Σε αυτήν την ανάρτηση, δείχνουμε πώς να τελειοποιήσετε αποτελεσματικά ένα μοντέλο γλώσσας πρωτεΐνης τελευταίας τεχνολογίας (pLM) για να προβλέψετε τον υποκυτταρικό εντοπισμό πρωτεΐνης χρησιμοποιώντας Amazon Sage Maker.
Οι πρωτεΐνες είναι οι μοριακές μηχανές του σώματος, υπεύθυνες για τα πάντα, από την κίνηση των μυών σας μέχρι την απόκριση σε λοιμώξεις. Παρά αυτή την ποικιλία, όλες οι πρωτεΐνες αποτελούνται από επαναλαμβανόμενες αλυσίδες μορίων που ονομάζονται αμινοξέα. Το ανθρώπινο γονιδίωμα κωδικοποιεί 20 τυπικά αμινοξέα, το καθένα με ελαφρώς διαφορετική χημική δομή. Αυτά μπορούν να αναπαρασταθούν με γράμματα του αλφαβήτου, το οποίο στη συνέχεια μας επιτρέπει να αναλύουμε και να εξερευνούμε πρωτεΐνες ως συμβολοσειρά κειμένου. Ο τεράστιος πιθανός αριθμός αλληλουχιών και δομών πρωτεϊνών είναι αυτό που δίνει στις πρωτεΐνες τη μεγάλη ποικιλία χρήσεων τους.
Οι πρωτεΐνες παίζουν επίσης βασικό ρόλο στην ανάπτυξη φαρμάκων, ως πιθανοί στόχοι αλλά και ως θεραπευτικοί παράγοντες. Όπως φαίνεται στον παρακάτω πίνακα, πολλά από τα φάρμακα με τις μεγαλύτερες πωλήσεις το 2022 ήταν είτε πρωτεΐνες (ειδικά αντισώματα) είτε άλλα μόρια όπως το mRNA μεταφρασμένα σε πρωτεΐνες στο σώμα. Εξαιτίας αυτού, πολλοί ερευνητές της βιοεπιστήμης πρέπει να απαντήσουν σε ερωτήσεις σχετικά με τις πρωτεΐνες πιο γρήγορα, φθηνότερα και με μεγαλύτερη ακρίβεια.
| Όνομα | Κατασκευαστής | Παγκόσμιες πωλήσεις 2022 (δισεκατομμύρια δολάρια ΗΠΑ) | Ενδείξεις |
| Comirnaty | Pfizer / BioNTech | $40.8 | Covid-19 |
| Spikevax | Μοντέρνα | $21.8 | Covid-19 |
| Humira | AbbVie | $21.6 | Αρθρίτιδα, νόσο του Crohn και άλλα |
| Keytruda | Η Merck | $21.0 | Διάφοροι καρκίνοι |
Πηγή δεδομένων: Urquhart, L. Κορυφαίες εταιρείες και φάρμακα ανά πωλήσεις το 2022. Nature Reviews Drug Discovery 22, 260–260 (2023).
Επειδή μπορούμε να αναπαραστήσουμε τις πρωτεΐνες ως ακολουθίες χαρακτήρων, μπορούμε να τις αναλύσουμε χρησιμοποιώντας τεχνικές που αναπτύχθηκαν αρχικά για τη γραπτή γλώσσα. Αυτό περιλαμβάνει μεγάλα γλωσσικά μοντέλα (LLM) προεκπαιδευμένα σε τεράστια σύνολα δεδομένων, τα οποία στη συνέχεια μπορούν να προσαρμοστούν για συγκεκριμένες εργασίες, όπως σύνοψη κειμένου ή chatbots. Ομοίως, τα pLM εκπαιδεύονται εκ των προτέρων σε μεγάλες βάσεις δεδομένων αλληλουχίας πρωτεϊνών χρησιμοποιώντας μη επισημασμένη, αυτο-εποπτευόμενη μάθηση. Μπορούμε να τα προσαρμόσουμε για να προβλέψουμε πράγματα όπως η τρισδιάστατη δομή μιας πρωτεΐνης ή πώς μπορεί να αλληλεπιδράσει με άλλα μόρια. Οι ερευνητές έχουν χρησιμοποιήσει ακόμη και pLM για να σχεδιάσουν νέες πρωτεΐνες από την αρχή. Αυτά τα εργαλεία δεν αντικαθιστούν την ανθρώπινη επιστημονική τεχνογνωσία, αλλά έχουν τη δυνατότητα να επιταχύνουν την προκλινική ανάπτυξη και τον σχεδιασμό δοκιμών.
