
Imagen por editor
La ciencia de datos es un campo que ha crecido enormemente en los últimos cien años debido a los avances realizados en el campo de la informática. Dado que los costos de almacenamiento en la nube y las computadoras son cada vez más baratos, ahora podemos almacenar grandes cantidades de datos a un costo muy bajo en comparación con hace unos años. Con el aumento de la potencia computacional, podemos ejecutar algoritmos de aprendizaje automático en grandes conjuntos de datos y procesarlos para producir conocimientos. Con los avances en redes, podemos generar y transmitir datos a través de Internet a la velocidad del rayo. Como resultado de todo esto, vivimos en una era en la que cada segundo se generan abundantes datos. Tenemos datos en forma de correo electrónico, transacciones financieras, contenido de redes sociales, páginas web en Internet, datos de clientes para empresas, registros médicos de pacientes, datos de fitness de relojes inteligentes, contenido de vídeo en Youtube, telemetría de dispositivos inteligentes y la lista. sucede. Esta abundancia de datos tanto en formato estructurado como no estructurado nos ha hecho aterrizar en un campo llamado Data Mining.
Extracción de Información es el proceso de descubrir patrones, anomalías y correlaciones a partir de grandes conjuntos de datos para predecir un resultado. Si bien las técnicas de minería de datos se pueden aplicar a cualquier forma de datos, una de esas ramas de la minería de datos es Extracción de textos que se refiere a encontrar información significativa a partir de datos textuales no estructurados. En este artículo, me centraré en una tarea común en minería de textos para encontrar similitudes de documentos.
Similitud de documentos ayuda en la recuperación eficiente de información. Las aplicaciones de la similitud de documentos incluyen: detectar plagio, responder consultas de búsqueda web de manera efectiva, agrupar artículos de investigación por tema, encontrar artículos de noticias similares, agrupar preguntas similares en un sitio de preguntas y respuestas como Quora, StackOverflow, Reddit y agrupar productos en Amazon según la descripción. , etc. Empresas como DropBox y Google Drive también utilizan la similitud de documentos para evitar almacenar copias duplicadas del mismo documento, ahorrando así tiempo de procesamiento y costos de almacenamiento.
Hay varios pasos para calcular la similitud de documentos. El primer paso es representar el documento en formato vectorial. Luego podemos usar funciones de similitud por pares en estos vectores. Una función de similitud es una función que calcula el grado de similitud entre un par de vectores. Hay varias funciones de similitud por pares, como: distancia euclidiana, similitud del coseno, similitud de Jaccard, correlación de Pearson, correlación de Spearman, Tau de Kendall, etc. Se puede aplicar una función de similitud por pares a dos documentos, dos consultas de búsqueda o entre un documento y una consulta de búsqueda. Si bien las funciones de similitud por pares son adecuadas para comparar una cantidad menor de documentos, existen otras técnicas más avanzadas, como Doc2Vec, BERT, que se basan en técnicas de aprendizaje profundo y son utilizadas por motores de búsqueda como Google para una recuperación eficiente de información basada en la consulta de búsqueda. En este artículo, me centraré en la similitud de Jaccard, la distancia euclidiana, la similitud del coseno y la similitud del coseno con TF-IDF, Doc2Vec y BERT.
