Tämä on vieraspostaus, joka on kirjoitettu yhdessä Metan PyTorch-tiimin kanssa ja on jatkoa Osa 1 tämän sarjan, jossa esittelemme PyTorch 2.0:n suorituskyvyn ja helppouden AWS:ssä.
Koneoppimisen (ML) tutkimus on osoittanut, että suuret kielimallit (LLM), jotka on koulutettu merkittävästi suurilla tietojoukoilla, johtavat parempaan mallien laatuun. Viime vuosina nykyisen sukupolven mallien koko on kasvanut merkittävästi, ja ne edellyttävät nykyaikaisia työkaluja ja infrastruktuuria kouluttaakseen tehokkaasti ja mittakaavassa. PyTorch Distributed Data Parallelism (DDP) auttaa prosessoimaan dataa mittakaavassa yksinkertaisella ja vankalla tavalla, mutta se vaatii mallin mahtumaan yhteen GPU:hun. PyTorch Fully Sharded Data Parallel (FSDP) -kirjasto murtaa tämän esteen mahdollistamalla mallin sirpaloinnin, jolla voidaan kouluttaa suuria malleja tiedon rinnakkaisten työntekijöiden kesken.
Hajautettu mallikoulutus vaatii klusterin työntekijäsolmuja, jotka voivat skaalata. Amazonin elastisten kuberneettien palvelu (Amazon EKS) on suosittu Kubernetes-yhteensopiva palvelu, joka yksinkertaistaa huomattavasti AI/ML-työkuormien suorittamista, mikä tekee siitä hallittavamman ja vähemmän aikaa vievän.
Tässä blogiviestissä AWS tekee yhteistyötä Metan PyTorch-tiimin kanssa keskustellakseen PyTorchin FSDP-kirjaston käyttämisestä AWS:n syväoppimismallien lineaariseen skaalaukseen saumattomasti Amazon EKS:n ja AWS Deep Learning Containers (DLC:t). Osoitamme tämän toteuttamalla vaiheittaisen koulutuksen 7B, 13B ja 70B Llama2-malleja käyttämällä Amazon EKS:ää 16:lla Amazonin elastinen laskentapilvi (Amazon EC2) p4de.24xlarge instanssit (jokaisessa 8 NVIDIA A100 Tensor Core GPU:ta ja jokaisessa GPU:ssa 80 Gt HBM2e-muistia) tai 16 EC2 p5.48xlarge instanssit (joissakin 8 NVIDIA H100 Tensor Core -grafiikkasuoritinta ja jokaisessa GPU:ssa 80 Gt HBM3-muistia), saavuttavat lähes lineaarisen suorituskyvyn skaalauksen ja mahdollistavat viime kädessä nopeamman harjoitusajan.
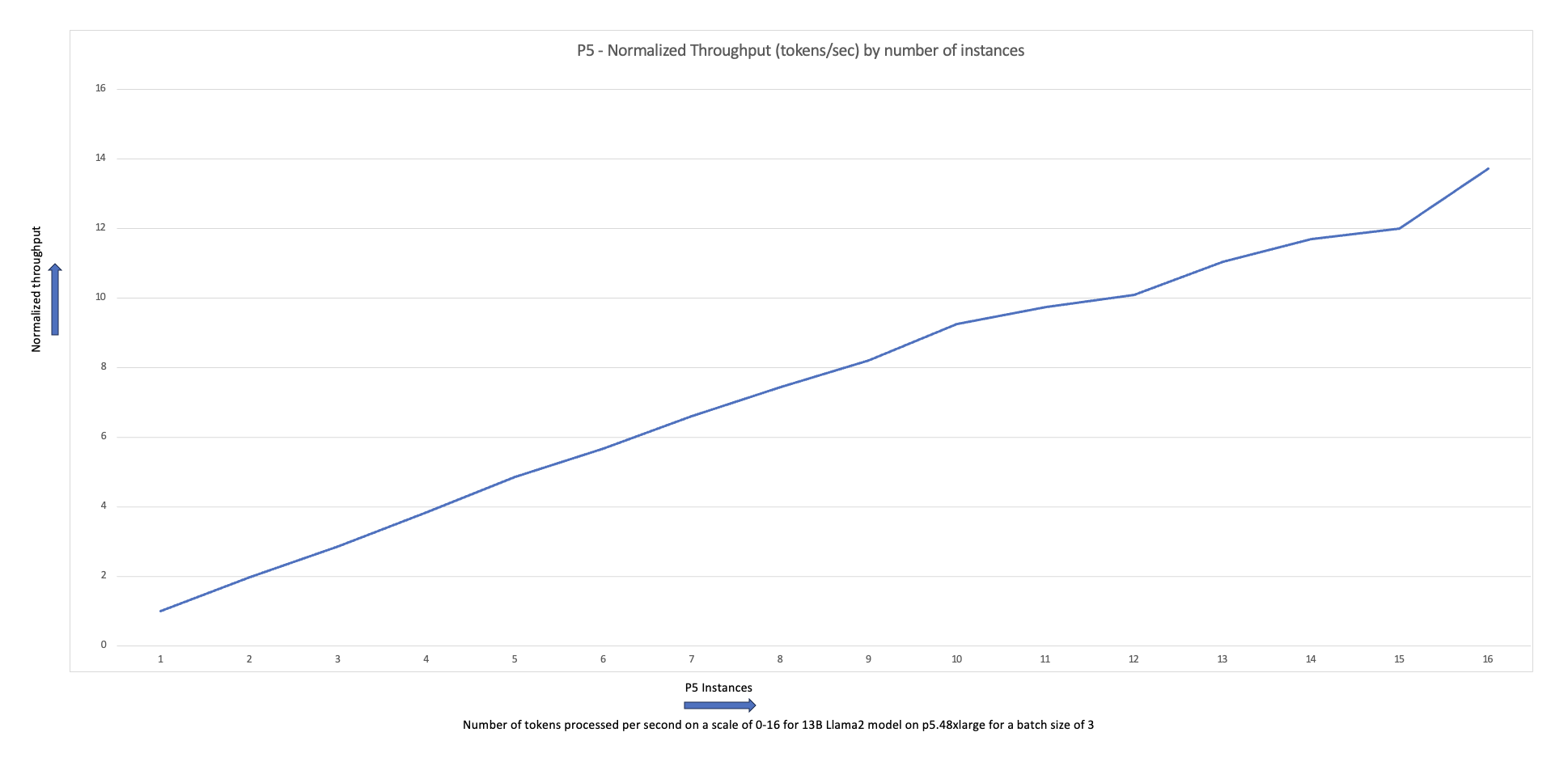
Seuraava skaalauskaavio osoittaa, että p5.48xlarge -esiintymät tarjoavat 87 %:n skaalaustehokkuuden FSDP Llama2 -hienosäädöllä 16-solmun klusterikokoonpanossa.
