Hoy en día, los clientes de todas las industrias (ya sean servicios financieros, atención médica y ciencias biológicas, viajes y hotelería, medios y entretenimiento, telecomunicaciones, software como servicio (SaaS) e incluso proveedores de modelos propietarios) están utilizando modelos de lenguaje grande (LLM) para Cree aplicaciones como chatbots de preguntas y respuestas (QnA), motores de búsqueda y bases de conocimientos. Estos IA generativa Las aplicaciones no solo se utilizan para automatizar procesos comerciales existentes, sino que también tienen la capacidad de transformar la experiencia de los clientes que utilizan estas aplicaciones. Con los avances que se están realizando con LLM como el Instrucciones Mixtral-8x7B, derivado de arquitecturas como la mezcla de expertos (MoE), los clientes buscan continuamente formas de mejorar el rendimiento y la precisión de las aplicaciones de IA generativa y al mismo tiempo permitirles utilizar de forma eficaz una gama más amplia de modelos de código abierto y cerrado.
Por lo general, se utilizan varias técnicas para mejorar la precisión y el rendimiento de los resultados de un LLM, como el ajuste con ajuste eficiente de parámetros (PEFT), aprendizaje por refuerzo a partir de la retroalimentación humana (RLHF)y realizando destilación del conocimiento. Sin embargo, al crear aplicaciones de IA generativa, puede utilizar una solución alternativa que permita la incorporación dinámica de conocimiento externo y le permita controlar la información utilizada para la generación sin la necesidad de ajustar su modelo fundamental existente. Aquí es donde entra en juego la Generación Aumentada de Recuperación (RAG), específicamente para aplicaciones de IA generativa, a diferencia de las alternativas de ajuste más costosas y robustas que hemos discutido. Si está implementando aplicaciones RAG complejas en sus tareas diarias, puede encontrar desafíos comunes con sus sistemas RAG, como recuperación inexacta, aumento del tamaño y complejidad de los documentos y desbordamiento del contexto, lo que puede afectar significativamente la calidad y confiabilidad de las respuestas generadas. .
Esta publicación analiza los patrones RAG para mejorar la precisión de la respuesta utilizando LangChain y herramientas como el recuperador de documentos principal, además de técnicas como la compresión contextual para permitir a los desarrolladores mejorar las aplicaciones de IA generativa existentes.
Resumen de la solución
En esta publicación, demostramos el uso de la generación de texto Instruct Mixtral-8x7B combinada con el modelo de incrustación BGE Large En para construir de manera eficiente un sistema RAG QnA en una computadora portátil Amazon SageMaker utilizando la herramienta de recuperación de documentos principal y la técnica de compresión contextual. El siguiente diagrama ilustra la arquitectura de esta solución.
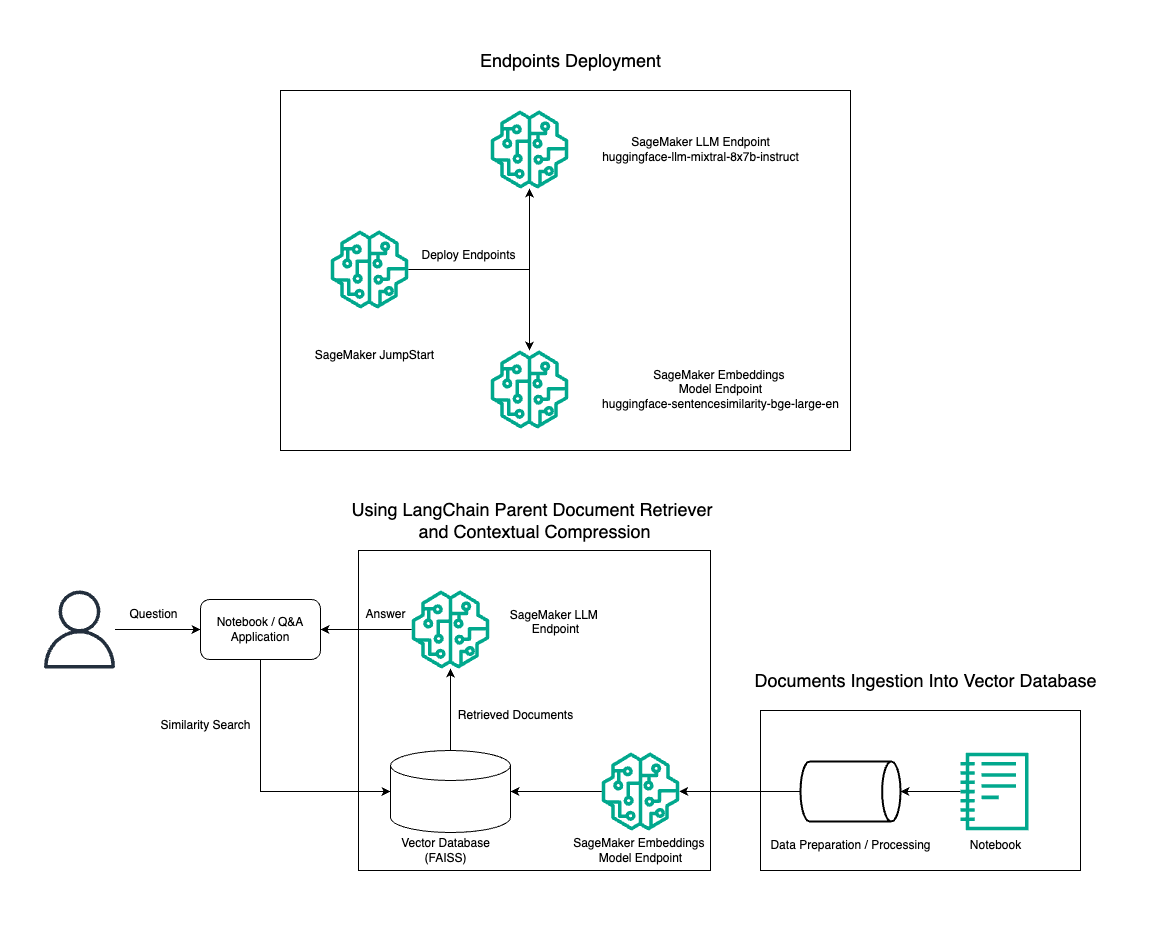
Puede implementar esta solución con solo unos pocos clics usando JumpStart de Amazon SageMaker, una plataforma totalmente administrada que ofrece modelos básicos de última generación para diversos casos de uso, como redacción de contenido, generación de código, respuesta a preguntas, redacción, resumen, clasificación y recuperación de información. Proporciona una colección de modelos previamente entrenados que puede implementar rápidamente y con facilidad, acelerando el desarrollo y la implementación de aplicaciones de aprendizaje automático (ML). Uno de los componentes clave de SageMaker JumpStart es Model Hub, que ofrece un amplio catálogo de modelos previamente entrenados, como el Mixtral-8x7B, para una variedad de tareas.
