امروزه، مشتریان همه صنایع – اعم از خدمات مالی، مراقبت های بهداشتی و علوم زیستی، مسافرت و مهمان نوازی، رسانه و سرگرمی، مخابرات، نرم افزار به عنوان سرویس (SaaS)، و حتی ارائه دهندگان مدل های اختصاصی – از مدل های زبان بزرگ (LLM) استفاده می کنند. برنامه هایی مانند چت ربات پرسش و پاسخ (QnA)، موتورهای جستجو و پایگاه های دانش بسازید. اینها هوش مصنوعی مولد برنامهها نه تنها برای خودکارسازی فرآیندهای تجاری موجود استفاده میشوند، بلکه این توانایی را دارند که تجربه را برای مشتریان با استفاده از این برنامهها تغییر دهند. با پیشرفت هایی که با LLM هایی مانند دستورالعمل Mixtral-8x7B، مشتق از معماری هایی مانند ترکیبی از کارشناسان (MOE)، مشتریان به طور مداوم به دنبال راه هایی برای بهبود عملکرد و دقت برنامه های کاربردی هوش مصنوعی مولد هستند و در عین حال به آنها اجازه می دهد تا به طور موثر از طیف گسترده تری از مدل های بسته و منبع باز استفاده کنند.
تعدادی از تکنیک ها معمولا برای بهبود دقت و عملکرد خروجی LLM استفاده می شود، مانند تنظیم دقیق با تنظیم دقیق کارآمد پارامتر (PEFT), یادگیری تقویتی از بازخورد انسانی (RLHF)، و اجرا تقطیر دانش. با این حال، هنگام ساخت برنامههای هوش مصنوعی مولد، میتوانید از یک راهحل جایگزین استفاده کنید که امکان ادغام پویا دانش خارجی را فراهم میکند و به شما امکان میدهد اطلاعات مورد استفاده برای تولید را بدون نیاز به تنظیم دقیق مدل پایه موجود خود کنترل کنید. اینجا جایی است که Retrieval Augmented Generation (RAG) وارد میشود، بهویژه برای برنامههای هوش مصنوعی مولد بر خلاف جایگزینهای تنظیم دقیق گرانتر و قویتر که در مورد آن صحبت کردیم. اگر برنامههای پیچیده RAG را در وظایف روزانه خود پیادهسازی میکنید، ممکن است با چالشهای رایج سیستمهای RAG خود مانند بازیابی نادرست، افزایش اندازه و پیچیدگی اسناد، و سرریز متن مواجه شوید که میتواند به طور قابلتوجهی بر کیفیت و قابلیت اطمینان پاسخهای تولید شده تأثیر بگذارد. .
این پست در مورد الگوهای RAG برای بهبود دقت پاسخ با استفاده از LangChain و ابزارهایی مانند بازیابی اسناد والد، علاوه بر تکنیکهایی مانند فشردهسازی متنی به منظور توانمندسازی توسعهدهندگان برای بهبود برنامههای هوش مصنوعی مولد موجود بحث میکند.
بررسی اجمالی راه حل
در این پست، ما استفاده از تولید متن دستورالعمل Mixtral-8x7B همراه با مدل تعبیهسازی BGE Large En را برای ساخت کارآمد یک سیستم RAG QnA روی نوتبوک آمازون SageMaker با استفاده از ابزار بازیابی سند والد و تکنیک فشردهسازی متنی نشان میدهیم. نمودار زیر معماری این راه حل را نشان می دهد.
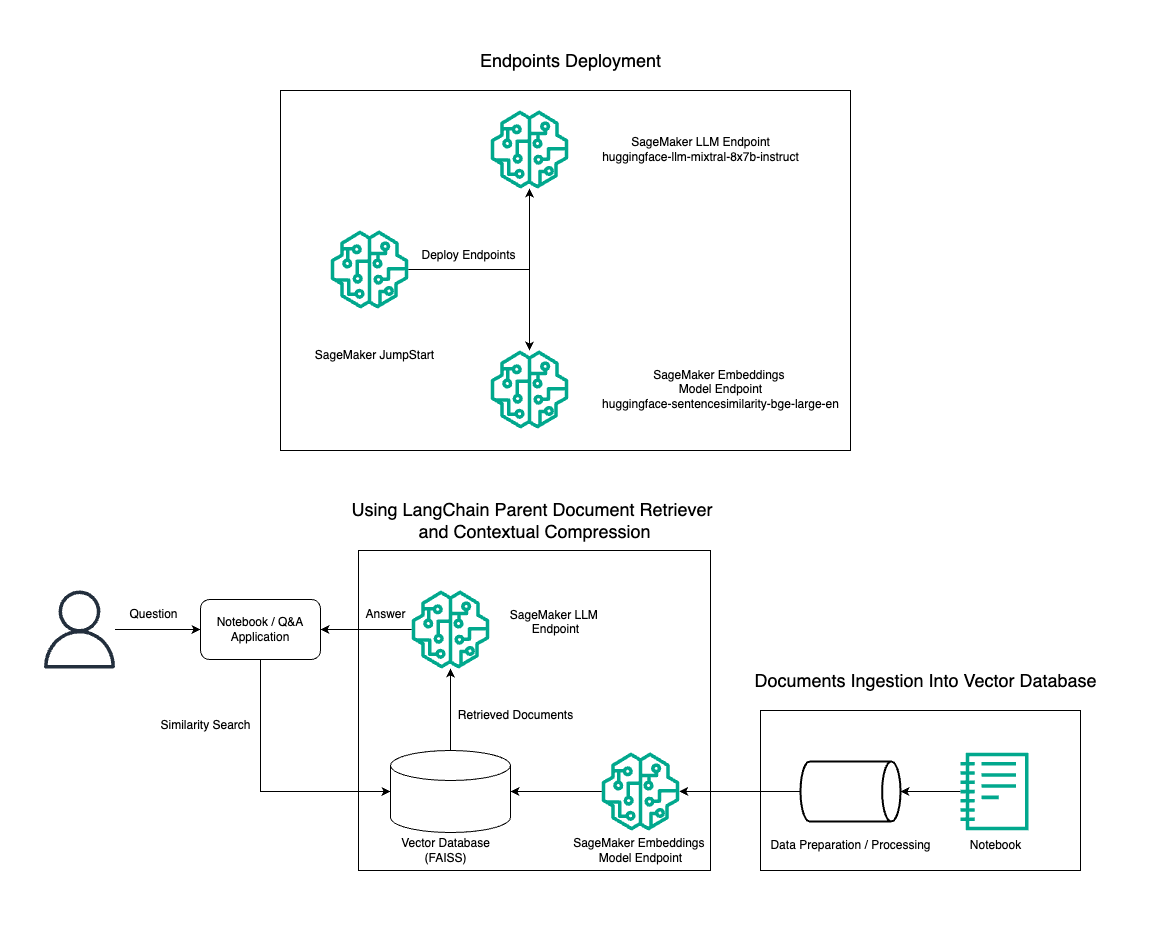
شما می توانید این راه حل را تنها با چند کلیک استفاده کنید Amazon SageMaker JumpStart، یک پلتفرم کاملاً مدیریت شده که مدل های بنیادی پیشرفته ای را برای موارد استفاده مختلف مانند نوشتن محتوا، تولید کد، پاسخ به سؤال، کپی رایتینگ، خلاصه سازی، طبقه بندی و بازیابی اطلاعات ارائه می دهد. مجموعه ای از مدل های از پیش آموزش دیده را ارائه می دهد که می توانید آنها را به سرعت و به راحتی اجرا کنید و توسعه و استقرار برنامه های کاربردی یادگیری ماشین (ML) را تسریع می بخشد. یکی از اجزای کلیدی SageMaker JumpStart مدل Hub است که کاتالوگ گسترده ای از مدل های از پیش آموزش دیده مانند Mixtral-8x7B را برای کارهای مختلف ارائه می دهد.
