Introducción
Etiquetar la imagen o anotar la foto en el panorama general de la visión por computadora fue un desafío. Nuestra exploración profundiza en el trabajo en equipo de LabelImg y Detectron, un poderoso dúo que combina la anotación precisa con la construcción eficiente de modelos. LabelImg, que es fácil de usar y preciso, lidera la anotación cuidadosa, sentando una base sólida para una detección clara de objetos.
A medida que exploramos LabelImg y mejoramos en el dibujo de cuadros delimitadores, pasamos sin problemas a Detectron. Este sólido marco organiza nuestros datos marcados, lo que lo hace útil para entrenar modelos avanzados. LabelImg y Detectron juntos hacen que la detección de objetos sea fácil para todos, ya sea principiante o experto. Vamos, donde cada imagen marcada nos ayuda a desbloquear todo el poder de la información visual.
OBJETIVOS DE APRENDIZAJE
- Primeros pasos con LabelImg.
- Configuración del entorno e instalación de LabelImg.
- Comprensión de LabelImg y su funcionalidad.
- Conversión de datos VOC o Pascal al formato COCO para la detección de objetos.
Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Tabla de contenidos.
Diagrama de flujo

Configuración de su entorno
1. Cree un entorno virtual:
conda create -p ./venv python=3.8 -yEste comando crea un entorno virtual llamado "venv" usando Python versión 3.8.
2. Activar el Entorno Virtual:
conda activate venvActive el entorno virtual para aislar la instalación de LabelImg.
Instalación y uso de LabelImg
1. Instale LabelImg:
pip install labelImgInstale LabelImg dentro del entorno virtual activado.
2. Inicie LabelImg:
labelImg
Solución de problemas: si encuentra errores al ejecutar el script
Si encuentra errores al ejecutar el script, he preparado un archivo zip que contiene el entorno virtual (venv) para su comodidad.
1. Descargue el archivo Zip:
- Descargue el archivo venv.zip desde Enlace
2. Cree una carpeta LabelImg:
- Cree una nueva carpeta llamada LabelImg en su máquina local.
3. Extraiga la carpeta venv:
- Extraiga el contenido del archivo venv.zip en la carpeta LabelImg.
4. Activar el Entorno Virtual:
- Abra su símbolo del sistema o terminal.
- Navegue hasta la carpeta LabelImg.
- Ejecute el siguiente comando para activar el entorno virtual:
conda activate ./venvEste proceso garantiza que tenga un entorno virtual preconfigurado listo para usar con LabelImg. El archivo zip proporcionado encapsula las dependencias necesarias, lo que permite una experiencia más fluida sin preocuparse por una posible instalación.
Ahora, continúe con los pasos anteriores para instalar y utilizar LabelImg dentro de este entorno virtual activado.
Flujo de trabajo de anotación con LabelImg
1. Anotar imágenes en formato PascalVOC:
- Compile y ejecute LabelImg.
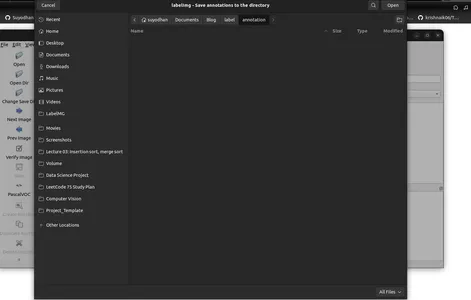
- Haga clic en 'Cambiar carpeta de anotaciones guardadas predeterminada' en Menú/Archivo.
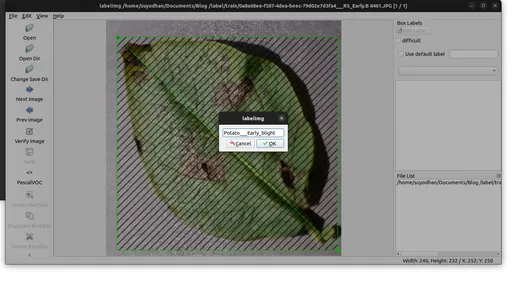
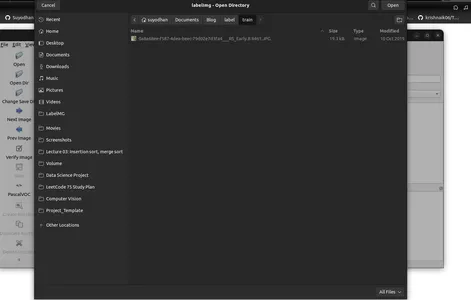
- Haga clic en 'Abrir directorio' para seleccionar el directorio de imágenes.
