Εισαγωγή
Στην καρδιά του επιστημονικά δεδομένα Τα στατιστικά ψέματα, τα οποία υπάρχουν εδώ και αιώνες, αλλά παραμένουν θεμελιωδώς ουσιαστικά στη σημερινή ψηφιακή εποχή. Γιατί; Επειδή οι βασικές έννοιες της στατιστικής είναι η ραχοκοκαλιά ανάλυση δεδομένων, δίνοντάς μας τη δυνατότητα να κατανοήσουμε τις τεράστιες ποσότητες δεδομένων που παράγονται καθημερινά. Είναι σαν να συνομιλούμε με δεδομένα, όπου τα στατιστικά μάς βοηθούν να κάνουμε τις σωστές ερωτήσεις και να κατανοήσουμε τις ιστορίες που προσπαθούν να πουν τα δεδομένα.
Από την πρόβλεψη μελλοντικών τάσεων και τη λήψη αποφάσεων με βάση δεδομένα μέχρι τον έλεγχο υποθέσεων και τη μέτρηση της απόδοσης, τα στατιστικά είναι το εργαλείο που τροφοδοτεί τις γνώσεις πίσω από αποφάσεις που βασίζονται σε δεδομένα. Είναι η γέφυρα μεταξύ ακατέργαστων δεδομένων και πρακτικών πληροφοριών, καθιστώντας το αναπόσπαστο μέρος της επιστήμης δεδομένων.
Σε αυτό το άρθρο, έχω συγκεντρώσει τις κορυφαίες 15 βασικές έννοιες στατιστικών που κάθε αρχάριος στην επιστήμη δεδομένων πρέπει να γνωρίζει!

Πίνακας περιεχομένων
1. Στατιστική δειγματοληψία και συλλογή δεδομένων
Θα μάθουμε μερικές βασικές έννοιες στατιστικών, αλλά η κατανόηση από πού προέρχονται τα δεδομένα μας και πώς τα συγκεντρώνουμε είναι απαραίτητη πριν βουτήξουμε βαθιά στον ωκεανό των δεδομένων. Εδώ μπαίνουν στο παιχνίδι οι πληθυσμοί, τα δείγματα και οι διάφορες τεχνικές δειγματοληψίας.
Φανταστείτε ότι θέλουμε να μάθουμε το μέσο ύψος των ανθρώπων σε μια πόλη. Είναι πρακτικό να μετράμε όλους, επομένως παίρνουμε μια μικρότερη ομάδα (δείγμα) που αντιπροσωπεύει τον μεγαλύτερο πληθυσμό. Το κόλπο βρίσκεται στο πώς επιλέγουμε αυτό το δείγμα. Τεχνικές όπως η τυχαία, η στρωματοποιημένη δειγματοληψία ή η δειγματοληψία σε ομάδες διασφαλίζουν ότι το δείγμα μας αντιπροσωπεύεται καλά, ελαχιστοποιώντας την προκατάληψη και καθιστώντας τα ευρήματά μας πιο αξιόπιστα.
Κατανοώντας τους πληθυσμούς και τα δείγματα, μπορούμε με σιγουριά να επεκτείνουμε τις γνώσεις μας από το δείγμα σε ολόκληρο τον πληθυσμό, λαμβάνοντας τεκμηριωμένες αποφάσεις χωρίς να χρειάζεται να ερευνούμε όλους.
2. Τύποι Δεδομένων και Κλίμακες μέτρησης
Τα δεδομένα έρχονται σε διάφορες γεύσεις και η γνώση του τύπου των δεδομένων με τα οποία αντιμετωπίζετε είναι ζωτικής σημασίας για την επιλογή των σωστών στατιστικών εργαλείων και τεχνικών.
Ποσοτικά & Ποιοτικά Δεδομένα
- Ποσοτικά δεδομένα: Αυτός ο τύπος δεδομένων αφορά αριθμούς. Είναι μετρήσιμο και μπορεί να χρησιμοποιηθεί για μαθηματικούς υπολογισμούς. Τα ποσοτικά δεδομένα μας λένε «πόσο» ή «πόσο», όπως ο αριθμός των χρηστών που επισκέπτονται έναν ιστότοπο ή η θερμοκρασία σε μια πόλη. Είναι απλό και αντικειμενικό, παρέχοντας μια σαφή εικόνα μέσω αριθμητικών τιμών.
- Ποιοτικα δεδομενα: Αντίθετα, τα ποιοτικά δεδομένα ασχολούνται με χαρακτηριστικά και περιγραφές. Έχει να κάνει με το «τι τύπος» ή «ποια κατηγορία». Σκεφτείτε το ως τα δεδομένα που περιγράφουν ιδιότητες ή ιδιότητες, όπως το χρώμα ενός αυτοκινήτου ή το είδος ενός βιβλίου. Αυτά τα δεδομένα είναι υποκειμενικά, βασισμένα σε παρατηρήσεις και όχι σε μετρήσεις.
Τέσσερις κλίμακες μέτρησης
- Ονομαστική κλίμακα: Αυτή είναι η απλούστερη μορφή μέτρησης που χρησιμοποιείται για την κατηγοριοποίηση δεδομένων χωρίς συγκεκριμένη σειρά. Τα παραδείγματα περιλαμβάνουν τύπους κουζίνας, ομάδες αίματος ή εθνικότητα. Πρόκειται για επισήμανση χωρίς καμία ποσοτική αξία.
