Amazon SageMaker Studio tarjoaa täysin hallitun ratkaisun datatieteilijöille koneoppimismallien (ML) interaktiiviseen rakentamiseen, kouluttamiseen ja käyttöönottoon. Työskennellessään ML-tehtäviensä parissa datatieteilijät yleensä aloittavat työnkulkunsa etsimällä asiaankuuluvia tietolähteitä ja muodostamalla niihin yhteyden. He käyttävät sitten SQL:ää tutkiakseen, analysoidakseen, visualisoidakseen ja integroidakseen eri lähteistä peräisin olevaa dataa ennen kuin käyttävät sitä ML-koulutuksessaan ja päätelmissään. Aikaisemmin datatieteilijät huomasivat usein jongleeraavansa useita työkaluja tukeakseen SQL:ää työnkulussaan, mikä esti tuottavuutta.
Meillä on ilo ilmoittaa, että SageMaker Studion JupyterLab-muistikirjoissa on nyt sisäänrakennettu SQL-tuki. Datatieteilijät voivat nyt:
- Yhdistä suosittuihin datapalveluihin, mukaan lukien Amazon Athena, Amazonin punainen siirto, Amazon DataZone, ja Snowflake suoraan muistikirjoissa
- Selaa ja etsi tietokantoja, skeemoja, taulukoita ja näkymiä sekä esikatsele tietoja kannettavan tietokoneen käyttöliittymässä
- Sekoita SQL- ja Python-koodi samassa muistikirjassa tehokkaaseen tietojen tutkimiseen ja muuntamiseen käytettäväksi ML-projekteissa
- Käytä kehittäjien tuottavuusominaisuuksia, kuten SQL-komentojen viimeistelyä, koodin muotoiluapua ja syntaksin korostusta nopeuttaaksesi koodin kehitystä ja parantaaksesi yleistä kehittäjien tuottavuutta.
Lisäksi järjestelmänvalvojat voivat hallita turvallisesti yhteyksiä näihin tietopalveluihin, jolloin datatutkijat voivat käyttää valtuutettuja tietoja ilman, että heidän tarvitsee hallita tunnistetietoja manuaalisesti.
Tässä viestissä opastamme sinua tämän ominaisuuden määrittämisessä SageMaker Studiossa ja opastamme sinut tämän ominaisuuden eri ominaisuuksien läpi. Sitten näytämme, kuinka voit parantaa kannettavan tietokoneen SQL-kokemusta käyttämällä edistyneiden suurten kielimallien (LLM) tarjoamia Text-to-SQL-ominaisuuksia monimutkaisten SQL-kyselyjen kirjoittamiseen käyttämällä luonnollisen kielen tekstiä syötteenä. Lopuksi, jotta laajempi käyttäjäryhmä voisi luoda SQL-kyselyitä muistikirjoissaan olevista luonnollisen kielen syötteistä, näytämme sinulle, kuinka nämä Text-to-SQL-mallit otetaan käyttöön käyttämällä Amazon Sage Maker päätepisteitä.
Ratkaisun yleiskatsaus
SageMaker Studio JupyterLab -muistikirjan SQL-integraation avulla voit nyt muodostaa yhteyden suosittuihin tietolähteisiin, kuten Snowflake, Athena, Amazon Redshift ja Amazon DataZone. Tämän uuden ominaisuuden avulla voit suorittaa erilaisia toimintoja.
Voit esimerkiksi tutkia visuaalisesti tietolähteitä, kuten tietokantoja, taulukoita ja skeemoja suoraan JupyterLab-ekosysteemistäsi. Jos kannettavan tietokoneesi ympäristöissä on käytössä SageMaker Distribution 1.6 tai uudempi, etsi uusi widget JupyterLab-käyttöliittymän vasemmalta puolelta. Tämä lisäys parantaa tietojen saatavuutta ja hallintaa kehitysympäristössäsi.
Jos et tällä hetkellä käytä ehdotettua SageMaker-jakelua (1.5 tai vanhempi) tai mukautetussa ympäristössä, katso lisätietoja liitteestä.
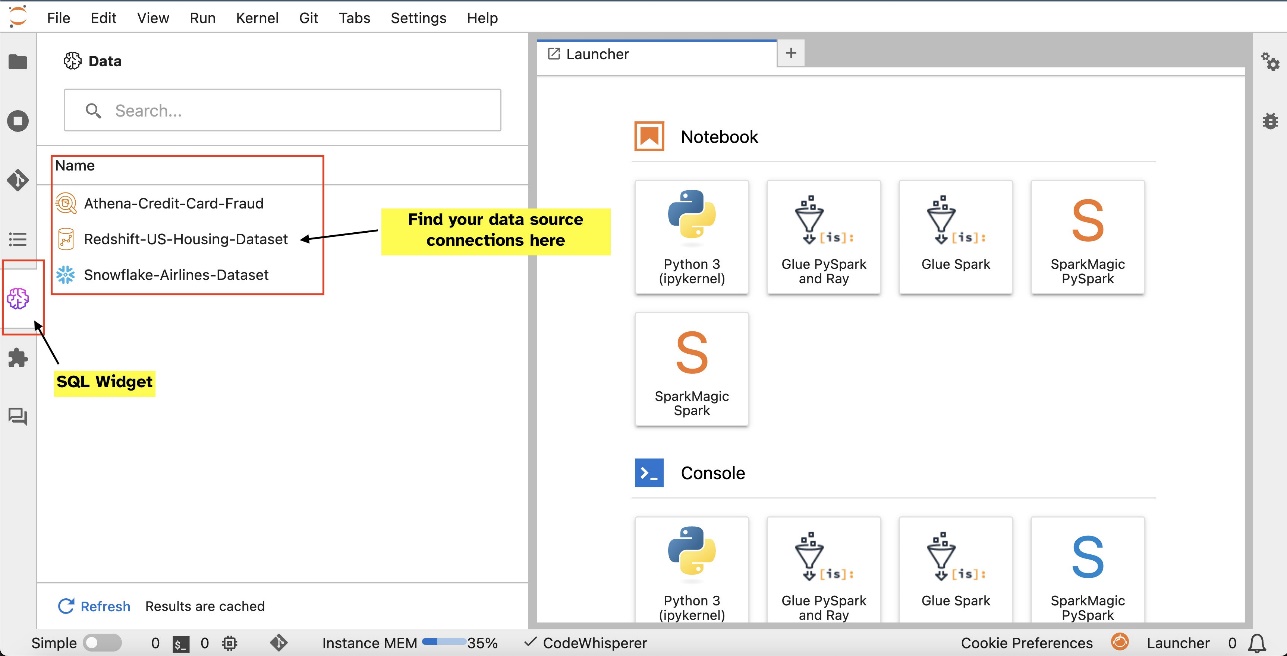
Kun olet määrittänyt yhteydet (kuvattu seuraavassa osiossa), voit luetella datayhteydet, selata tietokantoja ja taulukoita ja tarkastella skeemoja.