Mixtral-8x7B utiliza una arquitectura MoE. Esta arquitectura permite que diferentes partes de una red neuronal se especialicen en diferentes tareas, dividiendo efectivamente la carga de trabajo entre múltiples expertos. Este enfoque permite el entrenamiento y la implementación eficiente de modelos más grandes en comparación con las arquitecturas tradicionales.
Una de las principales ventajas de la arquitectura MoE es su escalabilidad. Al distribuir la carga de trabajo entre varios expertos, los modelos MoE se pueden entrenar en conjuntos de datos más grandes y lograr un mejor rendimiento que los modelos tradicionales del mismo tamaño. Además, los modelos MoE pueden ser más eficientes durante la inferencia porque solo es necesario activar un subconjunto de expertos para una entrada determinada.
Para obtener más información sobre Mixtral-8x7B Instruct en AWS, consulte Mixtral-8x7B ya está disponible en Amazon SageMaker JumpStart. El modelo Mixtral-8x7B está disponible bajo la licencia permisiva Apache 2.0, para su uso sin restricciones.
En esta publicación, discutimos cómo puede usar LangChain para crear aplicaciones RAG efectivas y más eficientes. LangChain es una biblioteca Python de código abierto diseñada para crear aplicaciones con LLM. Proporciona un marco modular y flexible para combinar LLM con otros componentes, como bases de conocimiento, sistemas de recuperación y otras herramientas de inteligencia artificial, para crear aplicaciones potentes y personalizables.
Analizamos la construcción de una tubería RAG en SageMaker con Mixtral-8x7B. Usamos el modelo de generación de texto Mixtral-8x7B Instruct con el modelo de incrustación BGE Large En para crear un sistema QnA eficiente usando RAG en una computadora portátil SageMaker. Usamos una instancia ml.t3.medium para demostrar la implementación de LLM a través de SageMaker JumpStart, al que se puede acceder a través de un punto final API generado por SageMaker. Esta configuración permite la exploración, experimentación y optimización de técnicas RAG avanzadas con LangChain. También ilustramos la integración de la tienda de incrustaciones FAISS en el flujo de trabajo de RAG, destacando su papel en el almacenamiento y recuperación de incrustaciones para mejorar el rendimiento del sistema.
Realizamos un breve recorrido por el cuaderno SageMaker. Para obtener instrucciones más detalladas y paso a paso, consulte la Patrones RAG avanzados con Mixtral en el repositorio SageMaker Jumpstart GitHub.
La necesidad de patrones RAG avanzados
Los patrones RAG avanzados son esenciales para mejorar las capacidades actuales de los LLM en el procesamiento, comprensión y generación de texto similar a un humano. A medida que aumentan el tamaño y la complejidad de los documentos, representar múltiples facetas del documento en una sola incrustación puede provocar una pérdida de especificidad. Aunque es esencial capturar la esencia general de un documento, es igualmente crucial reconocer y representar los variados subcontextos que contiene. Este es un desafío al que se enfrenta a menudo cuando trabaja con documentos de gran tamaño. Otro desafío con RAG es que, con la recuperación, no se conocen las consultas específicas que abordará su sistema de almacenamiento de documentos al momento de la ingesta. Esto podría provocar que la información más relevante para una consulta quede oculta bajo el texto (desbordamiento de contexto). Para mitigar las fallas y mejorar la arquitectura RAG existente, puede utilizar patrones RAG avanzados (recuperador de documentos principales y compresión contextual) para reducir los errores de recuperación, mejorar la calidad de las respuestas y permitir el manejo de preguntas complejas.
