esittely
Retrieval Augmented-Generation (RAG) on valloittanut maailman Stormin alusta lähtien. RAG on se, mitä tarvitaan suurille kielimalleille (LLM) tarjotakseen tai tuottaakseen tarkkoja ja asiallisia vastauksia. Ratkaisemme LLM:iden tosiasiallisuuden RAG:lla, jossa yritämme antaa LLM:lle kontekstin, joka on kontekstuaalisesti samanlainen kuin käyttäjän kysely, jotta LLM toimii tämän kontekstin kanssa ja tuottaa tosiasiallisesti oikean vastauksen. Teemme tämän esittämällä tietomme ja käyttäjäkyselymme vektoriupotusten muodossa ja suorittamalla kosinin samankaltaisuuden. Mutta ongelmana on, että kaikki perinteiset lähestymistavat edustavat dataa yhdessä upotuksessa, mikä ei ehkä ole ihanteellinen hyvälle hakujärjestelmät. Tässä oppaassa tarkastelemme ColBERTiä, joka suorittaa haun paremmin kuin perinteiset bi-enkooderimallit.
Oppimistavoitteet
- Ymmärrä, kuinka RAG:n haku toimii korkealla tasolla.
- Ymmärrä yksittäisen upottamisen rajoitukset haussa.
- Paranna hakukontekstia ColBERTin tunnuksen upotuksilla.
- Opi kuinka ColBERTin myöhäinen vuorovaikutus parantaa hakua.
- Opi työskentelemään ColBERTin kanssa tarkan haun saamiseksi.
Tämä artikkeli julkaistiin osana Data Science Blogathon.
Sisällysluettelo
Mikä on RAG?
Vaikka LLM:t pystyvätkin luomaan tekstiä, joka on sekä merkityksellistä että kieliopillisesti oikeaa, nämä LLM:t kärsivät hallusinaatioiksi kutsutusta ongelmasta. Hallusinaatiot LLM:issä on käsite, jossa LLM:t luovat luottavaisesti vääriä vastauksia, toisin sanoen he muodostavat vääriä vastauksia tavalla, joka saa meidät uskomaan sen olevan totta. Tämä on ollut suuri ongelma LLM:ien käyttöönoton jälkeen. Nämä hallusinaatiot johtavat vääriin ja tosiasiallisesti vääriin vastauksiin. Tästä syystä Retrieval Augmented Generation otettiin käyttöön.
RAG:ssa otamme luettelon asiakirjoista/asiakirjapaloista ja koodaamme nämä tekstidokumentit numeeriseen esitykseen, jota kutsutaan vektori upotuksiksi, jossa yksi vektori upotus edustaa yhtä asiakirjapalaa ja tallentaa ne tietokantaan nimeltä vektorikauppa. Malleja, joita tarvitaan näiden kappaleiden koodaamiseen upotuksiksi, kutsutaan koodausmalleiksi tai bi-enkooderiksi. Nämä enkooderit on koulutettu suurelle tietojoukolle, mikä tekee niistä riittävän tehokkaita koodaamaan asiakirjapalat yhdeksi vektori upotusesitysksi.
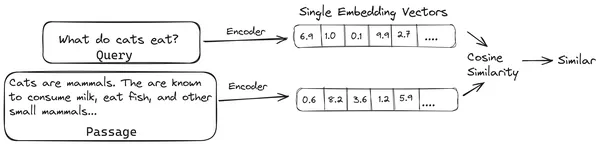
Nyt kun käyttäjä kysyy kyselyn LLM:lle, annamme tämän kyselyn samalle kooderille tuottamaan yhden vektorin upotuksen. Tätä upotusta käytetään sitten laskemaan samankaltaisuuspisteet useiden muiden dokumentin osien vektoriupotusten kanssa, jotta saadaan asiakirjan osuvin osa. LLM:lle annetaan osuvin osa tai luettelo tärkeimmistä osista yhdessä käyttäjän kyselyn kanssa. LLM vastaanottaa sitten nämä ylimääräiset kontekstuaaliset tiedot ja muodostaa sitten vastauksen, joka on kohdistettu käyttäjän kyselystä vastaanotettuun kontekstiin. Näin varmistetaan, että LLM:n tuottama sisältö on tosiasioihin liittyvää, ja se voidaan tarvittaessa jäljittää.