Μια πρόκληση με αυτά τα μοντέλα είναι το μέγεθός τους. Τόσο τα LLM όσο και τα pLM έχουν αυξηθεί κατά τάξεις μεγέθους τα τελευταία χρόνια, όπως φαίνεται στο παρακάτω σχήμα. Αυτό σημαίνει ότι μπορεί να χρειαστεί πολύς χρόνος για να τα εκπαιδεύσετε με επαρκή ακρίβεια. Σημαίνει επίσης ότι πρέπει να χρησιμοποιήσετε υλικό, ειδικά GPU, με μεγάλες ποσότητες μνήμης για να αποθηκεύσετε τις παραμέτρους του μοντέλου.
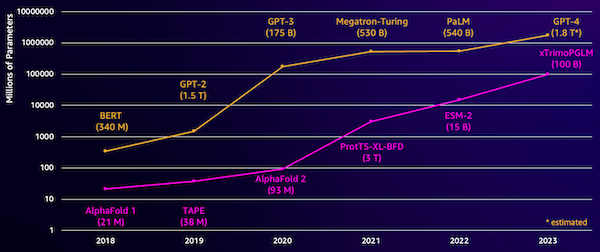
Οι μεγάλοι χρόνοι εκπαίδευσης, καθώς και οι μεγάλες περιπτώσεις, ισοδυναμούν με υψηλό κόστος, το οποίο μπορεί να θέσει αυτή την εργασία απρόσιτη για πολλούς ερευνητές. Για παράδειγμα, το 2023, α ερευνητική ομάδα περιέγραψε την εκπαίδευση ενός pLM 100 δισεκατομμυρίων παραμέτρων σε 768 GPU A100 για 164 ημέρες! Ευτυχώς, σε πολλές περιπτώσεις μπορούμε να εξοικονομήσουμε χρόνο και πόρους προσαρμόζοντας ένα υπάρχον pLM στη συγκεκριμένη εργασία μας. Αυτή η τεχνική ονομάζεται τελειοποίηση, και μας επιτρέπει επίσης να δανειστούμε προηγμένα εργαλεία από άλλους τύπους μοντελοποίησης γλώσσας.
Επισκόπηση λύσεων
Το συγκεκριμένο πρόβλημα που αντιμετωπίζουμε σε αυτήν την ανάρτηση είναι υποκυτταρικός εντοπισμός: Με δεδομένη μια αλληλουχία πρωτεΐνης, μπορούμε να φτιάξουμε ένα μοντέλο που να μπορεί να προβλέψει εάν ζει στο εξωτερικό (κυτταρική μεμβράνη) ή στο εσωτερικό ενός κυττάρου; Αυτή είναι μια σημαντική πληροφορία που μπορεί να μας βοηθήσει να κατανοήσουμε τη λειτουργία και αν θα ήταν καλός στόχος φαρμάκου.
Ξεκινάμε κατεβάζοντας ένα δημόσιο σύνολο δεδομένων χρησιμοποιώντας Στούντιο Amazon SageMaker. Στη συνέχεια χρησιμοποιούμε το SageMaker για να τελειοποιήσουμε το μοντέλο γλώσσας πρωτεΐνης ESM-2 χρησιμοποιώντας μια αποτελεσματική μέθοδο εκπαίδευσης. Τέλος, αναπτύσσουμε το μοντέλο ως τελικό σημείο συμπερασμάτων σε πραγματικό χρόνο και το χρησιμοποιούμε για να δοκιμάσουμε ορισμένες γνωστές πρωτεΐνες. Το παρακάτω διάγραμμα απεικονίζει αυτή τη ροή εργασίας.

Στις επόμενες ενότητες, ακολουθούμε τα βήματα για να προετοιμάσουμε τα δεδομένα εκπαίδευσης, να δημιουργήσουμε ένα σενάριο εκπαίδευσης και να εκτελέσουμε μια εργασία εκπαίδευσης του SageMaker. Όλος ο κώδικας που εμφανίζεται σε αυτήν την ανάρτηση είναι διαθέσιμος στο GitHub.