Con las técnicas analizadas en esta publicación, puede abordar desafíos clave asociados con la recuperación e integración de conocimientos externos, permitiendo que su aplicación brinde respuestas más precisas y contextualmente conscientes.
En las siguientes secciones, exploramos cómo recuperadores de documentos principales y compresión contextual puede ayudarle a resolver algunos de los problemas que hemos analizado.
Recuperador de documentos para padres
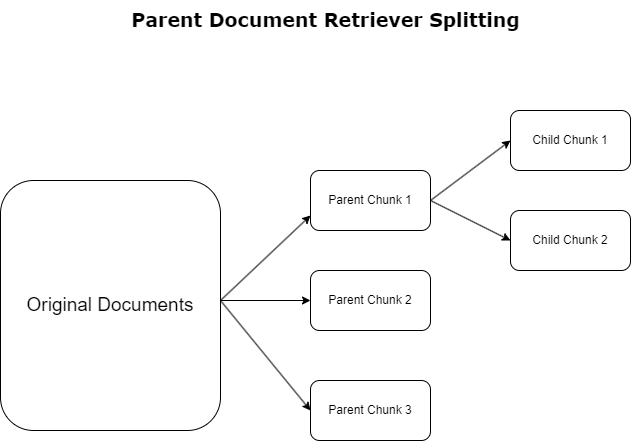
En la sección anterior, destacamos los desafíos que enfrentan las aplicaciones RAG cuando tratan con documentos extensos. Para abordar estos desafíos, recuperadores de documentos principales categorizar y designar los documentos entrantes como documentos de los padres. Estos documentos son reconocidos por su naturaleza integral pero no se utilizan directamente en su forma original para incrustaciones. En lugar de comprimir un documento completo en una sola incrustación, los recuperadores de documentos principales analizan estos documentos principales en documentos infantiles. Cada documento secundario captura distintos aspectos o temas del documento principal más amplio. Tras la identificación de estos segmentos secundarios, se asignan incrustaciones individuales a cada uno, capturando su esencia temática específica (consulte el siguiente diagrama). Durante la recuperación, se invoca el documento principal. Esta técnica proporciona capacidades de búsqueda específicas pero de amplio alcance, lo que proporciona al LLM una perspectiva más amplia. Los recuperadores de documentos principales brindan a los LLM una doble ventaja: la especificidad de las incrustaciones de documentos secundarios para la recuperación de información precisa y relevante, junto con la invocación de documentos principales para la generación de respuestas, lo que enriquece los resultados del LLM con un contexto completo y en capas.
Compresión contextual
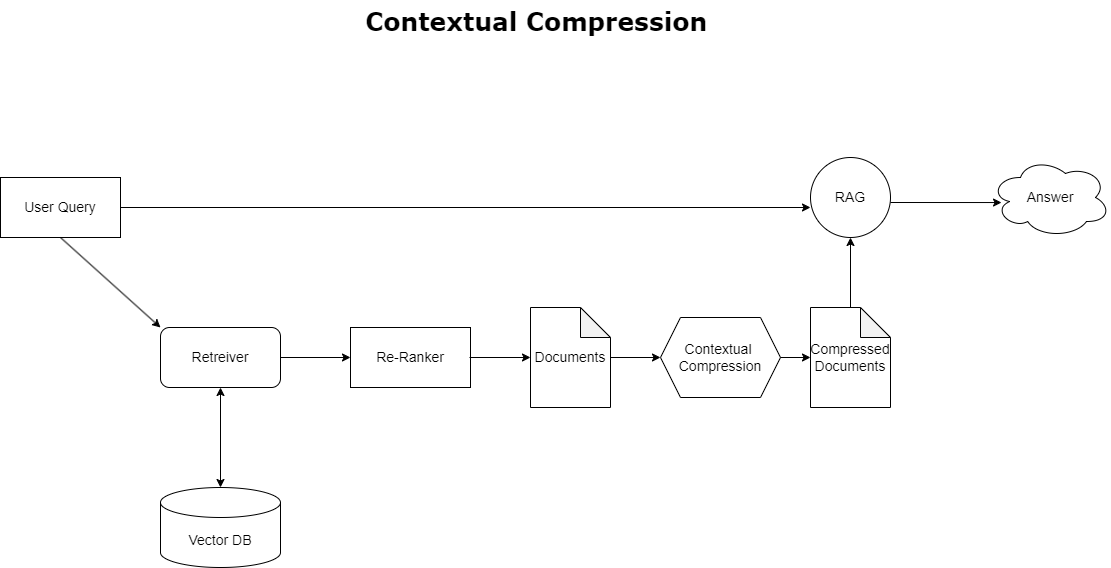
Para abordar el problema del desbordamiento de contexto discutido anteriormente, puede usar compresión contextual para comprimir y filtrar los documentos recuperados en alineación con el contexto de la consulta, de modo que solo se conserve y procese la información pertinente. Esto se logra mediante una combinación de un recuperador de base para la recuperación inicial de documentos y un compresor de documentos para refinar estos documentos reduciendo su contenido o excluyéndolos por completo según su relevancia, como se ilustra en el siguiente diagrama. Este enfoque optimizado, facilitado por el recuperador de compresión contextual, mejora en gran medida la eficiencia de la aplicación RAG al proporcionar un método para extraer y utilizar sólo lo esencial de una masa de información. Aborda de frente el problema de la sobrecarga de información y el procesamiento de datos irrelevantes, lo que conduce a una mejor calidad de respuesta, operaciones de LLM más rentables y un proceso de recuperación general más fluido. Básicamente, es un filtro que adapta la información a la consulta en cuestión, lo que la convierte en una herramienta muy necesaria para los desarrolladores que buscan optimizar sus aplicaciones RAG para un mejor rendimiento y satisfacción del usuario.