Perinteisten bi-enkooderien ongelma
Ongelma perinteisissä Encoder-malleissa, kuten all-miniLM, OpenAI upotusmalli ja muut enkooderimallit on, että ne pakkaavat koko tekstin yhdeksi vektori upotusesitykseen. Nämä yhden vektorin upotetut esitykset ovat hyödyllisiä, koska ne auttavat samanlaisten asiakirjojen tehokkaassa ja nopeassa hakemisessa. Ongelma piilee kuitenkin kyselyn ja asiakirjan välisessä kontekstuaalisuudesta. Yhden vektorin upottaminen ei välttämättä riitä tallentamaan dokumenttipalan kontekstuaalista tietoa, mikä luo tiedon pullonkaulan.
Kuvittele, että 500 sanaa pakataan yhdeksi vektoriksi, jonka koko on 782. Ei ehkä riitä edustamaan tällaista palaa yhdellä vektorin upotuksella, mikä antaa useimmissa tapauksissa alituloksia haussa. Yksivektoriesitys voi myös epäonnistua monimutkaisissa kyselyissä tai asiakirjoissa. Yksi tällainen ratkaisu olisi esittää asiakirjakappale tai kysely upotusvektorien luettelona yhden upotusvektorin sijaan, tässä ColBERT tulee käyttöön.
Mikä on ColBERT?
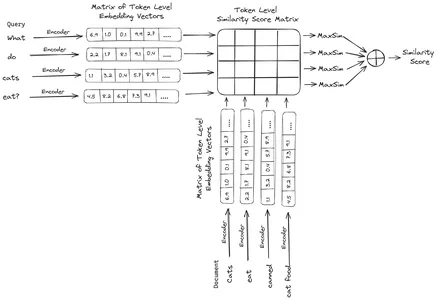
ColBERT (Contextual Late Interactions BERT) on bi-enkooderi, joka edustaa tekstiä monivektorisuutettuna esityksenä. Se vastaanottaa kyselyn tai osan dokumentista / pienen asiakirjan ja luo vektorin upotuksia merkkitasolla. Tämä tarkoittaa, että jokainen vuoromerkki saa oman vektoriupotuksensa, ja kysely/asiakirja koodataan token-tason vektoriupotusten luetteloon. Tunnustason upotukset luodaan esiopetetusta BERTI malli, josta nimi BERT.
Nämä tallennetaan sitten vektoritietokantaan. Nyt, kun kysely saapuu, sille luodaan luettelo token-tason upotuksista ja sitten suoritetaan matriisin kertolasku käyttäjän kyselyn ja kunkin asiakirjan välillä, jolloin tuloksena on samankaltaisuuspisteet sisältävä matriisi. Yleinen samankaltaisuus saavutetaan ottamalla kunkin kyselytunnisteen asiakirjatunnisteiden suurimman samankaltaisuuden summa. Tämän kaavan voi nähdä alla olevasta kuvasta:
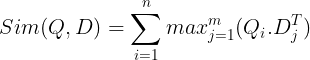
Tässä yllä olevassa yhtälössä näemme, että teemme pistetulon Query Tokens -matriisin (sisältää N merkkitason vektoriupotusta) ja Transpono of Document Tokens -matriisin (sisältää M merkkitason vektorin upotuksia) välillä, ja sitten otamme suurimman samankaltaisuuden. rajaa kunkin kyselytunnisteen asiakirjatunnukset. Sitten otamme kaikkien näiden maksimaalisten samankaltaisuuksien summan, mikä antaa meille lopullisen samankaltaisuuspisteen dokumentin ja kyselyn välillä. Syy siihen, miksi tämä tuottaa tehokkaan ja tarkan haun, on se, että meillä on token-tason vuorovaikutus, joka antaa tilaa kontekstuaalisemmalle ymmärtämiselle kyselyn ja asiakirjan välillä.
Miksi nimi ColBERT?