Προετοιμάστε τα δεδομένα εκπαίδευσης
Χρησιμοποιούμε μέρος του Δεδομένα DeepLoc-2, το οποίο περιέχει αρκετές χιλιάδες πρωτεΐνες SwissProt με πειραματικά προσδιορισμένες θέσεις. Φιλτράρουμε για αλληλουχίες υψηλής ποιότητας μεταξύ 100-512 αμινοξέων:
df = pd.read_csv(
"https://services.healthtech.dtu.dk/services/DeepLoc-2.0/data/Swissprot_Train_Validation_dataset.csv"
).drop(["Unnamed: 0", "Partition"], axis=1)
df["Membrane"] = df["Membrane"].astype("int32")
# filter for sequences between 100 and 512 amino acides
df = df[df["Sequence"].apply(lambda x: len(x)).between(100, 512)]
# Remove unnecessary features
df = df[["Sequence", "Kingdom", "Membrane"]]
Στη συνέχεια, προσαρμόζουμε τις ακολουθίες και τις χωρίζουμε σε σετ εκπαίδευσης και αξιολόγησης:
dataset = Dataset.from_pandas(df).train_test_split(test_size=0.2, shuffle=True)
tokenizer = AutoTokenizer.from_pretrained("facebook/esm2_t33_650M_UR50D")
def preprocess_data(examples, max_length=512):
text = examples["Sequence"]
encoding = tokenizer(text, truncation=True, max_length=max_length)
encoding["labels"] = examples["Membrane"]
return encoding
encoded_dataset = dataset.map(
preprocess_data,
batched=True,
num_proc=os.cpu_count(),
remove_columns=dataset["train"].column_names,
)
encoded_dataset.set_format("torch")
Τέλος, ανεβάζουμε τα επεξεργασμένα δεδομένα εκπαίδευσης και αξιολόγησης στο Απλή υπηρεσία αποθήκευσης Amazon (Amazon S3):
train_s3_uri = S3_PATH + "/data/train"
test_s3_uri = S3_PATH + "/data/test"
encoded_dataset["train"].save_to_disk(train_s3_uri)
encoded_dataset["test"].save_to_disk(test_s3_uri)Δημιουργήστε ένα σενάριο εκπαίδευσης
Λειτουργία σεναρίου SageMaker σας επιτρέπει να εκτελείτε τον προσαρμοσμένο σας κώδικα εκπαίδευσης σε κοντέινερ πλαισίου βελτιστοποιημένης μηχανικής εκμάθησης (ML) που διαχειρίζεται το AWS. Για αυτό το παράδειγμα, προσαρμόζουμε ένα υπάρχον σενάριο για ταξινόμηση κειμένου από το Hugging Face. Αυτό μας επιτρέπει να δοκιμάζουμε διάφορες μεθόδους για τη βελτίωση της αποτελεσματικότητας της εκπαιδευτικής μας εργασίας.
Μέθοδος 1: Κατηγορία σταθμισμένης προπόνησης
Όπως πολλά βιολογικά σύνολα δεδομένων, τα δεδομένα DeepLoc είναι άνισα κατανεμημένα, που σημαίνει ότι δεν υπάρχει ίσος αριθμός μεμβρανικών και μη μεμβρανικών πρωτεϊνών. Θα μπορούσαμε να ξαναδείξουμε τα δεδομένα μας και να απορρίψουμε εγγραφές από την πλειοψηφική τάξη. Ωστόσο, αυτό θα μείωνε τα συνολικά δεδομένα προπόνησης και ενδεχομένως θα έβλαπτε την ακρίβειά μας. Αντίθετα, υπολογίζουμε τα βάρη της τάξης κατά τη διάρκεια της εργασίας προπόνησης και τα χρησιμοποιούμε για να προσαρμόσουμε την απώλεια.