Mixtral-8x7B از معماری MoE استفاده می کند. این معماری به بخش های مختلف یک شبکه عصبی اجازه می دهد تا در کارهای مختلف تخصص داشته باشند و به طور موثر حجم کار را بین متخصصان متعدد تقسیم کند. این رویکرد آموزش کارآمد و به کارگیری مدل های بزرگتر را در مقایسه با معماری های سنتی امکان پذیر می کند.
یکی از مزایای اصلی معماری MOE مقیاس پذیری آن است. با توزیع حجم کاری بین متخصصان متعدد، مدلهای MOE میتوانند بر روی مجموعه دادههای بزرگتر آموزش داده شوند و نسبت به مدلهای سنتی با همان اندازه عملکرد بهتری داشته باشند. علاوه بر این، مدلهای MOE میتوانند در طول استنتاج کارآمدتر باشند، زیرا تنها زیر مجموعهای از متخصصان باید برای یک ورودی مشخص فعال شوند.
برای اطلاعات بیشتر در مورد دستورالعمل Mixtral-8x7B در AWS، مراجعه کنید Mixtral-8x7B اکنون در Amazon SageMaker JumpStart در دسترس است. مدل Mixtral-8x7B تحت مجوز مجاز Apache 2.0 برای استفاده بدون محدودیت در دسترس است.
در این پست به نحوه استفاده شما می پردازیم LangChain برای ایجاد برنامه های RAG موثر و کارآمدتر. LangChain یک کتابخانه منبع باز پایتون است که برای ساخت برنامه های کاربردی با LLM طراحی شده است. این یک چارچوب ماژولار و منعطف برای ترکیب LLM ها با سایر مؤلفه ها، مانند پایگاه های دانش، سیستم های بازیابی و سایر ابزارهای هوش مصنوعی، برای ایجاد برنامه های کاربردی قدرتمند و قابل تنظیم ارائه می دهد.
ما در حال ساخت یک خط لوله RAG در SageMaker با Mixtral-8x7B هستیم. ما از مدل تولید متن Mixtral-8x7B Instruct با مدل جاسازی BGE Large En برای ایجاد یک سیستم QnA کارآمد با استفاده از RAG در نوت بوک SageMaker استفاده می کنیم. ما از یک نمونه ml.t3.medium برای نشان دادن استقرار LLM ها از طریق SageMaker JumpStart استفاده می کنیم، که می توان از طریق یک نقطه پایانی API تولید شده توسط SageMaker به آن دسترسی داشت. این راهاندازی امکان کاوش، آزمایش و بهینهسازی تکنیکهای پیشرفته RAG را با LangChain فراهم میکند. ما همچنین ادغام فروشگاه FAISS Embedding را در گردش کار RAG نشان میدهیم و نقش آن را در ذخیره و بازیابی جاسازیها برای افزایش عملکرد سیستم برجسته میکنیم.
ما یک بررسی مختصر از نوت بوک SageMaker انجام می دهیم. برای دستورالعمل های دقیق تر و گام به گام به ادامه مطلب مراجعه کنید الگوهای RAG پیشرفته با Mixtral در مخزن SageMaker Jumpstart GitHub.
نیاز به الگوهای پیشرفته RAG
الگوهای پیشرفته RAG برای بهبود قابلیتهای فعلی LLMها در پردازش، درک و تولید متن شبیه انسان ضروری هستند. همانطور که اندازه و پیچیدگی اسناد افزایش می یابد، نمایش چندین جنبه از سند در یک جاسازی می تواند منجر به از دست دادن ویژگی شود. اگرچه درک ماهیت کلی یک سند ضروری است، شناسایی و بازنمایی زیرمجموعه های متنوع درون آن نیز به همان اندازه ضروری است. این چالشی است که اغلب هنگام کار با اسناد بزرگتر با آن مواجه می شوید. چالش دیگر با RAG این است که با بازیابی، شما از پرس و جوهای خاصی که سیستم ذخیره سازی اسناد شما در هنگام جذب با آنها برخورد می کند، آگاه نیستید. این می تواند منجر به این شود که اطلاعات مربوط به یک پرس و جو در زیر متن مدفون شود (سرریز بافت). برای کاهش خطا و بهبود معماری RAG موجود، میتوانید از الگوهای پیشرفته RAG (بازیابی سند والد و فشردهسازی متنی) برای کاهش خطاهای بازیابی، بهبود کیفیت پاسخ و فعال کردن مدیریت سؤالات پیچیده استفاده کنید.
با تکنیکهای مورد بحث در این پست، میتوانید چالشهای کلیدی مرتبط با بازیابی و ادغام دانش خارجی را برطرف کنید و برنامهتان را قادر به ارائه پاسخهای دقیقتر و آگاهانهتر کنید.