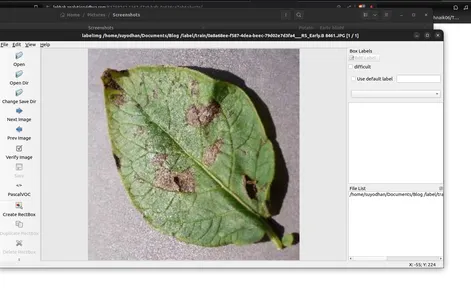
- Utilice 'Crear RectBox' para anotar objetos en la imagen.
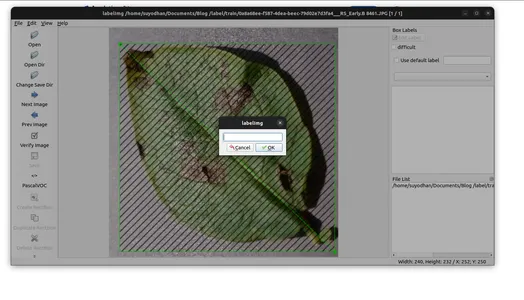
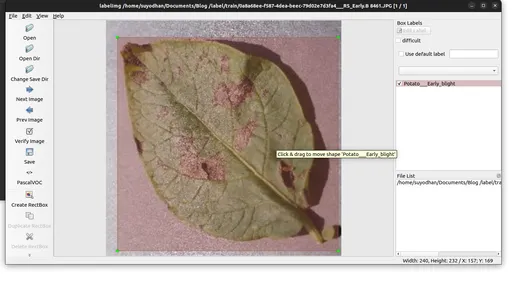
- Guarde las anotaciones en la carpeta especificada.
dentro del .xml
<annotation>
<folder>train</folder>
<filename>0a8a68ee-f587-4dea-beec-79d02e7d3fa4___RS_Early.B 8461.JPG</filename>
<path>/home/suyodhan/Documents/Blog /label
/train/0a8a68ee-f587-4dea-beec-79d02e7d3fa4___RS_Early.B 8461.JPG</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>256</width>
<height>256</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>Potato___Early_blight</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>12</xmin>
<ymin>18</ymin>
<xmax>252</xmax>
<ymax>250</ymax>
</bndbox>
</object>
</annotation>Esta estructura XML sigue el formato de anotación Pascal VOC, comúnmente utilizado para conjuntos de datos de detección de objetos. Este formato proporciona una representación estandarizada de datos anotados para entrenar modelos de visión por computadora. Si tiene imágenes adicionales con anotaciones, puede continuar generando archivos XML similares para cada objeto anotado en las imágenes respectivas.
Conversión de anotaciones Pascal VOC al formato COCO: un script en Python
Los modelos de detección de objetos a menudo requieren anotaciones en formatos específicos para entrenarse y evaluarse de manera efectiva. Si bien Pascal VOC es un formato ampliamente utilizado, marcos específicos como Detectron prefieren las anotaciones COCO. Para cerrar esta brecha, presentamos un versátil Python script, voc2coco.py, diseñado para convertir anotaciones Pascal VOC al formato COCO sin problemas.
#!/usr/bin/python
# pip install lxml
import sys
import os
import json
import xml.etree.ElementTree as ET
import glob
START_BOUNDING_BOX_ID = 1
PRE_DEFINE_CATEGORIES = None
# If necessary, pre-define category and its id
# PRE_DEFINE_CATEGORIES = {"aeroplane": 1, "bicycle": 2, "bird": 3, "boat": 4,
# "bottle":5, "bus": 6, "car": 7, "cat": 8, "chair": 9,
# "cow": 10, "diningtable": 11, "dog": 12, "horse": 13,
# "motorbike": 14, "person": 15, "pottedplant": 16,
# "sheep": 17, "sofa": 18, "train": 19, "tvmonitor": 20}
def get(root, name):
vars = root.findall(name)
return vars
def get_and_check(root, name, length):
vars = root.findall(name)
if len(vars) == 0:
raise ValueError("Can not find %s in %s." % (name, root.tag))
if length > 0 and len(vars) != length:
raise ValueError(
"The size of %s is supposed to be %d, but is %d."
% (name, length, len(vars))
)
if length == 1:
vars = vars[0]
return vars
def get_filename_as_int(filename):
try:
filename = filename.replace("", "/")
filename = os.path.splitext(os.path.basename(filename))[0]
return str(filename)
except:
raise ValueError("Filename %s is supposed to be an integer." % (filename))
def get_categories(xml_files):
"""Generate category name to id mapping from a list of xml files.
Arguments:
xml_files {list} -- A list of xml file paths.
Returns:
dict -- category name to id mapping.
