Εισαγωγή
Το Retrieval Augmented-Generation (RAG) έχει κατακτήσει τον κόσμο από το Storm από την έναρξή του. Το RAG είναι αυτό που είναι απαραίτητο για τα Μεγάλα Γλωσσικά Μοντέλα (LLM) να παρέχουν ή να δημιουργούν ακριβείς και πραγματικές απαντήσεις. Επιλύουμε την πραγματικότητα των LLM από το RAG, όπου προσπαθούμε να δώσουμε στο LLM ένα περιβάλλον παρόμοιο με τα συμφραζόμενα με το ερώτημα του χρήστη, έτσι ώστε το LLM να λειτουργεί με αυτό το πλαίσιο και να δημιουργήσει μια πραγματικά σωστή απάντηση. Αυτό το κάνουμε αντιπροσωπεύοντας τα δεδομένα μας και το ερώτημα χρήστη με τη μορφή διανυσματικών ενσωματώσεων και εκτελώντας μια ομοιότητα συνημιτόνου. Αλλά το πρόβλημα είναι ότι όλες οι παραδοσιακές προσεγγίσεις αντιπροσωπεύουν τα δεδομένα σε μια ενιαία ενσωμάτωση, η οποία μπορεί να μην είναι ιδανική για καλό συστήματα ανάκτησης. Σε αυτόν τον οδηγό, θα εξετάσουμε το ColBERT το οποίο εκτελεί την ανάκτηση με καλύτερη ακρίβεια από τα παραδοσιακά μοντέλα bi-encoder.
Στόχοι μάθησης
- Κατανοήστε πώς η ανάκτηση στο RAG λειτουργεί σε υψηλό επίπεδο.
- Κατανοήστε τους περιορισμούς μεμονωμένης ενσωμάτωσης στην ανάκτηση.
- Βελτιώστε το πλαίσιο ανάκτησης με τις ενσωματώσεις διακριτικών του ColBERT.
- Μάθετε πώς η καθυστερημένη αλληλεπίδραση του ColBERT βελτιώνει την ανάκτηση.
- Μάθετε πώς να εργάζεστε με το ColBERT για ακριβή ανάκτηση.
Αυτό το άρθρο δημοσιεύθηκε ως μέρος του Data Science Blogathon.
Πίνακας περιεχομένων
Τι είναι το RAG;
Τα LLMs, αν και είναι ικανά να δημιουργήσουν κείμενο που έχει νόημα και γραμματικά σωστό, αυτά τα LLM πάσχουν από ένα πρόβλημα που ονομάζεται ψευδαίσθηση. Ψευδαίσθηση σε LLMs είναι η έννοια όπου οι LLM δημιουργούν με σιγουριά λάθος απαντήσεις, δηλαδή δημιουργούν λάθος απαντήσεις με τρόπο που μας κάνει να πιστεύουμε ότι είναι αλήθεια. Αυτό ήταν ένα σημαντικό πρόβλημα από την εισαγωγή των LLM. Αυτές οι παραισθήσεις οδηγούν σε λανθασμένες και λανθασμένες απαντήσεις. Ως εκ τούτου, εισήχθη το Retrieval Augmented Generation.
Στο RAG, παίρνουμε μια λίστα εγγράφων/τμημάτων εγγράφων και κωδικοποιούμε αυτά τα κειμενικά έγγραφα σε μια αριθμητική αναπαράσταση που ονομάζεται διανυσματικές ενσωματώσεις, όπου μια ενσωμάτωση μεμονωμένου διανύσματος αντιπροσωπεύει ένα ενιαίο κομμάτι εγγράφου και τα αποθηκεύει σε μια βάση δεδομένων που ονομάζεται κατάστημα διάνυσμα. Τα μοντέλα που απαιτούνται για την κωδικοποίηση αυτών των τμημάτων σε ενσωματώσεις ονομάζονται μοντέλα κωδικοποίησης ή δι-κωδικοποιητές. Αυτοί οι κωδικοποιητές εκπαιδεύονται σε ένα μεγάλο σύνολο δεδομένων, καθιστώντας τους έτσι αρκετά ισχυρούς ώστε να κωδικοποιούν τα κομμάτια των εγγράφων σε μια ενιαία αναπαράσταση ενσωμάτωσης διανυσμάτων.
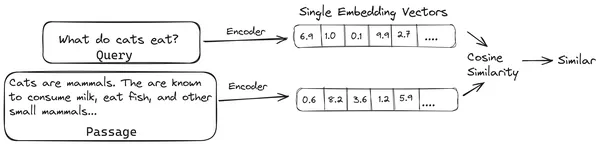
Τώρα, όταν ένας χρήστης κάνει ένα ερώτημα στο LLM, τότε δίνουμε αυτό το ερώτημα στον ίδιο κωδικοποιητή για να δημιουργήσει μια ενσωμάτωση διανύσματος. Αυτή η ενσωμάτωση χρησιμοποιείται στη συνέχεια για τον υπολογισμό της βαθμολογίας ομοιότητας με διάφορες άλλες διανυσματικές ενσωματώσεις των τμημάτων του εγγράφου για να ληφθεί το πιο σχετικό κομμάτι του εγγράφου. Το πιο σχετικό κομμάτι ή μια λίστα με τα πιο σχετικά κομμάτια μαζί με το ερώτημα χρήστη δίνονται στο LLM. Στη συνέχεια, το LLM λαμβάνει αυτές τις επιπλέον πληροφορίες σχετικά με τα συμφραζόμενα και στη συνέχεια δημιουργεί μια απάντηση που ευθυγραμμίζεται με το πλαίσιο που λαμβάνεται από το ερώτημα χρήστη. Αυτό διασφαλίζει ότι το περιεχόμενο που δημιουργείται από το LLM είναι τεκμηριωμένο και ότι μπορεί να εντοπιστεί εάν είναι απαραίτητο.
