Μου πήρε πολύ χρόνο για να συνειδητοποιήσω ότι η αναζήτηση είναι το μεγαλύτερο πρόβλημα στο NLP. Απλώς κοιτάξτε το Google, το Amazon και το Bing. Αυτές είναι επιχειρήσεις πολλών δισεκατομμυρίων δολαρίων δυνατές μόνο λόγω των ισχυρών μηχανών αναζήτησης.
Οι αρχικές σκέψεις μου για την έρευνα επικεντρώθηκαν σε μη εποπτευόμενο ML, αλλά συμμετείχα Microsoft Hackathon 2018 για τον Bing και γνώρισε τους διάφορους τρόπους με τους οποίους μπορεί να γίνει μια μηχανή αναζήτησης με βαθιά μάθηση.
Τα ακόλουθα θέματα θα καλυφθούν σε αυτό το άρθρο:
Θεωρείτε ότι αυτή η σε βάθος τεχνική εκπαίδευση σχετικά με τις εφαρμογές NLP είναι χρήσιμη; Εγγραφείτε παρακάτω για να ενημερώνεστε όταν δημοσιεύουμε νέο σχετικό περιεχόμενο.
Κλασικές μηχανές αναζήτησης
Η διαδικασία αναζήτησης μπορεί να χωριστεί σε 4 βήματα:
- Αυτόματη συμπλήρωση ερωτήματος - Προτείνετε ερώτημα με βάση τους πρώτους χαρακτήρες που πληκτρολογούνται
- Φιλτράρισμα ερωτημάτων - Αφαίρεση διακριτικών, βλάβη και μείωση
- Αύξηση ερωτήματος - Προσθήκη συνωνύμων και συστολή / επέκταση αρκτικόλεξου
- Βαθμολόγηση εγγράφων - Βαθμολογία (έγγραφο | ερώτημα) σύμφωνα με τον μηχανισμό βαθμολόγησης που είναι κυρίως BM25
Τώρα χωρίς να ξοδέψω χρόνο για να εξηγήσω αυτά τα βήματα, θα αρχίσω να συζητώ τα μειονεκτήματα μιας κλασικής μηχανής αναζήτησης, όπως η Lucene, η οποία είναι η πιο δημοφιλής μηχανή αναζήτησης.
Πρόβλημα 1: Αντιστοίχιση διακριτικών
Φανταστείτε ότι ενδιαφέρομαι να βρω το καλύτερο βιβλίο Ο πίσω πολλαπλασιασμός. Σύμφωνα με τις κριτικές των χρηστών, Deep Learning από τους Ian Goodfellow et al. θεωρείται το καλύτερο στο θέμα και σε άλλους που το περιβάλλουν. Υπάρχει όμως μια πλήρης αναντιστοιχία λέξεων μεταξύ του Ερώτημα: Backpropagation και Τίτλος εγγράφου: Βαθιά μάθηση. Αυτά είναι τα αποτελέσματα του amazon.com. Το βιβλίο βαθιάς μάθησης δεν είναι εκεί!

Αποτέλεσμα για το ερώτημα "Backpropagation"
Αν και ψάχνω για βαθιά μάθηση, παίρνω το βιβλίο στην κορυφή.

Αποτέλεσμα για το ερώτημα «βαθιά μάθηση»
Αυτό είναι το πρόβλημα της σκληρής αντιστοίχισης.
