Σήμερα, πελάτες όλων των βιομηχανιών —είτε είναι οι χρηματοοικονομικές υπηρεσίες, η υγειονομική περίθαλψη και οι επιστήμες της ζωής, τα ταξίδια και η φιλοξενία, τα μέσα ενημέρωσης και η ψυχαγωγία, οι τηλεπικοινωνίες, το λογισμικό ως υπηρεσία (SaaS), ακόμη και οι πάροχοι ιδιόκτητων μοντέλων— χρησιμοποιούν μεγάλα γλωσσικά μοντέλα (LLM) για να να δημιουργήσετε εφαρμογές όπως chatbot ερωτήσεων και απαντήσεων (QnA), μηχανές αναζήτησης και βάσεις γνώσεων. Αυτά τα γενετική AI Οι εφαρμογές δεν χρησιμοποιούνται μόνο για την αυτοματοποίηση των υπαρχουσών επιχειρηματικών διαδικασιών, αλλά έχουν επίσης τη δυνατότητα να μεταμορφώσουν την εμπειρία για τους πελάτες που χρησιμοποιούν αυτές τις εφαρμογές. Με τις εξελίξεις που γίνονται με LLM όπως το Mixtral-8x7B Instruct, παράγωγο αρχιτεκτονικών όπως το μείγμα εμπειρογνωμόνων (ΥΠ), οι πελάτες αναζητούν συνεχώς τρόπους βελτίωσης της απόδοσης και της ακρίβειας των γενετικών εφαρμογών AI, επιτρέποντάς τους ταυτόχρονα να χρησιμοποιούν αποτελεσματικά ένα ευρύτερο φάσμα μοντέλων κλειστού και ανοιχτού κώδικα.
Ένας αριθμός τεχνικών χρησιμοποιούνται συνήθως για τη βελτίωση της ακρίβειας και της απόδοσης των αποτελεσμάτων ενός LLM, όπως η τελειοποίηση με αποδοτική λεπτομέρεια παραμέτρων (PEFT), ενισχυτική μάθηση από την ανθρώπινη ανατροφοδότηση (RLHF), και την εκτέλεση απόσταξη γνώσης. Ωστόσο, κατά τη δημιουργία γενετικών εφαρμογών τεχνητής νοημοσύνης, μπορείτε να χρησιμοποιήσετε μια εναλλακτική λύση που επιτρέπει τη δυναμική ενσωμάτωση εξωτερικής γνώσης και σας επιτρέπει να ελέγχετε τις πληροφορίες που χρησιμοποιούνται για παραγωγή χωρίς να χρειάζεται να τελειοποιήσετε το υπάρχον θεμελιώδες μοντέλο σας. Εδώ μπαίνει το Retrieval Augmented Generation (RAG), ειδικά για τις παραγωγικές εφαρμογές τεχνητής νοημοσύνης σε αντίθεση με τις πιο ακριβές και ισχυρές εναλλακτικές μικρορύθμισης που έχουμε συζητήσει. Εάν εφαρμόζετε πολύπλοκες εφαρμογές RAG στις καθημερινές σας εργασίες, ενδέχεται να αντιμετωπίσετε κοινές προκλήσεις με τα συστήματα RAG, όπως ανακριβή ανάκτηση, αύξηση του μεγέθους και πολυπλοκότητας των εγγράφων και υπερχείλιση του περιβάλλοντος, που μπορεί να επηρεάσει σημαντικά την ποιότητα και την αξιοπιστία των απαντήσεων που δημιουργούνται .
Αυτή η ανάρτηση συζητά μοτίβα RAG για τη βελτίωση της ακρίβειας απόκρισης χρησιμοποιώντας το LangChain και εργαλεία όπως η γονική ανάκτηση εγγράφων εκτός από τεχνικές όπως η συμπίεση με βάση τα συμφραζόμενα, προκειμένου να επιτραπεί στους προγραμματιστές να βελτιώσουν τις υπάρχουσες εφαρμογές δημιουργίας τεχνητής νοημοσύνης.
Επισκόπηση λύσεων
Σε αυτήν την ανάρτηση, παρουσιάζουμε τη χρήση της δημιουργίας κειμένου Mixtral-8x7B Instruct σε συνδυασμό με το μοντέλο ενσωμάτωσης BGE Large En για την αποτελεσματική κατασκευή ενός συστήματος RAG QnA σε έναν φορητό υπολογιστή Amazon SageMaker χρησιμοποιώντας το γονικό εργαλείο ανάκτησης εγγράφων και την τεχνική συμπίεσης με βάση τα συμφραζόμενα. Το παρακάτω διάγραμμα απεικονίζει την αρχιτεκτονική αυτής της λύσης.
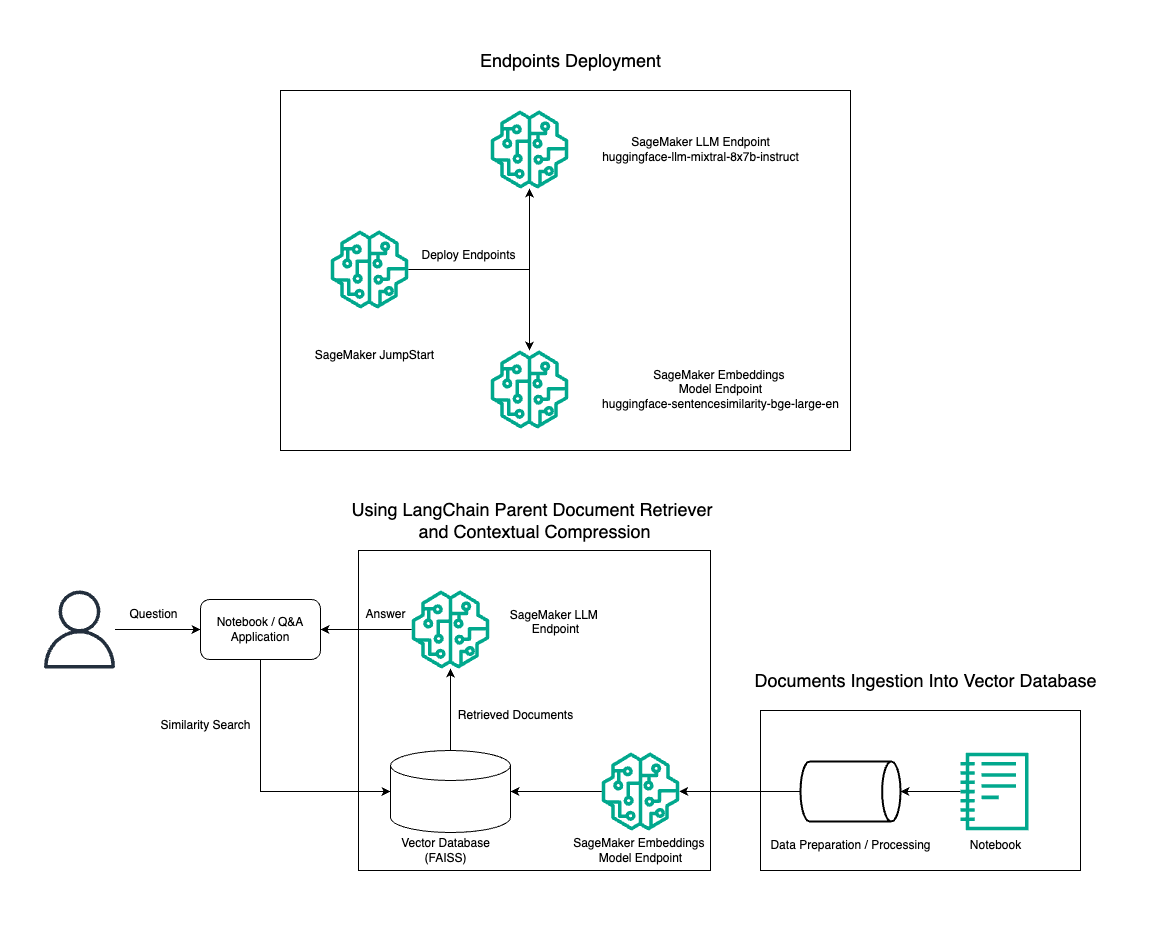
Μπορείτε να αναπτύξετε αυτήν τη λύση με λίγα μόνο κλικ χρησιμοποιώντας Amazon SageMaker JumpStart, μια πλήρως διαχειριζόμενη πλατφόρμα που προσφέρει μοντέλα θεμελίωσης τελευταίας τεχνολογίας για διάφορες περιπτώσεις χρήσης, όπως η συγγραφή περιεχομένου, η δημιουργία κώδικα, η απάντηση ερωτήσεων, η σύνταξη κειμένων, η σύνοψη, η ταξινόμηση και η ανάκτηση πληροφοριών. Παρέχει μια συλλογή προεκπαιδευμένων μοντέλων που μπορείτε να αναπτύξετε γρήγορα και εύκολα, επιταχύνοντας την ανάπτυξη και την ανάπτυξη εφαρμογών μηχανικής μάθησης (ML). Ένα από τα βασικά στοιχεία του SageMaker JumpStart είναι το Model Hub, το οποίο προσφέρει έναν τεράστιο κατάλογο προεκπαιδευμένων μοντέλων, όπως το Mixtral-8x7B, για μια ποικιλία εργασιών.
