Nykyään asiakkaat kaikilla toimialoilla – olipa kyseessä sitten rahoituspalvelut, terveydenhuolto ja biotieteet, matkailu ja vieraanvaraisuus, media ja viihde, tietoliikenne, ohjelmistot palveluna (SaaS) ja jopa patentoitujen mallien tarjoajat – käyttävät suuria kielimalleja (LLM) rakentaa sovelluksia, kuten kysymys ja vastaus (QnA) chatbotteja, hakukoneita ja tietokantoja. Nämä generatiivinen tekoäly sovelluksia ei käytetä vain olemassa olevien liiketoimintaprosessien automatisointiin, vaan niillä on myös mahdollisuus muuttaa näitä sovelluksia käyttävien asiakkaiden kokemusta. Edistyksillä, joita tehdään LLM:ien, kuten Mixtral-8x7B ohje, johdannainen arkkitehtuureista, kuten asiantuntijoiden sekoitus (KM), asiakkaat etsivät jatkuvasti tapoja parantaa generatiivisten tekoälysovellusten suorituskykyä ja tarkkuutta samalla kun he voivat käyttää tehokkaasti laajempaa valikoimaa suljetun ja avoimen lähdekoodin malleja.
Useita tekniikoita käytetään tyypillisesti parantamaan LLM:n lähdön tarkkuutta ja suorituskykyä, kuten hienosäätöä parametritehokas hienosäätö (PEFT), vahvistusoppiminen ihmispalautteesta (RLHF), ja esiintyminen tiedon tislaus. Kun rakennat generatiivisia tekoälysovelluksia, voit kuitenkin käyttää vaihtoehtoista ratkaisua, joka mahdollistaa ulkoisen tiedon dynaamisen sisällyttämisen ja antaa sinun hallita luomiseen käytettyä tietoa ilman, että sinun tarvitsee hienosäätää olemassa olevaa perusmalliasi. Tässä tulee esiin Retrieval Augmented Generation (RAG), erityisesti generatiivisille tekoälysovelluksille verrattuna keskustelemiimme kalliimpiin ja vankempiin hienosäätövaihtoehtoihin. Jos käytät monimutkaisia RAG-sovelluksia päivittäisiin tehtäviisi, saatat kohdata RAG-järjestelmissäsi yleisiä haasteita, kuten epätarkkoja hakuja, asiakirjojen kasvavaa kokoa ja monimutkaisuutta sekä kontekstin ylivuotoa, mikä voi vaikuttaa merkittävästi luotujen vastausten laatuun ja luotettavuuteen. .
Tässä viestissä käsitellään RAG-malleja, joilla parannetaan vastaustarkkuutta LangChainilla ja työkaluilla, kuten pääasiakirjan noutajalla, sekä tekniikoiden, kuten kontekstuaalisen pakkauksen, lisäksi, jotta kehittäjät voivat parantaa olemassa olevia luovia tekoälysovelluksia.
Ratkaisun yleiskatsaus
Tässä viestissä esittelemme Mixtral-8x7B Instruct -tekstinluonnin käyttöä yhdistettynä BGE Large En -upotusmalliin RAG QnA -järjestelmän tehokkaaseen rakentamiseen Amazon SageMaker -muistikirjaan käyttämällä pääasiakirjan palautustyökalua ja kontekstuaalista pakkaustekniikkaa. Seuraava kaavio havainnollistaa tämän ratkaisun arkkitehtuuria.
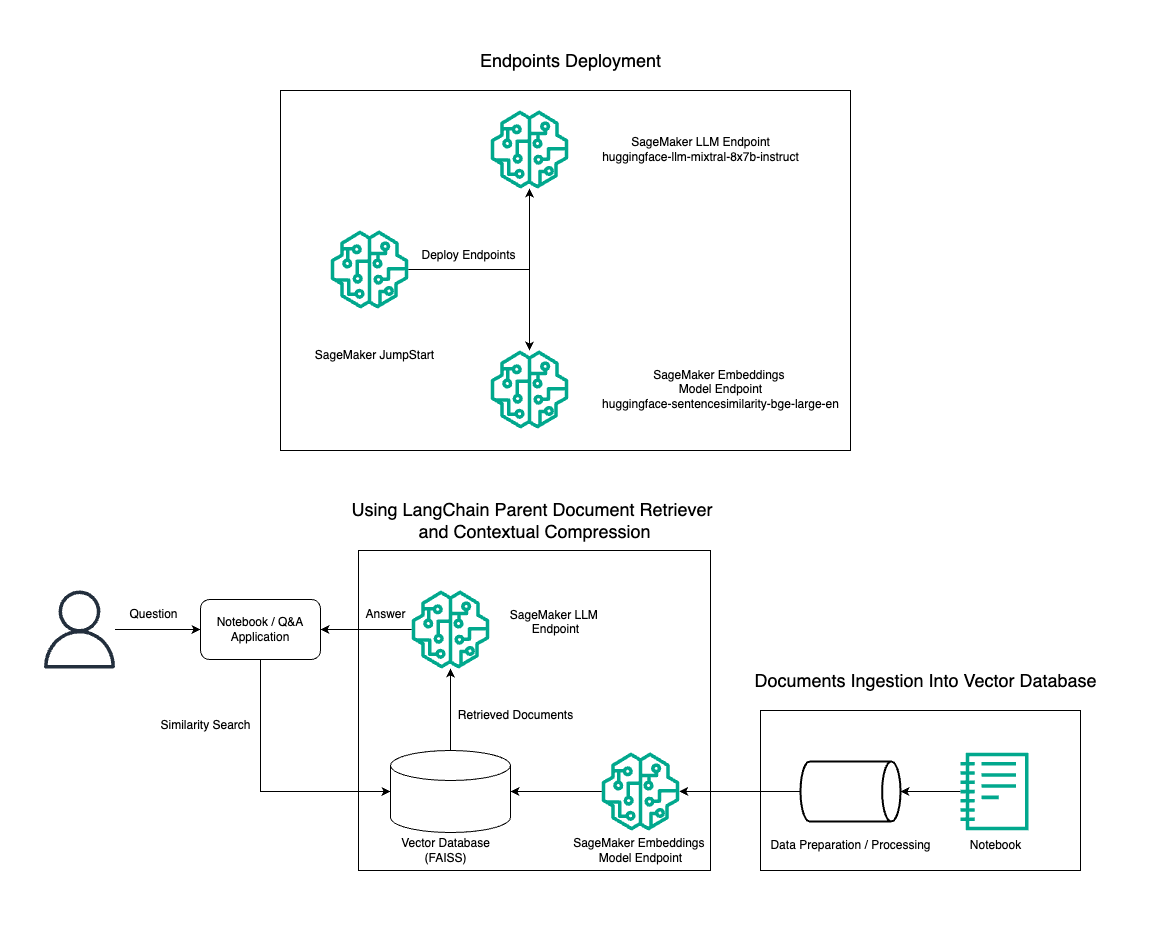
Voit ottaa tämän ratkaisun käyttöön vain muutamalla napsautuksella Amazon SageMaker JumpStart, täysin hallittu alusta, joka tarjoaa huippuluokan perusmalleja erilaisiin käyttötapauksiin, kuten sisällön kirjoittamiseen, koodin luomiseen, kysymyksiin vastaamiseen, tekstin kirjoittamiseen, yhteenvetoon, luokitteluun ja tiedonhakuun. Se tarjoaa kokoelman esikoulutettuja malleja, jotka voit ottaa käyttöön nopeasti ja helposti, mikä nopeuttaa koneoppimissovellusten (ML) kehitystä ja käyttöönottoa. Yksi SageMaker JumpStartin avainkomponenteista on Model Hub, joka tarjoaa laajan valikoiman esikoulutettuja malleja, kuten Mixtral-8x7B, erilaisiin tehtäviin.