"""
classes_names = []
for xml_file in xml_files:
tree = ET.parse(xml_file)
root = tree.getroot()
for member in root.findall("object"):
classes_names.append(member[0].text)
classes_names = list(set(classes_names))
classes_names.sort()
return {name: i for i, name in enumerate(classes_names)}
def convert(xml_files, json_file):
json_dict = {"images": [], "type": "instances", "annotations": [], "categories": []}
if PRE_DEFINE_CATEGORIES is not None:
categories = PRE_DEFINE_CATEGORIES
else:
categories = get_categories(xml_files)
bnd_id = START_BOUNDING_BOX_ID
for xml_file in xml_files:
tree = ET.parse(xml_file)
root = tree.getroot()
path = get(root, "path")
if len(path) == 1:
filename = os.path.basename(path[0].text)
elif len(path) == 0:
filename = get_and_check(root, "filename", 1).text
else:
raise ValueError("%d paths found in %s" % (len(path), xml_file))
## The filename must be a number
image_id = get_filename_as_int(filename)
size = get_and_check(root, "size", 1)
width = int(get_and_check(size, "width", 1).text)
height = int(get_and_check(size, "height", 1).text)
image = {
"file_name": filename,
"height": height,
"width": width,
"id": image_id,
}
json_dict["images"].append(image)
## Currently we do not support segmentation.
# segmented = get_and_check(root, 'segmented', 1).text
# assert segmented == '0'
for obj in get(root, "object"):
category = get_and_check(obj, "name", 1).text
if category not in categories:
new_id = len(categories)
categories[category] = new_id
category_id = categories[category]
bndbox = get_and_check(obj, "bndbox", 1)
xmin = int(get_and_check(bndbox, "xmin", 1).text) - 1
ymin = int(get_and_check(bndbox, "ymin", 1).text) - 1
xmax = int(get_and_check(bndbox, "xmax", 1).text)
ymax = int(get_and_check(bndbox, "ymax", 1).text)
assert xmax > xmin
assert ymax > ymin
o_width = abs(xmax - xmin)
o_height = abs(ymax - ymin)
ann = {
"area": o_width * o_height,
"iscrowd": 0,
"image_id": image_id,
"bbox": [xmin, ymin, o_width, o_height],
"category_id": category_id,
"id": bnd_id,
"ignore": 0,
"segmentation": [],
}
json_dict["annotations"].append(ann)
bnd_id = bnd_id + 1
for cate, cid in categories.items():
cat = {"supercategory": "none", "id": cid, "name": cate}
json_dict["categories"].append(cat)
#os.makedirs(os.path.dirname(json_file), exist_ok=True)
json_fp = open(json_file, "w")
json_str = json.dumps(json_dict)
json_fp.write(json_str)
json_fp.close()
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser(
description="Convert Pascal VOC annotation to COCO format."
)
parser.add_argument("xml_dir", help="Directory path to xml files.", type=str)
parser.add_argument("json_file", help="Output COCO format json file.", type=str)
args = parser.parse_args()
xml_files = glob.glob(os.path.join(args.xml_dir, "*.xml"))
# If you want to do train/test split, you can pass a subset of xml files to convert function.
print("Number of xml files: {}".format(len(xml_files)))
convert(xml_files, args.json_file)
print("Success: {}".format(args.json_file))Descripción general del guión
El script voc2coco.py simplifica el proceso de conversión aprovechando la biblioteca lxml. Antes de profundizar en el uso, exploremos sus componentes clave:
1. Dependencias:
- Asegúrese de que la biblioteca lxml esté instalada usando pip install lxml.
2. Configuración:
- Opcionalmente, predefina categorías utilizando la variable PRE_DEFINE_CATEGORIES. Descomente y modifique esta sección según su conjunto de datos.
3. FunciónObtener
- get, get_and_check, get_filename_as_int: funciones auxiliares para el análisis XML.
- get_categories: genera un nombre de categoría para asignar ID a partir de una lista de archivos XML.
- convertir: la función de conversión principal procesa archivos XML y genera formato COCO JSON.
Instrucciones de uso
Ejecutar el script es sencillo, ejecútelo desde la línea de comandos, proporcionando la ruta a sus archivos XML Pascal VOC y especificando la ruta de salida deseada para el archivo JSON en formato COCO. He aquí un ejemplo:
python voc2coco.py /path/to/xml/files /path/to/output/output.jsonSalida:
El script genera un archivo JSON en formato COCO bien estructurado que contiene información esencial sobre imágenes, anotaciones y categorías.