Το Mixtral-8x7B χρησιμοποιεί μια αρχιτεκτονική MoE. Αυτή η αρχιτεκτονική επιτρέπει σε διαφορετικά μέρη ενός νευρωνικού δικτύου να εξειδικεύονται σε διαφορετικές εργασίες, μοιράζοντας αποτελεσματικά τον φόρτο εργασίας μεταξύ πολλών ειδικών. Αυτή η προσέγγιση επιτρέπει την αποτελεσματική εκπαίδευση και ανάπτυξη μεγαλύτερων μοντέλων σε σύγκριση με τις παραδοσιακές αρχιτεκτονικές.
Ένα από τα κύρια πλεονεκτήματα της αρχιτεκτονικής του MoE είναι η επεκτασιμότητα του. Με την κατανομή του φόρτου εργασίας σε πολλούς ειδικούς, τα μοντέλα MoE μπορούν να εκπαιδευτούν σε μεγαλύτερα σύνολα δεδομένων και να επιτύχουν καλύτερη απόδοση από τα παραδοσιακά μοντέλα του ίδιου μεγέθους. Επιπλέον, τα μοντέλα MoE μπορούν να είναι πιο αποτελεσματικά κατά την εξαγωγή συμπερασμάτων, επειδή μόνο ένα υποσύνολο ειδικών χρειάζεται να ενεργοποιηθεί για μια δεδομένη είσοδο.
Για περισσότερες πληροφορίες σχετικά με το Mixtral-8x7B Instruct on AWS, ανατρέξτε στο Το Mixtral-8x7B είναι πλέον διαθέσιμο στο Amazon SageMaker JumpStart. Το μοντέλο Mixtral-8x7B διατίθεται υπό την επιτρεπτή άδεια Apache 2.0, για χρήση χωρίς περιορισμούς.
Σε αυτήν την ανάρτηση, συζητάμε πώς μπορείτε να χρησιμοποιήσετε LangChain για τη δημιουργία αποτελεσματικών και πιο αποδοτικών εφαρμογών RAG. Το LangChain είναι μια βιβλιοθήκη Python ανοιχτού κώδικα που έχει σχεδιαστεί για τη δημιουργία εφαρμογών με LLM. Παρέχει ένα αρθρωτό και ευέλικτο πλαίσιο για το συνδυασμό LLM με άλλα στοιχεία, όπως βάσεις γνώσεων, συστήματα ανάκτησης και άλλα εργαλεία τεχνητής νοημοσύνης, για τη δημιουργία ισχυρών και προσαρμόσιμων εφαρμογών.
Προχωράμε στην κατασκευή ενός αγωγού RAG στο SageMaker με το Mixtral-8x7B. Χρησιμοποιούμε το μοντέλο δημιουργίας κειμένου Mixtral-8x7B Instruct με το μοντέλο ενσωμάτωσης BGE Large En για να δημιουργήσουμε ένα αποτελεσματικό σύστημα QnA χρησιμοποιώντας RAG σε φορητό υπολογιστή SageMaker. Χρησιμοποιούμε ένα στιγμιότυπο ml.t3.medium για να επιδείξουμε την ανάπτυξη LLM μέσω του SageMaker JumpStart, το οποίο είναι προσβάσιμο μέσω ενός τερματικού σημείου API που δημιουργείται από το SageMaker. Αυτή η ρύθμιση επιτρέπει την εξερεύνηση, τον πειραματισμό και τη βελτιστοποίηση προηγμένων τεχνικών RAG με το LangChain. Παρουσιάζουμε επίσης την ενσωμάτωση του καταστήματος FAISS Embedding στη ροή εργασιών RAG, τονίζοντας τον ρόλο του στην αποθήκευση και την ανάκτηση ενσωματώσεων για τη βελτίωση της απόδοσης του συστήματος.
Κάνουμε μια σύντομη περιγραφή του σημειωματάριου SageMaker. Για πιο λεπτομερείς και βήμα προς βήμα οδηγίες, ανατρέξτε στο Προηγμένα μοτίβα RAG με Mixtral στο αποθετήριο SageMaker Jumpstart GitHub.
Η ανάγκη για προηγμένα μοτίβα RAG
Τα προηγμένα μοτίβα RAG είναι απαραίτητα για τη βελτίωση των σημερινών δυνατοτήτων των LLM στην επεξεργασία, την κατανόηση και τη δημιουργία κειμένου που μοιάζει με άνθρωπο. Καθώς το μέγεθος και η πολυπλοκότητα των εγγράφων αυξάνονται, η αναπαράσταση πολλαπλών όψεων του εγγράφου σε μια ενιαία ενσωμάτωση μπορεί να οδηγήσει σε απώλεια της εξειδίκευσης. Αν και είναι απαραίτητο να συλλάβουμε τη γενική ουσία ενός εγγράφου, είναι εξίσου σημαντικό να αναγνωρίζουμε και να αναπαριστάνουμε τα ποικίλα υποπλαίσια μέσα. Αυτή είναι μια πρόκληση που αντιμετωπίζετε συχνά όταν εργάζεστε με μεγαλύτερα έγγραφα. Μια άλλη πρόκληση με το RAG είναι ότι με την ανάκτηση, δεν γνωρίζετε τα συγκεκριμένα ερωτήματα που θα αντιμετωπίσει το σύστημα αποθήκευσης εγγράφων σας κατά την απορρόφηση. Αυτό θα μπορούσε να οδηγήσει σε πληροφορίες που είναι πιο σχετικές με ένα ερώτημα να θαφτεί κάτω από κείμενο (υπερχείλιση περιβάλλοντος). Για να μειώσετε την αποτυχία και να βελτιώσετε την υπάρχουσα αρχιτεκτονική RAG, μπορείτε να χρησιμοποιήσετε προηγμένα μοτίβα RAG (γονική ανάκτηση εγγράφων και συμπίεση με βάση τα συμφραζόμενα) για να μειώσετε τα σφάλματα ανάκτησης, να βελτιώσετε την ποιότητα των απαντήσεων και να ενεργοποιήσετε τη διαχείριση σύνθετων ερωτήσεων.
Με τις τεχνικές που συζητούνται σε αυτήν την ανάρτηση, μπορείτε να αντιμετωπίσετε βασικές προκλήσεις που σχετίζονται με την εξωτερική ανάκτηση και ενσωμάτωση γνώσης, επιτρέποντας στην εφαρμογή σας να παρέχει πιο ακριβείς και συναφείς απαντήσεις.
Στις επόμενες ενότητες, διερευνούμε πώς γονικοί ανακτητές εγγράφων και συμφραζόμενη συμπίεση μπορεί να σας βοηθήσει να αντιμετωπίσετε ορισμένα από τα προβλήματα που συζητήσαμε.