Mixtral-8x7B käyttää MoE-arkkitehtuuria. Tämä arkkitehtuuri mahdollistaa hermoverkon eri osien erikoistumisen erilaisiin tehtäviin, mikä jakaa työtaakan tehokkaasti useiden asiantuntijoiden kesken. Tämä lähestymistapa mahdollistaa perinteisiin arkkitehtuureihin verrattuna suurempien mallien tehokkaan koulutuksen ja käyttöönoton.
Yksi MoE-arkkitehtuurin tärkeimmistä eduista on sen skaalautuvuus. Jakamalla työtaakka useille asiantuntijoille, MoE-malleja voidaan kouluttaa suurempiin tietokokonaisuuksiin ja saavuttaa parempi suorituskyky kuin perinteiset samankokoiset mallit. Lisäksi MoE-mallit voivat olla tehokkaampia päättelyn aikana, koska vain osa asiantuntijoita tarvitsee aktivoida tietylle syötteelle.
Lisätietoja Mixtral-8x7B Instructista AWS:ssä on kohdassa Mixtral-8x7B on nyt saatavilla Amazon SageMaker JumpStartissa. Mixtral-8x7B-malli on saatavilla sallitulla Apache 2.0 -lisenssillä käytettäväksi ilman rajoituksia.
Tässä viestissä keskustelemme siitä, miten voit käyttää LangChain luoda tehokkaita ja tehokkaampia RAG-sovelluksia. LangChain on avoimen lähdekoodin Python-kirjasto, joka on suunniteltu rakentamaan sovelluksia LLM:ien kanssa. Se tarjoaa modulaarisen ja joustavan kehyksen LLM:ien yhdistämiseen muihin komponentteihin, kuten tietokantoihin, hakujärjestelmiin ja muihin tekoälytyökaluihin, tehokkaiden ja mukautettavien sovellusten luomiseksi.
Käymme läpi RAG-putkilinjan rakentamisen SageMakerissa Mixtral-8x7B:llä. Käytämme Mixtral-8x7B Instruct -tekstin luontimallia BGE Large En -upotusmallin kanssa luodaksemme tehokkaan QnA-järjestelmän käyttämällä RAG:ta SageMaker-muistikirjassa. Käytämme ml.t3.medium-instanssia esitelläksemme LLM:ien käyttöönottoa SageMaker JumpStartin kautta, jota voidaan käyttää SageMakerin luoman API-päätepisteen kautta. Tämä asennus mahdollistaa edistyneiden RAG-tekniikoiden tutkimisen, kokeilun ja optimoinnin LangChainin avulla. Havainnollistamme myös FAISS Embedding -myymälän integroimista RAG-työnkulkuun korostaen sen roolia upotusten tallentamisessa ja noutamisessa järjestelmän suorituskyvyn parantamiseksi.
Suoritamme lyhyen esittelyn SageMaker-muistikirjasta. Katso tarkemmat ja vaiheittaiset ohjeet kohdasta Kehittyneet RAG-mallit Mixtralin kanssa SageMaker Jumpstart GitHub -repossa.
Edistyneiden RAG-kuvioiden tarve
Kehittyneet RAG-mallit ovat välttämättömiä, jotta voidaan parantaa LLM:iden nykyisiä kykyjä käsitellä, ymmärtää ja luoda ihmisen kaltaista tekstiä. Asiakirjojen koon ja monimutkaisuuden kasvaessa asiakirjan useiden osien edustaminen yhdessä upotuksessa voi johtaa tarkkuuden menettämiseen. Vaikka asiakirjan yleisen olemuksen vangitseminen on välttämätöntä, on yhtä tärkeää tunnistaa ja edustaa sen sisältämät vaihtelevat osakontekstit. Tämä on haaste, jonka kohtaat usein, kun käsittelet suurempia asiakirjoja. Toinen RAG:n haaste on, että noudon yhteydessä et ole tietoinen erityisistä kyselyistä, joita asiakirjojen tallennusjärjestelmäsi käsittelee käsiteltäessä. Tämä voi johtaa siihen, että kyselyn kannalta oleellisimmat tiedot jäävät tekstin alle (kontekstin ylivuoto). Voit vähentää virheitä ja parantaa olemassa olevaa RAG-arkkitehtuuria käyttämällä kehittyneitä RAG-malleja (emoasiakirjan noutaja ja kontekstuaalinen pakkaus) vähentämään hakuvirheitä, parantamaan vastausten laatua ja mahdollistamaan monimutkaisen kysymysten käsittelyn.
Tässä viestissä käsiteltyjen tekniikoiden avulla voit käsitellä ulkoisen tiedon hakuun ja integroimiseen liittyviä keskeisiä haasteita, jolloin sovelluksesi voi tarjota tarkempia ja kontekstuaalisesti tietoisempia vastauksia.
Seuraavissa osioissa tutkimme, miten vanhempien asiakirjojen noutajat ja kontekstuaalinen pakkaus voi auttaa sinua käsittelemään joitain käsittelemiämme ongelmia.