Πρόβλημα 2: Εξατομίκευση
Το παραπάνω παράδειγμα λειτουργεί με ερωτήματα βαθιάς μάθησης. Τι γίνεται αν μου αρέσει να διαβάζω βιβλία με πρακτικά παραδείγματα αντί να διαβάζω τη θεωρία. Αυτό μας φέρνει στο θέμα του αναζήτηση με βάση τα συμφραζόμενα. Σε αυτήν την περίπτωση, αυτά τα βιβλία ήταν τέλεια για μένα. Δεν είναι;

Ένα πρακτικό βιβλίο για την εκμάθηση του «νευρικού δικτύου»

Ένα άλλο πρακτικό βιβλίο για την εκμάθηση «νευρωνικό δίκτυο»
Και γιατί στο διάολο βλέπω βιβλία για το NLP (Νευρογλωσσικός προγραμματισμός) όταν ψάχνω στο NLP! Η αναζήτηση με βάση τα συμφραζόμενα μπορεί να το λύσει - εάν η μηχανή αναζήτησης γνωρίζει ότι αγοράζω βιβλία για την επιστήμη των υπολογιστών, θα μου έδειχνε βιβλία για την επεξεργασία φυσικής γλώσσας.

And I get these when I search GAN. Again an issue of non-personalisation.

Πρόβλημα 3: Ερώτηση παρεξήγησης
Ερώτηση: επιρροή του x στο y Αποτελέσματα πρώτου επιστημονικού άρθρου: επιρροή του a στο x
Αντί να βρούμε την επιρροή του Bernhard στον ακαδημαϊκό, το πρώτο άρθρο αφορά την επιρροή του Herbart στον Bernhard.

Αναζητήθηκε στις 14 Νοεμβρίου 2019
Επειδή η μηχανή αντιστοίχισης διακριτικών δεν λαμβάνει υπόψη την ακολουθία των λέξεων, μπορεί να πετάξει λάθος αποτελέσματα. 😞
Ωστόσο, η παρόμοια πρόταση ερωτήματος της Google είναι καλύτερη!

Αναζητήθηκε στις 14 Νοεμβρίου 2019
Πρόβλημα 4: Αναζήτηση εικόνων
Τέλος, ο μόνος τρόπος με τον οποίο μπορούμε να αναζητήσουμε εικόνες με κείμενο είναι η δημιουργία μεταδεδομένων όλων των εικόνων με περιγραφές ή ετικέτες - κάτι που είναι πρακτικά αδύνατο.
Ποια είναι η επίδραση στη μέτρησή μας;
Εξαιτίας αυτού, η μέτρηση επηρεάζεται αρνητικά.
Σκληρή αντιστοίχιση διακριτικών → ΛΙΓΟΤΕΡΑ ΑΝΑΓΝΩΣΗ
Απουσία περιβάλλοντος → ΛΙΓΟΤΕΡΑ ΑΚΡΙΒΕΙΑ
Βαθιά μάθηση για αναζήτηση 🔥
Τώρα που έχετε κατανοήσει τα προβλήματα που σχετίζονται με την απλή αντιστοίχιση διακριτικών, μπορούμε να συζητήσουμε πώς να κάνουμε αναζήτηση χρησιμοποιώντας βαθιά μάθηση. Οι σκέψεις μου βασίζονται στο βιβλίο Βαθιά μάθηση για αναζήτηση από τον Tommaso Teofili.
Λύση 1: Δημιουργία συνωνύμων
Το πρόβλημα της αντιστοίχισης διακριτικών μπορεί να λυθεί με την αύξηση των λέξεων με συνώνυμες λέξεις μέσω ενός προσαρμοσμένου λεξικού στο Elasticsearch. Για αυτό, πρέπει να καταλάβω με μη αυτόματο τρόπο τις λέξεις που απαιτούν συνώνυμα και, στη συνέχεια, να βρω τα συνώνυμα τους. Αυτό είναι εύκολο να ξεκινήσετε αλλά είναι δύσκολο να το διατηρήσετε. Αντ 'αυτού, μπορούμε να αξιοποιήσουμε τη βαθιά μάθηση εδώ! Αρχικά βρίσκουμε το POS (Μέρος του λόγου) χρησιμοποιώντας μια βιβλιοθήκη όπως το Spacy και παίρνουμε συνώνυμα για λέξεις που έχουν POS (Μέρος του λόγου) ως ουσιαστικό, ρήμα ή επίθετο. Πρέπει να διατηρήσουμε την ομοιότητα του συνημίτονου για την επιλογή παρόμοιων λέξεων για να αποφύγουμε την προσθήκη πάρα πολλών ή άσχετων συνωνύμων.