Το πρόβλημα με τους παραδοσιακούς Bi-Encoders
Το πρόβλημα με τα παραδοσιακά μοντέλα Encoder όπως το all-miniLM, OpenAI μοντέλο ενσωμάτωσης και άλλα μοντέλα κωδικοποιητή είναι ότι συμπιέζουν ολόκληρο το κείμενο σε μια ενιαία διανυσματική αναπαράσταση ενσωμάτωσης. Αυτές οι αναπαραστάσεις ενσωμάτωσης μεμονωμένων διανυσμάτων είναι χρήσιμες επειδή βοηθούν στην αποτελεσματική και γρήγορη ανάκτηση παρόμοιων εγγράφων. Ωστόσο, το πρόβλημα έγκειται στη συνάφεια μεταξύ του ερωτήματος και του εγγράφου. Η ενσωμάτωση ενός διανύσματος μπορεί να μην είναι επαρκής για την αποθήκευση των πληροφοριών με βάση τα συμφραζόμενα ενός κομματιού εγγράφου, δημιουργώντας έτσι ένα σημείο συμφόρησης πληροφοριών.
Φανταστείτε ότι 500 λέξεις συμπιέζονται σε ένα μεμονωμένο διάνυσμα μεγέθους 782. Μπορεί να μην αρκεί η αναπαράσταση ενός τέτοιου κομματιού με μια ενσωμάτωση ενός διανύσματος, δίνοντας έτσι αποτελέσματα χαμηλότερα στην ανάκτηση στις περισσότερες περιπτώσεις. Η αναπαράσταση ενός διανύσματος μπορεί επίσης να αποτύχει σε περιπτώσεις περίπλοκων ερωτημάτων ή εγγράφων. Μια τέτοια λύση θα ήταν να αναπαραστήσετε το κομμάτι του εγγράφου ή ένα ερώτημα ως μια λίστα διανυσμάτων ενσωμάτωσης αντί για ένα μεμονωμένο διάνυσμα ενσωμάτωσης, εδώ μπαίνει το ColBERT.
Τι είναι το ColBERT;
Το ColBERT (Contextual Late Interactions BERT) είναι ένας bi-κωδικοποιητής που αναπαριστά κείμενο σε μια αναπαράσταση ενσωμάτωσης πολλαπλών διανυσμάτων. Λαμβάνει ένα ερώτημα ή ένα κομμάτι ενός εγγράφου / ένα μικρό έγγραφο και δημιουργεί διανυσματικές ενσωματώσεις σε επίπεδο διακριτικού. Δηλαδή, κάθε διακριτικό έχει τη δική του ενσωμάτωση διανυσμάτων και το ερώτημα/έγγραφο κωδικοποιείται σε μια λίστα ενσωματώσεων διανυσμάτων σε επίπεδο διακριτικού. Οι ενσωματώσεις σε επίπεδο διακριτικού παράγονται από ένα προεκπαιδευμένο ΜΠΕΡΤ μοντέλο εξ ου και το όνομα BERT.
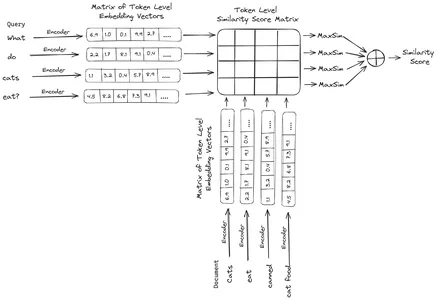
Αυτά στη συνέχεια αποθηκεύονται στη διανυσματική βάση δεδομένων. Τώρα, όταν εισέρχεται ένα ερώτημα, δημιουργείται μια λίστα με ενσωματώσεις σε επίπεδο διακριτικού και, στη συνέχεια, εκτελείται ένας πολλαπλασιασμός πίνακα μεταξύ του ερωτήματος χρήστη και κάθε εγγράφου, καταλήγοντας έτσι σε έναν πίνακα που περιέχει βαθμολογίες ομοιότητας. Η συνολική ομοιότητα επιτυγχάνεται λαμβάνοντας το άθροισμα της μέγιστης ομοιότητας μεταξύ των διακριτικών εγγράφων για κάθε διακριτικό ερωτήματος. Ο τύπος για αυτό φαίνεται στην παρακάτω εικόνα:
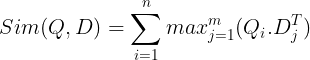
Εδώ στην παραπάνω εξίσωση, βλέπουμε ότι κάνουμε ένα γινόμενο κουκκίδων μεταξύ του Query Tokens Matrix (που περιέχει ενσωματώσεις διανυσματικών σε επίπεδο Ν διακριτικών) και του πίνακα Transpose of Document Tokens Matrix (που περιέχει ενσωματώσεις διανυσμάτων επιπέδου διακριτικού M) και, στη συνέχεια, παίρνουμε τη μέγιστη ομοιότητα διασταυρώστε τα διακριτικά του εγγράφου για κάθε διακριτικό ερωτήματος. Στη συνέχεια παίρνουμε το άθροισμα όλων αυτών των μέγιστων ομοιοτήτων, το οποίο μας δίνει την τελική βαθμολογία ομοιότητας μεταξύ του εγγράφου και του ερωτήματος. Ο λόγος για τον οποίο αυτό παράγει αποτελεσματική και ακριβή ανάκτηση είναι ότι εδώ έχουμε μια αλληλεπίδραση σε επίπεδο διακριτικού, η οποία δίνει χώρο για περισσότερη κατανόηση των συμφραζομένων μεταξύ του ερωτήματος και του εγγράφου.
