Ζούμε σε μια εποχή όπου το μοντέλο μηχανικής μάθησης βρίσκεται στο αποκορύφωμά του. Σε σύγκριση με πριν από δεκαετίες, οι περισσότεροι άνθρωποι δεν θα είχαν ακούσει ποτέ για το ChatGPT ή την Τεχνητή Νοημοσύνη. Ωστόσο, αυτά είναι τα θέματα για τα οποία ο κόσμος συνεχίζει να μιλάει. Γιατί; Γιατί οι αξίες που δίνονται είναι τόσο σημαντικές σε σύγκριση με την προσπάθεια.
Η ανακάλυψη της τεχνητής νοημοσύνης τα τελευταία χρόνια θα μπορούσε να αποδοθεί σε πολλά πράγματα, αλλά ένα από αυτά είναι το μεγάλο γλωσσικό μοντέλο (LLM). Πολλοί χρήστες τεχνητής νοημοσύνης για τη δημιουργία κειμένου τροφοδοτούνται από το μοντέλο LLM. Για παράδειγμα, το ChatGPT χρησιμοποιεί το μοντέλο GPT του. Καθώς το LLM είναι ένα σημαντικό θέμα, θα πρέπει να το μάθουμε.
Αυτό το άρθρο θα συζητήσει τα μεγάλα γλωσσικά μοντέλα σε 3 επίπεδα δυσκολίας, αλλά θα θίξουμε μόνο ορισμένες πτυχές των LLM. Θα διαφέρουμε μόνο με τρόπο που επιτρέπει σε κάθε αναγνώστη να καταλάβει τι είναι το LLM. Έχοντας αυτό κατά νου, ας μπούμε σε αυτό.
Στο πρώτο επίπεδο, υποθέτουμε ότι ο αναγνώστης δεν γνωρίζει για το LLM και μπορεί να γνωρίζει λίγα για τον τομέα της επιστήμης δεδομένων/μηχανικής μάθησης. Έτσι, θα εισαγάγω εν συντομία την τεχνητή νοημοσύνη και τη μηχανική μάθηση πριν μεταβώ στα LLM.
Τεχνητή νοημοσύνη είναι η επιστήμη της ανάπτυξης ευφυών προγραμμάτων υπολογιστών. Προορίζεται για το πρόγραμμα να εκτελεί έξυπνες εργασίες που θα μπορούσαν να κάνουν οι άνθρωποι, αλλά δεν έχει περιορισμούς στις ανθρώπινες βιολογικές ανάγκες. Εκμάθηση μηχανών είναι ένα πεδίο της τεχνητής νοημοσύνης που εστιάζει σε μελέτες γενίκευσης δεδομένων με στατιστικούς αλγόριθμους. Κατά κάποιο τρόπο, η Μηχανική Μάθηση προσπαθεί να επιτύχει Τεχνητή Νοημοσύνη μέσω μελέτης δεδομένων, ώστε το πρόγραμμα να μπορεί να εκτελεί εργασίες νοημοσύνης χωρίς οδηγίες.
Ιστορικά, το πεδίο που διασταυρώνεται μεταξύ της πληροφορικής και της γλωσσολογίας ονομάζεται Φυσικό Επεξεργασία Γλωσσών πεδίο. Το πεδίο αφορά κυρίως οποιαδήποτε δραστηριότητα μηχανικής επεξεργασίας σε ανθρώπινο κείμενο, όπως έγγραφα κειμένου. Προηγουμένως, αυτό το πεδίο περιοριζόταν μόνο στο σύστημα που βασίζεται σε κανόνες, αλλά έγινε περισσότερο με την εισαγωγή προηγμένων ημι-εποπτευόμενων και μη εποπτευόμενων αλγορίθμων που επιτρέπουν στο μοντέλο να μαθαίνει χωρίς καμία κατεύθυνση. Ένα από τα προηγμένα μοντέλα για να γίνει αυτό είναι το μοντέλο γλώσσας.
Η γλώσσα μοντέλο είναι ένα πιθανό μοντέλο NLP για την εκτέλεση πολλών ανθρώπινων εργασιών όπως μετάφραση, διόρθωση γραμματικής και δημιουργία κειμένου. Η παλιά μορφή του γλωσσικού μοντέλου χρησιμοποιεί καθαρά στατιστικές προσεγγίσεις όπως η μέθοδος n-gram, όπου η υπόθεση είναι ότι η πιθανότητα της επόμενης λέξης εξαρτάται μόνο από τα δεδομένα σταθερού μεγέθους της προηγούμενης λέξης.