Η αύξηση του συνωνύμου μπορεί να μας βοηθήσει να βελτιώσουμε την ανάκληση αλλά και να μειώσουμε την ακρίβεια 😅
Προσοχή ❌
Εδώ πρέπει να προσέξουμε να μην αυξήσουμε συγκεκριμένες λέξεις. Παραδόξως, οι πλησιέστερες λέξεις για «καλό» σύμφωνα με το word2vec είναι «κακές» και «κακές». Αυτό μπορεί να αλλάξει τα αποτελέσματα σε ορισμένες περιπτώσεις. 😅
Μπορείτε να δοκιμάσετε https://projector.tensorflow.org
Η πλησιέστερη λέξη για το «καταπληκτικό» σύμφωνα με το word2vec είναι η «αράχνη» που μπορεί να προέρχεται από την ταινία The Amazing Spider-Man. Αυτό μπορεί να οδηγήσει σε εκπληκτικά αποτελέσματα
Λύση 2: Αυτόματη συμπλήρωση ερωτήματος
Γιατί να μην βοηθήσετε τον χρήστη να ολοκληρώσει το ερώτημα σωστά όταν πληκτρολογεί έτσι ώστε το ολοκληρωμένο ερώτημα να μην φέρει κενό αποτέλεσμα! Το Elasticsearch διαθέτει επίσης δυνατότητα αυτόματης συμπλήρωσης ερωτήματος, αλλά είναι ένα πεπερασμένο αυτόματο. Εάν πληκτρολογήσετε μια ακολουθία χαρακτήρων που δεν εμφανίστηκε στο ευρετήριο, δεν θα εμφανίσει αποτελέσματα. Ενώ στην περίπτωση ενός γλωσσικού μοντέλου (LM), η γενιά δεν είναι πεπερασμένη. (Παρόλο που η παραγωγή LM ενδέχεται να αποτύχει για μεγαλύτερα ερωτήματα εάν το μοντέλο έχει εκπαιδευτεί για μικρότερες ακολουθίες.)
Δυνατότητα αυτόματης συμπλήρωσης ερωτημάτων έτσι ώστε το αποτέλεσμα να μην είναι κενό μπορεί να αλλάξει δραματικά την εμπειρία του χρήστη και να αποφύγει το churnout☺️
Κόλπο: Καταργήστε εκείνα τα ερωτήματα από την εκπαίδευση που επιστρέφουν κενά αποτελέσματα, καθώς δεν υπάρχει λόγος να προτείνετε ερωτήματα που θα οδηγήσουν σε κανένα αποτέλεσμα.
Λύση 3: Εναλλακτική δημιουργία ερωτημάτων
Εάν έχουμε ένα αρχείο καταγραφής ερωτημάτων από περιόδους σύνδεσης χρηστών, μπορούμε να εκπαιδεύσουμε ένα δημιουργικό μοντέλο για δημιουργία (επόμενο ερώτημα | τρέχον ερώτημα). Η υπόθεση είναι ότι όλα τα ερωτήματα σε μια συνεδρία είναι παρόμοια μεταξύ τους. Τα αρχεία καταγραφής μπορεί να είναι έτσι.
- Τεχνητή νοημοσύνη
- Τάση ροής
- Νευρωνικά δίκτυα
- ...
Δεδομένα εκπαίδευσης (x, y) (Τεχνητή νοημοσύνη, Tensorflow) (Tensorflow, Neural network)
Η δημιουργία ερωτημάτων μπορεί να μας βοηθήσει να προτείνουμε σχετικά ερωτήματα κατανοώντας την αγοραστική πρόθεση του χρήστη.
Λύση 4: Χρήση ενσωματώσεων λέξεων και εγγράφων
Μόλις το ερώτημα έχει εισαχθεί από τον χρήστη, αντί να το αντιπροσωπεύουμε σε μια κανονική ή TF-IDF κανονικοποιημένη μορφή, μπορούμε να διανύσουμε λέξεις, προτάσεις και έγγραφα χρησιμοποιώντας μερικές προσεγγίσεις.