Kun laskemme upotusvektoreiden luetteloa ennen itseään ja suoritamme vain tämän MaxSim (maksimi samankaltaisuus) -operaation mallin päättelyn aikana, kutsuen sitä siten myöhäiseksi vuorovaikutusvaiheeksi, ja koska saamme enemmän kontekstuaalista tietoa merkkitason vuorovaikutusten kautta, sitä kutsutaan kontekstuaaliseksi. myöhäisiä vuorovaikutuksia. Siten nimi Contextual Late Interactions BERTI tai ColBERT. Nämä laskelmat voidaan suorittaa rinnakkain, joten ne voidaan laskea tehokkaasti. Lopuksi yksi huolenaihe on tila, toisin sanoen se vaatii paljon tilaa tämän merkkitason vektoriupotusten luettelon tallentamiseen. Tämä ongelma ratkaistiin ColBERTv2:ssa, jossa upotukset pakataan jäännöspakkaukseksi kutsutulla tekniikalla, mikä optimoi käytetyn tilan.
Käytännöllinen ColBERT esimerkin kanssa
Tässä osiossa tutustumme ColBERTiin ja jopa tarkistamme, kuinka se toimii tavalliseen upotusmalliin verrattuna.
Vaihe 1: Lataa kirjastot
Aloitamme lataamalla seuraavan kirjaston:
!pip install ragatouille langchain langchain_openai chromadb einops sentence-transformers tiktoken- RAGatouille: Tämän kirjaston avulla voimme työskennellä uusimpien (SOTA) hakumenetelmien, kuten ColBERTin, kanssa helppokäyttöisellä tavalla. Se tarjoaa vaihtoehtoja luoda indeksejä tietojoukkojen päälle, tehdä kyselyitä niistä ja jopa antaa meille mahdollisuuden kouluttaa ColBERT-mallin tiedoillemme.
- LangChain: Tämä kirjasto antaa meille mahdollisuuden työskennellä avoimen lähdekoodin upotusmallien kanssa, jotta voimme testata, kuinka hyvin muut upotusmallit toimivat verrattuna ColBERTiin.
- langchain_openai: Asenna LangChain riippuvuudet OpenAI:lle. Työskentelemme jopa OpenAI Embedding -mallin kanssa tarkistaaksemme sen suorituskyvyn ColBERTin kanssa.
- ChromaDB: Tämän kirjaston avulla voimme luoda vektorivaraston ympäristöömme, jotta voimme tallentaa tietoihimme luomamme upotukset ja suorittaa myöhemmin semanttisen haun kyselyn ja tallennettujen upotusten välillä.
- einops: Tätä kirjastoa tarvitaan tehokkaaseen tensorimatriisikertomiseen.
- lausemuuntajia ja tiktoken kirjastoa tarvitaan, jotta avoimen lähdekoodin upotusmallit toimivat kunnolla.
Vaihe 2: Lataa esikoulutettu malli
Seuraavassa vaiheessa lataamme valmiiksi koulutetun ColBERT-mallin. Tätä varten koodi on
from ragatouille import RAGPretrainedModel
RAG = RAGPretrainedModel.from_pretrained("colbert-ir/colbertv2.0")- Tuomme ensin RAGPretrainedModel-luokan RAGatouille-kirjastosta.
- Sitten kutsumme .from_pretrained() ja annamme mallin nimen eli “colbert-ir/colbertv2.0”.
Yllä olevan koodin suorittaminen luo ColBERT RAG -mallin. Ladataan nyt Wikipedia-sivu ja haetaan sieltä. Tätä varten koodi on:
from ragatouille.utils import get_wikipedia_page
document = get_wikipedia_page("Elon_Musk")
print("Word Count:",len(document))
print(document[:1000])RAGatouillessa on kätevä toiminto nimeltä get_wikipedia_page, joka ottaa merkkijonon ja saa vastaavan Wikipedia-sivun. Täältä lataamme Wikipedia-sisällön Elon Muskista ja tallennamme sen muuttuvaan asiakirjaan. Tulostetaan asiakirjassa olevien sanojen määrä ja asiakirjan ensimmäiset rivit.
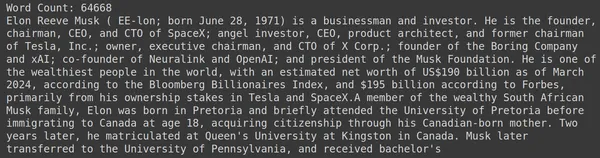
Tässä näemme kuvan tuotoksen. Näemme, että Elon Muskin Wikipedia-sivulla on yhteensä 64,668 XNUMX sanaa.
Vaihe 3: Indeksointi
Nyt luomme tähän asiakirjaan indeksin.
