Perusmallit (FM:t) ovat suuria koneoppimismalleja (ML), jotka on koulutettu laajalle kirjolle merkitsemättömiä ja yleisiä tietojoukkoja. Kuten nimestä voi päätellä, FM:t tarjoavat perustan erikoistuneiden loppupään sovellusten rakentamiselle, ja ne ovat ainutlaatuisia sopeutumiskyvyltään. Hän osaa suorittaa monenlaisia tehtäviä, kuten luonnollisen kielen käsittelyä, kuvien luokittelua, trendien ennustamista, tunteiden analysointia ja kysymyksiin vastaamista. Tämä mittakaava ja yleiskäyttöinen mukautuvuus tekevät FM:istä eron perinteisistä ML-malleista. FM:t ovat multimodaalisia; ne toimivat erilaisten tietotyyppien, kuten tekstin, videon, äänen ja kuvien, kanssa. Suuret kielimallit (LLM) ovat FM-tyyppiä, ja ne ovat valmiiksi koulutettuja käyttämään suuria määriä tekstidataa, ja niissä on tyypillisesti sovellusten käyttötarkoituksia, kuten tekstin luominen, älykkäät chatbotit tai yhteenveto.
Datan suoratoisto helpottaa monipuolisen ja ajantasaisen tiedon jatkuvaa kulkua, mikä parantaa mallien kykyä mukautua ja tuottaa tarkempia, kontekstuaalisesti relevantteja tuloksia. Tämä suoratoistodatan dynaaminen integrointi mahdollistaa generatiivinen tekoäly sovelluksia reagoida nopeasti muuttuviin olosuhteisiin, parantaa niiden sopeutumiskykyä ja yleistä suorituskykyä erilaisissa tehtävissä.
Ymmärtääksesi tämän paremmin, kuvittele chatbot, joka auttaa matkustajia varaamaan matkansa. Tässä skenaariossa chatbot tarvitsee reaaliaikaisen pääsyn lentoyhtiöiden luetteloon, lennon tilaan, hotellien luetteloon, viimeisimpiin hintamuutoksiin ja muihin. Nämä tiedot tulevat yleensä kolmansilta osapuolilta, ja kehittäjien on löydettävä tapa saada nämä tiedot ja käsitellä tietojen muutokset sitä mukaa kuin niitä tapahtuu.
Eräkäsittely ei sovi tähän skenaarioon parhaiten. Kun tiedot muuttuvat nopeasti, niiden eräkäsittely voi johtaa vanhentuneiden tietojen käyttämiseen chatbotissa, mikä antaa asiakkaalle virheellistä tietoa, mikä vaikuttaa asiakaskokemukseen. Stream-käsittelyn avulla chatbot voi kuitenkin päästä käsiksi reaaliaikaiseen dataan ja mukautua saatavuuden ja hinnan muutoksiin, mikä antaa parhaan opastuksen asiakkaalle ja parantaa asiakaskokemusta.
Toinen esimerkki on tekoälyyn perustuva havainnointi- ja seurantaratkaisu, jossa FM-laitteet valvovat järjestelmän reaaliaikaisia sisäisiä mittareita ja tuottavat hälytyksiä. Kun malli havaitsee poikkeaman tai epänormaalin mittarin arvon, sen tulee antaa välittömästi hälytys ja ilmoittaa siitä operaattorille. Tällaisten tärkeiden tietojen arvo kuitenkin pienenee huomattavasti ajan myötä. Nämä ilmoitukset tulisi mieluiten saada muutamassa sekunnissa tai jopa sen tapahtuessa. Jos operaattorit saavat nämä ilmoitukset minuutteja tai tunteja sen jälkeen, kun ne tapahtuivat, tällaista tietoa ei voida toteuttaa ja se on mahdollisesti menettänyt arvonsa. Löydät samanlaisia käyttötapauksia muilta toimialoilta, kuten vähittäiskaupan, autonvalmistuksen, energian ja rahoitusteollisuuden aloilta.
Tässä viestissä keskustelemme siitä, miksi datan suoratoisto on keskeinen osa generatiivisia tekoälysovelluksia sen reaaliaikaisen luonteen vuoksi. Keskustelemme AWS-tietojen suoratoistopalveluiden arvosta, kuten Amazon hallinnoi suoratoistoa Apache Kafkalle (Amazon MSK), Amazon Kinesis -tietovirrat, Amazonin hallinnoima palvelu Apache Flinkilleja Amazon Kinesis Data Firehose generatiivisten AI-sovellusten rakentamisessa.