در بخشهای بعدی، چگونگی آن را بررسی میکنیم بازیابی اسناد والدین و فشرده سازی متنی می تواند به شما کمک کند تا با برخی از مشکلاتی که در مورد آنها صحبت کردیم مقابله کنید.
بازیابی اسناد والدین
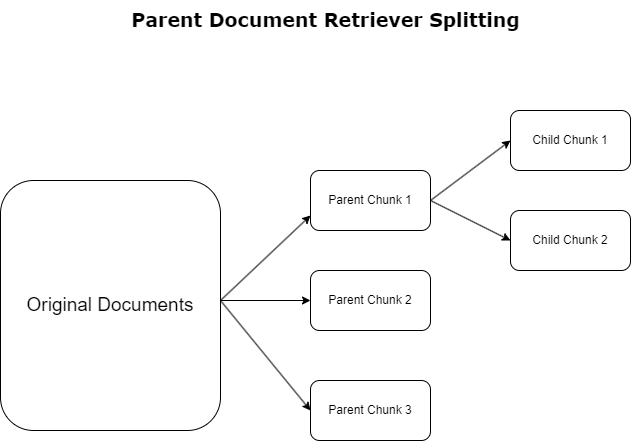
در بخش قبل، چالشهایی را که برنامههای RAG هنگام برخورد با اسناد گسترده با آن مواجه میشوند، برجسته کردیم. برای مقابله با این چالش ها، بازیابی اسناد والدین دسته بندی و تعیین اسناد ورودی به عنوان اسناد والدین. این اسناد به دلیل ماهیت جامع آنها شناخته می شوند اما مستقیماً در شکل اصلی خود برای جاسازی استفاده نمی شوند. به جای فشرده سازی کل یک سند در یک جاسازی واحد، بازیابی اسناد والد این اسناد والد را در اسناد کودک. هر سند فرزند جنبه ها یا موضوعات متمایز را از سند والد گسترده تر نشان می دهد. پس از شناسایی این بخشهای کودک، تعبیههای فردی به هر یک اختصاص داده میشود و جوهر موضوعی خاص آنها را نشان میدهد (نمودار زیر را ببینید). در حین بازیابی، سند مادر فراخوانی می شود. این تکنیک قابلیتهای جستجوی هدفمند و در عین حال گستردهای را فراهم میکند و به LLM چشمانداز وسیعتری ارائه میکند. بازیابی اسناد والد یک مزیت دوگانه برای LLM ها فراهم می کند: اختصاصی بودن جاسازی اسناد فرزند برای بازیابی اطلاعات دقیق و مرتبط، همراه با فراخوانی اسناد والد برای تولید پاسخ، که خروجی های LLM را با یک زمینه لایه ای و کامل غنی می کند.
فشرده سازی متنی
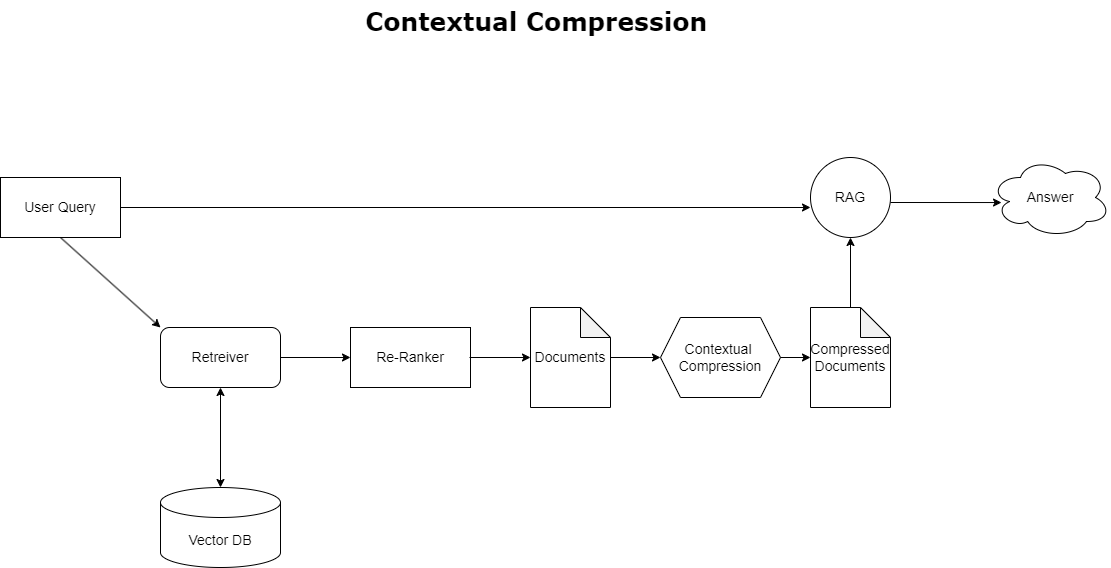
برای پرداختن به موضوع سرریز زمینه که قبلاً بحث شد، می توانید استفاده کنید فشرده سازی متنی برای فشرده سازی و فیلتر کردن اسناد بازیابی شده در تراز با زمینه پرس و جو، بنابراین فقط اطلاعات مربوط نگهداری و پردازش می شود. این امر از طریق ترکیبی از یک بازیابی پایه برای واکشی اولیه سند و یک کمپرسور سند برای اصلاح این اسناد با تجزیه محتوای آنها یا حذف کامل آنها بر اساس ارتباط، همانطور که در نمودار زیر نشان داده شده است، به دست می آید. این رویکرد کارآمد، که توسط بازیابی فشرده سازی متنی تسهیل می شود، با ارائه روشی برای استخراج و استفاده تنها از آنچه از انبوه اطلاعات ضروری است، کارایی برنامه RAG را تا حد زیادی افزایش می دهد. این موضوع به طور مستقیم با مسئله اضافه بار اطلاعات و پردازش نامربوط داده ها مقابله می کند، که منجر به بهبود کیفیت پاسخ، عملیات LLM مقرون به صرفه تر، و فرآیند بازیابی کلی نرم تر می شود. اساساً، این فیلتری است که اطلاعات را بر اساس پرس و جوی موجود تنظیم می کند و آن را به ابزاری بسیار مورد نیاز برای توسعه دهندگانی تبدیل می کند که قصد دارند برنامه های RAG خود را برای عملکرد بهتر و رضایت کاربر بهینه کنند.
