Lors de l'exécution d'applications Apache Flink sur Service géré Amazon pour Apache Flink, vous avez l'avantage unique de profiter de sa nature sans serveur. Cela signifie que les exercices d’optimisation des coûts peuvent avoir lieu à tout moment : ils n’ont plus besoin d’avoir lieu lors de la phase de planification. Avec Managed Service pour Apache Flink, vous pouvez ajouter et supprimer des calculs en un seul clic.
Apache Flink est un framework de traitement de flux open source utilisé par des centaines d'entreprises dans des applications métiers critiques et par des milliers de développeurs ayant des besoins de traitement de flux pour leurs charges de travail. Il est hautement disponible et évolutif, offrant un débit élevé et une faible latence pour les applications de traitement de flux les plus exigeantes. Ces propriétés évolutives d'Apache Flink peuvent être essentielles pour optimiser vos coûts dans le cloud.
Le service géré pour Apache Flink est un service entièrement géré qui réduit la complexité de la création et de la gestion des applications Apache Flink. Le service géré pour Apache Flink gère l'infrastructure sous-jacente et les composants Apache Flink qui fournissent un état d'application durable, des métriques, des journaux, etc.
Dans cet article, vous pourrez en savoir plus sur le modèle de coût du service géré pour Apache Flink, les domaines permettant d'économiser sur les coûts dans vos applications Apache Flink et, dans l'ensemble, mieux comprendre vos pipelines de traitement de données. Nous approfondissons la compréhension de vos coûts, déterminons si votre application est surprovisionnée, comment penser à la mise à l'échelle automatique et comment optimiser vos applications Apache Flink pour économiser sur les coûts. Enfin, nous posons des questions importantes sur votre charge de travail afin de déterminer si Apache Flink est la bonne technologie pour votre cas d'utilisation.
Comment les coûts sont calculés sur le service géré pour Apache Flink
Pour optimiser les coûts de votre application de service géré pour Apache Flink, il peut être utile d'avoir une bonne idée de ce qui entre dans la tarification du service géré.
Le service géré pour les applications Apache Flink est composé d'unités de traitement Kinesis (KPU), qui sont des instances de calcul composées d'un processeur virtuel et de 1 Go de mémoire. Le nombre total de KPU attribués à l'application est déterminé en multipliant deux paramètres que vous contrôlez directement :
- Parallélisme – Le niveau de traitement parallèle dans l’application Apache Flink
- Parallélisme par KPU – Le nombre de ressources dédiées à chaque parallélisme
Le nombre de KPU est déterminé par la formule simple : KPU = Parallelism / ParallelismPerKPU, arrondi à l'entier supérieur.
Un KPU supplémentaire par application est également facturé pour l'orchestration et n'est pas directement utilisé pour le traitement des données.
Le nombre total de KPU détermine le nombre de ressources, de CPU, de mémoire et de stockage d'application alloués à l'application. Pour chaque KPU, l'application reçoit 1 vCPU et 4 Go de mémoire, dont 3 Go sont alloués par défaut à l'application en cours d'exécution et les 1 Go restants sont utilisés pour la gestion du magasin d'état de l'application. Chaque KPU est également livré avec 50 Go de stockage attaché à l'application. Apache Flink conserve l'état de l'application en mémoire dans une limite configurable et s'étend au stockage connecté.
Le troisième élément de coût concerne les sauvegardes d'applications durables, ou des instantanés. Ceci est entièrement facultatif et son impact sur le coût global est faible, à moins que vous ne conserviez un très grand nombre d’instantanés.
Au moment de la rédaction de cet article, chaque KPU dans la région AWS USA Est (Ohio) coûte 0.11 USD par heure, et le stockage des applications connectées coûte 0.10 USD par Go et par mois. Le coût d’une sauvegarde durable des applications (instantanés) est de 0.023 $ par Go et par mois. Faire référence à Tarification du service géré Amazon pour Apache Flink pour les prix à jour et les différentes régions.
Le diagramme suivant illustre les proportions relatives des éléments de coût pour une application en cours d'exécution sur Managed Service pour Apache Flink. Vous contrôlez le nombre de KPU via les paramètres de parallélisme et de parallélisme par KPU. Le stockage de sauvegarde d’application durable n’est pas représenté.