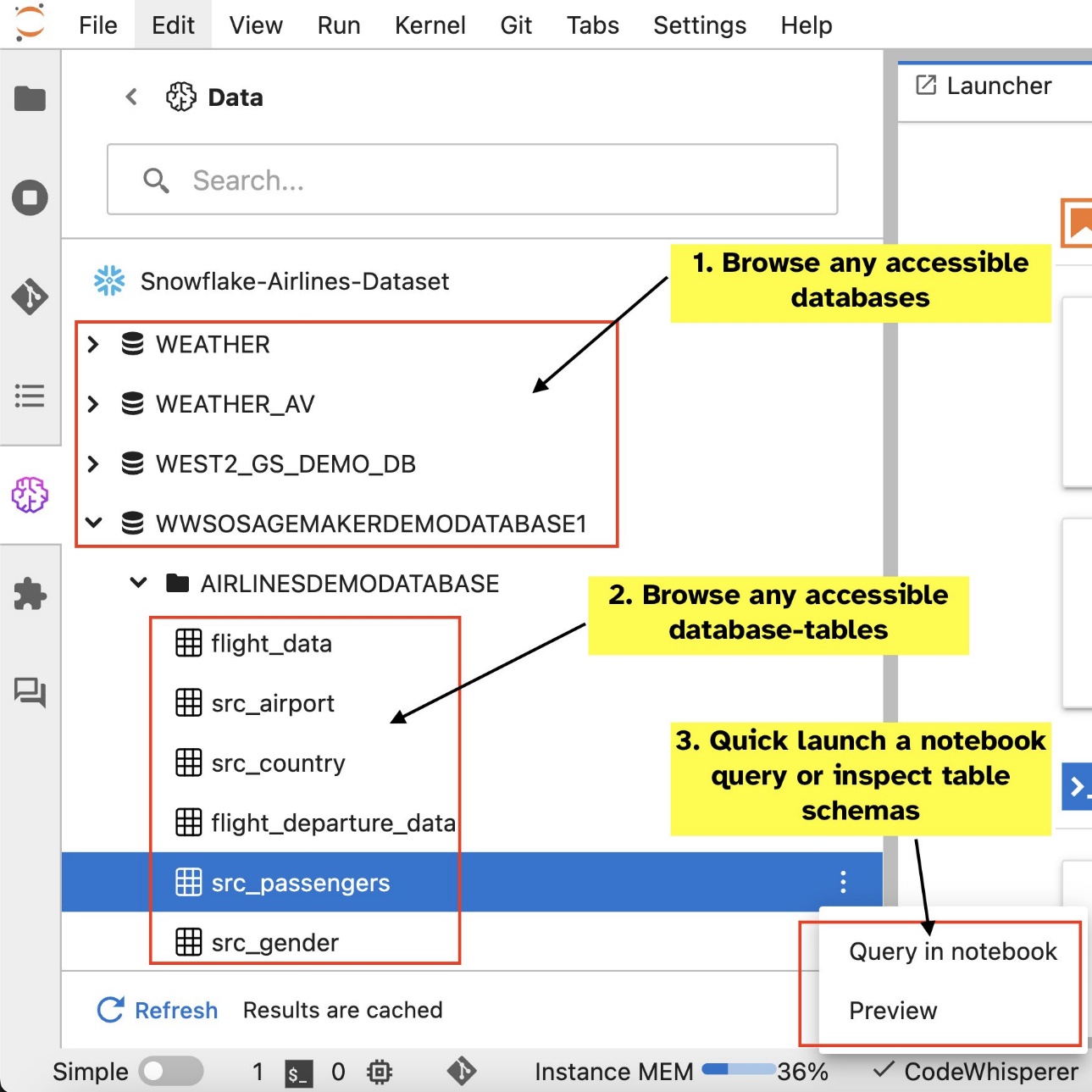
SageMaker Studion JupyterLabin sisäänrakennettu SQL-laajennus mahdollistaa myös SQL-kyselyjen suorittamisen suoraan muistikirjasta. Jupyter-muistikirjat voivat erottaa SQL- ja Python-koodin toisistaan käyttämällä %%sm_sql magic-komento, joka on sijoitettava minkä tahansa SQL-koodia sisältävän solun yläosaan. Tämä komento ilmaisee JupyterLabille, että seuraavat ohjeet ovat SQL-komentoja Python-koodin sijaan. Kyselyn tulos voidaan näyttää suoraan muistikirjassa, mikä helpottaa SQL- ja Python-työnkulkujen saumatonta integrointia tietoanalyysiisi.
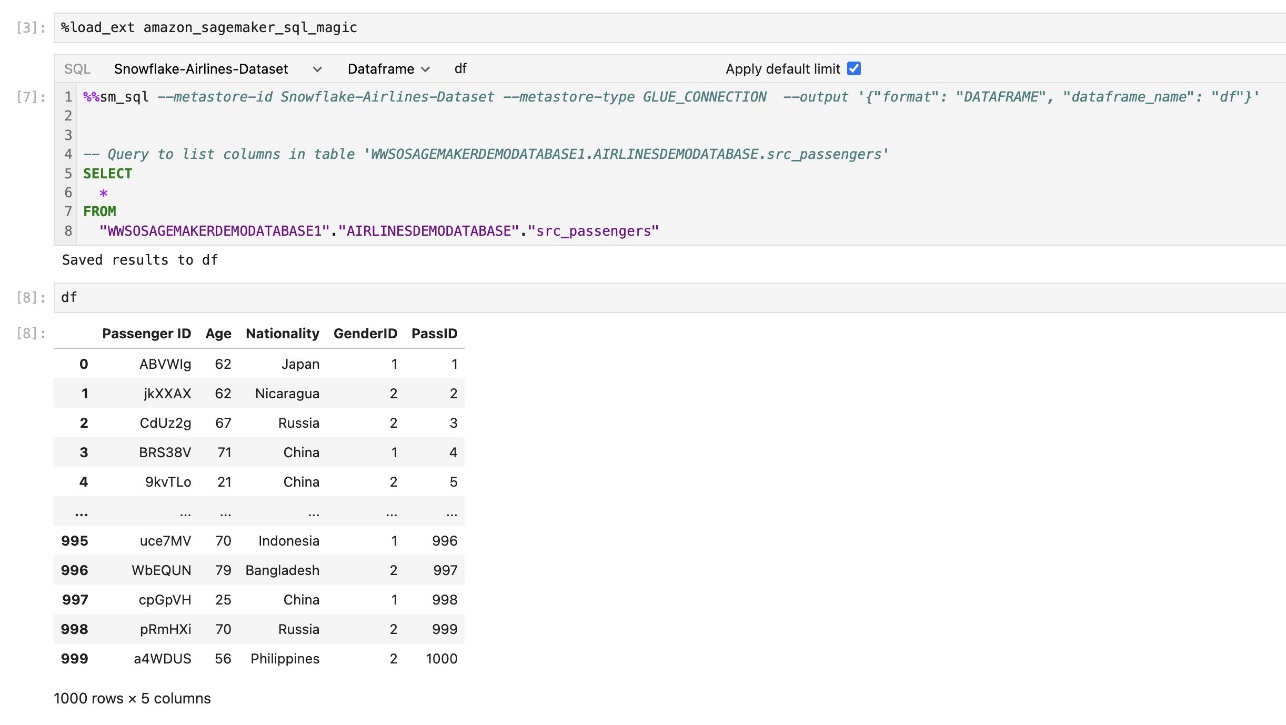
Kyselyn tulos voidaan näyttää visuaalisesti HTML-taulukoina, kuten seuraavassa kuvakaappauksessa näkyy.

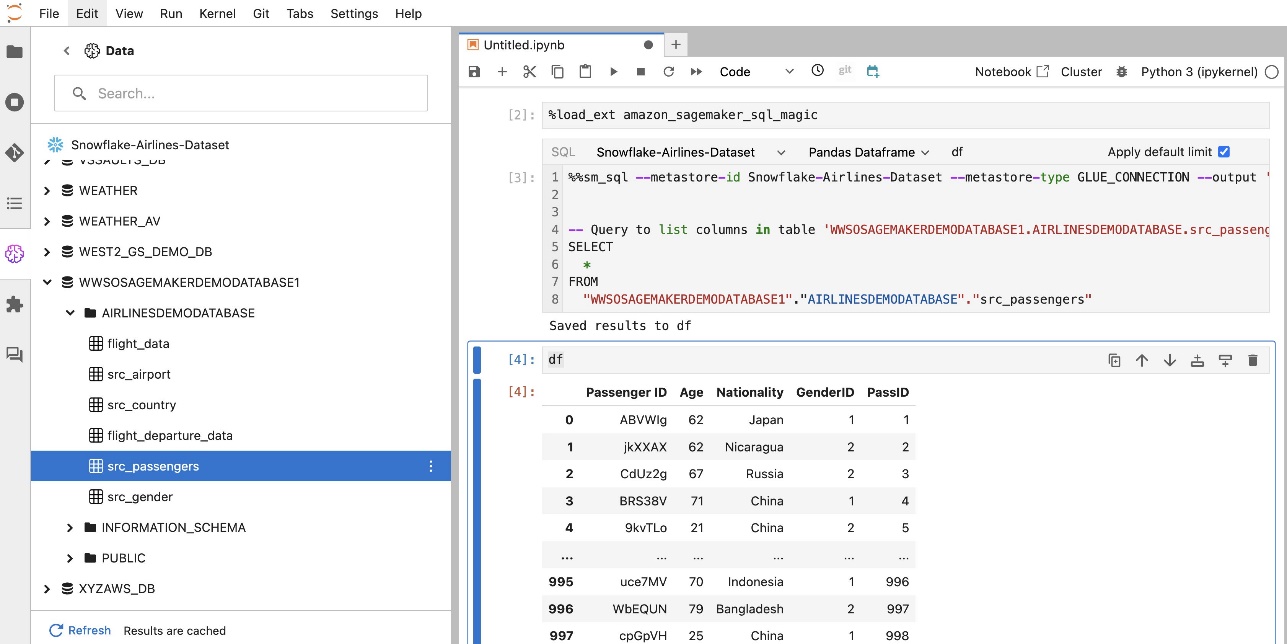
Ne voidaan kirjoittaa myös a pandas DataFrame.
Edellytykset
Varmista, että täytät seuraavat edellytykset käyttääksesi SageMaker Studio -muistikirjan SQL-kokemusta:
- SageMaker Studio V2 – Varmista, että käytät viimeisintä versiota SageMaker Studio -verkkotunnus ja käyttäjäprofiilit. Jos käytät tällä hetkellä SageMaker Studio Classicia, katso Siirtyminen Amazon SageMaker Studio Classicista.
