Krones proporciona a cervecerías, embotelladores de bebidas y productores de alimentos de todo el mundo máquinas individuales y líneas de producción completas. Cada día pasan por una línea de Krones millones de botellas de vidrio, latas y envases de PET. Las líneas de producción son sistemas complejos con muchos errores posibles que podrían detener la línea y disminuir el rendimiento de la producción. Krones quiere detectar el fallo lo antes posible (a veces incluso antes de que se produzca) y avisar a los operadores de la línea de producción para aumentar la fiabilidad y el rendimiento. Entonces, ¿cómo detectar un fallo? Krones equipa sus líneas con sensores para la recopilación de datos, que luego pueden evaluarse según reglas. Krones, tanto como fabricante de la línea como como operador de la línea, tiene la posibilidad de crear reglas de vigilancia para las máquinas. Por lo tanto, los embotelladores de bebidas y otros operadores pueden definir su propio margen de error para la línea. Krones utilizó en el pasado un sistema basado en una base de datos de series temporales. Los principales desafíos fueron que este sistema era difícil de depurar y además las consultas representaban el estado actual de las máquinas, pero no las transiciones de estado.
Este post muestra cómo Krones construyó una solución de streaming para monitorear sus líneas, basada en Kinesis amazónica y Servicio administrado de Amazon para Apache Flink. Estos servicios totalmente administrados reducen la complejidad de crear aplicaciones de transmisión con Apache Flink. El servicio administrado para Apache Flink administra los componentes subyacentes de Apache Flink que brindan estados duraderos de las aplicaciones, métricas, registros y más, y Kinesis le permite procesar datos de streaming de manera rentable a cualquier escala. Si desea comenzar con su propia aplicación Apache Flink, consulte la Repositorio GitHub para obtener ejemplos que utilizan las API de Java, Python o SQL de Flink.
Resumen de la solución
La supervisión de líneas de Krones forma parte del Guía de Krones para el taller sistema. Brinda apoyo en la organización, priorización, gestión y documentación de todas las actividades de la empresa. Les permite notificar a un operador si la máquina se detiene o se necesitan materiales, independientemente de dónde se encuentre el operador en la línea. Las reglas de monitoreo de condición comprobadas ya están integradas, pero el usuario también puede definirlas a través de la interfaz de usuario. Por ejemplo, si un determinado punto de datos que se monitorea viola un umbral, puede haber un mensaje de texto o un desencadenante de una orden de mantenimiento en la línea.
El sistema de evaluación de reglas y monitoreo de condición está construido en AWS y utiliza los servicios de análisis de AWS. El siguiente diagrama ilustra la arquitectura.
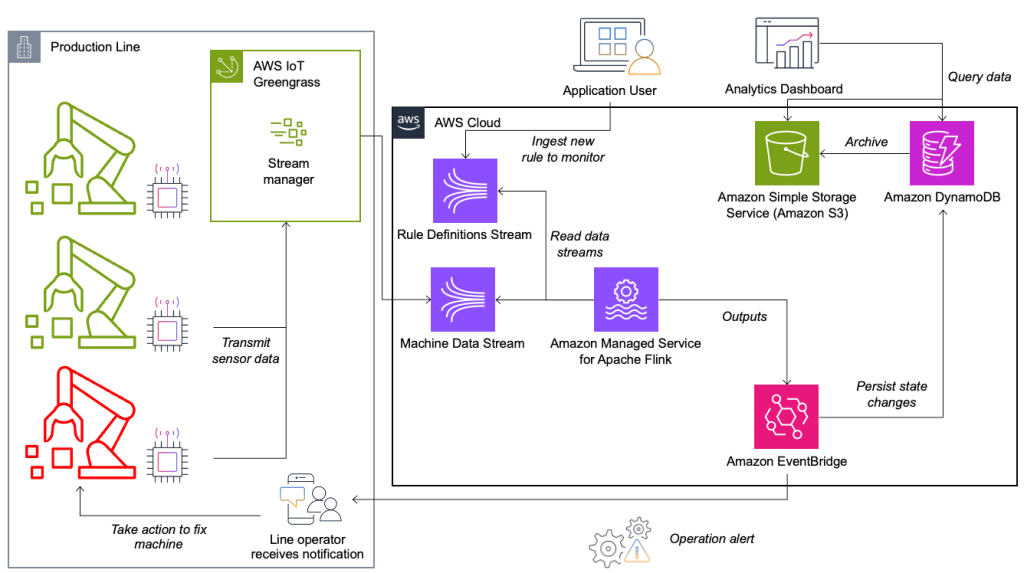
Casi todas las aplicaciones de transmisión de datos constan de cinco capas: fuente de datos, ingesta de transmisión, almacenamiento de transmisión, procesamiento de transmisión y uno o más destinos. En las siguientes secciones profundizaremos en cada capa y en el funcionamiento de la solución de monitorización de líneas de Krones.
