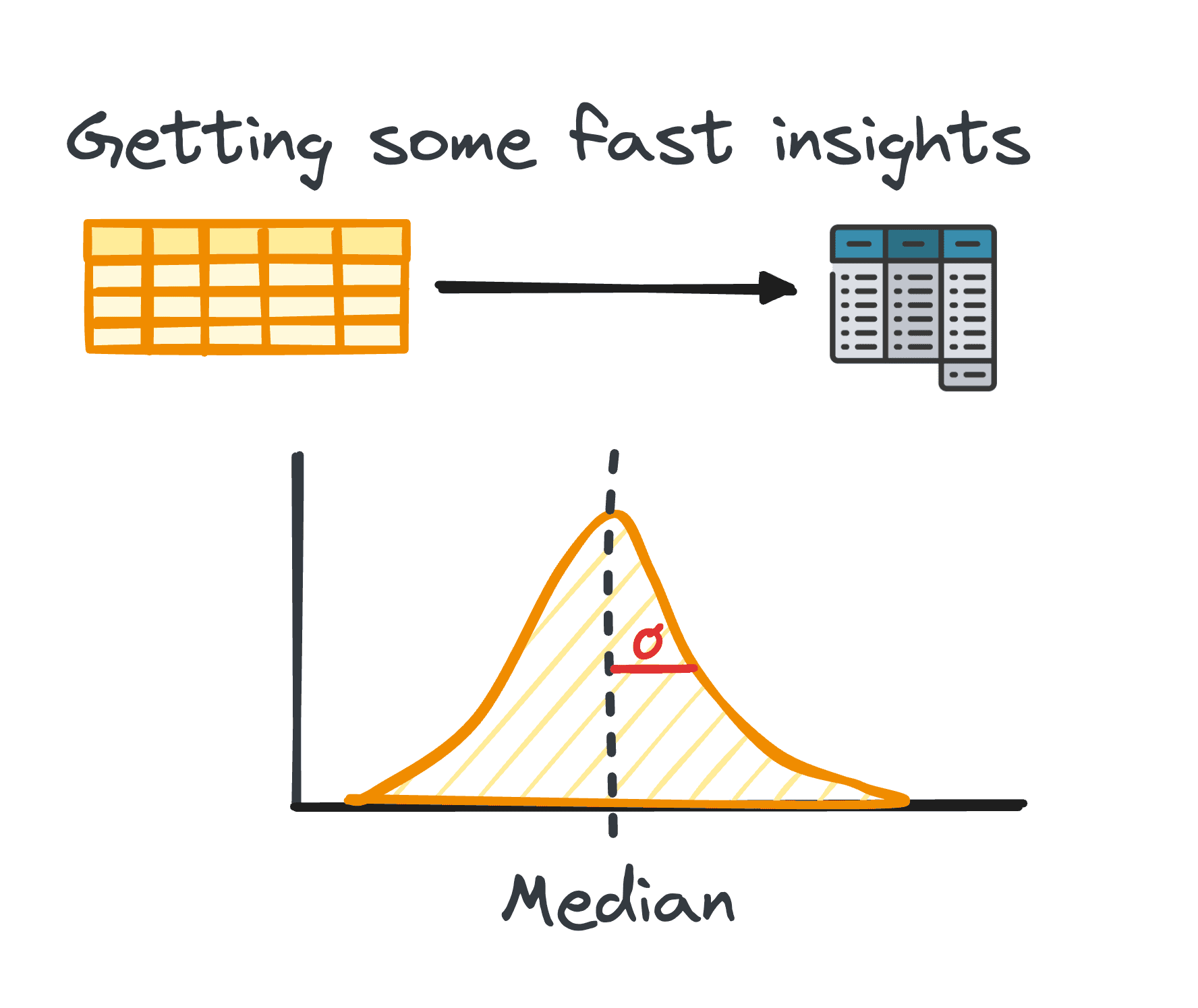
Image par auteur
3. Préparation des données pour l'EDA
Avant de commencer notre exploration, les données doivent généralement être préparées pour une analyse plus approfondie. La préparation des données implique la transformation, l'agrégation ou le nettoyage des données à l'aide de la bibliothèque pandas de Python pour répondre aux besoins de votre analyse.
Cette étape est adaptée à la structure des données et peut inclure le regroupement, l'ajout, la fusion, le tri, la catégorisation et le traitement des doublons.
En Python, l'accomplissement de cette tâche est facilité par la bibliothèque pandas à travers ses différents modules.