RAG.index(
# List of Documents
collection=[document],
# List of IDs for the above Documents
document_ids=['elon_musk'],
# List of Dictionaries for the metadata for the above Documents
document_metadatas=[{"entity": "person", "source": "wikipedia"}],
# Name of the index
index_name="Elon2",
# Chunk Size of the Document Chunks
max_document_length=256,
# Wether to Split Document or Not
split_documents=True
)Tässä kutsumme RAG:n .index()-koodia dokumenttimme indeksoimiseksi. Tätä varten välitämme seuraavat:
- kokoelma: Tämä on luettelo asiakirjoista, jotka haluamme indeksoida. Tässä meillä on vain yksi asiakirja, joten luettelo yhdestä asiakirjasta.
- document_ids: Jokainen asiakirja odottaa yksilöllistä asiakirjatunnusta. Tässä annamme sille nimen elon_musk, koska dokumentti kertoo Elon Muskista.
- document_metadatas: Jokaisella asiakirjalla on metatietonsa. Tämä on jälleen luettelo sanakirjoista, jossa jokainen sanakirja sisältää tietyn asiakirjan avain-arvoparin metatiedot.
- index_name: Luomamme indeksin nimi. Nimetään se Elon2.
- max_document_size: Tämä on samanlainen kuin palan koko. Määritämme, kuinka paljon kunkin asiakirjapalan tulee olla. Tässä annamme sille arvon 256. Jos emme määritä arvoa, 256 otetaan oletuspalakooksi.
- split_documents: Se on boolen arvo, jossa True osoittaa, että haluamme jakaa asiakirjamme annetun palakoon mukaan, ja False tarkoittaa, että haluamme tallentaa koko asiakirjan yhtenä kappaleena.
Yllä olevan koodin suorittaminen jakaa asiakirjamme kooksi 256 kappaletta kohden ja upottaa ne sitten ColBERT-mallin kautta, joka tuottaa luettelon tunnistetason vektoriupotuksista jokaiselle osalle ja tallentaa ne lopuksi hakemistoon. Tämä vaihe kestää jonkin aikaa, ja sitä voidaan nopeuttaa, jos sinulla on GPU. Lopuksi se luo hakemiston, johon hakemistomme on tallennettu. Tässä hakemisto on ".ragatouille/colbert/indexes/Elon2"
Vaihe 4: Yleinen kysely
Nyt aloitamme etsinnän. Tätä varten koodi on
results = RAG.search(query="What companies did Elon Musk find?", k=3, index_name='Elon2')
for i, doc, in enumerate(results):
print(f"---------------------------------- doc-{i} ------------------------------------")
print(doc["content"])- Tässä ensin kutsumme RAG-objektin .search()-metodia
- Tähän annamme muuttujat, jotka sisältävät kyselyn nimen, k (haettavien asiakirjojen lukumäärä) ja haettavan indeksin nimen
- Täällä tarjoamme kyselyn "Mitä yrityksiä Elon Musk löysi?". Saatu tulos on luettelossa sanakirjamuodossa, joka sisältää avaimet, kuten sisältö, pisteet, sijoitus, asiakirjan_tunnus, passage_id ja document_metadata.
- Tästä syystä käytämme alla olevaa koodia tulostaaksemme haetut asiakirjat siististi
- Täällä käymme sanakirjaluettelon läpi ja tulostamme asiakirjojen sisällön
Koodin suorittaminen tuottaa seuraavat tulokset:
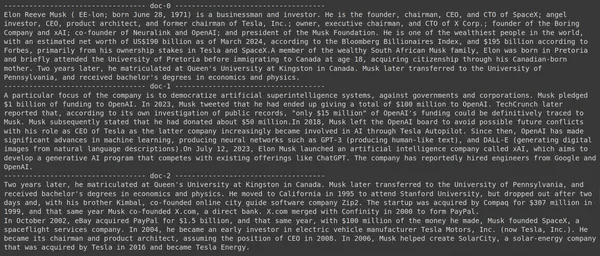
Kuvasta näkyy, että ensimmäinen ja viimeinen dokumentti kattavat kokonaan Elon Muskin perustamat eri yritykset. ColBERT pystyi hakemaan oikein kyselyyn vastaamiseen tarvittavat osat.