Γιατί το όνομα ColBERT;
Καθώς υπολογίζουμε τη λίστα των διανυσμάτων ενσωμάτωσης πριν από τον εαυτό της και εκτελούμε μόνο αυτή τη λειτουργία MaxSim (μέγιστη ομοιότητα) κατά τη διάρκεια της εξαγωγής του μοντέλου, ονομάζοντάς την έτσι ένα αργό βήμα αλληλεπίδρασης, και καθώς λαμβάνουμε περισσότερες πληροφορίες με βάση τα συμφραζόμενα μέσω αλληλεπιδράσεων σε επίπεδο διακριτικού, ονομάζεται συμφραζόμενη καθυστερημένες αλληλεπιδράσεις. Έτσι το όνομα Contextual Late Interactions ΜΠΕΡΤ ή ColBERT. Αυτοί οι υπολογισμοί μπορούν να εκτελεστούν παράλληλα, επομένως μπορούν να υπολογιστούν αποτελεσματικά. Τέλος, μια ανησυχία είναι ο χώρος, δηλαδή απαιτεί πολύ χώρο για την αποθήκευση αυτής της λίστας ενσωματώσεων διανυσμάτων σε επίπεδο διακριτικού. Αυτό το πρόβλημα επιλύθηκε στο ColBERTv2, όπου οι ενσωματώσεις συμπιέζονται μέσω της τεχνικής που ονομάζεται υπολειπόμενη συμπίεση, βελτιστοποιώντας έτσι τον χώρο που χρησιμοποιείται.
Hands-On ColBERT με Παράδειγμα
Σε αυτήν την ενότητα, θα έρθουμε σε επαφή με το ColBERT και θα ελέγξουμε ακόμη και πώς αποδίδει σε ένα κανονικό μοντέλο ενσωμάτωσης.
Βήμα 1: Λήψη Βιβλιοθηκών
Θα ξεκινήσουμε κατεβάζοντας την παρακάτω βιβλιοθήκη:
!pip install ragatouille langchain langchain_openai chromadb einops sentence-transformers tiktoken- RAGatouille: Αυτή η βιβλιοθήκη μας επιτρέπει να εργαστούμε με μεθόδους ανάκτησης τελευταίας τεχνολογίας (SOTA) όπως το ColBERT με έναν εύκολο στη χρήση τρόπο. Παρέχει επιλογές για τη δημιουργία ευρετηρίων πάνω από τα σύνολα δεδομένων, την υποβολή ερωτημάτων σε αυτά και ακόμη μας επιτρέπει να εκπαιδεύσουμε ένα μοντέλο ColBERT στα δεδομένα μας.
- LangChain: Αυτή η βιβλιοθήκη θα μας επιτρέψει να εργαστούμε με τα μοντέλα ενσωμάτωσης ανοιχτού κώδικα, ώστε να μπορούμε να ελέγξουμε πόσο καλά λειτουργούν τα άλλα μοντέλα ενσωμάτωσης σε σύγκριση με το ColBERT.
- langchain_openai: Εγκαθιστά το LangChain εξαρτήσεις για το OpenAI. Θα συνεργαστούμε ακόμη και με το μοντέλο OpenAI Embedding για να ελέγξουμε την απόδοσή του έναντι του ColBERT.
- ChromaDB: Αυτή η βιβλιοθήκη θα μας επιτρέψει να δημιουργήσουμε ένα διανυσματικό χώρο αποθήκευσης στο περιβάλλον μας, ώστε να μπορούμε να αποθηκεύσουμε τις ενσωματώσεις που δημιουργήσαμε στα δεδομένα μας και αργότερα να εκτελέσουμε μια σημασιολογική αναζήτηση μεταξύ του ερωτήματος και των αποθηκευμένων ενσωματώσεων.
- einops: Αυτή η βιβλιοθήκη χρειάζεται για αποτελεσματικούς πολλαπλασιασμούς πινάκων τανυστών.