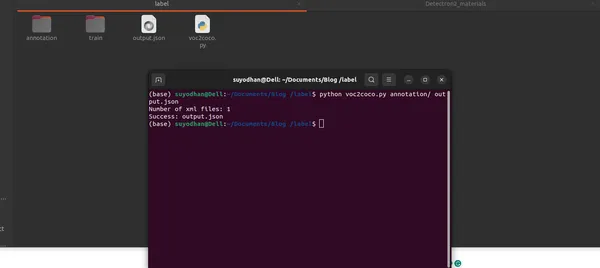
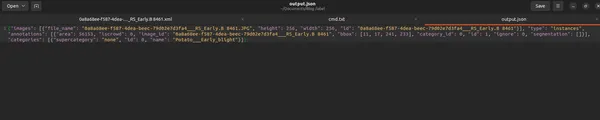
Conclusión
En conclusión, al concluir nuestro viaje a través de la detección de objetos con LabelImg y Detectron, es crucial reconocer la variedad de herramientas de anotación dirigidas a entusiastas y profesionales. LabelImg, como joya de código abierto, ofrece versatilidad y accesibilidad, lo que la convierte en la mejor opción.
Más allá de las herramientas gratuitas, soluciones pagas como VGG Image Annotator (VIA), RectLabel y Labelbox intervienen para tareas complejas y proyectos grandes. Estas plataformas ofrecen funciones avanzadas y escalabilidad, aunque requieren una inversión financiera, lo que garantiza la eficiencia en iniciativas de alto riesgo.
Nuestra exploración enfatiza la elección de la herramienta de anotación adecuada según las características específicas del proyecto, el presupuesto y el nivel de sofisticación. Ya sea apegándose a la apertura de LabelImg o invirtiendo en herramientas pagas, la clave es alinearse con la escala y los objetivos de su proyecto. En el campo en evolución de la visión por computadora, las herramientas de anotación continúan diversificándose, brindando opciones para proyectos de todos los tamaños y complejidades.
Puntos clave
- La interfaz intuitiva y las funciones avanzadas de LabelImg la convierten en una herramienta versátil de código abierto para anotaciones precisas de imágenes, ideal para quienes se inician en la detección de objetos.
- Las herramientas pagas como VIA, RectLabel y Labelbox se adaptan a tareas de anotación complejas y proyectos a gran escala, ofreciendo funciones avanzadas y escalabilidad.
- La conclusión fundamental es elegir la herramienta de anotación adecuada en función de las necesidades del proyecto, el presupuesto y la sofisticación deseada, garantizando la eficiencia y el éxito en los esfuerzos de detección de objetos.
Recursos para mayor aprendizaje:
1. Documentación de LabelImg:
- Explore la documentación oficial de LabelImg para obtener información detallada sobre sus características y funcionalidades.
- Documentación de LabelImg
2. Documentación del marco de Detectron:
- Profundice en la documentación de Detectron, el potente marco de detección de objetos, para comprender sus capacidades y uso.
- Documentación de Detectrón
3. Guía del anotador de imágenes VGG (VIA):
- Si está interesado en explorar VIA, VGG Image Annotator, consulte la guía completa para obtener instrucciones detalladas.
- Guía del usuario de VÍA
4.Documentación de RectLabel:
- Obtenga más información sobre RectLabel, una herramienta de anotación paga, consultando su documentación oficial para obtener orientación sobre su uso y funciones.
- Documentación de RectLabel
5.Centro de aprendizaje de Labelbox:
- Descubra recursos educativos y tutoriales en el Centro de aprendizaje de Labelbox para mejorar su comprensión de esta plataforma de anotaciones.
- Centro de aprendizaje Labelbox
Preguntas frecuentes
R: LabelImg es una herramienta de anotación de imágenes de código abierto para tareas de detección de objetos. Su interfaz fácil de usar y su versatilidad lo distinguen. A diferencia de algunas herramientas, LabelImg permite anotaciones precisas en cuadros delimitadores, lo que la convierte en la opción preferida para quienes son nuevos en la detección de objetos.
R: Sí, varias herramientas de anotación pagas, como VGG Image Annotator (VIA), RectLabel y Labelbox, ofrecen funciones avanzadas y escalabilidad. Si bien las herramientas gratuitas como LabelImg son excelentes para tareas básicas, las soluciones pagas están diseñadas para proyectos más complejos y brindan funciones de colaboración y mayor eficiencia.
R: Convertir anotaciones al formato Pascal VOC es crucial para la compatibilidad con marcos como Detectron. Garantiza un etiquetado de clases consistente y una integración perfecta en el proceso de capacitación, lo que facilita la creación de modelos precisos de detección de objetos.
R: Detectron es un marco robusto de detección de objetos que agiliza el proceso de entrenamiento del modelo. Desempeña un papel crucial en el manejo de datos anotados, preparándolos para el entrenamiento y optimizando la eficiencia general de los modelos de detección de objetos.
R: Si bien las herramientas de anotación pagas suelen estar asociadas con tareas de nivel empresarial, también pueden beneficiar a proyectos de pequeña escala. La decisión depende de los requisitos específicos, las restricciones presupuestarias y el nivel deseado de sofisticación para las tareas de anotación.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
Relacionado:
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2023/11/detectron-integration-with-labelimg/