- Τακτική κλίμακα: Τα δεδομένα μπορούν να ταξινομηθούν ή να ταξινομηθούν εδώ, αλλά τα διαστήματα μεταξύ των τιμών δεν έχουν καθοριστεί. Σκεφτείτε μια έρευνα ικανοποίησης με επιλογές όπως ικανοποιημένος, ουδέτερος και μη ικανοποιημένος. Μας λέει τη σειρά αλλά όχι την απόσταση μεταξύ των βαθμολογιών.
- Κλίμακα διαστήματος: Οι κλίμακες διαστήματος παραγγέλνουν δεδομένα και ποσοτικοποιούν τη διαφορά μεταξύ των καταχωρήσεων. Ωστόσο, δεν υπάρχει πραγματικό σημείο μηδέν. Ένα καλό παράδειγμα είναι η θερμοκρασία σε Κελσίου. η διαφορά μεταξύ 10°C και 20°C είναι ίδια με αυτή μεταξύ 20°C και 30°C, αλλά 0°C δεν σημαίνει απουσία θερμοκρασίας.
- Κλίμακα αναλογίας: Η πιο κατατοπιστική κλίμακα έχει όλες τις ιδιότητες μιας κλίμακας διαστήματος συν ένα σημαντικό σημείο μηδέν, επιτρέποντας μια ακριβή σύγκριση μεγεθών. Παραδείγματα περιλαμβάνουν το βάρος, το ύψος και το εισόδημα. Εδώ, μπορούμε να πούμε ότι κάτι είναι διπλάσιο από ένα άλλο.
3. Περιγραφική Στατιστική
Imagine περιγραφικά στατιστικά ως το πρώτο σας ραντεβού με τα δεδομένα σας. Έχει να κάνει με το να γνωρίσεις τα βασικά, τις πλατιές πινελιές που περιγράφουν αυτό που έχεις μπροστά σου. Η περιγραφική στατιστική έχει δύο βασικούς τύπους: μέτρα κεντρικής τάσης και μεταβλητότητας.
Μέτρα Κεντρικής Τάσης: Αυτά είναι σαν το κέντρο βάρους των δεδομένων. Μας δίνουν μια ενιαία τιμή τυπική ή αντιπροσωπευτική του συνόλου δεδομένων μας.
Σημαίνω: Ο μέσος όρος υπολογίζεται αθροίζοντας όλες τις τιμές και διαιρώντας με τον αριθμό των τιμών. Είναι σαν τη συνολική βαθμολογία ενός εστιατορίου με βάση όλες τις κριτικές. Ο μαθηματικός τύπος για τον μέσο όρο δίνεται παρακάτω:

Διάμεσος: Η μεσαία τιμή όταν τα δεδομένα ταξινομούνται από το μικρότερο στο μεγαλύτερο. Εάν ο αριθμός των παρατηρήσεων είναι άρτιος, είναι ο μέσος όρος των δύο μεσαίων αριθμών. Χρησιμοποιείται για την εύρεση του μεσαίου σημείου μιας γέφυρας.
Αν το n είναι άρτιο, η διάμεσος είναι ο μέσος όρος των δύο κεντρικών αριθμών.
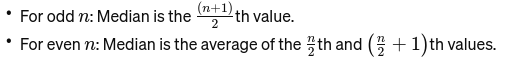
Τρόπος: Είναι η τιμή που εμφανίζεται πιο συχνά σε ένα σύνολο δεδομένων. Σκεφτείτε το ως το πιο δημοφιλές πιάτο σε ένα εστιατόριο.
Μέτρα μεταβλητότητας: Ενώ τα μέτρα κεντρικής τάσης μας φέρνουν στο κέντρο, τα μέτρα μεταβλητότητας μας λένε για τη διάδοση ή τη διασπορά.
Περιοχή: Η διαφορά μεταξύ της υψηλότερης και της χαμηλότερης τιμής. Δίνει μια βασική ιδέα της εξάπλωσης.
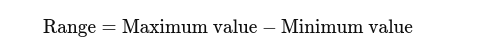
Διαφορά: Μετρά πόσο απέχει κάθε αριθμός στο σύνολο από τον μέσο όρο και επομένως από κάθε άλλο αριθμό στο σύνολο. Για ένα δείγμα, υπολογίζεται ως εξής:
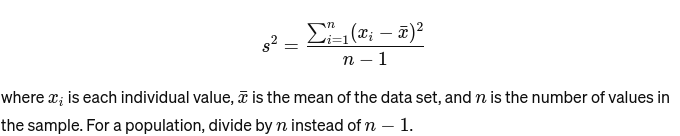
Τυπική απόκλιση: Η τετραγωνική ρίζα της διακύμανσης παρέχει ένα μέτρο της μέσης απόστασης από τη μέση τιμή. Είναι σαν να αξιολογείς τη συνοχή των μεγεθών κέικ ενός αρτοποιού. Αντιπροσωπεύεται ως:
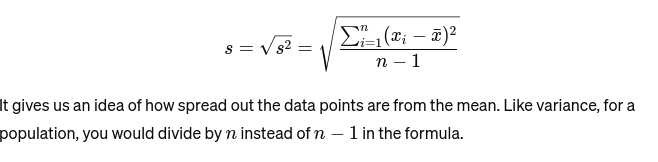
Πριν περάσουμε στην επόμενη βασική ιδέα της στατιστικής, ορίστε ένα Οδηγός για αρχάριους για στατιστική ανάλυση για σας!