LLM-koulutuksen haasteita
Yritykset ottavat yhä enemmän käyttöön LLM:itä erilaisiin tehtäviin, mukaan lukien virtuaaliassistentit, käännös, sisällön luominen ja tietokonenäkö, parantaakseen tehokkuutta ja tarkkuutta eri sovelluksissa.
Näiden suurten mallien kouluttaminen tai hienosäätö räätälöityä käyttötapausta varten vaatii kuitenkin suuren määrän dataa ja laskentatehoa, mikä lisää ML-pinon yleistä suunnittelun monimutkaisuutta. Tämä johtuu myös rajoitetusta muistista, joka on käytettävissä yhdellä grafiikkasuorittimella, mikä rajoittaa koulutettavan mallin kokoa ja rajoittaa myös harjoituksen aikana käytettävää GPU-eräkokoa.
Tämän haasteen ratkaisemiseksi erilaisia mallin rinnakkaisuustekniikoita, kuten DeepSpeed ZeRO ja PyTorch FSDP luotiin, jotta voit voittaa tämän rajallisen GPU-muistin esteen. Tämä tehdään ottamalla käyttöön sirpaloitujen tietojen rinnakkaistekniikka, jossa jokaisessa kiihdytin on vain siivu (a sirpale).
Tämä viesti osoittaa, kuinka voit käyttää PyTorch FSDP:tä Llama2-mallin hienosäätämiseen Amazon EKS:n avulla. Saavutamme tämän skaalaamalla laskenta- ja GPU-kapasiteettia vastaamaan mallin vaatimuksia.
FSDP:n yleiskatsaus
PyTorch DDP -koulutuksessa jokainen GPU (johon viitataan nimellä a työntekijä PyTorchin yhteydessä) sisältää täydellisen kopion mallista, mukaan lukien mallin painot, gradientit ja optimoijan tilat. Jokainen työntekijä käsittelee joukon tietoja ja käyttää takaperin siirtoa kaikki vähentää toiminto synkronoida gradientit eri työntekijöiden välillä.
Mallin kopio jokaisessa GPU:ssa rajoittaa mallin kokoa, joka voidaan sisällyttää DDP-työnkulkuun. FSDP auttaa voittamaan tämän rajoituksen jakamalla malliparametreja, optimointitiloja ja gradientteja tietojen rinnakkaisten työntekijöiden välillä säilyttäen silti tietojen rinnakkaisuuden yksinkertaisuuden.
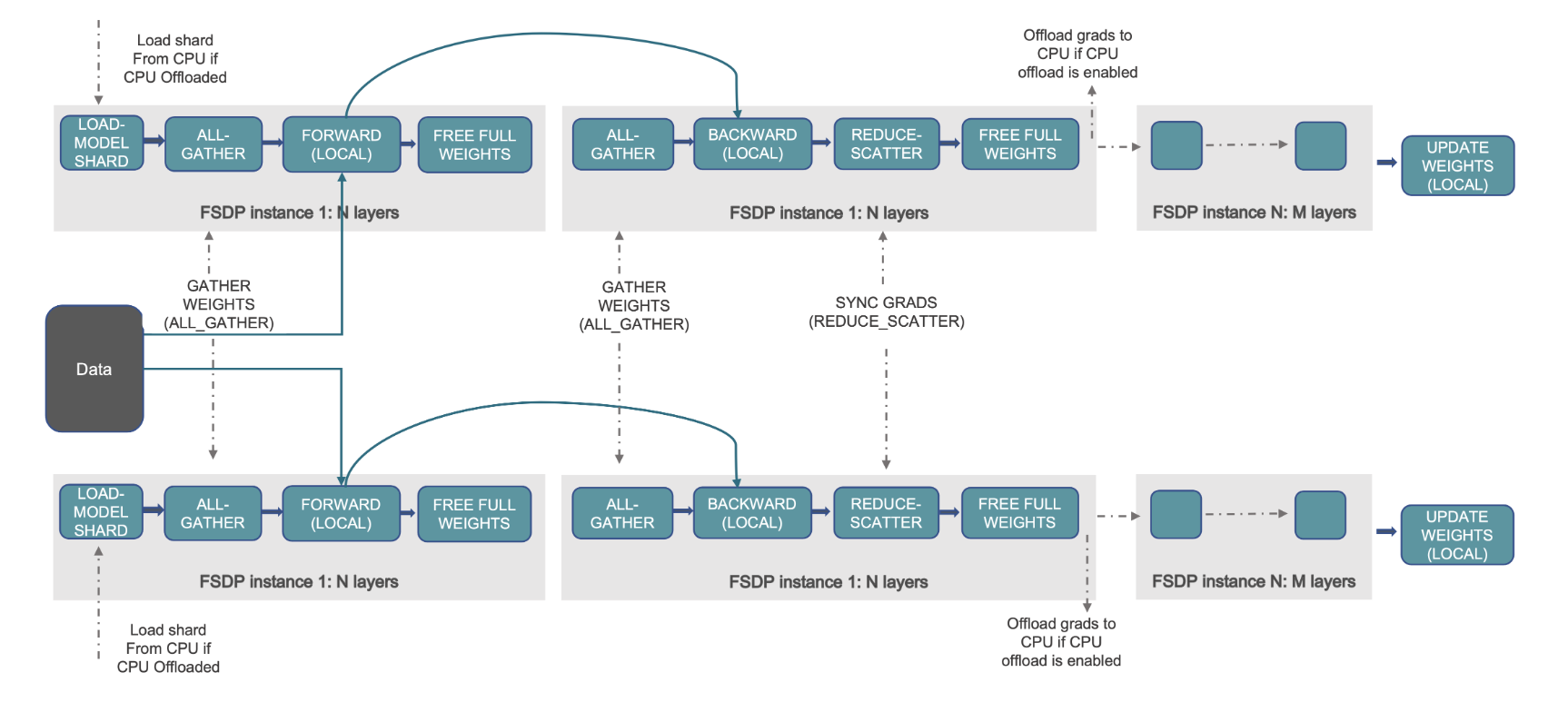
Tämä näkyy seuraavassa kaaviossa, jossa DDP:n tapauksessa jokaisella GPU:lla on täydellinen kopio mallin tilasta, mukaan lukien optimoijan tila (OS), gradientit (G) ja parametrit (P): M(OS + G) + P). FSDP:ssä jokainen GPU sisältää vain osan mallin tilasta, mukaan lukien optimoijan tila (OS), gradientit (G) ja parametrit (P): M (OS + G + P). FSDP:n käyttö johtaa huomattavasti pienempään grafiikkasuorittimen muistiin verrattuna DDP:hen kaikilla työntekijöillä, mikä mahdollistaa erittäin suurten mallien koulutuksen tai suurempien eräkokojen käytön koulutustöissä.