Vanhemman asiakirjan noutaja
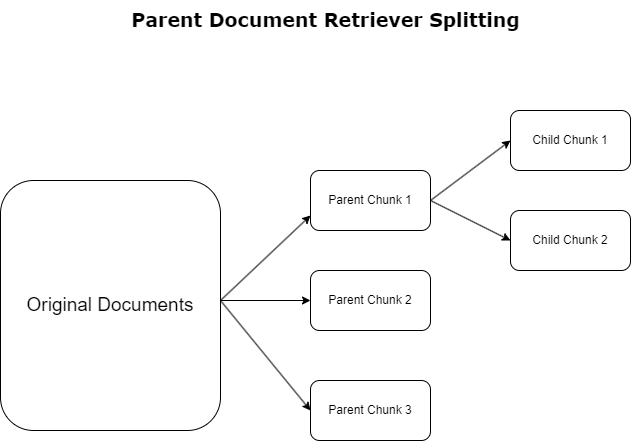
Edellisessä osiossa korostimme haasteita, joita RAG-sovellukset kohtaavat käsitellessään laajoja asiakirjoja. Vastatakseen näihin haasteisiin, vanhempien asiakirjojen noutajat luokitella ja nimetä saapuvat asiakirjat nimellä vanhempien asiakirjat. Nämä asiakirjat tunnetaan kattavasta luonteestaan, mutta niitä ei käytetä suoraan alkuperäisessä muodossaan upotuksiin. Sen sijaan, että pakkaaisit koko asiakirjan yhdeksi upotukseksi, pääasiakirjan noutajat hajottavat nämä pääasiakirjat lasten asiakirjat. Jokainen aladokumentti kaappaa eri näkökohtia tai aiheita laajemmasta pääasiakirjasta. Näiden alatason segmenttien tunnistamisen jälkeen kullekin kohdistetaan yksittäiset upotukset, jotka kuvaavat niiden erityistä temaattista olemusta (katso seuraava kaavio). Haun aikana pääasiakirjaa vedetään. Tämä tekniikka tarjoaa kohdistettuja mutta laaja-alaisia hakuominaisuuksia ja tarjoaa LLM:lle laajemman näkökulman. Pääasiakirjan noutajat tarjoavat LLM:ille kaksinkertaisen edun: alatason asiakirjojen upotusten spesifisyys tarkan ja relevantin tiedon hakuun yhdistettynä emoasiakirjojen kutsumiseen vastausten luomista varten, mikä rikastaa LLM:n tuloksia kerroksellisella ja perusteellisella kontekstilla.
Kontekstuaalinen pakkaus
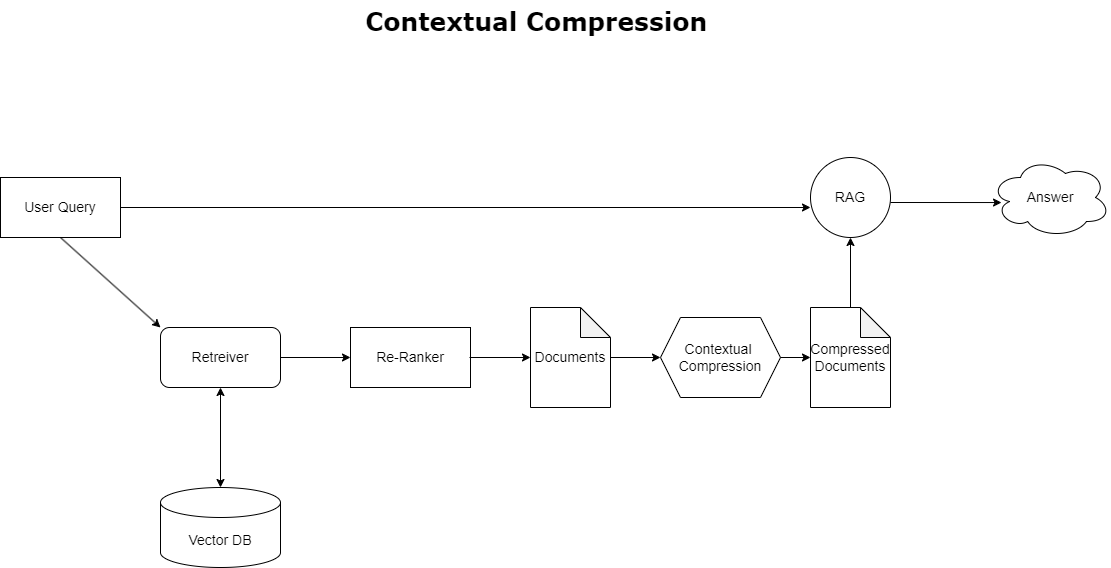
Voit ratkaista aiemmin käsitellyn kontekstin ylivuotoongelman käyttämällä kontekstuaalinen pakkaus pakata ja suodattaa haetut asiakirjat kyselyn kontekstin mukaisesti, joten vain asiaankuuluvat tiedot säilytetään ja käsitellään. Tämä saavutetaan yhdistämällä perusnoutaja alkuperäisen asiakirjan noutoon ja asiakirjapakkauslaite, joka jalostaa näitä asiakirjoja pienentämällä niiden sisältöä tai sulkemalla ne kokonaan pois merkityksellisyyden perusteella, kuten seuraavassa kaaviossa näkyy. Tämä virtaviivaistettu lähestymistapa, jota helpottaa kontekstuaalinen pakkauksen noutaja, parantaa huomattavasti RAG-sovellusten tehokkuutta tarjoamalla menetelmän, jolla voidaan poimia ja käyttää vain olennaista tietomassasta. Se käsittelee tiedon ylikuormitusta ja epäolennaista tietojenkäsittelyä suoraan, mikä johtaa parempaan vastausten laatuun, kustannustehokkaampiin LLM-toimintoihin ja sujuvampaan yleiseen hakuprosessiin. Pohjimmiltaan se on suodatin, joka räätälöi tiedot käsillä olevaan kyselyyn, mikä tekee siitä erittäin tarpeellisen työkalun kehittäjille, jotka pyrkivät optimoimaan RAG-sovelluksensa suorituskyvyn ja käyttäjätyytyväisyyden parantamiseksi.
Edellytykset
Jos olet uusi SageMaker-käyttäjä, katso Amazon SageMaker -kehitysopas.