4. Οπτικοποίηση δεδομένων
Οπτικοποίηση δεδομένων είναι η τέχνη και η επιστήμη της αφήγησης ιστοριών με δεδομένα. Μετατρέπει πολύπλοκα αποτελέσματα από την ανάλυσή μας σε κάτι απτό και κατανοητό. Είναι ζωτικής σημασίας για την διερευνητική ανάλυση δεδομένων, όπου ο στόχος είναι να αποκαλυφθούν μοτίβα, συσχετίσεις και γνώσεις από δεδομένα χωρίς ακόμη να βγαίνουν επίσημα συμπεράσματα.
- Διαγράμματα και γραφήματα: Ξεκινώντας από τα βασικά, τα γραφήματα ράβδων, τα γραφήματα γραμμής και τα γραφήματα πίτας παρέχουν θεμελιώδεις πληροφορίες για τα δεδομένα. Είναι τα ABC της οπτικοποίησης δεδομένων, απαραίτητα για κάθε αφηγητή δεδομένων.
Έχουμε ένα παράδειγμα ραβδωτού γραφήματος (αριστερά) και γραμμικού γραφήματος (δεξιά) παρακάτω.
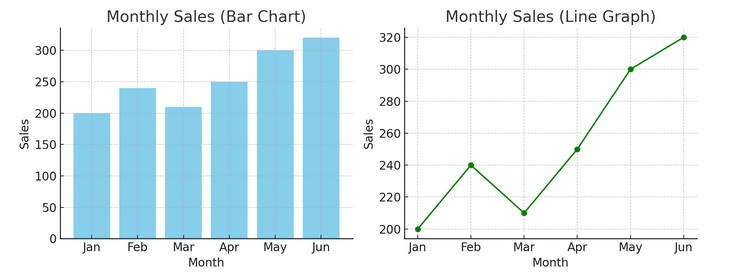
- Προηγμένες οπτικοποιήσεις: Καθώς βουτάμε βαθύτερα, οι χάρτες θερμότητας, τα διαγράμματα διασποράς και τα ιστογράμματα επιτρέπουν πιο λεπτή ανάλυση. Αυτά τα εργαλεία βοηθούν στον εντοπισμό τάσεων, διανομών και ακραίων τιμών.
Παρακάτω είναι ένα παράδειγμα γραφικής παράστασης διασποράς και ιστογράμματος

Οι οπτικοποιήσεις γεφυρώνουν τα ακατέργαστα δεδομένα και την ανθρώπινη γνώση, επιτρέποντάς μας να ερμηνεύσουμε και να κατανοήσουμε γρήγορα σύνθετα σύνολα δεδομένων.
5. Βασικά Πιθανότητες
Πιθανότητα είναι η γραμματική της γλώσσας της στατιστικής. Αφορά την πιθανότητα ή την πιθανότητα να συμβούν γεγονότα. Η κατανόηση των εννοιών στην πιθανότητα είναι απαραίτητη για την ερμηνεία των στατιστικών αποτελεσμάτων και την πραγματοποίηση προβλέψεων.
- Ανεξάρτητες και εξαρτημένες εκδηλώσεις:
- Ανεξάρτητες εκδηλώσεις: Το αποτέλεσμα ενός γεγονότος δεν επηρεάζει το αποτέλεσμα ενός άλλου. Όπως το χτύπημα ενός κέρματος, έτσι και το να ρίξετε τα κεφάλια σε ένα χτύπημα δεν αλλάζει τις πιθανότητες για το επόμενο χτύπημα.
- Εξαρτημένα συμβάντα: Το αποτέλεσμα ενός γεγονότος επηρεάζει το αποτέλεσμα ενός άλλου. Για παράδειγμα, αν τραβήξετε ένα φύλλο από μια τράπουλα και δεν το αντικαταστήσετε, οι πιθανότητές σας να τραβήξετε ένα άλλο συγκεκριμένο φύλλο αλλάζουν.
Η πιθανότητα παρέχει τη βάση για την εξαγωγή συμπερασμάτων σχετικά με τα δεδομένα και είναι κρίσιμη για την κατανόηση της στατιστικής σημασίας και του ελέγχου υποθέσεων.
6. Κοινές Κατανομές Πιθανοτήτων
Κατανομές πιθανότητας είναι σαν διαφορετικά είδη στο στατιστικό οικοσύστημα, το καθένα προσαρμοσμένο στη θέση των εφαρμογών του.
- Κανονική κατανομή: Συχνά ονομάζεται καμπύλη καμπάνας λόγω του σχήματός της, αυτή η κατανομή χαρακτηρίζεται από τη μέση και τυπική της απόκλιση. Είναι μια κοινή υπόθεση σε πολλές στατιστικές δοκιμές, επειδή πολλές μεταβλητές κατανέμονται φυσικά με αυτόν τον τρόπο στον πραγματικό κόσμο.