پیش نیازها
اگر با SageMaker تازه کار هستید، به آن مراجعه کنید راهنمای توسعه Amazon SageMaker.
قبل از اینکه راه حل را شروع کنید، یک حساب AWS ایجاد کنید. هنگامی که یک حساب AWS ایجاد می کنید، یک هویت ورود به سیستم (SSO) دریافت می کنید که به تمام خدمات و منابع AWS در حساب دسترسی کامل دارد. این هویت حساب AWS نامیده می شود کاربر ریشه.
ورود به سیستم کنسول مدیریت AWS استفاده از آدرس ایمیل و رمز عبوری که برای ایجاد حساب کاربری استفاده کردید، به شما امکان دسترسی کامل به تمام منابع AWS در حساب خود را می دهد. ما قویاً توصیه می کنیم که از کاربر root برای کارهای روزمره، حتی کارهای اداری استفاده نکنید.
در عوض، به آن پایبند باشید بهترین شیوه های امنیتی in هویت AWS و مدیریت دسترسی (IAM)، و یک کاربر و گروه اداری ایجاد کنید. سپس به طور ایمن اعتبار کاربری root را قفل کنید و از آنها برای انجام تنها چند کار مدیریت حساب و سرویس استفاده کنید.
مدل Mixtral-8x7b به یک نمونه ml.g5.48xlarge نیاز دارد. SageMaker JumpStart روشی ساده برای دسترسی و استقرار بیش از 100 مدل منبع باز و پایه شخص ثالث مختلف را ارائه می دهد. به منظور. واسه اینکه. برای اینکه یک نقطه پایانی برای میزبانی Mixtral-8x7B از SageMaker JumpStart راه اندازی کنید، ممکن است برای دسترسی به یک نمونه ml.g5.48xlarge برای استفاده از نقطه پایانی نیاز به افزایش سهمیه خدمات داشته باشید. تو می توانی درخواست سهمیه خدمات افزایش می یابد از طریق کنسول، رابط خط فرمان AWS (AWS CLI)، یا API برای اجازه دسترسی به آن منابع اضافی.
یک نمونه نوت بوک SageMaker را راه اندازی کنید و وابستگی ها را نصب کنید
برای شروع، یک نمونه نوت بوک SageMaker ایجاد کنید و وابستگی های مورد نیاز را نصب کنید. رجوع به GitHub repo برای اطمینان از راه اندازی موفق پس از تنظیم نمونه نوت بوک، می توانید مدل را مستقر کنید.
همچنین می توانید نوت بوک را به صورت محلی در محیط توسعه یکپارچه ترجیحی خود (IDE) اجرا کنید. مطمئن شوید که آزمایشگاه نوت بوک Jupyter را نصب کرده اید.
مدل را مستقر کنید
استقرار مدل Mixtral-8X7B Instruct LLM در SageMaker JumpStart:
مدل جاسازی BGE Large En را در SageMaker JumpStart اجرا کنید:
LangChain را راه اندازی کنید
پس از وارد کردن تمام کتابخانههای لازم و استقرار مدل Mixtral-8x7B و مدل جاسازیهای BGE Large En، اکنون میتوانید LangChain را راهاندازی کنید. برای دستورالعمل های گام به گام، به GitHub repo.
آماده سازی داده ها
در این پست، ما از چندین سال نامه آمازون به سهامداران به عنوان مجموعه متنی برای اجرای QnA استفاده می کنیم. برای جزئیات بیشتر مراحل آماده سازی داده ها، به ادامه مطلب مراجعه کنید GitHub repo.
جواب سوال
پس از آماده شدن داده ها، می توانید از لفاف ارائه شده توسط LangChain استفاده کنید که در اطراف فروشگاه برداری می پیچد و ورودی LLM را می گیرد. این روکش مراحل زیر را انجام می دهد:
- سوال ورودی را بپذیرید.
- یک جاسازی سوال ایجاد کنید.
- اسناد مربوطه را واکشی کنید
- مدارک و سوال را در یک درخواست بگنجانید.
- مدل را با اعلان فراخوانی کنید و پاسخ را به صورت خوانا تولید کنید.
اکنون که فروشگاه وکتور درست شده است، می توانید شروع به پرسیدن سؤال کنید:
زنجیره رتریور معمولی
در سناریوی قبلی، ما راه سریع و سرراست برای به دست آوردن یک پاسخ آگاهانه به سوال شما را بررسی کردیم. اکنون بیایید به گزینه قابل تنظیم تر با کمک RetrievalQA نگاه کنیم، جایی که می توانید نحوه افزودن اسناد واکشی شده به درخواست را با استفاده از پارامتر chain_type سفارشی کنید. همچنین برای کنترل تعداد اسناد مربوطه که باید بازیابی شوند، می توانید پارامتر k را در کد زیر تغییر دهید تا خروجی های مختلف را مشاهده کنید. در بسیاری از سناریوها، ممکن است بخواهید بدانید که LLM از کدام اسناد منبع برای ایجاد پاسخ استفاده کرده است. می توانید با استفاده از آن اسناد را در خروجی دریافت کنید return_source_documents، که اسنادی را که به متن اعلان LLM اضافه شده اند برمی گرداند. RetrievalQA همچنین به شما امکان می دهد یک الگوی درخواستی سفارشی ارائه دهید که می تواند مختص مدل باشد.
بیایید یک سوال بپرسیم:
زنجیره بازیابی اسناد والدین
بیایید به یک گزینه RAG پیشرفته تر با کمک نگاه کنیم ParentDocumentRetriever. هنگام کار با بازیابی سند، ممکن است با یک مبادله بین ذخیره تکه های کوچک یک سند برای جاسازی دقیق و اسناد بزرگتر برای حفظ بافت بیشتر مواجه شوید. بازیابی سند مادر با تقسیم و ذخیره تکه های کوچک داده، این تعادل را ایجاد می کند.