Tästä aiheutuu kuitenkin lisääntyneen tiedonsiirron kustannuksella, jota pienennetään FSDP:n optimoinnilla, kuten päällekkäisillä viestintä- ja laskentaprosesseilla, joissa on mm. esihaku. Katso tarkemmat tiedot osoitteesta FSDP:n (Fully Sharded Data Parallel) käytön aloittaminen.
FSDP tarjoaa erilaisia parametreja, joiden avulla voit säätää koulutustöiden suorituskykyä ja tehokkuutta. Jotkut FSDP:n tärkeimmistä ominaisuuksista ja ominaisuuksista ovat:
- Muuntajan käärintäpolitiikka
- Joustava sekoitettu tarkkuus
- Aktivoinnin tarkistuspiste
- Erilaisia jakostrategioita, jotka sopivat erilaisiin verkkonopeuksiin ja klusteritopologioihin:
- FULL_SHARD – Sirpalemallin parametrit, gradientit ja optimointitilat
- HYBRID_SHARD – Täysi sirpale solmun DDP sisällä solmujen välillä; tukee joustavaa jakoryhmää mallin täydelliselle kopiolle (HSDP)
- SHARD_GRAD_OP – Sirpale vain gradientit ja optimointitilat
- NO_SHARD – Samanlainen kuin DDP
Lisätietoja FSDP:stä on kohdassa Tehokas laajamittainen koulutus Pytorch FSDP:n ja AWS:n avulla.
Seuraava kuva näyttää, kuinka FSDP toimii kahdessa rinnakkaisessa dataprosessissa.
Ratkaisun yleiskatsaus
Tässä viestissä määritimme laskentaklusterin käyttämällä Amazon EKS:ää, joka on hallittu palvelu Kubernetesin suorittamiseen AWS-pilvessä ja paikallisissa palvelinkeskuksissa. Monet asiakkaat omaksuvat Amazon EKS:n suorittaakseen Kubernetes-pohjaisia AI/ML-työkuormia hyödyntäen sen suorituskykyä, skaalautuvuutta, luotettavuutta ja saatavuutta sekä sen integraatioita AWS-verkko-, tietoturva- ja muihin palveluihin.
FSDP-käyttötapauksessamme käytämme Kubeflow-koulutusoperaattori Amazon EKS:ssä, joka on Kubernetes-natiiviprojekti, joka helpottaa ML-mallien hienosäätöä ja skaalautuvaa hajautettua koulutusta. Se tukee erilaisia ML-kehyksiä, mukaan lukien PyTorch, jonka avulla voit ottaa käyttöön ja hallita PyTorchin koulutustöitä mittakaavassa.
Hyödyntämällä Kubeflow Training Operatorin PyTorchJob mukautettua resurssia, suoritamme koulutustöitä Kubernetesissa konfiguroitavalla määrällä työntekijöiden replikoita, mikä mahdollistaa resurssien käytön optimoinnin.