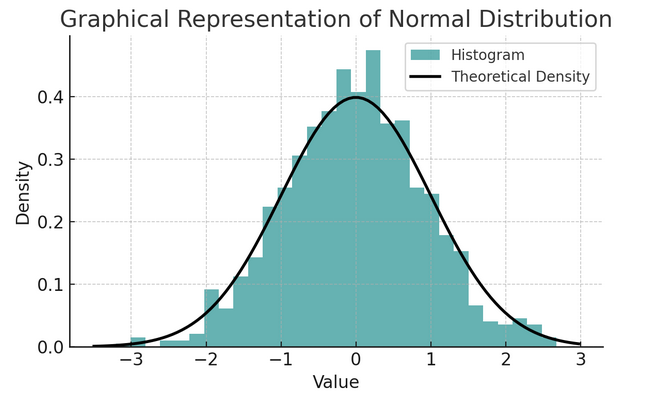
Ένα σύνολο κανόνων γνωστό ως εμπειρικός κανόνας ή κανόνας 68-95-99.7 συνοψίζει τα χαρακτηριστικά μιας κανονικής κατανομής, η οποία περιγράφει τον τρόπο με τον οποίο τα δεδομένα κατανέμονται γύρω από το μέσο όρο.
68-95-99.7 Κανόνας (Εμπειρικός Κανόνας)
Αυτός ο κανόνας ισχύει για μια απολύτως κανονική κατανομή και περιγράφει τα ακόλουθα:
- 68% των δεδομένων εμπίπτει σε μία τυπική απόκλιση (σ) του μέσου όρου (μ).
- 95% των δεδομένων εμπίπτουν σε δύο τυπικές αποκλίσεις του μέσου όρου.
- Περίπου 99.7% των δεδομένων εμπίπτουν σε τρεις τυπικές αποκλίσεις του μέσου όρου.
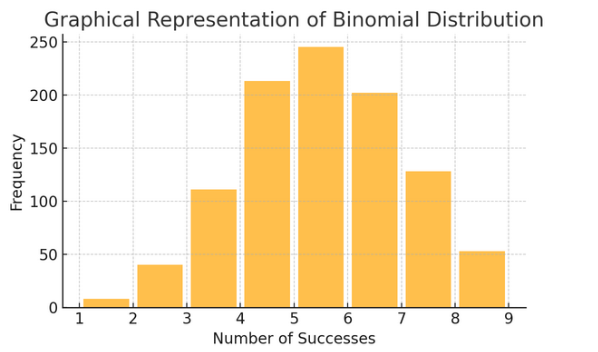
Διωνυμική κατανομή: Αυτή η κατανομή εφαρμόζεται σε καταστάσεις με δύο αποτελέσματα (όπως επιτυχία ή αποτυχία) που επαναλαμβάνονται πολλές φορές. Βοηθά στη μοντελοποίηση γεγονότων όπως η ανατροπή ενός νομίσματος ή η πραγματοποίηση ενός τεστ αληθούς/λάθους.
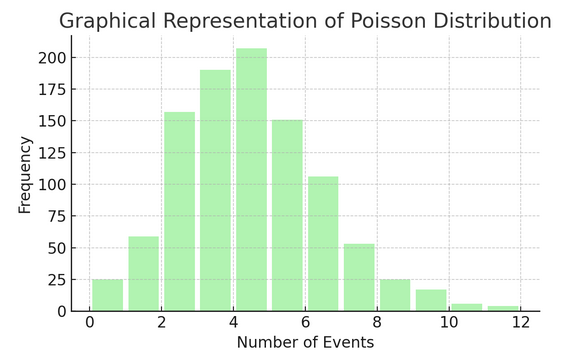
Διανομή Poisson μετράει πόσες φορές συμβαίνει κάτι σε ένα συγκεκριμένο διάστημα ή διάστημα. Είναι ιδανικό για καταστάσεις όπου τα γεγονότα συμβαίνουν ανεξάρτητα και συνεχώς, όπως τα καθημερινά email που λαμβάνετε.
Κάθε διανομή έχει το δικό της σύνολο τύπων και χαρακτηριστικών και η επιλογή του σωστού εξαρτάται από τη φύση των δεδομένων σας και από το τι προσπαθείτε να μάθετε. Η κατανόηση αυτών των κατανομών επιτρέπει στους στατιστικολόγους και τους επιστήμονες δεδομένων να μοντελοποιούν τα φαινόμενα του πραγματικού κόσμου και να προβλέπουν με ακρίβεια μελλοντικά γεγονότα.
7 . Έλεγχος Υποθέσεων
Σκέφτομαι δοκιμή υπόθεσης ως αστυνομική εργασία στη στατιστική. Είναι μια μέθοδος για να ελέγξουμε εάν μια συγκεκριμένη θεωρία σχετικά με τα δεδομένα μας θα μπορούσε να είναι αληθινή. Αυτή η διαδικασία ξεκινά με δύο αντίθετες υποθέσεις:
- Μηδενική υπόθεση (H0): Αυτή είναι η προεπιλεγμένη υπόθεση, υποδηλώνοντας ότι υπάρχει αποτέλεσμα ή διαφορά. Λέει, «Δεν είναι καινούργιο εδώ».
- Αλ «εναλλακτική υπόθεση (H1 ή Ha): Αυτό αμφισβητεί το status quo, προτείνοντας ένα αποτέλεσμα ή μια διαφορά. Ισχυρίζεται, «Κάτι ενδιαφέρον συμβαίνει».
Παράδειγμα: Έλεγχος εάν ένα νέο πρόγραμμα διατροφής οδηγεί σε απώλεια βάρους σε σύγκριση με τη μη τήρηση δίαιτας.