Requisitos previos
Si es nuevo en SageMaker, consulte la Guía de desarrollo de Amazon SageMaker.
Antes de comenzar con la solución, crear una cuenta de AWS. Cuando crea una cuenta de AWS, obtiene una identidad de inicio de sesión único (SSO) que tiene acceso completo a todos los servicios y recursos de AWS de la cuenta. Esta identidad se llama cuenta de AWS. usuario root.
Iniciar sesión en el Consola de administración de AWS El uso de la dirección de correo electrónico y la contraseña que utilizó para crear la cuenta le brinda acceso completo a todos los recursos de AWS en su cuenta. Le recomendamos encarecidamente que no utilice el usuario root para las tareas cotidianas, ni siquiera las administrativas.
En lugar de ello, adhiérase a las mejores prácticas de seguridad in Gestión de identidades y accesos de AWS (Soy y crear un usuario y grupo administrativo. Luego, guarde de forma segura las credenciales del usuario raíz y utilícelas para realizar solo unas pocas tareas de administración de cuentas y servicios.
El modelo Mixtral-8x7b requiere una instancia ml.g5.48xlarge. SageMaker JumpStart proporciona una forma simplificada de acceder e implementar más de 100 modelos básicos de código abierto y de terceros diferentes. Con el fin de lanzar un punto final para alojar Mixtral-8x7B desde SageMaker JumpStart, es posible que deba solicitar un aumento de la cuota de servicio para acceder a una instancia ml.g5.48xlarge para uso de endpoints. Puede solicitar aumentos de cuota de servicio a través de la consola, Interfaz de línea de comandos de AWS (AWS CLI) o API para permitir el acceso a esos recursos adicionales.
Configurar una instancia de cuaderno de SageMaker e instalar dependencias
Para comenzar, cree una instancia de cuaderno de SageMaker e instale las dependencias necesarias. Referirse a Repositorio GitHub para garantizar una configuración exitosa. Después de configurar la instancia del cuaderno, puede implementar el modelo.
También puede ejecutar el portátil localmente en su entorno de desarrollo integrado (IDE) preferido. Asegúrese de tener instalado el laboratorio de portátiles Jupyter.
Implementar el modelo
Implemente el modelo Mixtral-8X7B Instruct LLM en SageMaker JumpStart:
Implemente el modelo de incrustación BGE Large En en SageMaker JumpStart:
Configurar LangChain
Después de importar todas las bibliotecas necesarias e implementar el modelo Mixtral-8x7B y el modelo de incorporación BGE Large En, ahora puede configurar LangChain. Para obtener instrucciones paso a paso, consulte la Repositorio GitHub.
Preparación de datos
En esta publicación, utilizamos varios años de Cartas a los accionistas de Amazon como corpus de texto para realizar QnA. Para conocer pasos más detallados para preparar los datos, consulte la Repositorio GitHub.
Respuesta a la pregunta
Una vez que los datos estén preparados, puede usar el contenedor proporcionado por LangChain, que envuelve el almacén de vectores y toma información para el LLM. Este contenedor realiza los siguientes pasos:
- Responda la pregunta de entrada.
- Crea una pregunta incrustada.
- Obtener documentos relevantes.
- Incorpore los documentos y la pregunta en un mensaje.
- Invoque el modelo con el mensaje y genere la respuesta de manera legible.
Ahora que la tienda de vectores está operativa, puedes empezar a hacer preguntas:
Cadena de perro perdiguero normal
En el escenario anterior, exploramos la forma rápida y sencilla de obtener una respuesta contextual a su pregunta. Ahora veamos una opción más personalizable con la ayuda de RetrievalQA, donde puede personalizar cómo se deben agregar los documentos recuperados al mensaje utilizando el parámetro chain_type. Además, para controlar cuántos documentos relevantes se deben recuperar, puede cambiar el parámetro k en el siguiente código para ver diferentes resultados. En muchos escenarios, es posible que desee saber qué documentos fuente utilizó el LLM para generar la respuesta. Puede obtener esos documentos en la salida usando return_source_documents, que devuelve los documentos que se agregan al contexto del mensaje LLM. RetrievalQA también le permite proporcionar una plantilla de aviso personalizada que puede ser específica del modelo.
