معرفی
در این مقاله به بررسی آنچه هست می پردازیم تست فرضیهبا تمرکز بر فرمولبندی فرضیههای صفر و جایگزین، راهاندازی آزمونهای فرضیه و به بررسی عمیق آزمونهای پارامتریک و ناپارامتریک خواهیم پرداخت و در مورد فرضیات مربوطه و اجرای آنها در پایتون بحث خواهیم کرد. اما تمرکز اصلی ما بر روی تست های ناپارامتریک مانند آزمون U Mann-Whitney و آزمون Kruskal-Wallis خواهد بود. در پایان، شما درک جامعی از آزمون فرضیه ها و ابزارهای عملی برای اعمال این مفاهیم در تجزیه و تحلیل های آماری خود خواهید داشت.
اهداف یادگیری
- اصول آزمون فرضیه، از جمله فرمول بندی فرضیه های صفر و جایگزین را بدانید.
- راه اندازی آزمون فرضیه.
- آشنایی با آزمون پارامتریک و انواع آن
- آشنایی با تست های غیر پارامتریک و انواع آن به همراه پیاده سازی های آن.
- تفاوت بین پارامتری و غیر پارامتری
جدول محتوا
آزمون فرضیه چیست؟
فرضیه ادعایی است که توسط یک شخص/سازمان مطرح می شود. این ادعا معمولاً در مورد پارامترهای جمعیت مانند میانگین یا نسبت است و ما به دنبال شواهدی از نمونه ای برای تأیید ادعا هستیم.
آزمون فرضیه، که گاهی به آن آزمون معناداری نیز گفته می شود، روشی برای تأیید یک ادعا یا فرضیه در مورد یک پارامتر در یک جامعه با استفاده از داده های اندازه گیری شده در یک نمونه است. با استفاده از این روش، چندین نظریه را با تعیین این پتانسیل بررسی میکنیم که اگر فرضیه پارامتر جمعیت درست بود، یک آمار نمونه انتخاب میشد.
آزمون فرضیه شامل دو فرضیه است:
- فرضیه صفر (H0)
- فرضیه جایگزین (H1)
فرضیه صفر : معمولاً یک فرضیه بدون تفاوت است و معمولاً با H0 نشان داده می شود. به گفته RA Fisher، فرضیه صفر فرضیه ای است که برای رد احتمالی آن با فرض درستی آن مورد آزمایش قرار می گیرد (Ref Fundamentals of Mathematical Statistics).
فرضیه جایگزین: هر فرضیه ای که مکمل فرضیه صفر باشد، فرضیه جایگزین نامیده می شود که معمولاً با H1 نشان داده می شود.
هدف از آزمون فرضیه رد یا حفظ یک فرضیه صفر برای ایجاد رابطه آماری معنی دار بین دو متغیر است (معمولاً یک متغیر مستقل و یک متغیر وابسته، یعنی معمولاً یکی علت و یکی معلول است).
راه اندازی آزمون فرضیه
- فرضیه را با کلمات توصیف کنید یا ادعا کنید.
- بر اساس ادعا، فرضیه های صفر و جایگزین را تعریف کنید.
- نوع آزمون فرضیه مناسب برای ادعای فوق را مشخص کنید.
- آمار آزمون مورد استفاده برای آزمون اعتبار فرضیه صفر را شناسایی کنید.
- معیارهای رد و حفظ فرضیه صفر را تعیین کنید. این مقدار اهمیت نامیده می شود که به طور سنتی با نماد α (آلفا) نشان داده می شود.
- مقدار p را محاسبه کنید که احتمال مشروط مشاهده مقدار آماره آزمون در زمانی است که فرضیه صفر درست باشد. به زبان ساده، p-value شواهدی در تأیید فرضیه صفر است.
آزمون پارامتریک و غیر پارامتریک
آزمونهای آماری ناپارامتریک بر فرضیات مربوط به پارامترهای توزیع جامعه که دادهها از آنها نمونهبرداری میشوند، تکیه نمیکنند، در حالی که آزمونهای آماری پارامتریک این کار را انجام میدهند.
تست های پارامتریک
بیشتر آزمون های آماری با استفاده از مجموعه ای از مفروضات به عنوان پایه و اساس آنها انجام می شود. تجزیه و تحلیل ممکن است نتایج گمراه کننده یا کاملاً نادرست را در صورت نقض برخی فرضیات به دست آورد.
به طور معمول مفروضات عبارتند از:
- نرمال بودن: توزیع نمونه برداری از پارامترهای مورد آزمایش از توزیع نرمال (یا حداقل متقارن) پیروی می کند.