Ωστόσο, η εισαγωγή του Νευρικό σύστημα έχει εκθρονίσει την προηγούμενη προσέγγιση. Ένα τεχνητό νευρωνικό δίκτυο, ή NN, είναι ένα πρόγραμμα υπολογιστή που μιμείται τη δομή των νευρώνων του ανθρώπινου εγκεφάλου. Η προσέγγιση του νευρωνικού δικτύου είναι καλή για χρήση, επειδή μπορεί να χειριστεί την αναγνώριση σύνθετων προτύπων από τα δεδομένα κειμένου και να χειριστεί διαδοχικά δεδομένα όπως το κείμενο. Γι' αυτό το τρέχον μοντέλο γλώσσας βασίζεται συνήθως στο NN.
Μεγάλα γλωσσικά μοντέλα, ή LLM, είναι μοντέλα μηχανικής εκμάθησης που μαθαίνουν από έναν τεράστιο αριθμό εγγράφων δεδομένων για την εκτέλεση δημιουργίας γλωσσών γενικού σκοπού. Εξακολουθούν να είναι ένα μοντέλο γλώσσας, αλλά ο τεράστιος αριθμός παραμέτρων που μαθαίνει το NN τις κάνει να θεωρούνται μεγάλες. Με τους απλούς όρους, το μοντέλο θα μπορούσε να αποδώσει τον τρόπο με τον οποίο γράφουν οι άνθρωποι προβλέποντας πολύ καλά τις επόμενες λέξεις από τις δεδομένες λέξεις εισαγωγής.
Παραδείγματα εργασιών LLM περιλαμβάνουν μετάφραση γλώσσας, μηχανικό chatbot, απάντηση ερωτήσεων και πολλά άλλα. Από οποιαδήποτε ακολουθία εισαγωγής δεδομένων, το μοντέλο θα μπορούσε να αναγνωρίσει σχέσεις μεταξύ των λέξεων και να δημιουργήσει έξοδο κατάλληλο από την εντολή.
Σχεδόν όλα τα προϊόντα Generative AI που διαθέτουν κάτι χρησιμοποιώντας τη δημιουργία κειμένου τροφοδοτούνται από τα LLM. Μεγάλα προϊόντα όπως το ChatGPT, το Google's Bard και πολλά άλλα χρησιμοποιούν LLM ως βάση του προϊόντος τους.
Ο αναγνώστης έχει γνώσεις επιστήμης δεδομένων, αλλά πρέπει να μάθει περισσότερα για το LLM σε αυτό το επίπεδο. Τουλάχιστον, ο αναγνώστης μπορεί να κατανοήσει τους όρους που χρησιμοποιούνται στο πεδίο δεδομένων. Σε αυτό το επίπεδο, θα βουτήξαμε βαθύτερα στη βασική αρχιτεκτονική.
Όπως εξηγήθηκε προηγουμένως, το LLM είναι ένα μοντέλο νευρωνικού δικτύου που εκπαιδεύεται σε τεράστιες ποσότητες δεδομένων κειμένου. Για να κατανοήσουμε περαιτέρω αυτήν την έννοια, θα ήταν ωφέλιμο να κατανοήσουμε πώς λειτουργούν τα νευρωνικά δίκτυα και η βαθιά μάθηση.
Στο προηγούμενο επίπεδο, εξηγήσαμε ότι ένας νευρικός νευρώνας είναι ένα μοντέλο που μιμείται τη νευρική δομή του ανθρώπινου εγκεφάλου. Το κύριο στοιχείο του Νευρωνικού Δικτύου είναι οι νευρώνες, που συχνά ονομάζονται κόμβοι. Για να εξηγήσετε καλύτερα την έννοια, δείτε την τυπική αρχιτεκτονική νευρωνικών δικτύων στην παρακάτω εικόνα.