Fuente de datos
Los datos los recopila un servicio que se ejecuta en un dispositivo perimetral que lee varios protocolos como Siemens S7 u OPC/UA. Los datos sin procesar se preprocesan para crear una estructura JSON unificada, lo que facilita su procesamiento posterior en el motor de reglas. Una carga útil de muestra convertida a JSON podría verse similar a la siguiente:
{
"version": 1,
"timestamp": 1234,
"equipmentId": "84068f2f-3f39-4b9c-a995-d2a84d878689",
"tag": "water_temperature",
"value": 13.45,
"quality": "Ok",
"meta": {
"sequenceNumber": 123,
"flags": ["Fst", "Lst", "Wmk", "Syn", "Ats"],
"createdAt": 12345690,
"sourceId": "filling_machine"
}
}Ingestión de flujo
AWS IoT Greengrass es un servicio de nube y tiempo de ejecución perimetral de Internet de las cosas (IoT) de código abierto. Esto le permite actuar sobre los datos localmente y agregar y filtrar datos del dispositivo. AWS IoT Greengrass proporciona componentes prediseñados que se pueden implementar en el borde. La solución de línea de producción utiliza el componente Stream Manager, que puede procesar datos y transferirlos a destinos de AWS, como Análisis de IoT de AWS, Servicio de almacenamiento simple de Amazon (Amazon S3) y Kinesis. El administrador de secuencias almacena en búfer y agrega registros y luego los envía a una secuencia de datos de Kinesis.
Almacenamiento de flujo
El trabajo del almacenamiento de flujo es almacenar en búfer los mensajes de manera tolerante a fallas y ponerlos a disposición para el consumo de una o más aplicaciones de consumo. Para lograr esto en AWS, las tecnologías más comunes son Kinesis y Streaming administrado por Amazon para Apache Kafka (Amazon MSK). Para almacenar los datos de nuestros sensores de las líneas de producción, Krones elige Kinesis. Kinesis es un servicio de transmisión de datos sin servidor que funciona a cualquier escala con baja latencia. Los fragmentos dentro de un flujo de datos de Kinesis son una secuencia de registros de datos identificada de forma única, donde un flujo se compone de uno o más fragmentos. Cada fragmento tiene 2 MB/s de capacidad de lectura y 1 MB/s de capacidad de escritura (con un máximo de 1,000 registros/s). Para evitar alcanzar esos límites, los datos deben distribuirse entre los fragmentos de la manera más uniforme posible. Cada registro que se envía a Kinesis tiene una clave de partición, que se utiliza para agrupar datos en un fragmento. Por lo tanto, desea tener una gran cantidad de claves de partición para distribuir la carga de manera uniforme. El administrador de secuencias que se ejecuta en AWS IoT Greengrass admite asignaciones aleatorias de claves de partición, lo que significa que todos los registros terminan en un fragmento aleatorio y la carga se distribuye uniformemente. Una desventaja de las asignaciones aleatorias de claves de partición es que los registros no se almacenan en orden en Kinesis. Te explicamos cómo solucionar esto en el siguiente apartado, donde hablamos de marcas de agua.
