Introducción
En visión por computadora, existen diferentes técnicas para la detección de objetos vivos, incluida Faster R-CNN, SSDy YOLO. Cada técnica tiene sus limitaciones y ventajas. Si bien Faster R-CNN puede sobresalir en precisión, es posible que no funcione tan bien en escenarios en tiempo real, lo que provoca un cambio hacia la Algoritmo YOLO.
La detección de objetos es fundamental en la visión por computadora, ya que permite a las máquinas identificar y ubicar objetos dentro de un marco o pantalla. A lo largo de los años, se han desarrollado varios algoritmos de detección de objetos, siendo YOLO uno de los más exitosos. Recientemente, se introdujo YOLOv8, lo que mejora aún más las capacidades del algoritmo.
En esta guía completa, exploramos tres algoritmos de detección de objetos destacados: Faster R-CNN, SSD (Single Shot MultiBox Detector) y YOLOv8. Discutimos los aspectos prácticos de la implementación de estos algoritmos, incluida la configuración de un entorno virtual y el desarrollo de una aplicación Streamlit.
Objetivo de aprendizaje
- Comprenda Faster R-CNN, SSD y YOLO y analice las diferencias entre ellos.
- Obtenga experiencia práctica en la implementación de sistemas de detección de objetos vivos utilizando OpenCV, Supervisión y YOLOv8.
- Comprender el modelo de segmentación de imágenes mediante la anotación Roboflow.
- Cree una aplicación Streamlit para una interfaz de usuario sencilla.
¡Exploremos cómo segmentar imágenes con YOLOv8!
Tabla de contenidos.
Este artículo fue publicado como parte del Blogatón de ciencia de datos.
R-CNN más rápido
Faster R-CNN (red neuronal convolucional basada en regiones más rápidas) es un algoritmo de detección de objetos basado en aprendizaje profundo. Se evalúa utilizando los marcos R-CNN y Fast R-CNN y puede considerarse una extensión de Fast R-CNN.
Este algoritmo introduce la Red de Propuestas de Región (RPN) para generar propuestas de región, reemplazando la búsqueda selectiva utilizada en R-CNN. La RPN comparte capas convolucionales con la red de detección, lo que permite un entrenamiento eficiente de un extremo a otro.
Las propuestas de región generadas luego se introducen en una red Fast R-CNN para refinar el cuadro delimitador y clasificar objetos.
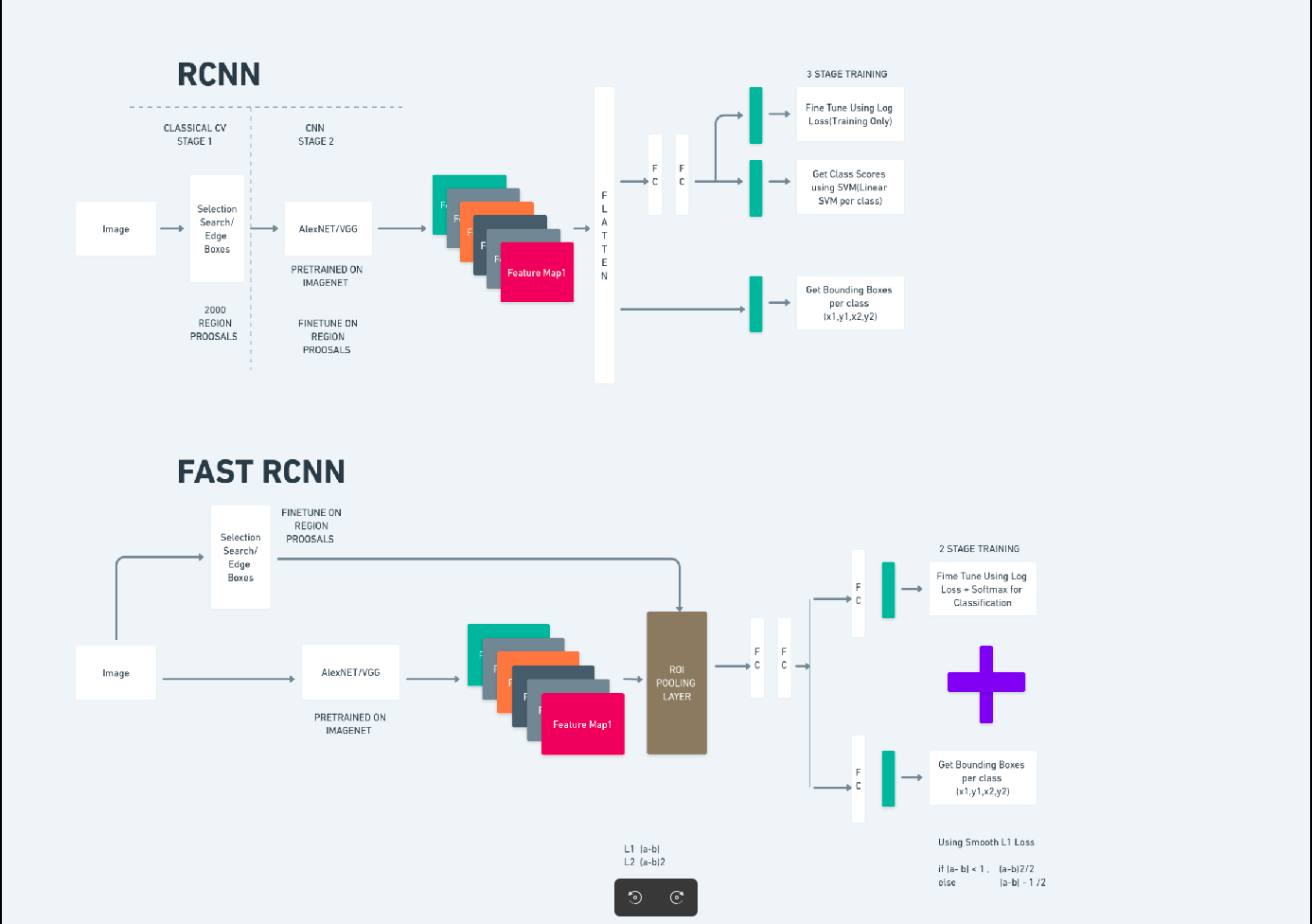
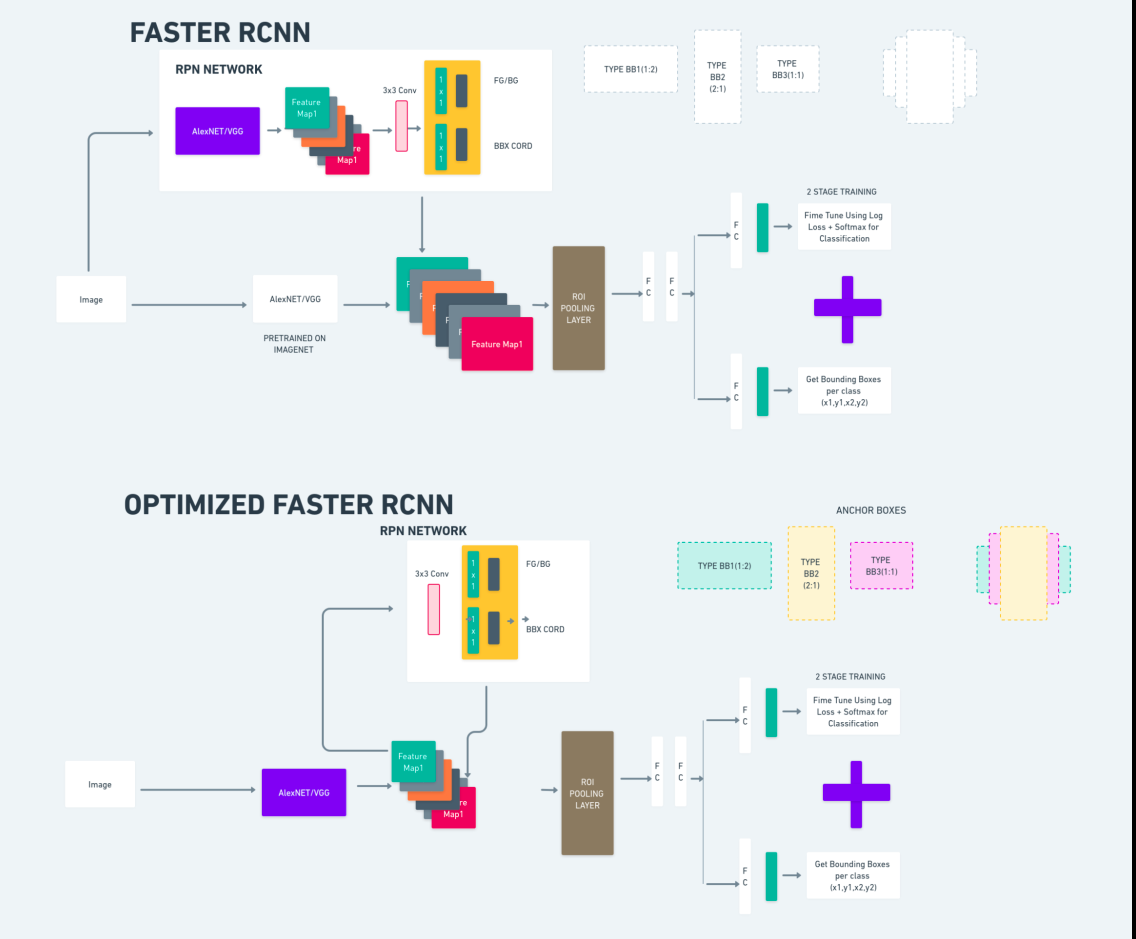
El diagrama anterior ilustra la familia Faster R-CNN de manera integral y es fácil de entender para evaluar cada algoritmo.
