A medida que las empresas se expanden, la demanda de direcciones IP dentro de la red corporativa a menudo supera la oferta. La red de una organización a menudo se diseña con cierta anticipación a los requisitos futuros, pero a medida que las empresas evolucionan, sus necesidades de tecnología de la información (TI) superan las de la red diseñada previamente. Las empresas pueden verse desafiadas a la hora de gestionar el conjunto limitado de direcciones IP.
Para cargas de trabajo de ingeniería de datos cuando Pegamento AWS se utiliza en una configuración de red tan restringida, su equipo a veces puede enfrentar obstáculos al ejecutar muchos trabajos simultáneamente. Esto sucede porque es posible que no tenga suficientes direcciones IP para admitir las conexiones necesarias a las bases de datos. Para superar esta escasez, el equipo puede obtener más direcciones IP de su grupo de redes corporativas. Estas direcciones IP obtenidas pueden ser únicas (no superpuestas) o superpuestas, cuando las direcciones IP se reutilizan en su red corporativa.
Cuando utiliza direcciones IP superpuestas, necesita una administración de red adicional para establecer la conectividad. Las soluciones de red pueden incluir opciones como puertas de enlace privadas de traducción de direcciones de red (NAT), Enlace privado de AWSo dispositivos NAT autoadministrados para traducir direcciones IP.
En esta publicación, analizaremos dos estrategias para escalar los trabajos de AWS Glue:
- Optimizar el consumo de direcciones IP ajustando el tamaño de las Unidades de procesamiento de datos (DPU), utilizando la función Auto Scaling de AWS Glue y ajustando los trabajos.
- Ampliar la capacidad de la red utilizando un rango adicional de enrutamiento entre dominios sin clase (CIDR) no enrutable con una puerta de enlace NAT privada.
Antes de profundizar en estas soluciones, comprendamos cómo utiliza AWS Glue Interfaz de red elástica (ENI) para establecer la conectividad. Para habilitar el acceso a los almacenes de datos dentro de una VPC, debe crear una conexión de AWS Glue conectada a su VPC. Cuando se ejecuta un trabajo de AWS Glue en su VPC, el trabajo crea una ENI dentro de la VPC configurada para cada conexión de datos, y esa ENI utiliza una dirección IP en la VPC especificada. Estos ENI son de corta duración y están activos hasta que se completa el trabajo.
Ahora veamos la primera solución que explica la optimización del consumo de direcciones IP de AWS Glue.
Estrategias para un consumo eficiente de direcciones IP
En AWS Glue, la cantidad de trabajadores que utiliza un trabajo determina el recuento de direcciones IP utilizadas desde su subred de VPC. Esto se debe a que cada trabajador requiere una dirección IP que se asigne a un ENI. Cuando no tiene suficiente rango CIDR asignado a la subred de AWS Glue, es posible que observe errores de agotamiento de direcciones IP. Las siguientes son algunas de las mejores prácticas para optimizar el consumo de direcciones IP de AWS Glue:
- Ajustar el tamaño de las DPU del trabajo: AWS Glue es un motor de procesamiento distribuido. Funciona de manera eficiente cuando puede ejecutar tareas en paralelo. Si un trabajo tiene más DPU de las requeridas, no siempre se ejecuta más rápido. Por lo tanto, encontrar la cantidad correcta de DPU garantizará que utilice las direcciones IP de manera óptima. Al generar observabilidad en el sistema y analizar el desempeño del trabajo, puede obtener información sobre las tendencias de consumo de ENI y luego configurar la capacidad adecuada en el trabajo para el tamaño correcto. Para obtener más detalles, consulte Monitoreo para la planificación de capacidad de DPU. La interfaz de usuario de Spark es una herramienta útil para monitorear el uso de los trabajadores de los trabajos de AWS Glue. Para obtener más detalles, consulte Supervisión de trabajos mediante la interfaz de usuario web de Apache Spark.
- AWS Glue Auto Scaling: a menudo es difícil predecir de antemano los requisitos de capacidad de un trabajo. Habilitar la función Auto Scaling de AWS Glue descargará parte de esta responsabilidad a AWS. En tiempo de ejecución, según los requisitos de la carga de trabajo, el trabajo escala automáticamente los nodos trabajadores hasta la configuración máxima definida. Si no hay ninguna necesidad adicional, AWS Glue no aprovisionará trabajadores en exceso, lo que ahorrará recursos y reducirá costos. La función Auto Scaling está disponible en AWS Glue 3.0 y versiones posteriores. Para obtener más información, consulte Presentamos AWS Glue Auto Scaling: cambie automáticamente el tamaño de los recursos informáticos sin servidor a un menor costo con Apache Spark optimizado.
- Optimización a nivel de trabajo: identifique optimizaciones a nivel de trabajo mediante el uso Métricas de trabajo de AWS Glue y aplicar las mejores prácticas de Mejores prácticas para ajustar el rendimiento de trabajos de AWS Glue para Apache Spark.