Kontekstin sisäinen oppiminen
LLM:t on koulutettu ajankohtaisilla tiedoilla, eikä heillä ole luontaista kykyä päästä käsiksi tuoreeseen dataan päättelyhetkellä. Kun uusia tietoja ilmaantuu, sinun on jatkuvasti hienosäädettävä tai harjoitettava mallia edelleen. Tämä ei ole vain kallis operaatio, vaan myös erittäin rajoittava käytännössä, koska uuden datan tuottonopeus ylittää huomattavasti hienosäädön nopeuden. Lisäksi LLM:iltä puuttuu kontekstuaalinen ymmärrys ja he luottavat yksinomaan harjoitustietoihinsa ja ovat siksi alttiita hallusinaatioille. Tämä tarkoittaa, että ne voivat tuottaa sujuvan, yhtenäisen ja syntaktisesti järkevän, mutta tosiasiallisesti virheellisen vastauksen. Niillä ei myöskään ole merkitystä, personointia ja kontekstia.
LLM:illä on kuitenkin kyky oppia kontekstista saamistaan tiedoista vastatakseen tarkemmin ilman mallin painojen muokkaamista. Tätä kutsutaan kontekstissa oppimista, ja niitä voidaan käyttää tuottamaan henkilökohtaisia vastauksia tai antamaan tarkkoja vastauksia organisaation käytäntöjen yhteydessä.
Esimerkiksi chatbotissa datatapahtumat voivat liittyä lentojen ja hotellien luetteloon tai hintamuutoksiin, jotka syötetään jatkuvasti suoratoiston tallennuskoneeseen. Lisäksi datatapahtumat suodatetaan, rikastetaan ja muunnetaan kuluvaan muotoon stream-prosessorin avulla. Tulos asetetaan sovelluksen saataville hakemalla viimeisin tilannekuva. Tilannekuva päivittyy jatkuvasti stream-käsittelyn avulla; siksi ajantasaiset tiedot tarjotaan malliin käyttäjän kehotteen yhteydessä. Näin malli pystyy mukautumaan viimeisimpiin hinnan ja saatavuuden muutoksiin. Seuraava kaavio havainnollistaa kontekstin sisäisen oppimisen perustyönkulkua.
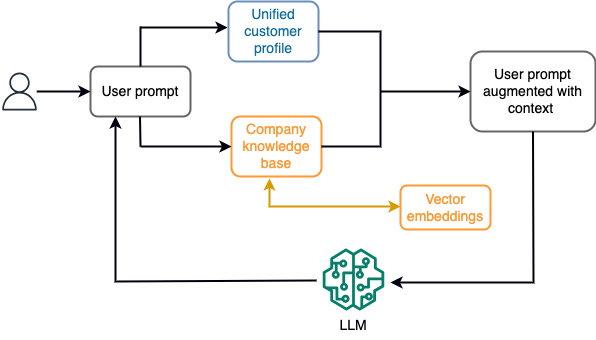
Yleisesti käytetty kontekstissa oppimisen lähestymistapa on käyttää tekniikkaa nimeltä Retrieval Augmented Generation (RAG). RAG:ssa annat kehotteeseen olennaiset tiedot, kuten tärkeimmät käytännöt ja asiakastiedot, sekä käyttäjän kysymyksen. Tällä tavalla LLM luo vastauksen käyttäjän kysymykseen käyttämällä kontekstina annettua lisätietoa. Lisätietoja RAG:sta on osoitteessa Kysymyksiin vastaaminen käyttämällä Retrieval Augmented Generationia perustusmalleilla Amazon SageMaker JumpStartissa.
RAG-pohjainen generatiivinen tekoälysovellus voi tuottaa vain yleisiä vastauksia koulutustietojensa ja tietokannan asiaankuuluvien asiakirjojen perusteella. Tämä ratkaisu on puutteellinen, kun sovellukselta odotetaan lähes reaaliaikaista yksilöllistä vastausta. Esimerkiksi matka-chatbotin odotetaan ottavan huomioon käyttäjän nykyiset varaukset, saatavilla olevat hotelli- ja lentovarastot ja paljon muuta. Lisäksi asiaankuuluvat asiakkaan henkilötiedot (tunnetaan yleisesti nimellä yhtenäinen asiakasprofiili) voi yleensä muuttua. Jos generatiivisen tekoälyn käyttäjäprofiilitietokannan päivittämiseen käytetään eräprosessia, asiakas voi saada tyytymättömiä vastauksia vanhojen tietojen perusteella.
Tässä viestissä keskustelemme stream-käsittelyn soveltamisesta parantamaan RAG-ratkaisua, jota käytetään kysymysvastaajien rakentamiseen kontekstilla reaaliaikaisesta pääsystä yhtenäisiin asiakasprofiileihin ja organisaation tietopohjaan.
Lähes reaaliaikaiset asiakasprofiilipäivitykset
Asiakastietueet jaetaan yleensä organisaation tietovarastoihin. Jotta generatiivinen tekoälysovelluksesi voisi tarjota relevantin, tarkan ja ajan tasalla asiakasprofiilin, on tärkeää rakentaa suoratoistodataputkia, jotka voivat suorittaa identiteetin selvittämisen ja profiilien yhdistämisen hajautettujen tietovarastojen välillä. Streaming-työt keräävät jatkuvasti uutta dataa synkronoitavaksi järjestelmien välillä ja voivat suorittaa rikastamista, muunnoksia, liitoksia ja aggregaatioita eri aikajaksojen välillä tehokkaammin. Muutostietojen keräys (CDC) -tapahtumat sisältävät tietoja lähdetietueesta, päivityksistä ja metatiedoista, kuten ajasta, lähteestä, luokituksesta (lisää, päivitä tai poista) ja muutoksen aloittajasta.