Hagamos una pregunta:
Cadena de recuperación de documentos principal
Veamos una opción RAG más avanzada con la ayuda de Recuperador De Documentos Padres. Al trabajar con la recuperación de documentos, es posible que encuentre un equilibrio entre almacenar pequeños fragmentos de un documento para incrustaciones precisas y documentos más grandes para preservar más contexto. El recuperador de documentos principal logra ese equilibrio dividiendo y almacenando pequeños fragmentos de datos.
Usamos un parent_splitter dividir los documentos originales en partes más grandes llamadas documentos principales y un child_splitter para crear documentos secundarios más pequeños a partir de los documentos originales:
Luego, los documentos secundarios se indexan en un almacén de vectores mediante incrustaciones. Esto permite la recuperación eficiente de documentos secundarios relevantes en función de la similitud. Para recuperar información relevante, el recuperador de documentos principal primero recupera los documentos secundarios del almacén de vectores. Luego busca los ID de los padres de esos documentos secundarios y devuelve los documentos principales más grandes correspondientes.
Hagamos una pregunta:
Cadena de compresión contextual
Veamos otra opción RAG avanzada llamada compresión contextual. Un desafío con la recuperación es que generalmente no conocemos las consultas específicas que enfrentará su sistema de almacenamiento de documentos cuando ingiera datos en el sistema. Esto significa que la información más relevante para una consulta puede estar oculta en un documento con mucho texto irrelevante. Pasar ese documento completo a través de su solicitud puede generar llamadas de LLM más costosas y peores respuestas.
El recuperador de compresión contextual aborda el desafío de recuperar información relevante de un sistema de almacenamiento de documentos, donde los datos pertinentes pueden estar enterrados dentro de documentos que contienen una gran cantidad de texto. Al comprimir y filtrar los documentos recuperados según el contexto de consulta determinado, solo se devuelve la información más relevante.
Para utilizar el recuperador de compresión contextual, necesitará:
- Un perro perdiguero de base – Este es el recuperador inicial que recupera documentos del sistema de almacenamiento según la consulta.
- Un compresor de documentos – Este componente toma los documentos recuperados inicialmente y los acorta reduciendo el contenido de documentos individuales o eliminando documentos irrelevantes por completo, utilizando el contexto de consulta para determinar la relevancia.
Agregar compresión contextual con un extractor de cadena LLM
Primero, envuelva su base retriever con un ContextualCompressionRetriever. Agregarás un LLMChainExtractor, que iterará sobre los documentos devueltos inicialmente y extraerá de cada uno solo el contenido que sea relevante para la consulta.
Inicialice la cadena usando el ContextualCompressionRetriever con una LLMChainExtractor y pasar el mensaje a través del chain_type_kwargs argumento.
Hagamos una pregunta:
Filtrar documentos con un filtro de cadena LLM
El LLMChainFiltro es un compresor ligeramente más simple pero más robusto que utiliza una cadena LLM para decidir cuáles de los documentos recuperados inicialmente filtrar y cuáles devolver, sin manipular el contenido del documento:
Inicialice la cadena usando el ContextualCompressionRetriever con una LLMChainFilter y pasar el mensaje a través del chain_type_kwargs argumento.
Hagamos una pregunta:
Comparar resultados
La siguiente tabla compara los resultados de diferentes consultas según la técnica.
| Tecnologia | Consulta 1 | Consulta 2 | Comparación |
| ¿Cómo evolucionó AWS? | ¿Por qué Amazon tiene éxito? | ||
| Salida de cadena de recuperador regular | AWS (Amazon Web Services) evolucionó de una inversión inicialmente no rentable a un negocio con ingresos anuales de 85 mil millones de dólares con una fuerte rentabilidad, que ofrece una amplia gama de servicios y características, y se convierte en una parte importante de la cartera de Amazon. A pesar de enfrentar escepticismo y obstáculos a corto plazo, AWS continuó innovando, atrayendo nuevos clientes y migrando clientes activos, ofreciendo beneficios como agilidad, innovación, rentabilidad y seguridad. AWS también amplió sus inversiones a largo plazo, incluido el desarrollo de chips, para proporcionar nuevas capacidades y cambiar lo que es posible para sus clientes. | Amazon tiene éxito debido a su continua innovación y expansión a nuevas áreas, como servicios de infraestructura tecnológica, dispositivos de lectura digital, asistentes personales controlados por voz y nuevos modelos de negocio como el mercado de terceros. Su capacidad para escalar operaciones rápidamente, como se ve en la rápida expansión de sus redes de cumplimiento y transporte, también contribuye a su éxito. Además, el enfoque de Amazon en la optimización y el aumento de la eficiencia en sus procesos ha resultado en mejoras de productividad y reducciones de costos. El ejemplo de Amazon Business destaca la capacidad de la empresa para aprovechar sus fortalezas de comercio electrónico y logística en diferentes sectores. | Con base en las respuestas de la cadena de recuperación regular, notamos que, aunque proporciona respuestas largas, sufre un desbordamiento de contexto y no menciona ningún detalle significativo del corpus con respecto a la respuesta a la consulta proporcionada. La cadena de recuperación habitual no es capaz de capturar los matices con profundidad o visión contextual, lo que podría perder aspectos críticos del documento. |