Detector MultiBox de disparo único (SSD)
El Detector MultiBox de disparo único (SSD) es popular en la detección de objetos y se utiliza principalmente en tareas de visión por computadora. En el método anterior, Faster R-CNN, seguimos dos pasos: el primer paso implicó la parte de detección y el segundo implicó la regresión. Sin embargo, con SSD, solo realizamos un paso de detección. SSD se introdujo en 2016 para abordar la necesidad de un modelo de detección de objetos rápido y preciso.

SSD tiene varias ventajas sobre métodos anteriores de detección de objetos como Faster R-CNN:
- Eficiencia: SSD es un detector de una sola etapa, lo que significa que predice directamente cuadros delimitadores y puntuaciones de clase sin requerir un paso de generación de propuestas por separado. Esto lo hace más rápido en comparación con detectores de dos etapas como Faster R-CNN.
- Capacitación de un extremo a otro: SSD se puede entrenar de un extremo a otro, optimizando tanto la red base como el cabezal de detección de forma conjunta, lo que simplifica el proceso de capacitación.
- Fusión de características multiescala: SSD opera en mapas de características en múltiples escalas, lo que le permite detectar objetos de diferentes tamaños de manera más efectiva.
SSD logra un buen equilibrio entre velocidad y precisión, lo que lo hace adecuado para aplicaciones en tiempo real donde tanto el rendimiento como la eficiencia son críticos.
Sólo miras una vez (YOLOv8)
En 2015, You Only Look Once (YOLO) se introdujo como un algoritmo de detección de objetos en un artículo de investigación de Joseph Redmon, Santosh Divvala, Ross Girshick y Ali Farhadi. YOLO es un algoritmo de disparo único que clasifica directamente un objeto en un solo paso haciendo que solo una red neuronal prediga cuadros delimitadores y probabilidades de clase utilizando una imagen completa como entrada.
Ahora, entendamos YOLOv8 como avances de última generación en detección de objetos en tiempo real con precisión y velocidad mejoradas. YOLOv8 le permite aprovechar modelos previamente entrenados, que ya están entrenados en un amplio conjunto de datos como COCO (Objetos comunes en contexto). La segmentación de imágenes proporciona información a nivel de píxeles sobre cada objeto, lo que permite un análisis y una comprensión más detallados del contenido de la imagen.
Si bien la segmentación de imágenes puede resultar costosa desde el punto de vista computacional, YOLOv8 integra este método en su arquitectura de red neuronal, lo que permite una segmentación de objetos eficiente y precisa.
Principio de funcionamiento de YOLOv8
YOLOv8 funciona dividiendo primero la imagen de entrada en celdas de la cuadrícula. Usando estas celdas de la cuadrícula, YOLOv8 predice los cuadros delimitadores (bbox) con probabilidades de clase.
Posteriormente, YOLOv8 emplea el algoritmo NMS para reducir la superposición. Por ejemplo, si hay varios automóviles presentes en la imagen, lo que da como resultado cuadros delimitadores superpuestos, el algoritmo NMS ayuda a reducir esta superposición.
Diferencia entre variantes de Yolo V8: YOLOv8 está disponible en tres variantes: YOLOv8, YOLOv8-L y YOLOv8-X. La principal diferencia entre las variantes es el tamaño de la red troncal. YOLOv8 tiene la red troncal más pequeña, mientras que YOLOv8-X tiene la red troncal más grande.
Diferencias entre Faster R-CNN, SSD y YOLO
| Aspecto | R-CNN más rápido | SSD | YOLO |
|---|---|---|---|
| Arquitectura | Detector de dos etapas con RPN y Fast R-CNN | Detector de una sola etapa | Detector de una sola etapa |
| Propuestas de región | Sí | No | No |
| Velocidad de detección | Más lento en comparación con SSD y YOLO | Más rápido en comparación con Faster R-CNN, más lento que YOLO | Muy rápido |
| Exactitud | Generalmente mayor precisión | Precisión y velocidad equilibradas | Precisión decente, especialmente para aplicaciones en tiempo real |
| Flexibilidad | Flexible, puede manejar varios tamaños de objetos y relaciones de aspecto | Puede manejar múltiples escalas de objetos. | Puede tener dificultades con la localización precisa de objetos pequeños. |
| Detección unificada | No | No | Sí |
| Compensación entre velocidad y precisión | Generalmente sacrifica la velocidad por la precisión. | Equilibra velocidad y precisión | Prioriza la velocidad manteniendo una precisión decente |
¿Qué es la segmentación?
Como sabemos, la segmentación significa que dividimos la imagen grande en grupos más pequeños en función de ciertas características. Entendamos la segmentación de imágenes, que es la técnica de visión por computadora que se utiliza para dividir una imagen en diferentes segmentos o regiones. Como las imágenes están hechas de píxeles y en la segmentación de imágenes, los píxeles se agrupan según la similitud en color, intensidad, textura u otras propiedades visuales.
Por ejemplo, si una imagen contiene árboles, automóviles o personas, la segmentación de la imagen dividirá la imagen en diferentes clases que representan objetos significativos o partes de la imagen. La segmentación de imágenes se usa ampliamente en diferentes campos, como imágenes médicas, análisis de imágenes satelitales, reconocimiento de objetos en visión por computadora y más.

En la parte de segmentación, inicialmente creamos el primer modelo de segmentación YOLOv8 usando Robflow. Luego, importamos el modelo de segmentación para realizar la tarea de segmentación. Surge la pregunta: ¿por qué creamos el modelo de segmentación cuando la tarea podría completarse únicamente con un algoritmo de detección?
La segmentación nos permite obtener la imagen corporal completa de una clase. Mientras que los algoritmos de detección se centran en detectar la presencia de objetos, la segmentación proporciona una comprensión más precisa al delinear los límites exactos de los objetos. Esto conduce a una localización y comprensión más precisa de los objetos presentes en la imagen.
Sin embargo, la segmentación suele implicar una mayor complejidad temporal en comparación con los algoritmos de detección porque requiere pasos adicionales, como separar anotaciones y crear el modelo. A pesar de este inconveniente, la mayor precisión que ofrece la segmentación puede superar el costo computacional en tareas donde la delimitación precisa de los objetos es crucial.