Marcas de agua
A filigrana es un mecanismo utilizado para rastrear y medir el progreso del tiempo del evento en un flujo de datos. La hora del evento es la marca de tiempo desde que se creó el evento en el origen. La marca de agua indica el progreso oportuno de la aplicación de procesamiento de flujo, por lo que todos los eventos con una marca de tiempo anterior o igual se consideran procesados. Esta información es esencial para que Flink avance el tiempo del evento y active cálculos relevantes, como evaluaciones de ventanas. El retraso permitido entre el tiempo del evento y la marca de agua se puede configurar para determinar cuánto tiempo esperar por los datos tardíos antes de considerar una ventana completa y avanzar la marca de agua.
Krones tiene instalaciones en todo el mundo y necesitaba gestionar llegadas tardías debido a pérdidas de conexión u otras limitaciones de la red. Comenzaron monitoreando las llegadas tarde y estableciendo el manejo de demora predeterminado de Flink en el valor máximo que vieron en esta métrica. Experimentaron problemas con la sincronización horaria desde los dispositivos periféricos, lo que los llevó a una forma más sofisticada de marca de agua. Crearon una marca de agua global para todos los remitentes y utilizaron el valor más bajo como marca de agua. Las marcas de tiempo se almacenan en un HashMap para todos los eventos entrantes. Cuando las marcas de agua se emiten periódicamente, se utiliza el valor más pequeño de este HashMap. Para evitar el estancamiento de las marcas de agua por datos faltantes, configuraron un idleTimeOut parámetro, que ignora las marcas de tiempo que son anteriores a un determinado umbral. Esto aumenta la latencia pero proporciona una gran coherencia a los datos.
public class BucketWatermarkGenerator implements WatermarkGenerator<DataPointEvent> {
private HashMap <String, WatermarkAndTimestamp> lastTimestamps;
private Long idleTimeOut;
private long maxOutOfOrderness;
}
Procesamiento de flujo
Una vez que los datos se recopilan de los sensores y se incorporan a Kinesis, es necesario evaluarlos mediante un motor de reglas. Una regla en este sistema representa el estado de una única métrica (como la temperatura) o un conjunto de métricas. Para interpretar una métrica, se utiliza más de un punto de datos, lo que constituye un cálculo con estado. En esta sección, profundizamos en el estado de clave y el estado de transmisión en Apache Flink y cómo se utilizan para construir el motor de reglas de Krones.
Controlar el flujo y el patrón de estado de transmisión
En Apache Flink, estado se refiere a la capacidad del sistema para almacenar y administrar información de manera persistente a lo largo del tiempo y las operaciones, lo que permite el procesamiento de datos en tiempo real con soporte para cálculos con estado.
El patrón de estado de transmisión permite la distribución de un estado a todas las instancias paralelas de un operador. Por tanto, todos los operadores tienen el mismo estado y los datos se pueden procesar utilizando este mismo estado. Estos datos de solo lectura se pueden ingerir mediante un flujo de control. Un flujo de control es un flujo de datos normal, pero normalmente con una velocidad de datos mucho menor. Este patrón le permite actualizar dinámicamente el estado de todos los operadores, lo que permite al usuario cambiar el estado y el comportamiento de la aplicación sin necesidad de volver a implementarla. Más precisamente, la distribución del estado se realiza mediante el uso de un flujo de control. Al agregar un nuevo registro al flujo de control, todos los operadores reciben esta actualización y utilizan el nuevo estado para el procesamiento de nuevos mensajes.
Esto permite a los usuarios de la aplicación Krones incorporar nuevas reglas en la aplicación Flink sin reiniciarla. Esto evita el tiempo de inactividad y brinda una excelente experiencia de usuario ya que los cambios ocurren en tiempo real. Una regla cubre un escenario para detectar una desviación del proceso. A veces, los datos de la máquina no son tan fáciles de interpretar como podría parecer a primera vista. Si un sensor de temperatura envía valores altos, esto podría indicar un error, pero también ser el efecto de un procedimiento de mantenimiento continuo. Es importante poner las métricas en contexto y filtrar algunos valores. Esto se logra mediante un concepto llamado agrupamiento.