Ennen kuin aloitat ratkaisun, luo AWS-tili. Kun luot AWS-tilin, saat kertakirjautumistunnuksen (SSO), jolla on täydellinen pääsy kaikkiin tilin AWS-palveluihin ja resursseihin. Tätä identiteettiä kutsutaan AWS-tiliksi root-käyttäjä.
Kirjautuminen palveluun AWS-hallintakonsoli käyttämällä sähköpostiosoitetta ja salasanaa, joita käytit tilin luomiseen, saat täydellisen pääsyn kaikkiin tilisi AWS-resursseihin. Suosittelemme, että et käytä pääkäyttäjää päivittäisiin tehtäviin, edes hallinnollisiin tehtäviin.
Noudata sen sijaan turvallisuuden parhaat käytännöt in AWS-henkilöllisyyden ja käyttöoikeuksien hallinta (IAM) ja luo järjestelmänvalvojan käyttäjä ja ryhmä. Lukitse sitten turvallisesti pääkäyttäjän tunnistetiedot ja käytä niitä vain muutaman tilin ja palvelun hallintatehtävän suorittamiseen.
Mixtral-8x7b-malli vaatii ml.g5.48xlarge-instanssin. SageMaker JumpStart tarjoaa yksinkertaistetun tavan käyttää ja ottaa käyttöön yli 100 erilaista avoimen lähdekoodin ja kolmannen osapuolen perusmallia. Jotta käynnistää päätepiste Mixtral-8x7B:n isännöintiin SageMaker JumpStartista, saatat joutua pyytämään palvelukiintiön lisäystä päästäksesi ml.g5.48xlarge-instanssiin päätepisteen käyttöä varten. Sinä pystyt Pyydä palvelukiintiöitä konsolin kautta, AWS-komentoriviliitäntä (AWS CLI) tai API sallia pääsyn näihin lisäresursseihin.
Määritä SageMaker-muistikirjan esiintymä ja asenna riippuvuudet
Aloita luomalla SageMaker-muistikirjan esiintymä ja asentamalla tarvittavat riippuvuudet. Viittaavat GitHub repo onnistuneen asennuksen varmistamiseksi. Kun olet määrittänyt muistikirjan ilmentymän, voit ottaa mallin käyttöön.
Voit myös käyttää muistikirjaa paikallisesti haluamassasi integroidussa kehitysympäristössä (IDE). Varmista, että sinulla on Jupyter Notebook Lab asennettuna.
Ota käyttöön malli
Ota Mixtral-8X7B Instruct LLM -malli käyttöön SageMaker JumpStartissa:
Ota BGE Large En -upotusmalli käyttöön SageMaker JumpStartissa:
Asenna LangChain
Kun olet tuonut kaikki tarvittavat kirjastot ja ottanut käyttöön Mixtral-8x7B-mallin ja BGE Large En -upotusmallin, voit nyt määrittää LangChainin. Katso vaiheittaiset ohjeet kohdasta GitHub repo.
Tietojen valmistelu
Tässä viestissä käytämme useiden vuosien ajan Amazonin kirjeitä osakkeenomistajille tekstikorpusena QnA:n suorittamiseen. Katso tarkemmat vaiheet tietojen valmistelemiseksi kohdasta GitHub repo.
Kysymykseen vastaaminen
Kun tiedot on valmisteltu, voit käyttää LangChainin tarjoamaa käärettä, joka kiertää vektorivaraston ja ottaa syötteen LLM:tä varten. Tämä kääre suorittaa seuraavat vaiheet:
- Ota syöttökysymys.
- Luo kysymyksen upotus.
- Hae asiaankuuluvat asiakirjat.
- Sisällytä asiakirjat ja kysymys kehotteeseen.
- Kutsu malli kehotteen avulla ja luo vastaus luettavalla tavalla.
Nyt kun vektorivarasto on paikallaan, voit alkaa esittää kysymyksiä:
Tavallinen noutajaketju
Edellisessä skenaariossa tutkimme nopeaa ja suoraviivaista tapaa saada kontekstitietoinen vastaus kysymykseesi. Katsotaan nyt muokattavampaa vaihtoehtoa RetrievalQA:n avulla, jossa voit mukauttaa, kuinka haetut asiakirjat lisätään kehotteeseen ketjun_tyyppi-parametrin avulla. Lisäksi, jotta voit hallita, kuinka monta asiaankuuluvaa dokumenttia tulee noutaa, voit muuttaa seuraavan koodin k-parametria nähdäksesi erilaiset tulosteet. Monissa tilanteissa saatat haluta tietää, mitä lähdeasiakirjoja LLM käytti vastauksen luomiseen. Voit saada ne asiakirjat tulosteeseen käyttämällä return_source_documents, joka palauttaa asiakirjat, jotka on lisätty LLM-kehotteen kontekstiin. RetrievalQA antaa sinun tarjota myös mukautetun kehotemallin, joka voi olla mallikohtainen.
Esitetään kysymys:
Vanhemman asiakirjan noutajaketju
Katsotaanpa edistyneempää RAG-vaihtoehtoa avulla ParentDocumentRetriever. Kun työskentelet asiakirjojen noudon parissa, saatat kohdata kompromissin, jossa tallennat asiakirjan pieniä paloja tarkkoja upotuksia varten ja suurempia asiakirjoja kontekstin säilyttämiseksi. Pääasiakirjan noutaja saavuttaa tämän tasapainon jakamalla ja tallentamalla pieniä tietopaloja.
Käytämme a parent_splitter jakaa alkuperäiset asiakirjat suurempiin osiin, joita kutsutaan pääasiakirjoiksi ja a child_splitter luodaksesi pienempiä aliasiakirjoja alkuperäisistä asiakirjoista:
Aliasiakirjat indeksoidaan sitten vektorivarastossa upotuksia käyttämällä. Tämä mahdollistaa asiaankuuluvien aliasiakirjojen tehokkaan haun samankaltaisuuden perusteella. Asianmukaisten tietojen hakemiseksi pääasiakirjan noutaja hakee ensin aliasiakirjat vektorivarastosta. Sitten se etsii näiden aliasiakirjojen ylätason tunnukset ja palauttaa vastaavat suuremmat ylätason asiakirjat.