Στο σενάριο εκπαίδευσης, υποκατηγορούμε το Trainer τάξη από transformers με WeightedTrainer κλάση που λαμβάνει υπόψη τα βάρη κλάσεων κατά τον υπολογισμό της απώλειας διασταυρούμενης εντροπίας. Αυτό βοηθά στην αποφυγή μεροληψίας στο μοντέλο μας:
class WeightedTrainer(Trainer):
def __init__(self, class_weights, *args, **kwargs):
self.class_weights = class_weights
super().__init__(*args, **kwargs)
def compute_loss(self, model, inputs, return_outputs=False):
labels = inputs.pop("labels")
outputs = model(**inputs)
logits = outputs.get("logits")
loss_fct = torch.nn.CrossEntropyLoss(
weight=torch.tensor(self.class_weights, device=model.device)
)
loss = loss_fct(logits.view(-1, self.model.config.num_labels), labels.view(-1))
return (loss, outputs) if return_outputs else lossΜέθοδος 2: Συσσώρευση κλίσης
Η συσσώρευση κλίσης είναι μια τεχνική εκπαίδευσης που επιτρέπει στα μοντέλα να προσομοιώνουν την εκπαίδευση σε μεγαλύτερα μεγέθη παρτίδων. Συνήθως, το μέγεθος παρτίδας (ο αριθμός των δειγμάτων που χρησιμοποιούνται για τον υπολογισμό της διαβάθμισης σε ένα βήμα εκπαίδευσης) περιορίζεται από τη χωρητικότητα της μνήμης GPU. Με τη συσσώρευση κλίσης, το μοντέλο υπολογίζει πρώτα τις διαβαθμίσεις σε μικρότερες παρτίδες. Στη συνέχεια, αντί να ενημερώνονται αμέσως τα βάρη του μοντέλου, οι διαβαθμίσεις συσσωρεύονται σε πολλές μικρές παρτίδες. Όταν οι συσσωρευμένες διαβαθμίσεις ισούνται με το στόχο μεγαλύτερης παρτίδας, το βήμα βελτιστοποίησης εκτελείται για την ενημέρωση του μοντέλου. Αυτό επιτρέπει στα μοντέλα να εκπαιδεύονται με αποτελεσματικά μεγαλύτερες παρτίδες χωρίς να υπερβαίνουν το όριο μνήμης GPU.
Ωστόσο, απαιτείται επιπλέον υπολογισμός για τις μικρότερες παρτίδες προς τα εμπρός και προς τα πίσω. Τα αυξημένα μεγέθη παρτίδων μέσω της συσσώρευσης κλίσης μπορεί να επιβραδύνουν την προπόνηση, ειδικά εάν χρησιμοποιούνται πάρα πολλά βήματα συσσώρευσης. Ο στόχος είναι να μεγιστοποιηθεί η χρήση της GPU, αλλά να αποφευχθούν οι υπερβολικές επιβραδύνσεις από πάρα πολλά επιπλέον βήματα υπολογισμού κλίσης.
Μέθοδος 3: Σημείο ελέγχου κλίσης
Το Gradient checkpointing είναι μια τεχνική που μειώνει τη μνήμη που απαιτείται κατά τη διάρκεια της προπόνησης, διατηρώντας παράλληλα τον υπολογιστικό χρόνο λογικό. Τα μεγάλα νευρωνικά δίκτυα καταλαμβάνουν πολλή μνήμη επειδή πρέπει να αποθηκεύσουν όλες τις ενδιάμεσες τιμές από το εμπρός πέρασμα για να υπολογίσουν τις διαβαθμίσεις κατά τη διέλευση προς τα πίσω. Αυτό μπορεί να προκαλέσει προβλήματα μνήμης. Μια λύση είναι να μην αποθηκεύονται αυτές οι ενδιάμεσες τιμές, αλλά στη συνέχεια πρέπει να υπολογιστούν εκ νέου κατά το πέρασμα προς τα πίσω, κάτι που απαιτεί πολύ χρόνο.
