Lujatekoisten ja uudelleenkäytettävien koneoppimisputkien (ML) luominen voi olla monimutkainen ja aikaa vievä prosessi. Kehittäjät testaavat yleensä prosessointi- ja koulutusskriptiään paikallisesti, mutta itse putkistot testataan yleensä pilvessä. Täyden putkilinjan luominen ja käyttäminen kokeilun aikana lisää ei-toivottuja yleiskustannuksia ja kustannuksia kehitystyön elinkaareen. Tässä viestissä kerromme yksityiskohtaisesti, kuinka voit käyttää Amazon SageMaker Pipelines -paikallinen tila käyttää ML-putkia paikallisesti lyhentääksesi sekä putkilinjan kehitystä että ajoaikaa ja samalla kustannuksia. Kun putki on täysin testattu paikallisesti, voit suorittaa sen helposti uudelleen Amazon Sage Maker hallinnoidut resurssit vain muutamalla koodirivillä.
Yleiskatsaus ML:n elinkaaresta
Yksi uusien innovaatioiden ja sovellusten tärkeimmistä tekijöistä ML:ssä on tiedon saatavuus ja määrä sekä halvemmat laskentavaihtoehdot. Monilla aloilla ML on osoittautunut kykeneväksi ratkaisemaan ongelmia, joita ei aiemmin voitu ratkaista klassisilla big datalla ja analyyttisilla tekniikoilla, ja tietotieteen ja ML-harjoittajien kysyntä kasvaa tasaisesti. Erittäin korkealta tasolta ML-elinkaari koostuu useista eri osista, mutta ML-mallin rakentaminen koostuu yleensä seuraavista yleisistä vaiheista:
- Tietojen puhdistus ja valmistelu (ominaisuussuunnittelu)
- Mallin koulutus ja viritys
- Mallin arviointi
- Mallin käyttöönotto (tai erämuunnos)
Tietojen valmisteluvaiheessa tiedot ladataan, hierotaan ja muunnetaan ML-mallin odottamien tulotyyppien tai ominaisuuksien mukaisiksi. Skriptien kirjoittaminen datan muuntamiseksi on tyypillisesti iteratiivinen prosessi, jossa nopeat palautesilmukat ovat tärkeitä kehityksen nopeuttamiseksi. Normaalisti ei ole tarpeen käyttää koko tietojoukkoa ominaisuussuunnitteluskriptien testauksessa, minkä vuoksi voit käyttää paikallistilan ominaisuus SageMaker Processingista. Tämän avulla voit suorittaa paikallisesti ja päivittää koodin iteratiivisesti käyttämällä pienempää tietojoukkoa. Kun lopullinen koodi on valmis, se lähetetään etäkäsittelytyöhön, joka käyttää koko tietojoukkoa ja toimii SageMaker-hallituissa ilmentymissä.
Kehitysprosessi on samanlainen kuin tietojen valmisteluvaihe sekä mallikoulutuksen että mallin arviointivaiheiden osalta. Tietotieteilijät käyttävät paikallistilan ominaisuus SageMaker Training -ohjelman avulla voit iteroida nopeasti pienempien tietojoukkojen kanssa paikallisesti, ennen kuin käytät kaikkia tietoja SageMakerin hallitussa ML-optimoitujen ilmentymien klusterissa. Tämä nopeuttaa kehitysprosessia ja eliminoi SageMakerin hallinnoimien ML-instanssien suorittamisen kustannukset kokeilun aikana.
Kun organisaation ML-kypsyys kasvaa, voit käyttää Amazon SageMaker -putkistot luoda ML-putkistoja, jotka yhdistävät nämä vaiheet ja luomalla monimutkaisempia ML-työnkulkuja, jotka käsittelevät, kouluttavat ja arvioivat ML-malleja. SageMaker Pipelines on täysin hallittu palvelu ML-työnkulun eri vaiheiden automatisoimiseksi, mukaan lukien tietojen lataaminen, tiedon muuntaminen, mallin koulutus ja viritys sekä mallin käyttöönotto. Viime aikoihin asti voit kehittää ja testata skriptejäsi paikallisesti, mutta sinun piti testata ML-putkistojasi pilvessä. Tämä teki ML-putkien virtauksen ja muodon iteroinnista hitaan ja kalliin prosessin. Nyt SageMaker Pipelinesin lisätyn paikallistilan ominaisuuden avulla voit iteroida ja testata ML-putkistoja samalla tavalla kuin testaat ja iteroit prosessointi- ja koulutusskriptejäsi. Voit ajaa ja testata liukuhihnasi paikallisella koneellasi käyttämällä pientä osajoukkoa putkilinjan syntaksin ja toimintojen vahvistamiseen.