- μετασχηματιστές προτάσεων και την tiktoken απαιτείται βιβλιοθήκη για να λειτουργήσουν σωστά τα μοντέλα ενσωμάτωσης ανοιχτού κώδικα.
Βήμα 2: Κατεβάστε το προεκπαιδευμένο μοντέλο
Στο επόμενο βήμα, θα κατεβάσουμε το προεκπαιδευμένο μοντέλο ColBERT. Για αυτό, ο κωδικός θα είναι
from ragatouille import RAGPretrainedModel
RAG = RAGPretrainedModel.from_pretrained("colbert-ir/colbertv2.0")- Πρώτα εισάγουμε την κλάση RAGPretrainedModel από τη βιβλιοθήκη RAGatouille.
- Στη συνέχεια καλούμε το .from_pretrained() και δίνουμε το όνομα του μοντέλου, δηλαδή “colbert-ir/colbertv2.0”.
Η εκτέλεση του παραπάνω κώδικα θα δημιουργήσει ένα μοντέλο ColBERT RAG. Τώρα ας κατεβάσουμε μια σελίδα της Wikipedia και ας κάνουμε ανάκτηση από αυτήν. Για αυτό, ο κωδικός θα είναι:
from ragatouille.utils import get_wikipedia_page
document = get_wikipedia_page("Elon_Musk")
print("Word Count:",len(document))
print(document[:1000])Το RAGatouille συνοδεύεται από μια εύχρηστη συνάρτηση που ονομάζεται get_wikipedia_page, η οποία παίρνει μια συμβολοσειρά και παίρνει την αντίστοιχη σελίδα της Wikipedia. Εδώ κατεβάζουμε το περιεχόμενο της Wikipedia στον Έλον Μασκ και το αποθηκεύουμε στο έγγραφο της μεταβλητής. Ας εκτυπώσουμε τον αριθμό των λέξεων που υπάρχουν στο έγγραφο και τις πρώτες λίγες γραμμές του εγγράφου.
Εδώ μπορούμε να δούμε την έξοδο στην εικόνα. Μπορούμε να δούμε ότι υπάρχουν συνολικά 64,668 λέξεις στη σελίδα Wikipedia του Έλον Μασκ.
Βήμα 3: Ευρετηρίαση
Τώρα θα δημιουργήσουμε ένα ευρετήριο σε αυτό το έγγραφο.
RAG.index(
# List of Documents
collection=[document],
# List of IDs for the above Documents
document_ids=['elon_musk'],
# List of Dictionaries for the metadata for the above Documents
document_metadatas=[{"entity": "person", "source": "wikipedia"}],
# Name of the index
index_name="Elon2",
# Chunk Size of the Document Chunks
max_document_length=256,
# Wether to Split Document or Not
split_documents=True
)Εδώ καλούμε το .index() του RAG για να ευρετηριάσει το έγγραφό μας. Σε αυτό περνάμε τα εξής:
- συλλογή: Αυτή είναι μια λίστα εγγράφων που θέλουμε να δημιουργήσουμε ευρετήριο. Εδώ έχουμε μόνο ένα έγγραφο, επομένως μια λίστα με ένα μόνο έγγραφο.
- document_ids: Κάθε έγγραφο αναμένει ένα μοναδικό αναγνωριστικό εγγράφου. Εδώ του περνάμε το όνομα elon_musk γιατί το έγγραφο αφορά τον Elon Musk.
- document_metadatas: Κάθε έγγραφο έχει τα μεταδεδομένα του. Αυτή είναι πάλι μια λίστα λεξικών, όπου κάθε λεξικό περιέχει μεταδεδομένα ζεύγους κλειδιού-τιμής για ένα συγκεκριμένο έγγραφο.
- index_name: Το όνομα του ευρετηρίου που δημιουργούμε. Ας το ονομάσουμε Elon2.
- μέγιστο_μέγεθος_εγγράφου: Αυτό είναι παρόμοιο με το μέγεθος του κομματιού. Καθορίζουμε πόσο πρέπει να είναι κάθε κομμάτι εγγράφου. Εδώ του δίνουμε μια τιμή 256. Εάν δεν προσδιορίσουμε καμία τιμή, το 256 θα ληφθεί ως το προεπιλεγμένο μέγεθος κομματιού.
- split_documents: Είναι μια δυαδική τιμή, όπου το True υποδηλώνει ότι θέλουμε να χωρίσουμε το έγγραφό μας σύμφωνα με το δεδομένο μέγεθος κομματιού και το False σημαίνει ότι θέλουμε να αποθηκεύσουμε ολόκληρο το έγγραφο ως ένα μόνο κομμάτι.