Vaihe 5: Tietty kysely
Mennään nyt askel pidemmälle ja kysytään sille tietty kysymys.
results = RAG.search(query="How much Tesla stocks did Elon sold in
Decemeber 2022?", k=3, index_name='Elon2')
for i, doc, in enumerate(results):
print(f"---------------
------------------- doc-{i} ------------------------------------")
print(doc["content"])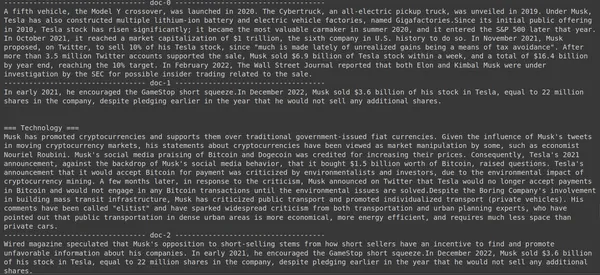
Tässä yllä olevassa koodissa kysymme erittäin tarkan kysymyksen siitä, kuinka monta osaketta Tesla Elon myytiin joulukuussa 2022. Näemme tuotoksen täältä. Asiakirja 1 sisältää vastauksen kysymykseen. Elon on myynyt osakkeitaan Teslassa 3.6 miljardin dollarin arvosta. Jälleen ColBERT pystyi noutamaan onnistuneesti asianmukaisen osan annetulle kyselylle.
Vaihe 6: Testaa muita malleja
Kokeillaan nyt samaa kysymystä muiden sekä avoimen lähdekoodin että suljettujen upotusmallien kanssa täällä:
from langchain_community.embeddings import HuggingFaceEmbeddings
from transformers import AutoModel
model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-en', trust_remote_code=True)
model_name = "jinaai/jina-embeddings-v2-base-en"
model_kwargs = {'device': 'cpu'}
embeddings = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
)
- Aloitamme lataamalla mallin ensin AutoModel-luokan kautta Transformers-kirjastosta.
- Sitten tallennamme mallin_nimi ja malli_kwargs vastaaviin muuttujiinsa.
- Nyt jotta voimme työskennellä tämän mallin kanssa LangChainissa, tuomme HuggingFaceEmbeddings LangChain ja anna sille mallin nimi ja model_kwargs.
Tämän koodin suorittaminen lataa ja lataa Jina-upotusmallin, jotta voimme työskennellä sen kanssa
Vaihe 7: Luo upotuksia
Nyt meidän on aloitettava asiakirjamme jakaminen ja sitten luotava siitä upotuksia ja tallennettava ne Chroma-vektorisäilöön. Tätä varten käytämme seuraavaa koodia:
from langchain_community.vectorstores import Chroma
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=256,
chunk_overlap=0)
splits = text_splitter.split_text(document)
vectorstore = Chroma.from_texts(texts=splits,
embedding=embeddings,
collection_name="elon")
retriever = vectorstore.as_retriever(search_kwargs = {'k':3})- Aloitamme tuomalla Chroma ja RecursiveCharacterTextSplitter LangChain-kirjastosta
- Sitten instantoimme text_splitterin kutsumalla RecursiveCharacterTextSplitterin .from_tiktoken_encoderille ja välittämällä sille chunk_size ja chunk_overlap
- Tässä käytämme samaa chunk_size-arvoa, jonka olemme toimittaneet ColBERTille
- Sitten kutsumme tämän text_splitterin menetelmää .split_text() ja annamme sille asiakirjan, joka sisältää Wikipedia-tietoja Elon Muskista. Sitten se jakaa asiakirjan annetun palakoon perusteella ja lopuksi asiakirjan osien luettelo tallennetaan muuttujan jaotuksiin
- Lopuksi kutsumme Chroma-luokan funktiota .from_texts() luodaksemme vektorivaraston. Tälle funktiolle annamme jaot, upotusmallin ja kokoelman_nimi
- Nyt luomme siitä noutajan kutsumalla vektorivarastoobjektin funktiota .as_retriever(). Annamme k-arvolle 3
Tämän koodin suorittaminen vie asiakirjamme, jakaa sen pienempiin asiakirjoihin, joiden koko on 256 kappaletta kohti, ja sitten upottaa nämä pienemmät osat Jina-upotusmallilla ja tallentaa nämä upotusvektorit värivektorivarastoon.
