Introducción
La recuperación de generación aumentada (RAG) ha conquistado el mundo desde sus inicios. RAG es lo necesario para que los modelos de lenguajes grandes (LLM) proporcionen o generen respuestas precisas y objetivas. Resolvemos la factualidad de los LLM mediante RAG, donde intentamos darle al LLM un contexto que sea contextualmente similar a la consulta del usuario para que el LLM trabaje con este contexto y genere una respuesta factualmente correcta. Hacemos esto representando nuestros datos y la consulta del usuario en forma de incrustaciones de vectores y realizando una similitud de coseno. Pero el problema es que todos los enfoques tradicionales representan los datos en una única incorporación, lo que puede no ser ideal para siempre. sistemas de recuperación. En esta guía, analizaremos ColBERT, que realiza la recuperación con mayor precisión que los modelos bicodificadores tradicionales.
OBJETIVOS DE APRENDIZAJE
- Comprenda cómo funciona la recuperación en RAG a alto nivel.
- Comprender las limitaciones de incrustación única en la recuperación.
- Mejore el contexto de recuperación con las incorporaciones de tokens de ColBERT.
- Descubra cómo la interacción tardía de ColBERT mejora la recuperación.
- Conozca cómo trabajar con ColBERT para una recuperación precisa.
Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Índice del contenido
¿Qué es RAG?
Los LLM, aunque son capaces de generar texto que sea significativo y gramaticalmente correcto, sufren de un problema llamado alucinación. Alucinaciones en LLM es el concepto en el que los LLM generan con confianza respuestas incorrectas, es decir, inventan respuestas incorrectas de una manera que nos hace creer que son ciertas. Este ha sido un problema importante desde la introducción de los LLM. Estas alucinaciones conducen a respuestas incorrectas y objetivamente erróneas. Por lo tanto, se introdujo la generación aumentada de recuperación.
En RAG, tomamos una lista de documentos/fragmentos de documentos y codificamos estos documentos textuales en una representación numérica llamada incrustaciones vectoriales, donde una única incrustación vectorial representa un único fragmento de documento y los almacena en una base de datos llamada tienda de vectores. Los modelos necesarios para codificar estos fragmentos en incrustaciones se denominan modelos de codificación o bicodificadores. Estos codificadores están entrenados en un gran corpus de datos, lo que los hace lo suficientemente potentes como para codificar fragmentos de documentos en una única representación de incrustación vectorial.
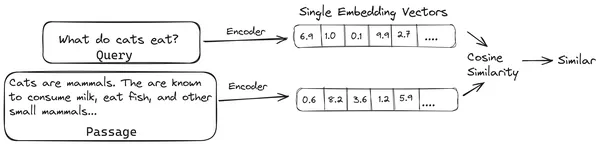
Ahora, cuando un usuario realiza una consulta al LLM, le damos esta consulta al mismo codificador para producir una incrustación de un solo vector. Esta incrustación se utiliza luego para calcular la puntuación de similitud con otras incrustaciones de vectores de los fragmentos del documento para obtener el fragmento más relevante del documento. El LLM recibe el fragmento más relevante o una lista de los fragmentos más relevantes junto con la consulta del usuario. Luego, el LLM recibe esta información contextual adicional y luego genera una respuesta que está alineada con el contexto recibido de la consulta del usuario. Esto garantiza que el contenido generado por el LLM sea factual y pueda rastrearse si es necesario.
El problema de los codificadores bicodificadores tradicionales
El problema con los modelos de codificadores tradicionales como el miniLM, OpenAI El modelo de incrustación y otros modelos de codificador es que comprimen todo el texto en una única representación de incrustación vectorial. Estas representaciones de incrustación de un solo vector son útiles porque ayudan a la recuperación rápida y eficiente de documentos similares. Sin embargo, el problema radica en la contextualidad entre la consulta y el documento. La incrustación de un único vector puede no ser suficiente para almacenar la información contextual de un fragmento de documento, creando así un cuello de botella de información.
Imagine que se comprimen 500 palabras en un único vector de tamaño 782. Puede que no sea suficiente representar dicho fragmento con un único vector incrustado, lo que da resultados deficientes en la recuperación en la mayoría de los casos. La representación vectorial única también puede fallar en casos de consultas o documentos complejos. Una de esas soluciones sería representar el fragmento del documento o una consulta como una lista de vectores de incrustación en lugar de un único vector de incrustación; aquí es donde entra en juego ColBERT.