- همگنی واریانسها: واریانس دادهها در گروههای مختلف یکسان است، مگر اینکه در حال آزمایش میانگین جمعیت از دو جمعیت متفاوت باشیم.
برخی از آزمون های پارامتریک عبارتند از:
- تست Z: زمانی که انحراف معیار جمعیت مشخص است، میانگین یا واریانس یا نسبت جمعیت را آزمایش کنید.
- آزمون تی دانشجویی: زمانی که انحراف معیار جمعیت مشخص نیست، میانگین یا واریانس یا نسبت جمعیت را آزمایش کنید.
- آزمون تی زوجی: برای مقایسه میانگین دو گروه یا شرایط مرتبط استفاده می شود.
- تجزیه و تحلیل واریانس (ANOVA): برای مقایسه میانگین ها در سه یا چند گروه مستقل استفاده می شود.
- تجزیه و تحلیل رگرسیون: برای ارزیابی رابطه بین یک یا چند متغیر مستقل و یک متغیر وابسته استفاده می شود.
- تجزیه و تحلیل کوواریانس (ANCOVA): ANOVA را با ترکیب متغیرهای کمکی اضافی در تجزیه و تحلیل گسترش می دهد.
- تحلیل واریانس چند متغیره (MANOVA): ANOVA را برای ارزیابی تفاوتها در متغیرهای وابسته چندگانه در بین گروهها گسترش میدهد.
حالا بیایید به تست غیر پارامتریک بپردازیم.
آزمون غیر پارامتریک
برای اولین بار، ولفوویتز از اصطلاح "ناپارامتریک" در سال 1942 استفاده کرد. برای درک ایده آمار ناپارامتریک، ابتدا باید یک درک اساسی از آمار پارامتریک داشت، که اکنون در مورد آن بحث کردیم. آ تست پارامتریک به نمونه ای نیاز دارد که از یک توزیع خاص (معمولاً نرمال) پیروی کند. علاوه بر این، آزمون های ناپارامتریک مستقل از مفروضات پارامتری مانند نرمال بودن هستند.
آزمونهای غیر پارامتریک (همچنین به عنوان آزمونهای بدون توزیع شناخته میشوند زیرا فرضیاتی در مورد توزیع جامعه ندارند). آزمونهای غیرپارامتریک نشان میدهند که آزمونها مبتنی بر این فرض نیستند که دادهها از یک توزیع احتمال از طریق پارامترهایی مانند میانگین، نسبت و انحراف معیار تعریف می شود.
آزمون های ناپارامتریک زمانی استفاده می شوند که:
- این آزمون در مورد پارامتر جمعیت مانند میانگین یا نسبت نیست.
- این روش به فرضیاتی در مورد توزیع جمعیت نیاز ندارد (مانند جمعیت از توزیع نرمال پیروی می کند).
انواع تست های غیر پارامتریک
اکنون بیایید مفهوم و روش انجام تست Chi-Square، آزمون من ویتنی، آزمون رتبه امضا شده Wilcoxon و آزمون Kruskal-Wallis را مورد بحث قرار دهیم:
آزمون Chi-Square
برای تعیین اینکه آیا ارتباط بین دو متغیر کیفی از نظر آماری معنادار است یا خیر، باید یک آزمون معناداری به نام آزمون کای دو انجام داد.
دو نوع اصلی تست Chi-Square وجود دارد:
Chi-Square Good-of-Fit
از آزمون خوب بودن برازش برای تصمیم گیری در مورد اینکه آیا جمعیتی با توزیع ناشناخته "براساس" توزیع شناخته شده است یا خیر، استفاده کنید. در این مورد یک سوال نظرسنجی کیفی واحد یا یک نتیجه از یک آزمایش از یک جمعیت واحد وجود خواهد داشت. خوب بودن تناسب معمولاً برای دیدن اینکه آیا جمعیت یکنواخت است (همه پیامدها با فراوانی مساوی رخ می دهند)، جمعیت نرمال است یا جمعیت مشابه با جمعیت دیگری با توزیع شناخته شده است، استفاده می شود. فرضیه های صفر و جایگزین عبارتند از:
- H0: جمعیت متناسب با توزیع داده شده است.
- Ha: جمعیت با توزیع داده شده تناسب ندارد.
بیایید این را با یک مثال درک کنیم
| روز | دوشنبه | سه شنبه | چهار شنبه | پنجشنبه | جمعه | شنبه | یکشنبه |
| تعداد خرابی ها | 14 | 22 | 16 | 18 | 12 | 19 | 11 |
جدول تعداد خرابی ها را در یک فاکتور نشان می دهد. در این مثال فقط یک متغیر وجود دارد و ما باید تعیین کنیم که آیا توزیع مشاهده شده (در جدول داده شده) با توزیع مورد انتظار مطابقت دارد یا خیر.