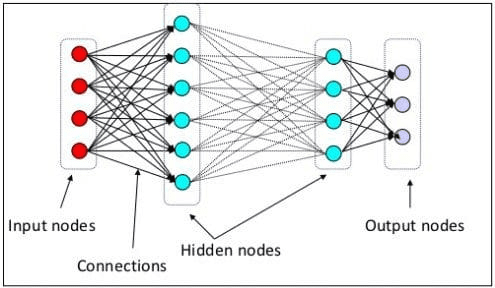
Αρχιτεκτονική Νευρωνικών Δικτύων (Πηγή εικόνας: KDnuggets)
Όπως μπορούμε να δούμε στην παραπάνω εικόνα, το Νευρωνικό Δίκτυο αποτελείται από τρία επίπεδα:
- Επίπεδο εισόδου όπου λαμβάνει τις πληροφορίες και τις μεταφέρει στους άλλους κόμβους στο επόμενο επίπεδο.
- Κρυφά επίπεδα κόμβου όπου γίνονται όλοι οι υπολογισμοί.
- Επίπεδο κόμβου εξόδου όπου βρίσκονται οι υπολογιστικές έξοδοι.
Ονομάζεται βαθιά μάθηση όταν εκπαιδεύουμε το μοντέλο νευρωνικών μας δικτύου με δύο ή περισσότερα κρυφά επίπεδα. Ονομάζεται βαθιά γιατί χρησιμοποιεί πολλά στρώματα ενδιάμεσα. Το πλεονέκτημα των μοντέλων βαθιάς μάθησης είναι ότι μαθαίνουν αυτόματα και εξάγουν χαρακτηριστικά από τα δεδομένα για τα οποία τα παραδοσιακά μοντέλα μηχανικής μάθησης δεν είναι σε θέση.
Στο Large Language Model, η βαθιά μάθηση είναι σημαντική καθώς το μοντέλο βασίζεται σε αρχιτεκτονικές βαθιών νευρωνικών δικτύων. Λοιπόν, γιατί ονομάζεται LLM; Είναι επειδή δισεκατομμύρια επίπεδα εκπαιδεύονται σε τεράστιες ποσότητες δεδομένων κειμένου. Τα επίπεδα θα παράγουν παραμέτρους μοντέλου που βοηθούν το μοντέλο να μάθει πολύπλοκα μοτίβα στη γλώσσα, όπως γραμματική, στυλ γραφής και πολλά άλλα.
Η απλοποιημένη διαδικασία της εκπαίδευσης μοντέλου φαίνεται στην παρακάτω εικόνα.
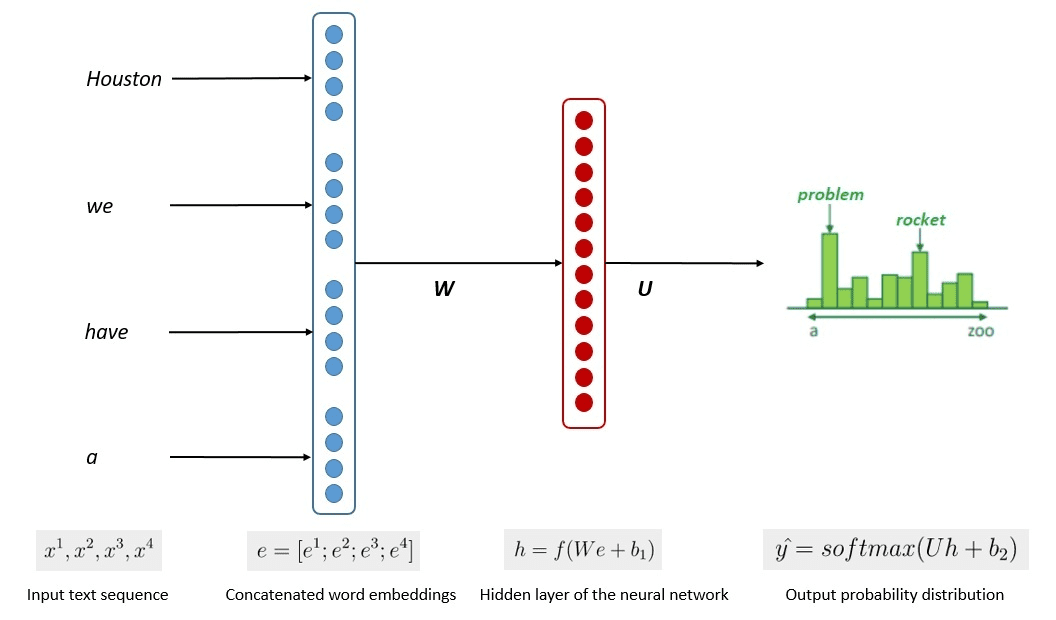
Εικόνα από Kumar Chandrakant (Πηγή: Baeldung.com)
Η διαδικασία έδειξε ότι τα μοντέλα μπορούσαν να δημιουργήσουν σχετικό κείμενο με βάση την πιθανότητα κάθε λέξης ή πρότασης των δεδομένων εισόδου. Στα LLMs, η προηγμένη προσέγγιση χρησιμοποιεί αυτο-εποπτευόμενη μάθηση και ημι-εποπτευόμενη μάθηση για την επίτευξη της ικανότητας γενικού σκοπού.