SageMaker-putkistot
SageMaker Pipelines tarjoaa täysin automatisoidun tavan suorittaa yksinkertaisia tai monimutkaisia ML-työnkulkuja. SageMaker Pipelinesin avulla voit luoda ML-työnkulkuja helppokäyttöisellä Python SDK:lla ja sitten visualisoida ja hallita työnkulkuasi käyttämällä Amazon SageMaker Studio. Datatieteen tiimisi voivat olla tehokkaampia ja skaalautua nopeammin tallentamalla ja käyttämällä uudelleen SageMaker Pipelinesissä luomiasi työnkulun vaiheita. Voit myös käyttää valmiita malleja, jotka automatisoivat infrastruktuurin ja arkiston luomisen mallien rakentamiseen, testaamiseen, rekisteröimiseen ja käyttöönottoon ML-ympäristössäsi. Nämä mallit ovat automaattisesti organisaatiosi käytettävissä, ja niitä käytetään AWS-palveluluettelo tuotteita.
SageMaker Pipelines tuo jatkuvan integroinnin ja jatkuvan käyttöönoton (CI/CD) käytännöt ML:ään, kuten pariteetin ylläpitämisen kehitys- ja tuotantoympäristöjen välillä, versionhallinnan, tilaustestauksen ja päästä päähän automatisoinnin, mikä auttaa sinua skaalaamaan ML:ää koko käyttösi ajan. organisaatio. DevOps-ammattilaiset tietävät, että CI/CD-tekniikoiden käytön tärkeimpiä etuja ovat tuottavuuden kasvu uudelleenkäytettävien komponenttien avulla ja laadun paraneminen automaattisen testauksen avulla, mikä johtaa nopeampaan sijoitetun pääoman tuottoprosenttiin liiketoimintatavoitteidesi saavuttamiseksi. Nämä edut ovat nyt MLOps-harjoittajien saatavilla käyttämällä SageMaker-putkia automatisoimaan ML-mallien koulutusta, testausta ja käyttöönottoa. Paikallisessa tilassa voit nyt iteroida paljon nopeammin, kun kehität skriptejä käytettäväksi liukuhihnassa. Huomaa, että paikallisia liukuhihnan esiintymiä ei voi tarkastella tai suorittaa Studio IDE:ssä. paikallisten putkien katselumahdollisuudet ovat kuitenkin pian saatavilla.
SageMaker SDK tarjoaa yleisen tarkoituksen paikallisen tilan määritys jonka avulla kehittäjät voivat käyttää ja testata tuettuja prosessoreita ja arvioijia paikallisessa ympäristössään. Voit käyttää paikallisen tilan harjoittelua useiden AWS-tuettujen kehyskuvien (TensorFlow, MXNet, Chainer, PyTorch ja Scikit-Learn) sekä itse toimittamiesi kuvien kanssa.
SageMaker Pipelines, joka rakentaa ohjatun asyklisen kaavion (DAG) organisoiduista työnkulun vaiheista, tukee monia toimintoja, jotka ovat osa ML:n elinkaarta. Paikallisessa tilassa seuraavat vaiheet ovat tuettuja:
- Työvaiheiden käsittely – Yksinkertaistettu, hallittu kokemus SageMakerissa tietojenkäsittelyn työkuormien suorittamiseen, kuten ominaisuuksien suunnittelu, tietojen validointi, mallin arviointi ja mallin tulkinta
- Koulutuksen työvaiheet – Iteratiivinen prosessi, joka opettaa mallin tekemään ennusteita esittämällä esimerkkejä harjoitustietojoukosta
- Hyperparametrien viritystyöt – Automaattinen tapa arvioida ja valita hyperparametrit, jotka tuottavat tarkimman mallin
- Ehdolliset juoksuvaiheet – Vaihe, joka tarjoaa ehdollisen haarojen sarjan liukuhihnassa
- Mallin vaihe – CreateModel-argumenttien avulla tämä vaihe voi luoda mallin käytettäväksi muunnosvaiheissa tai myöhemmässä käyttöönotossa päätepisteenä
- Muuta työn vaiheita – Erämuunnostyö, joka luo ennusteita suurista tietojoukoista ja suorittaa päättelyn, kun pysyvää päätepistettä ei tarvita
- Epäonnistuneet vaiheet – Vaihe, joka pysäyttää liukuhihnaajon ja merkitsee ajon epäonnistuneeksi
Ratkaisun yleiskatsaus
Ratkaisumme esittelee keskeiset vaiheet SageMaker-putkien luomiseksi ja suorittamiseksi paikallisessa tilassa, mikä tarkoittaa paikallisten prosessori-, RAM- ja levyresurssien käyttöä työnkulun vaiheiden lataamiseen ja suorittamiseen. Paikallinen ympäristösi voi toimia kannettavalla tietokoneella käyttämällä suosittuja IDE:itä, kuten VSCodea tai PyCharmia, tai sitä voi isännöidä SageMaker käyttämällä perinteisiä kannettavan tietokoneen ilmentymiä.
