esittely
Maisema tekoäly on muuttunut dramaattisesti muutaman viime vuoden aikana Suuret kielimallit (LLM:t). Nämä tehokkaat työkalut ovat kehittyneet yksinkertaisista tekstiprosessoreista monimutkaisiin järjestelmiin, jotka pystyvät ymmärtämään ja luomaan ihmisen kaltaista tekstiä, mikä on edistynyt merkittävästi sekä ominaisuuksissa että sovelluksissa. Tämän kehityksen kärjessä on Metan uusin tarjous, Llama 3, joka lupaa työntää rajoja sille, mitä avoimilla malleilla saavutetaan saavutettavuuden ja suorituskyvyn suhteen.
Sisällysluettelo
Llama 3:n tärkeimmät ominaisuudet
- Llama 3 ylläpitää vain dekooderin muuntaja-arkkitehtuuria, jossa on merkittäviä parannuksia, mukaan lukien 128,000 XNUMX merkkiä tukeva tokenisaattori, mikä parantaa kielen koodauksen tehokkuutta.
- Integroitu sekä 8 miljardiin että 70 miljardiin parametrimalliin, mikä parantaa päättelytehokkuutta kohdennetussa ja tehokkaassa käsittelyssä.
- Llama 3 päihittää edeltäjänsä ja kilpailijansa useissa vertailuissa ja on erinomaista sellaisissa tehtävissä kuin MMLU ja HumanEval.
- Koulutettu yli 15 biljoonan tunnuksen tietojoukossa, seitsemän kertaa suurempi kuin Laama 2n tietojoukko, joka sisältää monipuolisen kielellisen esityksen ja ei-englanninkielistä dataa yli 30 kielestä.
- Yksityiskohtaiset skaalauslainsäädäntö optimoi tietosekoituksen ja laskentaresurssit varmistaen vankan suorituskyvyn eri sovelluksissa ja kolminkertaistaen koulutusprosessin tehokkuuden Llama 2:een verrattuna.
- Tehostettu koulutuksen jälkeinen vaihe yhdistää valvotun hienosäädön, hylkäysnäytteenoton ja politiikan optimoinnin mallin laadun ja päätöksentekokyvyn parantamiseksi.
- Se on saatavilla useille tärkeimmille alustoille, ja siinä on parannettu tokenisaattorin tehokkuus ja turvallisuusominaisuudet, jotka antavat kehittäjille mahdollisuuden räätälöidä sovelluksia ja varmistaa vastuullisen tekoälyn käyttöönoton.
Puhumme AI Townista
Clement Delangue, yksi HuggingFacen perustajista ja toimitusjohtaja
Yann LeCun, NYU:n professori | Meta |:n johtava tekoälytutkija Tekoälyn, koneoppimisen, robotiikan jne. tutkija | ACM Turing -palkinnon saaja.
Andrej Karpathy, OpenAI:n perustajatiimi
Meta Llama 3 edustaa viimeisintä edistystä Metan kielimallien sarjassa, mikä on merkittävä askel eteenpäin generatiivisen tekoälyn kehityksessä. Nyt saatavilla oleva uusi sukupolvi sisältää malleja, joissa on 8 miljardia ja 70 miljardia parametria, joista kukin on suunniteltu erinomaisiksi erilaisissa sovelluksissa. Llama 3 asettaa suorituskyvylle uuden standardin päivittäisistä keskusteluista monimutkaisten päättelytehtävien ratkaisemiseen, ja se ylittää edeltäjänsä lukuisissa alan vertailuissa. Llama 3 on vapaasti saatavilla, ja se antaa yhteisölle mahdollisuuden ajaa tekoälyn innovaatioita sovellusten kehittämisestä kehittäjätyökalujen parantamiseen ja muuhunkin.