| Salida del recuperador de documentos principal | AWS (Amazon Web Services) comenzó con un lanzamiento inicial con pocas funciones del servicio Elastic Compute Cloud (EC2) en 2006, proporcionando solo un tamaño de instancia, en un centro de datos, en una región del mundo, con instancias del sistema operativo Linux únicamente. y sin muchas características clave como monitoreo, equilibrio de carga, escalado automático o almacenamiento persistente. Sin embargo, el éxito de AWS les permitió iterar y agregar rápidamente las capacidades faltantes, expandiéndose eventualmente para ofrecer varios tipos, tamaños y optimizaciones de computación, almacenamiento y redes, además de desarrollar sus propios chips (Graviton) para impulsar aún más el precio y el rendimiento. . El proceso iterativo de innovación de AWS requirió inversiones significativas en recursos financieros y humanos durante 20 años, a menudo mucho antes de cuando pagaría, para satisfacer las necesidades de los clientes y mejorar las experiencias de los clientes, la lealtad y los retornos a largo plazo para los accionistas. | Amazon tiene éxito debido a su capacidad para innovar constantemente, adaptarse a las condiciones cambiantes del mercado y satisfacer las necesidades de los clientes en varios segmentos del mercado. Esto es evidente en el éxito de Amazon Business, que ha crecido hasta generar aproximadamente $35 mil millones en ventas brutas anualizadas al brindar selección, valor y conveniencia a los clientes comerciales. Las inversiones de Amazon en comercio electrónico y capacidades logísticas también han permitido la creación de servicios como Buy with Prime, que ayuda a los comerciantes con sitios web directos al consumidor a impulsar la conversión de visitas a compras. | El recuperador de documentos principal profundiza en los detalles específicos de la estrategia de crecimiento de AWS, incluido el proceso iterativo de agregar nuevas funciones basadas en los comentarios de los clientes y el recorrido detallado desde un lanzamiento inicial con pocas funciones hasta una posición dominante en el mercado, al tiempo que proporciona una respuesta rica en contexto. . Las respuestas cubren una amplia gama de aspectos, desde innovaciones técnicas y estrategias de mercado hasta eficiencia organizacional y enfoque en el cliente, brindando una visión holística de los factores que contribuyen al éxito junto con ejemplos. Esto se puede atribuir a las capacidades de búsqueda específicas pero de amplio alcance del recuperador de documentos principal. |
| Extractor de cadena LLM: salida de compresión contextual | AWS evolucionó comenzando como un pequeño proyecto dentro de Amazon, que requería una importante inversión de capital y enfrentaba escepticismo tanto dentro como fuera de la empresa. Sin embargo, AWS tenía una ventaja sobre los competidores potenciales y creía en el valor que podía aportar a los clientes y a Amazon. AWS asumió un compromiso a largo plazo para continuar invirtiendo, lo que dio como resultado más de 3,300 nuevas funciones y servicios lanzados en 2022. AWS ha transformado la forma en que los clientes administran su infraestructura tecnológica y se ha convertido en un negocio con una tasa de ingresos anuales de $85 mil millones con una sólida rentabilidad. AWS también ha mejorado continuamente sus ofertas, como mejorar EC2 con funciones y servicios adicionales después de su lanzamiento inicial. | Según el contexto proporcionado, el éxito de Amazon puede atribuirse a su expansión estratégica desde una plataforma de venta de libros a un mercado global con un vibrante ecosistema de vendedores externos, inversión temprana en AWS, innovación en la introducción de Kindle y Alexa, y un crecimiento sustancial. en ingresos anuales de 2019 a 2022. Este crecimiento condujo a la expansión de la huella del centro logístico, la creación de una red de transporte de última milla y la construcción de una nueva red de centros de clasificación, que se optimizaron para la productividad y la reducción de costos. | El extractor de cadenas LLM mantiene un equilibrio entre cubrir puntos clave de manera integral y evitar profundidades innecesarias. Se ajusta dinámicamente al contexto de la consulta, por lo que el resultado es directamente relevante y completo. |
| Filtro de cadena LLM: salida de compresión contextual | AWS (Amazon Web Services) evolucionó lanzando inicialmente pocas funciones, pero iterando rápidamente en función de los comentarios de los clientes para agregar las capacidades necesarias. Este enfoque permitió a AWS lanzar EC2 en 2006 con características limitadas y luego agregar continuamente nuevas funcionalidades, como tamaños de instancia adicionales, centros de datos, regiones, opciones de sistemas operativos, herramientas de monitoreo, equilibrio de carga, escalado automático y almacenamiento persistente. Con el tiempo, AWS pasó de ser un servicio con pocas funciones a convertirse en un negocio multimillonario al centrarse en las necesidades, la agilidad, la innovación, la rentabilidad y la seguridad de los clientes. AWS ahora tiene una tasa de ingresos anuales de $ 85 mil millones y ofrece más de 3,300 nuevas funciones y servicios cada año, atendiendo a una amplia gama de clientes, desde empresas emergentes hasta empresas multinacionales y organizaciones del sector público. | Amazon tiene éxito gracias a sus modelos de negocio innovadores, avances tecnológicos continuos y cambios organizativos estratégicos. La compañía ha revolucionado constantemente las industrias tradicionales al introducir nuevas ideas, como una plataforma de comercio electrónico para diversos productos y servicios, un mercado de terceros, servicios de infraestructura en la nube (AWS), el lector electrónico Kindle y el asistente personal de voz Alexa. . Además, Amazon ha realizado cambios estructurales para mejorar su eficiencia, como la reorganización de su red de cumplimiento en EE. UU. para reducir los costos y los tiempos de entrega, lo que contribuye aún más a su éxito. | Similar al extractor de cadena LLM, el filtro de cadena LLM garantiza que, aunque se cubran los puntos clave, el resultado sea eficiente para los clientes que buscan respuestas concisas y contextuales. |
Al comparar estas diferentes técnicas, podemos ver que en contextos como detallar la transición de AWS de un servicio simple a una entidad compleja multimillonaria, o explicar los éxitos estratégicos de Amazon, la cadena de recuperación regular carece de la precisión que ofrecen las técnicas más sofisticadas. lo que lleva a una información menos específica. Aunque son muy pocas las diferencias visibles entre las técnicas avanzadas analizadas, son mucho más informativas que las cadenas de perros recuperadores normales.