Seuraavassa on muutamia koulutusoperaattorin osia, jotka vaikuttavat Llama2:n hienosäätöön:
- Keskitetty Kubernetes-ohjain, joka ohjaa hajautettuja koulutustöitä PyTorchille.
- PyTorchJob, Kubernetesin mukautettu PyTorchin resurssi, jonka tarjoaa Kubeflow Training Operator Llama2-harjoitustöiden määrittämiseen ja käyttöönottoon Kubernetesissa.
- etcd, joka liittyy PyTorch-mallien hajautetun koulutuksen koordinoimiseen tarkoitetun kohtaamismekanismin toteuttamiseen. Tämä
etcdpalvelin, osana kohtaamisprosessia, helpottaa osallistuvien työntekijöiden koordinointia ja synkronointia hajautetun koulutuksen aikana.
Seuraava kaavio kuvaa ratkaisuarkkitehtuuria.
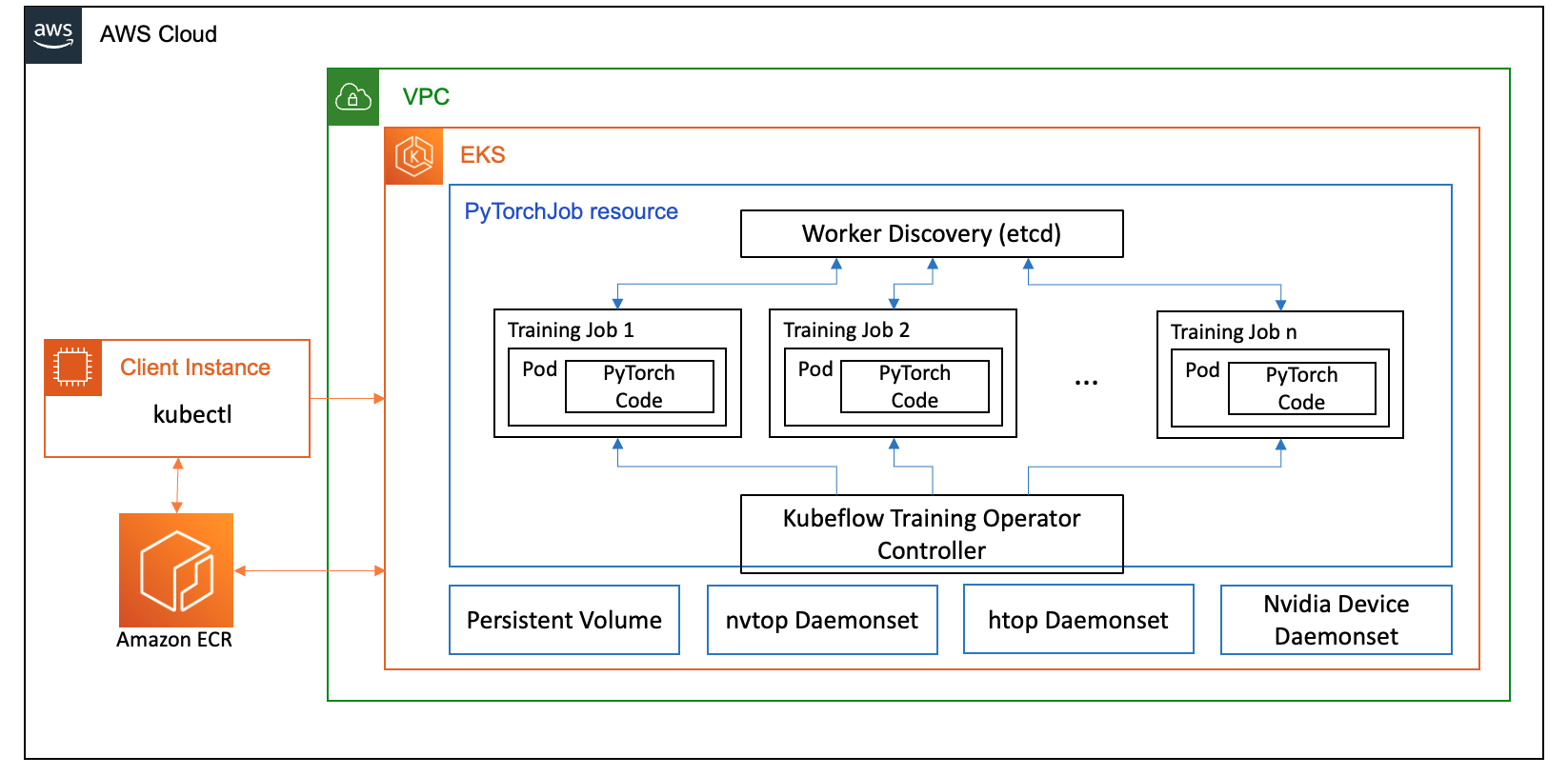
Suurin osa yksityiskohdista on abstrakti automaatiokomentosarjat, joita käytämme ajaa Llama2 esimerkki.
Käytämme tässä käyttötapauksessa seuraavia koodiviittauksia:
Mikä on Llama2?
Llama2 on LLM, joka on valmiiksi koulutettu 2 biljoonaan teksti- ja koodimerkkiin. Se on yksi suurimmista ja tehokkaimmista nykyään saatavilla olevista LLM:istä. Voit käyttää Llama2:ta erilaisiin tehtäviin, mukaan lukien luonnollisen kielen käsittelyyn (NLP), tekstin luomiseen ja kääntämiseen. Lisätietoja on kohdassa Aloittaminen Laman kanssa.