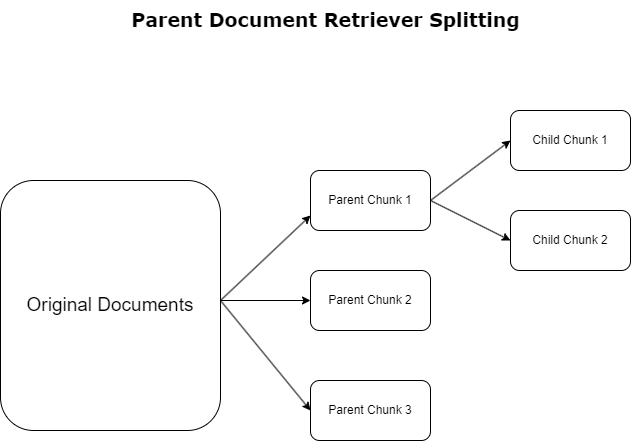
Μητρική ανάκτηση εγγράφων
Στην προηγούμενη ενότητα, επισημάναμε τις προκλήσεις που αντιμετωπίζουν οι εφαρμογές RAG όταν ασχολούνται με εκτενή έγγραφα. Για την αντιμετώπιση αυτών των προκλήσεων, γονικοί ανακτητές εγγράφων κατηγοριοποιήστε και ορίστε τα εισερχόμενα έγγραφα ως γονικά έγγραφα. Αυτά τα έγγραφα αναγνωρίζονται για την πλήρη φύση τους, αλλά δεν χρησιμοποιούνται άμεσα στην αρχική τους μορφή για ενσωματώσεις. Αντί να συμπιέζουν ένα ολόκληρο έγγραφο σε μια ενιαία ενσωμάτωση, οι ανακτητές γονικών εγγράφων ανατέμνουν αυτά τα γονικά έγγραφα σε παιδικά έγγραφα. Κάθε θυγατρικό έγγραφο καταγράφει ξεχωριστές πτυχές ή θέματα από το ευρύτερο γονικό έγγραφο. Μετά την αναγνώριση αυτών των θυγατρικών τμημάτων, εκχωρούνται μεμονωμένες ενσωματώσεις στο καθένα, αποτυπώνοντας τη συγκεκριμένη θεματική τους ουσία (δείτε το παρακάτω διάγραμμα). Κατά την ανάκτηση, γίνεται επίκληση του μητρικού εγγράφου. Αυτή η τεχνική παρέχει στοχευμένες αλλά ευρείας κλίμακας δυνατότητες αναζήτησης, παρέχοντας στο LLM μια ευρύτερη προοπτική. Οι γονικοί ανακτητές εγγράφων παρέχουν στα LLM ένα διπλό πλεονέκτημα: την ιδιαιτερότητα των ενσωματώσεων θυγατρικών εγγράφων για ακριβή και σχετική ανάκτηση πληροφοριών, σε συνδυασμό με την επίκληση γονικών εγγράφων για τη δημιουργία απόκρισης, που εμπλουτίζει τα αποτελέσματα του LLM με ένα πολυεπίπεδο και εμπεριστατωμένο πλαίσιο.
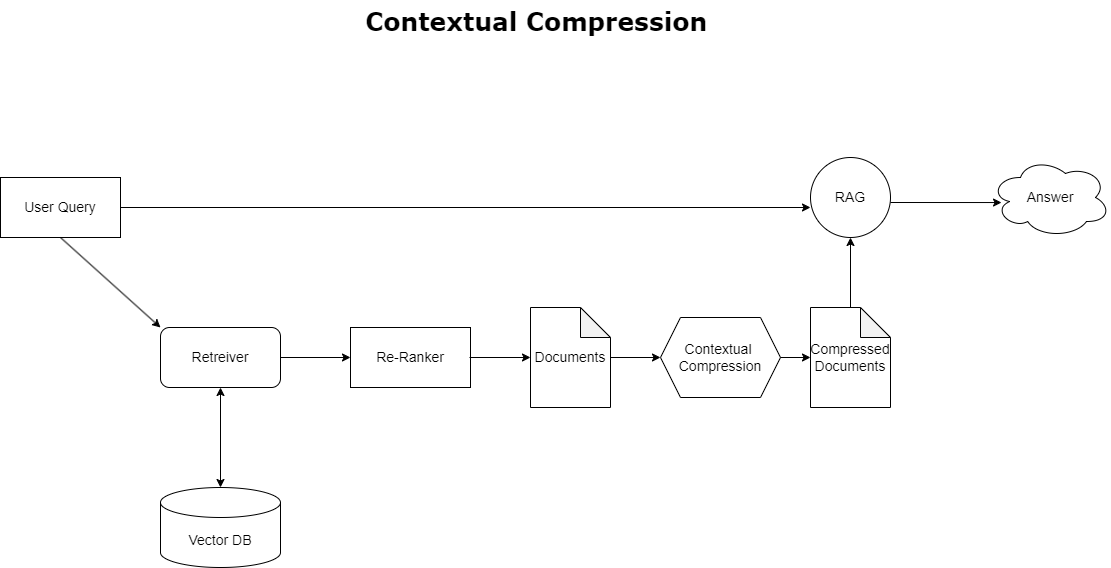
Συμφραζόμενη συμπίεση
Για να αντιμετωπίσετε το ζήτημα της υπερχείλισης περιβάλλοντος που συζητήθηκε νωρίτερα, μπορείτε να χρησιμοποιήσετε συμφραζόμενη συμπίεση για τη συμπίεση και το φιλτράρισμα των ανακτημένων εγγράφων σε ευθυγράμμιση με το πλαίσιο του ερωτήματος, έτσι ώστε να διατηρούνται και να υποβάλλονται σε επεξεργασία μόνο σχετικές πληροφορίες. Αυτό επιτυγχάνεται μέσω ενός συνδυασμού βάσης ανάκτησης για την αρχική ανάκτηση εγγράφων και συμπιεστή εγγράφων για την τελειοποίηση αυτών των εγγράφων, αναλύοντας το περιεχόμενό τους ή εξαιρώντας τα εντελώς βάσει της συνάφειας, όπως φαίνεται στο ακόλουθο διάγραμμα. Αυτή η βελτιστοποιημένη προσέγγιση, που διευκολύνεται από τον ανακτητή συμπίεσης με βάση τα συμφραζόμενα, βελτιώνει σημαντικά την αποτελεσματικότητα της εφαρμογής RAG παρέχοντας μια μέθοδο εξαγωγής και χρήσης μόνο ό,τι είναι απαραίτητο από μια μάζα πληροφοριών. Αντιμετωπίζει το ζήτημα της υπερφόρτωσης πληροφοριών και της άσχετης επεξεργασίας δεδομένων κατά μέτωπο, οδηγώντας σε βελτιωμένη ποιότητα απόκρισης, πιο οικονομικά αποδοτικές λειτουργίες LLM και ομαλότερη συνολική διαδικασία ανάκτησης. Ουσιαστικά, είναι ένα φίλτρο που προσαρμόζει τις πληροφορίες στο συγκεκριμένο ερώτημα, καθιστώντας το ένα πολύ απαραίτητο εργαλείο για προγραμματιστές που στοχεύουν να βελτιστοποιήσουν τις εφαρμογές RAG τους για καλύτερη απόδοση και ικανοποίηση των χρηστών.
Προϋποθέσεις
Εάν είστε νέοι στο SageMaker, ανατρέξτε στο Οδηγός ανάπτυξης Amazon SageMaker.
Πριν ξεκινήσετε με τη λύση, δημιουργήστε έναν λογαριασμό AWS. Όταν δημιουργείτε έναν λογαριασμό AWS, λαμβάνετε μια ταυτότητα ενιαίας σύνδεσης (SSO) που έχει πλήρη πρόσβαση σε όλες τις υπηρεσίες και τους πόρους AWS του λογαριασμού. Αυτή η ταυτότητα ονομάζεται λογαριασμός AWS root χρήστη.
Σύνδεση στο Κονσόλα διαχείρισης AWS Η χρήση της διεύθυνσης email και του κωδικού πρόσβασης που χρησιμοποιήσατε για τη δημιουργία του λογαριασμού σάς παρέχει πλήρη πρόσβαση σε όλους τους πόρους AWS στον λογαριασμό σας. Συνιστούμε ανεπιφύλακτα να μην χρησιμοποιείτε τον χρήστη root για καθημερινές εργασίες, ακόμα και για διοικητικές.