- Μηδενική υπόθεση (H0): Το νέο πρόγραμμα διατροφής δεν οδηγεί σε απώλεια βάρους (καμία διαφορά στην απώλεια βάρους μεταξύ αυτών που ακολουθούν το νέο πρόγραμμα διατροφής και αυτών που δεν το κάνουν).
- Εναλλακτική υπόθεση (Η1): Το νέο πρόγραμμα διατροφής οδηγεί σε απώλεια βάρους (διαφορά στην απώλεια βάρους μεταξύ αυτών που το ακολουθούν και αυτών που δεν το ακολουθούν).
Ο έλεγχος υποθέσεων περιλαμβάνει την επιλογή μεταξύ αυτών των δύο με βάση τα στοιχεία (τα δεδομένα μας).
Επίπεδα σφάλματος και σημασίας τύπου I και II:
- Σφάλμα τύπου I: Αυτό συμβαίνει όταν απορρίπτουμε λανθασμένα τη μηδενική υπόθεση. Καταδικάζει έναν αθώο άνθρωπο.
- Σφάλμα τύπου II: Αυτό συμβαίνει όταν αποτυγχάνουμε να απορρίψουμε μια ψευδή μηδενική υπόθεση. Αφήνει έναν ένοχο να απελευθερωθεί.
- Επίπεδο Σημασίας (α): Αυτό είναι το όριο για να αποφασιστεί πόσα στοιχεία είναι αρκετά για να απορριφθεί η μηδενική υπόθεση. Συχνά ορίζεται στο 5% (0.05), υποδεικνύοντας κίνδυνο 5% για σφάλμα τύπου Ι.
8. Διαστήματα εμπιστοσύνης
Διαστήματα εμπιστοσύνης δώστε μας ένα εύρος τιμών εντός των οποίων αναμένουμε ότι η έγκυρη παράμετρος πληθυσμού (όπως ένας μέσος όρος ή αναλογία) θα πέσει με ένα συγκεκριμένο επίπεδο εμπιστοσύνης (συνήθως 95%). Είναι σαν να προβλέπεις το τελικό σκορ μιας αθλητικής ομάδας με περιθώριο λάθους. λέμε, "Είμαστε 95% βέβαιοι ότι η πραγματική βαθμολογία θα είναι εντός αυτού του εύρους."
Η κατασκευή και η ερμηνεία των διαστημάτων εμπιστοσύνης μας βοηθά να κατανοήσουμε την ακρίβεια των εκτιμήσεών μας. Όσο μεγαλύτερο είναι το διάστημα, η εκτίμησή μας είναι λιγότερο ακριβής και το αντίστροφο.
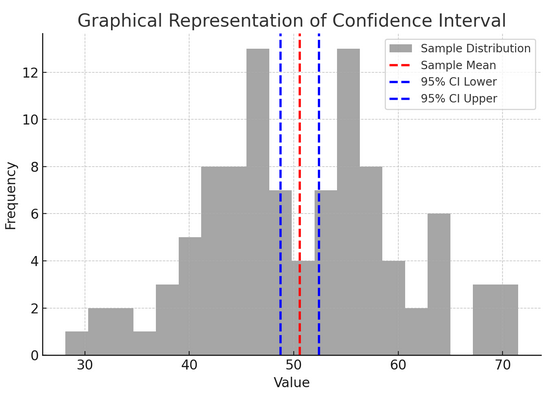
Το παραπάνω σχήμα απεικονίζει την έννοια του διαστήματος εμπιστοσύνης (CI) στις στατιστικές, χρησιμοποιώντας μια κατανομή δείγματος και το 95% του διαστήματος εμπιστοσύνης γύρω από τη μέση τιμή του δείγματος.
Ακολουθεί μια ανάλυση των κρίσιμων στοιχείων στο σχήμα:
- Κατανομή δείγματος (Γκρι Ιστόγραμμα): Αυτό αντιπροσωπεύει την κατανομή 100 σημείων δεδομένων που δημιουργούνται τυχαία από μια κανονική κατανομή με μέσο όρο 50 και τυπική απόκλιση 10. Το ιστόγραμμα απεικονίζει οπτικά πώς τα σημεία δεδομένων κατανέμονται γύρω από το μέσο όρο.
- Δείγμα μέσου όρου (Κόκκινη διακεκομμένη γραμμή): Αυτή η γραμμή υποδεικνύει τη μέση (μέση) τιμή του δείγματος δεδομένων. Χρησιμεύει ως η σημειακή εκτίμηση γύρω από την οποία κατασκευάζουμε το διάστημα εμπιστοσύνης. Σε αυτήν την περίπτωση, αντιπροσωπεύει τον μέσο όρο όλων των τιμών του δείγματος.
- Διάστημα εμπιστοσύνης 95% (Μπλε διακεκομμένες γραμμές): Αυτές οι δύο γραμμές σηματοδοτούν το κάτω και το ανώτερο όριο του διαστήματος εμπιστοσύνης 95% γύρω από τη μέση τιμή του δείγματος. Το διάστημα υπολογίζεται χρησιμοποιώντας το τυπικό σφάλμα του μέσου όρου (SEM) και ένα Z-score που αντιστοιχεί στο επιθυμητό επίπεδο εμπιστοσύνης (1.96 για 95% εμπιστοσύνη). Το διάστημα εμπιστοσύνης υποδηλώνει ότι είμαστε 95% σίγουροι ότι ο μέσος όρος του πληθυσμού βρίσκεται εντός αυτού του εύρους.