ما از a استفاده می کنیم parent_splitter برای تقسیم اسناد اصلی به تکه های بزرگتر به نام اسناد مادر و الف child_splitter برای ایجاد اسناد فرزند کوچکتر از اسناد اصلی:
سپس اسناد فرزند با استفاده از جاسازی ها در یک فروشگاه برداری نمایه می شوند. این امکان بازیابی کارآمد اسناد مربوط به کودک را بر اساس شباهت فراهم می کند. برای بازیابی اطلاعات مربوطه، بازیابی سند والد ابتدا اسناد فرزند را از فروشگاه برداری واکشی می کند. سپس شناسههای والدین را برای آن اسناد فرزند جستجو میکند و اسناد والدین بزرگتر مربوطه را برمیگرداند.
بیایید یک سوال بپرسیم:
زنجیره فشرده سازی متنی
بیایید به یکی دیگر از گزینه های پیشرفته RAG به نام نگاه کنیم فشرده سازی متنی. یکی از چالشهای بازیابی این است که معمولاً ما نمیدانیم که سیستم ذخیرهسازی اسناد شما هنگام وارد کردن دادهها به سیستم با چه سؤالاتی مواجه میشود. این بدان معنی است که اطلاعات مرتبط با یک پرس و جو ممکن است در یک سند با متن های نامربوط زیادی دفن شود. انتقال آن سند کامل از طریق برنامه شما می تواند منجر به تماس های LLM گران تر و پاسخ های ضعیف تر شود.
بازیابی فشرده سازی متنی به چالش بازیابی اطلاعات مربوطه از یک سیستم ذخیره سازی اسناد می پردازد، جایی که داده های مربوطه ممکن است در اسناد حاوی متن زیادی دفن شوند. با فشرده سازی و فیلتر کردن اسناد بازیابی شده بر اساس زمینه پرس و جو داده شده، تنها مرتبط ترین اطلاعات برگردانده می شود.
برای استفاده از بازیابی فشرده سازی متنی، به موارد زیر نیاز دارید:
- یک بیس رتریور – این بازیابی اولیه است که اسناد را بر اساس پرس و جو از سیستم ذخیره سازی واکشی می کند
- یک کمپرسور اسناد - این مؤلفه اسناد اولیه بازیابی شده را می گیرد و با کاهش محتوای اسناد جداگانه یا حذف کلی اسناد نامربوط، با استفاده از زمینه پرس و جو برای تعیین ارتباط، آنها را کوتاه می کند.
افزودن فشرده سازی متنی با استخراج زنجیر LLM
ابتدا بیس رتریور خود را با یک عدد بپیچید ContextualCompressionRetriever. شما یک را اضافه خواهید کرد LLMChainExtractor، که روی اسناد بازگشتی اولیه تکرار می شود و از هر یک فقط محتوای مربوط به درخواست را استخراج می کند.
زنجیره را با استفاده از ContextualCompressionRetriever با LLMChainExtractor و اعلان را از طریق chain_type_kwargs بحث و جدل.
بیایید یک سوال بپرسیم:
اسناد را با فیلتر زنجیره ای LLM فیلتر کنید
La LLMChainFilter کمپرسور کمی سادهتر اما قویتر است که از یک زنجیره LLM استفاده میکند تا تصمیم بگیرد کدام یک از اسناد بازیابی اولیه را فیلتر کند و کدام یک را بازگرداند، بدون دستکاری محتوای سند:
زنجیره را با استفاده از ContextualCompressionRetriever با LLMChainFilter و اعلان را از طریق chain_type_kwargs بحث و جدل.
بیایید یک سوال بپرسیم:
نتایج را مقایسه کنید
جدول زیر نتایج حاصل از پرس و جوهای مختلف را بر اساس تکنیک مقایسه می کند.
| تکنیک | پرس و جو 1 | پرس و جو 2 | مقایسه |
| AWS چگونه تکامل یافت؟ | چرا آمازون موفق است؟ | ||
| خروجی زنجیره رتریور معمولی | AWS (سرویسهای وب آمازون) از یک سرمایهگذاری اولیه بیسود به یک کسبوکار با نرخ درآمد سالانه 85 میلیارد دلاری با سودآوری قوی، ارائه طیف گستردهای از خدمات و ویژگیها و تبدیل شدن به بخش مهمی از سبد سهام آمازون تبدیل شد. علیرغم اینکه AWS با بدبینی ها و بادهای مخالف کوتاه مدت مواجه بود، به نوآوری، جذب مشتریان جدید و مهاجرت مشتریان فعال ادامه داد و مزایایی مانند چابکی، نوآوری، کارایی هزینه و امنیت را ارائه داد. AWS همچنین سرمایهگذاریهای بلندمدت خود از جمله توسعه تراشه را برای ارائه قابلیتهای جدید و تغییر آنچه برای مشتریانش ممکن است، گسترش داد. | آمازون به دلیل نوآوری و گسترش مستمر خود در زمینههای جدید مانند خدمات زیرساخت فناوری، دستگاههای خواندن دیجیتال، دستیارهای شخصی مبتنی بر صدا و مدلهای تجاری جدید مانند بازار شخص ثالث موفق است. توانایی آن در مقیاس سریع عملیات، همانطور که در گسترش سریع شبکه های تکمیل و حمل و نقل آن دیده می شود، نیز به موفقیت آن کمک می کند. علاوه بر این، تمرکز آمازون بر بهینه سازی و افزایش بهره وری در فرآیندهای خود منجر به بهبود بهره وری و کاهش هزینه شده است. مثال کسب و کار آمازون، توانایی این شرکت در استفاده از تجارت الکترونیک و نقاط قوت لجستیک در بخشهای مختلف را برجسته میکند. | بر اساس پاسخهای زنجیره بازیابی معمولی، متوجه میشویم که اگرچه پاسخهای طولانی ارائه میکند، اما از سرریز زمینه رنج میبرد و هیچ جزئیات قابل توجهی از مجموعه را در رابطه با پاسخ به پرسش ارائهشده ذکر نمیکند. زنجیره بازیابی منظم قادر به گرفتن نکات ظریف با عمق یا بینش متنی نیست، و به طور بالقوه جنبه های مهم سند را از دست می دهد. |