Αντίθετα, τηρήστε το βέλτιστες πρακτικές ασφάλειας in Διαχείριση ταυτότητας και πρόσβασης AWS (ΙΑΜ), και δημιουργήστε έναν διαχειριστή χρήστη και ομάδα. Στη συνέχεια, κλειδώστε με ασφάλεια τα διαπιστευτήρια χρήστη root και χρησιμοποιήστε τα για να εκτελέσετε μόνο μερικές εργασίες διαχείρισης λογαριασμού και υπηρεσιών.
Το μοντέλο Mixtral-8x7b απαιτεί μια παρουσία ml.g5.48xlarge. Το SageMaker JumpStart παρέχει έναν απλοποιημένο τρόπο πρόσβασης και ανάπτυξης πάνω από 100 διαφορετικών μοντέλων ανοιχτού κώδικα και θεμελίων τρίτων κατασκευαστών. Ωστε να εκκινήστε ένα τελικό σημείο για να φιλοξενήσει το Mixtral-8x7B από το SageMaker JumpStart, μπορεί να χρειαστεί να ζητήσετε αύξηση του ορίου υπηρεσίας για να αποκτήσετε πρόσβαση σε μια παρουσία ml.g5.48xlarge για χρήση τελικού σημείου. Μπορείς αύξηση της ποσόστωσης υπηρεσιών μέσω της κονσόλας, Διεπαφή γραμμής εντολών AWS (AWS CLI) ή API για να επιτρέπεται η πρόσβαση σε αυτούς τους πρόσθετους πόρους.
Ρυθμίστε μια παρουσία φορητού υπολογιστή SageMaker και εγκαταστήστε εξαρτήσεις
Για να ξεκινήσετε, δημιουργήστε μια παρουσία σημειωματάριου SageMaker και εγκαταστήστε τις απαιτούμενες εξαρτήσεις. Αναφέρομαι στο GitHub repo για να εξασφαλίσετε μια επιτυχημένη εγκατάσταση. Αφού ρυθμίσετε την παρουσία του φορητού υπολογιστή, μπορείτε να αναπτύξετε το μοντέλο.
Μπορείτε επίσης να εκτελέσετε το σημειωματάριο τοπικά στο προτιμώμενο περιβάλλον ολοκληρωμένης ανάπτυξης (IDE). Βεβαιωθείτε ότι έχετε εγκαταστήσει το εργαστήριο φορητών υπολογιστών Jupyter.
Αναπτύξτε το μοντέλο
Αναπτύξτε το μοντέλο Mixtral-8X7B Instruct LLM στο SageMaker JumpStart:
Αναπτύξτε το μοντέλο ενσωμάτωσης BGE Large En στο SageMaker JumpStart:
Ρυθμίστε το LangChain
Μετά την εισαγωγή όλων των απαραίτητων βιβλιοθηκών και την ανάπτυξη του μοντέλου Mixtral-8x7B και του μοντέλου ενσωματώσεων BGE Large En, μπορείτε τώρα να ρυθμίσετε το LangChain. Για οδηγίες βήμα προς βήμα, ανατρέξτε στο GitHub repo.
Προετοιμασία δεδομένων
Σε αυτήν την ανάρτηση, χρησιμοποιούμε πολλά χρόνια Επιστολών της Amazon προς τους Μετόχους ως σώμα κειμένου για την εκτέλεση QnA. Για πιο λεπτομερή βήματα για την προετοιμασία των δεδομένων, ανατρέξτε στο GitHub repo.
Ερώτηση απάντηση
Μόλις προετοιμαστούν τα δεδομένα, μπορείτε να χρησιμοποιήσετε το περιτύλιγμα που παρέχεται από τη LangChain, το οποίο τυλίγεται γύρω από το χώρο αποθήκευσης διανυσμάτων και λαμβάνει δεδομένα για το LLM. Αυτό το περιτύλιγμα εκτελεί τα ακόλουθα βήματα:
- Πάρτε την ερώτηση εισαγωγής.
- Δημιουργήστε μια ενσωμάτωση ερώτησης.
- Λάβετε σχετικά έγγραφα.
- Ενσωματώστε τα έγγραφα και την ερώτηση σε μια προτροπή.
- Επικαλέστε το μοντέλο με την προτροπή και δημιουργήστε την απάντηση με ευανάγνωστο τρόπο.
Τώρα που το διανυσματικό κατάστημα είναι στη θέση του, μπορείτε να αρχίσετε να κάνετε ερωτήσεις:
Κανονική αλυσίδα retriever
Στο προηγούμενο σενάριο, εξερευνήσαμε τον γρήγορο και άμεσο τρόπο για να λάβουμε μια απάντηση με επίγνωση του πλαισίου στην ερώτησή σας. Ας δούμε τώρα μια πιο προσαρμόσιμη επιλογή με τη βοήθεια του RetrievalQA, όπου μπορείτε να προσαρμόσετε τον τρόπο με τον οποίο τα έγγραφα που λαμβάνονται θα πρέπει να προστίθενται στο μήνυμα προτροπής χρησιμοποιώντας την παράμετρο chain_type. Επίσης, για να ελέγξετε πόσα σχετικά έγγραφα θα πρέπει να ανακτηθούν, μπορείτε να αλλάξετε την παράμετρο k στον παρακάτω κώδικα για να δείτε διαφορετικές εξόδους. Σε πολλά σενάρια, ίσως θέλετε να μάθετε ποια έγγραφα προέλευσης χρησιμοποίησε το LLM για να δημιουργήσει την απάντηση. Μπορείτε να λάβετε αυτά τα έγγραφα στην έξοδο χρησιμοποιώντας return_source_documents, το οποίο επιστρέφει τα έγγραφα που προστίθενται στο πλαίσιο της προτροπής LLM. Το RetrievalQA σάς επιτρέπει επίσης να παρέχετε ένα προσαρμοσμένο πρότυπο προτροπής που μπορεί να είναι συγκεκριμένο για το μοντέλο.
Ας κάνουμε μια ερώτηση:
Γονική αλυσίδα ανάκτησης εγγράφων
Ας δούμε μια πιο προηγμένη επιλογή RAG με τη βοήθεια του ParentDocumentRetriever. Όταν εργάζεστε με την ανάκτηση εγγράφων, μπορεί να αντιμετωπίσετε μια αντιστάθμιση μεταξύ της αποθήκευσης μικρών κομματιών ενός εγγράφου για ακριβείς ενσωματώσεις και μεγαλύτερων εγγράφων για τη διατήρηση περισσότερου περιβάλλοντος. Το μητρικό πρόγραμμα ανάκτησης εγγράφων επιτυγχάνει αυτή την ισορροπία διαχωρίζοντας και αποθηκεύοντας μικρά κομμάτια δεδομένων.
Χρησιμοποιούμε α parent_splitter για να χωρίσετε τα πρωτότυπα έγγραφα σε μεγαλύτερα κομμάτια που ονομάζονται γονικά έγγραφα και α child_splitter για να δημιουργήσετε μικρότερα θυγατρικά έγγραφα από τα πρωτότυπα έγγραφα:
Στη συνέχεια, τα θυγατρικά έγγραφα ευρετηριάζονται σε έναν χώρο αποθήκευσης διανυσμάτων χρησιμοποιώντας ενσωματώσεις. Αυτό επιτρέπει την αποτελεσματική ανάκτηση σχετικών εγγράφων για παιδιά με βάση την ομοιότητα. Για να ανακτήσει σχετικές πληροφορίες, η γονική συσκευή ανάκτησης εγγράφων ανακτά πρώτα τα θυγατρικά έγγραφα από το χώρο αποθήκευσης διανυσμάτων. Στη συνέχεια, αναζητά τα γονικά αναγνωριστικά για αυτά τα θυγατρικά έγγραφα και επιστρέφει τα αντίστοιχα μεγαλύτερα γονικά έγγραφα.