Paikallisen tilan avulla datatutkijat voivat yhdistää vaiheita, joihin voi sisältyä käsittely-, koulutus- ja arviointitöitä, ja suorittaa koko työnkulun paikallisesti. Kun olet lopettanut paikallisen testauksen, voit suorittaa liukuhihnan uudelleen SageMaker-hallitussa ympäristössä korvaamalla LocalPipelineSession esine kanssa PipelineSession, joka tuo johdonmukaisuutta ML:n elinkaareen.
Tässä muistikirjanäytteessä käytämme yleistä julkisesti saatavilla olevaa tietojoukkoa UCI Machine Learning Abalone Dataset. Tavoitteena on kouluttaa ML-malli määrittämään abalonetanan ikä sen fyysisten mittausten perusteella. Pohjimmiltaan tämä on regressio-ongelma.
Kaikki tämän kannettavan näytteen suorittamiseen tarvittava koodi on saatavilla GitHubissa osoitteessa amazon-sagemaker-esimerkkejä arkisto. Tässä muistikirjaesimerkissä jokainen liukuhihnan työnkulun vaihe luodaan itsenäisesti ja yhdistetään sitten liukuhihnan luomiseksi. Luomme seuraavat vaiheet:
- Käsittelyvaihe (ominaisuussuunnittelu)
- Koulutusvaihe (mallikoulutus)
- Käsittelyvaihe (mallin arviointi)
- Kuntovaihe (mallin tarkkuus)
- Luo mallin vaihe (malli)
- Muunnosvaihe (erämuunnos)
- Rekisteröi mallivaihe (mallipaketti)
- Epäonnistunut vaihe (ajo epäonnistui)
Seuraava kaavio havainnollistaa putkistoamme.
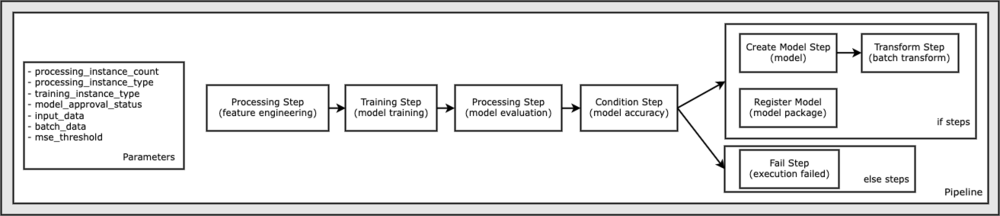
Edellytykset
Jotta voit seurata tätä viestiä, tarvitset seuraavat:
Kun nämä edellytykset on täytetty, voit käyttää mallimuistikirjan seuraavissa osissa kuvatulla tavalla.