¿Qué es ColBERT?
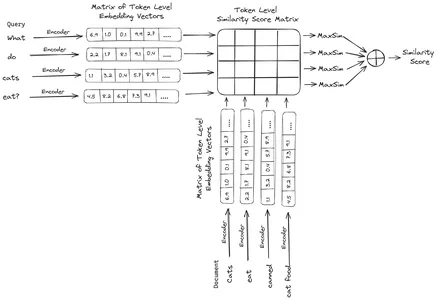
ColBERT (Contextual Late Interactions BERT) es un bicodificador que representa texto en una representación de incrustación de múltiples vectores. Toma una consulta o una parte de un documento/un documento pequeño y crea incrustaciones de vectores a nivel de token. Es decir, cada token obtiene su propia incrustación de vectores y la consulta/documento se codifica en una lista de incrustaciones de vectores a nivel de token. Las incorporaciones a nivel de token se generan a partir de un método previamente entrenado. BERTI modelo de ahí el nombre BERT.
Luego se almacenan en la base de datos de vectores. Ahora, cuando llega una consulta, se crea una lista de incrustaciones a nivel de token y luego se realiza una multiplicación de matrices entre la consulta del usuario y cada documento, lo que da como resultado una matriz que contiene puntuaciones de similitud. La similitud general se logra tomando la suma de la similitud máxima entre los tokens de documento para cada token de consulta. La fórmula para esto se puede ver en la siguiente imagen:
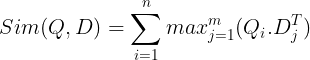
Aquí, en la ecuación anterior, vemos que hacemos un producto escalar entre la matriz de tokens de consulta (que contiene incrustaciones de vectores a nivel de token N) y la matriz de transposición de tokens de documento (que contiene incrustaciones de vectores a nivel de token M), y luego tomamos la similitud máxima. cruce los tokens de documento para cada token de consulta. Luego tomamos la suma de todas estas similitudes máximas, lo que nos da la puntuación de similitud final entre el documento y la consulta. La razón por la que esto produce una recuperación efectiva y precisa es que aquí estamos teniendo una interacción a nivel de token, lo que da espacio para una mayor comprensión contextual entre la consulta y el documento.
¿Por qué el nombre ColBERT?
Como estamos calculando la lista de vectores de incrustación antes de sí mismo y solo realizamos esta operación MaxSim (máxima similitud) durante la inferencia del modelo, por lo que lo llamamos un paso de interacción tardía, y como obtenemos más información contextual a través de interacciones a nivel de token, se llama contextual. interacciones tardías. De ahí el nombre de Interacciones Tardías Contextuales. BERTI o ColBERT. Estos cálculos se pueden realizar en paralelo, por lo que se pueden calcular de manera eficiente. Finalmente, una preocupación es el espacio, es decir, se requiere mucho espacio para almacenar esta lista de incrustaciones de vectores a nivel de token. Este problema se resolvió en ColBERTv2, donde los incrustaciones se comprimen mediante la técnica llamada compresión residual, optimizando así el espacio utilizado.
ColBERT práctico con ejemplo
En esta sección, pondremos manos a la obra con ColBERT e incluso comprobaremos su rendimiento frente a un modelo de incrustación normal.
Paso 1: descargar bibliotecas
Comenzaremos descargando la siguiente biblioteca:
!pip install ragatouille langchain langchain_openai chromadb einops sentence-transformers tiktoken- RAGatouille: Esta biblioteca nos permite trabajar con métodos de recuperación de última generación (SOTA) como ColBERT de una manera fácil de usar. Proporciona opciones para crear índices sobre los conjuntos de datos, consultarlos e incluso permitirnos entrenar un modelo ColBERT con nuestros datos.
- Cadena Lang: Esta biblioteca nos permitirá trabajar con los modelos de incrustación de código abierto para que podamos probar qué tan bien funcionan los otros modelos de incrustación en comparación con ColBERT.
- langchain_openai: Instala el LangChain dependencias para OpenAI. Incluso trabajaremos con el modelo OpenAI Embedding para comprobar su rendimiento frente a ColBERT.