- IAM-rooli – SageMaker vaatii AWS-henkilöllisyyden ja käyttöoikeuksien hallinta (IAM) rooli, joka määritetään SageMaker Studio -verkkotunnukselle tai käyttäjäprofiilille, jotta käyttöoikeuksia voidaan hallita tehokkaasti. Suoritusroolin päivitys saattaa olla tarpeen tietojen selailun ja SQL-ajoominaisuuden tuomiseksi käyttöön. Seuraava esimerkkikäytännön avulla käyttäjät voivat myöntää, luetteloida ja suorittaa AWS-liima, Athena, Amazonin yksinkertainen tallennuspalvelu (Amazon S3), AWS -salaisuuksien hallintaja Amazon Redshift -resurssit:
- JupyterLab Space – Tarvitset pääsyn päivitettyyn SageMaker Studioon ja JupyterLab Spaceen SageMaker-jakelu v1.6 tai uudemmat kuvaversiot. Jos käytät mukautettuja kuvia JupyterLab Spacesille tai SageMaker Distributionin vanhemmille versioille (v1.5 tai vanhempi), katso liitteestä ohjeet tarvittavien pakettien ja moduulien asentamiseen tämän ominaisuuden käyttöönottamiseksi ympäristöissäsi. Lisätietoja SageMaker Studio JupyterLab Spacesista on osoitteessa Paranna tuottavuutta Amazon SageMaker Studiossa: Esittelyssä JupyterLab Spaces ja generatiiviset tekoälytyökalut.
- Tietolähteen käyttöoikeustiedot – Tämä SageMaker Studion muistikirjan ominaisuus vaatii käyttäjätunnuksen ja salasanan pääsyn tietolähteisiin, kuten Snowflake ja Amazon Redshift. Luo käyttäjätunnus ja salasanapohjainen käyttöoikeus näihin tietolähteisiin, jos sinulla ei vielä ole sellaista. OAuth-pohjainen pääsy Snowflakeen ei ole tuettu ominaisuus tätä kirjoitettaessa.
- Lataa SQL magic – Ennen kuin suoritat SQL-kyselyitä muistikirjan Jupyter-solusta, on tärkeää ladata SQL Magics -laajennus. Käytä komentoa
%load_ext amazon_sagemaker_sql_magicottaaksesi tämän ominaisuuden käyttöön. Lisäksi voit ajaa%sm_sql?-komento nähdäksesi kattavan luettelon tuetuista vaihtoehdoista SQL-solusta kyselyyn. Näitä vaihtoehtoja ovat muun muassa kyselyn oletusrajan asettaminen 1,000 XNUMX:een, täyden purkamisen suorittaminen ja kyselyparametrien lisääminen. Tämä asetus mahdollistaa joustavan ja tehokkaan SQL-tietojen käsittelyn suoraan kannettavan tietokoneen ympäristössä.
Luo tietokantayhteyksiä
SageMaker Studion sisäänrakennettuja SQL-selaus- ja suoritusominaisuuksia parantavat AWS Glue -yhteydet. AWS Glue -yhteys on AWS Glue Data Catalog -objekti, joka tallentaa tärkeitä tietoja, kuten kirjautumistiedot, URI-merkkijonot ja virtuaalisen yksityisen pilven (VPC) tiedot tiettyjä tietovarastoja varten. Näitä yhteyksiä käyttävät AWS Glue -indeksoijat, työt ja kehityspäätepisteet päästäkseen erityyppisiin tietovarastoihin. Voit käyttää näitä yhteyksiä sekä lähde- että kohdetiedoille ja jopa käyttää samaa yhteyttä useissa indeksointiroboteissa tai poimia, muuntaa ja ladata (ETL) -töitä.
Jotta voit tutkia SQL-tietolähteitä SageMaker Studion vasemmassa ruudussa, sinun on ensin luotava AWS Glue -yhteysobjektit. Nämä yhteydet helpottavat pääsyä eri tietolähteisiin ja mahdollistavat niiden kaavamaisten tietoelementtien tutkimisen.
Seuraavissa osissa käydään läpi SQL-kohtaisten AWS-liimaliittimien luontiprosessi. Näin voit käyttää, tarkastella ja tutkia tietojoukkoja useissa tietovarastoissa. Lisätietoja AWS-liimaliitännöistä on kohdassa Yhdistetään dataan.
Luo AWS-liimayhteys
Ainoa tapa tuoda tietolähteitä SageMaker Studioon on AWS Glue -liitännät. Sinun on luotava AWS-liimayhteydet tietyillä yhteystyypeillä. Tätä kirjoitettaessa ainoa tuettu mekanismi näiden yhteyksien luomiseen on käyttää AWS-komentoriviliitäntä (AWS CLI).
Yhteyden määritelmän JSON-tiedosto
Kun muodostat yhteyden eri tietolähteisiin AWS Gluessa, sinun on ensin luotava JSON-tiedosto, joka määrittää yhteyden ominaisuudet. yhteysmääritystiedosto. Tämä tiedosto on ratkaisevan tärkeä AWS-liimayhteyden muodostamisessa, ja sen pitäisi sisältää kaikki tarvittavat konfiguraatiot tietolähteen käyttämiseksi. Turvallisuuden parhaiden käytäntöjen vuoksi on suositeltavaa käyttää Secrets Manageria arkaluonteisten tietojen, kuten salasanojen, turvalliseen tallentamiseen. Samaan aikaan muita yhteysominaisuuksia voidaan hallita suoraan AWS Glue -yhteyksien kautta. Tämä lähestymistapa varmistaa, että arkaluontoiset tunnistetiedot on suojattu, mutta silti yhteysmääritykset ovat käytettävissä ja hallittavissa.
Seuraavassa on esimerkki JSON-yhteysmäärittelystä:
Kun määrität AWS Glue -yhteyksiä tietolähteillesi, noudata muutamia tärkeitä ohjeita toiminnallisuuden ja turvallisuuden takaamiseksi:
- Ominaisuuksien ketjuttaminen - Sisällä
PythonPropertiesavain, varmista, että kaikki ominaisuudet ovat ketjutetut avainarvo-parit. On erittäin tärkeää välttää lainausmerkit oikein käyttämällä kenoviivaa () tarvittaessa. Tämä auttaa säilyttämään oikean muodon ja välttämään syntaksivirheet JSONissa. - Arkaluonteisten tietojen käsittely – Vaikka kaikki yhteysominaisuudet on mahdollista sisällyttää siihen
PythonProperties, ei ole suositeltavaa sisällyttää arkaluonteisia tietoja, kuten salasanoja, suoraan näihin ominaisuuksiin. Käytä sen sijaan Secrets Manageria arkaluonteisten tietojen käsittelyyn. Tämä lähestymistapa suojaa arkaluontoiset tietosi tallentamalla ne valvottuun ja salattuun ympäristöön erillään tärkeimmistä määritystiedostoista.
Luo AWS Glue -yhteys AWS CLI:n avulla
Kun olet sisällyttänyt kaikki tarvittavat kentät yhteysmäärittelyn JSON-tiedostoosi, olet valmis muodostamaan AWS Glue -yhteyden tietolähteellesi käyttämällä AWS CLI:tä ja seuraavaa komentoa:
Tämä komento käynnistää uuden AWS Glue -yhteyden JSON-tiedostossasi olevien määrittelyjen perusteella. Seuraava on nopea erittely komentokomponenteista:
- -alue – Tämä määrittää AWS-alueen, jossa AWS Glue -yhteytesi luodaan. On erittäin tärkeää valita alue, jossa tietolähteesi ja muut palvelusi sijaitsevat, jotta viive viivettä voidaan minimoida ja tietojen sijaintivaatimukset täyttyvät.
- –cli-input-json file:///path/to/file/connection/definition/file.json – Tämä parametri ohjaa AWS CLI:n lukemaan syöttömääritykset paikallisesta tiedostosta, joka sisältää yhteysmäärittelysi JSON-muodossa.
Sinun pitäisi pystyä luomaan AWS Glue -yhteyksiä edellisellä AWS CLI -komennolla Studio JupyterLab -päätteestäsi. Käytössä filee valikosta, valitse Uusi ja terminaali.

Jos create-connection komento suoritetaan onnistuneesti, sinun pitäisi nähdä tietolähteesi luettelossa SQL-selainruudussa. Jos et näe tietolähdettäsi luettelossa, valitse virkistää päivittääksesi välimuistin.

Luo Snowflake-yhteys
Tässä osiossa keskitymme Snowflake-tietolähteen integrointiin SageMaker Studioon. Snowflake-tilien, tietokantojen ja varastojen luominen ei kuulu tämän viestin piiriin. Aloita Snowflaken käytön katsomalla Lumihiutale käyttöopas. Tässä viestissä keskitymme luomaan Snowflake-määritelmän JSON-tiedoston ja muodostamaan Snowflake-tietolähdeyhteyden AWS-liimalla.
