In October 2022, I published an article on LLM selection for specific NLP use cases , such as conversation, translation and summarisation. Since then, AI has made a huge step forward, and in this article, we will review some of the trends of the past months as well as their implications for AI builders. Specifically, we will cover the topics of task selection for autoregressive models, the evolving trade-offs between commercial and open-source LLMs, as well as LLM integration and the mitigation of failures in production.
1. Generative AI pushes autoregressive models, while autoencoding models are waiting for their moment.
For many AI companies, it seems like ChatGPT has turned into the ultimative competitor. When pitching my analytics startups in earlier days, I would frequently be challenged: “what will you do if Google (Facebook, Alibaba, Yandex…) comes around the corner and does the same?” Now, the question du jour is: “why can’t you use ChatGPT to do this?”
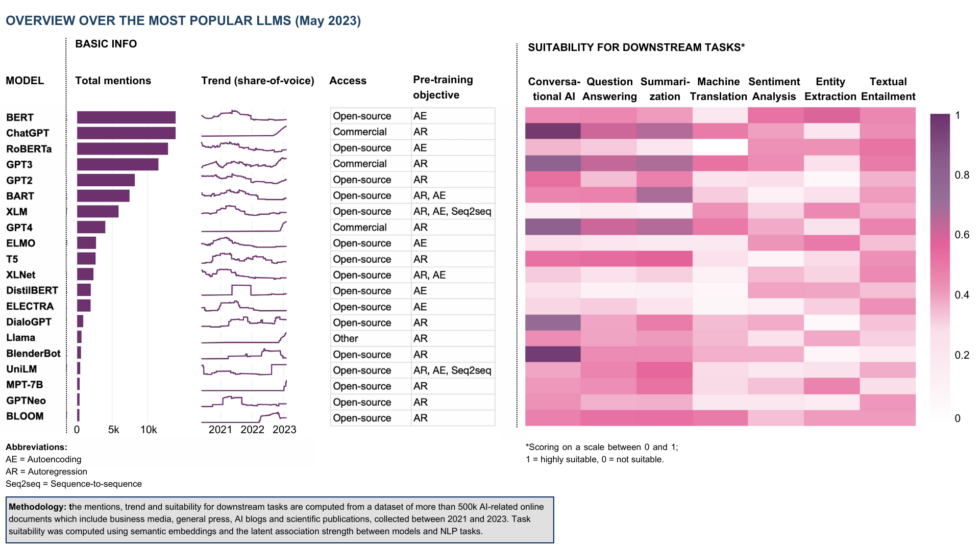
The short answer is: ChatGPT is great for many things, but it does by far not cover the full spectrum of AI. The current hype happens explicitly around generative AI — not analytical AI, or its rather fresh branch of synthetic AI [1]. What does this mean for LLMs? As described in my previous article, LLMs can be pre-trained with three objectives — autoregression, autoencoding and sequence-to-sequence (cf. also Table 1, column “Pre-training objective”). Typically, a model is pre-trained with one of these objectives, but there are exceptions — for example, UniLM [2] was pre-trained on all three objectives. The fun generative tasks that have popularised AI in the past months are conversation, question answering and content generation — those tasks where the model indeed learns to “generate” the next token, sentence etc. These are best carried out by autoregressive models, which include the GPT family as well as most of the recent open-source models, like MPT-7B, OPT and Pythia. Autoencoding models, which are better suited for information extraction, distillation and other analytical tasks, are resting in the background — but let’s not forget that the initial LLM breakthrough in 2018 happened with BERT, an autoencoding model. While this might feel like stone age for modern AI, autoencoding models are especially relevant for many B2B use cases where the focus is on distilling concise insights that address specific business tasks. We might indeed witness another wave around autoencoding and a new generation of LLMs that excel at extracting and synthesizing information for analytical purposes.
For builders, this means that popular autoregressive models can be used for everything that is content generation — and the longer the content, the better. However, for analytical tasks, you should carefully evaluate whether the autoregressive LLM you use will output a satisfying result, and consider to autoencoding models or even more traditional NLP methods otherwise.