Esitetään kysymys:
Kontekstuaalinen pakkausketju
Katsotaanpa toista kehittynyttä RAG-vaihtoehtoa nimeltä kontekstuaalinen pakkaus. Haasteena on se, että emme yleensä tiedä, mitä kyselyitä asiakirjojen tallennusjärjestelmäsi kohtaa, kun syötät tietoja järjestelmään. Tämä tarkoittaa, että kyselyn kannalta oleellisimmat tiedot voivat olla hautautuneita dokumenttiin, jossa on paljon epäolennaista tekstiä. Täydellisen asiakirjan välittäminen hakemuksesi läpi voi johtaa kalliimpiin LLM-puheluihin ja huonompiin vastauksiin.
Kontekstuaalinen pakkauksen noutaja vastaa haasteeseen, joka liittyy asiaankuuluvien tietojen hakemiseen asiakirjojen tallennusjärjestelmästä, jossa asiaankuuluvat tiedot voivat haudata paljon tekstiä sisältäviin asiakirjoihin. Pakkaamalla ja suodattamalla haetut asiakirjat tietyn kyselykontekstin perusteella, vain oleellisimmat tiedot palautetaan.
Jos haluat käyttää kontekstuaalista pakkausta, tarvitset:
- Perusnoutaja – Tämä on ensimmäinen noutaja, joka hakee asiakirjat tallennusjärjestelmästä kyselyn perusteella
- Asiakirjan kompressori – Tämä komponentti ottaa alun perin haetut asiakirjat ja lyhentää niitä vähentämällä yksittäisten asiakirjojen sisältöä tai hylkäämällä epäolennaiset asiakirjat kokonaan, käyttämällä kyselykontekstia asianmukaisuuden määrittämiseen.
Kontekstikohtaisen pakkauksen lisääminen LLM-ketjunpoistimella
Kääri ensin perusnoutajasi a ContextualCompressionRetriever. Lisäät an LLMChainExtractor, joka toistaa alun perin palautetut asiakirjat ja poimii kustakin vain kyselyn kannalta merkityksellisen sisällön.
Alusta ketju käyttämällä ContextualCompressionRetriever kanssa LLMChainExtractor ja välitä kehote chain_type_kwargs Perustelu.
Esitetään kysymys:
Suodata asiakirjat LLM-ketjusuodattimella
- LLMChainFilter on hieman yksinkertaisempi mutta tehokkaampi kompressori, joka päättää LLM-ketjun avulla, mitkä alun perin haetuista asiakirjoista suodatetaan pois ja mitkä palautetaan, ilman, että asiakirjan sisältöä käsitellään:
Alusta ketju käyttämällä ContextualCompressionRetriever kanssa LLMChainFilter ja välitä kehote chain_type_kwargs Perustelu.
Esitetään kysymys:
Vertaa tuloksia
Seuraavassa taulukossa vertaillaan tuloksia eri kyselyistä tekniikan mukaan.
| Tekniikka | Kysely 1 | Kysely 2 | Vertailu |
| Miten AWS kehittyi? | Miksi Amazon menestyy? | ||
| Tavallinen noutajaketjutulostus | AWS (Amazon Web Services) kehittyi alun perin kannattamattomasta sijoituksesta 85 miljardin dollarin vuotuiseksi liiketoiminnaksi, jolla on vahva kannattavuus ja joka tarjoaa laajan valikoiman palveluita ja ominaisuuksia, ja siitä tuli merkittävä osa Amazonin portfoliota. Huolimatta skeptisyydestä ja lyhytaikaisista vastatuulesta AWS jatkoi innovointia, uusien asiakkaiden houkuttelemista ja aktiivisten asiakkaiden siirtoa tarjoten etuja, kuten ketteryyttä, innovaatioita, kustannustehokkuutta ja turvallisuutta. AWS laajensi myös pitkän aikavälin investointejaan, mukaan lukien sirukehitys, tarjotakseen uusia ominaisuuksia ja muuttaakseen asiakkaidensa mahdollisuuksia. | Amazon menestyy jatkuvan innovaationsa ja laajentumisen ansiosta uusille alueille, kuten teknologiainfrastruktuuripalveluihin, digitaalisiin lukulaitteisiin, ääniohjattuihin henkilökohtaisiin avustajiin ja uusiin liiketoimintamalleihin, kuten kolmansien osapuolien markkinapaikalle. Sen kyky skaalata toimintaa nopeasti, mikä näkyy sen toimitus- ja kuljetusverkostojen nopeana laajentumisena, edistää myös sen menestystä. Lisäksi Amazonin keskittyminen prosessiensa optimointiin ja tehokkuuden parantamiseen on johtanut tuottavuuden parannuksiin ja kustannusten alentamiseen. Amazon Businessin esimerkki korostaa yrityksen kykyä hyödyntää sähköisen kaupankäynnin ja logistiikan vahvuuksiaan eri sektoreilla. | Tavallisen noutajaketjun vastausten perusteella huomaamme, että vaikka se tarjoaa pitkiä vastauksia, se kärsii kontekstin ylivuotosta eikä mainitse mitään merkittäviä yksityiskohtia korpuksesta koskien annettuun kyselyyn vastaamista. Tavallinen hakuketju ei pysty vangitsemaan vivahteita syvyyden tai kontekstuaalisen näkemyksen avulla, mikä saattaa puuttua asiakirjan kriittisistä osista. |
| Parent Document Retriever Output | AWS (Amazon Web Services) aloitti Elastic Compute Cloud (EC2) -palvelun ominaisuuksien puutteellisella lanseerauksella vuonna 2006, ja se tarjosi vain yhden ilmentymän koon, yhdessä palvelinkeskuksessa, yhdellä maailman alueella, ja vain Linux-käyttöjärjestelmän esiintymiä. , ja ilman monia tärkeitä ominaisuuksia, kuten valvontaa, kuormituksen tasapainotusta, automaattista skaalausta tai jatkuvaa tallennusta. AWS:n menestys kuitenkin antoi heille mahdollisuuden nopeasti iteroida ja lisätä puuttuvia ominaisuuksia, ja lopulta ne laajenivat tarjoamaan erilaisia makuja, kokoja ja optimointeja laskentaan, varastointiin ja verkkoon sekä kehittämään omia siruja (Graviton) nostaakseen hintaa ja suorituskykyä entisestään. . AWS:n iteratiivinen innovaatioprosessi vaati merkittäviä investointeja taloudellisiin ja henkilöresursseihin yli 20 vuoden ajan, usein hyvissä ajoin ennen kuin se maksaa, vastatakseen asiakkaiden tarpeisiin ja parantaakseen pitkäaikaisia asiakaskokemuksia, uskollisuutta ja osakkeenomistajien tuottoa. | Amazon menestyy, koska se pystyy jatkuvasti