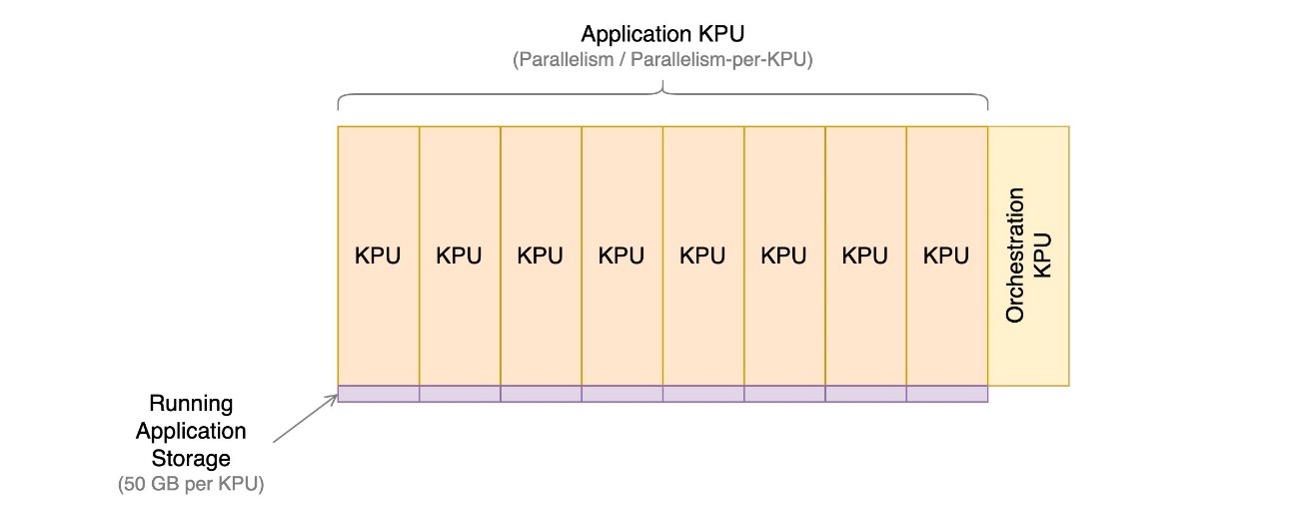
Dans les sections suivantes, nous examinons comment surveiller vos coûts, optimiser l'utilisation des ressources d'application et trouver le nombre requis de KPU pour gérer votre profil de débit.
AWS Cost Explorer et comprendre votre facture
Pour voir quelles sont vos dépenses actuelles en matière de service géré pour Apache Flink, vous pouvez utiliser Explorateur de coûts AWS.
Sur la console Cost Explorer, vous pouvez filtrer par plage de dates, type d'utilisation et service pour isoler vos dépenses pour les applications Managed Service pour Apache Flink. La capture d'écran suivante montre les coûts des 12 derniers mois répartis selon les catégories de prix décrites dans la section précédente. La majorité des dépenses au cours de bon nombre de ces mois provenaient de KPU interactifs de Service géré Amazon pour Apache Flink Studio.