- Απλός μέσος όρος ενσωμάτωσης
- Σταθμισμένος μέσος όρος ενσωμάτωσης πολλαπλασιάζοντας με τιμές IDF
- Ενσωμάτωση ποινών χρησιμοποιώντας ένα μοντέλο όπως infersent, USE (Universal πρόταση encoder), πρόταση-bert
- αυτόματης κωδικοποίησης seq2seq
Αυτό μπορεί να μας βοηθήσει να αντιπροσωπεύσουμε όλα τα διακριτικά στο α σημασιολογικά και συμπιεσμένα μορφή ενός φορέα σταθερού μεγέθους ανεξάρτητα από το μέγεθος του λεξιλογίου. Αυτό απαιτεί εφάπαξ βαρύ κόστος διανυσματοποίησης χρησιμοποιώντας το μοντέλο, αλλά όλες οι αναζητήσεις αργότερα θα είναι διανυσματική αναζήτηση σε διάσταση n. Η τρέχουσα κατάσταση στη διανυσματική αναζήτηση είναι&nb
sp;μιλβους. Φόρουμ κατά προσέγγιση κοντινός γείτονας μπορείτε να χρησιμοποιήσετε flann και ενοχλητικό.
Λύση 5: Εξατομίκευση
Παράγοντες που πρέπει να λαμβάνονται υπόψη από τη μηχανή αναζήτησης για εξατομίκευση / εξατομίκευση
- Ιστορικό χρήστη - Ενδιαφέροντα από την προηγούμενη αναζήτησή του και αν έκανε την ίδια αναζήτηση στο παρελθόν, τι έκανε κλικ
- Γεωγραφία χρήστη - Η αναζήτηση της λέξης «πρόεδρος» μου δίνει τον «Ram Nath Kovind» → τον σημερινό πρόεδρο της Ινδίας
- Χρονικές αλλαγές στις πληροφορίες - Το αποτέλεσμα του ερωτήματος «πρόεδρος» θα αλλάξει με την πάροδο του χρόνου
Το ιστορικό χρήστη μπορεί να χρησιμοποιηθεί κωδικοποιώντας κάθε κλικ ως σταθερό διάνυσμα και δημιουργία αποτελεσμάτων (έγγραφο | ιστορικό + ερώτημα)
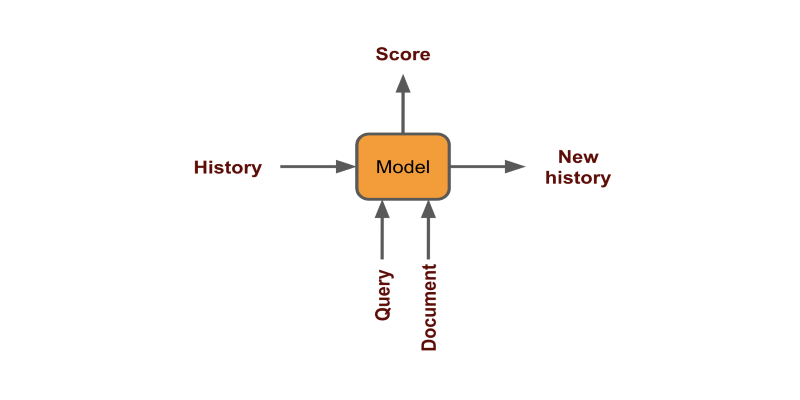
Η γεωγραφία και η χρονική μπορούν να ληφθούν υπόψη είτε φιλτράροντας είτε προσθέτοντάς τα ως χαρακτηριστικά κατά την εκπαίδευση του μοντέλου.
Η εξατομίκευση μας επιτρέπει να παρέχουμε προτάσεις σε επίπεδο ανθρώπου στον χρήστη, οι οποίες μπορούν να μας βοηθήσουν να βελτιώσουμε τη μετατροπή.