Detección en vivo paso a paso y segmentación de imágenes con YOLOv8
En este concepto, exploramos los pasos para crear un entorno virtual usando conda, activando venv e instalando los paquetes de requisitos usando pip. Primero creamos el script Python normal y luego creamos la aplicación Streamlit.
Paso 1: cree un entorno virtual usando Conda
conda create -p ./venv python=3.8 -yPaso 2: active el entorno virtual
conda activate ./venv
Paso 3: crear requisitos.txt
Abra la terminal y pegue el siguiente script:
touch requirements.txtPaso 4: use el comando Nano y edite el archivo de requisitos.txt
Después de crear el archivo require.txt, escriba el siguiente comando para editarlo.
nano requirements.txtDespués de ejecutar el script anterior, podrá ver esta interfaz de usuario.
Escriba sus paquetes requeridos.
ultralytics==8.0.32
supervision==0.2.1
streamlitLuego presione el “ctrl+o”(este comando guarda la parte de edición) y luego presione el botón "Entrar"
Después de presionar el botón “Ctrl+x”. puedes salir del archivo. y yendo al camino principal.
Paso 5: instalar el archivo requisitos.txt
pip install -r requirements.txtPaso 6: cree el script de Python
En la terminal escriba el siguiente script o podemos decir comando.
touch main.pyDespués de crear main.py, abra el código vs y use el comando escribir en la terminal,
code Paso 7: escribir el script de Python
import cv2
from ultralytics import YOLO
import supervision as sv
# Define the frame width and height for video capture
frame_width = 1280
frame_height = 720
def main():
# Initialize video capture from default camera
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, frame_width)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, frame_height)
# Load YOLOv8 model
model = YOLO("yolov8l.pt")
# Initialize box annotator for visualization
box_annotator = sv.BoxAnnotator(
thickness=2,
text_thickness=2,
text_scale=1
)
# Main loop for video processing
while True:
# Read frame from video capture
ret, frame = cap.read()
# Perform object detection using YOLOv8
result = model(frame, agnostic_nms=True)[0]
detections = sv.Detections.from_yolov8(result)
# Prepare labels for detected objects
labels = [
f"{model.model.names[class_id]} {confidence:0.2f}"
for _, confidence, class_id, _
in detections
]
# Annotate frame with bounding boxes and labels
frame = box_annotator.annotate(
scene=frame,
detections=detections,
labels=labels
)
# Display annotated frame
cv2.imshow("yolov8", frame)
# Check for quit key
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Release video capture
cap.release()
cv2.destroyAllWindows()
if __name__ == "__main__":
main()
Después de ejecutar este comando, podrás ver que tu cámara está abierta y detecta una parte de ti. como género y partes de fondo.
Paso 7: cree una aplicación optimizada
import cv2
import streamlit as st
from ultralytics import YOLO
import supervision as sv
# Define the frame width and height for video capture
frame_width = 1280
frame_height = 720
def main():
# Set page title and header
st.title("Live Object Detection with YOLOv8")
# Button to start the camera
start_camera = st.button("Start Camera")
if start_camera:
# Initialize video capture from default camera
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, frame_width)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, frame_height)
# Load YOLOv8 model
model = YOLO("yolov8l.pt")
# Initialize box annotator for visualization
box_annotator = sv.BoxAnnotator(
thickness=2,
text_thickness=2,
text_scale=1
)
# Main loop for video processing
while True:
# Read frame from video capture
ret, frame = cap.read()
# Perform object detection using YOLOv8
result = model(frame, agnostic_nms=True)[0]
detections = sv.Detections.from_yolov8(result)
# Prepare labels for detected objects
labels = [
f"{model.model.names[class_id]} {confidence:0.2f}"
for _, confidence, class_id, _
in detections
]
# Annotate frame with bounding boxes and labels
frame = box_annotator.annotate(
scene=frame,
detections=detections,
labels=labels
)
# Display annotated frame
st.image(frame, channels="BGR", use_column_width=True)
# Check for quit key
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Release video capture
cap.release()
if __name__ == "__main__":
main()
En este script, estamos creando la aplicación Streamlit y creando el botón para que después de presionar el botón la cámara de su dispositivo esté abierta y detecte la parte en el marco.
Ejecute este script usando este comando.
streamlit run app.py
# first create the app.py then paste the above code and run this script.Después de ejecutar el comando anterior, supongamos que recibió un error de comunicación como,
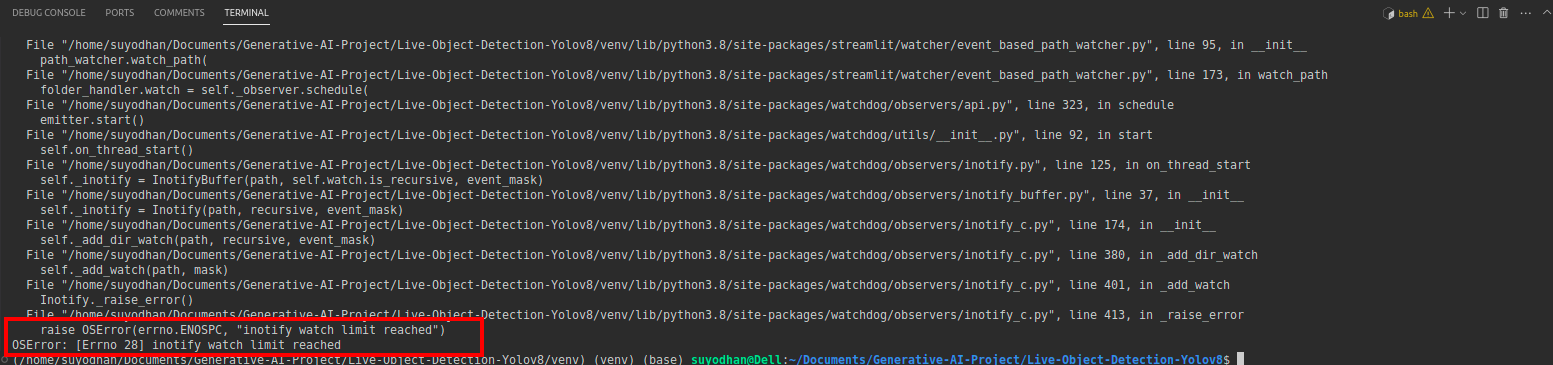
luego presione este comando,
sudo sysctl fs.inotify.max_user_watches=524288Después de presionar el comando mediante el cual desea escribir su contraseña porque estamos usando el comando sudo sudo es dios :)
Ejecute el script nuevamente. y puedes ver la aplicación streamlit.