innovoimaan, mukautumaan muuttuviin markkinaolosuhteisiin ja vastaamaan asiakkaiden tarpeisiin eri markkinasegmenteillä. Tämä näkyy Amazon Businessin menestyksessä, joka on kasvanut noin 35 miljardin dollarin vuosittaiseen bruttomyyntiin tarjoamalla yritysasiakkaille valikoimaa, arvoa ja mukavuutta. Amazonin investoinnit verkkokauppaan ja logistiikkaominaisuuksiin ovat myös mahdollistaneet sellaisten palvelujen luomisen, kuten Buy with Prime, joka auttaa kauppiaita, joilla on suorat kuluttajasivustot, ohjaamaan konversioita näyttökerroista ostoksiin. | Pääasiakirjan noutaja sukeltaa syvemmälle AWS:n kasvustrategian erityispiirteisiin, mukaan lukien iteratiiviseen uusien ominaisuuksien lisäämisprosessiin asiakaspalautteen perusteella ja yksityiskohtaisen matkan ominaisuuksiltaan puutteellisesta alkuperäisestä lanseerauksesta hallitsevaan markkina-asemaan ja tarjoaa samalla kontekstirikkaan vastauksen. . Vastaukset kattavat monenlaisia näkökohtia teknisistä innovaatioista ja markkinastrategiasta organisaation tehokkuuteen ja asiakaslähtöisyyteen. Ne tarjoavat esimerkkien ohella kokonaisvaltaisen näkemyksen menestykseen vaikuttavista tekijöistä. Tämä johtuu pääasiakirjan noutajan kohdistetuista mutta monipuolisista hakuominaisuuksista. |
| LLM Chain Extractor: Contextual Compression Output | AWS kehittyi aloittamalla pienestä projektista Amazonin sisällä, joka vaati merkittäviä pääomasijoituksia ja kohtasi skeptisisyyttä sekä yrityksen sisältä että ulkopuolelta. AWS:llä oli kuitenkin etumatka mahdollisiin kilpailijoihin nähden, ja se uskoi arvoon, jonka se voisi tuoda asiakkaille ja Amazonille. AWS sitoutui pitkällä aikavälillä jatkamaan investointeja, minkä seurauksena vuonna 3,300 lanseerattiin yli 2022 85 uutta ominaisuutta ja palvelua. AWS on muuttanut tapaa, jolla asiakkaat hallitsevat teknologiainfrastruktuuriaan, ja siitä on tullut 2 miljardin dollarin vuotuinen liikevaihto ja vahva kannattavuus. AWS on myös jatkuvasti parantanut tarjontaansa, kuten parantanut ECXNUMX:ta lisäominaisuuksilla ja palveluilla sen ensimmäisen julkaisun jälkeen. | Annetun kontekstin perusteella Amazonin menestys johtuu sen strategisesta laajentumisesta kirjojen myyntialustasta globaalille markkinapaikalle, jossa on vilkas kolmannen osapuolen myyjäekosysteemi, varhaisesta investoinnista AWS:ään, innovaatioihin Kindlen ja Alexan käyttöönotossa sekä merkittävään kasvuun. vuosiliikevaihdossa vuosina 2019–2022. Tämä kasvu johti toimituskeskusten jalanjäljen laajentamiseen, viimeisen mailin kuljetusverkoston luomiseen ja uuden lajittelukeskusverkoston rakentamiseen, jotka optimoitiin tuottavuutta ja kustannussäästöjä varten. | LLM-ketjuimuri säilyttää tasapainon avainkohtien kattavan peittämisen ja tarpeettoman syvyyden välttämisen välillä. Se mukautuu dynaamisesti kyselyn kontekstiin, joten tulos on suoraan relevantti ja kattava. |
| LLM-ketjusuodatin: kontekstuaalinen pakkaustulostus | AWS (Amazon Web Services) kehittyi lanseeraamalla alun perin ominaisuuksiltaan heikkoja, mutta toistuvia nopeasti asiakkaiden palautteen perusteella tarvittavien ominaisuuksien lisäämiseksi. Tämän lähestymistavan ansiosta AWS saattoi käynnistää EC2:n vuonna 2006 rajoitetuilla ominaisuuksilla ja lisätä sitten jatkuvasti uusia toimintoja, kuten ylimääräisiä ilmentymien kokoja, datakeskuksia, alueita, käyttöjärjestelmävaihtoehtoja, valvontatyökaluja, kuormituksen tasapainotusta, automaattista skaalausta ja jatkuvaa tallennusta. Ajan myötä AWS muuttui ominaisuuksiltaan huonosta palvelusta usean miljardin dollarin yritykseksi keskittymällä asiakkaiden tarpeisiin, ketteryyteen, innovaatioihin, kustannustehokkuuteen ja turvallisuuteen. AWS:n vuotuinen liikevaihto on nyt 85 miljardia dollaria, ja se tarjoaa vuosittain yli 3,300 XNUMX uutta ominaisuutta ja palvelua, jotka palvelevat laajaa asiakaskuntaa aloittavista yrityksistä monikansallisiin yrityksiin ja julkisen sektorin organisaatioihin. | Amazon menestyy innovatiivisten liiketoimintamalliensa, jatkuvan teknologisen kehityksensä ja strategisten organisaatiomuutosten ansiosta. Yritys on jatkuvasti häirinnyt perinteisiä toimialoja ottamalla käyttöön uusia ideoita, kuten verkkokauppaalustan eri tuotteille ja palveluille, kolmannen osapuolen markkinapaikan, pilviinfrastruktuuripalvelut (AWS), Kindle-e-lukijan ja Alexa ääniohjatun henkilökohtaisen avustajan. . Lisäksi Amazon on tehnyt rakenteellisia muutoksia parantaakseen tehokkuuttaan, kuten uudelleenorganisoinut Yhdysvaltain toimitusverkostonsa kustannusten ja toimitusaikojen alentamiseksi, mikä on edelleen edistänyt sen menestystä. | LLM-ketjusuodattimen tapaan LLM-ketjusuodatin varmistaa, että vaikka keskeiset kohdat on katettu, tulos on tehokas asiakkaille, jotka etsivät ytimekkäitä ja kontekstuaalisia vastauksia. |
Vertailemalla näitä eri tekniikoita voimme nähdä, että esimerkiksi selostettaessa AWS:n siirtymistä yksinkertaisesta palvelusta monimutkaiseen, monen miljardin dollarin kokonaisuuteen tai selitettäessä Amazonin strategisia menestyksiä, tavalliselta noutajaketjulta puuttuu tarkkuutta, jota kehittyneemmät tekniikat tarjoavat. johtaa vähemmän kohdistettuun tietoon. Vaikka käsiteltyjen edistyneiden tekniikoiden välillä on vain vähän eroja, ne ovat paljon informatiivisempia kuin tavalliset noutajaketjut.