| خروجی بازیابی سند والد | AWS (سرویسهای وب آمازون) با راهاندازی اولیه سرویس Elastic Compute Cloud (EC2) در سال 2006 شروع به کار کرد و تنها یک اندازه نمونه را در یک مرکز داده، در یک منطقه از جهان، تنها با نمونههای سیستم عامل لینوکس ارائه کرد. و بدون بسیاری از ویژگی های کلیدی مانند نظارت، تعادل بار، مقیاس خودکار یا ذخیره سازی مداوم. با این حال، موفقیت AWS به آنها اجازه داد تا به سرعت تکرار کنند و قابلیتهای از دست رفته را اضافه کنند، در نهایت برای ارائه طعمها، اندازهها، و بهینهسازیهای مختلف محاسبات، ذخیرهسازی و شبکه، و همچنین توسعه تراشههای خود (Graviton) برای افزایش قیمت و عملکرد گسترش یافت. . فرآیند نوآوری تکراری AWS مستلزم سرمایهگذاری قابل توجهی در منابع مالی و مردمی در طی 20 سال بود، اغلب خیلی زودتر از زمان پرداخت، برای رفع نیازهای مشتری و بهبود تجارب بلندمدت مشتری، وفاداری و بازده سهامداران. | آمازون به دلیل توانایی خود در نوآوری مداوم، انطباق با شرایط متغیر بازار و برآوردن نیازهای مشتریان در بخش های مختلف بازار موفق است. این امر در موفقیت آمازون بیزینس مشهود است، که با ارائه انتخاب، ارزش و راحتی به مشتریان تجاری، به فروش ناخالص سالانه 35 میلیارد دلاری رسیده است. سرمایهگذاریهای آمازون در تجارت الکترونیک و قابلیتهای تدارکات، ایجاد خدماتی مانند Buy with Prime را نیز امکانپذیر کرده است، که به بازرگانان با وبسایتهای مستقیم به مصرفکننده کمک میکند تا تبدیل از بازدیدها به خرید را افزایش دهند. | بازیابی سند مادر به جزئیات استراتژی رشد AWS، از جمله فرآیند تکراری افزودن ویژگیهای جدید بر اساس بازخورد مشتری و سفر دقیق از یک راهاندازی اولیه با ویژگیهای ضعیف به موقعیت بازار غالب، عمیقتر میپردازد، در حالی که پاسخی غنی از زمینه ارائه میدهد. . پاسخها طیف گستردهای از جنبهها، از نوآوریهای فنی و استراتژی بازار گرفته تا کارایی سازمانی و تمرکز بر مشتری را در بر میگیرند، و دیدگاهی جامع از عوامل مؤثر در موفقیت همراه با مثالها ارائه میدهند. این را می توان به قابلیت های جستجوی هدفمند و در عین حال گسترده بازیابی سند والد نسبت داد. |
| استخراج کننده زنجیره ای LLM: خروجی فشرده سازی متنی | AWS با شروع به عنوان یک پروژه کوچک در داخل آمازون، که نیاز به سرمایه گذاری قابل توجهی داشت و با شک و تردید از داخل و خارج شرکت مواجه شد، تکامل یافت. با این حال، AWS از رقبای بالقوه شروع کرد و به ارزشی که می تواند برای مشتریان و آمازون به ارمغان بیاورد اعتقاد داشت. AWS تعهد بلندمدتی برای ادامه سرمایهگذاری کرد که در نتیجه آن بیش از 3,300 ویژگی و خدمات جدید در سال 2022 راهاندازی شد. AWS همچنین به طور مداوم پیشنهادات خود را بهبود بخشیده است، مانند بهبود EC85 با ویژگی ها و خدمات اضافی پس از راه اندازی اولیه. | بر اساس زمینه ارائه شده، موفقیت آمازون را می توان به گسترش استراتژیک آن از یک پلت فرم فروش کتاب به یک بازار جهانی با اکوسیستم فروشنده شخص ثالث پر جنب و جوش، سرمایه گذاری اولیه در AWS، نوآوری در معرفی Kindle و Alexa و رشد قابل توجه نسبت داد. در درآمد سالانه از 2019 تا 2022. این رشد منجر به گسترش ردپای مرکز تحقق، ایجاد یک شبکه حمل و نقل آخرین مایل، و ساخت یک شبکه مرکز مرتب سازی جدید شد که برای کاهش بهره وری و هزینه بهینه شده بودند. | استخراج زنجیر LLM تعادلی را بین پوشش کامل نقاط کلیدی و اجتناب از عمق غیر ضروری حفظ می کند. به صورت پویا با زمینه پرس و جو تنظیم می شود، بنابراین خروجی مستقیما مرتبط و جامع است. |
| فیلتر زنجیره ای LLM: خروجی فشرده سازی متنی | AWS (سرویسهای وب آمازون) با راهاندازی اولیه با ویژگیهای ضعیف اما با تکرار سریع بر اساس بازخورد مشتری برای افزودن قابلیتهای لازم تکامل یافت. این رویکرد به AWS اجازه داد تا EC2 را در سال 2006 با ویژگیهای محدود راهاندازی کند و سپس به طور مداوم قابلیتهای جدیدی مانند اندازههای نمونه اضافی، مراکز داده، مناطق، گزینههای سیستم عامل، ابزارهای نظارت، تعادل بار، مقیاس خودکار و ذخیرهسازی مداوم را اضافه کند. با گذشت زمان، AWS با تمرکز بر نیازهای مشتری، چابکی، نوآوری، کارایی هزینه و امنیت، از یک سرویس ضعیف به یک تجارت چند میلیارد دلاری تبدیل شد. AWS اکنون دارای نرخ درآمد سالانه 85 میلیارد دلاری است و بیش از 3,300 ویژگی و خدمات جدید را در هر سال ارائه میکند که به طیف وسیعی از مشتریان از شرکتهای نوپا گرفته تا شرکتهای چندملیتی و سازمانهای بخش عمومی خدمات ارائه میدهد. | آمازون به دلیل مدل های کسب و کار نوآورانه، پیشرفت های مداوم تکنولوژیکی و تغییرات استراتژیک سازمانی موفق است. این شرکت با معرفی ایدههای جدید، مانند پلتفرم تجارت الکترونیک برای محصولات و خدمات مختلف، بازار شخص ثالث، خدمات زیرساخت ابری (AWS)، کتابخوان الکترونیکی Kindle و دستیار شخصی صوتی الکسا، همواره صنایع سنتی را مختل کرده است. . علاوه بر این، آمازون تغییرات ساختاری برای بهبود کارایی خود ایجاد کرده است، مانند سازماندهی مجدد شبکه اجرای ایالات متحده برای کاهش هزینه ها و زمان تحویل، که بیشتر به موفقیت آن کمک می کند. | فیلتر زنجیره ای LLM مانند استخراج کننده زنجیره ای LLM اطمینان می دهد که اگرچه نکات کلیدی پوشش داده شده است، اما خروجی برای مشتریانی که به دنبال پاسخ های مختصر و متنی هستند کارآمد است. |
با مقایسه این تکنیکهای مختلف، میتوانیم ببینیم که در زمینههایی مانند توضیح جزئیات انتقال AWS از یک سرویس ساده به یک موجودیت پیچیده و چند میلیارد دلاری، یا توضیح موفقیتهای استراتژیک آمازون، زنجیره معمولی رتریور فاقد دقتی است که تکنیکهای پیچیدهتر ارائه میدهند. منجر به اطلاعات کمتر هدفمند می شود. اگرچه تفاوتهای بسیار کمی بین تکنیکهای پیشرفته مورد بحث قابل مشاهده است، اما آنها بسیار آموزندهتر از زنجیرههای رتریور معمولی هستند.