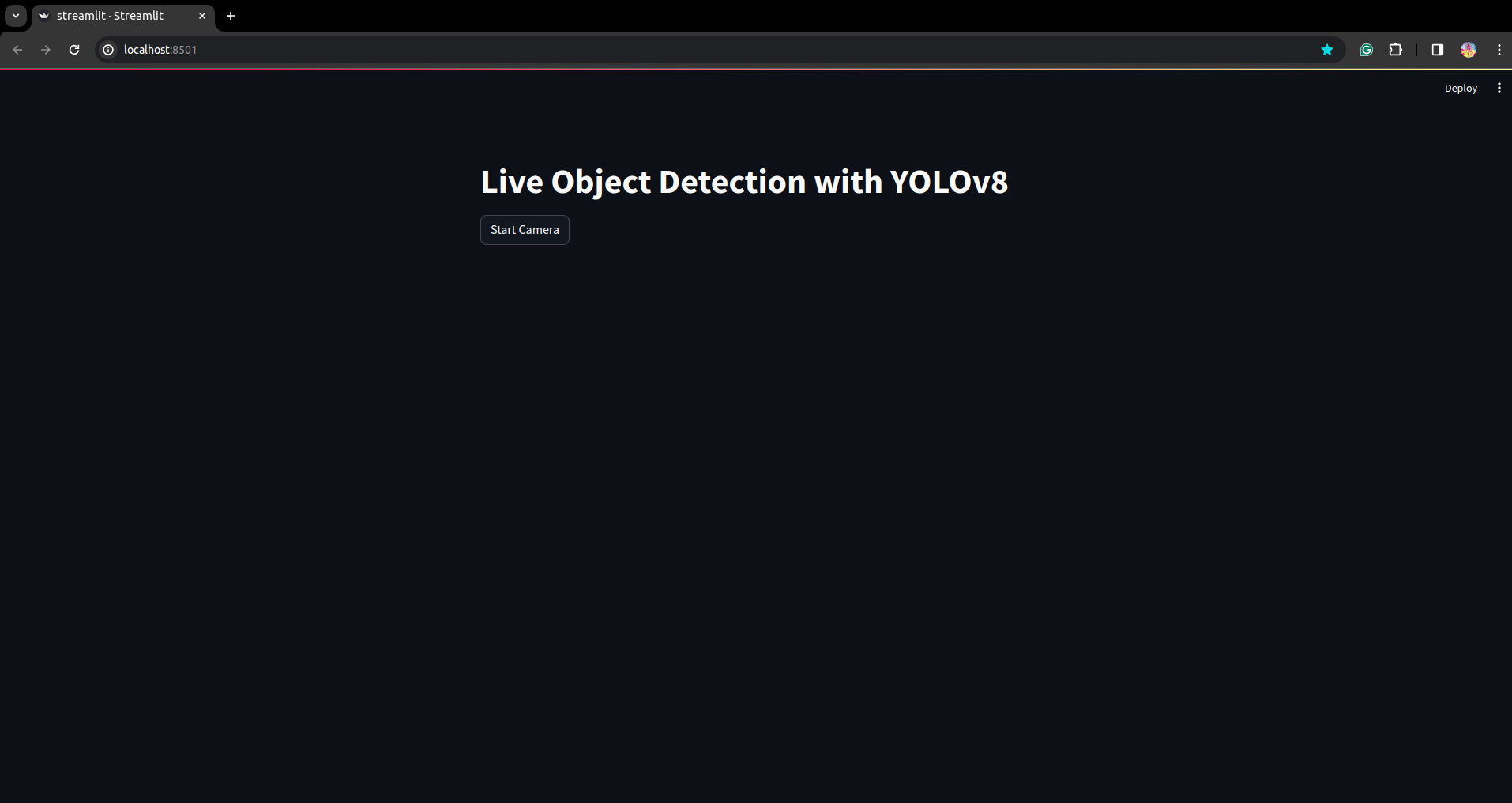
Aquí podemos crear una aplicación de detección en vivo exitosa. En la siguiente parte veremos la parte de segmentación.
Pasos para la anotación
Paso 1: Configuración de Roboflow
Después de firmar el "Crear Proyecto”. aquí puede crear el proyecto y el grupo de anotaciones.

Paso 2: Descarga del conjunto de datos
Aquí consideramos el ejemplo simple, pero desea usarlo en el planteamiento de su problema, así que estoy usando aquí el conjunto de datos Duck.
ve a esto liga y descargue el conjunto de datos del pato.

Extraiga la carpeta allí podrá ver las tres carpetas: entrenar, probar y val.
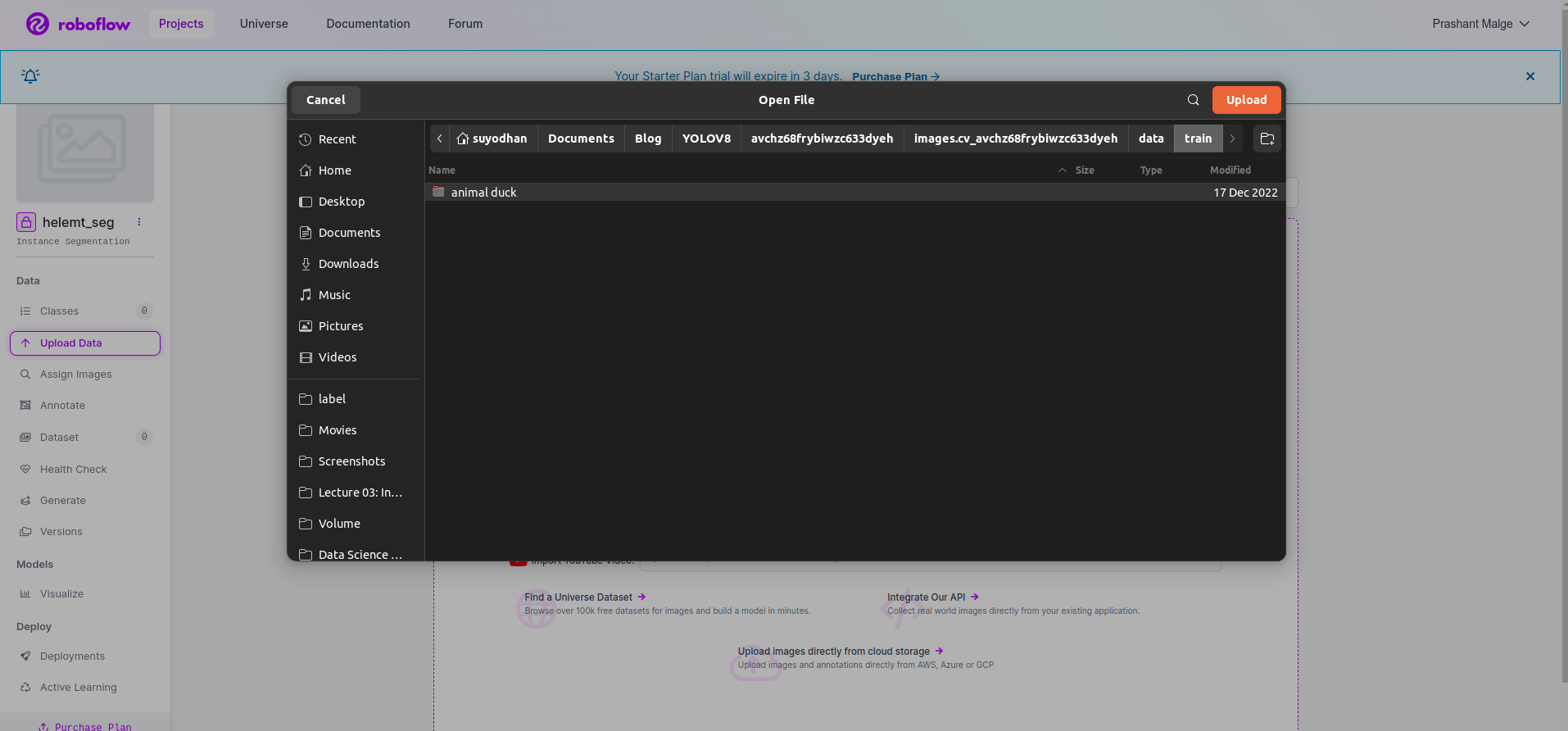
Paso 3: cargar el conjunto de datos en roboflow
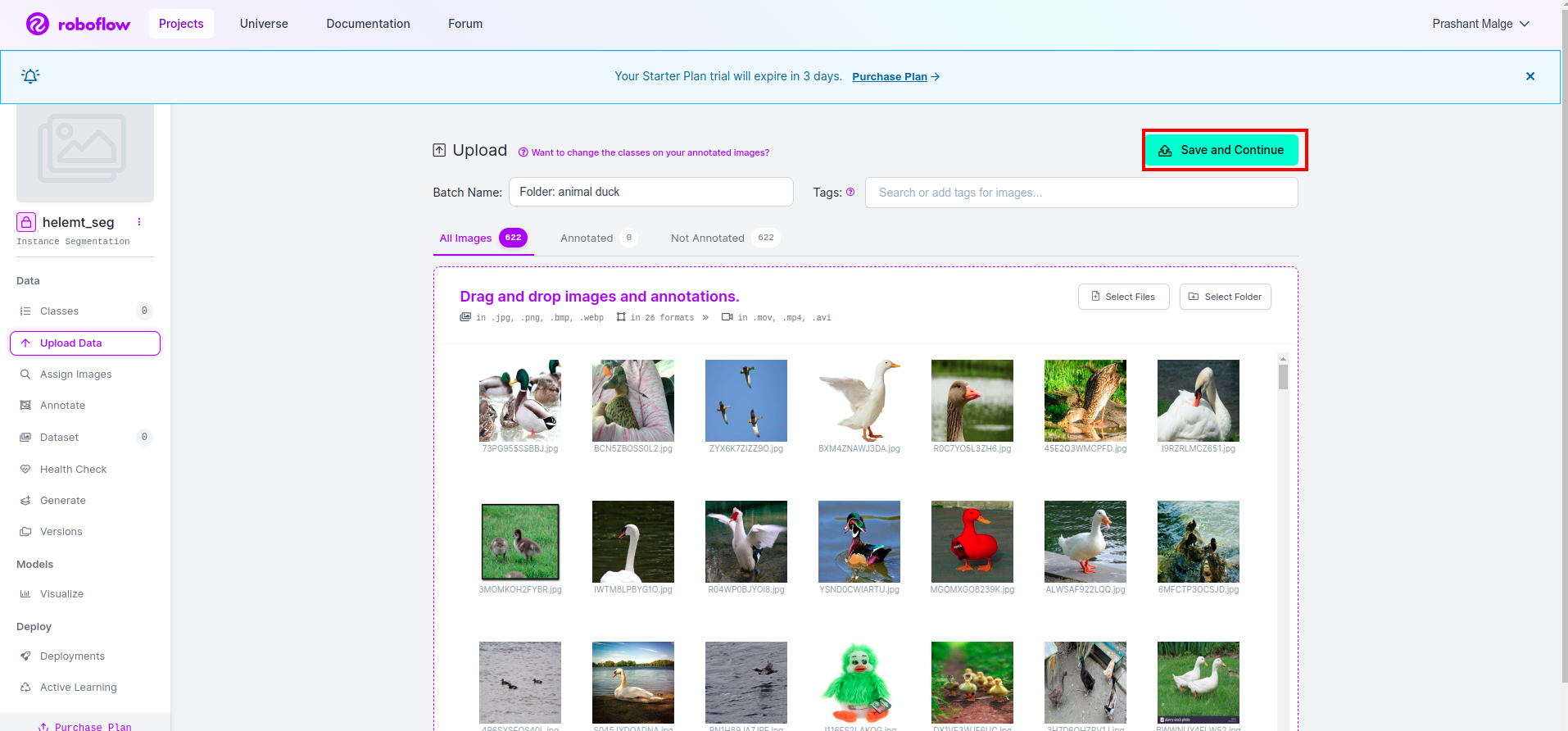