Llama2 on saatavana kolmessa eri mallikoossa:
- Laama2-70b – Tämä on suurin Llama2-malli, jossa on 70 miljardia parametria. Se on tehokkain Llama2-malli ja sitä voidaan käyttää vaativimpiinkin tehtäviin.
- Laama2-13b – Tämä on keskikokoinen Llama2-malli, jossa on 13 miljardia parametria. Se on hyvä tasapaino suorituskyvyn ja tehokkuuden välillä, ja sitä voidaan käyttää monenlaisiin tehtäviin.
- Laama2-7b – Tämä on pienin Llama2-malli, jossa on 7 miljardia parametria. Se on tehokkain Llama2-malli, ja sitä voidaan käyttää tehtäviin, jotka eivät vaadi korkeinta suorituskykyä.
Tämän viestin avulla voit hienosäätää kaikkia näitä malleja Amazon EKS:ssä. Jotta voimme tarjota yksinkertaisen ja toistettavan kokemuksen EKS-klusterin luomisesta ja FSDP-töiden suorittamisesta siinä, käytämme aws-do-eks hanke. Esimerkki toimii myös olemassa olevan EKS-klusterin kanssa.
Käsikirjoitettu esittely on saatavilla osoitteessa GitHub saadaksesi käyttökokemuksen. Seuraavissa osissa selitämme prosessin päästä päähän yksityiskohtaisemmin.
Tarjoa ratkaisun infrastruktuuri
Tässä viestissä kuvatuissa kokeissa käytämme klustereita p4de (A100 GPU) ja p5 (H100 GPU) solmuilla.
Klusteri p4de.24xsuurilla solmuilla
P4de-solmujen klusterissamme käytämme seuraavaa eks-gpu-p4de-odcr.yaml käsikirjoitus:
Käyttäminen esimerkki ja edeltävä klusteriluettelo, luomme klusterin p4de-solmuilla:
Klusteri p5.48xsuurilla solmuilla
Terraform-malli EKS-klusterille, jossa on P5-solmuja, sijaitsee seuraavassa GitHub repo.
Voit mukauttaa klusterin kautta muuttujat. tf tiedosto ja luo se sitten Terraform CLI:n kautta:
Voit tarkistaa klusterin saatavuuden suorittamalla yksinkertaisen kubectl-komennon:
Klusteri on kunnossa, jos tämän komennon tulos näyttää odotetun solmumäärän Valmis-tilassa.
Ota käyttöön edellytykset
Käytämme FSDP:n suorittamiseen Amazon EKS:ssä PyTorchJob mukautettu resurssi. Se vaatii jne ja Kubeflow-koulutusoperaattori edellytyksinä.
Ota etcd käyttöön seuraavalla koodilla:
Ota Kubeflow Training Operator käyttöön seuraavalla koodilla:
Luo ja työnnä FSDP-konttikuva Amazon ECR:ään
Käytä seuraavaa koodia FSDP-konttikuvan luomiseen ja työnnä se siihen Amazonin elastisten säiliörekisteri (Amazon ECR):
Luo FSDP PyTorchJob -luettelo
Aseta Halaava kasvomerkki seuraavassa katkelmassa ennen sen suorittamista:
Määritä PyTorchJob -sovelluksella .env tiedostoon tai suoraan ympäristömuuttujiisi seuraavasti:
Luo PyTorchJob-luettelo käyttämällä fsdp-malli ja gener.sh skripti tai luo se suoraan alla olevan skriptin avulla:
Suorita PyTorchJob
Suorita PyTorchJob seuraavalla koodilla:
Näet määritetyn määrän luotuja FDSP-työntekijöitä, ja kuvan vetämisen jälkeen ne siirtyvät Käynnissä-tilaan.
Voit nähdä PyTorchJobin tilan käyttämällä seuraavaa koodia:
PyTorchJobin pysäyttämiseksi käytä seuraavaa koodia:
Kun työ on valmis, se on poistettava ennen uuden ajon aloittamista. Olemme myös havainneet, että poistamallaetcdpod ja sen käynnistäminen uudelleen ennen uuden työn aloittamista auttaa välttämään a RendezvousClosedError.
Skaalaa klusteri
Voit toistaa edelliset töiden luomisen ja suorittamisen vaiheet samalla kun muutat klusterin työntekijäsolmujen määrää ja ilmentymän tyyppiä. Tämän avulla voit tuottaa aiemmin esitetyn kaltaisia skaalauskaavioita. Yleensä sinun pitäisi nähdä grafiikkasuorittimen muistin jalanjäljen pieneneminen, epookkiajan pieneneminen ja suorituskyvyn lisääntyminen, kun klusteriin lisätään lisää solmuja. Edellinen kaavio on tuotettu suorittamalla useita kokeita käyttämällä p5-solmuryhmää, jonka koko vaihtelee 1–16 solmun välillä.
Huomioi FSDP:n koulutustyömäärä
Generatiivisen tekoälyn työkuormien havainnointi on tärkeää, jotta voit nähdä käynnissä olevat työsi sekä auttaa maksimoimaan laskentaresurssien käytön. Tässä viestissä käytämme tähän tarkoitukseen muutamia Kubernetesin alkuperäisiä ja avoimen lähdekoodin havainnointityökaluja. Näiden työkalujen avulla voit seurata virheitä, tilastoja ja mallikäyttäytymistä, mikä tekee tekoälyn havaittavuudesta keskeisen osan liiketoimintaa. Tässä osiossa näytämme erilaisia lähestymistapoja FSDP:n koulutustöiden tarkkailuun.