Vaihe 8: Luo noutaja
Lopuksi luomme siitä noutajan. Nyt suoritamme vektorihaun ja tarkistamme tulokset.
docs = retriever.get_relevant_documents("What companies did Elon Musk find?",)
for i, doc in enumerate(docs):
print(f"---------------------------------- doc-{i} ------------------------------------")
print(doc.page_content)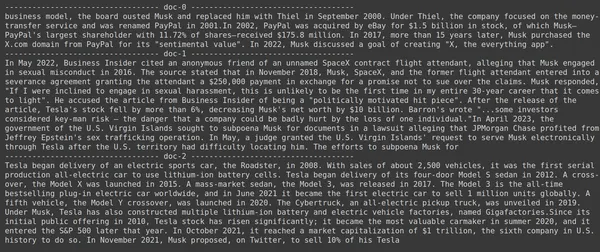
- Kutsumme noutajaobjektin funktiota .get_relevent_documents() ja annamme sille saman kyselyn.
- Sitten tulostamme siististi kolme parasta haettua asiakirjaa.
- Kuvassa näemme, että vaikka Jina Embedder on suosittu upotusmalli, kyselymme haku on huono. Se ei onnistunut saamaan oikeita asiakirjapaloja.
Voimme selvästi havaita eron Jinan, upotusmallin, joka edustaa jokaista palaa yksittäisenä vektorin upotuksena, ja ColBERT-mallin välillä, joka edustaa kutakin palaa token-tason upotusvektoreiden luettelona. ColBERT on selvästi parempi kuin tässä tapauksessa.
Vaihe 9: Testaa OpenAI:n upotusmalli
Yritetään nyt käyttää suljetun lähdekoodin upotusmallia, kuten OpenAI Embedding -mallia.
import os
os.environ["OPENAI_API_KEY"] = "Your API Key"
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
model_name = "gpt-4",
chunk_size = 256,
chunk_overlap = 0,
)
splits = text_splitter.split_text(document)
vectorstore = Chroma.from_texts(texts=splits,
embedding=embeddings,
collection_name="elon_collection")
retriever = vectorstore.as_retriever(search_kwargs = {'k':3})Tässä koodi on hyvin samanlainen kuin juuri kirjoittamamme
- Ainoa ero on, että välitämme OpenAI API -avaimen ympäristömuuttujan asettamiseen.
- Luomme sitten OpenAI Embedding -mallin esiintymän tuomalla sen LangChainista.
- Ja kokoelman nimeä luotaessa annamme erilaisen kokoelman nimen, jotta OpenAI Embedding -mallin upotukset tallennetaan eri kokoelmaan.
Tämän koodin suorittaminen ottaa jälleen asiakirjamme, lohkoa ne pienempiin asiakirjoihin, joiden koko on 256, ja sitten upottaa ne yksittäiseen vektori upotusesitykseen OpenAI-upotusmallilla ja tallentaa lopuksi nämä upotukset Chroma Vector Storeen. Yritetään nyt hakea asiaankuuluvat asiakirjat toiseen kysymykseen.
docs = retriever.get_relevant_documents("How much Tesla stocks did Elon sold in Decemeber 2022?",)
for i, doc in enumerate(docs):
print(f"---------------------------------- doc-{i} ------------------------------------")
print(doc.page_content)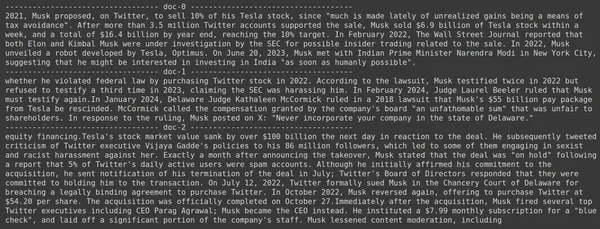
- Näemme, että vastausta, jota odotamme, ei löydy haetuista paloista.
- Osa sisältää tietoa Teslan osakkeista vuonna 2022, mutta ei puhu Elonin myymisestä niitä.
- Sama näkyy kahdessa jäljellä olevassa asiakirjapalassa, joissa niiden sisältämät tiedot koskevat Teslaa ja sen osakkeita, mutta tämä ei ole sitä tietoa, jota odotamme.
- Yllä haetut palaset eivät tarjoa kontekstia, jonka avulla LLM voi vastata toimittamiimme kyselyihin.
Jopa tässä voimme nähdä selkeän eron yksivektorisen upotusesityksen ja monivektorisen upotusesityksen välillä. Useita upotuksia sisältävät esitykset kaappaavat selkeästi monimutkaiset kyselyt, mikä johtaa tarkempiin hakuihin.