Luo Secrets Managerin salaisuus
Voit muodostaa yhteyden Snowflake-tiliisi joko käyttäjätunnuksella ja salasanalla tai yksityisillä avaimilla. Jotta voit muodostaa yhteyden käyttäjätunnuksella ja salasanalla, sinun on tallennettava tunnistetietosi turvallisesti Secrets Manageriin. Kuten aiemmin mainittiin, vaikka nämä tiedot on mahdollista upottaa PythonPropertiesin alle, ei ole suositeltavaa tallentaa arkaluontoisia tietoja pelkkänä tekstinä. Varmista aina, että arkaluonteisia tietoja käsitellään turvallisesti mahdollisten turvallisuusriskien välttämiseksi.
Tallentaaksesi tietoja Secrets Manageriin, suorita seuraavat vaiheet:
- Valitse Secrets Manager -konsolista Tallenna uusi salaisuus.
- varten Salainen tyyppi, valitse Muunlainen salaisuus.
- Valitse avain-arvo-parille plaintext ja kirjoita seuraava:
- Anna salaisuudellesi nimi, esim
sm-sql-snowflake-secret. - Jätä muut asetukset oletusasetuksiksi tai muokkaa niitä tarvittaessa.
- Luo salaisuus.
Luo AWS-liimaliitäntä Snowflakelle
Kuten aiemmin mainittiin, AWS Glue -liitännät ovat välttämättömiä minkä tahansa SageMaker Studion yhteyden käyttämiseen. Löydät luettelon kaikki lumihiutaleen tuetut yhteysominaisuudet. Seuraava on esimerkkiyhteysmäärittelyn JSON Snowflakelle. Korvaa paikkamerkkiarvot sopivilla arvoilla ennen kuin tallennat sen levylle:
Luo AWS Glue -yhteysobjekti Snowflake-tietolähteelle käyttämällä seuraavaa komentoa:
Tämä komento luo SQL-selainruutuun uuden lumihiutale-tietolähdeyhteyden, joka on selattavissa, ja voit suorittaa sitä vastaan SQL-kyselyitä JupyterLab-muistikirjan solusta.
Luo Amazon Redshift -yhteys
Amazon Redshift on täysin hallittu, petatavun mittakaavainen tietovarastopalvelu, joka yksinkertaistaa ja pienentää kaikkien tietojesi analysointikustannuksia tavallisella SQL:llä. Amazon Redshift -yhteyden luontimenettely vastaa tarkasti Snowflake-yhteyden luomista.
Luo Secrets Managerin salaisuus
Samoin kuin Snowflake-asetuksissa, jotta voit muodostaa yhteyden Amazon Redshiftiin käyttäjätunnuksella ja salasanalla, sinun on tallennettava salaisuudet turvallisesti Secrets Manageriin. Suorita seuraavat vaiheet:
- Valitse Secrets Manager -konsolista Tallenna uusi salaisuus.
- varten Salainen tyyppi, valitse Amazon Redshift -klusterin valtuustiedot.
- Anna tunnistetiedot, joilla kirjaudut sisään, jotta voit käyttää Amazon Redshiftiä tietolähteenä.
- Valitse salaisuuksiin liittyvä Redshift-klusteri.
- Anna salaisuudelle nimi, esim
sm-sql-redshift-secret. - Jätä muut asetukset oletusasetuksiksi tai muokkaa niitä tarvittaessa.
- Luo salaisuus.
Seuraamalla näitä vaiheita varmistat, että yhteystietojasi käsitellään turvallisesti ja käytät AWS:n vahvoja suojausominaisuuksia arkaluonteisten tietojen tehokkaaseen hallintaan.
Luo AWS-liimayhteys Amazon Redshiftille
Jos haluat muodostaa yhteyden Amazon Redshiftin kanssa JSON-määritelmän avulla, täytä tarvittavat kentät ja tallenna seuraavat JSON-kokoonpanot levylle:
Voit luoda AWS Glue -yhteysobjektin Redshift-tietolähteelle käyttämällä seuraavaa AWS CLI -komentoa:
Tämä komento luo yhteyden AWS Glue -sovellukseen, joka on linkitetty Redshift-tietolähteeseen. Jos komento suoritetaan onnistuneesti, näet Redshift-tietolähteesi SageMaker Studio JupyterLab -muistikirjassa, valmiina SQL-kyselyjen suorittamiseen ja tietojen analysointiin.

Luo Athena-yhteys
Athena on AWS:n täysin hallittu SQL-kyselypalvelu, joka mahdollistaa Amazon S3:een tallennettujen tietojen analysoinnin tavallisella SQL:llä. Jos haluat määrittää Athena-yhteyden tietolähteeksi JupyterLab-muistikirjan SQL-selaimessa, sinun on luotava Athena-malliyhteysmäärittelyn JSON. Seuraava JSON-rakenne määrittää tarvittavat tiedot Athena-yhteyden muodostamiseksi määrittämällä tietoluettelon, S3-vaihehakemiston ja alueen:
Voit luoda AWS Glue -yhteysobjektin Athena-tietolähteelle käyttämällä seuraavaa AWS CLI -komentoa:
Jos komento onnistuu, voit käyttää Athenen tietoluetteloa ja taulukoita suoraan SageMaker Studio JupyterLab -muistikirjan SQL-selaimesta.
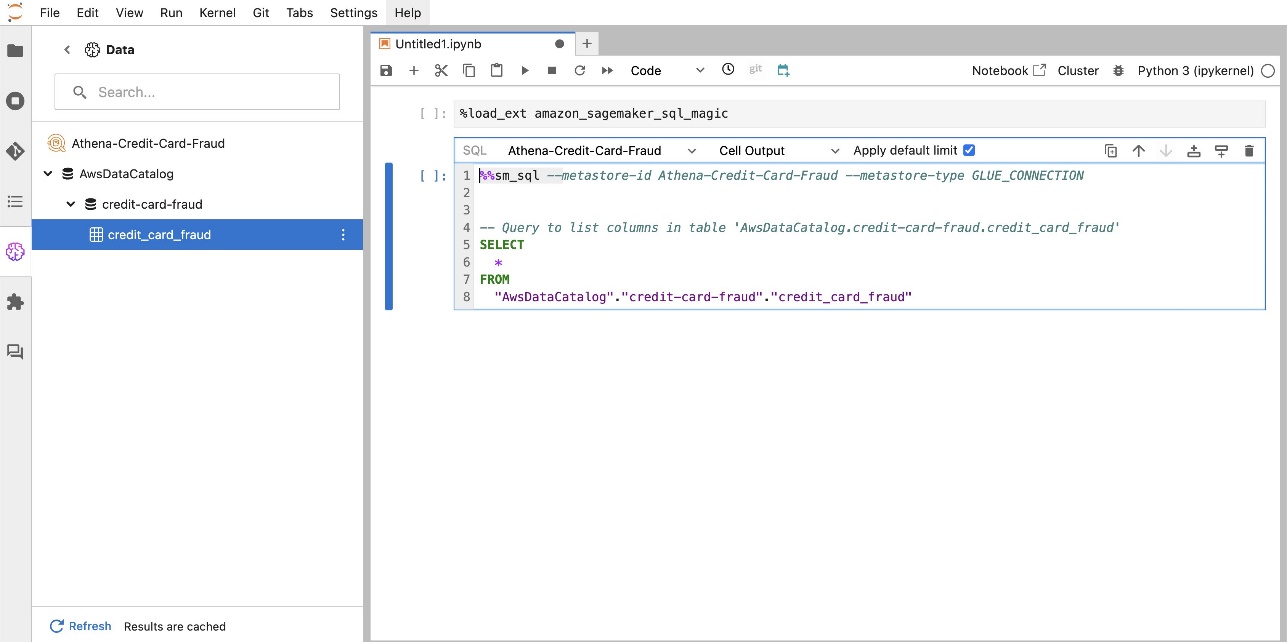
Pyydä tietoja useista lähteistä
Jos sinulla on useita tietolähteitä integroituna SageMaker Studioon sisäänrakennetun SQL-selaimen ja muistikirjan SQL-ominaisuuden kautta, voit nopeasti suorittaa kyselyitä ja vaihtaa vaivattomasti tietolähteen taustaohjelmien välillä muistikirjan seuraavissa soluissa. Tämä ominaisuus mahdollistaa saumattoman siirtymisen eri tietokantojen tai tietolähteiden välillä analyysin työnkulun aikana.