Ας κάνουμε μια ερώτηση:
Συμφραζόμενη αλυσίδα συμπίεσης
Ας δούμε μια άλλη προηγμένη επιλογή RAG που ονομάζεται συμφραζόμενη συμπίεση. Μια πρόκληση με την ανάκτηση είναι ότι συνήθως δεν γνωρίζουμε τα συγκεκριμένα ερωτήματα που θα αντιμετωπίσει το σύστημα αποθήκευσης εγγράφων σας όταν εισάγετε δεδομένα στο σύστημα. Αυτό σημαίνει ότι οι πληροφορίες που είναι πιο σχετικές με ένα ερώτημα μπορεί να ενταφιάζονται σε ένα έγγραφο με πολύ άσχετο κείμενο. Η διαβίβαση αυτού του πλήρους εγγράφου μέσω της αίτησής σας μπορεί να οδηγήσει σε ακριβότερες κλήσεις LLM και φτωχότερες απαντήσεις.
Το συμφραζόμενο ανάκτησης συμπίεσης αντιμετωπίζει την πρόκληση της ανάκτησης σχετικών πληροφοριών από ένα σύστημα αποθήκευσης εγγράφων, όπου τα σχετικά δεδομένα μπορούν να ενταφιάζονται σε έγγραφα που περιέχουν πολύ κείμενο. Με τη συμπίεση και το φιλτράρισμα των ανακτημένων εγγράφων με βάση το δεδομένο πλαίσιο ερωτήματος, επιστρέφονται μόνο οι πιο σχετικές πληροφορίες.
Για να χρησιμοποιήσετε το συμφραζόμενο ανάκτηση συμπίεσης, θα χρειαστείτε:
- Βασικό ριτρίβερ – Αυτό είναι το αρχικό retriever που ανακτά έγγραφα από το σύστημα αποθήκευσης με βάση το ερώτημα
- Συμπιεστής εγγράφων – Αυτό το στοιχείο λαμβάνει τα αρχικά ανακτημένα έγγραφα και τα συντομεύει μειώνοντας τα περιεχόμενα μεμονωμένων εγγράφων ή απορρίπτοντας εντελώς άσχετα έγγραφα, χρησιμοποιώντας το πλαίσιο ερωτήματος για τον προσδιορισμό της συνάφειας
Προσθήκη συμπίεσης συμφραζομένων με εξαγωγέα αλυσίδας LLM
Πρώτα, τυλίξτε τη βάση ριτρίβερ σας με ένα ContextualCompressionRetriever. Θα προσθέσετε ένα LLMChainExtractor, το οποίο θα επαναλάβει τα αρχικά επιστρεφόμενα έγγραφα και θα εξαγάγει από καθένα μόνο το περιεχόμενο που σχετίζεται με το ερώτημα.
Αρχικοποιήστε την αλυσίδα χρησιμοποιώντας το ContextualCompressionRetriever με ένα LLMChainExtractor και περάστε την προτροπή μέσω του chain_type_kwargs διαφωνία.
Ας κάνουμε μια ερώτηση:
Φιλτράρετε έγγραφα με φίλτρο αλυσίδας LLM
Η LLMCchainFilter είναι ένας ελαφρώς απλούστερος αλλά πιο στιβαρός συμπιεστής που χρησιμοποιεί μια αλυσίδα LLM για να αποφασίσει ποια από τα αρχικά ανακτημένα έγγραφα θα φιλτράρει και ποια θα επιστρέψει, χωρίς να τροποποιήσει το περιεχόμενο του εγγράφου:
Αρχικοποιήστε την αλυσίδα χρησιμοποιώντας το ContextualCompressionRetriever με ένα LLMChainFilter και περάστε την προτροπή μέσω του chain_type_kwargs διαφωνία.
Ας κάνουμε μια ερώτηση:
Συγκρίνετε τα αποτελέσματα
Ο παρακάτω πίνακας συγκρίνει αποτελέσματα από διαφορετικά ερωτήματα με βάση την τεχνική.
| Τεχνική | Ερώτημα 1 | Ερώτημα 2 | Σύγκριση |
| Πώς εξελίχθηκε το AWS; | Γιατί η Amazon είναι επιτυχημένη; | ||
| Έξοδος κανονικής αλυσίδας Retriever | Το AWS (Amazon Web Services) εξελίχθηκε από μια αρχικά ασύμφορη επένδυση σε μια επιχείρηση με ετήσιο ρυθμό εσόδων 85 δισεκατομμυρίων δολαρίων με ισχυρή κερδοφορία, προσφέροντας ένα ευρύ φάσμα υπηρεσιών και λειτουργιών και έγινε σημαντικό μέρος του χαρτοφυλακίου της Amazon. Παρά τον σκεπτικισμό και τους βραχυπρόθεσμους αντίθετους ανέμους, η AWS συνέχισε να καινοτομεί, να προσελκύει νέους πελάτες και να μεταναστεύει ενεργούς πελάτες, προσφέροντας οφέλη όπως ευελιξία, καινοτομία, οικονομική απόδοση και ασφάλεια. Η AWS επέκτεινε επίσης τις μακροπρόθεσμες επενδύσεις της, συμπεριλαμβανομένης της ανάπτυξης chip, για να παρέχει νέες δυνατότητες και να αλλάξει ό,τι είναι δυνατό για τους πελάτες της. | Η Amazon είναι επιτυχημένη λόγω της συνεχούς καινοτομίας και της επέκτασής της σε νέους τομείς όπως οι υπηρεσίες τεχνολογικής υποδομής, οι ψηφιακές συσκευές ανάγνωσης, οι προσωπικοί βοηθοί που βασίζονται στη φωνή και τα νέα επιχειρηματικά μοντέλα όπως η αγορά τρίτων. Η ικανότητά του να κλιμακώνει γρήγορα τις λειτουργίες του, όπως φαίνεται από την ταχεία επέκταση των δικτύων εκπλήρωσης και μεταφοράς, συμβάλλει επίσης στην επιτυχία του. Επιπλέον, η εστίαση της Amazon στη βελτιστοποίηση και τα κέρδη αποδοτικότητας στις διαδικασίες της είχε ως αποτέλεσμα βελτιώσεις παραγωγικότητας και μειώσεις κόστους. Το παράδειγμα του Amazon Business υπογραμμίζει την ικανότητα της εταιρείας να αξιοποιεί τις δυνάμεις του ηλεκτρονικού εμπορίου και των logistics σε διαφορετικούς τομείς. | Με βάση τις απαντήσεις από την κανονική αλυσίδα retriever, παρατηρούμε ότι αν και παρέχει μεγάλες απαντήσεις, υποφέρει από υπερχείλιση περιβάλλοντος και δεν αναφέρει σημαντικές λεπτομέρειες από το σώμα σχετικά με την απάντηση στο ερώτημα που παρέχεται. Η κανονική αλυσίδα ανάκτησης δεν είναι σε θέση να καταγράψει τις αποχρώσεις με βάθος ή κατανόηση των συμφραζομένων, καθώς ενδέχεται να λείπουν κρίσιμες πτυχές του εγγράφου. |
| Έξοδος γονικής ανάκτησης εγγράφων | Το AWS (Amazon Web Services) ξεκίνησε με μια αρχική παρουσίαση της υπηρεσίας Elastic Compute Cloud (EC2) το 2006 με φτωχά χαρακτηριστικά, παρέχοντας μόνο ένα μέγεθος παρουσίας, σε ένα κέντρο δεδομένων, σε μια περιοχή του κόσμου, με μόνο παρουσίες λειτουργικού συστήματος Linux και χωρίς πολλά βασικά χαρακτηριστικά, όπως παρακολούθηση, εξισορρόπηση φορτίου, αυτόματη κλιμάκωση ή μόνιμη αποθήκευση. Ωστόσο, η επιτυχία του AWS τους επέτρεψε να επαναλάβουν γρήγορα και να προσθέσουν τις δυνατότητες που λείπουν, επεκτείνοντας τελικά για να προσφέρει διάφορες γεύσεις, μεγέθη και βελτιστοποιήσεις υπολογισμού, αποθήκευσης και δικτύωσης, καθώς και να αναπτύξουν τα δικά τους τσιπ (Graviton) για να ωθήσουν περαιτέρω την τιμή και την απόδοση . Η επαναληπτική διαδικασία καινοτομίας της AWS απαιτούσε σημαντικές επενδύσεις σε χρηματοοικονομικούς και ανθρώπινους πόρους για 20 χρόνια, συχνά πολύ νωρίτερα από την ημερομηνία πληρωμής, για την κάλυψη των αναγκών των πελατών και τη βελτίωση των μακροπρόθεσμων εμπειριών πελατών, της αφοσίωσης και των αποδόσεων για τους μετόχους. | Η Amazon είναι επιτυχημένη λόγω της ικανότητάς