Työntekijän lokit
Alkeimmalla tasolla sinun on voitava nähdä harjoituskoteloidesi lokit. Tämä voidaan tehdä helposti käyttämällä Kubernetes-natiivikomentoja.
Hae ensin luettelo podista ja etsi sen nimi, jonka lokit haluat nähdä:
Tarkastele sitten valitun ryhmän lokeja:

Vain yhdessä työntekijän (valitun johtajan) pod-loki sisältää yleiset työtilastot. Valitun johtajaryhmän nimi on saatavilla jokaisen työntekijäryhmän lokin alussa, ja se tunnistetaan avaimella master_addr=.
CPU: n käyttö
Hajautetut koulutustyömäärät vaativat sekä CPU- että GPU-resursseja. Näiden työkuormien optimoimiseksi on tärkeää ymmärtää, miten näitä resursseja käytetään. Onneksi saatavilla on hienoja avoimen lähdekoodin apuohjelmia, jotka auttavat visualisoimaan suorittimen ja grafiikkasuorittimen käytön. Voit tarkastella suorittimen käyttöähtop. Jos worker podit sisältävät tämän apuohjelman, voit käyttää alla olevaa komentoa avataksesi kuoren podiksi ja suorittaaksesi senhtop.
Vaihtoehtoisesti voit ottaa käyttöön htopindaemonsetkuten seuraavassa esitetty GitHub repo.
-daemonsetkäyttää kevyttä htop pod jokaisessa solmussa. Voit suorittaa minkä tahansa näistä podista ja suorittaa senhtopkomento:
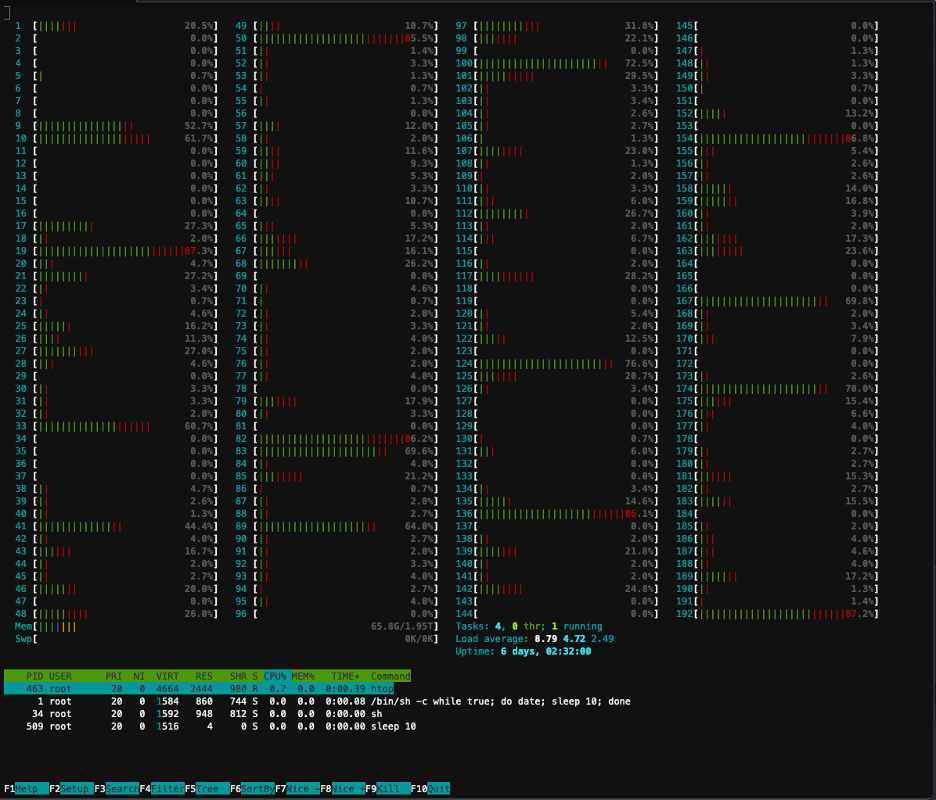
Seuraavassa kuvakaappauksessa näkyy prosessorin käyttöaste yhdessä klusterin solmuista. Tässä tapauksessa tarkastelemme P5.48xlarge-instanssia, jossa on 192 vCPU:ta. Prosessoriytimet ovat käyttämättömänä, kun mallipainot ladataan, ja näemme käyttöasteen nousevan, kun mallipainoja ladataan GPU-muistiin.
GPU:n käyttö
Josnvtopapuohjelma on saatavilla podissasi, voit suorittaa sen alla olevalla tavalla ja suorittaa sen sittennvtop.
Vaihtoehtoisesti voit ottaa käyttöön nvtopindaemonsetkuten seuraavassa esitetty GitHub repo.
Tämä ajaa anvtoppod jokaisessa solmussa. Voit suorittaa minkä tahansa noista paloista ja juostanvtop:
Seuraava kuvakaappaus näyttää GPU-käytön yhdessä koulutusklusterin solmuista. Tässä tapauksessa tarkastelemme P5.48xlarge-instanssia, jossa on 8 NVIDIA H100 GPU:ta. Grafiikkasuorittimet ovat käyttämättömänä, kun mallipainot ladataan, sitten GPU-muistin käyttöaste kasvaa, kun mallipainot ladataan GPU:hun, ja grafiikkasuorittimen käyttöaste nousee 100 prosenttiin, kun koulutusiteraatiot ovat käynnissä.