Voit suorittaa kyselyitä erilaisille tietolähteiden taustaohjelmille ja tuoda tulokset suoraan Python-tilaan lisäanalyysiä tai visualisointia varten. Tätä helpottaa %%sm_sql magic-komento saatavilla SageMaker Studion muistikirjoissa. SQL-kyselyn tulosten tulostamiseksi pandas DataFrameen on kaksi vaihtoehtoa:
- Valitse tulostetyyppi kannettavan tietokoneen solun työkalupalkista Datakehys ja nimeä DataFrame-muuttujasi
- Liitä seuraava parametri omaan
%%sm_sqlkomento:
Seuraava kaavio havainnollistaa tätä työnkulkua ja esittelee, kuinka voit vaivattomasti suorittaa kyselyitä eri lähteistä myöhemmissä muistikirjan soluissa sekä kouluttaa SageMaker-mallia käyttämällä koulutustöitä tai suoraan muistikirjassa paikallista laskentaa käyttämällä. Lisäksi kaaviossa korostetaan, kuinka SageMaker Studion sisäänrakennettu SQL-integraatio yksinkertaistaa purku- ja rakentamisprosesseja suoraan JupyterLab-muistikirjan solun tutussa ympäristössä.
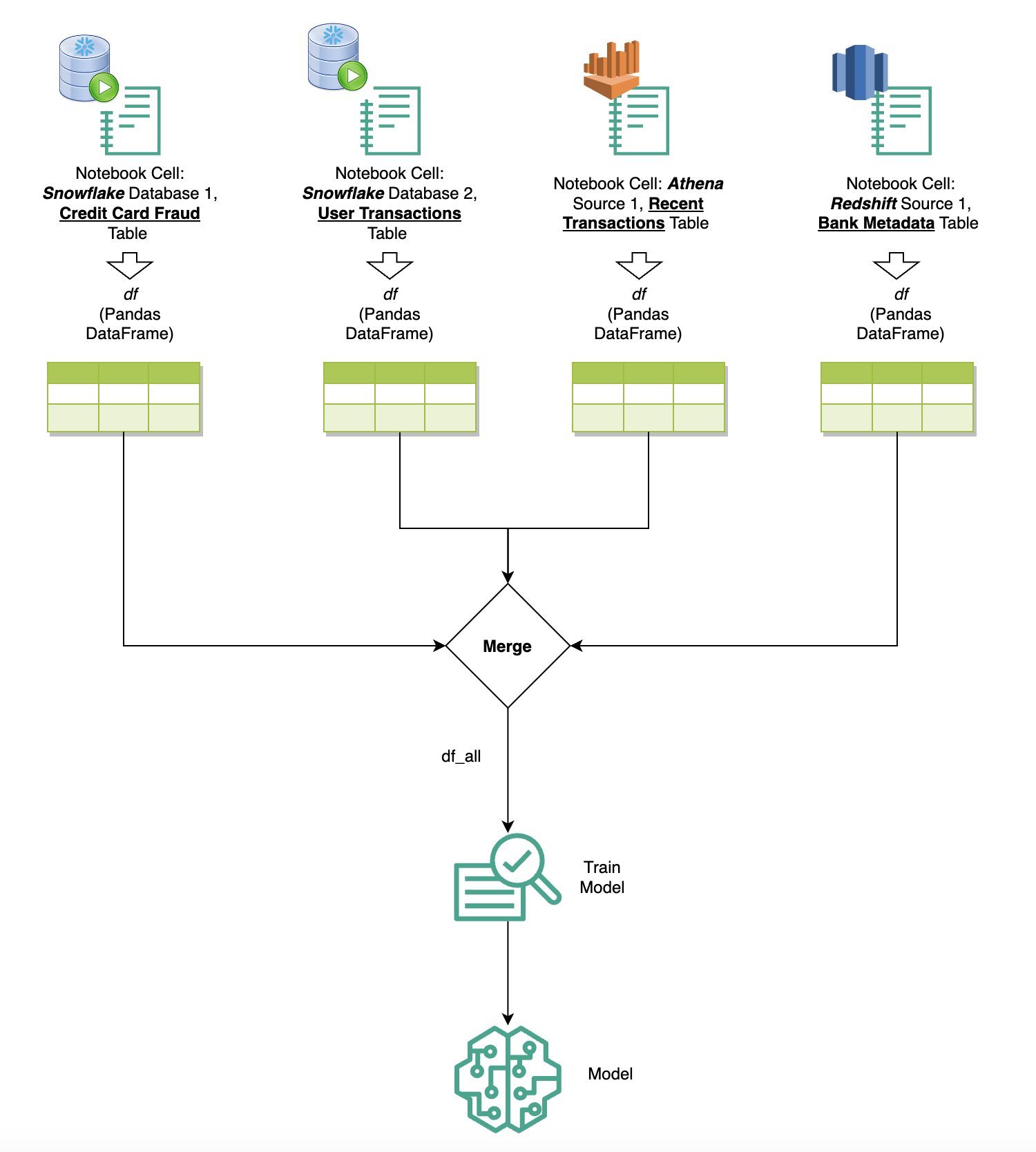
Teksti SQL:ksi: Luonnollisen kielen käyttäminen kyselyn luomisen parantamiseen
SQL on monimutkainen kieli, joka edellyttää tietokantojen, taulukoiden, syntaksien ja metatietojen ymmärtämistä. Nykyään generatiivisen tekoälyn (AI) avulla voit kirjoittaa monimutkaisia SQL-kyselyitä ilman syvällistä SQL-kokemusta. LLM:ien edistyminen on vaikuttanut merkittävästi luonnollisen kielen käsittelyyn (NLP) perustuvaan SQL:n luomiseen, mikä mahdollistaa tarkkojen SQL-kyselyjen luomisen luonnollisen kielen kuvauksista – tekniikkaa, jota kutsutaan tekstistä SQL:ksi. On kuitenkin olennaista tunnustaa ihmiskielen ja SQL:n väliset luontaiset erot. Ihmisen kieli voi joskus olla moniselitteistä tai epätäsmällistä, kun taas SQL on jäsenneltyä, selkeää ja yksiselitteistä. Tämän aukon kurominen ja luonnollisen kielen tarkka muuntaminen SQL-kyselyiksi voi olla valtava haaste. Kun LLM:t saavat asianmukaisia kehotteita, ne voivat auttaa kuromaan umpeen tämän aukon ymmärtämällä ihmiskielen taustalla olevan tarkoituksen ja luomalla tarkkoja SQL-kyselyjä sen mukaisesti.
SageMaker Studion kannettavan tietokoneen SQL-kyselyominaisuuden julkaisun myötä SageMaker Studio tekee tietokantojen ja skeemojen tarkastamisen sekä SQL-kyselyjen laatimisen, suorittamisen ja virheenkorjauksen yksinkertaiseksi poistumatta Jupyter-muistikirjan IDE:stä. Tässä osiossa tarkastellaan, kuinka edistyneiden LLM:ien tekstistä SQL:ksi -ominaisuudet voivat helpottaa SQL-kyselyjen luomista käyttämällä luonnollista kieltä Jupyter-muistikirjoissa. Käytämme uusinta Text-to-SQL-mallia defog/sqlcoder-7b-2 yhdessä Jupyter AI:n kanssa, generatiivisen AI-avustajan kanssa, joka on erityisesti suunniteltu Jupyter-kannettaville, luomaan monimutkaisia SQL-kyselyitä luonnollisesta kielestä. Käyttämällä tätä edistynyttä mallia voimme vaivattomasti ja tehokkaasti luoda monimutkaisia SQL-kyselyitä luonnollisella kielellä, mikä parantaa SQL-kokemustamme kannettavissa tietokoneissa.
Kannettavan prototyyppien tekeminen Hugging Face Hubilla
Prototyyppien luomisen aloittamiseksi tarvitset seuraavat:
- GitHub-koodi – Tässä osiossa esitetty koodi on saatavilla seuraavassa GitHub repo ja viittaamalla esimerkki muistikirja.
- JupyterLab Space – Pääsy SageMaker Studio JupyterLab Spaceen, jota tukevat GPU-pohjaiset esiintymät, on välttämätöntä. Varten
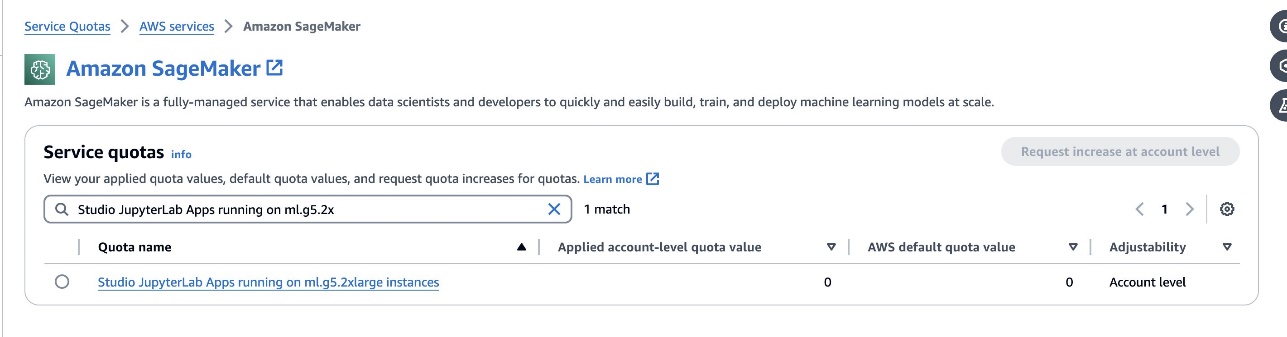
defog/sqlcoder-7b-2mallissa suositellaan 7B-parametrimallia, jossa käytetään ml.g5.2xlarge-instanssia. Vaihtoehtoja, kutendefog/sqlcoder-70b-alpha taidefog/sqlcoder-34b-alphaovat myös käyttökelpoisia luonnollisen kielen muuntamiseen SQL:ksi, mutta prototyyppien tekemiseen voidaan tarvita suurempia ilmentymätyyppejä. Varmista, että sinulla on kiintiö GPU-tuetun ilmentymän käynnistämiseen siirtymällä Service Quota -konsoliin, etsimällä SageMakeria ja etsimälläStudio JupyterLab Apps running on <instance type>.