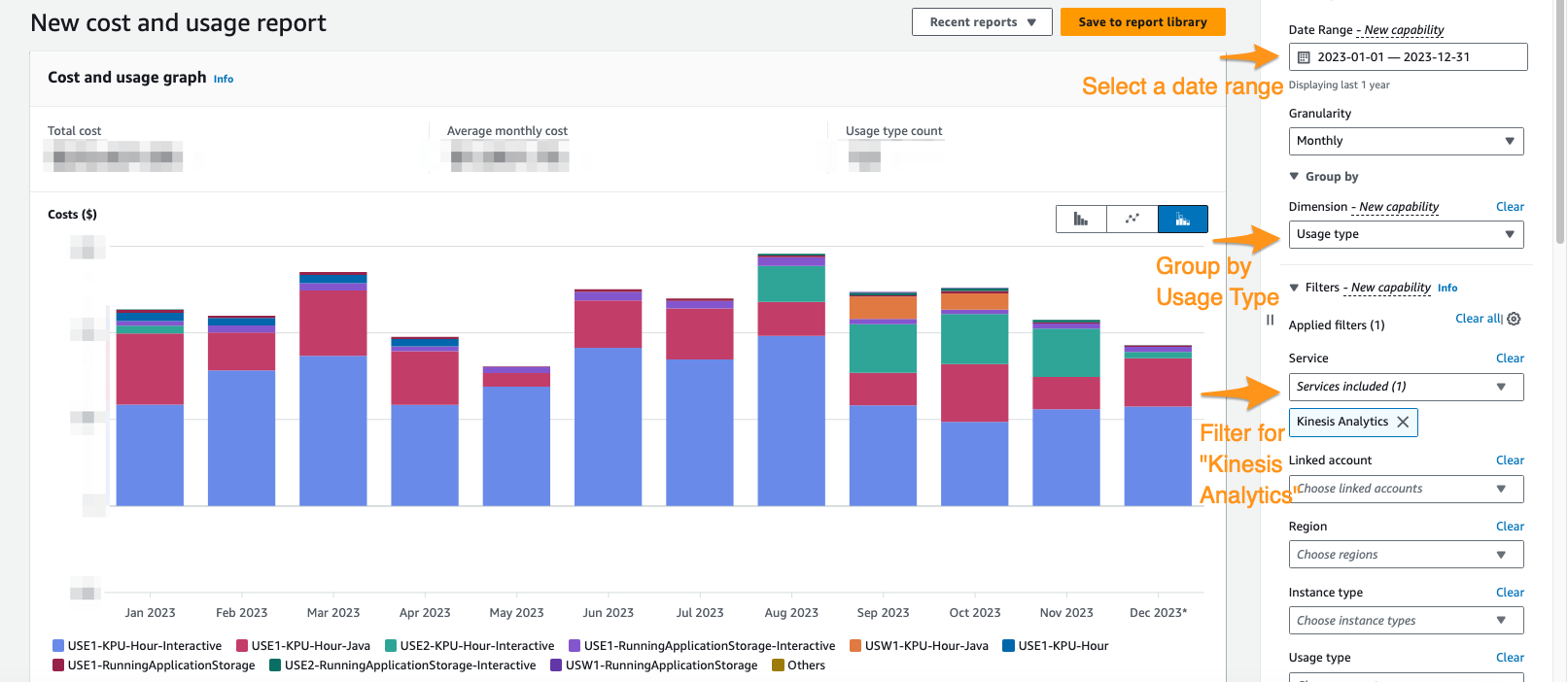
L'utilisation de Cost Explorer peut non seulement vous aider à comprendre votre facture, mais également à optimiser davantage des applications particulières qui peuvent avoir évolué au-delà des attentes automatiquement ou en raison des exigences de débit. Avec un balisage approprié des applications, vous pouvez également ventiler ces dépenses par application pour voir quelles applications représentent le coût.
Signes de surprovisionnement ou d’utilisation inefficace des ressources
Pour minimiser les coûts associés au service géré pour les applications Apache Flink, une approche simple consiste à réduire le nombre de KPU utilisés par vos applications. Cependant, il est crucial de reconnaître que cette réduction pourrait nuire aux performances si elle n'est pas soigneusement évaluée et testée. Pour évaluer rapidement si vos applications risquent d'être surprovisionnées, examinez les indicateurs clés tels que l'utilisation du processeur et de la mémoire, les fonctionnalités des applications et la distribution des données. Cependant, bien que ces indicateurs puissent suggérer un surprovisionnement potentiel, il est essentiel d'effectuer des tests de performances et de valider vos modèles de mise à l'échelle avant d'apporter des ajustements au nombre de KPU.
Métrique
L'analyse métriques pour votre application on Amazon Cloud Watch peut révéler des signaux clairs de surprovisionnement. Si la containerCPUUtilization ainsi que containerMemoryUtilization Si les métriques restent constamment inférieures à 20 % sur une période statistiquement significative pour les modèles de trafic de votre application, il peut être viable de réduire la taille et d'allouer plus de données à moins de machines. En règle générale, nous considérons les applications de taille appropriée lorsque containerCPUUtilization oscille entre 50 et 75 %. Bien que containerMemoryUtilization peut fluctuer tout au long de la journée et être influencée par l'optimisation du code, une valeur constamment faible pendant une durée substantielle pourrait indiquer un surprovisionnement potentiel.