2. Open-source competes with for-profits, spurring innovation in LLM efficiency and scaling.
In the past months, there has been a lot of debate about the uneasy relationship between open-source and commercial AI. In the short term, the open-source community cannot keep up in a race where winning entails a huge spend on data and/or compute. But with a long-term perspective in mind, even the big companies like Google and OpenAI feel threatened by open-source.[3] Spurred by this tension, both camps have continued building, and the resulting advances are eventually converging into fruitful synergies. The open-source community has a strong focus on frugality, i. e. increasing the efficiency of LLMs by doing more with less. This not only makes LLMs affordable to a broader user base — think AI democratisation — but also more sustainable from an environmental perspective. There are three principal dimensions along which LLMs can become more efficient:
- Less compute and memory: for example, FlashAttention [4] allows to reduce number of reads and writes on GPU as compared to standard attention algorithms, thus leading to faster and memory-efficient fine-tuning.
- Less parameters: in standard fine-tuning, all model weights are retrained — however, in most cases only a small subset of weights affect the performance of a model on the fine-tuning data. Parameter-efficient fine-tuning (PEFT) identifies this subset and “freezes” the other weights, which allows to heavily reduce resource usage while achieving a more stable performance of the model.
- Less training data: data quality scales better than data size [3] — the more focussed and curated your training data, the less of it is needed to optimise performance. One of the most successful approaches here is instruction fine-tuning. During training, the LLM is provided with task-specific instructions which reflect how it will eventually be prompted during inference. Narrowing down the training space enables faster learning from less data. Instruction fine-tuning has been practiced for a while already, for instance in T0, FLAN, InstructGPT — and ultimately, it is also the method that underlies ChatGPT.
On the other extreme, for now, “generative AI control is in the hands of the few that can afford the dollars to train and deploy models at scale”.[5] The commercial offerings are exploding in size — be it model size, data size or the time spent on training — and clearly outcompete open-source models in terms of output quality. There is not much to report here technically — rather, the concerns are more on the side of governance and regulation. Thus, “one key risk is that powerful LLMs like GPT develop only in a direction that suits the commercial objectives of these companies.”[5]
How will these two ends meet — and will they meet at all? On the one hand, any tricks that allow to reduce resource consumption can eventually be scaled up again by throwing more resources at them. On the other hand, LLM training follows the power law, which means that the learning curve flattens out as model size, dataset size and training time increase.[6] You can think of this in terms of the human education analogy — over the lifetime of humanity, schooling times have increased, but did the intelligence and erudition of the average person follow suit?
The positive thing about a flattening learning curve is the relief it brings amidst fears about AI growing “stronger and smarter” than humans. But brace yourself — the LLM world is full of surprises, and one of the most unpredictable ones is emergence.[7] Emergence is when quantitative changes in a system result in qualitative changes in behaviour — summarised with “quantity leads to quality”, or simply “more is different”.[8] At some point in their training, LLMs seem to acquire new, unexpected capabilities that were not in the original training scope. At present, these capabilities come in the form of new linguistic skills — for instance, instead of just generating text, models suddenly learn to summarise or translate. It is impossible to predict when this might happen and what the nature and scope of the new capabilities will be. Hence, the phenomenon of emergence, while fascinating for researchers and futurists, is still far away from providing robust value in a commercial context.
As more and more methods are developed that increase the efficiency of LLM finetuning and inference, the resource bottleneck around the physical operation of open-source LLMs seems to be loosening. Concerned with the high usage cost and restricted quota of commercial LLMs, more and more companies consider deploying their own LLMs. However, development and maintenance costs remain, and most of the described optimisations also require extended technical skills for manipulating both the models and the hardware on which they are deployed. The choice between open-source and commercial LLMs is a strategic one and should be done after a careful exploration of a range of trade-offs that include costs (incl. development, operating and usage costs), availability, flexibility and performance. A common line of advice is to get a head start with the big commercial LLMs to quickly validate the business value of your end product, and “switch” to open-source later down the road. But this transition can be tough and even unrealistic, since LLMs widely differ in the tasks they are good at. There is a risk that open-source models cannot satisfy the requirements of your already developed application, or that you need to do considerable modifications to mitigate the associated trade-offs. Finally, the most advanced setup for companies that build a variety of features on LLMs is a multi-LLM architecture that allows to leverage the advantages of different LLMs.