Grafana kojelauta
Nyt kun ymmärrät, kuinka järjestelmäsi toimii pod- ja solmutasolla, on myös tärkeää tarkastella mittareita klusteritasolla. NVIDIA DCGM Exporter ja Prometheus voivat kerätä koottuja käyttömittoja ja visualisoida Grafanassa.
Esimerkki Prometheus-Grafana-asennuksesta on saatavilla seuraavassa GitHub repo.
Esimerkki DCGM-viejän käyttöönotosta on saatavilla seuraavassa GitHub repo.
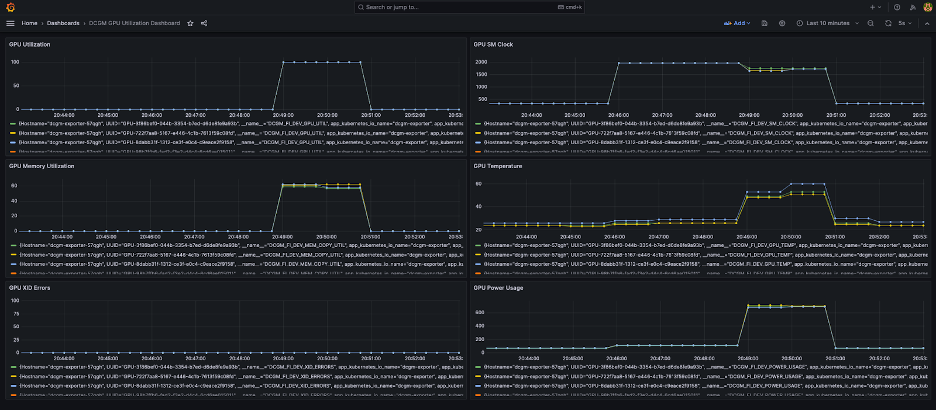
Yksinkertainen Grafana-kojelauta näkyy seuraavassa kuvakaappauksessa. Se luotiin valitsemalla seuraavat DCGM-mittarit: DCGM_FI_DEV_GPU_UTIL, DCGM_FI_MEM_COPY_UTIL, DCGM_FI_DEV_XID_ERRORS, DCGM_FI_DEV_SM_CLOCK, DCGM_FI_DEV_GPU_TEMPja DCGM_FI_DEV_POWER_USAGE. Kojelauta voidaan tuoda Prometheukseen osoitteesta GitHub.
Seuraava kojelauta näyttää yhden Llama2 7b:n yhden aikakauden harjoitustyön suorituksen. Kaaviot osoittavat, että streaming multiprocessor (SM) -kellon kasvaessa myös GPU:iden virrankulutus ja lämpötila kasvavat sekä GPU- ja muistin käyttöaste. Voit myös nähdä, että XID-virheitä ei ollut ja GPU:t olivat kunnossa tämän ajon aikana.
Maaliskuusta 2024 lähtien EKS:n GPU-havainnointia on tuettu natiivisti CloudWatch Container Insights. Ota tämä toiminto käyttöön vain ottamalla käyttöön CloudWatch Observability -lisäosa EKS-klusteriisi. Sitten voit selata pod-, solmu- ja klusteritason mittareita Container Insightsin esikonfiguroitujen ja muokattavissa olevien koontinäyttöjen kautta.
Puhdistaa
Jos loit klusterin käyttämällä tässä blogissa annettuja esimerkkejä, voit suorittaa seuraavan koodin poistaaksesi klusterin ja kaikki siihen liittyvät resurssit, mukaan lukien VPC:n:
Eksctl:
Terraformille:
Tulevat ominaisuudet
FSDP:n odotetaan sisältävän parametrikohtaisen sharding-ominaisuuden, jonka tavoitteena on edelleen parantaa sen muistijalanjälkeä GPU:ta kohti. Lisäksi FP8-tuen jatkuvalla kehittämisellä pyritään parantamaan FSDP:n suorituskykyä H100-grafiikkasuorittimissa. Lopuksi, kun FSDP on integroitutorch.compile, toivomme näkevämme lisää suorituskyvyn parannuksia ja ominaisuuksien, kuten valikoivan aktivoinnin tarkistuspisteen, käyttöönottoa.
Yhteenveto
Tässä viestissä keskustelimme siitä, kuinka FSDP vähentää kunkin GPU:n muistijalanjälkeä mahdollistaen suurempien mallien koulutuksen tehokkaammin ja saavuttaen lähes lineaarisen suorituskyvyn skaalauksen. Osoitimme tämän kouluttamalla Llama2-mallia vaiheittaisesti käyttämällä Amazon EKS:ää P4de- ja P5-esiintymissä ja käytimme havainnointityökaluja, kuten kubectl, htop, nvtop ja dcgm, valvomaan lokeja sekä suorittimen ja grafiikkasuorittimen käyttöä.
Suosittelemme sinua hyödyntämään PyTorch FSDP:tä omissa LLM-koulutustehtävissäsi. Aloita klo aws-do-fsdp.
Tietoja Tekijät
 Kanwaljit Khurmi on johtava AI/ML-ratkaisuarkkitehti Amazon Web Services -palvelussa. Hän työskentelee AWS-asiakkaiden kanssa tarjotakseen ohjausta ja teknistä apua, mikä auttaa heitä parantamaan koneoppimisratkaisujensa arvoa AWS:ssä. Kanwaljit on erikoistunut auttamaan asiakkaita konteissa, hajautetussa tietojenkäsittelyssä ja syväoppimissovelluksissa.