Seuraava kaavio havainnollistaa esimerkkityönkulkua CDC-suoratoiston käsittelystä ja yhdistettyjen asiakasprofiilien käsittelystä.

Tässä osiossa käsittelemme RAG-pohjaisten generatiivisten AI-sovellusten tukemiseen tarvittavan CDC-suoratoistomallin pääkomponentteja.
CDC-suoratoiston otto
CDC-replikaattori on prosessi, joka kerää datamuutoksia lähdejärjestelmästä (yleensä lukemalla tapahtumalokeja tai binlogeja) ja kirjoittaa CDC-tapahtumat täsmälleen samassa järjestyksessä kuin ne tapahtuivat suoratoistotietovirrassa tai aiheessa. Tämä sisältää lokipohjaisen kaappauksen työkaluilla, kuten AWS -tietokannan siirtopalvelu (AWS DMS) tai avoimen lähdekoodin liittimet, kuten Debezium for Apache Kafka connect. Apache Kafka Connect on osa Apache Kafka -ympäristöä, jonka avulla tietoja voidaan syöttää eri lähteistä ja toimittaa useisiin kohteisiin. Voit käyttää Apache Kafka -liitintäsi Amazon MSK Connect muutamassa minuutissa murehtimatta Apache Kafka -klusterin määrityksestä ja käytöstä. Sinun tarvitsee vain lähettää liittimesi käännetty koodi osoitteeseen Amazonin yksinkertainen tallennuspalvelu (Amazon S3) ja määritä liittimesi työkuormasi mukaisilla määrityksillä.
On myös muita menetelmiä tietojen muutosten tallentamiseen. Esimerkiksi, Amazon DynamoDB tarjoaa ominaisuuden CDC-tietojen suoratoistoon Amazon DynamoDB-virrat tai Kinesis Data Streams. Amazon S3 tarjoaa liipaisimen kutsua AWS Lambda toimintoa, kun uusi asiakirja tallennetaan.
Suoratoistotallennustila
Suoratoistotallennus toimii välipuskurina CDC-tapahtumien tallentamiseen ennen niiden käsittelyä. Suoratoistotallennus tarjoaa luotettavan tallennustilan suoratoistotiedoille. Suunnittelultaan se on erittäin saatavilla ja kestää laitteisto- tai solmuhäiriöitä ja ylläpitää tapahtumien järjestystä sellaisena kuin ne on kirjoitettu. Suoratoistotallennus voi tallentaa datatapahtumia joko pysyvästi tai tietyn ajan. Tämä mahdollistaa stream-prosessorien lukemisen virran osasta, jos ilmenee vika tai uudelleenkäsittelyn tarve. Kinesis Data Streams on palvelimeton suoratoistodatapalvelu, jonka avulla on helppoa siepata, käsitellä ja tallentaa tietovirtoja mittakaavassa. Amazon MSK on täysin hallittu, erittäin saatavilla oleva ja turvallinen AWS:n tarjoama palvelu Apache Kafkan käyttämiseen.
Virran käsittely
Virrankäsittelyjärjestelmät tulee suunnitella rinnakkaisiksi, jotta ne voivat käsitellä suurta tiedonsiirtokapasiteettia. Niiden tulisi osioida syöttövirta useiden tehtävien välillä, jotka suoritetaan useissa laskentasolmuissa. Tehtävien tulee pystyä lähettämään yhden operaation tulos seuraavaan verkon kautta, mikä mahdollistaa tietojen rinnakkaisen käsittelyn suorittaessaan toimintoja, kuten liitoksia, suodatusta, rikastamista ja aggregaatioita. Virrankäsittelysovellusten tulisi kyetä käsittelemään tapahtumia tapahtuma-ajan suhteen käyttötapauksissa, joissa tapahtumat voivat saapua myöhässä tai oikea laskenta perustuu tapahtumien esiintymisaikaan järjestelmän ajan sijaan. Lisätietoja on kohdassa Ajan käsitteet: Tapahtuma-aika ja käsittelyaika.