9. Συσχέτιση και αιτιότητα
Συσχέτιση και αιτιότητα συχνά μπερδεύονται, αλλά είναι διαφορετικά:
- Συσχέτιση: Υποδεικνύει μια σχέση ή συσχέτιση μεταξύ δύο μεταβλητών. Όταν το ένα αλλάζει, τείνει να αλλάξει και το άλλο. Η συσχέτιση μετριέται με έναν συντελεστή συσχέτισης που κυμαίνεται από -1 έως 1. Μια τιμή πιο κοντά στο 1 ή -1 δείχνει μια ισχυρή σχέση, ενώ το 0 υποδηλώνει ότι δεν υπάρχουν δεσμοί.
- Αιτία: Υπονοεί ότι οι αλλαγές σε μια μεταβλητή προκαλούν άμεσα αλλαγές σε μια άλλη. Είναι ένας ισχυρότερος ισχυρισμός από τον συσχετισμό και απαιτεί αυστηρό έλεγχο.
Ακριβώς επειδή δύο μεταβλητές συσχετίζονται δεν σημαίνει ότι η μία προκαλεί την άλλη. Αυτή είναι μια κλασική περίπτωση μη σύγχυσης της «συσχέτισης» με την «αιτιώδη συνάφεια».
10. Απλή Γραμμική Παλινδρόμηση
Απλούς γραμμικής παλινδρόμησης είναι ένας τρόπος να μοντελοποιήσουμε τη σχέση μεταξύ δύο μεταβλητών προσαρμόζοντας μια γραμμική εξίσωση στα παρατηρούμενα δεδομένα. Η μία μεταβλητή θεωρείται επεξηγηματική μεταβλητή (ανεξάρτητη) και η άλλη είναι εξαρτημένη μεταβλητή.
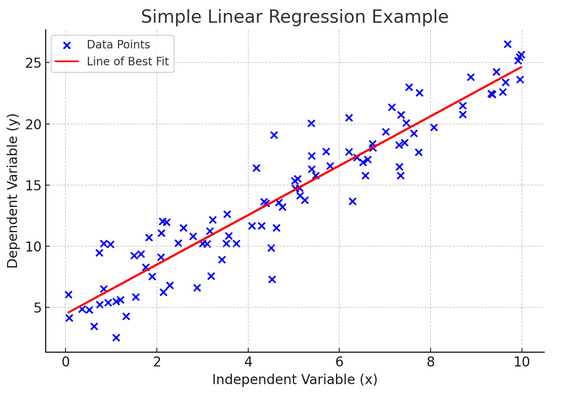
Η απλή γραμμική παλινδρόμηση μας βοηθά να κατανοήσουμε πώς οι αλλαγές στην ανεξάρτητη μεταβλητή επηρεάζουν την εξαρτημένη μεταβλητή. Είναι ένα ισχυρό εργαλείο πρόβλεψης και είναι θεμελιώδες για πολλά άλλα πολύπλοκα στατιστικά μοντέλα. Αναλύοντας τη σχέση μεταξύ δύο μεταβλητών, μπορούμε να κάνουμε εμπεριστατωμένες προβλέψεις για το πώς θα αλληλεπιδράσουν.
Η απλή γραμμική παλινδρόμηση προϋποθέτει μια γραμμική σχέση μεταξύ της ανεξάρτητης μεταβλητής (επεξηγηματική μεταβλητή) και της εξαρτημένης μεταβλητής. Εάν η σχέση μεταξύ αυτών των δύο μεταβλητών δεν είναι γραμμική, τότε οι υποθέσεις της απλής γραμμικής παλινδρόμησης μπορεί να παραβιαστούν, οδηγώντας ενδεχομένως σε ανακριβείς προβλέψεις ή ερμηνείες. Επομένως, η επαλήθευση μιας γραμμικής σχέσης στα δεδομένα είναι απαραίτητη πριν από την εφαρμογή απλής γραμμικής παλινδρόμησης.
11. Πολλαπλή Γραμμική Παλινδρόμηση
Σκεφτείτε την πολλαπλή γραμμική παλινδρόμηση ως επέκταση της απλής γραμμικής παλινδρόμησης. Ωστόσο, αντί να προσπαθείτε να προβλέψετε ένα αποτέλεσμα με έναν ιππότη με λαμπερή πανοπλία (πρόβλεψη), έχετε μια ολόκληρη ομάδα. Είναι σαν να αναβαθμίζεσαι από έναν αγώνα μπάσκετ ένας προς έναν σε μια ολόκληρη ομαδική προσπάθεια, όπου κάθε παίκτης (προγνωστικός) φέρνει μοναδικές δεξιότητες. Η ιδέα είναι να δούμε πώς πολλές μεταβλητές μαζί επηρεάζουν ένα μεμονωμένο αποτέλεσμα.