Käynnistä uusi GPU-tuki JupyterLab Space SageMaker Studiosta. On suositeltavaa luoda uusi JupyterLab Space, jossa on vähintään 75 Gt Amazonin elastisten lohkojen myymälä (Amazon EBS) tallennustila 7B-parametrimallille.

- Hugging Face Hub – Jos SageMaker Studio -verkkotunnuksellasi on pääsy mallien lataamiseen osoitteesta Hugging Face Hub, voit käyttää
AutoModelForCausalLMluokasta alkaen halaavat kasvot/muuntajat ladataksesi malleja automaattisesti ja kiinnittääksesi ne paikallisiin grafiikkasuorittimiisi. Mallin painot tallennetaan paikallisen koneen välimuistiin. Katso seuraava koodi:
Kun malli on ladattu kokonaan ja ladattu muistiin, sinun pitäisi havaita paikallisen koneen GPU-käytön lisääntyminen. Tämä osoittaa, että malli käyttää aktiivisesti GPU-resursseja laskentatehtäviin. Voit varmistaa tämän omassa JupyterLab-tilassasi suorittamalla nvidia-smi (kertanäytölle) tai nvidia-smi —loop=1 (toistaa joka sekunti) JupyterLab-päätteestäsi.
Text-to-SQL-mallit ymmärtävät erinomaisesti käyttäjän pyynnön tarkoituksen ja kontekstin, vaikka käytetty kieli on keskustelukielinen tai moniselitteinen. Prosessi sisältää luonnollisen kielen syötteiden kääntämisen oikeiksi tietokantaskeeman elementeiksi, kuten taulukoiden nimiksi, sarakkeiden nimiksi ja ehdoksi. Valmis tekstistä SQL-muotoon -malli ei kuitenkaan luonnostaan tunne tietovarastosi rakennetta, tiettyjä tietokantaskeemoja tai pysty tulkitsemaan tarkasti taulukon sisältöä pelkästään sarakkeiden nimien perusteella. Jotta näitä malleja voitaisiin käyttää tehokkaasti käytännöllisten ja tehokkaiden SQL-kyselyjen luomiseen luonnollisesta kielestä, on tarpeen mukauttaa SQL-tekstin luontimalli tiettyyn varastotietokantaskeemaasi. Tätä sopeutumista helpotetaan käyttämällä LLM kehottaa. Seuraava on suositeltu kehotemalli defog/sqlcoder-7b-2 Text-to-SQL-mallille, jaettu neljään osaan:
- Tehtävä – Tässä osiossa tulisi määrittää korkean tason tehtävä, joka mallin tulee suorittaa. Sen tulisi sisältää tietokannan taustajärjestelmän tyyppi (kuten Amazon RDS, PostgreSQL tai Amazon Redshift), jotta malli tulee tietoiseksi kaikista vivahteellisista syntaktisista eroista, jotka voivat vaikuttaa lopullisen SQL-kyselyn luomiseen.
- Ohjeet – Tässä osiossa tulisi määritellä mallin tehtävärajat ja toimialuetietoisuus, ja se voi sisältää muutamia esimerkkejä, jotka ohjaavat mallia luomaan hienosäädettyjä SQL-kyselyjä.
- Tietokantakaavio – Tässä osiossa tulee esitellä varastotietokantakaaviot yksityiskohtaisesti ja hahmotella taulukoiden ja sarakkeiden väliset suhteet, jotta mallia voidaan ymmärtää tietokannan rakenteen ymmärtämisessä.
- Vastaus – Tämä osa on varattu mallille, joka lähettää SQL-kyselyvastauksen luonnollisen kielen syötteeseen.
Esimerkki tässä osiossa käytetystä tietokantaskeemasta ja kehotteesta on saatavilla osoitteessa GitHub Repo.
Nopea suunnittelu ei ole vain kysymysten tai lausuntojen muodostamista; se on vivahteikas taide ja tiede, joka vaikuttaa merkittävästi vuorovaikutuksen laatuun tekoälymallin kanssa. Tapa, jolla kirjoitat kehotteen, voi vaikuttaa syvästi tekoälyn vastauksen luonteeseen ja hyödyllisyyteen. Tämä taito on avainasemassa tekoälyn vuorovaikutuksen potentiaalin maksimoinnissa, erityisesti monimutkaisissa tehtävissä, jotka vaativat erityistä ymmärrystä ja yksityiskohtaisia vastauksia.
On tärkeää, että sinulla on mahdollisuus rakentaa ja testata nopeasti mallin vastaus tietylle kehotteelle ja optimoida kehote vastauksen perusteella. JupyterLab-muistikirjat tarjoavat mahdollisuuden vastaanottaa välitöntä mallipalautetta paikallisella laskennalla toimivasta mallista ja optimoida kehotteen ja säätää mallin vastetta edelleen tai muuttaa mallia kokonaan. Tässä viestissä käytämme SageMaker Studio JupyterLab -kannettavaa ml.g5.2xlargen NVIDIA A10G 24 Gt:n grafiikkasuorittimella suorittamaan tekstistä SQL:ksi mallipäätelmiä kannettavassa tietokoneessa ja rakentamaan interaktiivisesti mallikehotetta, kunnes mallin vastaus on riittävästi viritetty tarjoamaan vastaukset, jotka voidaan suorittaa suoraan JupyterLabin SQL-soluissa. Mallin päättelyn suorittamiseksi ja mallin vastausten samanaikaiseksi suoratoistoksi käytämme yhdistelmää model.generate ja TextIteratorStreamer seuraavan koodin mukaisesti:
Mallin tuotos voidaan koristella SageMaker SQL -magialla %%sm_sql ..., jonka avulla JupyterLab-muistikirja voi tunnistaa solun SQL-soluksi.
Isännöi Text-to-SQL-malleja SageMaker-päätepisteinä
Prototyyppivaiheen lopussa olemme valinneet ensisijaisen Text-to-SQL LLM:n, tehokkaan kehotteen muodon ja sopivan ilmentymän tyypin mallin isännöintiin (joko yhden tai useamman GPU:n). SageMaker helpottaa mukautettujen mallien skaalautuvaa isännöintiä SageMaker-päätepisteiden avulla. Nämä päätepisteet voidaan määrittää erityisten kriteerien mukaan, mikä mahdollistaa LLM:ien käytön päätepisteinä. Tämän ominaisuuden avulla voit skaalata ratkaisun laajemmalle yleisölle, jolloin käyttäjät voivat luoda SQL-kyselyitä luonnollisen kielen syötteistä käyttämällä mukautettuja isännöityjä LLM:itä. Seuraava kaavio havainnollistaa tätä arkkitehtuuria.

Jotta voit isännöidä LLM:täsi SageMaker-päätepisteenä, luot useita artefakteja.
Ensimmäinen artefakti on mallipainot. SageMaker Deep Java Library (DJL) -palvelu säilöjen avulla voit määrittää konfiguraatioita metan kautta palvelevat.ominaisuudet tiedosto, jonka avulla voit ohjata mallien hankintaa – joko suoraan Hugging Face Hubista tai lataamalla malliesineet Amazon S3:sta. Jos määrittelet model_id=defog/sqlcoder-7b-2, DJL Serving yrittää ladata tämän mallin suoraan Hugging Face Hubista. Saatat kuitenkin veloittaa verkon sisään-/ulostulomaksuja aina, kun päätepiste otetaan käyttöön tai skaalataan joustavasti. Näiden maksujen välttämiseksi ja mahdollisesti malliesineiden lataamisen nopeuttamiseksi on suositeltavaa ohittaa käyttö model_id in serving.properties ja tallenna mallin painot S3-artefakteina ja määritä ne vain s3url=s3://path/to/model/bin.