Preprocesamiento
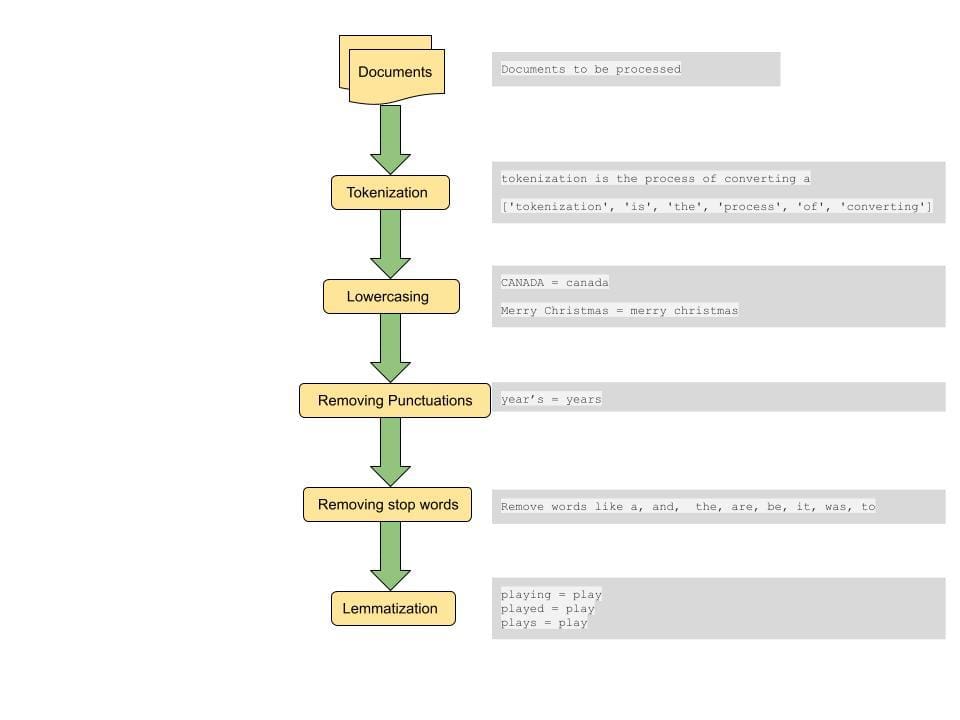
Un paso común para calcular la distancia entre documentos o las similitudes entre documentos es realizar algún procesamiento previo en el documento. El paso de preprocesamiento incluye convertir todo el texto a minúsculas, tokenizar el texto, eliminar palabras vacías, eliminar puntuaciones y lematizar palabras[4].
Tokenización: Este paso implica dividir las oraciones en unidades más pequeñas para su procesamiento. Un token es el átomo léxico más pequeño en el que se puede dividir una oración. Una oración se puede dividir en tokens usando un espacio como delimitador. Esta es una forma de tokenizar. Por ejemplo, una oración de la forma "la tokenización es un paso realmente interesante" se divide en tokens de la forma ['tokenización', 'es', a, 'realmente', 'genial', 'paso']. Estos tokens forman los componentes básicos de la minería de textos y son uno de los primeros pasos en el modelado de datos textuales.
Minúsculas: Si bien puede ser necesario conservar los casos en algunos casos especiales, en la mayoría de los casos queremos tratar las palabras con mayúsculas diferentes como una sola. Este paso es importante para obtener resultados consistentes a partir de un gran conjunto de datos. Por ejemplo, si un usuario busca la palabra "india", queremos recuperar documentos relevantes que contengan palabras en mayúsculas y minúsculas diferentes, ya sea como "India", "INDIA" e "india" si son relevantes para la consulta de búsqueda.
Eliminación de puntuaciones: Eliminar los signos de puntuación y los espacios en blanco ayuda a centrar la búsqueda en palabras y símbolos importantes.
Eliminación de palabras vacías: Las palabras vacías son un conjunto de palabras que se usan comúnmente en el idioma inglés y la eliminación de dichas palabras puede ayudar a recuperar documentos que coincidan con palabras más importantes que transmiten el contexto de la consulta. Esto también ayuda a reducir el tamaño del vector de características, lo que ayuda con el tiempo de procesamiento.
Lematización: La lematización ayuda a reducir la escasez al asignar palabras a su palabra raíz. Por ejemplo, "Plays", "Played" y "Playing" están todos asignados para jugar. Al hacer esto, también reducimos el tamaño del conjunto de características y hacemos coincidir todas las variaciones de una palabra en diferentes documentos para mostrar el documento más relevante.
Este método es uno de los más sencillos. Tokeniza las palabras y calcula la suma del recuento de los términos compartidos con la suma del número total de términos en ambos documentos. Si los dos documentos son similares la puntuación es uno, si los dos documentos son diferentes la puntuación es cero [3].
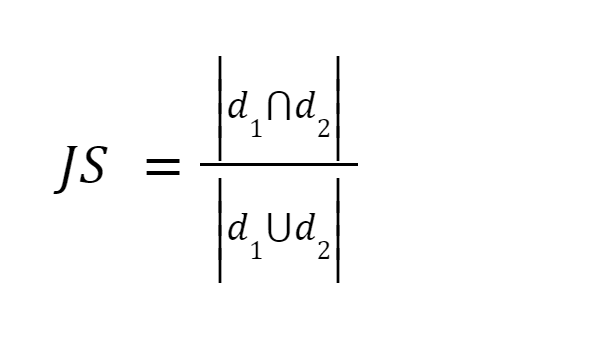
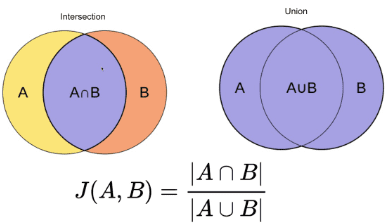
Fuente de la imagen: O'Reilly
Resumen: Este método tiene algunos inconvenientes. A medida que aumenta el tamaño del documento, aumentará el número de palabras comunes, aunque los dos documentos sean semánticamente diferentes.