برای مشتریانی در صنایعی مانند مراقبتهای بهداشتی، مخابرات و خدمات مالی که به دنبال پیادهسازی RAG در برنامههای خود هستند، محدودیتهای زنجیره بازیابی معمولی در ارائه دقت، اجتناب از افزونگی و فشردهسازی مؤثر اطلاعات، آن را برای برآوردن این نیازها در مقایسه با آنها کمتر مناسب میسازد. به تکنیک های پیشرفته تر بازیابی اسناد والد و فشرده سازی متنی. این تکنیکها میتوانند حجم وسیعی از اطلاعات را در بینشهای متمرکز و تأثیرگذار مورد نیاز شما جمعآوری کنند، در حالی که به بهبود عملکرد قیمت کمک میکنند.
پاک کردن
پس از اتمام کار با نوت بوک، منابعی را که ایجاد کرده اید حذف کنید تا از انباشت هزینه برای منابع در حال استفاده جلوگیری کنید:
نتیجه
در این پست، راهحلی ارائه کردیم که به شما امکان میدهد تکنیکهای بازیابی سند والد و زنجیره فشردهسازی متنی را برای افزایش توانایی LLM برای پردازش و تولید اطلاعات پیادهسازی کنید. ما این تکنیکهای پیشرفته RAG را با مدلهای Mixtral-8x7B Instruct و BGE Large En موجود با SageMaker JumpStart آزمایش کردیم. ما همچنین استفاده از ذخیرهسازی دائمی برای جاسازیها و تکههای سند و ادغام با فروشگاههای داده سازمانی را بررسی کردیم.
تکنیکهایی که ما انجام دادیم نه تنها نحوه دسترسی مدلهای LLM و ترکیب دانش خارجی را اصلاح میکند، بلکه کیفیت، ارتباط و کارایی خروجیهای آنها را نیز بهطور قابلتوجهی بهبود میبخشد. این تکنیکهای پیشرفته RAG با ترکیب بازیابی از مجموعههای متنی بزرگ با قابلیتهای تولید زبان، LLMها را قادر میسازد تا پاسخهای واقعیتر، منسجمتر و متناسب با زمینه تولید کنند و عملکرد آنها را در وظایف مختلف پردازش زبان طبیعی افزایش دهند.
SageMaker JumpStart در مرکز این راه حل قرار دارد. با SageMaker JumpStart، به مجموعه گسترده ای از مدل های منبع باز و بسته دسترسی پیدا می کنید، روند شروع کار با ML را ساده می کند و آزمایش و استقرار سریع را امکان پذیر می کند. برای شروع به کارگیری این راه حل، به نوت بوک موجود در قسمت بروید GitHub repo.
درباره نویسنده
 نییتیین ویجاسواران یک معمار راه حل در AWS است. حوزه تمرکز او بر روی شتاب دهنده های هوش مصنوعی مولد و AWS AI است. او دارای مدرک لیسانس در رشته علوم کامپیوتر و بیوانفورماتیک است. Niithiyn از نزدیک با تیم Generative AI GTM همکاری می کند تا مشتریان AWS را در چندین جبهه فعال کند و پذیرش هوش مصنوعی مولد را تسریع بخشد. او از طرفداران پرشور دالاس ماوریکس است و از جمع آوری کفش های کتانی لذت می برد.
نییتیین ویجاسواران یک معمار راه حل در AWS است. حوزه تمرکز او بر روی شتاب دهنده های هوش مصنوعی مولد و AWS AI است. او دارای مدرک لیسانس در رشته علوم کامپیوتر و بیوانفورماتیک است. Niithiyn از نزدیک با تیم Generative AI GTM همکاری می کند تا مشتریان AWS را در چندین جبهه فعال کند و پذیرش هوش مصنوعی مولد را تسریع بخشد. او از طرفداران پرشور دالاس ماوریکس است و از جمع آوری کفش های کتانی لذت می برد.
 سباستین بوستیلو یک معمار راه حل در AWS است. او با اشتیاق عمیق به هوش مصنوعی مولد و شتابدهندههای محاسباتی روی فناوریهای AI/ML تمرکز دارد. او در AWS به مشتریان کمک می کند تا ارزش کسب و کار را از طریق هوش مصنوعی مولد باز کنند. وقتی سر کار نیست، از دم کردن یک فنجان قهوه مخصوص و کاوش در دنیا با همسرش لذت می برد.
سباستین بوستیلو یک معمار راه حل در AWS است. او با اشتیاق عمیق به هوش مصنوعی مولد و شتابدهندههای محاسباتی روی فناوریهای AI/ML تمرکز دارد. او در AWS به مشتریان کمک می کند تا ارزش کسب و کار را از طریق هوش مصنوعی مولد باز کنند. وقتی سر کار نیست، از دم کردن یک فنجان قهوه مخصوص و کاوش در دنیا با همسرش لذت می برد.