3. LLMs are getting operational with plugins, agents and frameworks.
The big challenges of LLM training being roughly solved, another branch of work has focussed on the integration of LLMs into real-world products. Beyond providing ready-made components that enhance convenience for developers, these innovations also help overcome the existing limitations of LLMs and enrich them with additional capabilities such as reasoning and the use of non-linguistic data.[9] The basic idea is that, while LLMs are already great at mimicking human linguistic capacity, they still have to be placed into the context of a broader computational “cognition” to conduct more complex reasoning and execution. This cognition encompasses a number of different capacities such as reasoning, action and observation of the environment. Basis: At the moment, it is approximated using plugins and agents, which can be combined using modular LLM frameworks such as LangChain, LlamaIndex and AutoGPT.
3.1 Plugins offer access to external data and functionality
Pre-trained LLMs have significant practical limitations when it comes to the data they leverage: on the one hand, the data quickly gets outdated — for instance, while GPT-4 was published in 2023, its data was cut off in 2021. On the other hand, most real-world applications require some customisation of the knowledge in the LLM. Consider building an app that allows you to create personalised marketing content — the more information you can feed into the LLM about your product and specific users, the better the result. Plugins make this possible — your program can fetch data from an external source, like customer e-mails and call records, and insert these into the prompt for a personalised, controlled output.
3.2 Agents walk the talk
Language is closely tied with actionability. Our communicative intents often circle around action, for example when we ask someone to do something or when we refuse to act in a certain way. The same goes for computer programs, which can be seen as collections of functions that execute specific actions, block them when certain conditions are not met etc. LLM-based agents bring these two worlds together. The instructions for these agents are not hard-coded in a programming language, but are freely generated by LLMs in the form of reasoning chains that lead to achieving a given goal. Each agent has a set of plugins at hand and can juggle them around as required by the reasoning chain — for example, he can combine a search engine for retrieving specific information and a calculator to subsequently execute computations on this information. The idea of agents has existed for a long time in reinforcement learning — however, as of today, reinforcement learning still happens in relatively closed and safe environments. Backed by the vast common knowledge of LLMs, agents can now not only venture into the “big world”, but also tap into an endless combinatorial potential: each agent can execute a multitude of tasks to reach their goals, and multiple agents can interact and collaborate with each other.[10] Moreover, agents learn from their interactions with the world and build up a memory that comes much closer to the multi-modal memory of humans than does the purely linguistic memory of LLMs.
3.3 Frameworks provide a handy interface for LLM integration
In the last months, we have seen a range of new LLM-based frameworks such as LangChain, AutoGPT and LlamaIndex. These frameworks allow to integrate plugins and agents into complex chains of generations and actions to implement complex processes that include multi-step reasoning and execution. Developers can now focus on efficient prompt engineering and quick app prototyping.[11] At the moment, a lot of hard-coding is still going on when you use these frameworks — but gradually, they might be evolving towards a more comprehensive and flexible system for modelling cognition and action, such as the JEPA architecture proposed by Yann LeCun.[12]
What are the implications of these new components and frameworks for builders? On the one hand, they boost the potential of LLMs by enhancing them with external data and agency. Frameworks, in combination with convenient commercial LLMs, have turned app prototyping into a matter of days. But the rise of LLM frameworks also has implications for the LLM layer. It is now hidden behind an additional abstraction, and as any abstraction it requires higher awareness and discipline to be leveraged in a sustainable way. First, when developing for production, a structured process is still required to evaluate and select specific LLMs for the tasks at hand. At the moment, many companies skip this process under the assumption that the latest models provided by OpenAI are the most appropriate. Second, LLM selection should be coordinated with the desired agent behaviour: the more complex and flexible the desired behaviour, the better the LLM should perform to ensure that it picks the right actions in a wide space of options.[13] Finally, in operation, an MLOps pipeline should ensure that the model doesn’t drift away from changing data distributions and user preferences.