Stream-prosessit tuottavat jatkuvasti tuloksia datatapahtumien muodossa, jotka on tulostettava kohdejärjestelmään. Kohdejärjestelmä voi olla mikä tahansa järjestelmä, joka voi integroitua suoraan prosessiin tai suoratoistotallennustilan kautta kuten välittäjänä. Riippuen virrankäsittelyyn valitsemastasi kehyksestä, sinulla on erilaisia vaihtoehtoja kohdejärjestelmille käytettävissä olevista nieluliittimistä riippuen. Jos päätät kirjoittaa tulokset välitysmuistiin, voit rakentaa erillisen prosessin, joka lukee tapahtumia ja ottaa muutokset käyttöön kohdejärjestelmään, kuten käyttää Apache Kafka -nieluliitintä. Riippumatta siitä, minkä vaihtoehdon valitset, CDC-tiedot tarvitsevat lisäkäsittelyä luonteensa vuoksi. Koska CDC-tapahtumat sisältävät tietoja päivityksistä tai poistoista, on tärkeää, että ne sulautuvat kohdejärjestelmään oikeassa järjestyksessä. Jos muutokset otetaan käyttöön väärässä järjestyksessä, kohdejärjestelmä ei ole synkronoitu lähteensä kanssa.
Apache Flash on tehokas virrankäsittelykehys, joka tunnetaan alhaisesta latenssistaan ja suuresta suorituskyvystään. Se tukee tapahtuman aikakäsittelyä, täsmälleen kerran käsittelyn semantiikkaa ja korkeaa vikasietoisuutta. Lisäksi se tarjoaa alkuperäisen tuen CDC-datalle erityisen rakenteen kautta dynaamiset taulukot. Dynaamiset taulukot jäljittelevät lähdetietokantataulukoita ja tarjoavat sarakeesityksen suoratoistotiedoista. Dynaamisten taulukoiden tiedot muuttuvat jokaisen käsiteltävän tapahtuman yhteydessä. Uusia tietueita voidaan liittää, päivittää tai poistaa milloin tahansa. Dynaamiset taulukot poistavat ylimääräisen logiikan, joka sinun on otettava käyttöön jokaiselle tietueoperaatiolle (lisää, päivitä, poista) erikseen. Lisätietoja on kohdassa Dynaamiset taulukot.
Kanssa Amazonin hallinnoima palvelu Apache Flinkille, voit suorittaa Apache Flink -töitä ja integroida muihin AWS-palveluihin. Hallittavia palvelimia ja klustereita ei ole, eikä laskenta- ja tallennusinfrastruktuuria ole määritettävä.
AWS-liima on täysin hallittu ETL-palvelu (ETL), mikä tarkoittaa, että AWS hoitaa infrastruktuurin hallinnan, skaalauksen ja ylläpidon puolestasi. Vaikka AWS Glue tunnetaan ensisijaisesti ETL-ominaisuuksistaan, sitä voidaan käyttää myös Spark-suoratoistosovelluksiin. AWS Glue voi olla vuorovaikutuksessa suoratoistodatapalvelujen, kuten Kinesis Data Streamsin ja Amazon MSK:n, kanssa CDC-tietojen käsittelemiseksi ja muuntamiseksi. AWS Glue voidaan myös integroida saumattomasti muihin AWS-palveluihin, kuten Lambda, AWS-vaihetoiminnotja DynamoDB, jotka tarjoavat sinulle kattavan ekosysteemin tietojenkäsittelyputkien rakentamiseen ja hallintaan.
Yhtenäinen asiakasprofiili
Erilaisten lähdejärjestelmien asiakasprofiilin yhtenäisyyden poistaminen edellyttää vankkojen tietoputkien kehittämistä. Tarvitset tietoputkia, jotka voivat tuoda ja synkronoida kaikki tietueet yhteen tietovarastoon. Tämä tietovarasto tarjoaa organisaatiollesi kokonaisvaltaisen asiakastietuenäkymän, jota tarvitaan RAG-pohjaisten generatiivisten tekoälysovellusten toiminnan tehostamiseen. Tällaisen tietovaraston rakentamiseen strukturoimaton tietovarasto olisi paras.
Identiteettikaavio on hyödyllinen rakenne yhtenäisen asiakasprofiilin luomiseen, koska se kokoaa ja integroi asiakasdataa eri lähteistä, varmistaa tietojen tarkkuuden ja päällekkäisyyden poistamisen, tarjoaa reaaliaikaisia päivityksiä, yhdistää järjestelmien välisiä näkemyksiä, mahdollistaa personoinnin, parantaa asiakaskokemusta ja tukee säännösten noudattamista. Tämä yhtenäinen asiakasprofiili antaa luovalle tekoälysovellukselle mahdollisuuden ymmärtää asiakkaita ja olla heidän kanssaan tehokkaasti tekemisissä sekä noudattaa tietosuojamääräyksiä, mikä parantaa viime kädessä asiakaskokemusta ja vauhdittaa liiketoiminnan kasvua. Voit rakentaa identiteettikaavioratkaisusi käyttämällä Amazonin Neptuuni, nopea, luotettava, täysin hallittu kaaviotietokantapalvelu.
AWS tarjoaa muutaman muun hallitun ja palvelimettoman NoSQL-tallennuspalvelun strukturoimattomille avainarvoobjekteille. Amazon DocumentDB (MongoDB-yhteensopivuuden kanssa) on nopea, skaalautuva, erittäin saatavilla oleva ja täysin hallittu yritys asiakirjatietokanta palvelu, joka tukee alkuperäisiä JSON-työkuormia. DynamoDB on täysin hallittu NoSQL-tietokantapalvelu, joka tarjoaa nopean ja ennustettavan suorituskyvyn sekä saumattoman skaalautuvuuden.