Para los clientes de industrias como la atención médica, las telecomunicaciones y los servicios financieros que buscan implementar RAG en sus aplicaciones, las limitaciones de la cadena de recuperación regular para brindar precisión, evitar la redundancia y comprimir información de manera efectiva la hacen menos adecuada para satisfacer estas necesidades en comparación. hasta el recuperador de documentos principal más avanzado y técnicas de compresión contextual. Estas técnicas pueden sintetizar grandes cantidades de información en los conocimientos concentrados e impactantes que necesita, al tiempo que ayudan a mejorar la relación precio-rendimiento.
Limpiar
Cuando haya terminado de ejecutar el cuaderno, elimine los recursos que creó para evitar la acumulación de cargos por los recursos en uso:
Conclusión
En esta publicación, presentamos una solución que le permite implementar el recuperador de documentos principal y técnicas de cadena de compresión contextual para mejorar la capacidad de los LLM para procesar y generar información. Probamos estas técnicas RAG avanzadas con los modelos Mixtral-8x7B Instruct y BGE Large En disponibles con SageMaker JumpStart. También exploramos el uso de almacenamiento persistente para incrustaciones y fragmentos de documentos y la integración con almacenes de datos empresariales.
Las técnicas que aplicamos no solo refinan la forma en que los modelos LLM acceden e incorporan conocimiento externo, sino que también mejoran significativamente la calidad, relevancia y eficiencia de sus resultados. Al combinar la recuperación de grandes corpus de texto con capacidades de generación de lenguaje, estas técnicas RAG avanzadas permiten a los LLM producir respuestas más objetivas, coherentes y apropiadas al contexto, mejorando su desempeño en diversas tareas de procesamiento del lenguaje natural.
SageMaker JumpStart está en el centro de esta solución. Con SageMaker JumpStart, obtiene acceso a una amplia variedad de modelos de código abierto y cerrado, lo que agiliza el proceso de introducción al aprendizaje automático y permite una experimentación e implementación rápidas. Para comenzar a implementar esta solución, navegue hasta el cuaderno en la Repositorio GitHub.
Acerca de los autores
 Niithiyn Vijeaswaran es arquitecto de soluciones en AWS. Su área de enfoque es la IA generativa y los aceleradores de IA de AWS. Tiene una Licenciatura en Informática y Bioinformática. Niithiyn trabaja en estrecha colaboración con el equipo de Generative AI GTM para ayudar a los clientes de AWS en múltiples frentes y acelerar su adopción de la IA generativa. Es un ávido fanático de los Dallas Mavericks y le gusta coleccionar zapatillas.
Niithiyn Vijeaswaran es arquitecto de soluciones en AWS. Su área de enfoque es la IA generativa y los aceleradores de IA de AWS. Tiene una Licenciatura en Informática y Bioinformática. Niithiyn trabaja en estrecha colaboración con el equipo de Generative AI GTM para ayudar a los clientes de AWS en múltiples frentes y acelerar su adopción de la IA generativa. Es un ávido fanático de los Dallas Mavericks y le gusta coleccionar zapatillas.
 Sebastián Bustillo es arquitecto de soluciones en AWS. Se centra en las tecnologías de IA/ML con una profunda pasión por la IA generativa y los aceleradores informáticos. En AWS, ayuda a los clientes a desbloquear valor empresarial a través de la IA generativa. Cuando no está en el trabajo, le gusta preparar una taza perfecta de café especial y explorar el mundo con su esposa.
Sebastián Bustillo es arquitecto de soluciones en AWS. Se centra en las tecnologías de IA/ML con una profunda pasión por la IA generativa y los aceleradores informáticos. En AWS, ayuda a los clientes a desbloquear valor empresarial a través de la IA generativa. Cuando no está en el trabajo, le gusta preparar una taza perfecta de café especial y explorar el mundo con su esposa.