- CromaDB: Esta biblioteca nos permitirá crear un almacén de vectores en nuestro entorno para que podamos guardar los embeddings que hayamos creado sobre nuestros datos y posteriormente realizar una búsqueda semántica entre la consulta y los embeddings almacenados.
- einops: Esta biblioteca es necesaria para multiplicaciones eficientes de matrices tensoriales.
- transformadores de oraciones y del tik token Se necesitan bibliotecas para que los modelos de incrustación de código abierto funcionen correctamente.
Paso 2: descargar el modelo previamente entrenado
En el siguiente paso, descargaremos el modelo ColBERT previamente entrenado. Para esto, el código será
from ragatouille import RAGPretrainedModel
RAG = RAGPretrainedModel.from_pretrained("colbert-ir/colbertv2.0")- Primero importamos la clase RAGPretrainedModel de la biblioteca RAGatouille.
- Luego llamamos a .from_pretrained() y le damos el nombre del modelo, es decir, “colbert-ir/colbertv2.0”.
Al ejecutar el código anterior se creará una instancia de un modelo ColBERT RAG. Ahora descarguemos una página de Wikipedia y recuperémosla. Para esto el código será:
from ragatouille.utils import get_wikipedia_page
document = get_wikipedia_page("Elon_Musk")
print("Word Count:",len(document))
print(document[:1000])RAGatouille viene con una práctica función llamada get_wikipedia_page que toma una cadena y obtiene la página de Wikipedia correspondiente. Aquí descargamos el contenido de Wikipedia sobre Elon Musk y lo almacenamos en el documento variable. Imprimamos la cantidad de palabras presentes en el documento y las primeras líneas del documento.
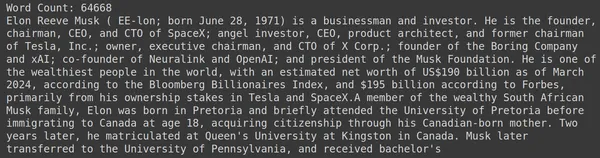
Aquí podemos ver el resultado en la imagen. Podemos ver que hay un total de 64,668 palabras en la página de Wikipedia de Elon Musk.
Paso 3: Indexación
Ahora crearemos un índice en este documento.
RAG.index(
# List of Documents
collection=[document],
# List of IDs for the above Documents
document_ids=['elon_musk'],
# List of Dictionaries for the metadata for the above Documents
document_metadatas=[{"entity": "person", "source": "wikipedia"}],
# Name of the index
index_name="Elon2",
# Chunk Size of the Document Chunks
max_document_length=256,
# Wether to Split Document or Not
split_documents=True
)Aquí llamamos al .index() del RAG para indexar nuestro documento. A esto le pasamos lo siguiente:
- colección: Esta es una lista de documentos que queremos indexar. Aquí tenemos solo un documento, por lo tanto, una lista de un solo documento.
- identificadores_documento: Cada documento espera una identificación de documento única. Aquí le pasamos el nombre elon_musk porque el documento trata sobre Elon Musk.
- metadatos_documento: Cada documento tiene sus metadatos. Nuevamente, esta es una lista de diccionarios, donde cada diccionario contiene metadatos de un par clave-valor para un documento en particular.
- nombre_índice: El nombre del índice que estamos creando. Llamémoslo Elon2.
- tamaño_max_documento: Esto es similar al tamaño del trozo. Especificamos cuánto debe ser cada fragmento de documento. Aquí le damos un valor de 256. Si no especificamos ningún valor, se tomará 256 como tamaño de fragmento predeterminado.
- documentos_divididos: Es un valor booleano, donde Verdadero indica que queremos dividir nuestro documento según el tamaño del fragmento dado y Falso indica que queremos almacenar el documento completo como un solo fragmento.
La ejecución del código anterior fragmentará nuestro documento en tamaños de 256 por fragmento, luego los incrustará a través del modelo ColBERT, que producirá una lista de incrustaciones de vectores a nivel de token para cada fragmento y finalmente los almacenará en un índice. Este paso tardará un poco en ejecutarse y puede acelerarse si tiene una GPU. Finalmente, crea un directorio donde se almacena nuestro índice. Aquí el directorio será “.ragatouille/colbert/indexes/Elon2”
Paso 4: Consulta general
Ahora comenzaremos la búsqueda. Para esto, el código será
results = RAG.search(query="What companies did Elon Musk find?", k=3, index_name='Elon2')
for i, doc, in enumerate(results):
print(f"---------------------------------- doc-{i} ------------------------------------")
print(doc["content"])- Aquí, primero, llamamos al método .search() del objeto RAG.