Parallélisme par KPU sous-utilisé
Un autre signe subtil indiquant que votre application est surprovisionnée est si votre application est purement liée aux E/S ou si elle n'effectue que de simples appels vers des bases de données et des opérations non gourmandes en CPU. Si tel est le cas, vous pouvez utiliser le paramètre parallélisme par KPU dans Managed Service pour Apache Flink pour charger davantage de tâches sur une seule unité de traitement.
Vous pouvez afficher le parallélisme par paramètre KPU comme mesure de la densité de charge de travail par unité de ressources de calcul et de mémoire (le KPU). L'augmentation du parallélisme par KPU au-dessus de la valeur par défaut de 1 rend le traitement plus dense, allouant davantage de processus parallèles sur un seul KPU.
Le diagramme suivant illustre comment, en gardant le parallélisme de l'application constant (par exemple, 4) et en augmentant le parallélisme par KPU (par exemple, de 1 à 2), votre application utilise moins de ressources avec le même niveau d'exécutions parallèles.
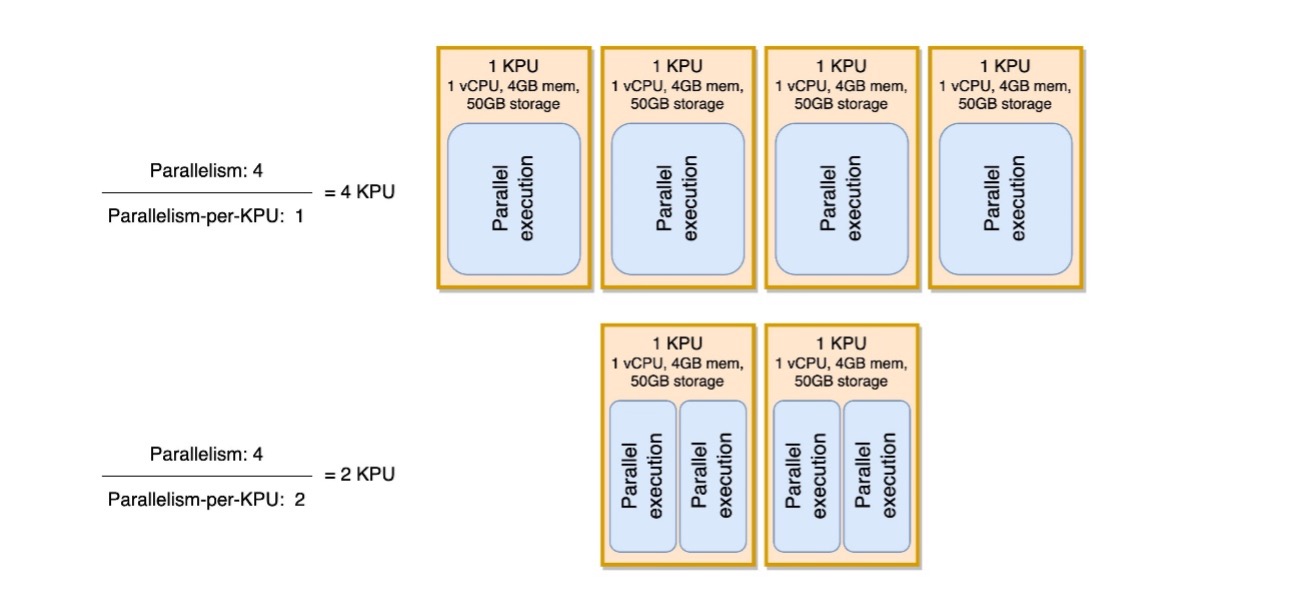
La décision d'augmenter le parallélisme par KPU, comme toutes les recommandations de cet article, doit être prise avec la plus grande prudence. L'augmentation du parallélisme par valeur de KPU peut imposer davantage de charge sur un seul KPU, et celui-ci doit être prêt à tolérer cette charge. Les opérations liées aux E/S n'augmenteront pas l'utilisation du processeur ou de la mémoire de manière significative, mais une fonction de processus qui calcule de nombreuses opérations complexes sur les données ne serait pas une opération idéale à rassembler sur un seul KPU, car elle pourrait surcharger les ressources. Testez les performances et évaluez s’il s’agit d’une bonne option pour vos applications.