Lähes reaaliaikaiset organisaatiotietokannan päivitykset
Samoin kuin asiakastietueet, sisäiset tietovarastot, kuten yrityksen käytännöt ja organisaatioasiakirjat, on yhdistetty tallennusjärjestelmiin. Tämä on tyypillisesti jäsentämätöntä dataa, ja se päivitetään ei-inkrementaalisesti. Strukturoimattoman datan käyttö tekoälysovelluksissa on tehokasta käyttämällä vektori upotuksia, jotka ovat tekniikka korkeaulotteisen datan, kuten tekstitiedostojen, kuvien ja äänitiedostojen, esittämiseksi moniulotteisena numeerisena.
AWS tarjoaa useita vektorimoottoripalvelut, Kuten Amazon OpenSearch palvelimeton, Amazon Kendraja Amazon Aurora PostgreSQL-yhteensopiva versio pgvector-laajennuksella vektorien upotusten tallentamiseen. Generatiiviset tekoälysovellukset voivat parantaa käyttökokemusta muuntamalla käyttäjäkehotteen vektoriksi ja käyttämällä sitä vektorimoottorin kyselyyn kontekstuaalisen tiedon hakemiseksi. Sekä kehote että haettu vektoridata välitetään sitten LLM:lle tarkemman ja henkilökohtaisemman vastauksen saamiseksi.
Seuraava kaavio havainnollistaa esimerkkivirran käsittelyn työnkulkua vektoriupotuksille.
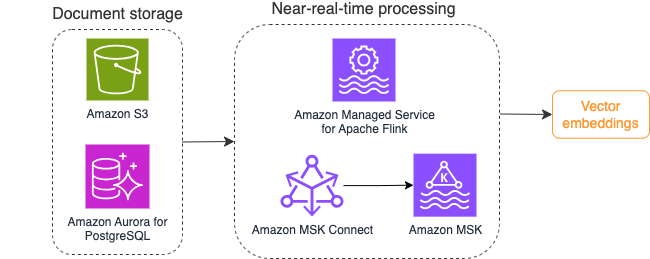
Tietokannan sisältö on muunnettava vektori upotuksiksi ennen kuin ne kirjoitetaan vektoritietovarastoon. Amazonin kallioperä or Amazon Sage Maker voi auttaa sinua pääsemään valitsemaasi malliin ja paljastamaan yksityisen päätepisteen tälle muunnokselle. Lisäksi voit käyttää kirjastoja, kuten LangChain, integroidaksesi näihin päätepisteisiin. Eräprosessin luominen voi auttaa sinua muuttamaan tietokannan sisällön vektoritiedoiksi ja tallentamaan sen aluksi vektoritietokantaan. Sinun on kuitenkin käytettävä aikaväliä asiakirjojen uudelleenkäsittelyssä synkronoidaksesi vektoritietokanta tietokannan sisällön muutosten kanssa. Jos asiakirjoja on paljon, tämä prosessi voi olla tehoton. Näiden välien välillä generatiivisen tekoälysovelluksesi käyttäjät saavat vastauksia vanhan sisällön mukaan tai virheellisen vastauksen, koska uutta sisältöä ei ole vielä vektoroitu.
Stream-käsittely on ihanteellinen ratkaisu näihin haasteisiin. Se tuottaa aluksi tapahtumia olemassa olevien asiakirjojen mukaisesti ja valvoo edelleen lähdejärjestelmää ja luo dokumentin muutostapahtuman heti, kun ne tapahtuvat. Nämä tapahtumat voidaan tallentaa suoratoistomuistiin ja odottaa, että suoratoistotyö käsittelee ne. Suoratoistotyö lukee nämä tapahtumat, lataa asiakirjan sisällön ja muuntaa sisällön joukoksi toisiinsa liittyviä sanamerkkejä. Jokainen merkki muunnetaan edelleen vektoridataksi API-kutsun kautta upotettavaan FM:ään. Tulokset lähetetään tallennettavaksi vektorimuistiin nieluoperaattorin kautta.
Jos käytät Amazon S3:a asiakirjojen tallentamiseen, voit rakentaa tapahtumalähdearkkitehtuurin, joka perustuu Lambdan S3-objektimuutostriggereihin. Lambda-toiminto voi luoda tapahtuman halutussa muodossa ja kirjoittaa sen suoratoistomuistiin.