A continuación, veamos la segunda solución que elabora la expansión de la capacidad de la red.
Soluciones para la expansión del tamaño de la red (dirección IP)
En esta sección, analizaremos dos posibles soluciones para ampliar el tamaño de la red con más detalle.
Amplíe los rangos de CIDR de VPC con direcciones enrutables
Una solución es agregar más rangos de CIDR IPv4 privados desde RFC 1918 a su VPC. En teoría, cada cuenta de AWS se puede asignar a algunos o todos estos CIDR de direcciones IP. Su equipo de administración de direcciones IP (IPAM) a menudo administra la asignación de direcciones IP que cada unidad de negocios puede usar desde RFC1918 para evitar la superposición de direcciones IP entre múltiples cuentas o unidades de negocios de AWS. Si su cuota actual de direcciones IP enrutables asignada por el equipo de IPAM no es suficiente, puede solicitar más.
Si su equipo de IPAM le emite un rango de CIDR adicional que no se superponga, puede agregarlo como CIDR secundario a su VPC existente o crear una nueva VPC con él. Si planea crear una nueva VPC, puede interconectar las VPC a través de Emparejamiento de VPC or Pasarela de tránsito de AWS.
Si esta capacidad adicional es suficiente para ejecutar todos sus trabajos dentro del plazo definido, entonces es una solución simple y rentable. De lo contrario, puede considerar adoptar direcciones IP superpuestas con una puerta de enlace NAT privada, como se describe en la siguiente sección. Con la siguiente solución, debe utilizar Transit Gateway para conectar VPC, ya que el emparejamiento de VPC no es posible cuando hay rangos de CIDR superpuestos en esas dos VPC.
Configure CIDR no enrutable con una puerta de enlace NAT privada
Como se describe en el documento técnico de AWS Creación de una infraestructura de red AWS multi-VPC escalable y segura, puede ampliar la capacidad de su red creando una subred de direcciones IP no enrutables y utilizando una puerta de enlace NAT privada ubicada en un espacio de direcciones IP enrutables (que no se superpongan) para enrutar el tráfico. Una puerta de enlace NAT privada traduce y enruta el tráfico entre direcciones IP no enrutables y direcciones IP enrutables. El siguiente diagrama muestra la solución con referencia a AWS Glue.
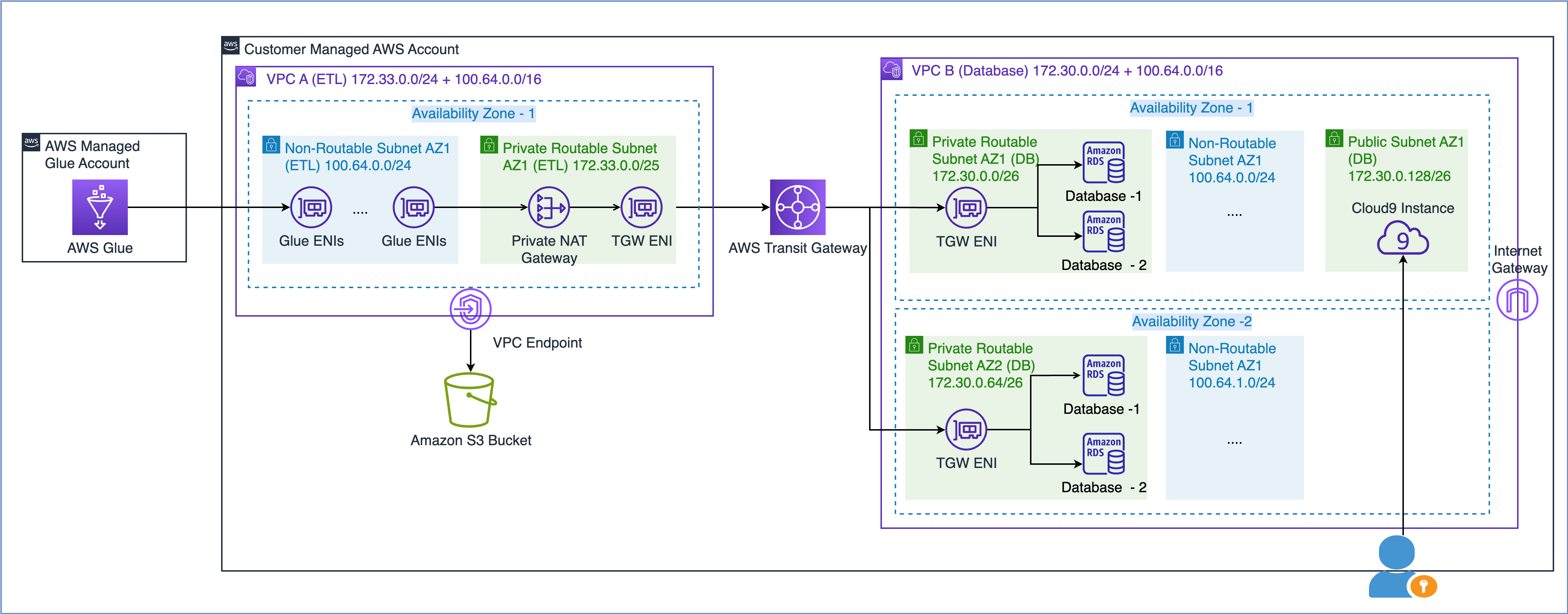
Como puede ver en el diagrama anterior, VPC A (ETL) tiene dos rangos CIDR adjuntos. El rango de CIDR más pequeño, 172.33.0.0/24, es enrutable porque no se reutiliza en ningún lugar, mientras que el rango de CIDR más grande, 100.64.0.0/16, no es enrutable porque se reutiliza en la VPC de la base de datos.