Rakenna putkisto
Tässä muistikirjanäytteessä käytämme SageMaker Script Mode useimmille ML-prosesseille, mikä tarkoittaa, että toimitamme todellisen Python-koodin (skriptit) toiminnon suorittamiseksi ja välitämme viittauksen tähän koodiin. Script Mode tarjoaa suuren joustavuuden ohjata toimintaa SageMaker-käsittelyssä sallimalla sinun mukauttaa koodiasi samalla kun hyödynnät SageMakerin valmiita säiliöitä, kuten XGBoost tai Scikit-Learn. Mukautettu koodi kirjoitetaan Python-skriptitiedostoon käyttämällä soluja, jotka alkavat magic-komennolla %%writefile, kuten seuraavat:
%%writefile code/evaluation.py
Paikallisen tilan ensisijainen mahdollistaja on LocalPipelineSession objekti, joka on instantoitu Python SDK:sta. Seuraavat koodisegmentit osoittavat, kuinka SageMaker-liukuhihna luodaan paikallisessa tilassa. Vaikka voit määrittää paikallisen tietopolun monille paikallisille liukuhihnan vaiheille, Amazon S3 on oletussijainti muunnoksen tuottamien tietojen tallentamiseen. Uusi LocalPipelineSession objekti välitetään Python SDK:lle monissa tässä viestissä kuvatuissa SageMaker-työnkulun API-kutsuissa. Huomaa, että voit käyttää local_pipeline_session muuttuja, joka hakee viittaukset S3-oletussäilöön ja nykyiseen alueen nimeen.
Ennen kuin luomme yksittäisiä liukuhihnavaiheita, asetamme joitain liukuhihnan käyttämiä parametreja. Jotkut näistä parametreista ovat merkkijonoliteraaaleja, kun taas toiset on luotu SDK:n tarjoamina erityisinä lueteltuina tyypeinä. Luettelo kirjoittaminen varmistaa, että kelvolliset asetukset toimitetaan liukuhihnalle, kuten tälle, joka välitetään ConditionLessThanOrEqualTo askel alaspäin:
mse_threshold = ParameterFloat(name="MseThreshold", default_value=7.0)
Luodaksemme tietojenkäsittelyvaiheen, jota käytetään tässä ominaisuuden suunnitteluun, käytämme SKLearnProcessor ladata ja muuttaa tietojoukko. Ohitamme local_pipeline_session muuttuja luokan rakentajalle, joka käskee työnkulun vaiheen ajamaan paikallisessa tilassa:
Seuraavaksi luomme ensimmäisen varsinaisen putkivaiheen, a ProcessingStep objekti, joka on tuotu SageMaker SDK:sta. Prosessorin argumentit palautetaan kutsusta SKLearnProcessor run() -menetelmä. Tämä työnkulun vaihe yhdistetään muihin muistikirjan loppua kohti johtaviin vaiheisiin osoittamaan toimintajärjestystä prosessissa.
Seuraavaksi tarjoamme koodin harjoitusvaiheen luomiseksi luomalla ensin standardiestimaattori SageMaker SDK:n avulla. Me ohitamme saman local_pipeline_session muuttuja estimaattoriin nimeltä xgb_train sagemaker_session Perustelu. Koska haluamme kouluttaa XGBoost-mallin, meidän on luotava kelvollinen kuvan URI määrittämällä seuraavat parametrit, mukaan lukien kehys ja useita versioparametreja:
Voimme valinnaisesti kutsua esimerkiksi muita estimaattorimenetelmiä set_hyperparameters(), antaaksesi harjoitustyön hyperparametriasetukset. Nyt kun estimaattori on määritetty, olemme valmiita luomaan varsinaisen harjoitusvaiheen. Jälleen kerran tuomme TrainingStep luokka SageMaker SDK -kirjastosta:
Seuraavaksi rakennamme toisen käsittelyvaiheen mallin arvioinnin suorittamiseksi. Tämä tehdään luomalla a ScriptProcessor esimerkki ja ohittaminen local_pipeline_session objekti parametrina:
Jos haluat ottaa käyttöön koulutetun mallin, joko a SageMaker reaaliaikainen päätepiste tai erämuunnokseen meidän on luotava a Model objektia välittämällä mallin artefaktit, oikean kuvan URI:n ja valinnaisesti mukautetun päättelykoodimme. Sitten ohitamme tämän Model vastustaa a ModelStep, joka lisätään paikalliseen putkistoon. Katso seuraava koodi:
Seuraavaksi luomme erämuunnosvaiheen, jossa lähetämme joukon piirrevektoreita ja teemme päättelyn. Meidän on ensin luotava a Transformer vastusta ja ohita local_pipeline_session parametri siihen. Sitten luomme a TransformStep, välittää vaaditut argumentit ja lisää tämä liukuhihnan määritelmään:
Lopuksi haluamme lisätä työnkulkuun haaraehdon, jotta suoritamme erämuunnoksen vain, jos mallin arvioinnin tulokset täyttävät kriteerimme. Voimme osoittaa tämän ehdollisen lisäämällä a ConditionStep tietyllä ehtotyypillä, kuten ConditionLessThanOrEqualTo. Tämän jälkeen luetellaan vaiheet kahdelle haaralle ja määritellään olennaisesti liukuhihnan if/else- tai true/false-haarat. Kohdassa annettu if_steps ConditionStep (step_create_model, askel_muunnos) suoritetaan aina, kun ehdon arvo on True.