Η εκτέλεση του παραπάνω κώδικα θα τεμαχίσει το έγγραφό μας σε μεγέθη 256 ανά κομμάτι και, στη συνέχεια, θα τα ενσωματώσει μέσω του μοντέλου ColBERT, το οποίο θα παράγει μια λίστα με ενσωματώσεις διανυσμάτων σε επίπεδο διακριτικού για κάθε κομμάτι και, τέλος, θα τα αποθηκεύσει σε ένα ευρετήριο. Αυτό το βήμα θα πάρει λίγο χρόνο για να εκτελεστεί και μπορεί να επιταχυνθεί εάν έχετε GPU. Τέλος, δημιουργεί έναν κατάλογο όπου αποθηκεύεται το ευρετήριό μας. Εδώ ο κατάλογος θα είναι ".ragatouille/colbert/indexes/Elon2"
Βήμα 4: Γενικό ερώτημα
Τώρα, θα ξεκινήσουμε την αναζήτηση. Για αυτό, ο κωδικός θα είναι
results = RAG.search(query="What companies did Elon Musk find?", k=3, index_name='Elon2')
for i, doc, in enumerate(results):
print(f"---------------------------------- doc-{i} ------------------------------------")
print(doc["content"])- Εδώ, πρώτα, καλούμε τη μέθοδο .search() του αντικειμένου RAG
- Σε αυτό, δίνουμε τις μεταβλητές που περιλαμβάνουν το όνομα του ερωτήματος, k (αριθμός εγγράφων προς ανάκτηση) και το όνομα ευρετηρίου για αναζήτηση
- Εδώ παρέχουμε το ερώτημα "Ποιες εταιρείες βρήκε ο Έλον Μασκ;". Το αποτέλεσμα που προκύπτει θα είναι σε μια λίστα με μορφή λεξικού, η οποία περιέχει τα κλειδιά όπως περιεχόμενο, βαθμολογία, κατάταξη, αναγνωριστικό_document, passage_id και document_metadata
- Ως εκ τούτου, εργαζόμαστε με τον παρακάτω κώδικα για να εκτυπώσουμε τα ανακτημένα έγγραφα με καθαρό τρόπο
- Εδώ εξετάζουμε τη λίστα των λεξικών και εκτυπώνουμε το περιεχόμενο των εγγράφων
Η εκτέλεση του κώδικα θα παράγει τα ακόλουθα αποτελέσματα:
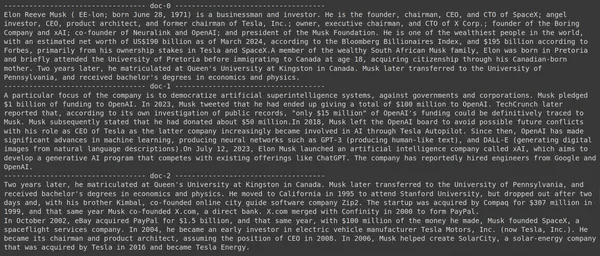
Στην εικόνα, μπορούμε να δούμε ότι το πρώτο και το τελευταίο έγγραφο καλύπτει εξ ολοκλήρου τις διάφορες εταιρείες που ίδρυσε ο Έλον Μασκ. Το ColBERT μπόρεσε να ανακτήσει σωστά τα σχετικά κομμάτια που απαιτούνταν για να απαντήσει στο ερώτημα.
Βήμα 5: Συγκεκριμένο ερώτημα
Τώρα ας πάμε ένα βήμα παραπέρα και ας του κάνουμε μια συγκεκριμένη ερώτηση.
results = RAG.search(query="How much Tesla stocks did Elon sold in
Decemeber 2022?", k=3, index_name='Elon2')
for i, doc, in enumerate(results):
print(f"---------------
------------------- doc-{i} ------------------------------------")
print(doc["content"])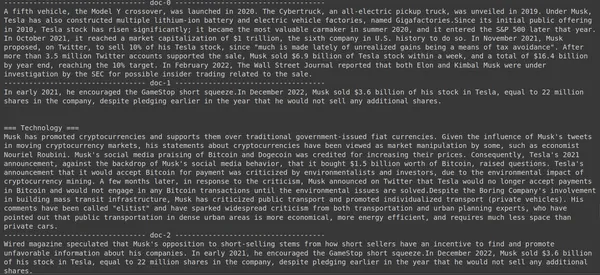
Εδώ στον παραπάνω κώδικα, θέτουμε μια πολύ συγκεκριμένη ερώτηση σχετικά με το πόσες μετοχές της Tesla Elon πούλησε τον μήνα Δεκέμβριο του 2022. Μπορούμε να δούμε την απόδοση εδώ. Το έγγραφο-1 περιέχει την απάντηση στην ερώτηση. Ο Έλον πούλησε τη μετοχή του στην Tesla αξίας 3.6 δισεκατομμυρίων δολαρίων. Και πάλι, το ColBERT μπόρεσε να ανακτήσει με επιτυχία το σχετικό κομμάτι για το συγκεκριμένο ερώτημα.
Βήμα 6: Δοκιμή άλλων μοντέλων
Ας δοκιμάσουμε τώρα την ίδια ερώτηση με τα άλλα μοντέλα ενσωμάτωσης τόσο ανοιχτού κώδικα όσο και κλειστού εδώ:
from langchain_community.embeddings import HuggingFaceEmbeddings
from transformers import AutoModel
model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-en', trust_remote_code=True)
model_name = "jinaai/jina-embeddings-v2-base-en"
model_kwargs = {'device': 'cpu'}
embeddings = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
)
- Ξεκινάμε κατεβάζοντας το μοντέλο πρώτα μέσω της κατηγορίας AutoModel από τη βιβλιοθήκη Transformers.