Malliarkkitehtuuri ja parannukset Llama 2:sta
Llama 3 säilyttää todistetun vain dekooderin muuntaja-arkkitehtuurin ja sisältää merkittäviä parannuksia, jotka nostavat sen toiminnallisuutta Llama 2:n tasoa pidemmälle. Llama 3:ssa on johdonmukaista suunnittelufilosofiaa noudattaen tokenisaattori, joka tukee laajaa 128,000 3 tokenin sanastoa, mikä parantaa huomattavasti mallin tehokkuutta. koodauskielellä. Tämä kehitys merkitsee huomattavasti parantunutta yleistä suorituskykyä. Lisäksi päättelytehokkuuden parantamiseksi Llama 8 integroi Grouped Query Attention (GQA) -toiminnon sekä 70 miljardiin että 8,192 miljardiin parametrimalliin. Tämä malli käyttää myös 3 XNUMX merkin sekvenssiä maskaustekniikalla, joka estää itsetarkkailua leviämästä yli asiakirjan rajojen, mikä varmistaa tarkemman ja tehokkaamman käsittelyn. Nämä parannukset yhdessä parantavat Llama XNUMX:n kykyä käsitellä laajempaa joukkoa tehtäviä parannetulla tarkkuudella ja tehokkuudella.
| Ominaisuus | Laama 2 | Laama 3 |
| Parametrialue | 7B - 70B parametrit | 8B ja 70B parametrit 400B+ suunnitelmilla |
| Malli arkkitehtuuri | Perustuu muuntajan arkkitehtuuriin | Normaali vain dekooderin muuntajaarkkitehtuuri |
| Tokenoinnin tehokkuus | Kontekstin pituus jopa 4096 merkkiä | Käyttää tokenisaattoria, jonka sanasto on 128 XNUMX merkkiä |
| Harjoittelutiedot | 2 biljoonaa tokenia julkisista lähteistä | Yli 15 t tokenia julkisista lähteistä |
| Päätelmätehokkuus | Parannuksia, kuten GQA 70B-malliin | Grouped Query Attention (GQA) parantaa tehokkuutta |
| Hienosäätömenetelmät | Valvottu hienosäätö ja RLHF | Valvottu hienosäätö (SFT), hylkäysnäytteenotto, PPO, DPO |
| Turvallisuus ja eettiset näkökohdat | Turvallinen kontradiktorisen nopean testauksen mukaan | Laaja punatiimi turvallisuuden takaamiseksi |
| Avoin lähdekoodi ja saavutettavuus | Yhteisön lisenssi tietyin rajoituksin | Tavoitteena on avoin lähestymistapa tekoälyekosysteemin edistämiseen |
| Käytä koteloita | Optimoitu chatille ja koodin luomiseen | Laaja käyttö useilla verkkotunnuksilla keskittyen ohjeiden seuraamiseen |
Vertailutulokset muihin malleihin verrattuna
Llama 3 on nostanut rimaa generatiivisessa tekoälyssä ohittaen edeltäjänsä ja kilpailijansa useissa vertailuissa. Se on menestynyt erityisesti testeissä, kuten eri osa-alueiden tietoa arvioivassa MMLU:ssa ja koodaustaitoon keskittyvässä HumanEvalissa. Lisäksi Llama 3 on päihittänyt muut korkeaparametriset mallit, kuten Googlen Gemini 1.5 Pron ja Anthropicin Claude 3 Sonnetin, erityisesti monimutkaisissa päättely- ja ymmärtämistehtävissä.
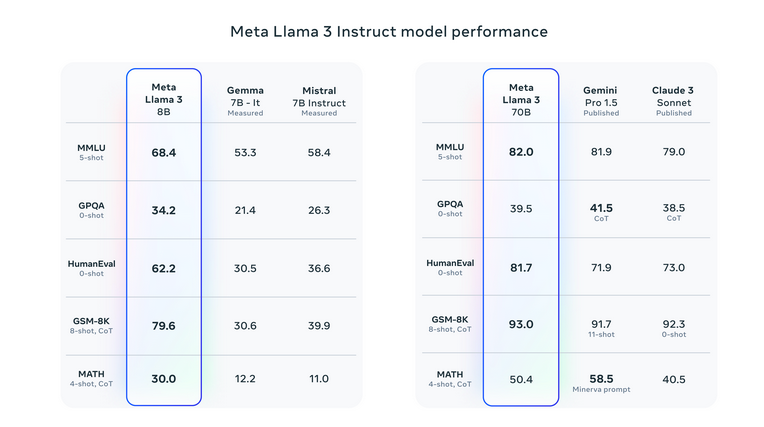
Katso arvioinnin yksityiskohdat asetuksille ja parametreille, joilla nämä arvioinnit lasketaan.