- A esto, le damos las variables que incluyen el nombre de la consulta, k (número de documentos a recuperar) y el nombre del índice a buscar.
- Aquí proporcionamos la consulta "¿Qué empresas encontró Elon Musk?". El resultado obtenido estará en una lista en formato de diccionario, que contiene claves como contenido, puntuación, clasificación, id_documento, id_pasaje y metadatos_documento.
- Por lo tanto, trabajamos con el siguiente código para imprimir los documentos recuperados de forma ordenada.
- Aquí revisamos la lista de diccionarios e imprimimos el contenido de los documentos.
Ejecutar el código producirá los siguientes resultados:
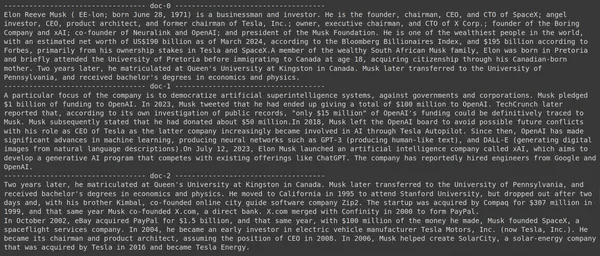
En la imagen podemos ver que el primer y último documento cubren íntegramente las diferentes empresas fundadas por Elon Musk. ColBERT pudo recuperar correctamente los fragmentos relevantes necesarios para responder a la consulta.
Paso 5: Consulta específica
Ahora vayamos un paso más allá y hagámosle una pregunta específica.
results = RAG.search(query="How much Tesla stocks did Elon sold in
Decemeber 2022?", k=3, index_name='Elon2')
for i, doc, in enumerate(results):
print(f"---------------
------------------- doc-{i} ------------------------------------")
print(doc["content"])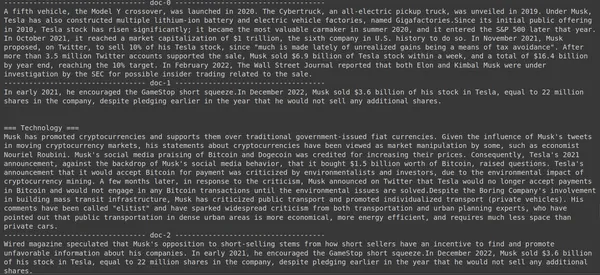
Aquí, en el código anterior, hacemos una pregunta muy específica sobre cuántas acciones de Tesla Elon se vendieron en el mes de diciembre de 2022. Podemos ver el resultado aquí. El doc-1 contiene la respuesta a la pregunta. Elon ha vendido acciones de Tesla por valor de 3.6 millones de dólares. Nuevamente, ColBERT pudo recuperar con éxito el fragmento relevante para la consulta dada.
Paso 6: probar otros modelos
Intentemos ahora la misma pregunta con los otros modelos de incrustación, tanto de código abierto como cerrados aquí:
from langchain_community.embeddings import HuggingFaceEmbeddings
from transformers import AutoModel
model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-en', trust_remote_code=True)
model_name = "jinaai/jina-embeddings-v2-base-en"
model_kwargs = {'device': 'cpu'}
embeddings = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
)
- Comenzamos descargando el modelo primero a través de la clase AutoModel de la biblioteca de Transformers.
- Luego almacenamos model_name y model_kwargs en sus respectivas variables.
- Ahora, para trabajar con este modelo en LangChain, importamos HuggingFaceEmbeddings del LangChain y dale el nombre del modelo y model_kwargs.
Al ejecutar este código se descargará y cargará el modelo de incrustación de Jina para que podamos trabajar con él.
Paso 7: crear incrustaciones
Ahora, necesitamos comenzar a dividir nuestro documento y luego crear incrustaciones a partir de él y almacenarlas en el almacén de vectores Chroma. Para ello trabajamos con el siguiente código:
from langchain_community.vectorstores import Chroma
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=256,
chunk_overlap=0)
splits = text_splitter.split_text(document)
vectorstore = Chroma.from_texts(texts=splits,
embedding=embeddings,
collection_name="elon")
retriever = vectorstore.as_retriever(search_kwargs = {'k':3})- Comenzamos importando Chroma y RecursiveCharacterTextSplitter de la biblioteca LangChain.