Voit myös käyttää Apache Flinkiä suoratoistotyönä. Apache Flink tarjoaa alkuperäisen FileSystem-lähdeliittimen, joka voi löytää olemassa olevat tiedostot ja lukea niiden sisällön aluksi. Sen jälkeen se voi jatkuvasti tarkkailla tiedostojärjestelmääsi uusien tiedostojen varalta ja kaapata niiden sisältöä. Liitin tukee tiedostojoukon lukemista hajautetuista tiedostojärjestelmistä, kuten Amazon S3 tai HDFS pelkän tekstin, Avron, CSV:n, parketin ja muiden muodossa, ja tuottaa suoratoistotietueen. Täysin hallittu palvelu, Managed Service for Apache Flink poistaa Flink-töiden käyttöönotosta ja ylläpidosta aiheutuvat yleiskustannukset, jolloin voit keskittyä suoratoistosovellustesi rakentamiseen ja skaalaamiseen. Saumaton integrointi AWS-suoratoistopalveluihin, kuten Amazon MSK tai Kinesis Data Streams, tarjoaa ominaisuuksia, kuten automaattisen skaalauksen, turvallisuuden ja joustavuuden, tarjoten luotettavia ja tehokkaita Flink-sovelluksia reaaliaikaisen suoratoistodatan käsittelyyn.
DevOps-asetuksesi perusteella voit valita suoratoistotietueiden tallentamiseen Kinesis Data Streamsin tai Amazon MSK:n välillä. Kinesis Data Streams yksinkertaistaa mukautettujen suoratoistodatasovellusten rakentamisen ja hallinnan monimutkaisuutta, jolloin voit keskittyä oivallusten saamiseen tiedoistasi infrastruktuurin ylläpidon sijaan. Apache Kafkaa käyttävät asiakkaat valitsevat usein Amazon MSK:n sen yksinkertaisuuden, skaalautuvuuden ja luotettavuuden vuoksi valvoessaan Apache Kafka -klustereita AWS-ympäristössä. Täysin hallinnoituna palveluna Amazon MSK vastaa Apache Kafka -klustereiden käyttöönottoon ja ylläpitoon liittyvistä toiminnallisista monimutkaisuuksista, jolloin voit keskittyä suoratoistosovellustesi rakentamiseen ja laajentamiseen.
Koska RESTful API -integraatio sopii tämän prosessin luonteeseen, tarvitset kehyksen, joka tukee tilallista rikastusmallia RESTful API -kutsujen kautta, jotta voit seurata epäonnistumisia ja yrittää uudelleen epäonnistuneen pyynnön osalta. Apache Flink on jälleen kehys, joka voi suorittaa tilallisia toimintoja muistin nopeudella. Ymmärtääksesi parhaat tavat tehdä API-kutsuja Apache Flinkin kautta, katso Yleiset suoratoistodatan rikastusmallit Amazon Kinesis Data Analytics for Apache Flinkissä.
Apache Flink tarjoaa alkuperäiset nieluliittimet tietojen kirjoittamiseen vektoritietovarastoihin, kuten Amazon Aurora for PostgreSQL pgvector- tai Amazon OpenSearch-palvelu VectorDB:n kanssa. Vaihtoehtoisesti voit asettaa Flink-työn tulosteen (vektorisoidut tiedot) MSK-aiheeseen tai Kinesis-tietovirtaan. OpenSearch-palvelu tukee natiivia tiedonkeruuta Kinesis-tietovirroista tai MSK-aiheista. Lisätietoja on kohdassa Esittelyssä Amazon MSK Amazon OpenSearchin käsittelyn lähteenä ja Ladataan suoratoistodataa Amazon Kinesis Data Streamsista.
Palauteanalytiikka ja hienosäätö
Tietojen toiminnan johtajien ja AI/ML-kehittäjien on tärkeää saada käsitys generatiivisen AI-sovelluksen ja käytössä olevien FM-laitteiden suorituskyvystä. Tämän saavuttamiseksi sinun on rakennettava tietoputkia, jotka laskevat tärkeitä keskeisiä suorituskykyindikaattoreita (KPI) käyttäjien palautteen ja erilaisten sovelluslokien ja mittareiden perusteella. Nämä tiedot ovat hyödyllisiä sidosryhmille, jotta he voivat saada reaaliaikaisen käsityksen FM:n ja sovelluksen suorituskyvystä ja yleisestä käyttäjien tyytyväisyydestä sovelluksestasi saamansa tuen laatuun. Sinun on myös kerättävä ja tallennettava keskusteluhistoriaa, jotta voit hienosäätää FM-lähettimiäsi parantaaksesi niiden kykyä suorittaa toimialuekohtaisia tehtäviä.
Tämä käyttötapaus sopii erittäin hyvin streaming-analytiikan verkkotunnukseen. Sovelluksesi tulee tallentaa jokainen keskustelu suoratoistotallennustilaan. Sovelluksesi voi pyytää käyttäjiä arvioimaan kunkin vastauksen tarkkuutta ja heidän yleistä tyytyväisyyttään. Nämä tiedot voivat olla binäärimuodossa tai vapaamuotoisessa tekstissä. Nämä tiedot voidaan tallentaa Kinesis-tietovirtaan tai MSK-aiheeseen, ja niitä voidaan käsitellä KPI:iden luomiseksi reaaliajassa. Voit laittaa FM:t toimimaan käyttäjien tunteiden analysoinnissa. FM:t voivat analysoida jokaisen vastauksen ja määrittää käyttäjätyytyväisyysluokan.