Arviointi vakio- ja mukautetuista testisarjoista
Meta on luonut ainutlaatuisia arviointisarjoja perinteisten vertailuarvojen lisäksi testatakseen Llama 3:a erilaisissa todellisissa sovelluksissa. Tämä räätälöity arviointikehys sisältää 1,800 12 kehotetta, jotka kattavat 3 kriittistä käyttötapausta: neuvojen antaminen, aivoriihi, luokittelu, sekä suljettuihin että avoimiin kysymyksiin vastaaminen, koodaus, luova koostumus, tiedon poiminta, roolileikit, looginen päättely, tekstin uudelleenkirjoittaminen ja yhteenveto. Pääsyn rajoittaminen tähän tiettyyn sarjaan, jopa Metan mallinnusryhmille, suojaa mallin mahdolliselta yliasennusta vastaan. Tämä tiukka testaustapa on osoittanut Llama XNUMX:n ylivoimaisen suorituskyvyn, joka usein ylittää muut mallit. Tämä korostaa sen sopeutumiskykyä ja ammattitaitoa.
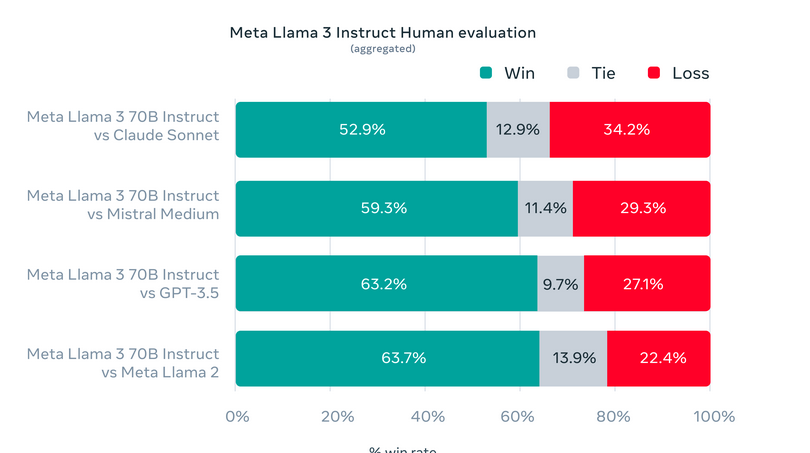
Katso arvioinnin yksityiskohdat asetuksille ja parametreille, joilla nämä arvioinnit lasketaan.
Koulutustiedot ja skaalausstrategiat
Tutkitaan nyt harjoitustietoja ja skaalausstrategioita:
Harjoittelutiedot
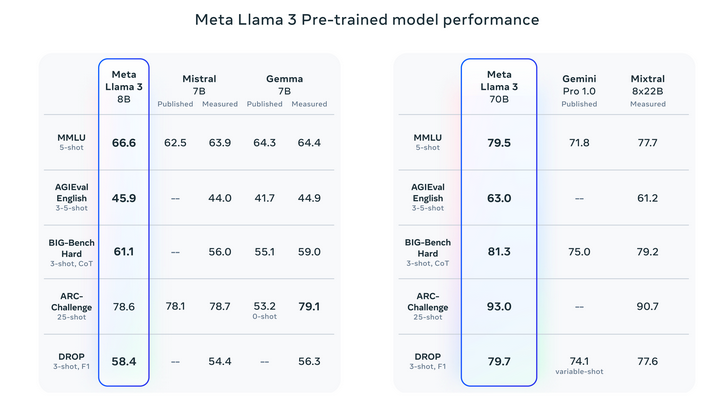
- Llama 3:n harjoitustietojoukko, yli 15 biljoonaa tokenia, on seitsemän kertaa suurempi kuin Llama 2.
- Tietojoukko sisältää neljä kertaa enemmän koodia ja yli 5 % korkealaatuista ei-englanninkielistä dataa 30 kielestä. Monipuolisen kielellisen edustuksen varmistaminen monikielisissä sovelluksissa.
- Tietojen laadun ylläpitämiseksi Meta käyttää kehittyneitä tietojen suodatusputkia, mukaan lukien heuristisia suodattimia, NSFW-suodattimia, semanttisia duplikaatioita ja tekstiluokituksia.