της να καινοτομεί συνεχώς, να προσαρμόζεται στις μεταβαλλόμενες συνθήκες της αγοράς και να ανταποκρίνεται στις ανάγκες των πελατών σε διάφορα τμήματα της αγοράς. Αυτό είναι εμφανές στην επιτυχία του Amazon Business, το οποίο έχει αυξηθεί για να οδηγήσει περίπου 35 δισεκατομμύρια δολάρια σε ετήσιες ακαθάριστες πωλήσεις παρέχοντας επιλογή, αξία και ευκολία στους επιχειρηματικούς πελάτες. Οι επενδύσεις της Amazon στο ηλεκτρονικό εμπόριο και τις δυνατότητες εφοδιαστικής επέτρεψαν επίσης τη δημιουργία υπηρεσιών όπως το Buy with Prime, που βοηθά τους εμπόρους με ιστοτόπους απευθείας σε καταναλωτές να αυξήσουν τη μετατροπή από προβολές σε αγορές. | Το μητρικό πρόγραμμα ανάκτησης εγγράφων εμβαθύνει στις ιδιαιτερότητες της στρατηγικής ανάπτυξης του AWS, συμπεριλαμβανομένης της επαναληπτικής διαδικασίας προσθήκης νέων λειτουργιών με βάση τα σχόλια των πελατών και της λεπτομερούς διαδρομής από μια αρχική κυκλοφορία με φτωχά χαρακτηριστικά σε μια δεσπόζουσα θέση στην αγορά, παρέχοντας παράλληλα μια ανταπόκριση πλούσια σε περιβάλλον . Οι απαντήσεις καλύπτουν ένα ευρύ φάσμα πτυχών, από τεχνικές καινοτομίες και στρατηγική αγοράς έως την οργανωτική αποτελεσματικότητα και την εστίαση στον πελάτη, παρέχοντας μια ολιστική άποψη των παραγόντων που συμβάλλουν στην επιτυχία μαζί με παραδείγματα. Αυτό μπορεί να αποδοθεί στις στοχευμένες αλλά ευρείας κλίμακας δυνατότητες αναζήτησης του γονικού ανακτητή εγγράφων. |
| Εξαγωγέας αλυσίδας LLM: Έξοδος συμπίεσης με βάση τα συμφραζόμενα | Το AWS εξελίχθηκε ξεκινώντας ως ένα μικρό έργο εντός της Amazon, απαιτώντας σημαντικές επενδύσεις κεφαλαίου και αντιμετωπίζοντας σκεπτικισμό τόσο εντός όσο και εκτός της εταιρείας. Ωστόσο, η AWS είχε ένα προβάδισμα σε δυνητικούς ανταγωνιστές και πίστευε στην αξία που θα μπορούσε να προσφέρει στους πελάτες και την Amazon. Η AWS δεσμεύτηκε μακροπρόθεσμα να συνεχίσει να επενδύει, με αποτέλεσμα πάνω από 3,300 νέες δυνατότητες και υπηρεσίες να λανσαριστούν το 2022. Η AWS έχει αλλάξει τον τρόπο με τον οποίο οι πελάτες διαχειρίζονται την τεχνολογική τους υποδομή και έχει γίνει μια επιχείρηση με ετήσιο ρυθμό εσόδων 85 δισεκατομμυρίων $ με υψηλή κερδοφορία. Η AWS βελτιώνει επίσης συνεχώς τις προσφορές της, όπως τη βελτίωση του EC2 με πρόσθετες δυνατότητες και υπηρεσίες μετά την αρχική του κυκλοφορία. | Με βάση το παρεχόμενο πλαίσιο, η επιτυχία της Amazon μπορεί να αποδοθεί στη στρατηγική επέκτασή της από μια πλατφόρμα πώλησης βιβλίων σε μια παγκόσμια αγορά με ένα ζωντανό οικοσύστημα πωλητών τρίτων, την πρώιμη επένδυση στο AWS, την καινοτομία στην εισαγωγή του Kindle και της Alexa και την ουσιαστική ανάπτυξη στα ετήσια έσοδα από το 2019 έως το 2022. Αυτή η ανάπτυξη οδήγησε στην επέκταση του αποτυπώματος του κέντρου εκπλήρωσης, στη δημιουργία ενός δικτύου μεταφοράς τελευταίου μιλίου και στη δημιουργία ενός νέου δικτύου κέντρων διαλογής, τα οποία βελτιστοποιήθηκαν για μείωση της παραγωγικότητας και του κόστους. | Ο εξολκέας αλυσίδας LLM διατηρεί μια ισορροπία μεταξύ της ολοκληρωμένης κάλυψης βασικών σημείων και της αποφυγής περιττού βάθους. Προσαρμόζεται δυναμικά στο πλαίσιο του ερωτήματος, ώστε η έξοδος να είναι άμεσα σχετική και ολοκληρωμένη. |
| LLM Chain Filter: Contextual Compression Output | Το AWS (Amazon Web Services) αναπτύχθηκε λανσάροντας αρχικά με φτωχές δυνατότητες, αλλά επαναλαμβάνεται γρήγορα με βάση τα σχόλια των πελατών για να προσθέσει τις απαραίτητες δυνατότητες. Αυτή η προσέγγιση επέτρεψε στο AWS να λανσάρει το EC2 το 2006 με περιορισμένα χαρακτηριστικά και στη συνέχεια να προσθέτει συνεχώς νέες λειτουργίες, όπως πρόσθετα μεγέθη παρουσίας, κέντρα δεδομένων, περιοχές, επιλογές λειτουργικού συστήματος, εργαλεία παρακολούθησης, εξισορρόπηση φορτίου, αυτόματη κλιμάκωση και μόνιμη αποθήκευση. Με την πάροδο του χρόνου, η AWS μετατράπηκε από μια υπηρεσία με φτωχά χαρακτηριστικά σε μια επιχείρηση πολλών δισεκατομμυρίων δολαρίων, εστιάζοντας στις ανάγκες των πελατών, την ευελιξία, την καινοτομία, τη σχέση κόστους-αποτελεσματικότητας και την ασφάλεια. Η AWS έχει πλέον ετήσιο ρυθμό εσόδων 85 δισεκατομμυρίων δολαρίων και προσφέρει πάνω από 3,300 νέες δυνατότητες και υπηρεσίες κάθε χρόνο, καλύπτοντας ένα ευρύ φάσμα πελατών από νεοφυείς επιχειρήσεις έως πολυεθνικές εταιρείες και οργανισμούς του δημόσιου τομέα. | Η Amazon είναι επιτυχημένη λόγω των καινοτόμων επιχειρηματικών μοντέλων, των συνεχών τεχνολογικών εξελίξεων και των στρατηγικών οργανωτικών αλλαγών της. Η εταιρεία έχει διαταράξει συνεχώς τις παραδοσιακές βιομηχανίες εισάγοντας νέες ιδέες, όπως μια πλατφόρμα ηλεκτρονικού εμπορίου για διάφορα προϊόντα και υπηρεσίες, μια αγορά τρίτων, υπηρεσίες υποδομής cloud (AWS), τον ηλεκτρονικό αναγνώστη Kindle και τον προσωπικό βοηθό που βασίζεται στη φωνή Alexa . Επιπλέον, η Amazon έχει προβεί σε διαρθρωτικές αλλαγές για να βελτιώσει την αποτελεσματικότητά της, όπως η αναδιοργάνωση του δικτύου εκπλήρωσής της στις ΗΠΑ για να μειώσει το κόστος και τους χρόνους παράδοσης, συμβάλλοντας περαιτέρω στην επιτυχία της. | Παρόμοια με τον εξαγωγέα αλυσίδας LLM, το φίλτρο αλυσίδας LLM διασφαλίζει ότι, παρόλο που καλύπτονται τα βασικά σημεία, η έξοδος είναι αποτελεσματική για πελάτες που αναζητούν συνοπτικές και συναφείς απαντήσεις. |
Συγκρίνοντας αυτές τις διαφορετικές τεχνικές, μπορούμε να δούμε ότι σε περιβάλλοντα όπως η λεπτομερής μετάβαση του AWS από μια απλή υπηρεσία σε μια σύνθετη οντότητα πολλών δισεκατομμυρίων δολαρίων ή η εξήγηση των στρατηγικών επιτυχιών της Amazon, η κανονική αλυσίδα retriever δεν έχει την ακρίβεια που προσφέρουν οι πιο εξελιγμένες τεχνικές. οδηγώντας σε λιγότερο στοχευμένες πληροφορίες. Αν και είναι ορατές πολύ λίγες διαφορές μεταξύ των προηγμένων τεχνικών που συζητήθηκαν, είναι πολύ πιο ενημερωτικές από τις κανονικές αλυσίδες retriever.