En VPC B (Base de datos), hemos alojado dos bases de datos en las subredes enrutables 172.30.0.0/26 y 172.30.0.64/26. Estas dos subredes están en dos zonas de disponibilidad separadas para alta disponibilidad. También tenemos dos subredes adicionales no utilizadas, 100.64.0.0/24 y 100.64.1.0/24, para simular una configuración no enrutable.
Puede elegir el tamaño del rango CIDR no enrutable según sus requisitos de capacidad. Como puede reutilizar direcciones IP, puede crear una subred muy grande según sea necesario. Por ejemplo, una máscara CIDR de /16 le daría aproximadamente 65,000 direcciones IPv4. Puede trabajar con su equipo de ingeniería de redes y dimensionar las subredes.
En resumen, puede configurar trabajos de AWS Glue para utilizar subredes enrutables y no enrutables en su VPC para maximizar el grupo de direcciones IP disponibles.
Ahora comprendamos cómo las ENI de Glue que se encuentran en una subred no enrutable se comunican con fuentes de datos en otra VPC.
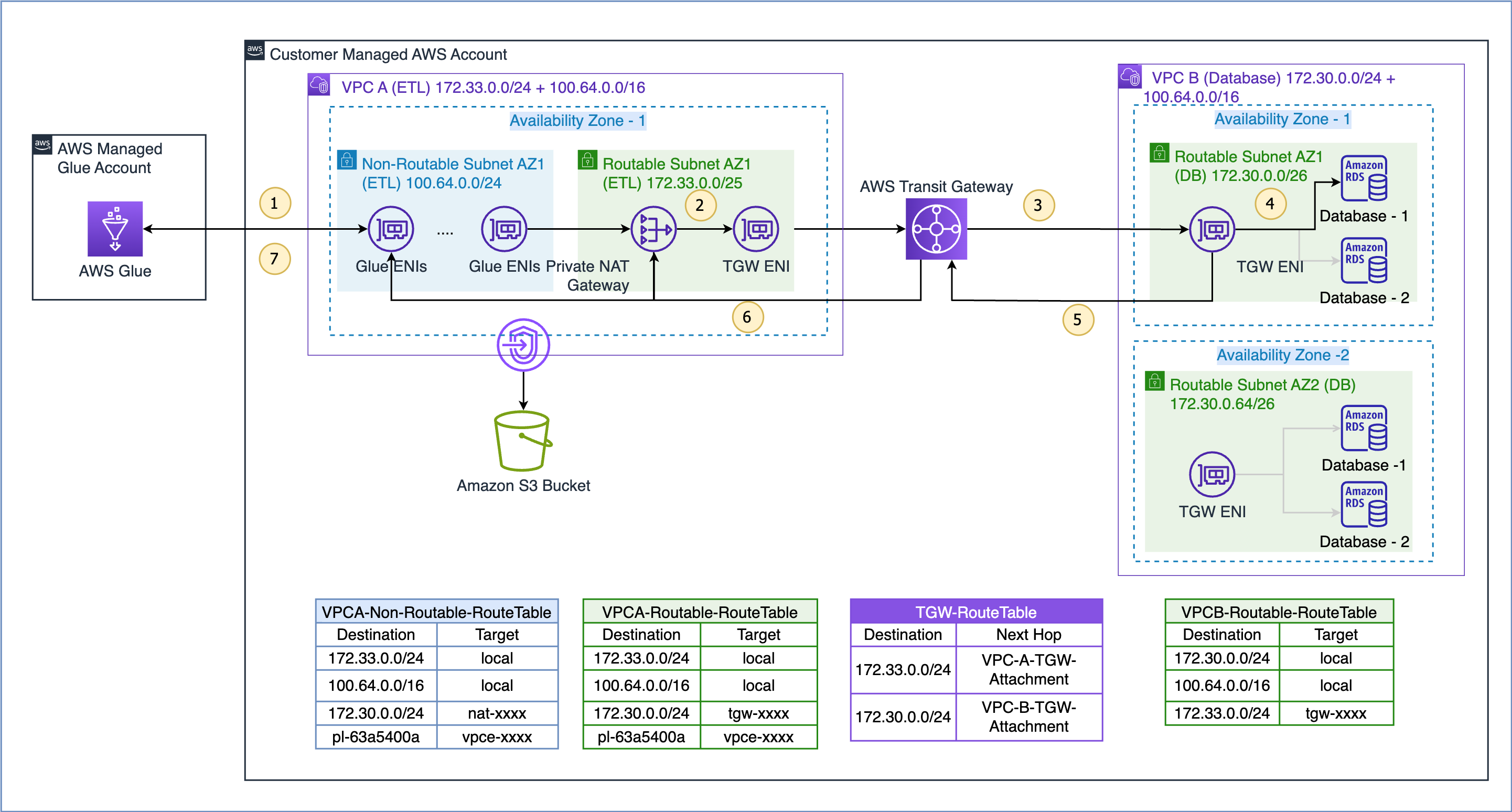
El flujo de datos para el caso de uso que se muestra aquí es el siguiente (con referencia a los pasos numerados en la figura anterior):
- Cuando un trabajo de AWS Glue necesita acceder a una fuente de datos, primero utiliza la conexión de AWS Glue en el trabajo y crea los ENI en la subred no enrutable 100.64.0.0/24 en la VPC A. Posteriormente, AWS Glue utiliza la configuración de conexión de la base de datos y intenta conectarse a la base de datos en VPC B 172.30.0.0/24.
- Según la tabla de rutas
VPCA-Non-Routable-RouteTableel destino 172.30.0.0/24 está configurado para una puerta de enlace NAT privada. La solicitud se envía a la puerta de enlace NAT, que luego traduce la dirección IP de origen de una dirección IP no enrutable a una dirección IP enrutable. Luego, el tráfico se envía al archivo adjunto de la puerta de enlace de tránsito en la VPC A porque está asociado con elVPCA-Routable-RouteTabletabla de rutas en la VPC A. - Transit Gateway utiliza la ruta 172.30.0.0/24 y envía el tráfico al archivo adjunto de la puerta de enlace de tránsito VPC B.