Seuraava kaavio havainnollistaa tätä ehdollista haaraa ja siihen liittyviä if/else-vaiheita. Vain yksi haara ajetaan mallin arviointivaiheen tuloksen perusteella verrattuna ehtovaiheessa.
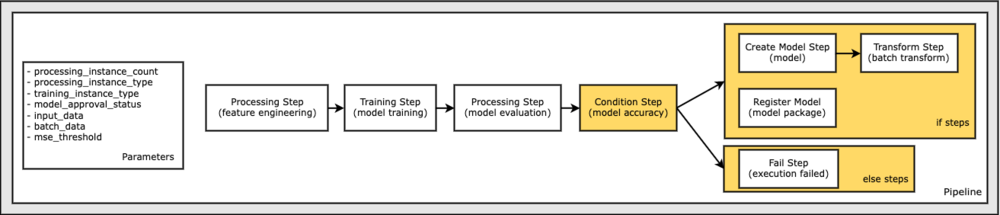
Nyt kun olemme määrittäneet kaikki vaiheemme ja luoneet taustalla olevat luokkaesiintymät, voimme yhdistää ne liukuhihnaksi. Tarjoamme joitain parametreja ja määrittelemme toimintajärjestyksen yksinkertaisesti luettelemalla vaiheet halutussa järjestyksessä. Huomaa, että TransformStep ei näy tässä, koska se on ehdollisen vaiheen kohde, ja se toimitettiin vaiheargumenttina ConditionalStep aikaisemmin.
Liukulinjan suorittamiseksi sinun on kutsuttava kaksi menetelmää: pipeline.upsert(), joka lataa putken taustalla olevaan palveluun ja pipeline.start(), joka käynnistää putkilinjan. Voit käyttää useita muita menetelmiä ajon tilan tiedustelemiseen, liukuhihnan vaiheiden luetteloimiseen ja paljon muuta. Koska käytimme paikallisen tilan liukuhihnaistuntoa, nämä vaiheet suoritetaan kaikki paikallisesti prosessorillasi. Aloitusmenetelmän alla oleva solutulos näyttää liukuhihnan lähdön:
Sinun pitäisi nähdä solutulosteen alaosassa seuraavanlainen viesti:
Pipeline execution d8c3e172-089e-4e7a-ad6d-6d76caf987b7 SUCCEEDED
Palaa hallinnoituihin resursseihin
Kun olemme vahvistaneet, että putki kulkee virheettömästi ja olemme tyytyväisiä putkilinjan virtaukseen ja muotoon, voimme luoda putkilinjan uudelleen SageMakerin hallinnoimilla resursseilla ja ajaa sen uudelleen. Ainoa tarvittava muutos on käyttää PipelineSession objektin sijaan LocalPipelineSession:
alkaen sagemaker.workflow.pipeline_context tuonti LocalPipelineSessionfrom sagemaker.workflow.pipeline_context import PipelineSession
local_pipeline_session = LocalPipelineSession()pipeline_session = PipelineSession()
Tämä kehottaa palvelua suorittamaan jokaisen tähän istuntoobjektiin viittaavan vaiheen SageMakerin hallinnoimissa resursseissa. Pienen muutoksen vuoksi kuvaamme vain tarvittavat koodimuutokset seuraavassa koodisolussa, mutta sama muutos tulisi toteuttaa jokaisessa solussa käyttämällä local_pipeline_session esine. Muutokset ovat kuitenkin identtisiä kaikissa soluissa, koska korvaamme vain local_pipeline_session esine pipeline_session esine.