Después de crear el proyecto en roboflow, puede ver esta interfaz de usuario aquí. Puede cargar su conjunto de datos, por lo que si carga solo imágenes de partes del tren, seleccione "seleccione la carpeta" .
Luego haz clic en "guardar y continuar" opción que marco en un cuadro rectangular rojo
Paso 4: agregue el nombre de la clase
Luego ve al parte de clase en el lado izquierdo de marque la casilla roja. y escribe el nombre de la clase como pato, después de hacer clic en el cuadro verde.
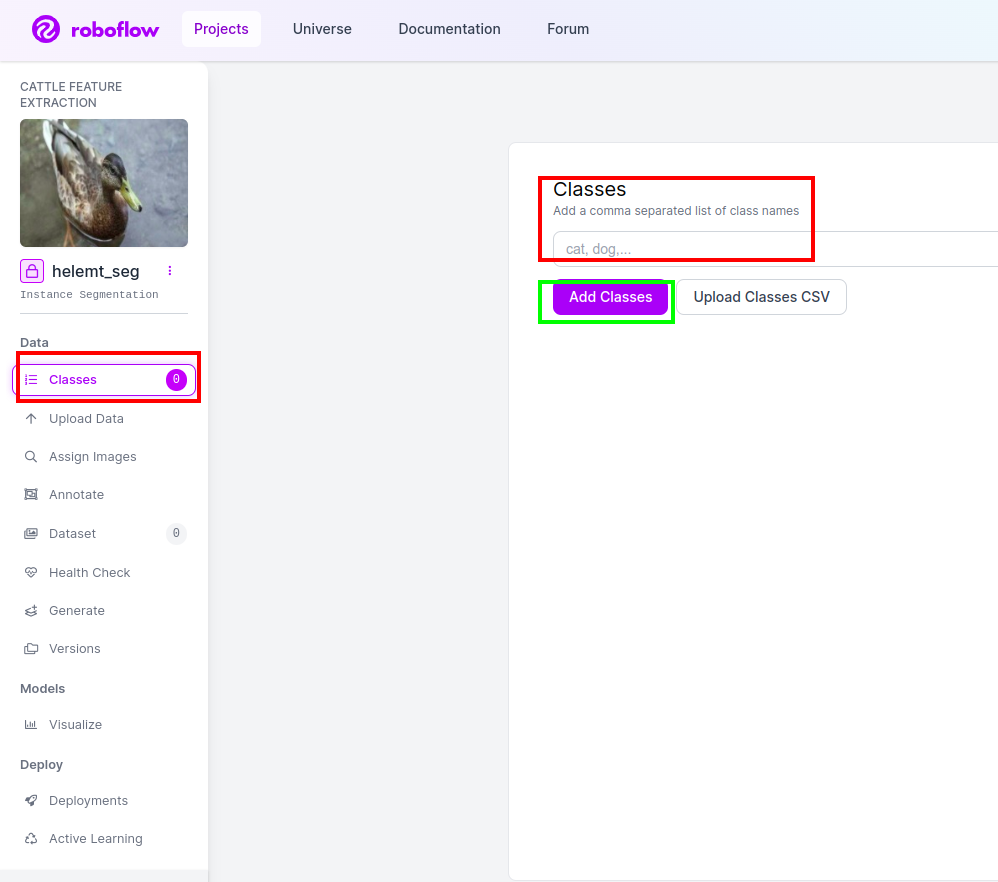
Ahora nuestra configuración está completa y la siguiente parte, como la parte de anotaciones, también es simple.
Paso 5: Inicie el parte de anotación
Visite la opción de anotación Marqué en el cuadro rojo y luego hice clic para iniciar la parte de anotación como lo marqué en el cuadro verde.
Haga clic en la primera imagen para ver esta interfaz de usuario. Después de ver esto, haga clic en la opción de anotación manual.