- Στη συνέχεια αποθηκεύουμε το model_name και το model_kwargs στις αντίστοιχες μεταβλητές τους.
- Τώρα για να δουλέψουμε με αυτό το μοντέλο στο LangChain, εισάγουμε το HuggingFaceEmbeddings από το LangChain και δώστε του το όνομα μοντέλου και το model_kwargs.
Με την εκτέλεση αυτού του κώδικα θα γίνει λήψη και φόρτωση του μοντέλου ενσωμάτωσης Jina, ώστε να μπορέσουμε να εργαστούμε μαζί του
Βήμα 7: Δημιουργία ενσωματώσεων
Τώρα, πρέπει να αρχίσουμε να χωρίζουμε το έγγραφό μας και, στη συνέχεια, να δημιουργήσουμε ενσωματώσεις από αυτό και να τις αποθηκεύσουμε στο κατάστημα Chroma vector. Για αυτό, εργαζόμαστε με τον ακόλουθο κώδικα:
from langchain_community.vectorstores import Chroma
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=256,
chunk_overlap=0)
splits = text_splitter.split_text(document)
vectorstore = Chroma.from_texts(texts=splits,
embedding=embeddings,
collection_name="elon")
retriever = vectorstore.as_retriever(search_kwargs = {'k':3})- Ξεκινάμε εισάγοντας το Chroma και το RecursiveCharacterTextSplitter από τη βιβλιοθήκη LangChain
- Στη συνέχεια, εγκαινιάζουμε ένα text_splitter καλώντας τον .from_tiktoken_encoder του RecursiveCharacterTextSplitter και περνώντας του τα chunk_size και chunk_overlap
- Εδώ θα χρησιμοποιήσουμε το ίδιο chunk_size που έχουμε δώσει στο ColBERT
- Στη συνέχεια καλούμε τη μέθοδο .split_text() αυτού του text_splitter και του δίνουμε το έγγραφο που περιέχει πληροφορίες της Wikipedia για τον Elon Musk. Στη συνέχεια, χωρίζει το έγγραφο με βάση το δεδομένο μέγεθος κομματιού και, τέλος, η λίστα των τεμαχίων εγγράφου αποθηκεύεται στις μεταβλητές διαχωρισμούς
- Τέλος, καλούμε τη συνάρτηση .from_texts() της κλάσης Chroma για να δημιουργήσουμε ένα διανυσματικό χώρο αποθήκευσης. Σε αυτή τη συνάρτηση, δίνουμε τα splits, το μοντέλο ενσωμάτωσης και το collection_name
- Τώρα, δημιουργούμε ένα retriever από αυτό καλώντας τη συνάρτηση .as_retriever() του αντικειμένου αποθήκευσης διανυσμάτων. Δίνουμε 3 για την τιμή k
Η εκτέλεση αυτού του κώδικα θα λάβει το έγγραφό μας, θα το χωρίσει σε μικρότερα έγγραφα μεγέθους 256 ανά κομμάτι και, στη συνέχεια, θα ενσωματώσει αυτά τα μικρότερα κομμάτια με το μοντέλο ενσωμάτωσης Jina και θα αποθηκεύσει αυτά τα διανύσματα ενσωμάτωσης στο χώρο αποθήκευσης διανυσμάτων χρώματος.
Βήμα 8: Δημιουργία Retriever
Τέλος, δημιουργούμε ένα retriever από αυτό. Τώρα θα πραγματοποιήσουμε μια διανυσματική αναζήτηση και θα ελέγξουμε τα αποτελέσματα.
docs = retriever.get_relevant_documents("What companies did Elon Musk find?",)
for i, doc in enumerate(docs):
print(f"---------------------------------- doc-{i} ------------------------------------")
print(doc.page_content)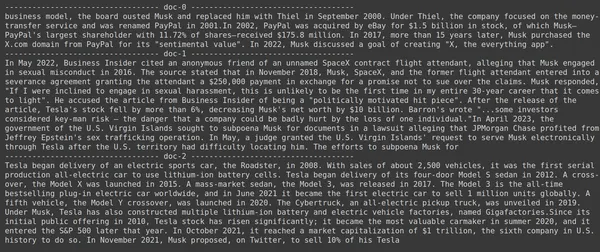
- Καλούμε τη συνάρτηση .get_relevent_documents() του αντικειμένου retriever και του δίνουμε το ίδιο ερώτημα.
- Στη συνέχεια εκτυπώνουμε προσεκτικά τα 3 κορυφαία έγγραφα που ανακτήθηκαν.
- Στην εικόνα, μπορούμε να δούμε ότι το Jina Embedder, παρόλο που είναι ένα δημοφιλές μοντέλο ενσωμάτωσης, η ανάκτηση για το ερώτημά μας είναι κακή. Δεν ήταν επιτυχής η λήψη των σωστών τμημάτων εγγράφων.