Kun paikallinen istuntoobjekti on korvattu kaikkialla, luomme liukuhihnan uudelleen ja suoritamme sen SageMakerin hallinnoimilla resursseilla:
Puhdistaa
Jos haluat pitää Studio-ympäristön siistinä, voit poistaa SageMaker-liukuhihnan ja mallin seuraavilla tavoilla. Koko koodi löytyy näytteestä muistikirja.
Yhteenveto
Viime aikoihin asti voit käyttää SageMaker Processingin ja SageMaker Trainingin paikallistilan ominaisuutta toistaaksesi prosessointi- ja koulutusskriptejäsi paikallisesti, ennen kuin suoritit ne kaikissa tiedoissa SageMakerin hallinnoimilla resursseilla. SageMaker Pipelinesin uuden paikallistilan ominaisuuden ansiosta ML-harjoittajat voivat nyt käyttää samaa menetelmää iteroidessaan ML-putkistojaan yhdistäen eri ML-työnkulkuja. Kun putki on valmis tuotantoa varten, sen käyttäminen SageMakerin hallituilla resursseilla vaatii vain muutaman rivin koodimuutoksia. Tämä lyhentää putkilinjan ajoaikaa kehityksen aikana, mikä johtaa nopeampaan putkien kehittämiseen nopeammilla kehityssykleillä ja samalla vähentää SageMakerin hallinnoimien resurssien kustannuksia.
Saat lisätietoja osoitteesta Amazon SageMaker -putkistot or Käytä SageMaker-putkia työsi suorittamiseen paikallisesti.
Tietoja kirjoittajista
 Paul Hargis on keskittynyt koneoppimiseen useissa yrityksissä, mukaan lukien AWS, Amazon ja Hortonworks. Hän nauttii teknisten ratkaisujen rakentamisesta ja ihmisten opettamisesta hyödyntämään niitä. Ennen rooliaan AWS:ssä hän oli Amazon Exports and Expansions -yksikön pääarkkitehti, joka auttoi amazon.com-sivustoa parantamaan kansainvälisten ostajien kokemusta. Paul haluaa auttaa asiakkaita laajentamaan koneoppimisaloitteitaan todellisten ongelmien ratkaisemiseksi.
Paul Hargis on keskittynyt koneoppimiseen useissa yrityksissä, mukaan lukien AWS, Amazon ja Hortonworks. Hän nauttii teknisten ratkaisujen rakentamisesta ja ihmisten opettamisesta hyödyntämään niitä. Ennen rooliaan AWS:ssä hän oli Amazon Exports and Expansions -yksikön pääarkkitehti, joka auttoi amazon.com-sivustoa parantamaan kansainvälisten ostajien kokemusta. Paul haluaa auttaa asiakkaita laajentamaan koneoppimisaloitteitaan todellisten ongelmien ratkaisemiseksi.
 Niklas Palm on ratkaisuarkkitehti AWS: llä Tukholmassa, Ruotsissa, jossa hän auttaa asiakkaita Pohjoismaissa menestymään pilvessä. Hän on erityisen intohimoinen palvelimettomista tekniikoista sekä esineiden internetistä ja koneoppimisesta. Työn ulkopuolella Niklas on innokas hiihtäjä ja lumilautailija sekä mestarimunakattila.
Niklas Palm on ratkaisuarkkitehti AWS: llä Tukholmassa, Ruotsissa, jossa hän auttaa asiakkaita Pohjoismaissa menestymään pilvessä. Hän on erityisen intohimoinen palvelimettomista tekniikoista sekä esineiden internetistä ja koneoppimisesta. Työn ulkopuolella Niklas on innokas hiihtäjä ja lumilautailija sekä mestarimunakattila.
 Kirit Thadaka on ML Solutions -arkkitehti, joka työskentelee SageMaker Service SA -tiimissä. Ennen AWS:ään liittymistä Kirit työskenteli varhaisen vaiheen tekoälyn startup-yrityksissä, minkä jälkeen hän konsultoi jonkin aikaa erilaisissa tekoälytutkimuksen, MLOps- ja teknisen johtajuuden rooleissa.
Kirit Thadaka on ML Solutions -arkkitehti, joka työskentelee SageMaker Service SA -tiimissä. Ennen AWS:ään liittymistä Kirit työskenteli varhaisen vaiheen tekoälyn startup-yrityksissä, minkä jälkeen hän konsultoi jonkin aikaa erilaisissa tekoälytutkimuksen, MLOps- ja teknisen johtajuuden rooleissa.