 آرماندو دیاز یک معمار راه حل در AWS است. او بر روی هوش مصنوعی، AI/ML و تجزیه و تحلیل داده های مولد تمرکز دارد. در AWS، آرماندو به مشتریان کمک میکند تا قابلیتهای پیشرفته هوش مصنوعی را در سیستمهای خود ادغام کنند و نوآوری و مزیت رقابتی را تقویت کنند. وقتی سر کار نیست، از گذراندن وقت با همسر و خانواده، پیاده روی و سفر به دور دنیا لذت می برد.
آرماندو دیاز یک معمار راه حل در AWS است. او بر روی هوش مصنوعی، AI/ML و تجزیه و تحلیل داده های مولد تمرکز دارد. در AWS، آرماندو به مشتریان کمک میکند تا قابلیتهای پیشرفته هوش مصنوعی را در سیستمهای خود ادغام کنند و نوآوری و مزیت رقابتی را تقویت کنند. وقتی سر کار نیست، از گذراندن وقت با همسر و خانواده، پیاده روی و سفر به دور دنیا لذت می برد.
 دکتر فاروق صابر یک معمار ارشد راه حل های متخصص هوش مصنوعی و یادگیری ماشین در AWS است. او دارای مدرک دکتری و کارشناسی ارشد در مهندسی برق از دانشگاه تگزاس در آستین و کارشناسی ارشد در علوم کامپیوتر از موسسه فناوری جورجیا است. او بیش از 15 سال سابقه کار دارد و همچنین دوست دارد به دانشجویان کالج تدریس و راهنمایی کند. او در AWS به مشتریان کمک می کند تا مشکلات تجاری خود را در زمینه علم داده، یادگیری ماشین، بینایی کامپیوتر، هوش مصنوعی، بهینه سازی عددی و حوزه های مرتبط فرموله و حل کنند. او و خانواده اش که در دالاس، تگزاس مستقر هستند، عاشق سفر و رفتن به سفرهای جاده ای طولانی هستند.
دکتر فاروق صابر یک معمار ارشد راه حل های متخصص هوش مصنوعی و یادگیری ماشین در AWS است. او دارای مدرک دکتری و کارشناسی ارشد در مهندسی برق از دانشگاه تگزاس در آستین و کارشناسی ارشد در علوم کامپیوتر از موسسه فناوری جورجیا است. او بیش از 15 سال سابقه کار دارد و همچنین دوست دارد به دانشجویان کالج تدریس و راهنمایی کند. او در AWS به مشتریان کمک می کند تا مشکلات تجاری خود را در زمینه علم داده، یادگیری ماشین، بینایی کامپیوتر، هوش مصنوعی، بهینه سازی عددی و حوزه های مرتبط فرموله و حل کنند. او و خانواده اش که در دالاس، تگزاس مستقر هستند، عاشق سفر و رفتن به سفرهای جاده ای طولانی هستند.
 مارکو پونیو یک معمار راه حل است که بر استراتژی هوش مصنوعی مولد، راه حل های هوش مصنوعی کاربردی و انجام تحقیقات برای کمک به مشتریان در مقیاس بیش از حد در AWS متمرکز است. مارکو یک مشاور ابر بومی دیجیتال با تجربه در فینتک، بهداشت و درمان و علوم زندگی، نرمافزار بهعنوان سرویس، و اخیراً در صنایع مخابرات است. او یک فنشناس واجد شرایط با علاقه به یادگیری ماشینی، هوش مصنوعی، و ادغام و اکتساب است. مارکو در سیاتل، WA مستقر است و در اوقات فراغت خود از نوشتن، خواندن، ورزش و ساختن برنامه های کاربردی لذت می برد.
مارکو پونیو یک معمار راه حل است که بر استراتژی هوش مصنوعی مولد، راه حل های هوش مصنوعی کاربردی و انجام تحقیقات برای کمک به مشتریان در مقیاس بیش از حد در AWS متمرکز است. مارکو یک مشاور ابر بومی دیجیتال با تجربه در فینتک، بهداشت و درمان و علوم زندگی، نرمافزار بهعنوان سرویس، و اخیراً در صنایع مخابرات است. او یک فنشناس واجد شرایط با علاقه به یادگیری ماشینی، هوش مصنوعی، و ادغام و اکتساب است. مارکو در سیاتل، WA مستقر است و در اوقات فراغت خود از نوشتن، خواندن، ورزش و ساختن برنامه های کاربردی لذت می برد.
 ای جی دیمین یک معمار راه حل در AWS است. او در زمینه هوش مصنوعی مولد، محاسبات بدون سرور و تجزیه و تحلیل داده ها تخصص دارد. او عضو فعال/مربی در انجمن حوزه فنی یادگیری ماشین است و چندین مقاله علمی در مورد موضوعات مختلف AI/ML منتشر کرده است. او با مشتریان، از شرکت های نوپا گرفته تا شرکت ها، برای توسعه راه حل های هوش مصنوعی AWSome کار می کند. او به ویژه در مورد استفاده از مدلهای زبان بزرگ برای تجزیه و تحلیل دادههای پیشرفته و کاوش در برنامههای کاربردی که چالشهای دنیای واقعی را بررسی میکنند، علاقهمند است. خارج از محل کار، AJ از سفر لذت می برد و در حال حاضر در 53 کشور با هدف بازدید از هر کشور در جهان است.
ای جی دیمین یک معمار راه حل در AWS است. او در زمینه هوش مصنوعی مولد، محاسبات بدون سرور و تجزیه و تحلیل داده ها تخصص دارد. او عضو فعال/مربی در انجمن حوزه فنی یادگیری ماشین است و چندین مقاله علمی در مورد موضوعات مختلف AI/ML منتشر کرده است. او با مشتریان، از شرکت های نوپا گرفته تا شرکت ها، برای توسعه راه حل های هوش مصنوعی AWSome کار می کند. او به ویژه در مورد استفاده از مدلهای زبان بزرگ برای تجزیه و تحلیل دادههای پیشرفته و کاوش در برنامههای کاربردی که چالشهای دنیای واقعی را بررسی میکنند، علاقهمند است. خارج از محل کار، AJ از سفر لذت می برد و در حال حاضر در 53 کشور با هدف بازدید از هر کشور در جهان است.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- PlatoHealth. هوش بیوتکنولوژی و آزمایشات بالینی. دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/machine-learning/advanced-rag-patterns-on-amazon-sagemaker/