- La puerta de enlace de tránsito ENI en la VPC B utiliza la ruta local de la VPC B para conectarse al punto final de la base de datos y consultar los datos.
- Cuando se completa la consulta, la respuesta se envía de vuelta a la VPC A. El tráfico de respuesta se enruta al archivo adjunto de la puerta de enlace de tránsito en la VPC B, luego Transit Gateway utiliza la ruta 172.33.0.0/24 y envía el tráfico al archivo adjunto de la puerta de enlace de tránsito de la VPC A. .
- La puerta de enlace de tránsito ENI en la VPC A utiliza la ruta local para reenviar el tráfico a la puerta de enlace NAT privada, que traduce la dirección IP de destino a la de las ENI en la subred no enrutable.
- Finalmente, el trabajo de AWS Glue recibe los datos y continúa procesándolos.
La solución de puerta de enlace NAT privada es una opción si necesita direcciones IP adicionales cuando no puede obtenerlas de una red enrutable de su organización. A veces, con cada servicio adicional se incurre en un costo adicional y esta compensación es necesaria para alcanzar sus objetivos. Consulte la sección de precios de NAT Gateway en la página Página de precios de Amazon VPC para obtener más información.
Requisitos previos
Para completar el recorrido por la solución de puerta de enlace NAT privada, necesita lo siguiente:
Implementar la solución
Para implementar la solución, complete los siguientes pasos:
- Inicie sesión en su consola de administración de AWS.
- Implemente la solución haciendo clic
 . Esta pila por defecto es
. Esta pila por defecto es us-east-1, puede seleccionar la región que desee. - Haga Clic en Next y luego especifique los detalles de la pila. Puede conservar los parámetros de entrada con los valores predeterminados precargados o cambiarlos según sea necesario.