Η αυτοεποπτευόμενη μάθηση είναι μια τεχνική όπου δεν έχουμε ετικέτες και, αντίθετα, τα δεδομένα εκπαίδευσης παρέχουν την ίδια την ανατροφοδότηση της εκπαίδευσης. Χρησιμοποιείται στη διαδικασία εκπαίδευσης LLM, καθώς τα δεδομένα συνήθως δεν διαθέτουν ετικέτες. Στο LLM, θα μπορούσε κανείς να χρησιμοποιήσει το περιβάλλον ως ένδειξη για να προβλέψει τις επόμενες λέξεις. Αντίθετα, η ημι-εποπτευόμενη μάθηση συνδυάζει τις εποπτευόμενες και μη εποπτευόμενες έννοιες μάθησης με μια μικρή ποσότητα δεδομένων με ετικέτα για να δημιουργήσει νέες ετικέτες για μεγάλο αριθμό δεδομένων χωρίς ετικέτα. Η ημι-εποπτευόμενη μάθηση χρησιμοποιείται συνήθως για LLM με συγκεκριμένες ανάγκες περιβάλλοντος ή τομέα.
Στο τρίτο επίπεδο, θα συζητούσαμε το LLM πιο βαθιά, ειδικά για την αντιμετώπιση της δομής του LLM και του τρόπου με τον οποίο θα μπορούσε να επιτύχει την ανθρώπινη ικανότητα παραγωγής.
Έχουμε συζητήσει ότι το LLM βασίζεται στο μοντέλο νευρωνικών δικτύων με τεχνικές Deep Learning. Το LLM έχει συνήθως χτιστεί με βάση με βάση μετασχηματιστή αρχιτεκτονική τα τελευταία χρόνια. Ο μετασχηματιστής βασίζεται στον μηχανισμό προσοχής πολλαπλών κεφαλών που εισάγεται από Βασουάνι et αϊ. (2017) και έχει χρησιμοποιηθεί σε πολλά LLM.
Οι μετασχηματιστές είναι μια αρχιτεκτονική μοντέλου που προσπαθεί να επιλύσει τις διαδοχικές εργασίες που είχαν προηγουμένως συναντηθεί στα RNN και LSTM. Ο παλιός τρόπος του Γλωσσικού Μοντέλου ήταν η χρήση RNN και LSTM για την επεξεργασία δεδομένων διαδοχικά, όπου το μοντέλο χρησιμοποιούσε κάθε έξοδο λέξης και τις επαναφέρει ώστε το μοντέλο να μην ξεχάσει. Ωστόσο, έχουν προβλήματα με δεδομένα μακράς ακολουθίας μόλις εισαχθούν οι μετασχηματιστές.
Πριν προχωρήσουμε βαθύτερα στους Transformers, θέλω να εισαγάγω την έννοια του κωδικοποιητή-αποκωδικοποιητή που χρησιμοποιήθηκε προηγουμένως σε RNN. Η δομή κωδικοποιητή-αποκωδικοποιητή επιτρέπει στο κείμενο εισόδου και εξόδου να μην έχουν το ίδιο μήκος. Το παράδειγμα χρήσης είναι μια μετάφραση γλώσσας, η οποία συχνά έχει διαφορετικό μέγεθος ακολουθίας.
Η δομή μπορεί να χωριστεί σε δύο. Το πρώτο μέρος ονομάζεται Encoder, το οποίο είναι ένα τμήμα που λαμβάνει ακολουθία δεδομένων και δημιουργεί μια νέα αναπαράσταση βάσει αυτής. Η αναπαράσταση θα χρησιμοποιηθεί στο δεύτερο μέρος του μοντέλου, που είναι ο αποκωδικοποιητής.