Después de preprocesar el documento, lo convertimos en un vector. El peso del vector puede ser la frecuencia del término donde contamos el número de veces que el término aparece en el documento, o puede ser la frecuencia relativa del término donde calculamos la relación entre el recuento del término y el número total de términos. en el documento [3].
Sean d1 y d2 dos documentos representados como vectores de n términos (que representan n dimensiones); Luego podemos calcular la distancia más corta entre dos documentos usando el teorema de Pitágoras para encontrar una línea recta entre dos vectores. Cuanto mayor es la distancia, menor es la similitud; cuanto menor es la distancia, mayor es la similitud entre dos documentos.
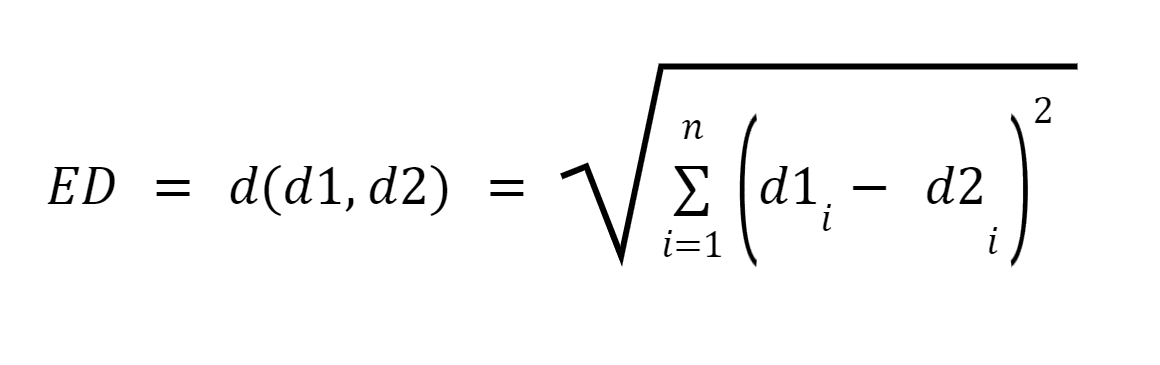
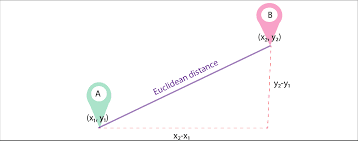
Fuente de la imagen: Medium.com
Resumen: El principal inconveniente de este enfoque es que cuando los documentos difieren en tamaño, la distancia euclidiana dará una puntuación más baja aunque los dos documentos sean de naturaleza similar. Los documentos más pequeños darán como resultado vectores con una magnitud más pequeña y los documentos más grandes darán como resultado vectores con una magnitud mayor, ya que la magnitud del vector es directamente proporcional al número de palabras en el documento, lo que hace que la distancia total sea mayor.
La similitud del coseno mide la similitud entre documentos midiendo el coseno del ángulo entre los dos vectores. Los resultados de similitud del coseno pueden tomar valores entre 0 y 1. Si los vectores apuntan en la misma dirección, la similitud es 1, si los vectores apuntan en direcciones opuestas, la similitud es 0. [6].
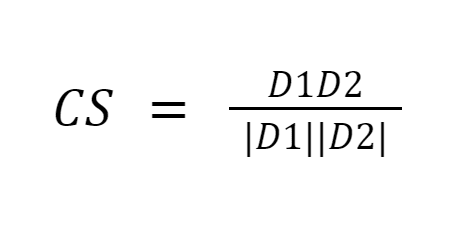
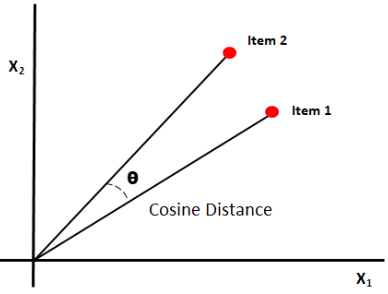
Fuente de la imagen: Medium.com
Resumen: Lo bueno de la similitud del coseno es que calcula la orientación entre vectores y no la magnitud. Por lo tanto, capturará la similitud entre dos documentos que son similares a pesar de tener diferentes tamaños.