-
DatabaseUserPassword, ingrese una contraseña alfanumérica de su elección y asegúrese de anotarla para su uso posterior. -
S3BucketName, introduce un único Servicio de almacenamiento simple de Amazon (Amazon S3) nombre del depósito. Este depósito almacena el script de trabajo de AWS Glue que se copiará de un repositorio de código público de AWS.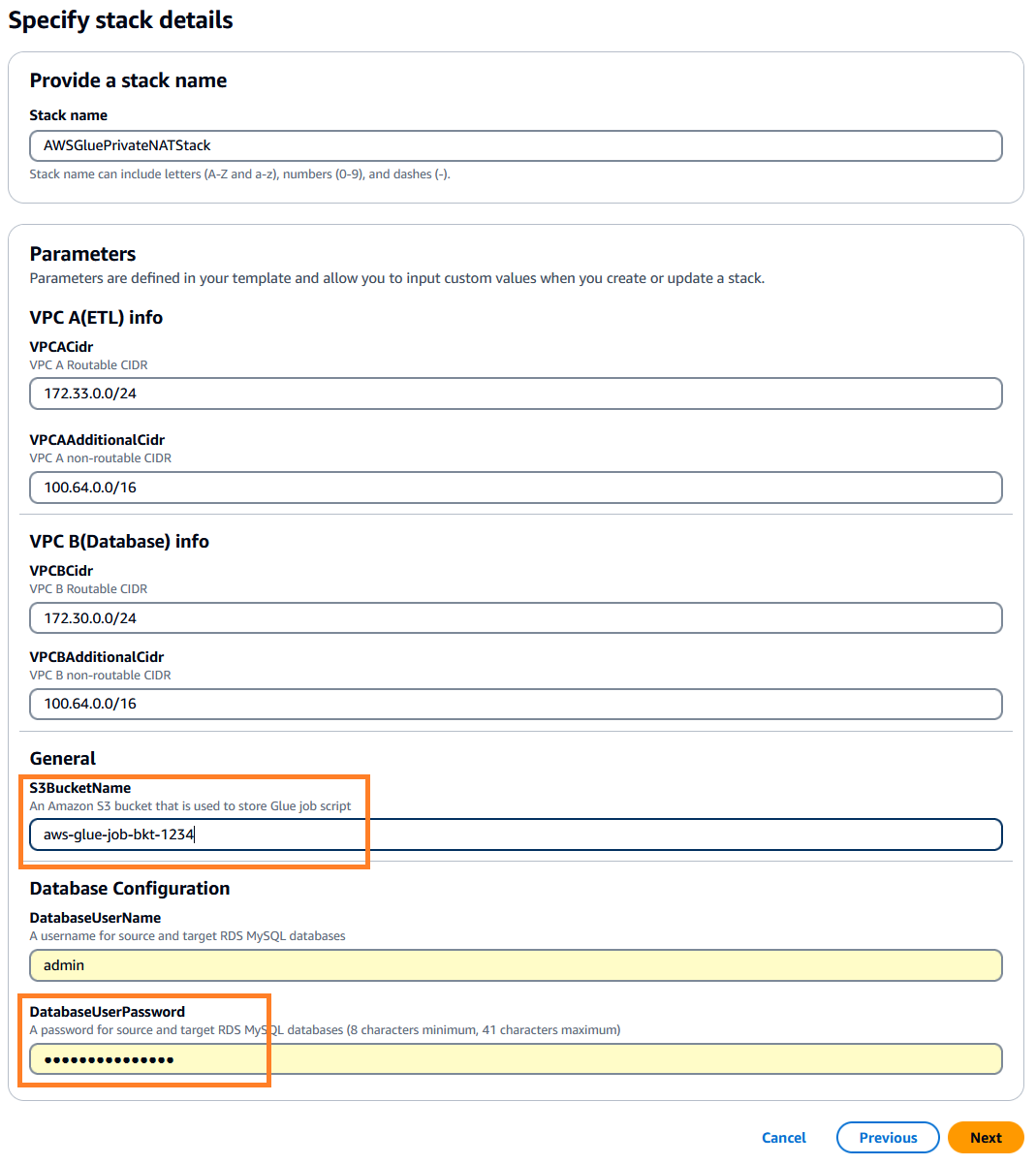
- Haga Clic en Next.
- Deje los valores predeterminados y haga clic Next de nuevo.
- Revise los detalles, reconozca la creación de recursos de IAM y haga clic en enviar para iniciar la implementación.
Puede monitorear los eventos para ver los recursos que se crean en la consola de AWS CloudFormation. La creación de los recursos de la pila puede tardar unos 20 minutos.
Una vez completada la creación de la pila, vaya a la pestaña Salidas en la consola de AWS CloudFormation y anote los siguientes valores para su uso posterior:
DBSourceDBTargetSourceCrawlerTargetCrawler
Conéctese a una instancia de AWS Cloud9
A continuación, debemos preparar las tablas de origen y de destino de Amazon RDS para MySQL mediante un Nube de AWS9 instancia. Complete los siguientes pasos:
- En la página de la consola de AWS Cloud9, busque el
aws-glue-cloud9ambiente. - En la columna Cloud9 IDE, haga clic en Abierto para iniciar su instancia de AWS Cloud9 en un nuevo navegador web.