Το gradient checkpoint παρέχει μια ισορροπημένη προσέγγιση. Αποθηκεύει μόνο μερικές από τις ενδιάμεσες τιμές, που ονομάζονται σημεία ελέγχου, και υπολογίζει εκ νέου τα άλλα ανάλογα με τις ανάγκες. Επομένως, χρησιμοποιεί λιγότερη μνήμη από την αποθήκευση των πάντων, αλλά και λιγότερους υπολογισμούς από τον επανυπολογισμό των πάντων. Επιλέγοντας στρατηγικά ποιες ενεργοποιήσεις θα σημείων ελέγχου, το gradient checkpoint επιτρέπει στα μεγάλα νευρωνικά δίκτυα να εκπαιδεύονται με διαχειρίσιμη χρήση μνήμης και υπολογιστικό χρόνο. Αυτή η σημαντική τεχνική καθιστά εφικτή την εκπαίδευση πολύ μεγάλων μοντέλων που διαφορετικά θα είχαν περιορισμούς στη μνήμη.
Στο σενάριο εκπαίδευσης, ενεργοποιούμε την ενεργοποίηση gradient και το checkpoint προσθέτοντας τις απαραίτητες παραμέτρους στο TrainingArguments αντικείμενο:
from transformers import TrainingArguments
training_args = TrainingArguments(
gradient_accumulation_steps=4,
gradient_checkpointing=True
)Μέθοδος 4: Προσαρμογή χαμηλού βαθμού LLM
Μεγάλα μοντέλα γλώσσας όπως το ESM-2 μπορεί να περιέχουν δισεκατομμύρια παραμέτρους που είναι δαπανηρές στην εκπαίδευση και την εκτέλεση. Ερευνητές ανέπτυξε μια μέθοδο εκπαίδευσης που ονομάζεται Low-Rank Adaptation (LoRA) για να κάνει τη βελτίωση αυτών των τεράστιων μοντέλων πιο αποτελεσματική.
Η βασική ιδέα πίσω από το LoRA είναι ότι κατά τη λεπτομερή ρύθμιση ενός μοντέλου για μια συγκεκριμένη εργασία, δεν χρειάζεται να ενημερώσετε όλες τις αρχικές παραμέτρους. Αντίθετα, το LoRA προσθέτει νέους μικρότερους πίνακες στο μοντέλο που μετασχηματίζουν τις εισόδους και τις εξόδους. Μόνο αυτοί οι μικρότεροι πίνακες ενημερώνονται κατά τη λεπτομέρεια, η οποία είναι πολύ πιο γρήγορη και χρησιμοποιεί λιγότερη μνήμη. Οι παράμετροι του αρχικού μοντέλου παραμένουν παγωμένες.
Μετά τη λεπτομέρεια με το LoRA, μπορείτε να συγχωνεύσετε τις μικρές προσαρμοσμένες μήτρες στο αρχικό μοντέλο. Εναλλακτικά, μπορείτε να τα κρατήσετε ξεχωριστά, εάν θέλετε να προσαρμόσετε γρήγορα το μοντέλο για άλλες εργασίες χωρίς να ξεχνάτε προηγούμενες. Συνολικά, το LoRA επιτρέπει στα LLM να προσαρμόζονται αποτελεσματικά σε νέες εργασίες με ένα κλάσμα του συνηθισμένου κόστους.
Στο σενάριο εκπαίδευσης, διαμορφώνουμε το LoRA χρησιμοποιώντας το PEFT βιβλιοθήκη από το Hugging Face:
from peft import get_peft_model, LoraConfig, TaskType
import torch
from transformers import EsmForSequenceClassification
model = EsmForSequenceClassification.from_pretrained(
“facebook/esm2_t33_650M_UR50D”,
Torch_dtype=torch.bfloat16,
Num_labels=2,
)
peft_config = LoraConfig(
task_type=TaskType.SEQ_CLS,
inference_mode=False,
bias="none",
r=8,
lora_alpha=16,
lora_dropout=0.05,
target_modules=[
"query",
"key",
"value",
"EsmSelfOutput.dense",
"EsmIntermediate.dense",
"EsmOutput.dense",
"EsmContactPredictionHead.regression",
"EsmClassificationHead.dense",
"EsmClassificationHead.out_proj",
]
)