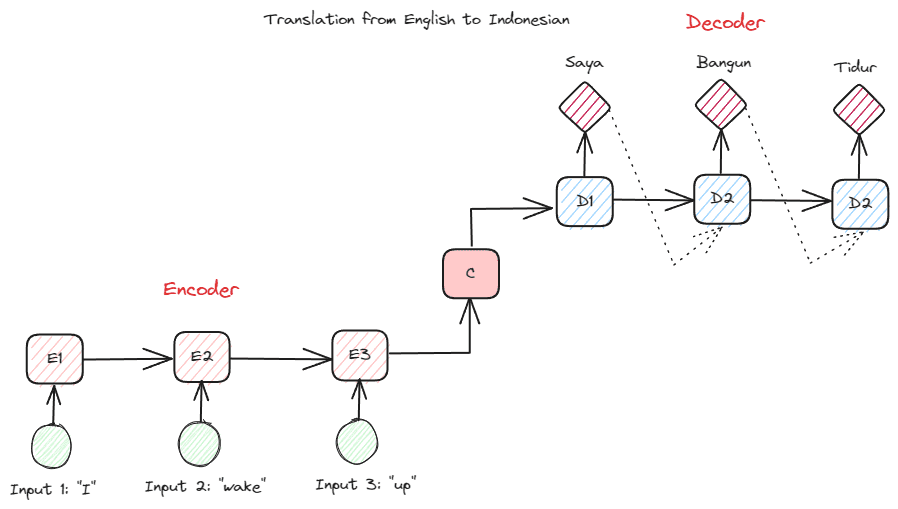
Εικόνα από συγγραφέα
Το πρόβλημα με το RNN είναι ότι το μοντέλο μπορεί να χρειάζεται βοήθεια για να θυμάται μεγαλύτερες ακολουθίες, ακόμη και με την παραπάνω δομή κωδικοποιητή-αποκωδικοποιητή. Αυτό είναι όπου ο μηχανισμός προσοχής θα μπορούσε να βοηθήσει στην επίλυση του προβλήματος, ένα επίπεδο που θα μπορούσε να λύσει μεγάλα προβλήματα εισόδου. Ο μηχανισμός προσοχής εισάγεται στην εργασία από Μπαχτανάου et αϊ. (2014) για να λύσετε τα RNN τύπου κωδικοποιητή-αποκωδικοποιητή εστιάζοντας σε ένα σημαντικό μέρος της εισόδου του μοντέλου ενώ έχετε την πρόβλεψη εξόδου.
Η δομή του μετασχηματιστή είναι εμπνευσμένη από τον τύπο κωδικοποιητή-αποκωδικοποιητή και έχει κατασκευαστεί με τις τεχνικές του μηχανισμού προσοχής, επομένως δεν χρειάζεται να επεξεργάζεται δεδομένα με διαδοχική σειρά. Το συνολικό μοντέλο μετασχηματιστών είναι δομημένο όπως στην παρακάτω εικόνα.

Transformers Architecture (Βασουάνι et αϊ. (2017))
Στην παραπάνω δομή, οι μετασχηματιστές κωδικοποιούν την ακολουθία διανυσμάτων δεδομένων στην ενσωμάτωση λέξης ενώ χρησιμοποιούν την αποκωδικοποίηση για να μετατρέψουν τα δεδομένα στην αρχική μορφή. Η κωδικοποίηση μπορεί να αποδώσει μια ορισμένη σημασία στην είσοδο με τον μηχανισμό προσοχής.
Έχουμε μιλήσει λίγο για μετασχηματιστές που κωδικοποιούν το διάνυσμα δεδομένων, αλλά τι είναι το διάνυσμα δεδομένων; Ας το συζητήσουμε. Στο μοντέλο μηχανικής εκμάθησης, δεν μπορούμε να εισαγάγουμε τα ακατέργαστα δεδομένα φυσικής γλώσσας στο μοντέλο, επομένως πρέπει να τα μετατρέψουμε σε αριθμητικές μορφές. Η διαδικασία μετασχηματισμού ονομάζεται ενσωμάτωση λέξης, όπου κάθε λέξη εισόδου υποβάλλεται σε επεξεργασία μέσω του μοντέλου ενσωμάτωσης λέξεων για να ληφθεί το διάνυσμα δεδομένων. Μπορούμε να χρησιμοποιήσουμε πολλές αρχικές ενσωματώσεις λέξεων, όπως π.χ Word2vec or Γάντι, αλλά πολλοί προχωρημένοι χρήστες προσπαθούν να τα βελτιώσουν χρησιμοποιώντας το λεξιλόγιό τους. Σε μια βασική μορφή, η διαδικασία ενσωμάτωσης λέξης μπορεί να παρουσιαστεί στην παρακάτω εικόνα.