برای این منظور فرضیه صفر و فرضیه جایگزین به صورت زیر فرموله می شود:
- H0:تجزیه ها به طور یکنواخت توزیع می شوند.
- Ha: خرابی ها به طور یکنواخت توزیع نمی شوند.
و درجه آزادی n-1 خواهد بود (در این مورد n=7، بنابراین df = 7-1=6)
Expected value will be= (14+22+16+18+12+19+11)/7=16
| روز | دوشنبه | سه شنبه | چهار شنبه | پنجشنبه | جمعه | شنبه | یکشنبه |
| تعداد خرابی ها (مشاهده شده) | 14 | 22 | 16 | 18 | 12 | 19 | 11 |
| انتظار می رود | 16 | 16 | 16 | 16 | 16 | 16 | 16 |
| (مشاهده-انتظاري) | -2 | 6 | 0 | 2 | -4 | 3 | -5 |
| (مشاهده-انتظاري)^2 | 4 | 36 | 0 | 4 | 16 | 9 | 25 |
با استفاده از این فرمول، Chi-square را محاسبه کنید
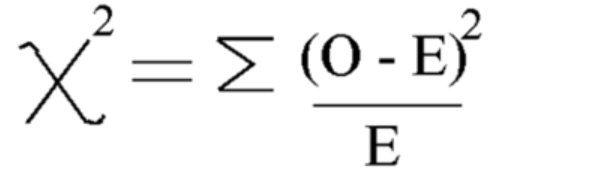
Chi-square = 5.875
و درجه آزادی = n-1=7-1=6 است
حالا بیایید مقدار بحرانی را ببینیم جدول توزیع چی مربع در سطح 5 درصد از اهمیت
بنابراین مقدار بحرانی 12.592 است
از آنجایی که مقدار محاسبهشده Chi-Square کمتر از مقدار بحرانی است، فرضیه صفر را میپذیریم و میتوانیم نتیجه بگیریم که شکستها به طور یکنواخت توزیع شدهاند.
Chi-Square Independence of Test
از آزمون استقلال برای تصمیم گیری در مورد مستقل یا وابسته بودن دو متغیر (عامل) استفاده کنید، یعنی اینکه آیا این دو متغیر رابطه معناداری بین آنها دارند یا خیر. در این صورت دو سوال یا آزمایش کیفی و یک جدول احتمالی ساخته خواهد شد. هدف این است که ببینیم آیا این دو متغیر غیر مرتبط (مستقل) یا مرتبط (وابسته) هستند. فرضیه های صفر و جایگزین عبارتند از:
- H0: دو متغیر (عامل) مستقل هستند.
- Ha: دو متغیر (عامل) وابسته هستند.
بیایید مثال بزنیم
مثالی که در آن می خواهیم بررسی کنیم که آیا جنسیت و رنگ ترجیحی پیراهن مستقل بوده است یا خیر. این بدان معنی است که ما می خواهیم بفهمیم که آیا جنسیت یک فرد بر انتخاب رنگ آنها تأثیر می گذارد یا خیر. ما یک نظرسنجی انجام دادیم و داده ها را در جدول سازماندهی کردیم.
این جدول مقادیر مشاهده شده است:
| سیاه پوست | سفید | قرمز | آبی | |
| نر | 48 | 12 | 33 | 57 |
| زن | 34 | 46 | 42 | 26 |
حال ابتدا فرضیه های صفر و جایگزین را فرموله کنید
- H0: جنسیت و رنگ ترجیحی پیراهن مستقل است
- Ha: جنسیت و رنگ ترجیحی پیراهن مستقل نیستند
برای محاسبه آمار آزمون Chi-squared باید مقدار مورد انتظار را محاسبه کنیم. بنابراین، تمام سطرها و ستون ها و مجموع کل را اضافه کنید:
| سیاه پوست | سفید | قرمز | آبی | جمع | |
| نر | 48 | 12 | 33 | 57 | 150 |
| زن | 34 | 46 | 42 | 26 | 148 |
| جمع | 82 | 58 | 75 | 83 | 298 |
پس از این می توانیم جدول مقدار مورد انتظار را از جدول بالا برای هر ورودی با استفاده از این فرمول محاسبه کنیم = (کل ردیف * کل ستون) / کل کل
جدول ارزش مورد انتظار:
| سیاه پوست | سفید | قرمز | آبی | |
| نر | 41.3 | 29.2 | 37.8 | 41.8 |
| زن | 40.7 | 28.8 | 37.2 | 41.2 |
اکنون مقدار Chi Square را با استفاده از فرمول تست chi-square محاسبه کنید:
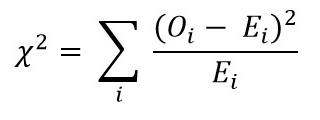
- Oi = مقدار مشاهده شده
- Ei = ارزش مورد انتظار
مقداری که به دست می آوریم: Χ2 = 34.9572 است
محاسبه درجه آزادی
DF=(تعداد ردیف-1)*(تعداد ستون-1)
اکنون مقدار بحرانی را با آزمون کای اسکوئر پیدا کرده و مقایسه کنید ارزش آماری:
برای انجام این کار می توانید درجه آزادی و سطح اهمیت (آلفا) را از قسمت جستجو کنید جدول توزیع کای دو
در آلفا = 0.050، مقدار بحرانی = 7.815 را دریافت خواهیم کرد
از آنجایی که chi-square> ارزش بحرانی دارد
بنابراین، فرضیه صفر را رد می کنیم و می توانیم نتیجه بگیریم که جنسیت و رنگ ترجیحی پیراهن مستقل نیستند.