El inconveniente fundamental de los tres enfoques anteriores es que la medición no permite encontrar documentos similares mediante semántica. Además, todas estas técnicas sólo se pueden realizar en parejas, por lo que se requieren más comparaciones.
Este método para encontrar similitudes de documentos se utiliza en implementaciones de búsqueda predeterminadas de ElasticSearch y existe desde 1972 [4]. tf-idf significa frecuencia de documento inversa de frecuencia. Primero calculamos el término frecuencia usando esta fórmula.
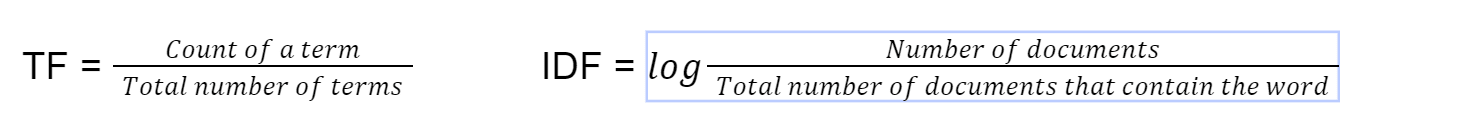
Finalmente calculamos tf-idf multiplicando TF*IDF. Luego usamos similitud de coseno en el vector con tf-idf como peso del vector.
Resumen: Multiplicar el término frecuencia por la frecuencia inversa del documento ayuda a compensar algunas palabras que aparecen con más frecuencia en general en todos los documentos y a centrarse en palabras que son diferentes entre documentos. Esta técnica ayuda a encontrar documentos que coincidan con una consulta de búsqueda al centrar la búsqueda en palabras clave importantes.
Aunque usar palabras individuales (BOW – Bolsa de palabras) de documentos para convertir a vectores puede ser más fácil de implementar, no le da ninguna importancia al orden de las palabras en una oración. Doc2Vec está construido sobre Word2Vec. Mientras que Word2Vec representa el significado de una palabra, Doc2Vec representa el significado de un documento o párrafo [5].
Este método se utiliza para convertir un documento en su representación vectorial preservando al mismo tiempo el significado semántico del documento. Este enfoque convierte textos de longitud variable, como oraciones, párrafos o documentos, en vectores [5]. Luego se entrena el modo doc2vec. El entrenamiento de los modelos es similar al entrenamiento de otros modelos de aprendizaje automático: seleccionando conjuntos de entrenamiento y documentos de conjuntos de prueba y ajustando los parámetros de ajuste para lograr mejores resultados.
Resumen: Esta forma vectorizada del documento conserva el significado semántico del documento, ya que los párrafos con contexto o significado similar estarán más juntos durante la conversión a vector.
BERT es un modelo de aprendizaje automático basado en transformadores utilizado en tareas de PNL, desarrollado por Google.
Con la llegada de BERT (Representaciones de codificador bidireccional de Transformers), los modelos de PNL se entrenan con corpus de texto enormes y sin etiquetar que analizan un texto tanto de derecha a izquierda como de izquierda a derecha. BERT utiliza una técnica llamada "Atención" para mejorar los resultados. La clasificación de búsqueda de Google mejoró por un margen enorme después de usar BERT [4]. Algunas de las características únicas de BERT incluyen
- Pre-capacitado con artículos de Wikipedia de 104 idiomas.
- Mira el texto de izquierda a derecha y de derecha a izquierda.
- Ayuda a comprender el contexto.
Resumen: Como resultado, BERT se puede ajustar para muchas aplicaciones, como respuesta a preguntas, parafraseo de oraciones, clasificador de spam y detector de lenguaje de compilación, sin modificaciones sustanciales de la arquitectura específica de la tarea.
Fue fantástico aprender cómo se utilizan las funciones de similitud para encontrar similitudes en documentos. Actualmente, depende del desarrollador elegir la función de similitud que mejor se adapte al escenario. Por ejemplo, tf-idf es actualmente el estado del arte para hacer coincidir documentos, mientras que BERT es el estado del arte para búsquedas de consultas. Sería fantástico crear una herramienta que detecte automáticamente qué función de similitud es más adecuada según el escenario y así elegir una función de similitud que esté optimizada para la memoria y el tiempo de procesamiento. Esto podría ser de gran ayuda en escenarios como la comparación automática de currículums con descripciones de trabajo, agrupación de documentos por categoría, clasificación de pacientes en diferentes categorías según los registros médicos de los pacientes, etc.