Comment aborder le dimensionnement
Avant de mettre en place une application de service géré pour Apache Flink, il peut être difficile d'estimer le nombre de KPU que vous devez allouer à votre application. En général, vous devez avoir une bonne idée de vos modèles de trafic avant de faire une estimation. Comprendre vos modèles de trafic sur la base d'un taux d'ingestion en mégaoctets par seconde peut vous aider à vous rapprocher d'un point de départ.
En règle générale, vous pouvez commencer avec un KPU par 1 Mo/s que votre application traitera. Par exemple, si votre application traite 10 Mo/s (en moyenne), vous allouerez 10 KPU comme point de départ pour votre application. Gardez à l’esprit qu’il s’agit d’une approximation de très haut niveau que nous avons jugée efficace pour une estimation générale. Cependant, vous devez également tester les performances et évaluer s'il s'agit d'un dimensionnement approprié à long terme en fonction de métriques (CPU, mémoire, latence, performances globales du travail) sur une longue période.
Pour trouver le dimensionnement approprié pour votre application, vous devez augmenter et réduire l'application Apache Flink. Comme mentionné, dans Managed Service pour Apache Flink, vous disposez de deux contrôles distincts : le parallélisme et le parallélisme par KPU. Ensemble, ces paramètres déterminent le niveau de traitement parallèle au sein de l'application et les ressources globales de calcul, de mémoire et de stockage disponibles.
La méthodologie de test recommandée consiste à modifier le parallélisme ou le parallélisme par KPU séparément, tout en expérimentant pour trouver le bon dimensionnement. En général, modifiez uniquement le parallélisme par KPU pour augmenter le nombre d'opérations d'E/S parallèles, sans augmenter les ressources globales. Dans tous les autres cas, modifiez uniquement le parallélisme (le KPU changera en conséquence) pour trouver le dimensionnement adapté à votre charge de travail.
Vous pouvez aussi vous définir le parallélisme au niveau de l'opérateur pour restreindre les sources, les puits ou tout autre opérateur qui pourrait devoir être restreint et indépendant des mécanismes de mise à l'échelle. Vous pouvez l'utiliser pour une application Apache Flink qui lit à partir d'un sujet Apache Kafka comportant 10 partitions. Avec le setParallelism() , vous pouvez limiter KafkaSource à 10, mais faire évoluer l'application Managed Service pour Apache Flink vers un parallélisme supérieur à 10 sans créer de tâches inactives pour la source Kafka. Il est recommandé pour les autres cas de traitement de données de ne pas définir statiquement le parallélisme des opérateurs sur une valeur statique, mais plutôt sur une fonction du parallélisme de l'application afin qu'il évolue lorsque l'application globale évolue.
Mise à l'échelle et mise à l'échelle automatique
Dans Managed Service pour Apache Flink, la modification du parallélisme ou du parallélisme par KPU constitue une mise à jour de la configuration de l'application. Cela amène l'application à prendre automatiquement un instantané (sauf si désactivé), arrêtez l'application et redémarrez-la avec le nouveau dimensionnement, en restaurant l'état à partir de l'instantané. Les opérations de mise à l'échelle n'entraînent pas de perte de données ni d'incohérences, mais elles suspendent le traitement des données pendant une courte période pendant que l'infrastructure est ajoutée ou supprimée. C'est quelque chose que vous devez prendre en compte lors du redimensionnement dans un environnement de production.
Pendant le processus de test et d'optimisation, nous vous recommandons de désactiver mise à l'échelle automatique et modifier le parallélisme et le parallélisme par KPU pour trouver les valeurs optimales. Comme mentionné, la mise à l'échelle manuelle n'est qu'une mise à jour de la configuration de l'application et peut être exécutée via le Console de gestion AWS ou API avec le Action Mettre à jour l'application.
Une fois que vous avez trouvé le dimensionnement optimal, si vous prévoyez que votre débit ingéré varie considérablement, vous pouvez décider d'activer la mise à l'échelle automatique.