model = get_peft_model(model, peft_config)Υποβάλετε μια εργασία εκπαίδευσης SageMaker
Αφού ορίσετε το σενάριο εκπαίδευσης, μπορείτε να διαμορφώσετε και να υποβάλετε μια εργασία εκπαίδευσης SageMaker. Πρώτα, καθορίστε τις υπερπαραμέτρους:
hyperparameters = {
"model_id": "facebook/esm2_t33_650M_UR50D",
"epochs": 1,
"per_device_train_batch_size": 8,
"gradient_accumulation_steps": 4,
"use_gradient_checkpointing": True,
"lora": True,
}Στη συνέχεια, ορίστε ποιες μετρήσεις θα ληφθούν από τα αρχεία καταγραφής εκπαίδευσης:
metric_definitions = [
{"Name": "epoch", "Regex": "'epoch': ([0-9.]*)"},
{
"Name": "max_gpu_mem",
"Regex": "Max GPU memory use during training: ([0-9.e-]*) MB",
},
{"Name": "train_loss", "Regex": "'loss': ([0-9.e-]*)"},
{
"Name": "train_samples_per_second",
"Regex": "'train_samples_per_second': ([0-9.e-]*)",
},
{"Name": "eval_loss", "Regex": "'eval_loss': ([0-9.e-]*)"},
{"Name": "eval_accuracy", "Regex": "'eval_accuracy': ([0-9.e-]*)"},
]Τέλος, ορίστε έναν εκτιμητή Hugging Face και υποβάλετέ τον για εκπαίδευση σε έναν τύπο εμφάνισης ml.g5.2xlarge. Αυτός είναι ένας οικονομικά αποδοτικός τύπος παρουσίας που είναι ευρέως διαθέσιμος σε πολλές Περιοχές AWS:
from sagemaker.experiments.run import Run
from sagemaker.huggingface import HuggingFace
from sagemaker.inputs import TrainingInput
hf_estimator = HuggingFace(
base_job_name="esm-2-membrane-ft",
entry_point="lora-train.py",
source_dir="scripts",
instance_type="ml.g5.2xlarge",
instance_count=1,
transformers_version="4.28",
pytorch_version="2.0",
py_version="py310",
output_path=f"{S3_PATH}/output",
role=sagemaker_execution_role,
hyperparameters=hyperparameters,
metric_definitions=metric_definitions,
checkpoint_local_path="/opt/ml/checkpoints",
sagemaker_session=sagemaker_session,
keep_alive_period_in_seconds=3600,
tags=[{"Key": "project", "Value": "esm-fine-tuning"}],
)
with Run(
experiment_name=EXPERIMENT_NAME,
sagemaker_session=sagemaker_session,
) as run:
hf_estimator.fit(
{
"train": TrainingInput(s3_data=train_s3_uri),
"test": TrainingInput(s3_data=test_s3_uri),
}
)Ο παρακάτω πίνακας συγκρίνει τις διαφορετικές μεθόδους εκπαίδευσης που συζητήσαμε και την επίδρασή τους στο χρόνο εκτέλεσης, την ακρίβεια και τις απαιτήσεις μνήμης GPU της εργασίας μας.
| διαμόρφωση | Χρεώσιμος χρόνος (λεπτά) | Ακρίβεια αξιολόγησης | Μέγιστη χρήση μνήμης GPU (GB) |
| Μοντέλο βάσης | 28 | 0.91 | 22.6 |
| Βάση + GA | 21 | 0.90 | 17.8 |
| Βάση + GC | 29 | 0.91 | 10.2 |
| Βάση + LoRA | 23 | 0.90 | 18.6 |
Όλες οι μέθοδοι παρήγαγαν μοντέλα με υψηλή ακρίβεια αξιολόγησης. Η χρήση LoRA και η ενεργοποίηση gradient μείωσε το χρόνο εκτέλεσης (και το κόστος) κατά 18% και 25%, αντίστοιχα. Η χρήση του σημείου ελέγχου gradient μείωσε τη μέγιστη χρήση μνήμης GPU κατά 55%. Ανάλογα με τους περιορισμούς σας (κόστος, χρόνος, υλικό), μία από αυτές τις προσεγγίσεις μπορεί να έχει περισσότερο νόημα από μια άλλη.