Λύση 6: Εκμάθηση κατάταξης
Λόγω των ελαττωμάτων της αντιστοίχισης διακριτικών στο σχήμα TF-IDF, χρειαζόμαστε πραγματικά ένα επίπεδο που μπορεί να επαναξιολογήσει τα αποτελέσματα. Το σχήμα έχει υψηλή μεροληψία για σπάνιες λέξεις και επίσης δεν λαμβάνει υπόψη τη δυνατότητα μετατροπής ενός άρθρου. Εάν έχουμε ένα αρχείο καταγραφής ερωτημάτων χρηστών και τι έκαναν κλικ στα αποτελέσματα αναζήτησης, μπορούμε να εκπαιδεύσουμε το μοντέλο για να ταξινομήσουμε τα έγγραφα. Τα δεδομένα θα μοιάζουν με αυτό. (x, y) (Τεχνητή νοημοσύνη, τίτλος βιβλίου 2) (Tensorflow, τίτλος βιβλίου 1) (Νευρωνικά δίκτυα, τίτλος βιβλίου 4) Την επόμενη φορά που θα θέλουμε να δείξουμε αποτελέσματα, θα λάβουμε πρώτα τα κορυφαία αποτελέσματα x από μια φτηνή διαδικασία αντιστοίχισης διακριτικών μέσω TF-IDF / BM25, κυρίως μέσω του Elasticsearch και, στη συνέχεια, να δημιουργήσετε μια βαθμολογία για όλα τα ζεύγη. (x, ε)
- (ερώτημα, τίτλος 1) → σκορ 1
- (ερώτημα, τίτλος 2) → σκορ 2
- ...
Στη συνέχεια ταξινομούμε τους τίτλους με βάση το σκορ και δείχνουμε κορυφαία αποτελέσματα. Μπορείτε να βρείτε μια εφαρμογή αυτού χρησιμοποιώντας το BERT στο my GitHub.

BERT με κεφαλή NSP
Μπορούμε να ορίσουμε την εκμάθηση για να ταξινομήσουμε το πρόβλημα ως BERT NextSentencePrediction πρόβλημα - γνωστό και ως πρόβλημα εμπλοκής.
Λύση 7: Σύνολο
Στις περισσότερες περιπτώσεις, είναι πλεονεκτικό να αξιοποιήσετε και τις δύο προσεγγίσεις. Το βιβλίο αναφέρει ότι η χρήση ενός συνδυασμένου σκορ wordvector και BM25 λειτουργεί καλύτερα.

Από το "Deep learning for search"
Το Ensemble μας επιτρέπει να εκμεταλλευόμαστε καλύτερα τις δύο προσεγγίσεις - σκληρό ταίριασμα + σημασιολογία.
Λύση 8: Πολυγλωσσική αναζήτηση
Προσέγγιση 1

Σε ορισμένες περιπτώσεις, όταν η εφαρμογή βρίσκεται σε όλη τη γεωγραφία, η γλώσσα του χρήστη μπορεί να διαφέρει από το έγγραφο. Μια τέτοια αναζήτηση δεν είναι δυνατή με την κλασική προσέγγιση αναζήτησης, καθώς τα διακριτικά διαφορετικών γλωσσών δεν μπορούν να ταιριάζουν. Αυτό απαιτεί τη βοήθεια της μηχανικής μετάφρασης με βαθιά μάθηση.
- Εντοπισμός της γλώσσας του ερωτήματος χρήστη (π.χ. Γαλλικά)
- Μετάφραση ερωτήματος σε όλες τις γλώσσες για τις οποίες διαθέτουμε τα έγγραφα (Γαλλικά σε Αγγλικά, Γερμανικά και Ισπανικά)
- Αναζήτηση εγγράφων
- Μετάφραση όλων των εγγράφων με κορυφαία βαθμολογία στη γλώσσα του χρήστη (Αγγλικά, Γερμανικά και Ισπανικά σε Γαλλικά)
Προσέγγιση 2
Αντ 'αυτού μπορούμε να χρησιμοποιήσουμε έναν πολύγλωσσο κωδικοποιητή προτάσεων για την αναπαράσταση κειμένου από οποιαδήποτε γλώσσα σε παρόμοια διανύσματα. Ας διερευνήσουμε λεπτομερώς αυτήν την προσέγγιση.
