5G ya es real, aunque algunos de nosotros nos preguntamos por qué nuestras conexiones telefónicas no son más rápidas. Esa perspectiva pasa por alto la intención real de 5G: extender la comunicación de alto rendimiento (y baja latencia) a una gran cantidad y variedad de dispositivos de borde más allá de nuestros teléfonos. Una aplicación notable es el acceso inalámbrico fijo (FWA), que promete reemplazar la fibra con banda ancha inalámbrica para la conectividad de última milla. Los consumidores ya están cortando sus teléfonos fijos; con FWA también pueden cortar sus conexiones de cable. Las empresas pueden llevar esto más allá, instalando estaciones base FWA alrededor de fábricas, oficinas, hospitales, etc., para admitir muchos más dispositivos inteligentes en la empresa.
Un requisito comercial esencial para permitir este nivel de escalabilidad horizontal es una infraestructura de red inalámbrica mucho más rentable. Open Radio Access Network (Open RAN) y RAN virtualizada (vRAN) son dos esfuerzos complementarios para apoyar este objetivo. Open RAN estandariza las interfaces en toda la red, fomentando la competencia entre los proveedores de componentes de red. vRAN mejora el rendimiento dentro de un componente al explotar de manera más eficiente un recurso de hardware fijo para múltiples canales independientes. Sabemos cómo hacer esto con plataformas de procesadores multinúcleo estándar, mediante el envío de tareas a núcleos separados o mediante subprocesos múltiples. Las funciones importantes en la RAN ahora se ejecutan en DSP, que también admiten múltiples núcleos pero no subprocesos múltiples. ¿Es posible la innovación DSP para superar este inconveniente?
¿Cual es la solución?
Los componentes de infraestructura RAN existentes, específicamente los procesadores utilizados en banda base y backhaul, admiten virtualización/multiproceso y están bien establecidos para 4G y 5G temprano. ¿Seguramente los operadores de red deberían ceñirse a soluciones probadas y verdaderas para Open RAN y vRAN?
Desafortunadamente, los componentes existentes no funcionarán tan bien para el escalamiento horizontal que necesitamos para 5G completo. Son costosos, consumen mucha energía (perjudican el costo operativo), la competencia en componentes es muy limitada y estos dispositivos no están optimizados para los aspectos de procesamiento de señales de la RAN. Los operadores y los fabricantes de equipos se han cambiado con entusiasmo a los ASIC basados en DSP para superar esos problemas, especialmente a medida que se acercan a la interfaz de radio y al equipo del usuario, donde la RAN debe ofrecer soporte MIMO masivo.
Una mejor solución sería continuar aprovechando las ventajas demostradas de las plataformas basadas en DSP, cuando corresponda, mientras se innova para administrar el tráfico de alto volumen creciente de manera más eficiente en un espacio de DSP fijo.
Mayor rendimiento, menos DSP
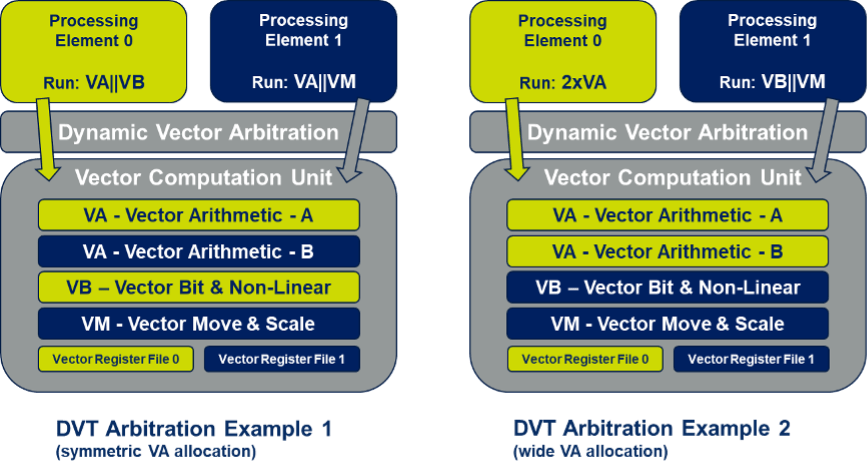
El sistema DSP multinúcleo ya está disponible. Pero cualquiera de esos núcleos DSP maneja solo un canal a la vez. Una solución más eficiente también permitiría subprocesos múltiples dentro de un núcleo. Por lo general, es posible dividir un núcleo para manejar dos o más canales a la vez, pero este subprocesamiento fijo es una asignación estática. Lo que limita más la flexibilidad es la unidad de cómputo vectorial (VCU) en cada núcleo DSP. Las VCU son los principales diferenciadores entre los DSP y las CPU de propósito general, ya que manejan todo el cálculo intensivo de la señal (formación de haces, FFT, agregación de canales y mucho más) en la ruta de procesamiento de RAN entre la infraestructura y los dispositivos de borde. Las VCU consumen una huella significativa en los núcleos de DSP, una consideración importante en los sistemas de múltiples núcleos durante los momentos en que el software ejecuta operaciones escalares y la VCU debe estar inactiva.
La utilización se puede mejorar significativamente a través de la arquitectura dinámica de subprocesos vectoriales ilustrada en la figura anterior. Dentro de un núcleo DSP, dos procesadores escalares admiten 2 canales en paralelo; esto no aumenta significativamente la huella. La VCU es común a ambos procesadores y proporciona funciones de cálculo vectorial y un archivo de registro vectorial para cada canal. Hasta ahora, esto se parece a la solución de división estática descrita anteriormente. Sin embargo, cuando solo un canal necesita cómputo vectorial en un momento dado, ese cálculo puede abarcar tanto unidades de cómputo como archivos de registro, duplicando el rendimiento de ese canal. Este es un subproceso de vector dinámico, que permite que dos canales usen recursos de vector en paralelo cuando sea necesario, o permite que un canal procese un vector de doble ancho con mayor rendimiento efectivo cuando la necesidad de vector en el otro canal está inactiva. Naturalmente, la solución se puede extender a más de dos subprocesos con extensiones de hardware obvias.
En pocas palabras, un sistema de este tipo puede procesar con múltiples núcleos y computar dinámicamente varios subprocesos vectoriales dentro de cada núcleo. Con una carga máxima absoluta, el sistema seguirá ofreciendo un rendimiento efectivo. Durante las cargas submáximas más comunes, ofrecerá un mayor rendimiento para un número fijo de núcleos que un sistema multinúcleo tradicional. Los operadores de red, las empresas y los consumidores podrán sacar más provecho del hardware instalado durante más tiempo, antes de tener que actualizarlo.
Habla con CEVA
CEVA ha estado trabajando durante muchos años con los grandes nombres en hardware de infraestructura, productos de consumo y comerciales. Me dijeron que esos clientes los han guiado activamente hacia esta capacidad de subprocesamiento múltiple vectorial, lo que sugiere que es probable que el subprocesamiento vectorial dinámico se estrene en los productos en los próximos años. Puede obtener más información sobre la arquitectura de la familia XC-20 de CEVA que ofrece subprocesos vectoriales dinámicos AQUÍ.
Comparte esta publicación a través de:
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://semiwiki.com/5g/325404-dsp-innovation-promises-to-boost-virtual-ran-efficiency/