Mallin (sen tokenisaattorin kanssa) tallentaminen levylle ja sen lataaminen Amazon S3:een voidaan suorittaa vain muutamalla koodirivillä:
Käytät myös tietokantakehotetiedostoa. Tässä asennuksessa tietokantakehote koostuu Task, Instructions, Database Schemaja Answer sections. Nykyiselle arkkitehtuurille varaamme erillisen kehotetiedoston jokaiselle tietokantaskeemalle. Tämä asetus voidaan kuitenkin laajentaa joustavasti sisältämään useita tietokantoja kehotetiedostoa kohden, jolloin malli voi suorittaa yhdistelmäliitoksia saman palvelimen tietokannoista. Prototyyppivaiheessa tallennamme tietokantakehotteen tekstitiedostona nimeltä <Database-Glue-Connection-Name>.prompt, Jossa Database-Glue-Connection-Name vastaa JupyterLab-ympäristössäsi näkyvää yhteyden nimeä. Esimerkiksi tämä viesti viittaa Snowflake-yhteyteen nimeltä Airlines_Dataset, joten tietokannan kehotetiedosto on nimetty Airlines_Dataset.prompt. Tämä tiedosto tallennetaan sitten Amazon S3:lle, minkä jälkeen mallin käyttölogiikka lukee ja tallentaa sen välimuistiin.
Lisäksi tämä arkkitehtuuri sallii tämän päätepisteen valtuutettujen käyttäjien määrittää, tallentaa ja luoda luonnollisen kielen SQL-kyselyille ilman, että mallia tarvitsee asentaa useita kertoja uudelleen. Käytämme seuraavaa esimerkki tietokantakehotteesta tekstistä SQL:ksi -toiminnallisuuden esittelyyn.
Seuraavaksi luot mukautetun mallin palvelulogiikan. Tässä osiossa esität mukautetun päättelylogiikan nimeltä malli.py. Tämä komentosarja on suunniteltu optimoimaan Text-to-SQL-palveluidemme suorituskyky ja integrointi:
- Määritä tietokantakehotetiedostojen välimuistin logiikka – Viiveen minimoimiseksi otamme käyttöön mukautetun logiikan tietokantakehotetiedostojen lataamiseen ja tallentamiseen välimuistiin. Tämä mekanismi varmistaa, että kehotteet ovat helposti saatavilla, mikä vähentää toistuviin latauksiin liittyviä yleiskustannuksia.
- Määritä mukautetun mallin päättelylogiikka – Päättelynopeuden parantamiseksi teksti-SQL-mallimme ladataan float16-tarkkuusmuodossa ja muunnetaan sitten DeepSpeed-malliksi. Tämä vaihe mahdollistaa tehokkaamman laskennan. Lisäksi tässä logiikassa määrität, mitä parametreja käyttäjät voivat säätää johtopäätöskutsujen aikana räätälöidäkseen toiminnallisuutta tarpeidensa mukaan.
- Määritä mukautettu tulo- ja lähtölogiikka – Selkeiden ja räätälöityjen syöttö-/tulostusmuotojen luominen on välttämätöntä sujuvan integroinnin kannalta myöhempien sovellusten kanssa. Yksi tällainen sovellus on JupyterAI, jota käsittelemme seuraavassa osiossa.
Lisäksi tarjoamme a serving.properties tiedosto, joka toimii yleisenä konfigurointitiedostona malleille, joita isännöidään DJL-palvelulla. Lisätietoja on kohdassa Kokoonpanot ja asetukset.
Lopuksi voit myös sisällyttää a requirements.txt tiedosto määrittääksesi lisämoduuleja, joita tarvitaan päätelmien tekemiseen, ja pakata kaikki tarball-tiedostoksi käyttöönottoa varten.
Katso seuraava koodi:
Integroi päätepisteesi SageMaker Studio Jupyter AI -avustajan kanssa
Jupyter AI on avoimen lähdekoodin työkalu, joka tuo generatiivisen tekoälyn Jupyter-kannettaviin ja tarjoaa vankan ja käyttäjäystävällisen alustan generatiivisten tekoälymallien tutkimiseen. Se parantaa JupyterLab- ja Jupyter-kannettavien tuottavuutta tarjoamalla ominaisuuksia, kuten %%ai-taika generatiivisen tekoälyn leikkikentän luomiseen kannettavien sisällä, JupyterLabin natiivi chat-käyttöliittymän vuorovaikutukseen tekoälyn kanssa keskusteluapulaisena sekä tukea laajalle valikoimalle LLM:itä palveluntarjoajat pitävät Amazon Titan, AI21, Anthropic, Cohere ja Hugging Face tai hallinnoidut palvelut, kuten Amazonin kallioperä ja SageMaker-päätepisteet. Tässä viestissä käytämme Jupyter AI:n valmiita integraatiota SageMaker-päätepisteiden kanssa tuodaksemme tekstistä SQL:ksi -ominaisuuden JupyterLab-muistikirjoihin. Jupyter AI -työkalu tulee esiasennettuna kaikkiin SageMaker Studio JupyterLab Spaces -tiloihin, joita tukee SageMaker Distribution -kuvat; loppukäyttäjien ei tarvitse tehdä lisämäärityksiä aloittaakseen Jupyter AI -laajennuksen käytön SageMaker-isännöidyn päätepisteen kanssa. Tässä osiossa käsittelemme kahta tapaa käyttää integroitua Jupyter AI -työkalua.
Jupyter AI muistikirjan sisällä taikuuden avulla
Jupyter AI:t %%ai magic-komennon avulla voit muuttaa SageMaker Studio JupyterLab -muistikirjasi toistettavaksi generatiiviseksi tekoälyympäristöksi. Aloita AI Magicsin käyttö varmistamalla, että olet ladannut käytettäväksi jupyter_ai_magics-laajennuksen %%ai taikuutta ja lisäksi lataamista amazon_sagemaker_sql_magic käyttää %%sm_sql taika:
Voit soittaa SageMaker-päätepisteeseen muistikirjastasi käyttämällä %%ai magic-komento, anna seuraavat parametrit ja rakenna komento seuraavasti:
- -alueen nimi – Määritä alue, jossa päätepisteesi on otettu käyttöön. Tämä varmistaa, että pyyntö reititetään oikeaan maantieteelliseen sijaintiin.
- -pyyntö-skeema – Sisällytä syöttötietojen skeema. Tämä skeema määrittelee odotetun muodon ja syöttötietojen tyypit, joita mallisi tarvitsee pyynnön käsittelyyn.
- -vastauspolku – Määritä polku vastausobjektissa, jossa mallisi tulos sijaitsee. Tätä polkua käytetään poimimaan asiaankuuluvat tiedot mallisi palauttamasta vastauksesta.
- -f (valinnainen) - Tämä on tulosteen muotoilija lippu, joka osoittaa mallin palauttaman tulosteen tyypin. Jos tuloste on Jupyter-muistikirjan yhteydessä koodi, tämä lippu tulee asettaa vastaavasti tulosteen muotoilemiseksi suoritettavaksi koodiksi Jupyter-muistikirjan solun yläosassa, jota seuraa vapaan tekstin syöttöalue käyttäjän vuorovaikutusta varten.
Esimerkiksi Jupyter-muistikirjan solussa oleva komento saattaa näyttää seuraavalta koodilta:
Jupyter AI chat-ikkuna
Vaihtoehtoisesti voit olla vuorovaikutuksessa SageMaker-päätepisteiden kanssa sisäänrakennetun käyttöliittymän kautta, mikä yksinkertaistaa kyselyjen luomista tai dialogia. Ennen kuin aloitat keskustelun SageMaker-päätepisteesi kanssa, määritä SageMaker-päätepisteen asianmukaiset asetukset Jupyter AI:ssä seuraavan kuvakaappauksen mukaisesti.