اجرای میدان چی
حالا بیایید اجرای Chi-Square را با استفاده از چند مثال واقعی در پایتون ببینیم:
- H0: جنسیت و رنگ ترجیحی پیراهن مستقل است
- Ha: جنسیت و رنگ ترجیحی پیراهن مستقل نیستند
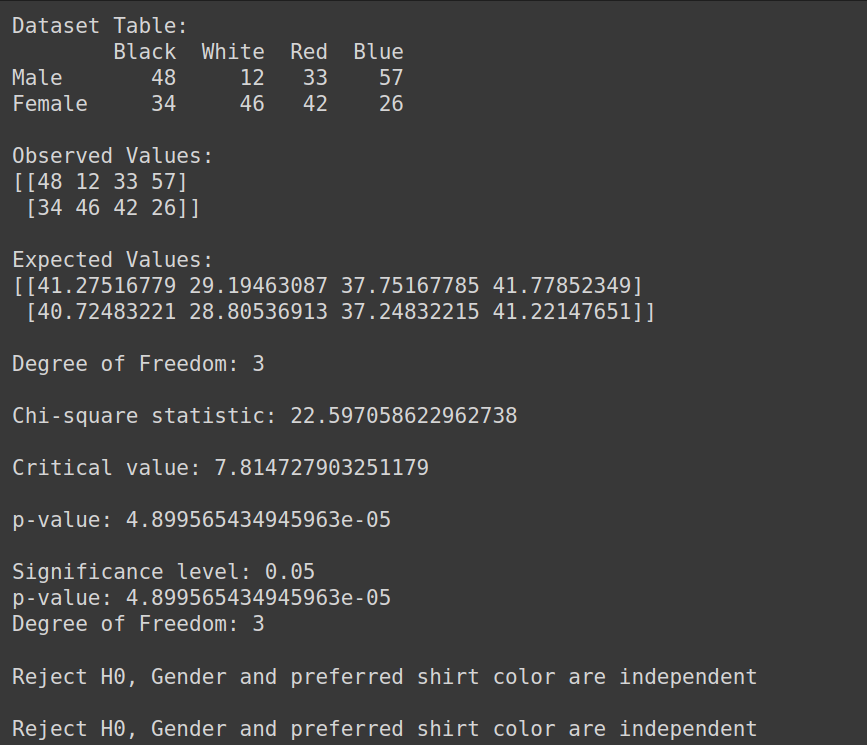
ایجاد مجموعه داده:
import pandas as pd
from scipy.stats import chi2_contingency
from scipy.stats import chi2
# Given dataset
df_dict = {
'Black': [48, 34],
'White': [12, 46],
'Red': [33, 42],
'Blue': [57, 26]
}
dataset_table = pd.DataFrame(df_dict, index=['Male', 'Female'])
print("Dataset Table:")
print(dataset_table)
print()
# Observed Values
Observed_Values = dataset_table.values
print("Observed Values:")
print(Observed_Values)
print()
# Perform chi-square test
val = chi2_contingency(dataset_table)
Expected_Values = val[3]
print("Expected Values:")
print(Expected_Values)
print()
# Degree of Freedom
no_of_rows = len(dataset_table.iloc[0:2, 0])
no_of_columns = 4
ddof = (no_of_rows - 1) * (no_of_columns - 1)
print("Degree of Freedom:", ddof)
print()
# Chi-square statistic
chi_square = sum([(o - e) ** 2. / e for o, e in zip(Observed_Values, Expected_Values)])
chi_square_statistic = chi_square[0] + chi_square[1]
print("Chi-square statistic:", chi_square_statistic)
print()
# Critical value
alpha = 0.05
critical_value = chi2.ppf(q=1-alpha, df=ddof)
print('Critical value:', critical_value)
print()
# p-value
p_value = 1 - chi2.cdf(x=chi_square_statistic, df=ddof)
print('p-value:', p_value)
print()
# Significance level
print('Significance level:', alpha)
print('p-value:', p_value)
print('Degree of Freedom:', ddof)
print()
# Hypothesis testing
if chi_square_statistic >= critical_value:
print("Reject H0, Gender and preferred shirt color are independent")
else:
print("Fail to reject H0, Gender and preferred shirt color are not independent")
print()
if p_value <= alpha:
print("Reject H0, Gender and preferred shirt color are independent")
else:
print("Fail to reject H0, Gender and preferred shirt color are not independent")
خروجی:
آزمون U Mann-Whitney
آزمون U Mann-Whitney به عنوان جایگزین ناپارامتری برای آزمون t نمونه مستقل عمل می کند. دو میانگین نمونه از یک جامعه را با هم مقایسه می کند و تعیین می کند که آیا آنها برابر هستند یا خیر. این آزمون معمولاً برای داده های ترتیبی یا زمانی که مفروضات آزمون t برآورده نمی شود استفاده می شود.