- Aiempien Llama-mallien oivalluksia hyödyntäen nämä järjestelmät tehostavat Llama 3:n koulutusta tunnistamalla ja sisällyttämällä laadukkaita tietoja.
Skaalausstrategiat
- Meta keskittyi maksimoimaan Llama 3:n tietojoukon hyödyllisyyttä kehittämällä yksityiskohtaisia skaalauslakeja.
- Tietojen yhdistelmän ja laskennallisten resurssien optimointi mahdollisti tarkan mallin suorituskyvyn ennustamisen eri tehtävissä.
- Strateginen ennakointi varmistaa vankan suorituskyvyn erilaisissa sovelluksissa, kuten trivia-, STEM-, koodaus- ja historiatiedoissa.
- Insights paljasti Chinchillan optimaalisen harjoituslaskennan määrän 8B-parametrimallille, noin 200 miljardia merkkiä.
- Sekä 8B- että 70B-mallit jatkavat suorituskyvyn parantamista log-lineaarisesti jopa 15 biljoonalla tokenilla.
- Meta saavutti yli 400 TFLOPS:a GPU:ta kohden käyttämällä 16,000 24,000 GPU:ta samanaikaisesti räätälöityjen XNUMX XNUMX GPU-klusterin kautta.
- Koulutusinfrastruktuurin innovaatiot sisältävät automaattisen virheiden havaitsemisen, järjestelmän ylläpidon ja skaalautuvat tallennusratkaisut.
- Nämä edistysaskeleet kolminkertaistivat Llama 3:n harjoittelutehokkuuden Llama 2:een verrattuna ja saavuttivat tehokkaan harjoitusajan yli 95 %.
- Nämä parannukset asettavat uudet standardit suurten kielimallien koulutukselle, mikä vie eteenpäin tekoälyn rajoja.
Hienosäätöohje
- Ohje-viritys parantaa esikoulutettujen chat-mallien toimivuutta.
- Prosessi yhdistää valvotun hienosäädön, hylkäysnäytteenoton, PPO:n ja DPO:n.
- Kehotteet SFT:ssä ja etusijajärjestykset PPO/DPO:ssa ovat tärkeitä mallin suorituskyvyn kannalta.
- Huolellinen tietojen kuratointi ja laadunvarmistus ihmisten toimesta.
- PPO/DPO:n etusijajärjestykset parantavat päättely- ja koodaustehtävien suorituskykyä.
- Mallit, jotka pystyvät tuottamaan oikeita vastauksia, mutta voivat kamppailla valinnan kanssa.
- Harjoittelu etusijajärjestyksen mukaan parantaa päätöksentekoa monimutkaisissa tehtävissä.
Llama3:n käyttöönotto
Llama 3 on asetettu laajalle saatavuudelle tärkeimmillä alustoilla, mukaan lukien pilvipalvelut ja mallisovellusliittymän tarjoajat. Siinä on parannettu tokenisointitehokkuus, joka vähentää merkkien käyttöä jopa 15 % verrattuna Llama 2:een, ja se sisältää Group Query Attention (GQA) -toiminnon 8B-mallissa päättelytehokkuuden ylläpitämiseksi jopa miljardilla lisäparametrilla Llama 1 2B:hen verrattuna. Avoimen lähdekoodin "Llama Recipes" tarjoaa kattavat resurssit käytännön käyttöönotto- ja optimointistrategioihin tukemalla Llama 7:n monipuolista sovellusta.
Llama 3:n parannukset ja turvallisuusominaisuudet
Llama 3 on suunniteltu tarjoamaan kehittäjille työkaluja ja joustavuutta räätälöidä sovelluksia erityistarpeiden mukaan. Se parantaa avointa tekoälyn ekosysteemiä. Tämä versio sisältää uusia turva- ja luottamustyökaluja, kuten Llama Guard 2:n, Cybersec Eval 2:n ja Code Shieldin, jotka auttavat suodattamaan epävarmaa koodia päättelyn aikana. Llama 3 on kehitetty yhteistyössä Torchtunen kanssa, PyTorch-natiivikirjaston kanssa, joka mahdollistaa tehokkaan, muistiystävällisen luomisen, hienosäädön ja LLM:ien testauksen. Tämä kirjasto tukee integrointia alustoihin, kuten Hugging Face ja Weights & Biases. Se myös helpottaa tehokasta päättelyä erilaisista laitteista Executorchin kautta.