4. The linguistic interface of LLMs comes introduces new challenges for human-machine interaction.
With the advance of prompting, using AI to do cool and creative things is getting accessible for non-technical people. No need to be a programmer anymore — just use language, our natural communication medium, to tell the machine what to do. However, amidst all the buzz and excitement around quick prototyping and experimentation with LLMs, at some point we still come to realise that “it’s easy to make something cool with LLMs, but very hard to make something production-ready with them.”[14] In production, LLMs hallucinate, are sensitive to imperfect prompt designs and raise a number of issues for governance, safety and alignment with desired outcomes. And the thing we love most about LLMs — its open-ended space of in- and outputs — also makes it all the harder to test for potential failures before deploying them to production.
4.1 Hallucinations and silent failures
If you have ever built an AI product, you will know that end users are often highly sensitive to AI failures. Users are prone to a “negativity bias”: even if your system achieves a high overall accuracy, those occasional but unavoidable error cases will be scrutinised with a magnifying glass. With LLMs, the situation is different. Just as any other complex AI system, LLMs do fail — but they do so in the silent way. Even if they don’t have a good response at hand, they will still generate something and present it in a highly confident way, tricking us into believing and accepting them and putting us in embarrassing situations further down the stream. Imagine a multi-step agent whose instructions are generated by an LLM — an error in the first generation will cascade to all subsequent tasks and corrupt the whole action sequence of the agent.
One of the biggest quality issues of LLMs is hallucination, which refers to the generation of texts that are semantically or syntactically plausible but are factually incorrect. Already Noam Chomsky, with his famous sentence “Colorless green ideas sleep furiously”, made the point that a sentence can be perfectly well-formed from the linguistic point of view, but completely nonsensical for humans. Not so for LLMs, which lack the non-linguistic knowledge that humans possess and thus cannot ground language in the reality of the underlying world. And while we can immediately spot the issue in Chomsky’s sentence, fact checking of LLM outputs becomes quite cumbersome once we get into more specialised domains that are outside of our field of expertise. The risk of undetected hallucinations is especially high for long-form content as well as for interactions for which no ground truth exists, such as forecasts and open-ended scientific or philosophical questions.[15]
There are multiple approaches to hallucination. From a statistical viewpoint, we can expect that as language models learn more, hallucination decreases. But in a business context, the incrementality and uncertain timeline of this “solution” make it rather unreliable. Another approach is rooted in neuro-symbolic AI. By combining the powers of statistical language generation and deterministic world knowledge, we may be able to reduce hallucinations and silent failures and finally make LLMs robust for large-scale production. For instance, ChatGPT makes this promise with the integration of Wolfram Alpha, a vast structured database of curated world knowledge.
4.2 The challenges of prompting
On the surface, the natural language interface offered by prompting seems to close the gap between AI experts and laypeople — after all, all of us know at least one language and use it for communication, so why not do the same with an LLM? But prompting is a fine craft. Successful prompting that goes beyond trivia not only requires strong linguistic intuitions, but also knowledge about how LLMs learn and work. And then, the process of designing successful prompts is highly iterative and requires systematic experimentation. As shown in the paper Why Johnny can’t prompt, humans struggle to maintain this rigour. On the one hand, we often are primed by expectations that are rooted in our experience of human interaction. Talking to humans is different from talking to LLMs — when we interact with each other, our inputs are transmitted in a rich situational context, which allows to neutralise the imprecisions and ambiguities of human language. An LLM only gets the linguistic information and thus is much less forgiving. On the other hand, it is difficult to adopt a systematic approach to prompt engineering, so we quickly end up with opportunistic trial-and-error, making it hard to construct a scalable and consistent system of prompts.