Agrupación de métricas
La agrupación de datos y métricas le permite definir la relevancia de los datos entrantes y producir resultados precisos. Repasemos el ejemplo de la siguiente figura.
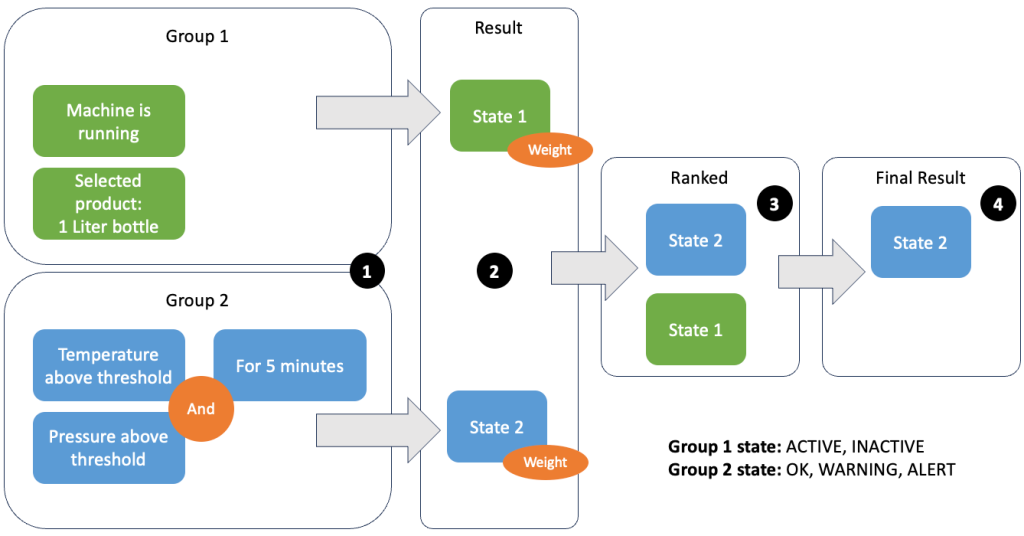
En el Paso 1, definimos dos grupos de condiciones. El grupo 1 recoge el estado de la máquina y qué producto pasa por la línea. El grupo 2 utiliza el valor de los sensores de temperatura y presión. Un grupo de condiciones puede tener diferentes estados según los valores que reciba. En este ejemplo, el grupo 1 recibe datos de que la máquina está funcionando y se selecciona como producto la botella de un litro; esto le da a este grupo el estado ACTIVE. El grupo 2 tiene métricas de temperatura y presión; Ambas métricas están por encima de sus umbrales durante más de 5 minutos. Esto da como resultado que el grupo 2 esté en una WARNING estado. Esto significa que el grupo 1 informa que todo está bien y el grupo 2 no. En el Paso 2, se agregan pesos a los grupos. Esto es necesario en algunas situaciones, porque los grupos pueden reportar información contradictoria. En este escenario, el grupo 1 informa ACTIVE y informes del grupo 2 WARNING, por lo que el sistema no tiene claro cuál es el estado de la línea. Después de sumar las ponderaciones, los estados se pueden clasificar, como se muestra en el paso 3. Por último, el estado mejor clasificado se elige como ganador, como se muestra en el paso 4.
Una vez evaluadas las reglas y definido el estado final de la máquina, los resultados se procesarán más. La acción tomada depende de la configuración de la regla; Esto puede ser una notificación al operador de línea para reabastecer materiales, realizar algún mantenimiento o simplemente una actualización visual en el tablero. Esta parte del sistema, que evalúa métricas y reglas y toma acciones basadas en los resultados, se conoce como motor de reglas.