Terveydenhuollon, televiestinnän ja rahoituspalvelujen kaltaisten toimialojen asiakkaille, jotka haluavat ottaa RAG:n käyttöön sovelluksissaan, tavallisen noutajaketjun rajoitukset tarkkuuden, redundanssin välttämisen ja tehokkaan tiedon pakkaamisen suhteen tekevät siitä vähemmän soveltuvan näihin tarpeisiin verrattuna. edistyneempään pääasiakirjan noutajaan ja kontekstuaaliseen pakkaustekniikkaan. Nämä tekniikat pystyvät tislaamaan valtavia määriä tietoa keskitetyiksi, vaikuttaviksi oivalluksiksi, joita tarvitset, ja auttavat samalla parantamaan hinta-suorituskykyä.
Puhdistaa
Kun olet lopettanut muistikirjan käyttämisen, poista luomasi resurssit välttääksesi kulujen kertymisen käytössä olevista resursseista:
Yhteenveto
Tässä viestissä esittelimme ratkaisun, jonka avulla voit ottaa käyttöön pääasiakirjan noutajan ja kontekstuaalisen pakkausketjun tekniikat parantaaksesi LLM:iden kykyä käsitellä ja luoda tietoa. Testasimme näitä kehittyneitä RAG-tekniikoita Mixtral-8x7B Instruct- ja BGE Large En -malleilla, jotka ovat saatavilla SageMaker JumpStartin kanssa. Tutkimme myös pysyvän tallennustilan käyttöä upotuksille ja dokumenttilohkoille sekä integrointia yritystietovarastoihin.
Suorittamamme tekniikat eivät ainoastaan paranta tapaa, jolla LLM-mallit pääsevät käsiksi ulkopuoliseen tietoon, vaan myös parantavat merkittävästi niiden tulosten laatua, relevanssia ja tehokkuutta. Yhdistämällä haun suurista tekstikorpuista kielen luontiominaisuuksiin, nämä edistyneet RAG-tekniikat antavat LLM:ille mahdollisuuden tuottaa asiallisempia, johdonmukaisempia ja kontekstikohtaisempia vastauksia, mikä parantaa niiden suorituskykyä erilaisissa luonnollisen kielen käsittelytehtävissä.
SageMaker JumpStart on tämän ratkaisun keskiössä. SageMaker JumpStartin avulla pääset käyttämään laajaa valikoimaa avoimen ja suljetun lähdekoodin malleja, mikä virtaviivaistaa ML:n aloitusprosessia ja mahdollistaa nopean kokeilun ja käyttöönoton. Aloita tämän ratkaisun käyttöönotto siirtymällä muistikirjaan sovelluksessa GitHub repo.
Tietoja Tekijät
 Niithiyn Vijeaswaran on ratkaisuarkkitehti AWS:ssä. Hänen painopistealueensa ovat generatiiviset AI- ja AWS-AI Accelerators -kiihdyttimet. Hän on koulutukseltaan tietojenkäsittelytieteen ja bioinformatiikan kandidaatti. Niithiyn työskentelee tiiviissä Generative AI GTM -tiimin kanssa mahdollistaakseen AWS-asiakkaiden käytön useilla rintamilla ja nopeuttaakseen heidän generatiivisen tekoälyn käyttöönottoa. Hän on innokas Dallas Mavericksin fani ja nauttii tennarien keräämisestä.
Niithiyn Vijeaswaran on ratkaisuarkkitehti AWS:ssä. Hänen painopistealueensa ovat generatiiviset AI- ja AWS-AI Accelerators -kiihdyttimet. Hän on koulutukseltaan tietojenkäsittelytieteen ja bioinformatiikan kandidaatti. Niithiyn työskentelee tiiviissä Generative AI GTM -tiimin kanssa mahdollistaakseen AWS-asiakkaiden käytön useilla rintamilla ja nopeuttaakseen heidän generatiivisen tekoälyn käyttöönottoa. Hän on innokas Dallas Mavericksin fani ja nauttii tennarien keräämisestä.
 Sebastian Bustillo on ratkaisuarkkitehti AWS:ssä. Hän keskittyy AI/ML-teknologioihin syvästi intohimolla generatiivisiin tekoälyihin ja laskentakiihdyttimiin. AWS:ssä hän auttaa asiakkaita avaamaan liiketoiminta-arvoa luovan tekoälyn avulla. Kun hän ei ole töissä, hän nauttii täydellisen erikoiskahvin keittämisestä ja maailmasta vaimonsa kanssa.
Sebastian Bustillo on ratkaisuarkkitehti AWS:ssä. Hän keskittyy AI/ML-teknologioihin syvästi intohimolla generatiivisiin tekoälyihin ja laskentakiihdyttimiin. AWS:ssä hän auttaa asiakkaita avaamaan liiketoiminta-arvoa luovan tekoälyn avulla. Kun hän ei ole töissä, hän nauttii täydellisen erikoiskahvin keittämisestä ja maailmasta vaimonsa kanssa.
 Armando Diaz on ratkaisuarkkitehti AWS:ssä. Hän keskittyy generatiiviseen tekoälyyn, AI/ML:ään ja Data Analyticsiin. AWS:ssä Armando auttaa asiakkaita integroimaan huippuluokan generatiivisia tekoälyominaisuuksia järjestelmiinsä, mikä edistää innovaatioita ja kilpailuetua. Kun hän ei ole töissä, hän viettää aikaa vaimonsa ja perheensä kanssa, vaeltaa ja matkustaa ympäri maailmaa.