Για πελάτες σε κλάδους όπως η υγειονομική περίθαλψη, οι τηλεπικοινωνίες και οι χρηματοοικονομικές υπηρεσίες που θέλουν να εφαρμόσουν το RAG στις εφαρμογές τους, οι περιορισμοί της κανονικής αλυσίδας retriever στην παροχή ακρίβειας, αποφυγής πλεονασμάτων και αποτελεσματικής συμπίεσης πληροφοριών την καθιστούν λιγότερο κατάλληλη για την κάλυψη αυτών των αναγκών σε σύγκριση στις πιο προηγμένες τεχνικές ανάκτησης γονικών εγγράφων και τεχνικών συμπίεσης με βάση τα συμφραζόμενα. Αυτές οι τεχνικές είναι σε θέση να αποστάξουν τεράστιες ποσότητες πληροφοριών στις συγκεντρωμένες, εντυπωσιακές πληροφορίες που χρειάζεστε, ενώ συμβάλλουν στη βελτίωση της απόδοσης τιμής.
εκκαθάριση
Όταν ολοκληρώσετε τη λειτουργία του σημειωματάριου, διαγράψτε τους πόρους που δημιουργήσατε για να αποφύγετε τη συγκέντρωση χρεώσεων για τους πόρους που χρησιμοποιούνται:
Συμπέρασμα
Σε αυτήν την ανάρτηση, παρουσιάσαμε μια λύση που σας επιτρέπει να εφαρμόσετε τις τεχνικές γονικής ανάκτησης εγγράφων και συμφραζόμενων αλυσίδων συμπίεσης για να βελτιώσετε την ικανότητα των LLM να επεξεργάζονται και να δημιουργούν πληροφορίες. Δοκιμάσαμε αυτές τις προηγμένες τεχνικές RAG με τα μοντέλα Mixtral-8x7B Instruct και BGE Large En που είναι διαθέσιμα με το SageMaker JumpStart. Εξερευνήσαμε επίσης τη χρήση μόνιμης αποθήκευσης για ενσωματώσεις και κομμάτια εγγράφων και ενσωμάτωση με καταστήματα δεδομένων επιχειρήσεων.
Οι τεχνικές που εφαρμόσαμε όχι μόνο βελτιώνουν τον τρόπο με τον οποίο τα μοντέλα LLM έχουν πρόσβαση και ενσωματώνουν εξωτερική γνώση, αλλά βελτιώνουν επίσης σημαντικά την ποιότητα, τη συνάφεια και την αποτελεσματικότητα των αποτελεσμάτων τους. Συνδυάζοντας την ανάκτηση από μεγάλα σώματα κειμένου με δυνατότητες δημιουργίας γλώσσας, αυτές οι προηγμένες τεχνικές RAG επιτρέπουν στα LLM να παράγουν πιο πραγματικές, συνεκτικές και κατάλληλες για το πλαίσιο απαντήσεις, βελτιώνοντας την απόδοσή τους σε διάφορες εργασίες επεξεργασίας φυσικής γλώσσας.
Το SageMaker JumpStart βρίσκεται στο κέντρο αυτής της λύσης. Με το SageMaker JumpStart, αποκτάτε πρόσβαση σε μια εκτεταμένη ποικιλία μοντέλων ανοιχτού και κλειστού κώδικα, απλοποιώντας τη διαδικασία έναρξης με την ML και επιτρέποντας τον γρήγορο πειραματισμό και την ανάπτυξη. Για να ξεκινήσετε την ανάπτυξη αυτής της λύσης, μεταβείτε στο σημειωματάριο στο GitHub repo.
Σχετικά με τους Συγγραφείς
 Niithiyn Vijeaswaran είναι αρχιτέκτονας λύσεων στην AWS. Η περιοχή εστίασής του είναι οι παραγωγικοί επιταχυντές AI και AWS AI. Είναι κάτοχος πτυχίου Πληροφορικής και Βιοπληροφορικής. Η Niithiyn συνεργάζεται στενά με την ομάδα Generative AI GTM για να επιτρέψει στους πελάτες AWS σε πολλαπλά μέτωπα και να επιταχύνει την υιοθέτηση της γενετικής AI. Είναι φανατικός θαυμαστής των Ντάλας Μάβερικς και του αρέσει να συλλέγει αθλητικά παπούτσια.
Niithiyn Vijeaswaran είναι αρχιτέκτονας λύσεων στην AWS. Η περιοχή εστίασής του είναι οι παραγωγικοί επιταχυντές AI και AWS AI. Είναι κάτοχος πτυχίου Πληροφορικής και Βιοπληροφορικής. Η Niithiyn συνεργάζεται στενά με την ομάδα Generative AI GTM για να επιτρέψει στους πελάτες AWS σε πολλαπλά μέτωπα και να επιταχύνει την υιοθέτηση της γενετικής AI. Είναι φανατικός θαυμαστής των Ντάλας Μάβερικς και του αρέσει να συλλέγει αθλητικά παπούτσια.
 Sebastian Bustillo είναι αρχιτέκτονας λύσεων στην AWS. Επικεντρώνεται στις τεχνολογίες AI/ML με βαθύ πάθος για την παραγωγική τεχνητή νοημοσύνη και τους επιταχυντές υπολογιστών. Στην AWS, βοηθά τους πελάτες να ξεκλειδώσουν την επιχειρηματική αξία μέσω της γενετικής τεχνητής νοημοσύνης. Όταν δεν είναι στη δουλειά, του αρέσει να παρασκευάζει έναν τέλειο καφέ και να εξερευνά τον κόσμο με τη γυναίκα του.
Sebastian Bustillo είναι αρχιτέκτονας λύσεων στην AWS. Επικεντρώνεται στις τεχνολογίες AI/ML με βαθύ πάθος για την παραγωγική τεχνητή νοημοσύνη και τους επιταχυντές υπολογιστών. Στην AWS, βοηθά τους πελάτες να ξεκλειδώσουν την επιχειρηματική αξία μέσω της γενετικής τεχνητής νοημοσύνης. Όταν δεν είναι στη δουλειά, του αρέσει να παρασκευάζει έναν τέλειο καφέ και να εξερευνά τον κόσμο με τη γυναίκα του.
 Αρμάντο Ντίαζ είναι αρχιτέκτονας λύσεων στην AWS. Εστιάζει στη δημιουργία AI, AI/ML και Data Analytics. Στην AWS, η Armando βοηθά τους πελάτες να ενσωματώσουν στα συστήματά τους δυνατότητες δημιουργίας τεχνητής νοημοσύνης αιχμής, ενισχύοντας την καινοτομία και το ανταγωνιστικό πλεονέκτημα. Όταν δεν είναι στη δουλειά, του αρέσει να περνά χρόνο με τη γυναίκα και την οικογένειά του, να κάνει πεζοπορία και να ταξιδεύει σε όλο τον κόσμο.
Αρμάντο Ντίαζ είναι αρχιτέκτονας λύσεων στην AWS. Εστιάζει στη δημιουργία AI, AI/ML και Data Analytics. Στην AWS, η Armando βοηθά τους πελάτες να ενσωματώσουν στα συστήματά τους δυνατότητες δημιουργίας τεχνητής νοημοσύνης αιχμής, ενισχύοντας την καινοτομία και το ανταγωνιστικό πλεονέκτημα. Όταν δεν είναι στη δουλειά, του αρέσει να περνά χρόνο με τη γυναίκα και την οικογένειά του, να κάνει πεζοπορία και να ταξιδεύει σε όλο τον κόσμο.