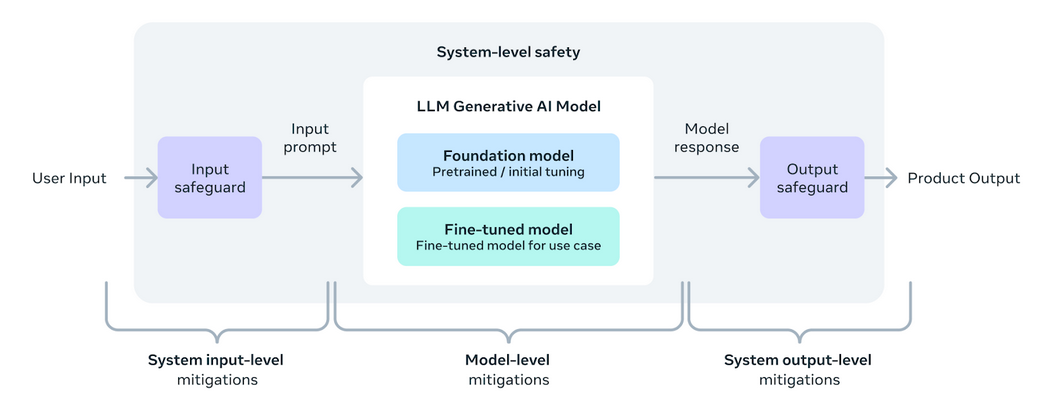
Järjestelmällinen lähestymistapa vastuulliseen käyttöönottoon varmistaa, että Llama 3 -mallit eivät ole vain hyödyllisiä vaan myös turvallisia. Ohjeiden hienosäätö on keskeinen komponentti, jota paransivat merkittävästi red-teaming-työt, jotka testaavat turvallisuutta ja kestävyyttä mahdollisia väärinkäytöksiä vastaan esimerkiksi kyberturvallisuuden alalla. Llama Guard 2:n käyttöönotto sisältää MLCommons-taksonomian, joka tukee alan standardien asettamista, kun taas CyberSecEval 2 parantaa turvatoimia koodin väärinkäyttöä vastaan.
Avoimen lähestymistavan omaksuminen Llama 3:n kehittämisessä pyrkii yhdistämään tekoälyyhteisön ja puuttumaan mahdollisiin riskeihin tehokkaasti. Meta on päivitetty Vastuullisen käytön opas (RUG) hahmottelee parhaat käytännöt sen varmistamiseksi, että kaikki mallin tulot ja lähdöt ovat turvallisuusstandardien mukaisia, ja niitä täydentävät pilvipalveluntarjoajien tarjoamat sisällönvalvontatyökalut. Nämä yhteiset pyrkimykset on suunnattu edistämään LLM:ien turvallista, vastuullista ja innovatiivista käyttöä eri sovelluksissa.
Llama 3:n tuleva kehitys
Llama 3 -mallien ensimmäinen julkaisu, mukaan lukien 8B- ja 70B-versiot. Se on vasta alkua tämän sarjan suunnitellulle kehitykselle. Meta kouluttaa parhaillaan entistä suurempia malleja yli 400 miljardilla parametrilla. Nämä mallit lupaavat parannettuja ominaisuuksia, kuten multimodaalisuutta, monikielistä viestintää, laajennettuja kontekstiikkunoita ja yleistä vahvempaa suorituskykyä. Tulevien kuukausien aikana nämä edistyneet mallit esitellään. Mukana on yksityiskohtainen tutkimuspaperi, jossa hahmotellaan Llama 3:n koulutuksen havaintoja. Meta on jakanut varhaisia tilannekuvia suurimman LLM-mallinsa jatkuvasta koulutuksesta ja tarjoaa näkemyksiä tulevista julkaisuista.