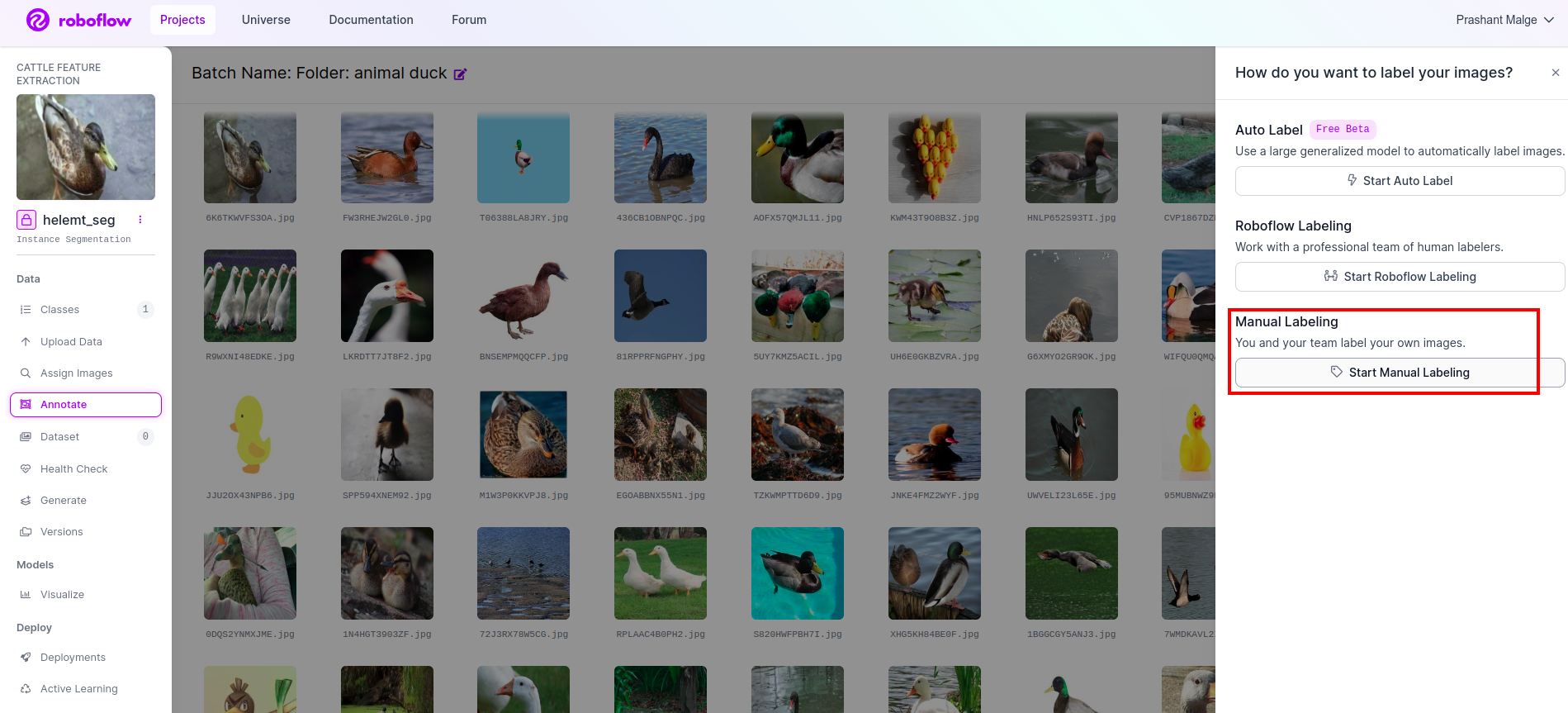
Luego agregue su identificación de correo electrónico o el nombre de su compañero de equipo para que pueda asignar la tarea.
Haga clic en la primera imagen para ver esta interfaz de usuario. aquí haga clic en el cuadro rojo para que pueda seleccionar el modelo multipolinomial.
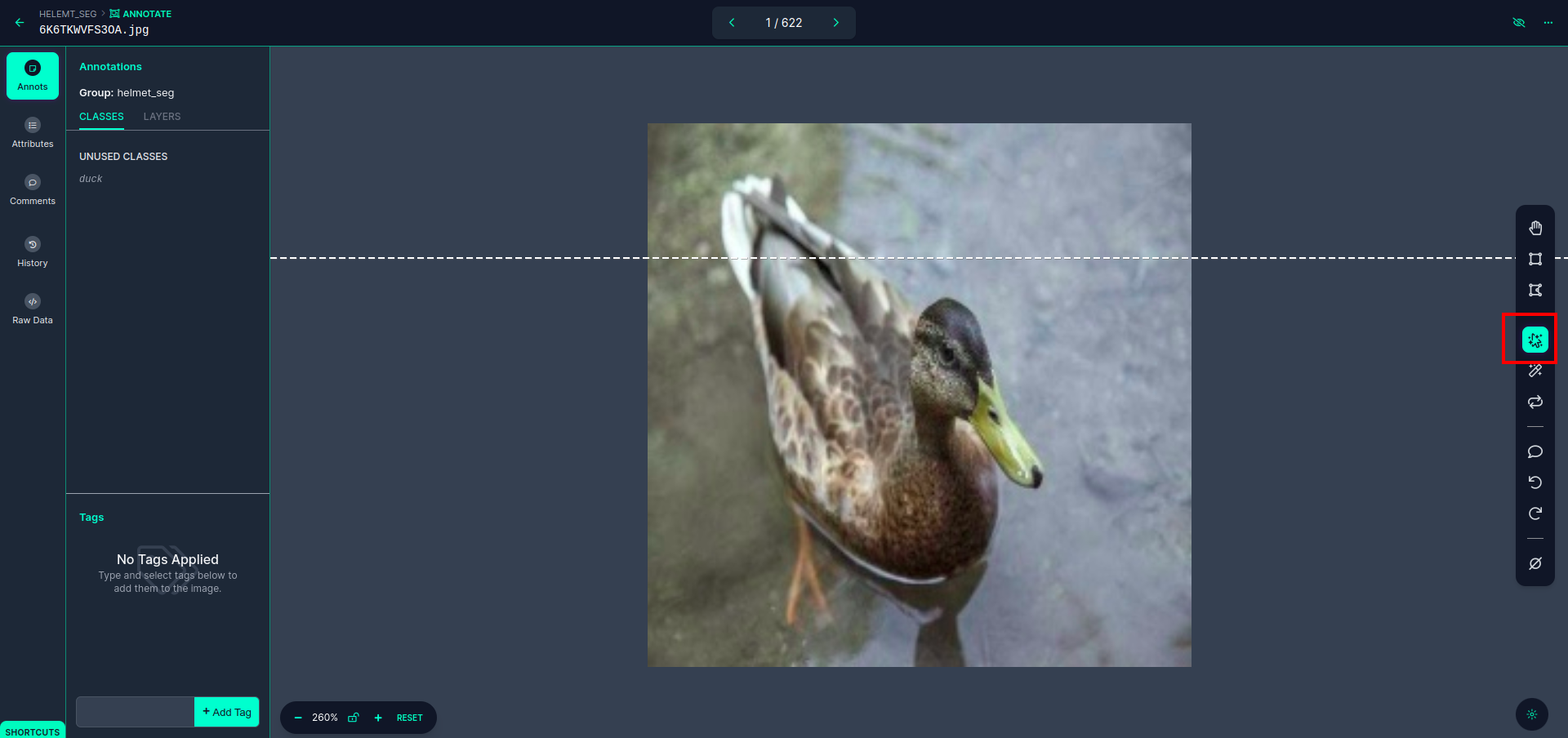
Después de hacer clic en el cuadro rojo, seleccione el modelo predeterminado y haga clic en el objeto pato. Esto segmentará automáticamente la imagen. Luego, haz clic en la siguiente parte y guárdala. Luego verá el lado izquierdo marcado en un cuadro rojo, donde podrá ver el nombre de la clase.