آزمون Mann-Whitney U تمام مقادیر هر دو گروه را با هم رتبه بندی می کند، سپس رتبه های هر گروه را جمع می کند. آمار آزمون U را بر اساس این رتبه ها محاسبه می کند. آماره U با یک مقدار بحرانی از یک جدول مقایسه می شود یا با استفاده از یک تقریب محاسبه می شود. اگر آماره U کمتر از مقدار بحرانی باشد، فرض صفر رد می شود.
این با آزمون های پارامتریک مانند آزمون t که میانگین ها را مقایسه می کند و توزیع نرمال را فرض می کند متفاوت است. آزمون Mann-Whitney U در عوض رتبه ها را مقایسه می کند و نیازی به فرض توزیع نرمال ندارد.
درک آزمون U Mann-Whitney می تواند دشوار باشد زیرا نتایج در تفاوت های رتبه بندی گروهی به جای تفاوت های میانگین گروهی ارائه می شود.
فرمول آزمون من ویتنی:
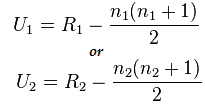
U= min(U1,U2)
در اینجا،
- U= آزمون U Mann-Whitney
- n1 = حجم نمونه یک
- n2= حجم نمونه دو
- R1= رتبه نمونه حجم یک
- R2= رتبه حجم نمونه 2
بنابراین، بیایید این را با یک مثال کوتاه درک کنیم:
فرض کنید می خواهیم اثربخشی دو روش درمانی مختلف (روش A و روش B) را در بهبود سلامت بیماران مقایسه کنیم. ما داده های زیر را داریم:
- روش الف: 3,4,2,6,2,5،XNUMX،XNUMX،XNUMX،XNUMX،XNUMX
- روش ب: 9,7,5,10,6,8،XNUMX،XNUMX،XNUMX،XNUMX،XNUMX
در اینجا، می بینیم که داده ها به طور معمول توزیع نشده اند و اندازه نمونه کوچک است.
اجرای آزمون U Mann-Whitney
حالا بیایید تست من ویتنی U را انجام دهیم:
اما ابتدا اجازه دهید فرضیه صفر و جایگزین را فرموله کنیم
- H0: هیچ تفاوتی بین رتبه هر درمان وجود ندارد
- Ha: بین رتبه هر درمان تفاوت وجود دارد
تمام درمان ها را ترکیب کنید: 3,4,2,6,2,5,9,7,5,10,6,8،XNUMX،XNUMX،XNUMX،XNUMX،XNUMX،XNUMX،XNUMX،XNUMX،XNUMX،XNUMX،XNUMX
داده های مرتب شده: 2,2,3,4,5,5,6,6,7,8,9,10،XNUMX،XNUMX،XNUMX،XNUMX،XNUMX،XNUMX،XNUMX،XNUMX،XNUMX،XNUMX،XNUMX
رتبه داده های مرتب شده: 1,2,3,4,5,6,7,8,9,10,11,12،XNUMX،XNUMX،XNUMX،XNUMX،XNUMX،XNUMX،XNUMX،XNUMX،XNUMX،XNUMX،XNUMX
- رتبه بندی داده ها به صورت جداگانه:
- Method A: 3(3),4(4),2(1.5),6(7.5),2(1.5),5(5.5)
- Method B: 9(11),7(9),5(5.5),10(12),6(1.5),8(10)
- محاسبه مجموع رتبه):
- R1: 3+4+1.5+7.5+1.5+5.5=23
- R2: 11+9+5.5+12+1.5+10=55
اکنون مقدار آماری را با استفاده از این فرمول محاسبه کنید:
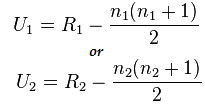
در اینجا n1=6 و n2=6
و مقدار بعد از محاسبه برای U1=2 و برای U2=34
محاسبه آمار U:
Us= min(U1,U2)= min(2,34)= 2
از جانب میز من ویتنی ما می توانیم مقدار بحرانی را پیدا کنیم
در این حالت Critical Value 5 خواهد بود
از آنجایی که Uc= 5 که در سطح معنی داری 5 درصد از Us بیشتر است. بنابراین، ما را رد می کنیم. H0
از این رو می توان نتیجه گرفت که بین رتبه هر درمان تفاوت وجود دارد.