Ωστόσο, με μια μεγαλύτερη ομάδα έρχεται η πρόκληση της διαχείρισης σχέσεων, γνωστή ως πολυσυγγραμμικότητα. Συμβαίνει όταν οι προγνωστικοί παράγοντες είναι πολύ κοντά ο ένας στον άλλο και μοιράζονται παρόμοιες πληροφορίες. Φανταστείτε δύο μπασκετμπολίστες να προσπαθούν συνεχώς να κάνουν το ίδιο σουτ. μπορούν να μπουν εμπόδιο ο ένας στον άλλον. Η παλινδρόμηση μπορεί να κάνει δύσκολο να δούμε τη μοναδική συνεισφορά κάθε προγνωστικού παράγοντα, δυνητικά παραμορφώνοντας την κατανόησή μας για το ποιες μεταβλητές είναι σημαντικές.
12. Logistic Regression
Ενώ η γραμμική παλινδρόμηση προβλέπει συνεχή αποτελέσματα (όπως θερμοκρασία ή τιμές), λογική παλινδρόμηση χρησιμοποιείται όταν το αποτέλεσμα είναι καθορισμένο (όπως ναι/όχι, νίκη/ήττα). Φανταστείτε να προσπαθείτε να προβλέψετε εάν μια ομάδα θα κερδίσει ή θα χάσει με βάση διάφορους παράγοντες. Η λογιστική παλινδρόμηση είναι η στρατηγική σας.
Μετασχηματίζει τη γραμμική εξίσωση έτσι ώστε η έξοδος της να πέφτει μεταξύ 0 και 1, αντιπροσωπεύοντας την πιθανότητα να ανήκει σε μια συγκεκριμένη κατηγορία. Είναι σαν να έχουμε έναν μαγικό φακό που μετατρέπει τις συνεχείς βαθμολογίες σε μια σαφή προβολή "αυτό ή εκείνο", επιτρέποντάς μας να προβλέψουμε κατηγορηματικά αποτελέσματα.
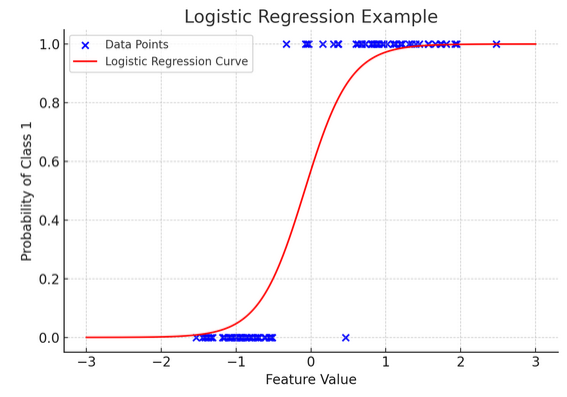
Η γραφική αναπαράσταση απεικονίζει ένα παράδειγμα λογιστικής παλινδρόμησης που εφαρμόζεται σε ένα συνθετικό δυαδικό σύνολο δεδομένων ταξινόμησης. Οι μπλε κουκκίδες αντιπροσωπεύουν τα σημεία δεδομένων, με τη θέση τους κατά μήκος του άξονα x να δείχνει την τιμή του χαρακτηριστικού και τον άξονα y να υποδεικνύει την κατηγορία (0 ή 1). Η κόκκινη καμπύλη αντιπροσωπεύει την πρόβλεψη του μοντέλου λογιστικής παλινδρόμησης για την πιθανότητα να ανήκει στην κλάση 1 (π.χ. «κερδίζει») για διαφορετικές τιμές χαρακτηριστικών. Όπως μπορείτε να δείτε, η καμπύλη μεταβαίνει ομαλά από την πιθανότητα της κλάσης 0 στην κλάση 1, καταδεικνύοντας την ικανότητα του μοντέλου να προβλέπει κατηγορικά αποτελέσματα με βάση ένα υποκείμενο συνεχές χαρακτηριστικό. ,
Ο τύπος για την λογιστική παλινδρόμηση δίνεται από:

Αυτός ο τύπος χρησιμοποιεί τη λογιστική συνάρτηση για να μετατρέψει την έξοδο της γραμμικής εξίσωσης σε πιθανότητα μεταξύ 0 και 1. Αυτός ο μετασχηματισμός μας επιτρέπει να ερμηνεύσουμε τις εξόδους ως πιθανότητες να ανήκουν σε μια συγκεκριμένη κατηγορία με βάση την τιμή της ανεξάρτητης μεταβλητής xx.
13. Δοκιμές ANOVA και Chi-Square
ANOVA (Analysis of Variance) και Τεστ Chi-Square είναι σαν ντετέκτιβ στον κόσμο της στατιστικής, που μας βοηθούν να λύσουμε διάφορα μυστήρια. Εγώt μας επιτρέπει να συγκρίνουμε μέσα σε πολλές ομάδες για να δούμε αν τουλάχιστον μία είναι στατιστικά διαφορετική. Σκεφτείτε το ως δείγματα γευσιγνωσίας από πολλές παρτίδες μπισκότων για να προσδιορίσετε εάν κάποια παρτίδα έχει σημαντικά διαφορετική γεύση.
Από την άλλη πλευρά, το τεστ Chi-Square χρησιμοποιείται για κατηγορικά δεδομένα. Μας βοηθά να καταλάβουμε αν υπάρχει σημαντική συσχέτιση μεταξύ δύο κατηγορικών μεταβλητών. Για παράδειγμα, υπάρχει σχέση μεταξύ του αγαπημένου είδους μουσικής ενός ατόμου και της ηλικιακής του ομάδας; Το τεστ Chi-Square βοηθά στην απάντηση σε τέτοιες ερωτήσεις.