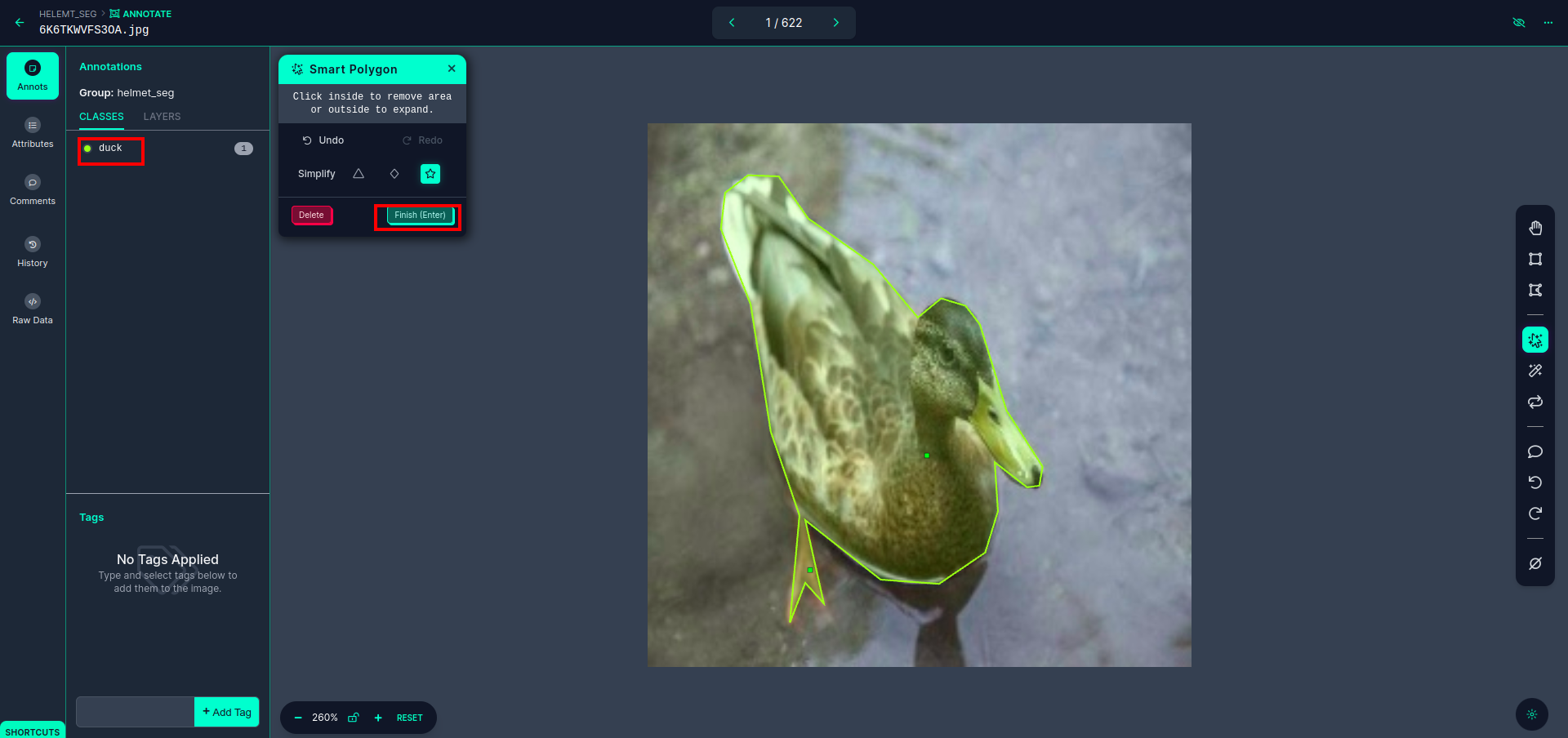
Haga clic en el guardar e ingresar opción. anotar todas las imágenes.
Agregue las imágenes para el formato YOLOv8. En el lado derecho, verá la opción para agregar imágenes en la sección de anotaciones. Aquí se crean dos partes: una para imágenes anotadas y otra para imágenes sin anotaciones.
- Primero, haga clic en el lado izquierdo "anotar" opción entonces add las imagenes al conjunto de datos.
- Luego haga clic en el siguiente "Añadir imágenes".
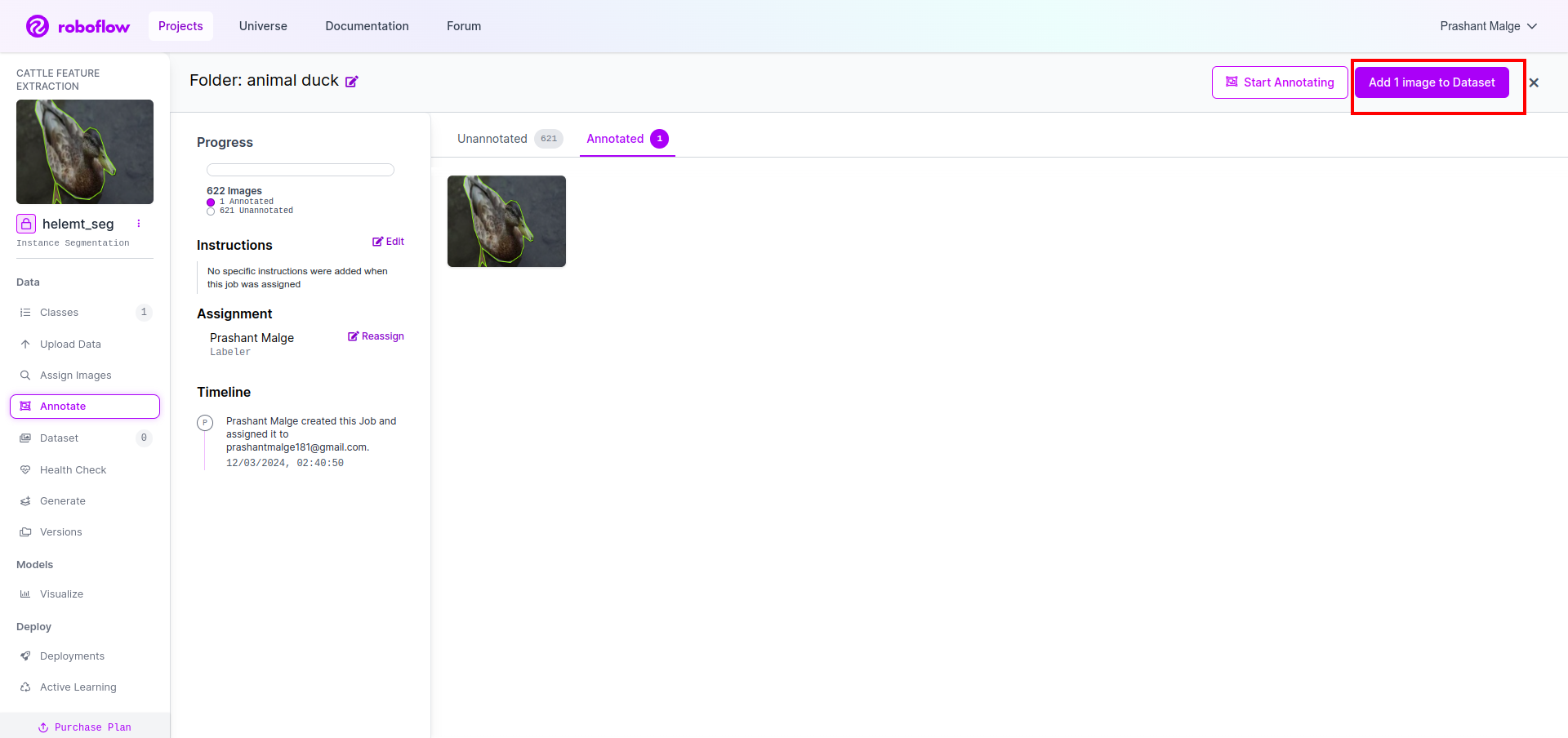
Ahora, por último, creamos el conjunto de datos, así que haga clic en la opción "Generar" en el lado izquierdo, luego marque la opción y presione la opción continuar.