 |
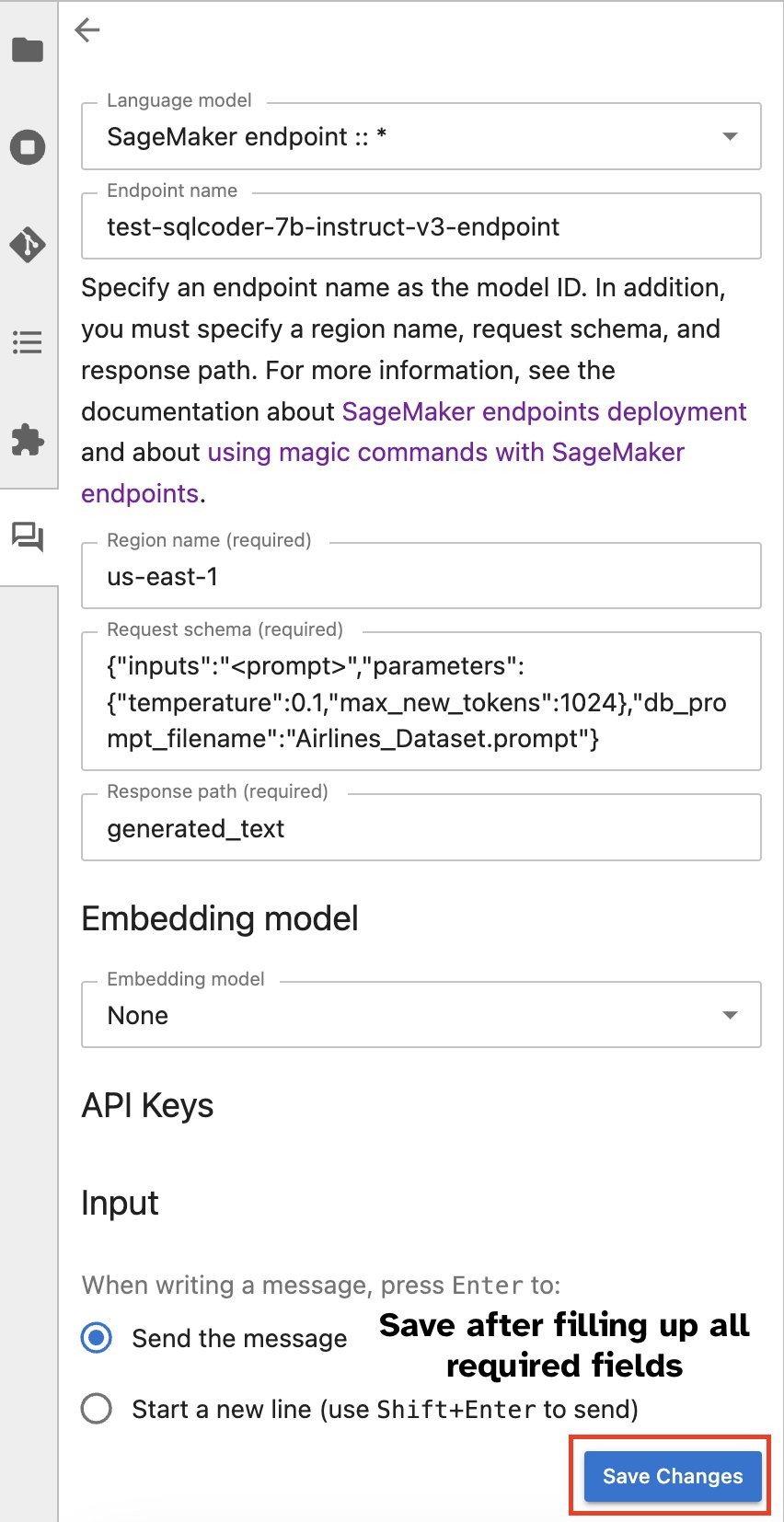 |
Yhteenveto
SageMaker Studio yksinkertaistaa ja virtaviivaistaa nyt datatutkijan työnkulkua integroimalla SQL-tuen JupyterLab-muistikirjoihin. Näin datatieteilijät voivat keskittyä tehtäviinsä ilman, että heidän tarvitsee hallita useita työkaluja. Lisäksi SageMaker Studion uusi sisäänrakennettu SQL-integraatio mahdollistaa datapersonoiden vaivattomasti generoida SQL-kyselyitä käyttämällä luonnollisen kielen tekstiä syötteenä, mikä nopeuttaa työnkulkuaan.
Kehotamme sinua tutkimaan näitä ominaisuuksia SageMaker Studiossa. Lisätietoja on kohdassa Valmistele tiedot SQL:llä Studiossa.
Liite
Ota SQL-selain ja muistikirjan SQL-solu käyttöön mukautetuissa ympäristöissä
Jos et käytä SageMaker Distribution -kuvaa tai Distribution-otoksia 1.5 tai vanhempi, suorita seuraavat komennot ottaaksesi SQL-selausominaisuuden käyttöön JupyterLab-ympäristössäsi:
Siirrä SQL-selainwidget
JupyterLab-widgetit mahdollistavat siirron. Halutessasi voit siirtää widgetejä JupyterLab-widget-ruudun kummallekin puolelle. Halutessasi voit siirtää SQL-widgetin suunnan sivupalkin vastakkaiselle puolelle (oikealta vasemmalle) napsauttamalla widgetin kuvaketta hiiren kakkospainikkeella ja valitsemalla Vaihda sivupalkin puolta.
 |
 |
Tietoja kirjoittajista
 Pranav Murthy on AI/ML Specialist Solutions -arkkitehti AWS:ssä. Hän keskittyy auttamaan asiakkaita rakentamaan, kouluttamaan, ottamaan käyttöön ja siirtämään koneoppimistyökuormia SageMakeriin. Aiemmin hän työskenteli puolijohdeteollisuudessa kehittäen suuria tietokonenäön (CV) ja luonnollisen kielen prosessointimalleja (NLP) puolijohdeprosessien parantamiseksi käyttämällä uusinta ML-tekniikkaa. Vapaa-ajallaan hän pelaa shakkia ja matkustaa. Löydät Pranavin osoitteesta LinkedIn.
Pranav Murthy on AI/ML Specialist Solutions -arkkitehti AWS:ssä. Hän keskittyy auttamaan asiakkaita rakentamaan, kouluttamaan, ottamaan käyttöön ja siirtämään koneoppimistyökuormia SageMakeriin. Aiemmin hän työskenteli puolijohdeteollisuudessa kehittäen suuria tietokonenäön (CV) ja luonnollisen kielen prosessointimalleja (NLP) puolijohdeprosessien parantamiseksi käyttämällä uusinta ML-tekniikkaa. Vapaa-ajallaan hän pelaa shakkia ja matkustaa. Löydät Pranavin osoitteesta LinkedIn.
 Varun Shah on ohjelmistosuunnittelija, joka työskentelee Amazon SageMaker Studiossa Amazon Web Services -palvelussa. Hän on keskittynyt rakentamaan interaktiivisia ML - ratkaisuja , jotka yksinkertaistavat tietojenkäsittelyä ja tietojen valmistelua . Vapaa-ajallaan Varun harrastaa ulkoilua, kuten vaellusta ja hiihtoa, ja on aina valmis löytämään uusia, jännittäviä paikkoja.
Varun Shah on ohjelmistosuunnittelija, joka työskentelee Amazon SageMaker Studiossa Amazon Web Services -palvelussa. Hän on keskittynyt rakentamaan interaktiivisia ML - ratkaisuja , jotka yksinkertaistavat tietojenkäsittelyä ja tietojen valmistelua . Vapaa-ajallaan Varun harrastaa ulkoilua, kuten vaellusta ja hiihtoa, ja on aina valmis löytämään uusia, jännittäviä paikkoja.
 Sumedha Swamy on päätuotepäällikkö Amazon Web Services -palvelussa, jossa hän johtaa SageMaker Studio -tiimiä sen tehtävässä kehittää tietotieteeseen ja koneoppimiseen parhaiten sopiva IDE. Hän on omistanut viimeiset 15 vuotta koneoppimiseen perustuvien kuluttaja- ja yritystuotteiden rakentamiseen.
Sumedha Swamy on päätuotepäällikkö Amazon Web Services -palvelussa, jossa hän johtaa SageMaker Studio -tiimiä sen tehtävässä kehittää tietotieteeseen ja koneoppimiseen parhaiten sopiva IDE. Hän on omistanut viimeiset 15 vuotta koneoppimiseen perustuvien kuluttaja- ja yritystuotteiden rakentamiseen.
 Bosco Albuquerque on AWS:n vanhempi kumppaniratkaisuarkkitehti ja hänellä on yli 20 vuoden kokemus tietokanta- ja analytiikkatuotteiden parissa työskentelystä yritystietokantatoimittajilta ja pilvipalveluntarjoajilta. Hän on auttanut teknologiayrityksiä suunnittelemaan ja toteuttamaan data-analytiikkaratkaisuja ja -tuotteita.
Bosco Albuquerque on AWS:n vanhempi kumppaniratkaisuarkkitehti ja hänellä on yli 20 vuoden kokemus tietokanta- ja analytiikkatuotteiden parissa työskentelystä yritystietokantatoimittajilta ja pilvipalveluntarjoajilta. Hän on auttanut teknologiayrityksiä suunnittelemaan ja toteuttamaan data-analytiikkaratkaisuja ja -tuotteita.
- SEO-pohjainen sisällön ja PR-jakelu. Vahvista jo tänään.
- PlatoData.Network Vertical Generatiivinen Ai. Vahvista itseäsi. Pääsy tästä.
- PlatoAiStream. Web3 Intelligence. Tietoa laajennettu. Pääsy tästä.
- PlatoESG. hiili, CleanTech, energia, ympäristö, Aurinko, Jätehuolto. Pääsy tästä.
- PlatonHealth. Biotekniikan ja kliinisten kokeiden älykkyys. Pääsy tästä.
- Lähde: https://aws.amazon.com/blogs/machine-learning/explore-data-with-ease-using-sql-and-text-to-sql-in-amazon-sagemaker-studio-jupyterlab-notebooks/