 Armando diaz es arquitecto de soluciones en AWS. Se centra en IA generativa, IA/ML y análisis de datos. En AWS, Armando ayuda a los clientes a integrar capacidades de IA generativa de vanguardia en sus sistemas, fomentando la innovación y la ventaja competitiva. Cuando no está en el trabajo, le gusta pasar tiempo con su esposa y su familia, hacer senderismo y viajar por el mundo.
Armando diaz es arquitecto de soluciones en AWS. Se centra en IA generativa, IA/ML y análisis de datos. En AWS, Armando ayuda a los clientes a integrar capacidades de IA generativa de vanguardia en sus sistemas, fomentando la innovación y la ventaja competitiva. Cuando no está en el trabajo, le gusta pasar tiempo con su esposa y su familia, hacer senderismo y viajar por el mundo.
 Dr. Farooq Sabir es arquitecto sénior de soluciones especialista en inteligencia artificial y aprendizaje automático en AWS. Tiene un doctorado y una maestría en ingeniería eléctrica de la Universidad de Texas en Austin y una maestría en informática del Instituto de Tecnología de Georgia. Tiene más de 15 años de experiencia laboral y también le gusta enseñar y asesorar a estudiantes universitarios. En AWS, ayuda a los clientes a formular y resolver sus problemas comerciales en ciencia de datos, aprendizaje automático, visión artificial, inteligencia artificial, optimización numérica y dominios relacionados. Con sede en Dallas, Texas, a él y a su familia les encanta viajar y hacer viajes largos por carretera.
Dr. Farooq Sabir es arquitecto sénior de soluciones especialista en inteligencia artificial y aprendizaje automático en AWS. Tiene un doctorado y una maestría en ingeniería eléctrica de la Universidad de Texas en Austin y una maestría en informática del Instituto de Tecnología de Georgia. Tiene más de 15 años de experiencia laboral y también le gusta enseñar y asesorar a estudiantes universitarios. En AWS, ayuda a los clientes a formular y resolver sus problemas comerciales en ciencia de datos, aprendizaje automático, visión artificial, inteligencia artificial, optimización numérica y dominios relacionados. Con sede en Dallas, Texas, a él y a su familia les encanta viajar y hacer viajes largos por carretera.
 Marco Puño es un arquitecto de soluciones centrado en la estrategia de IA generativa, soluciones de IA aplicada y en la realización de investigaciones para ayudar a los clientes a hiperescalar en AWS. Marco es un asesor de nube nativo digital con experiencia en las industrias de tecnología financiera, atención médica y ciencias biológicas, software como servicio y, más recientemente, en telecomunicaciones. Es un tecnólogo calificado apasionado por el aprendizaje automático, la inteligencia artificial y las fusiones y adquisiciones. Marco reside en Seattle, WA y le gusta escribir, leer, hacer ejercicio y crear aplicaciones en su tiempo libre.
Marco Puño es un arquitecto de soluciones centrado en la estrategia de IA generativa, soluciones de IA aplicada y en la realización de investigaciones para ayudar a los clientes a hiperescalar en AWS. Marco es un asesor de nube nativo digital con experiencia en las industrias de tecnología financiera, atención médica y ciencias biológicas, software como servicio y, más recientemente, en telecomunicaciones. Es un tecnólogo calificado apasionado por el aprendizaje automático, la inteligencia artificial y las fusiones y adquisiciones. Marco reside en Seattle, WA y le gusta escribir, leer, hacer ejercicio y crear aplicaciones en su tiempo libre.
 AJ Dhimine es arquitecto de soluciones en AWS. Se especializa en inteligencia artificial generativa, computación sin servidor y análisis de datos. Es un miembro activo/mentor en la comunidad de campo técnico de aprendizaje automático y ha publicado varios artículos científicos sobre diversos temas de IA/ML. Trabaja con clientes, desde empresas emergentes hasta empresas, para desarrollar algunas soluciones de IA generativa. Le apasiona especialmente aprovechar los modelos de lenguajes grandes para análisis de datos avanzados y explorar aplicaciones prácticas que aborden los desafíos del mundo real. Fuera del trabajo, a AJ le gusta viajar y actualmente se encuentra en 53 países con el objetivo de visitar todos los países del mundo.
AJ Dhimine es arquitecto de soluciones en AWS. Se especializa en inteligencia artificial generativa, computación sin servidor y análisis de datos. Es un miembro activo/mentor en la comunidad de campo técnico de aprendizaje automático y ha publicado varios artículos científicos sobre diversos temas de IA/ML. Trabaja con clientes, desde empresas emergentes hasta empresas, para desarrollar algunas soluciones de IA generativa. Le apasiona especialmente aprovechar los modelos de lenguajes grandes para análisis de datos avanzados y explorar aplicaciones prácticas que aborden los desafíos del mundo real. Fuera del trabajo, a AJ le gusta viajar y actualmente se encuentra en 53 países con el objetivo de visitar todos los países del mundo.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/advanced-rag-patterns-on-amazon-sagemaker/