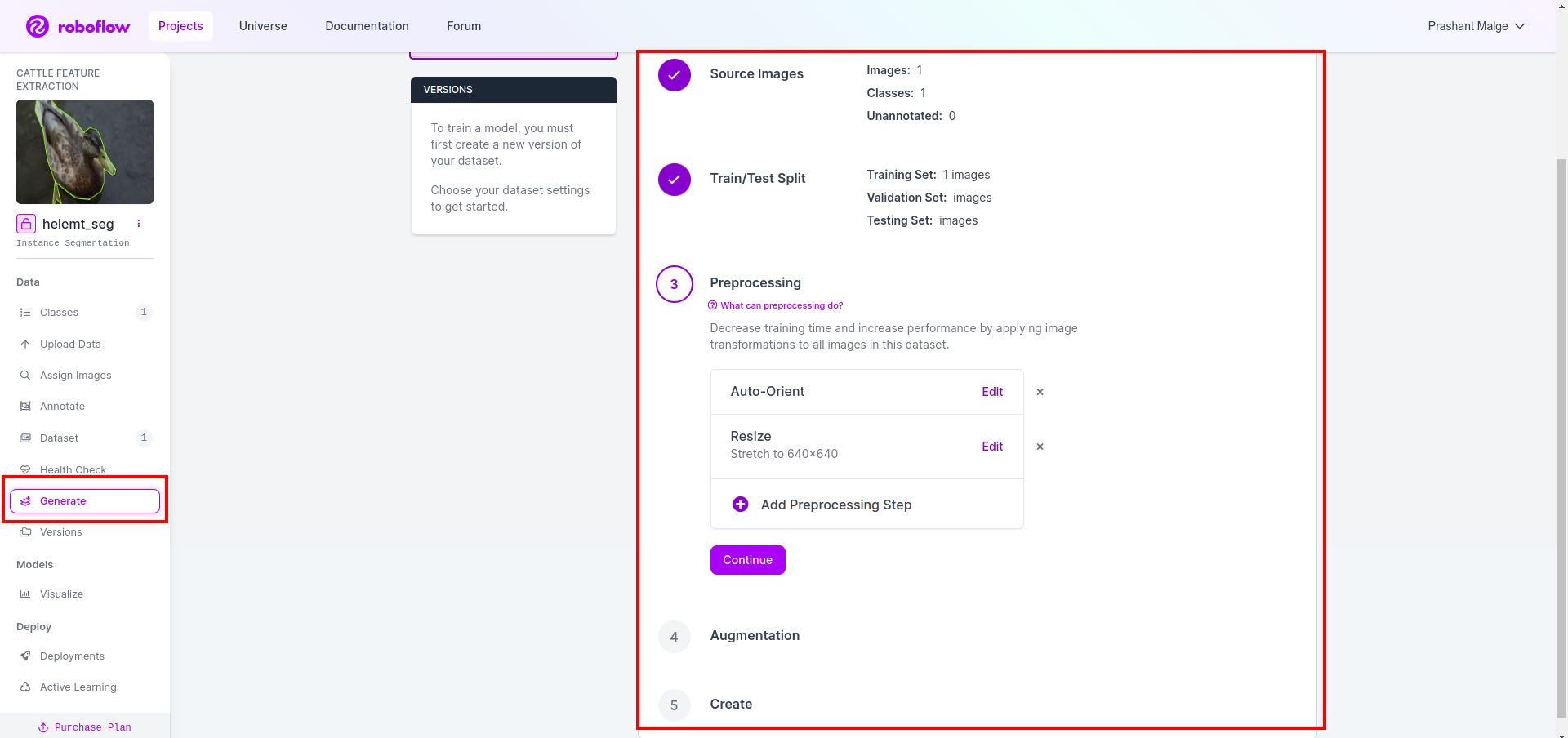
Luego obtienes la interfaz de usuario de la opción de división del conjunto de datos. Aquí puedes verificar las carpetas train, test y val, sus imágenes se dividen automáticamente. y haga clic en el cuadro rojo de arriba Opción Exportar conjunto de datos y descargar el archivo zip. la estructura de carpetas del archivo zip es como...
root_file.zip
│
├── test
│ ├── Images
│ └── labels
│
├── train
│ ├── Images
│ └── labels
│
├── val
│ ├── Images
│ └── labels
│
├── data.yaml
└── Readme.roboflow.txt
Paso 6: escribir el script para entrenar el modelo de segmentación de imágenes
Primero, en esta parte, crea el archivo de Google Collab usando Drive y luego carga su conjunto de datos. y conecte Google Drive mediante Google Collab.
1. Utilice este comando para Montar Google Drive
from google.colab import drive
drive.mount('/content/gdrive')2. Definir directorio de datos Utilice la variable constante.
DATA_DIR = '/content/drive/MyDrive/YoloV8/Data/'3. Instalando el paquete requerido, Instalar ultralíticos
!pip install ultralytics4. Importando las bibliotecas
import os
from ultralytics import YOLO5. carga YOLOv8 previamente entrenado modelo (aquí tenemos diferentes modelos, también consulte la documentación oficial allí puede ver los diferentes modelos)
model = YOLO('yolov8n-seg.pt')
# load a pretrained model (recommended for training)
6. Entrena el modelo
model.train(data='/content/drive/MyDrive/YoloV8/Data/data.yaml', epochs=2, imgsz=640)
# Update the path & and join this line together No verifique su unidad. Se crea la carpeta de nombre del modelo y allí se guarda el modelo para la predicción que queremos de este modelo.
7. Predecir el modelo
#Update the path
model_path = '/content/drive/MyDrive/YoloV8/Model/train2/weights/last.pt'
#Update the path
image_path = '/content/drive/MyDrive/YoloV8/Data/val/1be566eccffe9561.png'
img = cv2.imread(image_path)
H, W, _ = img.shape
model = YOLO(model_path)
results = model(img)
for result in results:
for j, mask in enumerate(result.masks.data):
mask = mask.numpy() * 255
mask = cv2.resize(mask, (W, H))
cv2.imwrite('./output.png', mask)Aquí puede ver que la imagen de segmentación está guardada.

Ahora finalmente podemos construir modelos de detección en vivo y de segmentación de imágenes.
Conclusión
En este blog, exploramos la detección de objetos en vivo y la segmentación de imágenes con YOLOv8. Para la detección en vivo, importamos un modelo YOLOv8 previamente entrenado y utilizamos la biblioteca de visión por computadora, OpenCV, para abrir la cámara y detectar objetos. Además, creamos una aplicación Streamlit para una interfaz de usuario atractiva.
A continuación, profundizamos en la segmentación de imágenes con YOLOv8. Importamos un modelo previamente entrenado y realizamos aprendizaje por transferencia en un conjunto de datos personalizado. Antes de esto, exploramos Roboflow para la anotación de conjuntos de datos, proporcionando una alternativa fácil de usar a herramientas como EtiquetaImg.
Finalmente, predecimos una imagen que contiene un pato. Aunque el objeto en la imagen parece ser un pájaro, especificamos el nombre de la clase como "pato”para fines de demostración.
Puntos clave
- Aprenda sobre modelos de detección de objetos como Faster R-CNN, SSD y el último YOLOv8.
- Comprender la herramienta de anotación Roboflow y su función en la creación de conjuntos de datos para modelos de segmentación YOLOv8.
- Explorar la detección de objetos vivos utilizando OpenCV (cv2) y Supervisión, mejorando las habilidades prácticas.
- Entrenando e implementando un modelo de segmentación usando YOLOv8, adquiriendo experiencia práctica.
Preguntas frecuentes
R. La detección de objetos implica identificar y ubicar varios objetos dentro de una imagen, generalmente dibujando cuadros delimitadores a su alrededor. La segmentación de imágenes, por otro lado, divide una imagen en segmentos o regiones según la similitud de píxeles, lo que proporciona una comprensión más detallada de los límites de los objetos.
R. YOLOv8 mejora las versiones anteriores al incorporar avances en arquitectura de red, técnicas de capacitación y optimización. Puede ofrecer mayor precisión, velocidad y eficiencia en comparación con YOLOv3.
R. YOLOv8 se puede utilizar para la detección de objetos en tiempo real en dispositivos integrados, según las capacidades del hardware y la optimización del modelo. Sin embargo, puede requerir optimizaciones como la poda o cuantificación del modelo para lograr un rendimiento en tiempo real en dispositivos con recursos limitados.
R. Roboflow ofrece herramientas de anotación intuitivas, funciones de gestión de conjuntos de datos y compatibilidad con varios formatos de anotación. Agiliza el proceso de anotación, permite la colaboración y proporciona control de versiones, lo que facilita la creación y gestión de conjuntos de datos para proyectos de visión por computadora.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2024/03/live-object-detection-and-image-segmentation-with-yolov8/