Μπορούμε ξεκάθαρα να εντοπίσουμε τη διαφορά μεταξύ του Jina, του μοντέλου ενσωμάτωσης που αντιπροσωπεύει κάθε κομμάτι ως ενσωμάτωση μεμονωμένου διανύσματος, και του μοντέλου ColBERT που αντιπροσωπεύει κάθε κομμάτι ως μια λίστα διανυσμάτων ενσωμάτωσης σε επίπεδο διακριτικού. Το ColBERT ξεπερνά σαφώς σε αυτή την περίπτωση.
Βήμα 9: Δοκιμή του μοντέλου ενσωμάτωσης του OpenAI
Τώρα ας δοκιμάσουμε να χρησιμοποιήσουμε ένα μοντέλο ενσωμάτωσης κλειστού κώδικα όπως το μοντέλο OpenAI Embedding.
import os
os.environ["OPENAI_API_KEY"] = "Your API Key"
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
model_name = "gpt-4",
chunk_size = 256,
chunk_overlap = 0,
)
splits = text_splitter.split_text(document)
vectorstore = Chroma.from_texts(texts=splits,
embedding=embeddings,
collection_name="elon_collection")
retriever = vectorstore.as_retriever(search_kwargs = {'k':3})Εδώ ο κώδικας μοιάζει πολύ με αυτόν που μόλις γράψαμε
- Η μόνη διαφορά είναι ότι περνάμε στο κλειδί OpenAI API για να ορίσουμε τη μεταβλητή περιβάλλοντος.
- Στη συνέχεια, δημιουργούμε ένα στιγμιότυπο του μοντέλου OpenAI Embedding εισάγοντάς το από το LangChain.
- Και κατά τη δημιουργία του ονόματος της συλλογής, δίνουμε ένα διαφορετικό όνομα συλλογής, έτσι ώστε οι ενσωματώσεις από το μοντέλο OpenAI Embedding να αποθηκεύονται σε διαφορετική συλλογή.
Η εκτέλεση αυτού του κώδικα θα λάβει ξανά τα έγγραφά μας, θα τα τεμαχίσει σε μικρότερα έγγραφα μεγέθους 256 και, στη συνέχεια, θα τα ενσωματώσει σε αναπαράσταση ενσωμάτωσης ενός διανύσματος με το μοντέλο ενσωμάτωσης OpenAI και, τέλος, θα αποθηκεύσει αυτές τις ενσωματώσεις στο Chroma Vector Store. Τώρα ας προσπαθήσουμε να ανακτήσουμε τα σχετικά έγγραφα για την άλλη ερώτηση.
docs = retriever.get_relevant_documents("How much Tesla stocks did Elon sold in Decemeber 2022?",)
for i, doc in enumerate(docs):
print(f"---------------------------------- doc-{i} ------------------------------------")
print(doc.page_content)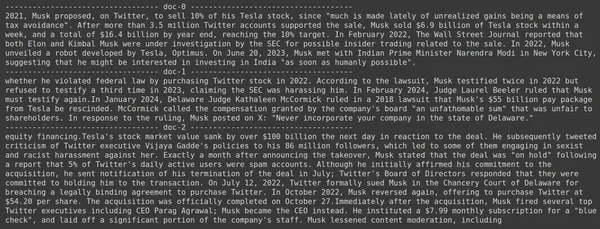
- Βλέπουμε ότι η απάντηση που περιμένουμε δεν βρίσκεται στα ανακτημένα κομμάτια.
- Το πρώτο περιέχει πληροφορίες για τις μετοχές της Tesla το 2022, αλλά δεν μιλάει για την πώληση του Elon.
- Το ίδιο μπορεί να φανεί με τα υπόλοιπα δύο κομμάτια εγγράφων, όπου οι πληροφορίες που περιέχουν αφορούν την Tesla και το απόθεμά της, αλλά αυτές δεν είναι οι πληροφορίες που περιμένουμε.
- Τα παραπάνω ανακτημένα κομμάτια δεν παρέχουν το πλαίσιο για να απαντήσει το LLM στο ερώτημα που έχουμε παράσχει.
Ακόμη και εδώ μπορούμε να δούμε μια σαφή διαφορά μεταξύ της αναπαράστασης ενσωμάτωσης ενός διανύσματος έναντι της αναπαράστασης ενσωμάτωσης πολλαπλών διανυσμάτων. Οι αναπαραστάσεις πολλαπλής ενσωμάτωσης καταγράφουν ξεκάθαρα τα περίπλοκα ερωτήματα που έχουν ως αποτέλεσμα πιο ακριβείς ανακτήσεις.
Συμπέρασμα
Συμπερασματικά, το ColBERT επιδεικνύει μια σημαντική πρόοδο στην απόδοση ανάκτησης έναντι των παραδοσιακών μοντέλων bi-encoder, αναπαριστώντας το κείμενο ως ενσωματώσεις πολλαπλών διανυσμάτων σε επίπεδο διακριτικού. Αυτή η προσέγγιση επιτρέπει πιο διαφοροποιημένη κατανόηση συμφραζομένων μεταξύ ερωτημάτων και εγγράφων, οδηγώντας σε πιο ακριβή αποτελέσματα ανάκτησης και μετριάζοντας το ζήτημα των παραισθήσεων που συνήθως παρατηρούνται στα LLM.