Πολύγλωσσο Universal Sentence Encoder
Παίρνω αυτά τα στοιχεία για να κάνω το POC:
- Μοντέλο - Πολυγλωσσικός κωδικοποιητής Universal Sentence
- Διάνυσμα αναζήτηση - FAISS
- ημερομηνία - Ζεύγος ερωτήσεων Quora από κουρέλι
Μπορείτε να διαβάσετε περισσότερα για το USE στο αυτό το χαρτί. Υποστηρίζει 16 γλώσσες.
ΒΗΜΑ 1. ΔΕΔΟΜΕΝΑ ΦΟΡΤΩΣΗΣ
Ας διαβάσουμε πρώτα τα δεδομένα. Επειδή το σύνολο δεδομένων quora είναι τεράστιο και απαιτεί πολύ χρόνο, θα πάρουμε μόνο το 1% των δεδομένων. Αυτό θα διαρκέσει περίπου 3 λεπτά για την κωδικοποίηση και την ευρετηρίαση. Θα έχει 4000 ερωτήσεις.
df = pd.read_csv('quora-question-pairs/train.csv')
df = df.sample(frac=0.01, random_state=1)
df.dropna(inplace=True)
questions = df.question1.values
ΒΗΜΑ 2. ΔΗΜΙΟΥΡΓΙΑ ΕΓΓΡΑΦΗ
Ας κάνουμε τάξεις κωδικοποιητή που φορτώνουν το μοντέλο και έχουν μια μέθοδο κωδικοποίησης. Έχω δημιουργήσει μαθήματα για διαφορετικά μοντέλα τα οποία μπορείτε να χρησιμοποιήσετε. Όλα τα μοντέλα λειτουργούν με αγγλικά και χρησιμοποιούν μόνο πολύγλωσσες εργασίες με άλλες γλώσσες.
Το USE κωδικοποιεί κείμενο σε σταθερό διάνυσμα μεγέθους 512.
Χρησιμοποιώ TFHub για χρήση και Flair για BERT για φόρτωση των μοντέλων.
class TFEncoder(metaclass=ABCMeta): """Base encoder to be used for all encoders.""" def __init__(self, model_path:str): self.model = hub.load(model_path) @abstractmethod def encode(self, text:list): """Encodes text. Text: should be a list of strings to encode """ class USE(TFEncoder): """Universal sentence encoder""" def __init__(self, model_path): super().__init__(model_path) def encode(self, text): return self.model(text).numpy() class USEQA(TFEncoder): """Universal sentence encoder trained on Question Answer pairs""" def __init__(self, model_path): super().__init__(model_path) def encode(self, text): return self.model.signatures['question_encoder'](tf.constant(s))['outputs'].numpy() class BERT(): """BERT models""" def __init__(self, model_name, layers="-2", pooling_operation="mean"): self.embeddings = BertEmbeddings(model_name, layers=layers, pooling_operation=pooling_operation) self.document_embeddings = DocumentPoolEmbeddings([self.embeddings], fine_tune_mode='nonlinear') def encode(self, text): sentence = Sentence(text) self.document_embeddings.embed(sentence) return sentence.embedding.detach().numpy().reshape(1, -1) model_path = "https://tfhub.dev/google/universal-sentence-encoder-multilingual-large/3" encoder = USE(model_path)
ΒΗΜΑ 3. ΔΗΜΙΟΥΡΓΙΑ ΔΕΙΚΤΗΣ
Τώρα θα δημιουργήσουμε την κλάση ευρετηρίου FAISS η οποία θα αποθηκεύει όλες τις ενσωματώσεις αποτελεσματικά για γρήγορη αναζήτηση διανυσμάτων.