Apache Flinkin arkkitehtuuri mahdollistaa monimutkaisen datan yhdistämisen ajan ikkunoissa. Se tukee myös SQL-kyselyitä datatapahtumien virran kautta. Siksi Apache Flinkin avulla voit nopeasti analysoida raakoja käyttäjien syötteitä ja luoda KPI:itä reaaliajassa kirjoittamalla tuttuja SQL-kyselyitä. Lisätietoja on kohdassa Taulukon API ja SQL.
Kanssa Amazonin hallinnoima palvelu Apache Flink Studiolle, voit rakentaa ja käyttää Apache Flink -virrankäsittelysovelluksia käyttämällä tavallisia SQL-, Python- ja Scala-sovelluksia interaktiivisessa muistikirjassa. Studio-kannettavat saavat virtansa Apache Zeppelinistä, ja ne käyttävät Apache Flinkiä streaminkäsittelymoottorina. Studio-muistikirjat yhdistävät nämä tekniikat saumattomasti, jotta tietovirtojen edistynyt analytiikka on kaikkien taitoryhmien kehittäjien saatavilla. Apache Flink tukee käyttäjän määrittämiä toimintoja (UDF) ja mahdollistaa räätälöityjen operaattoreiden rakentamisen integroitumaan ulkoisiin resursseihin, kuten FM:iin, suorittamaan monimutkaisia tehtäviä, kuten mielialan analysointia. UDF-tiedostojen avulla voit laskea erilaisia mittareita tai rikastuttaa käyttäjien palautteen raakadataa lisätiedoilla, kuten käyttäjien mielipiteillä. Lisätietoja tästä mallista on kohdassa Asiakkaiden huolenaiheiden ennakoiva käsitteleminen reaaliajassa GenAI:n, Flinkin, Apache Kafkan ja Kinesiksen avulla.
Apache Flink Studion Managed Service -palvelun avulla voit ottaa Studio-muistikirjasi käyttöön suoratoistotyönä yhdellä napsautuksella. Voit käyttää Apache Flinkin toimittamia alkuperäisiä nieluliittimiä lähettääksesi lähdön haluamaasi tallennustilaan tai asettaa sen Kinesis-tietovirtaan tai MSK-aiheeseen. Amazonin punainen siirto ja OpenSearch Service ovat molemmat ihanteellisia analyyttisten tietojen tallentamiseen. Molemmat moottorit tarjoavat Kinesis Data Streamsin ja Amazon MSK:n alkuperäisen tiedonkeruutuen erillisen suoratoistoputkiston kautta datajärveen tai tietovarastoon analysointia varten.
Amazon Redshift käyttää SQL:ää strukturoidun ja puolistrukturoidun datan analysointiin tietovarastoissa ja tietojärvissä käyttämällä AWS-suunniteltua laitteistoa ja koneoppimista parhaan hinta-suorituskyvyn saavuttamiseksi mittakaavassa. OpenSearch Service tarjoaa visualisointiominaisuuksia, jotka tukevat OpenSearch Dashboards ja Kibana (versiot 1.5–7.10).
Voit käyttää tällaisen analyysin tuloksia yhdistettynä käyttäjän kehotteisiin FM:n hienosäätämiseen tarvittaessa. SageMaker on yksinkertaisin tapa hienosäätää FM-lähetyksiäsi. Amazon S3:n käyttäminen SageMakerin kanssa tarjoaa tehokkaan ja saumattoman integraation mallien hienosäätöön. Amazon S3 toimii skaalautuvana ja kestävänä objektitallennusratkaisuna, joka mahdollistaa suurten tietojoukkojen, harjoitustietojen ja malliesineiden suoran tallennuksen ja haun. SageMaker on täysin hallittu ML-palvelu, joka yksinkertaistaa ML:n koko elinkaarta. Kun käytät Amazon S3:a SageMakerin tallennustaustana, voit hyötyä Amazon S3:n skaalautumisesta, luotettavuudesta ja kustannustehokkuudesta ja integroida se saumattomasti SageMakerin koulutus- ja käyttöönottoominaisuuksiin. Tämä yhdistelmä mahdollistaa tehokkaan tiedonhallinnan, helpottaa yhteistyömallien kehittämistä ja varmistaa, että ML-työnkulut ovat virtaviivaisia ja skaalautuvia, mikä viime kädessä parantaa ML-prosessin yleistä ketteryyttä ja suorituskykyä. Lisätietoja on kohdassa Hienosäädä Falcon 7B ja muut LLM:t Amazon SageMakerissa @remote Decoratorilla.