Prepare la tabla MySQL fuente
Complete los siguientes pasos para preparar su tabla fuente:
- Desde la terminal AWS Cloud9, instale el cliente MySQL usando el siguiente comando:
sudo yum update -y && sudo yum install -y mysql - Conéctese a la base de datos de origen usando el siguiente comando. Reemplace el nombre de host de origen con el valor DBSource que capturó anteriormente. Cuando se le solicite, ingrese la contraseña de la base de datos que especificó durante la creación de la pila.
mysql -h <Source Hostname> -P 3306 -u admin -p - Ejecute los siguientes scripts para crear la fuente
emptabla y cargue los datos de prueba:-- connect to source database USE srcdb; -- Drop emp table if it exists DROP TABLE IF EXISTS emp; -- Create the emp table CREATE TABLE emp (empid INT AUTO_INCREMENT, ename VARCHAR(100) NOT NULL, edept VARCHAR(100) NOT NULL, PRIMARY KEY (empid)); -- Create a stored procedure to load sample records into emp table DELIMITER $$ CREATE PROCEDURE sp_load_emp_source_data() BEGIN DECLARE empid INT; DECLARE ename VARCHAR(100); DECLARE edept VARCHAR(50); DECLARE cnt INT DEFAULT 1; -- Initialize counter to 1 to auto-increment the PK DECLARE rec_count INT DEFAULT 1000; -- Initialize sample records counter TRUNCATE TABLE emp; -- Truncate the emp table WHILE cnt <= rec_count DO -- Loop and load the required number of sample records SET ename = CONCAT('Employee_', FLOOR(RAND() * 100) + 1); -- Generate random employee name SET edept = CONCAT('Dept_', FLOOR(RAND() * 100) + 1); -- Generate random employee department -- Insert record with auto-incrementing empid INSERT INTO emp (ename, edept) VALUES (ename, edept); -- Increment counter for next record SET cnt = cnt + 1; END WHILE; COMMIT; END$$ DELIMITER ; -- Call the above stored procedure to load sample records into emp table CALL sp_load_emp_source_data(); - Verifica la fuente
emprecuento de la tabla utilizando la siguiente consulta SQL (necesitará esto en un paso posterior para la verificación).select count(*) from emp; - Ejecute el siguiente comando para salir de la utilidad del cliente MySQL y regresar a la terminal de la instancia de AWS Cloud9:
quit;
Prepare la tabla MySQL de destino
Complete los siguientes pasos para preparar la tabla de destino:
- Conéctese a la base de datos de destino usando el siguiente comando. Reemplace el nombre de host de destino con el valor de DBObjetivo que capturó anteriormente. Cuando se le solicite, ingrese la contraseña de la base de datos que especificó durante la creación de la pila.
mysql -h <Target Hostname> -P 3306 -u admin -p - Ejecute los siguientes scripts para crear el objetivo
empmesa. Esta tabla será cargada por el trabajo de AWS Glue en el paso siguiente.-- connect to the target database USE targetdb; -- Drop emp table if it exists DROP TABLE IF EXISTS emp; -- Create the emp table CREATE TABLE emp (empid INT AUTO_INCREMENT, ename VARCHAR(100) NOT NULL, edept VARCHAR(100) NOT NULL, PRIMARY KEY (empid) );
Verificar la configuración de red (opcional)
Los siguientes pasos son útiles para comprender la puerta de enlace NAT, las tablas de rutas y las configuraciones de la puerta de enlace de tránsito de la solución de puerta de enlace NAT privada. Estos componentes se crearon durante la creación de la pila de CloudFormation.
- En la página de la consola de Amazon VPC, navegue hasta la sección Nube privada virtual y localice las puertas de enlace NAT.
- Buscar puerta de enlace NAT con nombre
Glue-OverlappingCIDR-NATGWy explorarlo más a fondo. Como puede ver en la siguiente captura de pantalla, la puerta de enlace NAT se creó en la VPC A (ETL) en la subred enrutable.
- En el panel de navegación del lado izquierdo, navegue hasta Tablas de ruta en la sección de nube privada virtual.