Dans Managed Service pour Apache Flink, vous pouvez utiliser plusieurs types de mise à l'échelle automatique :
- Mise à l'échelle automatique prête à l'emploi – Vous pouvez activer cette option pour ajuster automatiquement le parallélisme de l'application en fonction du
containerCPUUtilizationmétrique. La mise à l'échelle automatique est activée par défaut sur les nouvelles applications. Pour plus de détails sur l'algorithme de mise à l'échelle automatique, reportez-vous à Mise à l'échelle automatique. - Mise à l'échelle automatique à granularité fine et basée sur des métriques – C’est simple à mettre en œuvre. L'automatisation peut être basée sur pratiquement toutes les mesures, y compris métriques personnalisées votre application expose.
- Mise à l'échelle planifiée – Cela peut être utile si vous prévoyez des pics de charge de travail à des moments donnés de la journée ou des jours de la semaine.
La mise à l’échelle automatique prête à l’emploi et la mise à l’échelle fine basée sur des métriques s’excluent mutuellement. Pour plus de détails sur la mise à l'échelle automatique basée sur des métriques fines et la mise à l'échelle planifiée, ainsi qu'un exemple de code entièrement fonctionnel, reportez-vous à Activer la mise à l'échelle planifiée et basée sur des métriques pour Amazon Managed Service pour Apache Flink.
Optimisations de code
Une autre façon de réaliser des économies pour vos applications de service géré pour Apache Flink consiste à optimiser le code. Un code non optimisé nécessitera davantage de machines pour effectuer les mêmes calculs. L'optimisation du code pourrait permettre de réduire l'utilisation globale des ressources, ce qui pourrait à son tour permettre une réduction et des économies de coûts en conséquence.
La première étape pour comprendre les performances de votre code consiste à utiliser l'utilitaire intégré d'Apache Flink appelé Graphiques de flamme.
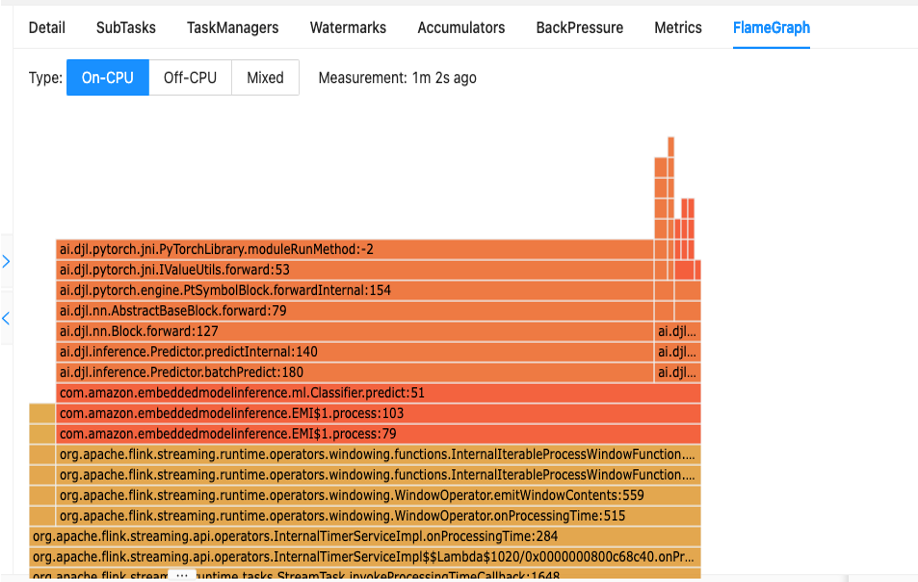
Les Flame Graphs, accessibles via le tableau de bord Apache Flink, vous donnent une représentation visuelle de votre trace de pile. Chaque fois qu'une méthode est appelée, la barre qui représente cet appel de méthode dans la trace de la pile s'agrandit proportionnellement au nombre total d'échantillons. Cela signifie que si vous avez un morceau de code inefficace avec une très longue barre dans le graphique de flamme, cela pourrait donner lieu à une enquête sur la façon de rendre ce code plus efficace. De plus, vous pouvez utiliser Profileur Amazon CodeGuru à surveillez et optimisez vos applications Apache Flink exécutées sur Managed Service pour Apache Flink.