Armando Diaz on ratkaisuarkkitehti AWS:ssä. Hän keskittyy generatiiviseen tekoälyyn, AI/ML:ään ja Data Analyticsiin. AWS:ssä Armando auttaa asiakkaita integroimaan huippuluokan generatiivisia tekoälyominaisuuksia järjestelmiinsä, mikä edistää innovaatioita ja kilpailuetua. Kun hän ei ole töissä, hän viettää aikaa vaimonsa ja perheensä kanssa, vaeltaa ja matkustaa ympäri maailmaa.
 Tohtori Farooq Sabir on AWS:n vanhempi tekoäly- ja koneoppimisen asiantuntijaratkaisuarkkitehti. Hänellä on tohtorin ja MS:n tutkinnot sähkötekniikasta Texasin yliopistosta Austinista ja MS-tutkinto tietojenkäsittelytieteestä Georgia Institute of Technologysta. Hänellä on yli 15 vuoden työkokemus ja hän haluaa myös opettaa ja mentoroida korkeakouluopiskelijoita. AWS:ssä hän auttaa asiakkaita muotoilemaan ja ratkaisemaan liiketoimintaongelmiaan datatieteen, koneoppimisen, tietokonenäön, tekoälyn, numeerisen optimoinnin ja niihin liittyvien alojen aloilla. Hän asuu Dallasissa, Texasissa, ja hän ja hänen perheensä rakastavat matkustamista ja pitkiä matkoja.
Tohtori Farooq Sabir on AWS:n vanhempi tekoäly- ja koneoppimisen asiantuntijaratkaisuarkkitehti. Hänellä on tohtorin ja MS:n tutkinnot sähkötekniikasta Texasin yliopistosta Austinista ja MS-tutkinto tietojenkäsittelytieteestä Georgia Institute of Technologysta. Hänellä on yli 15 vuoden työkokemus ja hän haluaa myös opettaa ja mentoroida korkeakouluopiskelijoita. AWS:ssä hän auttaa asiakkaita muotoilemaan ja ratkaisemaan liiketoimintaongelmiaan datatieteen, koneoppimisen, tietokonenäön, tekoälyn, numeerisen optimoinnin ja niihin liittyvien alojen aloilla. Hän asuu Dallasissa, Texasissa, ja hän ja hänen perheensä rakastavat matkustamista ja pitkiä matkoja.
 Marco Punio on ratkaisuarkkitehti, joka keskittyy generatiiviseen tekoälystrategiaan, soveltaviin tekoälyratkaisuihin ja tutkimusten tekemiseen auttaakseen asiakkaita AWS:n hypermittakaavassa. Marco on digitaalisen natiivipilven neuvonantaja, jolla on kokemusta FinTech-, Healthcare & Life Sciences-, Software-as-a-service- ja viimeksi telekommunikaatioalalta. Hän on pätevä tekniikan asiantuntija, joka on intohimoinen koneoppimiseen, tekoälyyn sekä fuusioihin ja yritysostoihin. Marco asuu Seattlessa, WA ja nauttii kirjoittamisesta, lukemisesta, harjoittelusta ja sovellusten rakentamisesta vapaa-ajallaan.
Marco Punio on ratkaisuarkkitehti, joka keskittyy generatiiviseen tekoälystrategiaan, soveltaviin tekoälyratkaisuihin ja tutkimusten tekemiseen auttaakseen asiakkaita AWS:n hypermittakaavassa. Marco on digitaalisen natiivipilven neuvonantaja, jolla on kokemusta FinTech-, Healthcare & Life Sciences-, Software-as-a-service- ja viimeksi telekommunikaatioalalta. Hän on pätevä tekniikan asiantuntija, joka on intohimoinen koneoppimiseen, tekoälyyn sekä fuusioihin ja yritysostoihin. Marco asuu Seattlessa, WA ja nauttii kirjoittamisesta, lukemisesta, harjoittelusta ja sovellusten rakentamisesta vapaa-ajallaan.
 AJ Dhimine on ratkaisuarkkitehti AWS:ssä. Hän on erikoistunut generatiiviseen tekoälyyn, palvelimettomaan laskemiseen ja data-analytiikkaan. Hän on koneoppimisen teknisen alan yhteisön aktiivinen jäsen/mentori ja on julkaissut useita tieteellisiä artikkeleita erilaisista AI/ML-aiheista. Hän työskentelee asiakkaiden kanssa aloittavista yrityksistä yrityksiin kehittääkseen AWSome generatiivisia tekoälyratkaisuja. Hän on erityisen intohimoinen suurten kielimallien hyödyntämiseen edistyneessä data-analytiikassa ja käytännön sovellusten tutkimisessa, jotka vastaavat todellisiin haasteisiin. Työn ulkopuolella AJ nauttii matkustamisesta ja on tällä hetkellä 53 maassa tavoitteenaan vierailla jokaisessa maailman maassa.
AJ Dhimine on ratkaisuarkkitehti AWS:ssä. Hän on erikoistunut generatiiviseen tekoälyyn, palvelimettomaan laskemiseen ja data-analytiikkaan. Hän on koneoppimisen teknisen alan yhteisön aktiivinen jäsen/mentori ja on julkaissut useita tieteellisiä artikkeleita erilaisista AI/ML-aiheista. Hän työskentelee asiakkaiden kanssa aloittavista yrityksistä yrityksiin kehittääkseen AWSome generatiivisia tekoälyratkaisuja. Hän on erityisen intohimoinen suurten kielimallien hyödyntämiseen edistyneessä data-analytiikassa ja käytännön sovellusten tutkimisessa, jotka vastaavat todellisiin haasteisiin. Työn ulkopuolella AJ nauttii matkustamisesta ja on tällä hetkellä 53 maassa tavoitteenaan vierailla jokaisessa maailman maassa.
- SEO-pohjainen sisällön ja PR-jakelu. Vahvista jo tänään.
- PlatoData.Network Vertical Generatiivinen Ai. Vahvista itseäsi. Pääsy tästä.
- PlatoAiStream. Web3 Intelligence. Tietoa laajennettu. Pääsy tästä.
- PlatoESG. hiili, CleanTech, energia, ympäristö, Aurinko, Jätehuolto. Pääsy tästä.
- PlatonHealth. Biotekniikan ja kliinisten kokeiden älykkyys. Pääsy tästä.
- Lähde: https://aws.amazon.com/blogs/machine-learning/advanced-rag-patterns-on-amazon-sagemaker/