class FAISS: def __init__(self, dimensions:int): self.dimensions = dimensions self.index = faiss.IndexFlatL2(dimensions) self.vectors = {} self.counter = 0 def add(self, text:str, v:list): self.index.add(v) self.vectors[self.counter] = (text, v) self.counter += 1 def search(self, v:list, k:int=10): distance, item_index = self.index.search(v, k) for dist, i in zip(distance[0], item_index[0]): if i==-1: break else: print(f'{self.vectors[i][0]}, %.2f'%dist)
ΒΗΜΑ 4. ΚΩΔΙΚΟΣ ΚΑΙ ΔΕΙΚΤΗΣ
Ας δημιουργήσουμε ενσωματώσεις για όλες τις ερωτήσεις και αποθηκεύστε τις στο FAISS. Καθορίζουμε μια μέθοδο αναζήτησης που μας δείχνει τα κορυφαία k παρόμοια αποτελέσματα με ένα ερώτημα.
d = encoder.encode(['hello']).shape[-1] # get dimension of emb index = FAISS(d) #index all questions for q in tqdm(questions): emb = encoder.encode([q]) index.add(q, emb) # embed and search a question def search(s, k=10): emb = encoder.encode([s]) index.search(emb, k)
ΒΗΜΑ 5. ΑΝΑΖΗΤΗΣΗ
Παρακάτω μπορούμε να δούμε τα αποτελέσματα του μοντέλου. Αρχικά γράφουμε μια ερώτηση στα Αγγλικά και δίνει αναμενόμενα αποτελέσματα. Στη συνέχεια, μετατρέπουμε το ερώτημα σε άλλες γλώσσες χρησιμοποιώντας το Google Translate και τα αποτελέσματα είναι εξαιρετικά καλά. Παρόλο που έχω κάνει ορθογραφικό λάθος να γράψω «χαλαρά» αντί για «χάσει», το μοντέλο το κατανοεί καθώς λειτουργεί σε επίπεδο υπο-λέξης και είναι συμφραζόμενα.

Όπως μπορείτε να δείτε, τα αποτελέσματα είναι τόσο εντυπωσιακά που το μοντέλο αξίζει να τεθεί σε παραγωγή.
Μπορείτε να βρείτε τον πλήρη κωδικό στο το φορητό μου σημειωματάριο. Μπορείτε να κατεβάσετε δεδομένα από εδώ.
Για να δημιουργήσετε καλύτερα μοντέλα, πρέπει να συντονίσετε το γλωσσικό μοντέλο για τα δεδομένα σας χρησιμοποιώντας την εκμάθηση μεταφοράς. Μπορείτε να διαβάσετε περισσότερα σε αυτό στο my τελευταίο άρθρο.
Και εδώ μπορείτε να διαβάσετε περισσότερα σχετικά με διαφορετικά μοντέλα κωδικοποίησης κειμένου για σημασιολογική αναζήτηση.
Συμπέρασμα
Ίσως γνωρίζετε ήδη ότι πρόσφατα η Google ώθησε την εφαρμογή με βάση το BERT στην παραγωγή για τη βελτίωση των αποτελεσμάτων αναζήτησης. Φαίνεται ότι η σημασιολογική αναζήτηση βρίσκεται σε άνοδο και θα γίνει κοινή στον κλάδο καθώς κατανοούμε περισσότερο την αξιοποίηση της βαθιάς μάθησης για αναζήτηση.
Αυτό το άρθρο δημοσιεύθηκε αρχικά στο Medium (μέρος 1 και μέρος 2) και επανεκδόθηκε στα TOPBOTS με άδεια του συγγραφέα.
Απολαύστε αυτό το άρθρο; Εγγραφείτε για περισσότερες ενημερώσεις AI και NLP.
Θα σας ενημερώσουμε όταν θα εκδώσουμε μια πιο εις βάθος τεχνική εκπαίδευση.