Lors de la conception de vos applications, il est recommandé d'utiliser l'API de plus haut niveau requise pour une opération particulière à un moment donné. Apache Flink propose quatre niveaux de support API : Flink SQL, Table API, Datastream API, et ProcessFunction Les API, avec des niveaux croissants de complexité et de responsabilité. Si votre application peut être entièrement écrite dans l'API Flink SQL ou Table, son utilisation peut vous aider à tirer parti du framework Apache Flink plutôt que de gérer manuellement l'état et les calculs.
Biais de données
Sur le tableau de bord Apache Flink, vous pouvez rassembler d'autres informations utiles sur vos tâches de service géré pour Apache Flink.
Sur le tableau de bord, vous pouvez inspecter les tâches individuelles dans le graphique de votre candidature à un emploi. Chaque case bleue représente une tâche et chaque tâche est composée de sous-tâches ou d'unités de travail distribuées pour cette tâche. Vous pouvez ainsi identifier les biais de données entre les sous-tâches.
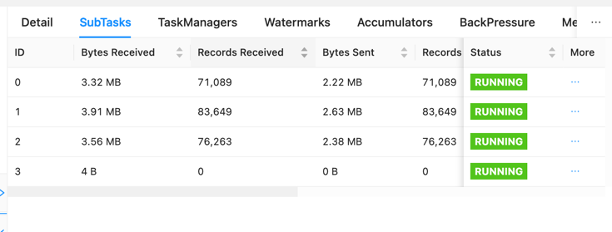
L'asymétrie des données est un indicateur que plus de données sont envoyées à une sous-tâche qu'à une autre et qu'une sous-tâche recevant plus de données effectue plus de travail que l'autre. Si vous présentez de tels symptômes de distorsion des données, vous pouvez travailler pour les éliminer en identifiant la source. Par exemple, un GroupBy or KeyedStream il pourrait y avoir un biais dans la clé. Cela signifierait que les données ne sont pas réparties uniformément entre les clés, ce qui entraînerait une répartition inégale du travail entre les instances de calcul Apache Flink. Imaginez un scénario dans lequel vous regroupez par userId, mais votre application reçoit beaucoup plus de données d'un utilisateur que des autres. Cela peut entraîner un biais dans les données. Pour éliminer cela, vous pouvez choisir une clé de regroupement différente pour répartir uniformément les données entre les sous-tâches. Gardez à l’esprit que cela nécessitera une modification du code pour choisir une clé différente.
Lorsque le biais de données est éliminé, vous pouvez revenir au containerCPUUtilization ainsi que containerMemoryUtilization métriques pour réduire le nombre de KPU.
D'autres domaines d'optimisation du code incluent la garantie que vous accédez aux systèmes externes via le API d'E/S asynchrones ou via une jointure de flux de données, car une requête synchrone vers un magasin de données peut créer des ralentissements et des problèmes de point de contrôle. De plus, reportez-vous à Performances de dépannage pour les problèmes que vous pourriez rencontrer avec des points de contrôle ou une journalisation lents, ce qui peut entraîner une contre-pression des applications.
Comment déterminer si Apache Flink est la bonne technologie
Si votre application n'utilise aucune des puissantes fonctionnalités du framework Apache Flink et du service géré pour Apache Flink, vous pourriez potentiellement économiser sur les coûts en utilisant quelque chose de plus simple.
Le slogan d'Apache Flink est « Calculs avec état sur des flux de données ». Avec état, dans ce contexte, signifie que vous utilisez la construction d'état Apache Flink. State, dans Apache Flink, vous permet de mémoriser les messages que vous avez vus dans le passé pendant des périodes plus longues, ce qui rend possibles des éléments tels que les jointures en streaming, la déduplication, le traitement unique, le fenêtrage et la gestion tardive des données. Pour ce faire, il utilise un magasin d'état en mémoire. Sur le service géré pour Apache Flink, il utilise RocksDB pour maintenir son état.