Yhteenveto
Yhteenvetona voidaan todeta, että ColBERT osoittaa merkittävää edistystä hakusuorituskyvyssä perinteisiin bi-enkooderimalleihin verrattuna esittämällä tekstiä monivektorisuutoksiin merkkitasolla. Tämä lähestymistapa mahdollistaa vivahteikkaamman kontekstuaalisen ymmärryksen kyselyjen ja asiakirjojen välillä, mikä johtaa tarkempiin hakutuloksiin ja lieventää LLM:issä yleisesti havaittuja hallusinaatioita.
Keskeiset ostokset
- RAG käsittelee hallusinaatioiden ongelmaa LLM:issä tarjoamalla kontekstuaalista tietoa asiallisten vastausten luomista varten.
- Perinteiset bi-enkooderit kärsivät tiedon pullonkaulasta, joka johtuu kokonaisten tekstien pakkaamisesta yhdeksi vektori upotukseksi, mikä johtaa huonompaan hakutarkkuuteen.
- ColBERT, jossa on token-tason upotusesitys, helpottaa parempaa kontekstuaalista ymmärtämistä kyselyjen ja asiakirjojen välillä, mikä parantaa hakusuorituskykyä.
- ColBERTin myöhäinen vuorovaikutusvaihe yhdistettynä tunnustason vuorovaikutukseen parantaa hakutarkkuutta ottamalla huomioon kontekstuaaliset vivahteet.
- ColBERTv2 optimoi tallennustilan jäännöspakkauksella säilyttäen samalla hakutehokkuuden.
- Käytännön kokeet osoittavat ColBERTin paremman hakusuorituskyvyn verrattuna perinteisiin ja avoimen lähdekoodin upotusmalleihin, kuten Jina ja OpenAI Embedding.
Usein kysytyt kysymykset
A. Perinteiset bi-enkooderit pakkaavat kokonaisia tekstejä yhdeksi vektori upotukseksi, mikä saattaa menettää kontekstuaalisen tiedon. Tämä rajoittaa niiden tehokkuutta hakutehtävissä, erityisesti monimutkaisissa kyselyissä tai asiakirjoissa.
A. ColBERT (Contextual Late Interactions BERT) on bi-enkooderin malli, joka edustaa tekstiä merkkitason vektoriupotusten avulla. Se mahdollistaa vivahteikkaamman kontekstuaalisen ymmärtämisen kyselyjen ja asiakirjojen välillä, mikä parantaa hakutarkkuutta.
V. ColBERT luo tunnistetason upotuksia kyselyille ja asiakirjoille, suorittaa matriisikertonnan samankaltaisuuspisteiden laskemiseksi ja valitsee sitten oleellisimmat tiedot tokenien suurimman samankaltaisuuden perusteella. Tämä mahdollistaa tehokkaan haun kontekstuaalisen ymmärtämisen avulla.
V. ColBERTv2 optimoi tilan jäännöspakkausmenetelmän avulla, mikä vähentää tunnistetason upotusten tallennusvaatimuksia säilyttäen samalla hakutarkkuuden.
V. Voit käyttää kirjastoja, kuten RAGatouille, työskennelläksesi ColBERTin kanssa helposti. Indeksoimalla asiakirjoja ja kyselyitä voit suorittaa tehokkaita hakutehtäviä ja luoda tarkkoja vastauksia kontekstiin kohdistetulla tavalla.
Tässä artikkelissa näkyvä media ei ole Analytics Vidhyan omistuksessa, ja sitä käytetään tekijän harkinnan mukaan.
- SEO-pohjainen sisällön ja PR-jakelu. Vahvista jo tänään.
- PlatoData.Network Vertical Generatiivinen Ai. Vahvista itseäsi. Pääsy tästä.
- PlatoAiStream. Web3 Intelligence. Tietoa laajennettu. Pääsy tästä.
- PlatoESG. hiili, CleanTech, energia, ympäristö, Aurinko, Jätehuolto. Pääsy tästä.
- PlatonHealth. Biotekniikan ja kliinisten kokeiden älykkyys. Pääsy tästä.
- Lähde: https://www.analyticsvidhya.com/blog/2024/04/colbert-improve-retrieval-performance-with-token-level-vector-embeddings/