 Δρ Φαρούκ Σαμπίρ είναι Ανώτερος Αρχιτέκτονας Λύσεων Ειδικός Τεχνητής Νοημοσύνης και Μηχανικής Μάθησης στο AWS. Είναι κάτοχος διδακτορικού και μεταπτυχιακού τίτλου στον Ηλεκτρολόγο Μηχανικό από το Πανεπιστήμιο του Τέξας στο Ώστιν και μεταπτυχιακό στην Επιστήμη Υπολογιστών από το Ινστιτούτο Τεχνολογίας της Τζόρτζια. Έχει πάνω από 15 χρόνια εργασιακή εμπειρία και επίσης του αρέσει να διδάσκει και να καθοδηγεί φοιτητές. Στην AWS, βοηθά τους πελάτες να διαμορφώσουν και να λύσουν τα επιχειρηματικά τους προβλήματα στην επιστήμη δεδομένων, τη μηχανική μάθηση, την όραση υπολογιστών, την τεχνητή νοημοσύνη, την αριθμητική βελτιστοποίηση και τους σχετικούς τομείς. Με έδρα το Ντάλας του Τέξας, αυτός και η οικογένειά του λατρεύουν να ταξιδεύουν και να κάνουν μακρινά οδικά ταξίδια.
Δρ Φαρούκ Σαμπίρ είναι Ανώτερος Αρχιτέκτονας Λύσεων Ειδικός Τεχνητής Νοημοσύνης και Μηχανικής Μάθησης στο AWS. Είναι κάτοχος διδακτορικού και μεταπτυχιακού τίτλου στον Ηλεκτρολόγο Μηχανικό από το Πανεπιστήμιο του Τέξας στο Ώστιν και μεταπτυχιακό στην Επιστήμη Υπολογιστών από το Ινστιτούτο Τεχνολογίας της Τζόρτζια. Έχει πάνω από 15 χρόνια εργασιακή εμπειρία και επίσης του αρέσει να διδάσκει και να καθοδηγεί φοιτητές. Στην AWS, βοηθά τους πελάτες να διαμορφώσουν και να λύσουν τα επιχειρηματικά τους προβλήματα στην επιστήμη δεδομένων, τη μηχανική μάθηση, την όραση υπολογιστών, την τεχνητή νοημοσύνη, την αριθμητική βελτιστοποίηση και τους σχετικούς τομείς. Με έδρα το Ντάλας του Τέξας, αυτός και η οικογένειά του λατρεύουν να ταξιδεύουν και να κάνουν μακρινά οδικά ταξίδια.
 Μάρκο Πούνιο είναι ένας αρχιτέκτονας λύσεων που επικεντρώνεται στη στρατηγική τεχνητής νοημοσύνης που δημιουργεί, εφαρμόζει λύσεις τεχνητής νοημοσύνης και διεξάγει έρευνα για να βοηθήσει τους πελάτες να αυξήσουν την κλίμακα στο AWS. Ο Marco είναι ένας εγγενής σύμβουλος ψηφιακού cloud με εμπειρία στους κλάδους FinTech, Healthcare & Life Sciences, Software-as-a-service, και πιο πρόσφατα, στις βιομηχανίες τηλεπικοινωνιών. Είναι διπλωματούχος τεχνολόγος με πάθος για τη μηχανική μάθηση, την τεχνητή νοημοσύνη και τις συγχωνεύσεις και εξαγορές. Ο Μάρκο εδρεύει στο Σιάτλ της Ουάσινγκτον και του αρέσει να γράφει, να διαβάζει, να ασκείται και να δημιουργεί εφαρμογές στον ελεύθερο χρόνο του.
Μάρκο Πούνιο είναι ένας αρχιτέκτονας λύσεων που επικεντρώνεται στη στρατηγική τεχνητής νοημοσύνης που δημιουργεί, εφαρμόζει λύσεις τεχνητής νοημοσύνης και διεξάγει έρευνα για να βοηθήσει τους πελάτες να αυξήσουν την κλίμακα στο AWS. Ο Marco είναι ένας εγγενής σύμβουλος ψηφιακού cloud με εμπειρία στους κλάδους FinTech, Healthcare & Life Sciences, Software-as-a-service, και πιο πρόσφατα, στις βιομηχανίες τηλεπικοινωνιών. Είναι διπλωματούχος τεχνολόγος με πάθος για τη μηχανική μάθηση, την τεχνητή νοημοσύνη και τις συγχωνεύσεις και εξαγορές. Ο Μάρκο εδρεύει στο Σιάτλ της Ουάσινγκτον και του αρέσει να γράφει, να διαβάζει, να ασκείται και να δημιουργεί εφαρμογές στον ελεύθερο χρόνο του.
 AJ Dhimine είναι αρχιτέκτονας λύσεων στην AWS. Ειδικεύεται στη γενετική τεχνητή νοημοσύνη, στους υπολογιστές χωρίς διακομιστή και στην ανάλυση δεδομένων. Είναι ενεργό μέλος/μέντορας στην Κοινότητα Τεχνικού Πεδίου Μηχανικής Μάθησης και έχει δημοσιεύσει αρκετές επιστημονικές εργασίες σε διάφορα θέματα AI/ML. Συνεργάζεται με πελάτες, από νεοφυείς επιχειρήσεις έως επιχειρήσεις, για την ανάπτυξη AWSome λύσεων τεχνητής νοημοσύνης. Είναι ιδιαίτερα παθιασμένος με την αξιοποίηση μοντέλων μεγάλων γλωσσών για προηγμένες αναλύσεις δεδομένων και την εξερεύνηση πρακτικών εφαρμογών που αντιμετωπίζουν τις προκλήσεις του πραγματικού κόσμου. Εκτός δουλειάς, ο AJ απολαμβάνει τα ταξίδια και αυτή τη στιγμή βρίσκεται σε 53 χώρες με στόχο να επισκεφτεί κάθε χώρα στον κόσμο.
AJ Dhimine είναι αρχιτέκτονας λύσεων στην AWS. Ειδικεύεται στη γενετική τεχνητή νοημοσύνη, στους υπολογιστές χωρίς διακομιστή και στην ανάλυση δεδομένων. Είναι ενεργό μέλος/μέντορας στην Κοινότητα Τεχνικού Πεδίου Μηχανικής Μάθησης και έχει δημοσιεύσει αρκετές επιστημονικές εργασίες σε διάφορα θέματα AI/ML. Συνεργάζεται με πελάτες, από νεοφυείς επιχειρήσεις έως επιχειρήσεις, για την ανάπτυξη AWSome λύσεων τεχνητής νοημοσύνης. Είναι ιδιαίτερα παθιασμένος με την αξιοποίηση μοντέλων μεγάλων γλωσσών για προηγμένες αναλύσεις δεδομένων και την εξερεύνηση πρακτικών εφαρμογών που αντιμετωπίζουν τις προκλήσεις του πραγματικού κόσμου. Εκτός δουλειάς, ο AJ απολαμβάνει τα ταξίδια και αυτή τη στιγμή βρίσκεται σε 53 χώρες με στόχο να επισκεφτεί κάθε χώρα στον κόσμο.
- SEO Powered Content & PR Distribution. Ενισχύστε σήμερα.
- PlatoData.Network Vertical Generative Ai. Ενδυναμώστε τον εαυτό σας. Πρόσβαση εδώ.
- PlatoAiStream. Web3 Intelligence. Ενισχύθηκε η γνώση. Πρόσβαση εδώ.
- PlatoESG. Ανθρακας, Cleantech, Ενέργεια, Περιβάλλον, Ηλιακός, Διαχείριση των αποβλήτων. Πρόσβαση εδώ.
- PlatoHealth. Ευφυΐα βιοτεχνολογίας και κλινικών δοκιμών. Πρόσβαση εδώ.
- πηγή: https://aws.amazon.com/blogs/machine-learning/advanced-rag-patterns-on-amazon-sagemaker/