Kanwaljit Khurmi on johtava AI/ML-ratkaisuarkkitehti Amazon Web Services -palvelussa. Hän työskentelee AWS-asiakkaiden kanssa tarjotakseen ohjausta ja teknistä apua, mikä auttaa heitä parantamaan koneoppimisratkaisujensa arvoa AWS:ssä. Kanwaljit on erikoistunut auttamaan asiakkaita konteissa, hajautetussa tietojenkäsittelyssä ja syväoppimissovelluksissa.
 Alex Iankoulski on pääratkaisuarkkitehti, itsehallinnollinen koneoppiminen AWS:ssä. Hän on täyspinon ohjelmisto- ja infrastruktuuriinsinööri, joka haluaa tehdä syvällistä, käytännönläheistä työtä. Tehtävässään hän keskittyy auttamaan asiakkaita ML- ja AI-työkuormien konteinnissa ja organisoinnissa konttikäyttöisissä AWS-palveluissa. Hän on myös avoimen lähdekoodin kirjoittaja tee puitteet ja Docker-kapteeni, joka rakastaa konttitekniikoiden soveltamista innovaation vauhdittamiseksi ja samalla maailman suurimpien haasteiden ratkaisemiseksi.
Alex Iankoulski on pääratkaisuarkkitehti, itsehallinnollinen koneoppiminen AWS:ssä. Hän on täyspinon ohjelmisto- ja infrastruktuuriinsinööri, joka haluaa tehdä syvällistä, käytännönläheistä työtä. Tehtävässään hän keskittyy auttamaan asiakkaita ML- ja AI-työkuormien konteinnissa ja organisoinnissa konttikäyttöisissä AWS-palveluissa. Hän on myös avoimen lähdekoodin kirjoittaja tee puitteet ja Docker-kapteeni, joka rakastaa konttitekniikoiden soveltamista innovaation vauhdittamiseksi ja samalla maailman suurimpien haasteiden ratkaisemiseksi.
 Ana Simoes on AWS:n koneoppimisasiantuntija, ML Frameworks. Hän tukee asiakkaita, jotka ottavat käyttöön tekoälyä, ML:ää ja generatiivista tekoälyä suuressa mittakaavassa HPC-infrastruktuurissa pilvessä. Ana keskittyy tukemaan asiakkaita saavuttamaan hinta-suorituskyky uusissa työkuormissa ja käyttötapauksissa generatiiviseen tekoälyyn ja koneoppimiseen.
Ana Simoes on AWS:n koneoppimisasiantuntija, ML Frameworks. Hän tukee asiakkaita, jotka ottavat käyttöön tekoälyä, ML:ää ja generatiivista tekoälyä suuressa mittakaavassa HPC-infrastruktuurissa pilvessä. Ana keskittyy tukemaan asiakkaita saavuttamaan hinta-suorituskyky uusissa työkuormissa ja käyttötapauksissa generatiiviseen tekoälyyn ja koneoppimiseen.
 Hamid Shojanazeri on PyTorchin kumppaniinsinööri, joka työskentelee avoimen lähdekoodin, tehokkaan mallin optimoinnin ja hajautetun koulutuksen parissa (FSDP), ja johtopäätös. Hän on luoja laama-resepti ja osallistuja SoihtuPalvelu. Hänen tärkein intressinsä on parantaa kustannustehokkuutta ja tehdä tekoälystä helpommin saavutettavissa laajemmalle yhteisölle.
Hamid Shojanazeri on PyTorchin kumppaniinsinööri, joka työskentelee avoimen lähdekoodin, tehokkaan mallin optimoinnin ja hajautetun koulutuksen parissa (FSDP), ja johtopäätös. Hän on luoja laama-resepti ja osallistuja SoihtuPalvelu. Hänen tärkein intressinsä on parantaa kustannustehokkuutta ja tehdä tekoälystä helpommin saavutettavissa laajemmalle yhteisölle.
 Vähemmän Wrightia on AI/Partner Engineer PyTorchissa. Hän työskentelee Triton/CUDA-ytimillä (Dekvantin kiihtyminen SplitK-työn hajottelulla); sivutut, suoratoisto- ja kvantisoidut optimoijat; ja PyTorch Distributed (PyTorch FSDP).
Vähemmän Wrightia on AI/Partner Engineer PyTorchissa. Hän työskentelee Triton/CUDA-ytimillä (Dekvantin kiihtyminen SplitK-työn hajottelulla); sivutut, suoratoisto- ja kvantisoidut optimoijat; ja PyTorch Distributed (PyTorch FSDP).
- SEO-pohjainen sisällön ja PR-jakelu. Vahvista jo tänään.
- PlatoData.Network Vertical Generatiivinen Ai. Vahvista itseäsi. Pääsy tästä.
- PlatoAiStream. Web3 Intelligence. Tietoa laajennettu. Pääsy tästä.
- PlatoESG. hiili, CleanTech, energia, ympäristö, Aurinko, Jätehuolto. Pääsy tästä.
- PlatonHealth. Biotekniikan ja kliinisten kokeiden älykkyys. Pääsy tästä.
- Lähde: https://aws.amazon.com/blogs/machine-learning/scale-llms-with-pytorch-2-0-fsdp-on-amazon-eks-part-2/