Escalar el motor de reglas
Al permitir que los usuarios creen sus propias reglas, el motor de reglas puede tener una gran cantidad de reglas que necesita evaluar, y algunas reglas pueden usar los mismos datos de sensores que otras reglas. Flink es un sistema distribuido que escala muy bien horizontalmente. Para distribuir un flujo de datos a varias tareas, puede utilizar el keyBy() método. Esto le permite particionar un flujo de datos de forma lógica y enviar partes de los datos a diferentes administradores de tareas. Esto a menudo se hace eligiendo una clave arbitraria para obtener una carga distribuida uniformemente. Krones añadió en este caso un ruleId al punto de datos y lo usó como clave. De lo contrario, los puntos de datos necesarios se procesan mediante otra tarea. El flujo de datos con clave se puede utilizar en todas las reglas como una variable normal.
Destinos
Cuando una regla cambia su estado, la información se envía a una secuencia de Kinesis y luego a través de Puente de eventos de Amazon a los consumidores. Uno de los consumidores crea una notificación del evento que se transmite a la línea de producción y alerta al personal para que actúe. Para poder analizar los cambios de estado de las reglas, otro servicio escribe los datos en un Amazon DynamoDB tabla para un acceso rápido y existe un TTL para descargar el historial a largo plazo a Amazon S3 para obtener más informes.
Conclusión
En este post le mostramos cómo Krones construyó un sistema de monitoreo de línea de producción en tiempo real en AWS. Managed Service para Apache Flink permitió al equipo de Krones empezar rápidamente, centrándose más en el desarrollo de aplicaciones que en la infraestructura. Las capacidades en tiempo real de Flink permitieron a Krones reducir el tiempo de inactividad de las máquinas en un 10 % y aumentar la eficiencia hasta un 5 %.
Si desea crear sus propias aplicaciones de transmisión por secuencias, consulte los ejemplos disponibles en el Repositorio GitHub. Si desea ampliar su aplicación Flink con conectores personalizados, consulte Facilitando la creación de conectores con Apache Flink: presentación del receptor asíncrono. Async Sink está disponible en Apache Flink versión 1.15.1 y posteriores.
Acerca de los autores
 Florian Maier es arquitecto senior de soluciones y experto en transmisión de datos en AWS. Es un tecnólogo que ayuda a los clientes en Europa a tener éxito e innovar resolviendo desafíos comerciales utilizando los servicios de la nube de AWS. Además de trabajar como arquitecto de soluciones, Florian es un apasionado del montañismo y ha escalado algunas de las montañas más altas de Europa.
Florian Maier es arquitecto senior de soluciones y experto en transmisión de datos en AWS. Es un tecnólogo que ayuda a los clientes en Europa a tener éxito e innovar resolviendo desafíos comerciales utilizando los servicios de la nube de AWS. Además de trabajar como arquitecto de soluciones, Florian es un apasionado del montañismo y ha escalado algunas de las montañas más altas de Europa.
 Emil Dietl es Senior Tech Lead en Krones y se especializa en ingeniería de datos, con un campo clave en Apache Flink y microservicios. Su trabajo a menudo implica el desarrollo y mantenimiento de software de misión crítica. Fuera de su vida profesional, valora profundamente pasar tiempo de calidad con su familia.
Emil Dietl es Senior Tech Lead en Krones y se especializa en ingeniería de datos, con un campo clave en Apache Flink y microservicios. Su trabajo a menudo implica el desarrollo y mantenimiento de software de misión crítica. Fuera de su vida profesional, valora profundamente pasar tiempo de calidad con su familia.
 Simón Peyer es arquitecto de soluciones en AWS con sede en Suiza. Es un hacedor práctico y le apasiona conectar la tecnología y las personas mediante los servicios de la nube de AWS. Para él, se centra especialmente en la transmisión de datos y las automatizaciones. Además del trabajo, Simon disfruta de su familia, el aire libre y las caminatas en las montañas.
Simón Peyer es arquitecto de soluciones en AWS con sede en Suiza. Es un hacedor práctico y le apasiona conectar la tecnología y las personas mediante los servicios de la nube de AWS. Para él, se centra especialmente en la transmisión de datos y las automatizaciones. Además del trabajo, Simon disfruta de su familia, el aire libre y las caminatas en las montañas.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/krones-real-time-production-line-monitoring-with-amazon-managed-service-for-apache-flink/