Le processus de préparation des données tabulaires n’adhère pas à une méthode universelle ; au lieu de cela, il est façonné par les caractéristiques spécifiques de nos données, notamment ses lignes, colonnes, types de données et les valeurs qu'elles contiennent.
4. Visualiser les données
La visualisation est un composant essentiel de l'EDA, rendant facilement compréhensibles les relations et les tendances complexes au sein de l'ensemble de données.
L'utilisation des bons graphiques peut nous aider à identifier les tendances au sein d'un grand ensemble de données et à trouver des modèles cachés ou des valeurs aberrantes. Python propose différentes bibliothèques pour la visualisation de données, notamment Matplotlib ou Seaborn, entre autres.
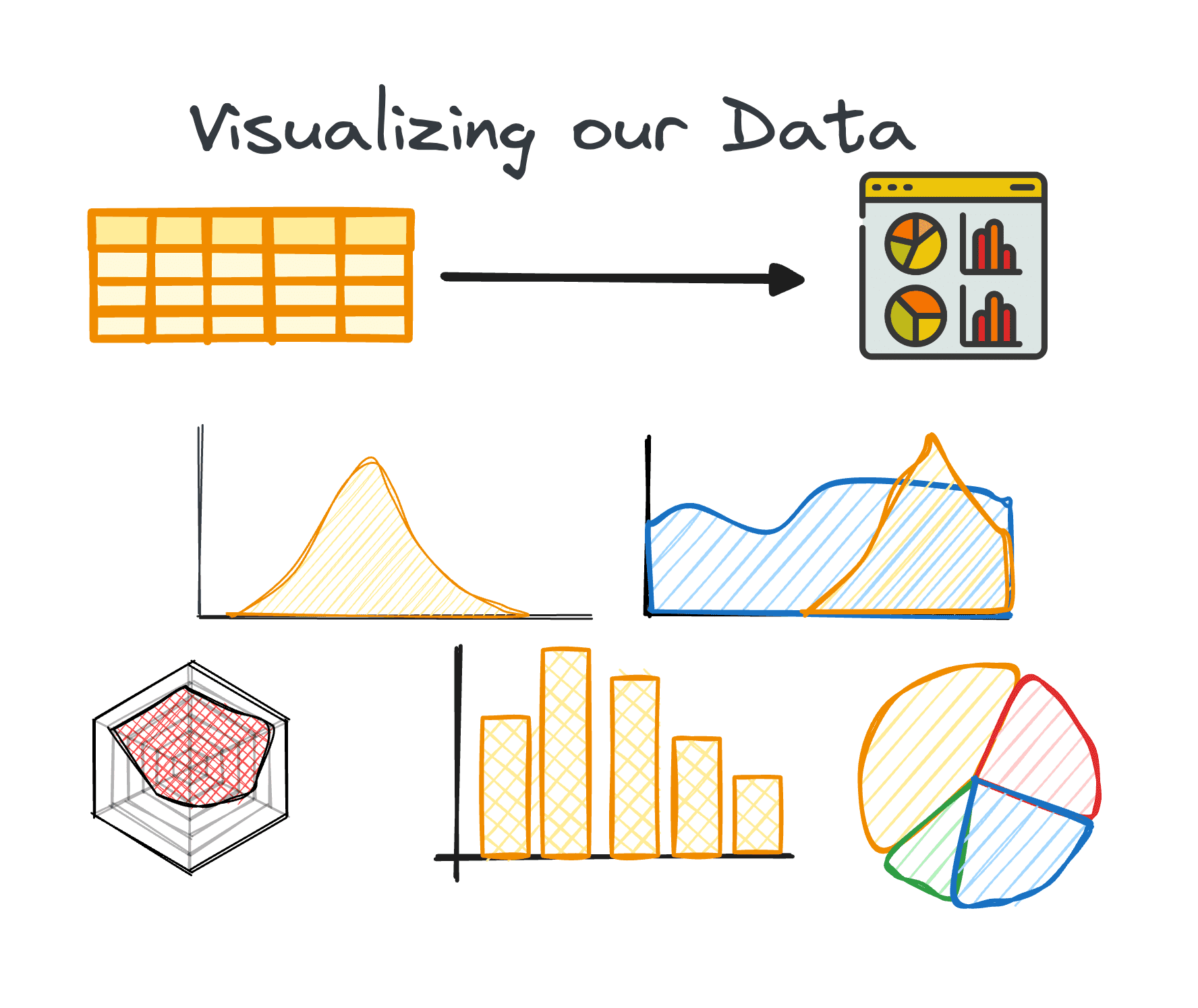
Image par auteur
5. Effectuer une analyse des variables :
L'analyse des variables peut être univariée, bivariée ou multivariée. Chacun d'eux fournit un aperçu de la distribution et des corrélations entre les variables de l'ensemble de données. Les techniques varient en fonction du nombre de variables analysées :
Univarié
L'objectif principal de l'analyse univariée est d'examiner chaque variable de notre ensemble de données individuellement. Au cours de cette analyse, nous pouvons découvrir des informations telles que la médiane, le mode, le maximum, la plage et les valeurs aberrantes.