Βασικές τακτικές
- Το RAG αντιμετωπίζει το πρόβλημα των παραισθήσεων στα LLM παρέχοντας πληροφορίες για τα συμφραζόμενα για τη δημιουργία πραγματικών απαντήσεων.
- Οι παραδοσιακοί δι-κωδικοποιητές υποφέρουν από ένα πρόβλημα συμφόρησης λόγω της συμπίεσης ολόκληρων κειμένων σε ενσωματώσεις μεμονωμένων διανυσμάτων, με αποτέλεσμα την ακρίβεια ανάκτησης κάτω από την ισοτιμία.
- Το ColBERT, με την αναπαράσταση ενσωμάτωσης σε επίπεδο διακριτικού, διευκολύνει την καλύτερη κατανόηση των συμφραζομένων μεταξύ ερωτημάτων και εγγράφων, οδηγώντας σε βελτιωμένη απόδοση ανάκτησης.
- Το αργό βήμα αλληλεπίδρασης στο ColBERT, σε συνδυασμό με αλληλεπιδράσεις σε επίπεδο διακριτικού, ενισχύει την ακρίβεια ανάκτησης λαμβάνοντας υπόψη τις αποχρώσεις του συμφραζομένου.
- Το ColBERTv2 βελτιστοποιεί τον αποθηκευτικό χώρο μέσω της υπολειπόμενης συμπίεσης, διατηρώντας παράλληλα την αποτελεσματικότητα της ανάκτησης.
- Τα πρακτικά πειράματα καταδεικνύουν την ανωτερότητα του ColBERT στην απόδοση ανάκτησης σε σύγκριση με τα παραδοσιακά μοντέλα και τα μοντέλα ενσωμάτωσης ανοιχτού κώδικα όπως το Jina και το OpenAI Embedding.
Συχνές Ερωτήσεις
Α. Οι παραδοσιακοί bi-κωδικοποιητές συμπιέζουν ολόκληρα κείμενα σε ενσωματώσεις μεμονωμένων διανυσμάτων, χάνοντας πιθανώς πληροφορίες σχετικά με τα συμφραζόμενα. Αυτό περιορίζει την αποτελεσματικότητά τους στις εργασίες ανάκτησης, ειδικά με πολύπλοκα ερωτήματα ή έγγραφα.
A. Το ColBERT (Contextual Late Interactions BERT) είναι ένα μοντέλο bi-encoder που αναπαριστά κείμενο χρησιμοποιώντας ενσωματώσεις διανυσμάτων σε επίπεδο διακριτικού. Επιτρέπει πιο διαφοροποιημένη κατανόηση συμφραζομένων μεταξύ ερωτημάτων και εγγράφων, βελτιώνοντας την ακρίβεια ανάκτησης.
A. Το ColBERT δημιουργεί ενσωματώσεις σε επίπεδο διακριτικού για ερωτήματα και έγγραφα, εκτελεί πολλαπλασιασμό μήτρας για τον υπολογισμό των βαθμολογιών ομοιότητας και, στη συνέχεια, επιλέγει τις πιο σχετικές πληροφορίες με βάση τη μέγιστη ομοιότητα μεταξύ των διακριτικών. Αυτό επιτρέπει την αποτελεσματική ανάκτηση με κατανόηση των συμφραζομένων.
A. Το ColBERTv2 βελτιστοποιεί το διάστημα μέσω της μεθόδου υπολειπόμενης συμπίεσης, μειώνοντας τις απαιτήσεις αποθήκευσης για ενσωματώσεις σε επίπεδο διακριτικού διατηρώντας παράλληλα την ακρίβεια ανάκτησης.
Α. Μπορείτε να χρησιμοποιήσετε βιβλιοθήκες όπως η RAGatouille για να εργαστείτε εύκολα με το ColBERT. Με την ευρετηρίαση εγγράφων και ερωτημάτων, μπορείτε να εκτελέσετε αποτελεσματικές εργασίες ανάκτησης και να δημιουργήσετε ακριβείς απαντήσεις ευθυγραμμισμένες με το περιβάλλον.
Τα μέσα που εμφανίζονται σε αυτό το άρθρο δεν ανήκουν στο Analytics Vidhya και χρησιμοποιούνται κατά την κρίση του συγγραφέα.
- SEO Powered Content & PR Distribution. Ενισχύστε σήμερα.
- PlatoData.Network Vertical Generative Ai. Ενδυναμώστε τον εαυτό σας. Πρόσβαση εδώ.
- PlatoAiStream. Web3 Intelligence. Ενισχύθηκε η γνώση. Πρόσβαση εδώ.
- PlatoESG. Ανθρακας, Cleantech, Ενέργεια, Περιβάλλον, Ηλιακός, Διαχείριση των αποβλήτων. Πρόσβαση εδώ.
- PlatoHealth. Ευφυΐα βιοτεχνολογίας και κλινικών δοκιμών. Πρόσβαση εδώ.
- πηγή: https://www.analyticsvidhya.com/blog/2024/04/colbert-improve-retrieval-performance-with-token-level-vector-embeddings/