Tiedostojärjestelmän nieluliittimen avulla Apache Flink -työt voivat toimittaa tietoja Amazon S3:lle avoimessa muodossa (kuten JSON-, Avro-, Parquet- ja muissa) tiedostoina tietoobjekteina. Jos haluat mieluummin hallita datajärviäsi transaktiotietojärven kehyksen avulla (kuten Apache Hudi, Apache Iceberg tai Delta Lake), kaikki nämä puitteet tarjoavat mukautetun liittimen Apache Flinkille. Katso lisätietoja osoitteesta Luo matalan viiveen lähde-data-järvi-putki käyttämällä Amazon MSK Connectia, Apache Flinkiä ja Apache Hudia.
Yhteenveto
RAG-malliin perustuvassa generatiivisessa tekoälysovelluksessa sinun on harkittava kahden tiedontallennusjärjestelmän rakentamista ja rakennettava tietooperaatioita, jotka pitävät ne ajan tasalla kaikissa lähdejärjestelmissä. Perinteiset erätyöt eivät riitä käsittelemään sen datan kokoa ja monimuotoisuutta, jota tarvitset generatiiviseen tekoälysovellukseesi integroitaessa. Viiveet lähdejärjestelmien muutosten käsittelyssä johtavat epätarkkoihin reaktioihin ja heikentävät generatiivisen tekoälysovelluksesi tehokkuutta. Tietojen suoratoiston avulla voit syöttää tietoja useista eri tietokannoista eri järjestelmissä. Sen avulla voit myös muuntaa, rikastaa, yhdistää ja koota tietoja useista lähteistä tehokkaasti lähes reaaliajassa. Datan suoratoisto tarjoaa yksinkertaistetun tietoarkkitehtuurin, jonka avulla voit kerätä ja muuttaa käyttäjien reaaliaikaisia reaktioita tai kommentteja sovellusvastauksista, mikä auttaa sinua toimittamaan ja tallentamaan tulokset datajärveen mallin hienosäätöä varten. Datan suoratoisto auttaa myös optimoimaan dataputket käsittelemällä vain muutostapahtumat, jolloin voit vastata datamuutoksiin nopeammin ja tehokkaammin.
Lisätietoja AWS-datan suoratoistopalvelut ja aloita oman datan suoratoistoratkaisusi rakentaminen.
Tietoja Tekijät
 Ali Alemi on Streaming Specialist Solutions -arkkitehti AWS:ssä. Ali neuvoo AWS-asiakkaita parhaiden arkkitehtonisten käytäntöjen kanssa ja auttaa heitä suunnittelemaan reaaliaikaisia analytiikkatietojärjestelmiä, jotka ovat luotettavia, turvallisia, tehokkaita ja kustannustehokkaita. Hän työskentelee taaksepäin asiakkaiden käyttötapauksista ja suunnittelee dataratkaisuja heidän liiketoimintaongelmiensa ratkaisemiseksi. Ennen AWS:ään liittymistään Ali tuki useita julkisen sektorin asiakkaita ja AWS-konsultointikumppaneita heidän sovellusten modernisoinnissa ja pilveen siirtymisessä.
Ali Alemi on Streaming Specialist Solutions -arkkitehti AWS:ssä. Ali neuvoo AWS-asiakkaita parhaiden arkkitehtonisten käytäntöjen kanssa ja auttaa heitä suunnittelemaan reaaliaikaisia analytiikkatietojärjestelmiä, jotka ovat luotettavia, turvallisia, tehokkaita ja kustannustehokkaita. Hän työskentelee taaksepäin asiakkaiden käyttötapauksista ja suunnittelee dataratkaisuja heidän liiketoimintaongelmiensa ratkaisemiseksi. Ennen AWS:ään liittymistään Ali tuki useita julkisen sektorin asiakkaita ja AWS-konsultointikumppaneita heidän sovellusten modernisoinnissa ja pilveen siirtymisessä.
 Imtiaz (Taz) sanoi on AWS:n maailmanlaajuinen analytiikan tekninen johtaja. Hän nauttii yhteydenpidosta yhteisön kanssa kaikessa datassa ja analytiikan alalla. Häneen saa yhteyden kautta LinkedIn.
Imtiaz (Taz) sanoi on AWS:n maailmanlaajuinen analytiikan tekninen johtaja. Hän nauttii yhteydenpidosta yhteisön kanssa kaikessa datassa ja analytiikan alalla. Häneen saa yhteyden kautta LinkedIn.
- SEO-pohjainen sisällön ja PR-jakelu. Vahvista jo tänään.
- PlatoData.Network Vertical Generatiivinen Ai. Vahvista itseäsi. Pääsy tästä.
- PlatoAiStream. Web3 Intelligence. Tietoa laajennettu. Pääsy tästä.
- PlatoESG. hiili, CleanTech, energia, ympäristö, Aurinko, Jätehuolto. Pääsy tästä.
- PlatonHealth. Biotekniikan ja kliinisten kokeiden älykkyys. Pääsy tästä.
- Lähde: https://aws.amazon.com/blogs/big-data/exploring-real-time-streaming-for-generative-ai-applications/