- Busque
VPCA-Non-Routable-RouteTabley explorarlo más a fondo. Puede ver que la tabla de rutas está configurada para traducir el tráfico de CIDR superpuesto mediante la puerta de enlace NAT.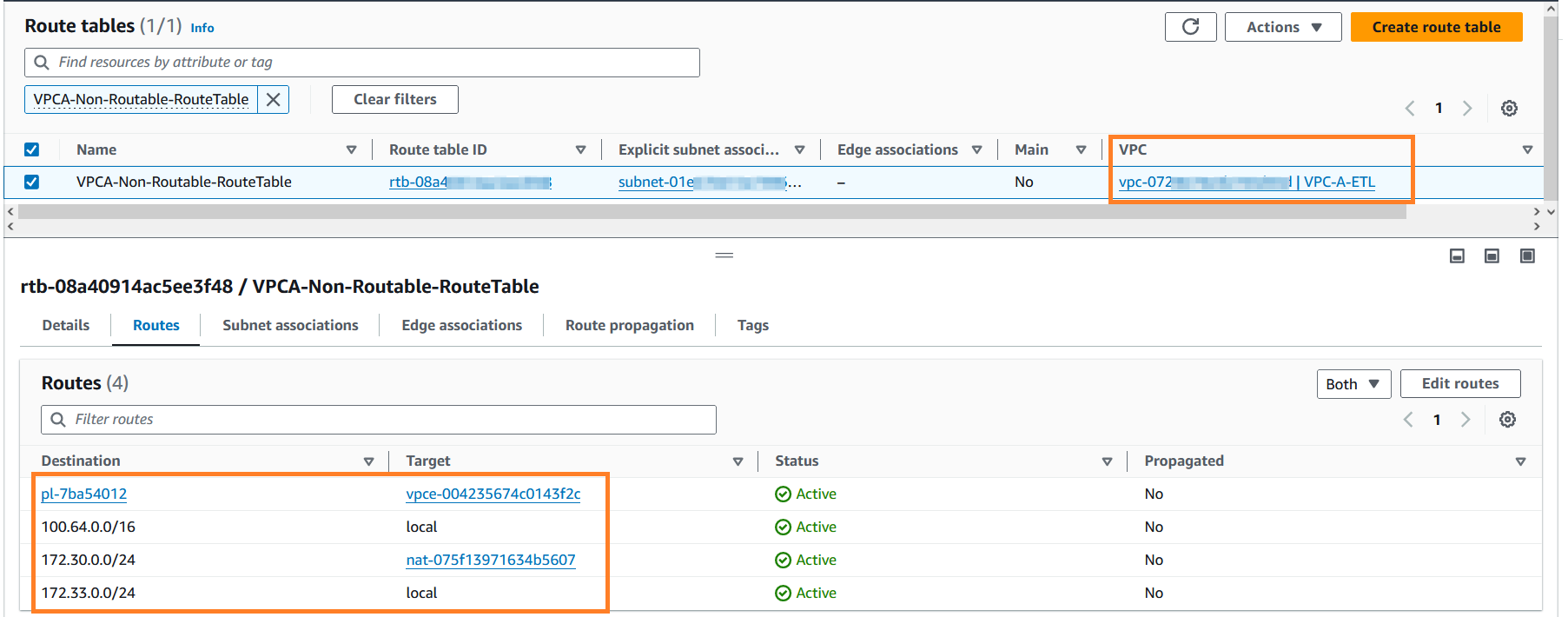
- En el panel de navegación del lado izquierdo, navegue hasta la sección Puertas de enlace de Transit y haga clic en Archivos adjuntos de la puerta de enlace de Transit. Ingresar
VPC-en el cuadro de búsqueda y localice los dos archivos adjuntos de puerta de enlace de tránsito recién creados. - Puede explorar estos archivos adjuntos más a fondo para conocer sus configuraciones.
Ejecute los rastreadores de AWS Glue
Complete los siguientes pasos para ejecutar los rastreadores de AWS Glue necesarios para catalogar el origen y el destino. emp mesas. Este es un paso previo para ejecutar el trabajo de AWS Glue.
- En la página de la consola de AWS Glue, en la sección Catálogo de datos del panel de navegación, haga clic en Rastreadores.
- Localice los rastreadores de origen y de destino que anotó anteriormente.
- Seleccione estos rastreadores y haga clic Ejecutar para crear las respectivas tablas del catálogo de datos de AWS Glue.
- Puede monitorear los rastreadores de AWS Glue para verificar que se completen exitosamente. Es posible que ambos rastreadores tarden entre 3 y 4 minutos en completarse. Cuando terminan, el estado de la última ejecución del trabajo cambia a Correcto y también puede ver que hay dos tablas del catálogo de AWS Glue creadas a partir de esta ejecución.

Ejecute el trabajo ETL de AWS Glue
Después de configurar las tablas y completar los pasos de requisitos previos, ahora está listo para ejecutar el trabajo de AWS Glue que creó utilizando la plantilla de CloudFormation. Este trabajo se conecta a la base de datos RDS para MySQL de origen, extrae los datos y los carga en la base de datos RDS para MySQL de destino. Este trabajo lee datos de una tabla MySQL de origen y los carga en la tabla MySQL de destino mediante una solución de puerta de enlace NAT privada. Para ejecutar el trabajo de AWS Glue, complete los siguientes pasos:
- En la consola de AWS Glue, haga clic en Empleos de ETL en el panel de navegación.