پیاده سازی با پایتون
from scipy.stats import mannwhitneyu, norm
import numpy as np
TreatmentA = np.array([3,4,2,6,2,5])
TreatmentB = np.array([9,7,5,10,6,8])
# Perform Mann-Whitney U test
U_statistic, p_value = mannwhitneyu(TreatmentA, TreatmentB)
# Print the result
print(f'The U-statistic is {U_statistic:.2f} and the p-value is {p_value:.4f}')
if p_value < 0.05:
print("Reject Null Hypothesis: There is a significant difference between the Rank of each treatment.")
else:
print("Fail to Reject Null Hypothesis: Fail to Reject Null Hypothesis: There is no enough evidence to conclude that there is difference between the Rank of each treatment")خروجی:

تست کروسکال-والیس
آزمون Kruskal-Wallis برای چندین گروه استفاده می شود. هنگامی که نرمال بودن و برابری واریانس مفروضات نقض می شود، جایگزین ناپارامتریک و ارزشمندی برای آزمون ANOVA یک طرفه است. آزمون کروسکال-والیس میانه های بیش از دو گروه مستقل را مقایسه می کند.
زمانی که k نمونه مستقل (k>=3) از جمعیتی با توزیع های یکسان، بدون نیاز به شرط نرمال بودن جمعیت ها، گرفته شود، فرضیه صفر را آزمایش می کند.
مفروضات:
اطمینان حاصل کنید که حداقل سه نمونه تصادفی مستقل ترسیم شده است. هر نمونه حداقل 5 مشاهده دارد، n>=5
مثالی را در نظر بگیرید که در آن میخواهیم تعیین کنیم آیا تکنیک مطالعه استفاده شده توسط سه گروه از دانشآموزان بر نمرات امتحانات آنها تأثیر میگذارد یا خیر. ما میتوانیم از آزمون کروسکال-والیس برای تجزیه و تحلیل دادهها استفاده کنیم و ارزیابی کنیم که آیا تفاوتهای آماری معنیداری در نمرات امتحان در بین گروهها وجود دارد یا خیر.
فرضیه صفر را به صورت زیر تنظیم کنید:
- H0: در بین سه گروه دانش آموزان تفاوتی در نمرات امتحانی وجود ندارد.
- Ha: در بین سه گروه دانش آموزان تفاوت نمره امتحان وجود دارد.
تست رتبه امضا شده ویلکاکسون
تست رتبه امضا شده Wilcoxon (همچنین به عنوان تست جفت منطبق ویلکاکسون شناخته می شود) نسخه غیر پارامتریک آزمون t نمونه وابسته یا آزمون t نمونه زوجی است. آزمون علامت، جایگزین ناپارامتری دیگر برای آزمون تی نمونه زوجی است. زمانی استفاده می شود که متغیرهای مورد نظر ماهیت دوگانه دارند (مانند مرد و زن، بله و خیر). آزمون رتبه امضا شده Wilcoxon نیز یک نسخه ناپارامتریک برای یک آزمون t نمونه است. آزمون رتبه امضا شده ویلکاکسون میانه های گروه ها را در دو موقعیت (نمونه های زوجی) مقایسه می کند یا میانه گروه را با میانه فرضی (یک نمونه) مقایسه می کند.
بیایید این را با یک مثال درک کنیم، فرض کنید اطلاعاتی در مورد مصرف روزانه سیگار افراد سیگاری قبل و بعد از شرکت در یک برنامه 8 هفته ای داریم و می خواهیم تعیین کنیم که آیا تفاوت قابل توجهی در مصرف روزانه سیگار قبل و بعد از برنامه وجود دارد یا خیر. از این تست استفاده کنید
فرمول فرضیه برای این خواهد بود
- H0: مصرف روزانه سیگار قبل و بعد از برنامه تفاوتی ندارد.