- Luego creamos una instancia de un text_splitter llamando al .from_tiktoken_encoder del RecursiveCharacterTextSplitter y pasándole el chunk_size y el chunk_overlap.
- Aquí usaremos el mismo tamaño de fragmento que le hemos proporcionado al ColBERT.
- Luego llamamos al método .split_text() de este text_splitter y le damos el documento que contiene información de Wikipedia sobre Elon Musk. Luego divide el documento según el tamaño de fragmento dado y, finalmente, la lista de fragmentos de documento se almacena en las divisiones variables.
- Finalmente, llamamos a la función .from_texts() de la clase Chroma para crear un almacén de vectores. A esta función, le damos las divisiones, el modelo de incrustación y el nombre_colección.
- Ahora, creamos un recuperador llamando a la función .as_retriever() del objeto de almacenamiento de vectores. Le damos 3 para el valor k
Al ejecutar este código, se tomará nuestro documento, se dividirá en documentos más pequeños de tamaño 256 por fragmento y luego se incrustarán estos fragmentos más pequeños con el modelo de incrustación de Jina y se almacenarán estos vectores de incrustación en el almacén de vectores cromáticos.
Paso 8: crear un recuperador
Finalmente, creamos un recuperador a partir de él. Ahora realizaremos una búsqueda vectorial y comprobaremos los resultados.
docs = retriever.get_relevant_documents("What companies did Elon Musk find?",)
for i, doc in enumerate(docs):
print(f"---------------------------------- doc-{i} ------------------------------------")
print(doc.page_content)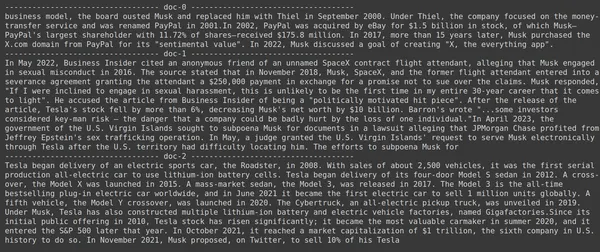
- Llamamos a la función .get_relevent_documents() del objeto recuperador y le damos la misma consulta.
- Luego imprimimos cuidadosamente los 3 documentos más recuperados.
- En la imagen, podemos ver que Jina Embedder, a pesar de ser un modelo de incrustación popular, la recuperación para nuestra consulta es deficiente. No logró obtener los fragmentos de documentos correctos.
Podemos detectar claramente la diferencia entre Jina, el modelo de incrustación que representa cada fragmento como una incrustación de un solo vector, y el modelo ColBERT que representa cada fragmento como una lista de vectores de incrustación a nivel de token. El ColBERT claramente supera en este caso.
Paso 9: Probar el modelo de integración de OpenAI
Ahora intentemos utilizar un modelo de incrustación de código cerrado como el modelo de incrustación de OpenAI.
import os
os.environ["OPENAI_API_KEY"] = "Your API Key"
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
model_name = "gpt-4",
chunk_size = 256,
chunk_overlap = 0,
)
splits = text_splitter.split_text(document)
vectorstore = Chroma.from_texts(texts=splits,
embedding=embeddings,
collection_name="elon_collection")
retriever = vectorstore.as_retriever(search_kwargs = {'k':3})Aquí el código es muy similar al que acabamos de escribir.
- La única diferencia es que pasamos la clave API de OpenAI para configurar la variable de entorno.
- Luego creamos una instancia del modelo OpenAI Embedding importándolo desde LangChain.
- Y mientras creamos el nombre de la colección, le damos un nombre de colección diferente, de modo que las incrustaciones del modelo OpenAI Embedding se almacenen en una colección diferente.