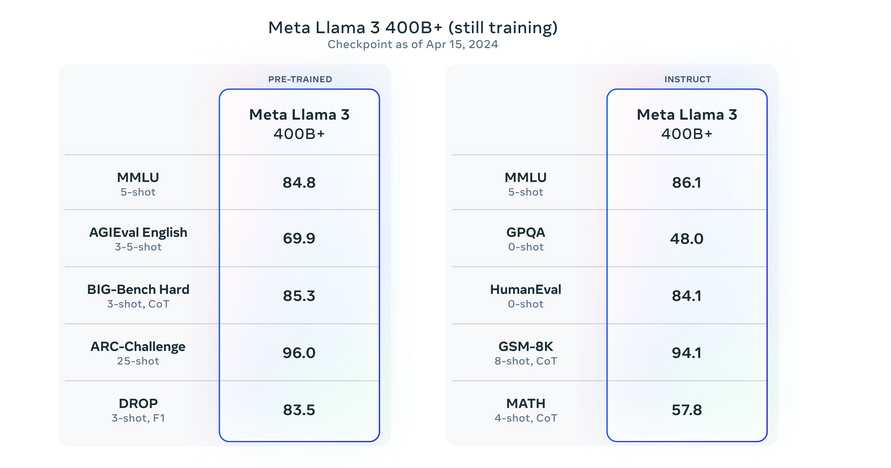
Katso arvioinnin yksityiskohdat asetuksille ja parametreille, joilla nämä arvioinnit lasketaan.
Laman vaikutus ja tuki 3
- Llama 3:sta tuli nopeasti nopein malli, joka saavutti Hugging Facen suosituimman paikan. Tämä ennätys saavutetaan vain muutaman tunnin sisällä sen julkaisusta.
Klikkaa tästä pääse linkkiin.
- Kun Llama 30,000:stä ja 1:sta on kehitetty 2 3 mallia, Llama XNUMX on valmis vaikuttamaan merkittävästi tekoälyn ekosysteemiin.
- Tärkeimmät tekoäly- ja pilvialustat, kuten AWS, Microsoft Azure, Google Cloud ja Hugging Face, sisällyttivät Llama 3:n nopeasti.
- Mallin läsnäolo Kagglessa laajentaa sen käytettävyyttä ja rohkaisee käytännönläheisempään tutkimiseen ja kehittämiseen datatieteen yhteisössä.
- Tämä LlamaIndexissä saatavilla oleva resurssi, jonka ovat koonneet asiantuntijat, kuten @ravithejads ja @LoganMarkewich, tarjoaa yksityiskohtaisia ohjeita Llama 3:n hyödyntämiseen useissa eri sovelluksissa yksinkertaisista tehtävistä monimutkaisiin RAG-putkiin. Napsauta tästä pääsylinkki.
Yhteenveto
Llama 3 asettaa uuden standardin suurten kielimallien kehityksessä. Ne parantavat tekoälyn ominaisuuksia useissa eri tehtävissä edistyneen arkkitehtuurin ja tehokkuuden ansiosta. Sen kattava testaus osoittaa ylivoimaisen suorituskyvyn, joka on parempi kuin edeltäjät ja nykyiset mallit. Vahvat koulutusstrategiat ja innovatiiviset turvallisuustoimenpiteet, kuten Llama Guard 2 ja Cybersec Eval 2. Llama 3 korostaa Metan sitoutumista vastuulliseen tekoälykehitykseen. Kun Llama 3 tulee laajalti saataville, se lupaa edistää merkittäviä edistysaskeleita tekoälysovelluksissa. Tarjoaa myös kehittäjille tehokkaan työkalun teknologian rajojen tutkimiseen ja laajentamiseen.
- SEO-pohjainen sisällön ja PR-jakelu. Vahvista jo tänään.
- PlatoData.Network Vertical Generatiivinen Ai. Vahvista itseäsi. Pääsy tästä.
- PlatoAiStream. Web3 Intelligence. Tietoa laajennettu. Pääsy tästä.
- PlatoESG. hiili, CleanTech, energia, ympäristö, Aurinko, Jätehuolto. Pääsy tästä.
- PlatonHealth. Biotekniikan ja kliinisten kokeiden älykkyys. Pääsy tästä.
- Lähde: https://www.analyticsvidhya.com/blog/2024/04/meta-llama-3-redefining-large-language-model-standards/