- Haga clic en el trabajo
glue-private-nat-job. - Haga Clic en Ejecutar para comenzarlo
El siguiente es el script PySpark para este trabajo ETL:
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
args = getResolvedOptions(sys.argv, ["JOB_NAME"])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args["JOB_NAME"], args)
# Script generated for node AWS Glue Data Catalog
AWSGlueDataCatalog_node = glueContext.create_dynamic_frame.from_catalog(
database="glue_cat_db_source",
table_name="srcdb_emp",
transformation_ctx="AWSGlueDataCatalog_node",
)
# Script generated for node Change Schema
ChangeSchema_node = ApplyMapping.apply(
frame=AWSGlueDataCatalog_node,
mappings=[
("empid", "int", "empid", "int"),
("ename", "string", "ename", "string"),
("edept", "string", "edept", "string"),
],
transformation_ctx="ChangeSchema_node",
)
# Script generated for node AWS Glue Data Catalog
AWSGlueDataCatalog_node = glueContext.write_dynamic_frame.from_catalog(
frame=ChangeSchema_node,
database="glue_cat_db_target",
table_name="targetdb_emp",
transformation_ctx="AWSGlueDataCatalog_node",
)
job.commit()
Según la configuración de DPU del trabajo, AWS Glue crea un conjunto de ENI en la subred no enrutable que está configurada en la conexión de AWS Glue. Puede monitorear estos ENI en la página Interfaces de red del Nube informática elástica de Amazon (Amazon EC2) consola.
La siguiente captura de pantalla muestra los 10 ENI que se crearon para la ejecución del trabajo para que coincidan con la cantidad solicitada de trabajadores configurados en los parámetros del trabajo. Como se esperaba, las ENI se crearon en la subred no enrutable de la VPC A, lo que permitió la escalabilidad de las direcciones IP. Una vez completado el trabajo, AWS Glue liberará automáticamente estos ENI.
Cuando el trabajo de AWS Glue se está ejecutando, puede monitorear su estado. Al finalizar exitosamente, el estado del trabajo cambia a logrado.
Verificar los resultados
Una vez completado el trabajo de AWS Glue, conéctese a la base de datos MySQL de destino. Verifique si el recuento de registros de destino coincide con el de origen. Puede utilizar la siguiente consulta SQL en la terminal AWS Cloud9.
USE targetdb;
SELECT count(*) from emp;Finalmente, salga de la utilidad del cliente MySQL usando el siguiente comando y regrese a la terminal AWS Cloud9: quit;
Ahora puede confirmar que AWS Glue ha completado correctamente un trabajo para cargar datos en una base de datos de destino utilizando las direcciones IP de una subred no enrutable. Esto concluye las pruebas de extremo a extremo de la solución de puerta de enlace NAT privada.
Limpiar
Para evitar incurrir en cargos futuros, elimine el recurso creado a través de la pila de CloudFormation completando los siguientes pasos:
- En la consola de AWS CloudFormation, haga clic en Pilas en el panel de navegación.
- Seleccione la pila
AWSGluePrivateNATStack. - Haga clic en Eliminar para eliminar la pila. Cuando se le solicite, confirme la eliminación de la pila.
Conclusión
En esta publicación, demostramos cómo puede escalar los trabajos de AWS Glue optimizando el consumo de direcciones IP y ampliando la capacidad de su red mediante el uso de una solución de puerta de enlace NAT privada. Este doble enfoque le ayuda a desbloquearse en un entorno que tiene limitaciones de capacidad de direcciones IP. Las opciones analizadas en la sección de optimización de direcciones IP de AWS Glue son complementarias a las soluciones de expansión de direcciones IP y puede compilarlas de forma iterativa para madurar su plataforma de datos.
Obtenga más información sobre las técnicas de optimización de trabajos de AWS Glue en Supervise y optimice los costos en AWS Glue para Apache Spark y Mejores prácticas para escalar trabajos de Apache Spark y particionar datos con AWS Glue.
Sobre los autores
 Sushanth Kothapally es arquitecto de soluciones en Amazon Web Services y brinda soporte a clientes de automoción y fabricación. Le apasiona diseñar soluciones tecnológicas para alcanzar objetivos comerciales y tiene un gran interés en las arquitecturas sin servidor y basadas en eventos.
Sushanth Kothapally es arquitecto de soluciones en Amazon Web Services y brinda soporte a clientes de automoción y fabricación. Le apasiona diseñar soluciones tecnológicas para alcanzar objetivos comerciales y tiene un gran interés en las arquitecturas sin servidor y basadas en eventos.
 Senthil Kamala Rathinam es Arquitecto de Soluciones en Amazon Web Services especializado en Datos y Análisis. Le apasiona ayudar a los clientes a diseñar y construir plataformas de datos modernas. En su tiempo libre, a Senthil le encanta pasar tiempo con su familia y jugar al bádminton.
Senthil Kamala Rathinam es Arquitecto de Soluciones en Amazon Web Services especializado en Datos y Análisis. Le apasiona ayudar a los clientes a diseñar y construir plataformas de datos modernas. En su tiempo libre, a Senthil le encanta pasar tiempo con su familia y jugar al bádminton.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/scale-aws-glue-jobs-by-optimizing-ip-address-consumption-and-expanding-network-capacity-using-a-private-nat-gateway/