La ejecución de este código tomará nuevamente nuestros documentos, los dividirá en documentos más pequeños de tamaño 256 y luego los incrustará en una representación de incrustación de un solo vector con el modelo de incrustación de OpenAI y finalmente almacenará estas incrustaciones en Chroma Vector Store. Ahora intentemos recuperar los documentos relevantes para la otra pregunta.
docs = retriever.get_relevant_documents("How much Tesla stocks did Elon sold in Decemeber 2022?",)
for i, doc in enumerate(docs):
print(f"---------------------------------- doc-{i} ------------------------------------")
print(doc.page_content)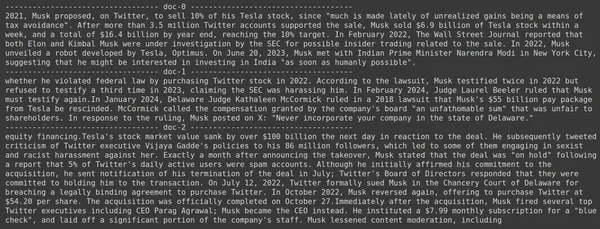
- Vemos que la respuesta que esperamos no se encuentra dentro de los fragmentos recuperados.
- El fragmento contiene información sobre las acciones de Tesla en 2022, pero no habla de que Elon las venda.
- Lo mismo se puede ver con los dos fragmentos de documentos restantes, donde la información que contienen es sobre Tesla y sus acciones, pero esta no es la información que esperábamos.
- Los fragmentos recuperados anteriormente no proporcionarán el contexto para que el LLM responda la consulta que le hemos proporcionado.
Incluso aquí podemos ver una clara diferencia entre la representación de incrustación de un solo vector y la representación de incrustación de múltiples vectores. Las representaciones de incrustación múltiple capturan claramente las consultas complejas, lo que da como resultado recuperaciones más precisas.
Conclusión
En conclusión, ColBERT demuestra un avance significativo en el rendimiento de recuperación con respecto a los modelos bicodificadores tradicionales al representar el texto como incrustaciones de múltiples vectores a nivel de token. Este enfoque permite una comprensión contextual más matizada entre consultas y documentos, lo que conduce a resultados de recuperación más precisos y mitiga el problema de las alucinaciones que se observan comúnmente en los LLM.
Puntos clave
- RAG aborda el problema de las alucinaciones en los LLM proporcionando información contextual para la generación de respuestas objetivas.
- Los bicodificadores tradicionales sufren de un cuello de botella en la información debido a la compresión de textos completos en incrustaciones de un solo vector, lo que resulta en una precisión de recuperación deficiente.
- ColBERT, con su representación integrada a nivel de token, facilita una mejor comprensión contextual entre consultas y documentos, lo que conduce a un mejor rendimiento de recuperación.
- El paso de interacción tardía en ColBERT, combinado con interacciones a nivel de token, mejora la precisión de la recuperación al considerar matices contextuales.
- ColBERTv2 optimiza el espacio de almacenamiento mediante la compresión residual mientras mantiene la efectividad de la recuperación.
- Los experimentos prácticos demuestran la superioridad de ColBERT en el rendimiento de recuperación en comparación con los modelos de integración tradicionales y de código abierto como Jina y OpenAI Embedding.
Preguntas frecuentes
R. Los bicodificadores tradicionales comprimen textos completos en incrustaciones de un solo vector, lo que podría perder información contextual. Esto limita su eficacia en tareas de recuperación, especialmente con consultas o documentos complejos.
R. ColBERT (BERT de interacciones tardías contextuales) es un modelo bicodificador que representa texto mediante incrustaciones de vectores a nivel de token. Permite una comprensión contextual más matizada entre consultas y documentos, lo que mejora la precisión de la recuperación.
R. ColBERT genera incrustaciones a nivel de token para consultas y documentos, realiza una multiplicación de matrices para calcular puntuaciones de similitud y luego selecciona la información más relevante en función de la similitud máxima entre tokens. Esto permite una recuperación efectiva con comprensión contextual.
R. ColBERTv2 optimiza el espacio mediante el método de compresión residual, lo que reduce los requisitos de almacenamiento para incorporaciones a nivel de token y al mismo tiempo mantiene la precisión de la recuperación.
R. Puede utilizar bibliotecas como RAGatouille para trabajar con ColBERT fácilmente. Al indexar documentos y consultas, puede realizar tareas de recuperación eficientes y generar respuestas precisas y alineadas con el contexto.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2024/04/colbert-improve-retrieval-performance-with-token-level-vector-embeddings/