En este artículo, cubrí algunos algoritmos notables para calcular la similitud de documentos. De ninguna manera es una lista exhaustiva. Existen varios otros métodos para encontrar similitudes de documentos y la decisión de elegir el correcto depende del escenario y caso de uso particular. Los métodos estadísticos simples como tf-idf, Jaccard, Euclidien y la similitud de coseno son muy adecuados para casos de uso más simples. Se puede configurar fácilmente con las bibliotecas existentes disponibles en Python, R y calcular la puntuación de similitud sin requerir máquinas pesadas ni capacidades de procesamiento. Algoritmos más avanzados como BERT dependen de redes neuronales preentrenadas que pueden llevar horas pero producen resultados eficientes para análisis que requieren comprensión del contexto del documento.
Referencia
[1] Heidarian, A. y Dinneen, M. J. (2016). Un enfoque geométrico híbrido para medir el nivel de similitud entre documentos y agrupación de documentos. Segunda Conferencia Internacional IEEE 2016 sobre Servicios y Aplicaciones de Computación de Big Data (BigDataService), 1-5. https://doi.org/10.1109/bigdataservice.2016.14
[2] Kavitha Karun A, Philip, M. y Lubna, K. (2013). Análisis comparativo de medidas de similitud en la agrupación de documentos. 2013 Conferencia Internacional sobre Computación, Comunicación y Conservación de Energía Verdes (ICGCE), 1-4. https://doi.org/10.1109/icgce.2013.6823554
[3] Lin, Y.-S., Jiang, J.-Y. y Lee, S.-J. (2014). Una medida de similitud para la clasificación y agrupación de textos. Transacciones de IEEE sobre conocimiento e ingeniería de datos, 26(7), 1575-1590. https://doi.org/10.1109/tkde.2013.19
[4] Nishimura, M. (2020 de septiembre de 9). El mejor algoritmo de similitud de documentos en 2020: una guía para principiantes: hacia la ciencia de datos. Medio. https://towardsdatascience.com/the-best-document-similarity-algorithm-in-2020-a-beginners-guide-a01b9ef8cf05
[5] Sharaki, O. (2020 de julio de 10). Detección de similitudes de documentos con Doc2vec: hacia la ciencia de datos. Medio. https://towardsdatascience.com/detecting-document-similarity-with-doc2vec-f8289a9a7db7
[6] Lüthe, M. (2019 de noviembre de 18). Calcule la similitud: las métricas más relevantes en pocas palabras: hacia la ciencia de datos. Medio. https://towardsdatascience.com/calculate-similarity-the-most-relevant-metrics-in-a-nutshell-9a43564f533e
[7] S. (2019 de octubre de 27). Medidas de similitud: puntuación de artículos textuales: hacia la ciencia de datos. Medio. https://towardsdatascience.com/similarity-measures-e3dbd4e58660
Poornima Muthukumar es gerente técnico senior de productos en Microsoft con más de 10 años de experiencia en el desarrollo y entrega de soluciones innovadoras para diversos dominios, como computación en la nube, inteligencia artificial, sistemas distribuidos y de big data. Tengo una Maestría en Ciencia de Datos de la Universidad de Washington. Tengo cuatro Patentes en Microsoft especializadas en AI/ML y Big Data Systems y fui el ganador del Global Hackathon en 2016 en la Categoría de Inteligencia Artificial. Tuve el honor de estar en el panel de revisión de la Conferencia Grace Hopper para la categoría Ingeniería de Software este año 2023. Fue una experiencia gratificante leer y evaluar las presentaciones de mujeres talentosas en estos campos y contribuir también al avance de las mujeres en la tecnología. para aprender de sus investigaciones y conocimientos. También fui miembro del comité de la conferencia de junio de 2023 de Microsoft Machine Learning AI and Data Science (MLADS). También soy embajadora de la comunidad mundial de mujeres en la ciencia de datos y de la comunidad de mujeres que codifican la ciencia de datos.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.kdnuggets.com/evaluating-methods-for-calculating-document-similarity?utm_source=rss&utm_medium=rss&utm_campaign=evaluating-methods-for-calculating-document-similarity