14. Το κεντρικό οριακό θεώρημα και η σημασία του στην επιστήμη των δεδομένων
Η Κεντρικό οριακό θεώρημα (CLT) είναι μια θεμελιώδης στατιστική αρχή που μοιάζει σχεδόν μαγική. Μας λέει ότι αν πάρετε αρκετά δείγματα από έναν πληθυσμό και υπολογίσετε τους μέσους όρους τους, αυτοί οι μέσοι όροι θα σχηματίσουν μια κανονική κατανομή (την καμπύλη καμπάνας), ανεξάρτητα από την αρχική κατανομή του πληθυσμού. Αυτό είναι απίστευτα ισχυρό γιατί μας επιτρέπει να βγάλουμε συμπεράσματα για τους πληθυσμούς ακόμη και όταν δεν γνωρίζουμε την ακριβή κατανομή τους.
Στην επιστήμη των δεδομένων, το CLT στηρίζει πολλές τεχνικές, επιτρέποντάς μας να χρησιμοποιούμε εργαλεία σχεδιασμένα για κανονικά κατανεμημένα δεδομένα, ακόμη και όταν τα δεδομένα μας αρχικά δεν πληρούν αυτά τα κριτήρια. Είναι σαν να βρίσκεις έναν καθολικό προσαρμογέα για στατιστικές μεθόδους, κάνοντας πολλά ισχυρά εργαλεία εφαρμόσιμα σε περισσότερες περιπτώσεις.
15. Μεροληψία-Variance Tradeoff
In προγνωστική μοντελοποίηση και μάθηση μηχανής, τη συμβιβασμός μεροληψίας-διακύμανσης είναι μια κρίσιμη ιδέα που υπογραμμίζει την ένταση μεταξύ δύο κύριων τύπων σφαλμάτων που μπορούν να κάνουν τα μοντέλα μας να στραβώσουν. Η προκατάληψη αναφέρεται σε σφάλματα από υπερβολικά απλοϊκά μοντέλα που δεν αποτυπώνουν καλά τις υποκείμενες τάσεις. Φανταστείτε να προσπαθείτε να τοποθετήσετε μια ευθεία γραμμή μέσα από έναν καμπύλο δρόμο. θα χάσεις το σημάδι. Αντίθετα, οι διακυμάνσεις από πολύ περίπλοκα μοντέλα καταγράφουν τον θόρυβο στα δεδομένα σαν να ήταν ένα πραγματικό μοτίβο - όπως η παρακολούθηση κάθε στροφής και η στροφή σε ένα ανώμαλο μονοπάτι, νομίζοντας ότι είναι η πορεία προς τα εμπρός.
Η τέχνη έγκειται στην εξισορρόπηση αυτών των δύο για την ελαχιστοποίηση του συνολικού σφάλματος, βρίσκοντας το γλυκό σημείο όπου το μοντέλο σας είναι το σωστό—αρκετά πολύπλοκο για να καταγράψει τα ακριβή μοτίβα αλλά αρκετά απλό ώστε να αγνοήσει τον τυχαίο θόρυβο. Είναι σαν να κουρδίζεις μια κιθάρα. δεν θα ακούγεται σωστά αν είναι πολύ σφιχτό ή χαλαρό. Η αντιστάθμιση μεροληψίας-διακύμανσης αφορά την εύρεση της τέλειας ισορροπίας μεταξύ αυτών των δύο. Η αντιστάθμιση μεροληψίας-διακύμανσης είναι η ουσία της ρύθμισης των στατιστικών μας μοντέλων ώστε να αποδίδουν καλύτερα στην ακριβή πρόβλεψη των αποτελεσμάτων.
Συμπέρασμα
Από τη στατιστική δειγματοληψία έως την αντιστάθμιση μεροληψίας-διακύμανσης, αυτές οι αρχές δεν είναι απλές ακαδημαϊκές έννοιες αλλά βασικά εργαλεία για διορατική ανάλυση δεδομένων. Εξοπλίζουν τους επίδοξους επιστήμονες δεδομένων με τις δεξιότητες να μετατρέψουν τεράστια δεδομένα σε πρακτικές ιδέες, δίνοντας έμφαση στις στατιστικές ως τη ραχοκοκαλιά της λήψης αποφάσεων με γνώμονα τα δεδομένα και της καινοτομίας στην ψηφιακή εποχή.
Έχουμε χάσει κάποια βασική ιδέα της στατιστικής; Ενημερώστε μας στην παρακάτω ενότητα σχολίων.
Εξερευνήστε μας οδηγός στατιστικών από άκρη σε άκρη για να μάθει η επιστήμη των δεδομένων για το θέμα!
- SEO Powered Content & PR Distribution. Ενισχύστε σήμερα.
- PlatoData.Network Vertical Generative Ai. Ενδυναμώστε τον εαυτό σας. Πρόσβαση εδώ.
- PlatoAiStream. Web3 Intelligence. Ενισχύθηκε η γνώση. Πρόσβαση εδώ.
- PlatoESG. Ανθρακας, Cleantech, Ενέργεια, Περιβάλλον, Ηλιακός, Διαχείριση των αποβλήτων. Πρόσβαση εδώ.
- PlatoHealth. Ευφυΐα βιοτεχνολογίας και κλινικών δοκιμών. Πρόσβαση εδώ.
- πηγή: https://www.analyticsvidhya.com/blog/2024/03/basic-statistics-concepts/