To resolve these challenges, it is necessary to educate both prompt engineers and users about the learning process and the failure modes of LLMs, and to maintain an awareness of possible mistakes in the interface. It should be clear that an LLM output is always an uncertain thing. For instance, this can be achieved using confidence scores in the user interface which can be derived via model calibration.[15] For prompt engineering, we currently see the rise of LLMOps, a subcategory of MLOps which allows to manage the prompt lifecycle with prompt templating, versioning, optimisation etc. Finally, finetuning trumps few-shot learning in terms of consistency since it removes the variable “human factor” of ad-hoc prompting and enriches the inherent knowledge of the LLM. Whenever possible given your setup, you should consider switching from prompting to finetuning once you have accumulated enough training data.
Conclusion
With new models, performance hacks and integrations coming up every day, the LLM rabbit hole is deepening day by day. For companies, it is important to stay differentiated, keep an eye on the recent developments and new risks and favour hands-on experimentation over the buzz — many trade-offs and issues related to LLMs only become visible during real-world use. In this article, we took a look at the recent developments and how they affect building with LLMs:
- Most current LLMs are autoregressive and excel at generative tasks. They might be unreliable for analytical tasks, in which case either autoencoding LLMs or alternative NLP techniques should be preferred.
- There are considerable differences between open-source and commercial LLMs, and switching between LLMs might turn out to be harder than it seems. Carefully consider the trade-offs, evaluate possible development paths (start with open-source and switch to commercial later) and consider a multi-LLM setup if different features of your product rely on LLMs.
- Frameworks provide a handy interface to build with LLMs, but don’t underestimate the importance of the LLM layer — LLMs should undergo a process of experimentation and careful selection, after which they run through the full MLOps cycle to ensure a robust, continuously optimised operation and mitigate issues such as model shift.
- Builders should proactively manage the human factor. LLMs have conquered language, a cognitive area that was originally only accessible to humans. As humans, we quickly forget that LLMs are still “machines”, and fail to operate them as such. For users and employees, consider how you can raise their awareness and educate them on the correct operation and usage of LLMs.
References
[1] Andreessen Horowitz. 2023. For B2B Generative AI Apps, Is Less More?
[2] Li Dong et al. 2019. Unified language model pre-training for natural language understanding and generation. In Proceedings of the 33rd International Conference on Neural Information Processing Systems, pp. 13063–13075.
[3] The Information. 2023. Google Researcher: Company Has ‘No Moat’ in AI.
[4] Tri Dao et al. 2022. FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness.
[5] EE Times. 2023. Can Open-Source LLMs Solve AI’s Democratization Problem?
[6] Jared Kaplan et al. 2023. Scaling Laws for Neural Language Models.
[7] Jason Wei et al. 2023. Emergent Abilities of Large Language Models.
[8] Philip Anderson. 1972. More is Different. In Science, Vol 177, Issue 4047, pp. 393–396.
[9] Janna Lipenkova. 2023. Overcoming the Limitations of Large Language Models.
[10] Joon Sung Park et al. 2023. Generative Agents: Interactive Simulacra of Human Behavior.
[11] Harvard University. 2023. GPT-4 — How does it work, and how do I build apps with it? — CS50 Tech Talk.
[12] Yann LeCun. 2022. A Path Towards Autonomous Machine Intelligence.
[13] Jerry Liu. 2023. Dumber LLM Agents Need More Constraints and Better Tools.
This article was originally published on Towards Data Science and re-published to TOPBOTS with permission from the author.
Enjoy this article? Sign up for more AI research updates.
We’ll let you know when we release more summary articles like this one.
Related
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoAiStream. Web3 Data Intelligence. Knowledge Amplified. Access Here.
- Minting the Future w Adryenn Ashley. Access Here.
- Buy and Sell Shares in PRE-IPO Companies with PREIPO®. Access Here.
- Source: https://www.topbots.com/four-large-language-model-trends/