- Ha: مصرف روزانه سیگار قبل و بعد از برنامه تفاوت دارد
تست نرمال بودن
حال اجازه دهید تست های نرمال بودن را مورد بحث قرار دهیم:
تست شاپیرو ویلک
آزمون Shapiro-Wilk ارزیابی می کند که آیا یک نمونه داده شده از یک جمعیت به طور معمول توزیع شده است یا خیر. این یکی از متداول ترین تست های مورد استفاده برای بررسی نرمال بودن است. این آزمون به ویژه زمانی مفید است که با حجم نمونه نسبتاً کوچک سروکار داریم.
در آزمون Shapiro-Wilk:
- فرضیه صفر : داده های نمونه از جمعیتی می آید که از توزیع نرمال پیروی می کند.
- فرضیه جایگزین: داده های نمونه از جمعیتی که از توزیع نرمال پیروی می کنند به دست نمی آید.
آمار آزمون تولید شده توسط آزمون Shapiro-Wilk اختلاف بین داده های مشاهده شده و داده های مورد انتظار را با فرض نرمال بودن اندازه گیری می کند. اگر مقدار p مربوط به آماره آزمون کمتر از سطح معناداری انتخاب شده باشد (مثلا 0.05)، ما فرضیه صفر را رد می کنیم، که نشان می دهد داده ها به طور معمول توزیع نشده اند. اگر مقدار p بیشتر از سطح معنیداری باشد، فرضیه صفر را رد نمیکنیم، و نشان میدهد که دادهها ممکن است از توزیع نرمال پیروی کنند.
ابتدا بیایید یک مجموعه داده برای این آزمایش ایجاد کنیم که می توانید از هر مجموعه داده ای که انتخاب می کنید استفاده کنید:
import pandas as pd
# Create the dictionary with the provided data
data = {
'population': [6.1101, 5.5277, 8.5186, 7.0032, 5.8598],
'profit': [17.5920, 9.1302, 13.6620, 11.8540, 6.8233]
}
# Create the DataFrame
df = pd.DataFrame(data)
response_var=df['profit']
Here, a sample for running Shapiro -Wilk test on python:
from scipy.stats import shapiro
stat, p_val = shapiro(response_var)
print(f'Shapiro-Wilk Test: Statistic={stat} p-value={p_val}')
if p_val > alpha:
print('Data looks normal (fail to reject H0)')
else:
print('Data looks normal (fail to reject H0)')خروجی:

این آزمون برای اندازههای نمونه نسبتاً کوچک (n=<50-2000) مناسبتر است، زیرا با اندازههای نمونه بزرگتر قابل اعتمادتر میشود.
اندرسون-عزیزم
ارزیابی می کند که آیا یک نمونه داده از یک توزیع مشخص، مانند توزیع نرمال، می آید یا خیر. این شبیه به آزمون Shapiro-Wilk است اما به خصوص برای اندازه های نمونه کوچکتر حساس تر است.
برای مواردی که پارامترهای توزیع ناشناخته هستند، برای چندین توزیع، از جمله توزیع نرمال، مناسب است.
در اینجا، کد پایتون برای پیاده سازی آن:
from scipy.stats import anderson
response_var = data['profit']
alpha = 0.05
# Anderson-Darling Test
result = anderson(response_var)
print(f'Anderson statistics: {result.statistic:.3f}')
if result.statistic > result.critical_values[-1]:
p_value = 0.0 # The p-value is essentially 0 if the statistic exceeds the largest critical value
else:
p_value = result.significance_level[result.statistic < result.critical_values][-1]
print("P-value:", p_value)
if p_value < alpha:
print("Reject null hypothesis: Data does not look normally distributed")
else:
print("Fail to reject null hypothesis: Data looks normally distributed")خروجی:

تست Jarque-Bera
آزمون Jarque-Bera ارزیابی می کند که آیا یک نمونه داده شده از یک جمعیت به طور معمول توزیع شده است یا خیر. بر اساس چولگی و کشیدگی داده ها است.