Ce type d'analyse est applicable aux variables catégorielles et numériques.
Bivarié
L'analyse bivariée vise à révéler des informations entre deux variables choisies et se concentre sur la compréhension de la distribution et de la relation entre ces deux variables.
Comme nous analysons deux variables en même temps, ce type d’analyse peut s’avérer plus délicat. Il peut englober trois paires différentes de variables : numérique-numérique, numérique-catégorielle et catégorielle-catégorielle.
Multivarié
Un défi fréquent avec les grands ensembles de données est l’analyse simultanée de plusieurs variables. Même si les méthodes d’analyse univariée et bivariée offrent des informations précieuses, cela ne suffit généralement pas pour analyser des ensembles de données contenant plusieurs variables (généralement plus de cinq).
Cette question de la gestion des données de grande dimension, généralement appelée la malédiction de la dimensionnalité, est bien documentée. Avoir un grand nombre de variables peut être avantageux car cela permet d’extraire plus d’informations. Dans le même temps, cet avantage peut être contre nous en raison du nombre limité de techniques disponibles pour analyser ou visualiser plusieurs variables simultanément.
6. Analyse des données de séries chronologiques
Cette étape se concentre sur l’examen des points de données collectés à intervalles de temps réguliers. Les données de séries chronologiques s'appliquent aux données qui changent au fil du temps. Cela signifie essentiellement que notre ensemble de données est composé d'un groupe de points de données enregistrés à intervalles de temps réguliers.
Lorsque nous analysons des données de séries chronologiques, nous pouvons généralement découvrir des modèles ou des tendances qui se répètent dans le temps et présentent une saisonnalité temporelle. Les composants clés des données de séries chronologiques comprennent les tendances, les variations saisonnières, les variations cycliques et les variations irrégulières ou le bruit.
7. Gérer les valeurs aberrantes et manquantes
Les valeurs aberrantes et manquantes peuvent fausser les résultats de l’analyse si elles ne sont pas correctement traitées. C’est pourquoi nous devrions toujours envisager une seule phase pour y faire face.
L'identification, la suppression ou le remplacement de ces points de données sont essentiels pour maintenir l'intégrité de l'analyse de l'ensemble de données. Il est donc très important de les résoudre avant de commencer à analyser nos données.
- Les valeurs aberrantes sont des points de données qui présentent un écart significatif par rapport aux autres. Ils présentent généralement des valeurs inhabituellement élevées ou faibles.
- Les valeurs manquantes sont l'absence de points de données correspondant à une variable ou à une observation spécifique.
Une première étape cruciale pour traiter les valeurs manquantes et les valeurs aberrantes consiste à comprendre pourquoi elles sont présentes dans l’ensemble de données. Cette compréhension guide souvent le choix de la méthode la plus appropriée pour y remédier. Des facteurs supplémentaires à prendre en compte sont les caractéristiques des données et l’analyse spécifique qui sera effectuée.
EDA améliore non seulement la clarté de l'ensemble de données, mais permet également aux professionnels des données de naviguer dans la malédiction de la dimensionnalité en fournissant des stratégies de gestion des ensembles de données comportant de nombreuses variables.
Grâce à ces étapes méticuleuses, EDA avec Python fournit aux analystes les outils nécessaires pour extraire des informations significatives à partir des données, établissant ainsi une base solide pour tous les efforts d'analyse de données ultérieurs.
Joseph Ferrier est un ingénieur analytique de Barcelone. Il est diplômé en génie physique et travaille actuellement dans le domaine de la science des données appliquée à la mobilité humaine. Il est un créateur de contenu à temps partiel axé sur la science et la technologie des données. Vous pouvez le contacter sur LinkedIn, Twitter or Moyenne.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://www.kdnuggets.com/7-steps-to-mastering-exploratory-data-analysis?utm_source=rss&utm_medium=rss&utm_campaign=7-steps-to-mastering-exploratory-data-analysis