Si votre application n'implique pas d'opérations avec état, vous pouvez envisager des alternatives telles que AWS Lambda, des applications conteneurisées ou un Cloud de calcul élastique Amazon (Amazon EC2) exécutant votre application. La complexité d'Apache Flink peut ne pas être nécessaire dans de tels cas. Les calculs avec état, y compris les données mises en cache ou les procédures d'enrichissement nécessitant une mémoire de position de flux indépendante, peuvent garantir les capacités avec état d'Apache Flink. S'il est possible que votre application devienne avec état à l'avenir, que ce soit en raison d'une conservation prolongée des données ou d'autres exigences avec état, continuer à utiliser Apache Flink pourrait être plus simple. Les organisations qui mettent l'accent sur Apache Flink pour les capacités de traitement de flux préféreront peut-être s'en tenir à Apache Flink pour les applications avec et sans état afin que toutes leurs applications traitent les données de la même manière. Vous devez également prendre en compte ses fonctionnalités d'orchestration telles que le traitement unique, les capacités de répartition et le calcul distribué avant de passer d'Apache Flink à des alternatives.
Une autre considération concerne vos exigences en matière de latence. Étant donné qu'Apache Flink excelle dans le traitement des données en temps réel, son utilisation pour une application nécessitant une latence de 6 heures ou 1 jour n'a pas de sens. Les économies de coûts réalisées en passant à un processus par lots temporel hors de Service de stockage simple Amazon (Amazon S3), par exemple, serait significatif.
Conclusion
Dans cet article, nous avons abordé certains aspects à prendre en compte lors de la tentative de mesures de réduction des coûts pour le service géré pour Apache Flink. Nous avons expliqué comment identifier vos dépenses globales pour le service géré, quelques mesures utiles à surveiller lors de la réduction de vos KPU, comment optimiser votre code pour la réduction et comment déterminer si Apache Flink convient à votre cas d'utilisation.
La mise en œuvre de ces stratégies de réduction des coûts améliore non seulement votre rentabilité, mais permet également un déploiement Apache Flink rationalisé et bien optimisé. En restant attentif à vos dépenses globales, en utilisant des indicateurs clés et en prenant des décisions éclairées concernant la réduction des ressources, vous pouvez réaliser une opération rentable sans compromettre les performances. Au fur et à mesure que vous parcourez le paysage d'Apache Flink, il devient essentiel d'évaluer constamment si cela correspond à votre cas d'utilisation spécifique, afin que vous puissiez obtenir une solution adaptée et efficace pour vos besoins de traitement de données.
Si l’une des recommandations évoquées dans cet article correspond à votre charge de travail, nous vous encourageons à les essayer. Avec les métriques spécifiées et les conseils pour mieux comprendre vos charges de travail, vous devriez maintenant disposer de ce dont vous avez besoin pour optimiser efficacement vos charges de travail Apache Flink sur Managed Service pour Apache Flink. Voici quelques ressources utiles que vous pouvez utiliser pour compléter cet article :
À propos des auteurs
 Jérémy Ber travaille dans le domaine des données de télémétrie depuis 10 ans en tant qu'ingénieur logiciel, ingénieur en apprentissage automatique et, plus récemment, ingénieur de données. Chez AWS, il est architecte de solutions spécialisé dans le streaming, prenant en charge à la fois Amazon Managed Streaming pour Apache Kafka (Amazon MSK) et Amazon Managed Service pour Apache Flink.
Jérémy Ber travaille dans le domaine des données de télémétrie depuis 10 ans en tant qu'ingénieur logiciel, ingénieur en apprentissage automatique et, plus récemment, ingénieur de données. Chez AWS, il est architecte de solutions spécialisé dans le streaming, prenant en charge à la fois Amazon Managed Streaming pour Apache Kafka (Amazon MSK) et Amazon Managed Service pour Apache Flink.
 Lorenzo Nicora travaille en tant qu'architecte principal de solutions de streaming chez AWS, aidant les clients de la région EMEA. Il construit des systèmes cloud natifs à forte intensité de données depuis plus de 25 ans, travaillant dans le secteur financier à la fois par le biais de cabinets de conseil et pour des sociétés de produits FinTech. Il a largement exploité les technologies open source et a contribué à plusieurs projets, dont Apache Flink.
Lorenzo Nicora travaille en tant qu'architecte principal de solutions de streaming chez AWS, aidant les clients de la région EMEA. Il construit des systèmes cloud natifs à forte intensité de données depuis plus de 25 ans, travaillant dans le secteur financier à la fois par le biais de cabinets de conseil et pour des sociétés de produits FinTech. Il a largement exploité les technologies open source et a contribué à plusieurs projets, dont Apache Flink.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/real-time-cost-savings-for-amazon-managed-service-for-apache-flink/