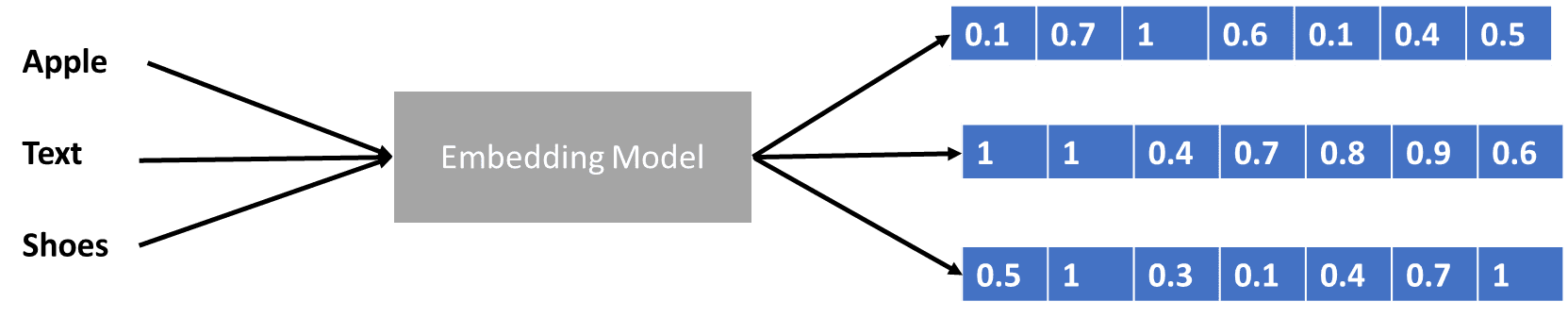
Εικόνα από συγγραφέα
Οι μετασχηματιστές θα μπορούσαν να δεχτούν την είσοδο και να παρέχουν πιο σχετικό πλαίσιο παρουσιάζοντας τις λέξεις σε αριθμητικές μορφές όπως το διάνυσμα δεδομένων παραπάνω. Στα LLM, οι ενσωματώσεις λέξεων συνήθως εξαρτώνται από το περιβάλλον, γενικά βελτιστοποιούνται ανάλογα με τις περιπτώσεις χρήσης και το επιδιωκόμενο αποτέλεσμα.
Συζητήσαμε το Large Language Model σε τρία επίπεδα δυσκολίας, από αρχάριους έως προχωρημένους. Από τη γενική χρήση του LLM μέχρι τον τρόπο δομής του, μπορείτε να βρείτε μια εξήγηση που εξηγεί την έννοια με περισσότερες λεπτομέρειες.
Cornellius Yudha Wijaya είναι βοηθός διευθυντής επιστήμης δεδομένων και συγγραφέας δεδομένων. Ενώ εργάζεται με πλήρη απασχόληση στην Allianz Indonesia, του αρέσει να μοιράζεται συμβουλές για Python και Data μέσω των μέσων κοινωνικής δικτύωσης και των μέσων συγγραφής.
- SEO Powered Content & PR Distribution. Ενισχύστε σήμερα.
- PlatoData.Network Vertical Generative Ai. Ενδυναμώστε τον εαυτό σας. Πρόσβαση εδώ.
- PlatoAiStream. Web3 Intelligence. Ενισχύθηκε η γνώση. Πρόσβαση εδώ.
- PlatoESG. Ανθρακας, Cleantech, Ενέργεια, Περιβάλλον, Ηλιακός, Διαχείριση των αποβλήτων. Πρόσβαση εδώ.
- PlatoHealth. Ευφυΐα βιοτεχνολογίας και κλινικών δοκιμών. Πρόσβαση εδώ.
- πηγή: https://www.kdnuggets.com/large-language-models-explained-in-3-levels-of-difficulty?utm_source=rss&utm_medium=rss&utm_campaign=large-language-models-explained-in-3-levels-of-difficulty