در اینجا اجرای Jarque-Bera Test در پایتون با داده های نمونه آورده شده است:
from scipy.stats import jarque_bera
# Performing Jarque-Bera test
test_statistic, p_value = jarque_bera(response_var)
print("Jarque-Bera Test Statistic:", test_statistic)
print("P-value:", p_value)
# Interpreting results
alpha = 0.05
if p_value < alpha:
print("Reject null hypothesis: Data does not look normally distributed")
else:
print("Fail to reject null hypothesis: Data looks normally distributed")خروجی:

| دسته بندی | تکنیک های آماری پارامتریک | آماری غیر پارامتریتکنیک |
| ارتباط | ضریب همبستگی لحظه محصول پیرسون (r) | همبستگی ضریب رتبه اسپیرمن (Rho)، کندال تاو |
| دو گروه، اقدامات مستقل | آزمون تی مستقل | تست U Mann-Whitney |
| بیش از دو گروه، اقدامات مستقل | ANOVA یک طرفه | Kruskal-Wallis ANOVA یک طرفه |
| دو گروه، اقدامات مکرر | آزمون تی زوجی | آزمون رتبه بندی جفتی همسان ویلکاکسون |
| بیش از دو گروه، اقدامات مکرر | ANOVA اندازه گیری های یک طرفه و مکرر | تحلیل واریانس دو طرفه فریدمن |
نتیجه
آزمایش فرضیه برای ارزیابی ادعاهای مربوط به پارامترهای جمعیت با استفاده از داده های نمونه ضروری است. آزمونهای پارامتریک بر مفروضات خاصی تکیه میکنند و برای دادههای بازهای یا نسبتی مناسب هستند، در حالی که آزمونهای غیرپارامتری انعطافپذیرتر هستند و برای دادههای اسمی یا ترتیبی بدون مفروضات دقیق توزیعی قابل استفاده هستند. تست هایی مانند Shapiro-Wilk و Anderson-Darling نرمال بودن را ارزیابی می کنند، در حالی که Chi-square و Jarque-Bera خوبی تناسب را ارزیابی می کنند. درک تفاوت بین آزمون های پارامتریک و ناپارامتریک برای انتخاب رویکرد آماری مناسب بسیار مهم است. به طور کلی، آزمون فرضیه یک چارچوب سیستماتیک برای تصمیم گیری های مبتنی بر داده و نتیجه گیری قابل اعتماد از شواهد تجربی فراهم می کند.
آماده تسلط بر تجزیه و تحلیل آماری پیشرفته هستید؟ امروز در دوره تجزیه و تحلیل داده BlackBelt ما ثبت نام کنید! کسب تخصص در آزمون فرضیه ها، آزمون های پارامتریک و ناپارامتریک، پیاده سازی پایتون و موارد دیگر. مهارت های آماری خود را ارتقا دهید و در تصمیم گیری مبتنی بر داده ها برتری پیدا کنید. همین الان ملحق شوید، همین الان بپیوندید!
پرسش و پاسخهای متداول
الف. آزمون های پارامتریک مفروضاتی را در مورد توزیع جمعیت و پارامترهایی مانند نرمال بودن و همگنی واریانس ایجاد می کنند، در حالی که آزمون های ناپارامتریک بر این مفروضات تکیه نمی کنند. تستهای پارامتری زمانی که مفروضات برآورده میشوند، قدرت بیشتری دارند، در حالی که تستهای ناپارامتریک قویتر هستند و در طیف وسیعتری از موقعیتها، از جمله زمانی که دادهها دارای انحراف هستند یا به طور معمول توزیع نمیشوند، قویتر هستند.
الف- آزمون کای دو برای تعیین اینکه آیا ارتباط معنی داری بین دو متغیر طبقه بندی وجود دارد یا خیر استفاده می شود. معمولاً داده های طبقه بندی شده را تجزیه و تحلیل می کند و فرضیه های مربوط به استقلال متغیرها را در جداول احتمالی آزمایش می کند.
الف) آزمون من ویتنی U دو گروه مستقل را در زمانی که متغیر وابسته ترتیبی است یا به طور معمول توزیع نمی شود، مقایسه می کند. این ارزیابی می کند که آیا تفاوت معنی داری بین میانه های دو گروه وجود دارد یا خیر.
الف. آزمون Shapiro-Wilk ارزیابی می کند که آیا یک نمونه از یک جمعیت به طور معمول توزیع شده است یا خیر. این فرضیه صفر را آزمایش می کند که داده ها از توزیع نرمال پیروی می کنند. اگر مقدار p کمتر از سطح معناداری انتخاب شده باشد (به عنوان مثال 0.05)، فرض صفر را رد می کنیم و به این نتیجه می رسیم که داده ها به طور معمول توزیع نشده اند.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- PlatoHealth. هوش بیوتکنولوژی و آزمایشات بالینی. دسترسی به اینجا.
- منبع: https://www.analyticsvidhya.com/blog/2024/04/a-comprehensive-guide-on-non-parametric-tests/