Κάθε μία από αυτές τις μεθόδους έχει καλή απόδοση από μόνη της, αλλά τι συμβαίνει όταν τις χρησιμοποιούμε σε συνδυασμό; Ο παρακάτω πίνακας συνοψίζει τα αποτελέσματα.
| διαμόρφωση | Χρεώσιμος χρόνος (λεπτά) | Ακρίβεια αξιολόγησης | Μέγιστη χρήση μνήμης GPU (GB) |
| Όλες οι μέθοδοι | 12 | 0.80 | 3.3 |
Σε αυτή την περίπτωση, βλέπουμε μείωση της ακρίβειας κατά 12%. Ωστόσο, μειώσαμε το χρόνο εκτέλεσης κατά 57% και τη χρήση μνήμης GPU κατά 85%! Πρόκειται για μια τεράστια μείωση που μας επιτρέπει να εκπαιδευόμαστε σε ένα ευρύ φάσμα οικονομικών τύπων παρουσιών.
εκκαθάριση
Εάν παρακολουθείτε τον δικό σας λογαριασμό AWS, διαγράψτε τυχόν τελικά σημεία και δεδομένα συμπερασμάτων σε πραγματικό χρόνο που δημιουργήσατε για να αποφύγετε περαιτέρω χρεώσεις.
predictor.delete_endpoint()
bucket = boto_session.resource("s3").Bucket(S3_BUCKET)
bucket.objects.filter(Prefix=S3_PREFIX).delete()Συμπέρασμα
Σε αυτήν την ανάρτηση, δείξαμε πώς να τελειοποιήσετε αποτελεσματικά μοντέλα γλώσσας πρωτεΐνης όπως το ESM-2 για μια επιστημονικά σχετική εργασία. Για περισσότερες πληροφορίες σχετικά με τη χρήση των βιβλιοθηκών Transformers και PEFT για την εκπαίδευση του pLMS, ανατρέξτε στις αναρτήσεις Βαθιά Μάθηση με Πρωτεΐνες και ESMBind (ESMB): Προσαρμογή χαμηλής κατάταξης του ESM-2 για πρόβλεψη τοποθεσίας δέσμευσης πρωτεΐνης στο ιστολόγιο Hugging Face. Μπορείτε επίσης να βρείτε περισσότερα παραδείγματα χρήσης μηχανικής εκμάθησης για την πρόβλεψη ιδιοτήτων πρωτεΐνης στο Καταπληκτική ανάλυση πρωτεΐνης στο AWS Αποθήκη GitHub.
Σχετικά με το Συγγραφέας
 Μπράιαν Λόιαλ είναι Ανώτερος Αρχιτέκτονας Λύσεων AI/ML στην ομάδα Global Healthcare and Life Sciences στο Amazon Web Services. Έχει περισσότερα από 17 χρόνια εμπειρίας στη βιοτεχνολογία και τη μηχανική μάθηση και είναι παθιασμένος με το να βοηθά τους πελάτες να λύσουν γονιδιωματικές και πρωτεωμικές προκλήσεις. Στον ελεύθερο χρόνο του, του αρέσει να μαγειρεύει και να τρώει με τους φίλους και την οικογένειά του.
Μπράιαν Λόιαλ είναι Ανώτερος Αρχιτέκτονας Λύσεων AI/ML στην ομάδα Global Healthcare and Life Sciences στο Amazon Web Services. Έχει περισσότερα από 17 χρόνια εμπειρίας στη βιοτεχνολογία και τη μηχανική μάθηση και είναι παθιασμένος με το να βοηθά τους πελάτες να λύσουν γονιδιωματικές και πρωτεωμικές προκλήσεις. Στον ελεύθερο χρόνο του, του αρέσει να μαγειρεύει και να τρώει με τους φίλους και την οικογένειά του.
- SEO Powered Content & PR Distribution. Ενισχύστε σήμερα.
- PlatoData.Network Vertical Generative Ai. Ενδυναμώστε τον εαυτό σας. Πρόσβαση εδώ.
- PlatoAiStream. Web3 Intelligence. Ενισχύθηκε η γνώση. Πρόσβαση εδώ.
- PlatoESG. Ανθρακας, Cleantech, Ενέργεια, Περιβάλλον, Ηλιακός, Διαχείριση των αποβλήτων. Πρόσβαση εδώ.
- PlatoHealth. Ευφυΐα βιοτεχνολογίας και κλινικών δοκιμών. Πρόσβαση εδώ.
- πηγή: https://aws.amazon.com/blogs/machine-learning/efficiently-fine-tune-the-esm-2-protein-language-model-with-amazon-sagemaker/

