Αυτή είναι μια guest post που γράφτηκε από κοινού με την ομάδα PyTorch του Meta και αποτελεί συνέχεια του Μέρος 1 αυτής της σειράς, όπου επιδεικνύουμε την απόδοση και την ευκολία εκτέλεσης του PyTorch 2.0 σε AWS.
Η έρευνα μηχανικής μάθησης (ML) έχει αποδείξει ότι τα μεγάλα γλωσσικά μοντέλα (LLM) που έχουν εκπαιδευτεί με σημαντικά μεγάλα σύνολα δεδομένων έχουν ως αποτέλεσμα καλύτερη ποιότητα μοντέλων. Τα τελευταία χρόνια, το μέγεθος των μοντέλων τρέχουσας γενιάς έχει αυξηθεί σημαντικά και απαιτούν σύγχρονα εργαλεία και υποδομές για να εκπαιδευτούν αποτελεσματικά και σε κλίμακα. Ο PyTorch Distributed Data Parallelism (DDP) βοηθά στην επεξεργασία δεδομένων σε κλίμακα με απλό και ισχυρό τρόπο, αλλά απαιτεί το μοντέλο να ταιριάζει σε μία GPU. Η βιβλιοθήκη PyTorch Fully Sharded Data Parallel (FSDP) σπάει αυτό το εμπόδιο, επιτρέποντας την κοινή χρήση μοντέλων να εκπαιδεύει μεγάλα μοντέλα σε παράλληλους εργάτες δεδομένων.
Η εκπαίδευση κατανεμημένων μοντέλων απαιτεί μια ομάδα κόμβων εργαζομένων που μπορούν να κλιμακωθούν. Υπηρεσία Amazon Elastic Kubernetes (Amazon EKS) είναι μια δημοφιλής υπηρεσία που συμμορφώνεται με το Kubernetes που απλοποιεί σημαντικά τη διαδικασία εκτέλεσης φόρτου εργασίας AI/ML, καθιστώντας την πιο διαχειρίσιμη και λιγότερο χρονοβόρα.
Σε αυτήν την ανάρτηση ιστολογίου, το AWS συνεργάζεται με την ομάδα PyTorch της Meta για να συζητήσει πώς να χρησιμοποιήσετε τη βιβλιοθήκη PyTorch FSDP για την επίτευξη γραμμικής κλιμάκωσης των μοντέλων βαθιάς μάθησης στο AWS χωρίς προβλήματα χρησιμοποιώντας το Amazon EKS και Εμπορευματοκιβώτια βαθιάς μάθησης AWS (DLCs). Αυτό το αποδεικνύουμε μέσα από μια βήμα προς βήμα υλοποίηση εκπαιδευτικών μοντέλων Llama7 13B, 70B και 2B χρησιμοποιώντας το Amazon EKS με 16 Amazon Elastic Compute Cloud (Amazon EC2) p4de.24xlarge περιπτώσεις (καθεμία με 8 NVIDIA A100 Tensor Core GPU και κάθε GPU με 80 GB μνήμη HBM2e) ή 16 EC2 σελ.5.48xlarge στιγμιότυπα (καθεμία με 8 NVIDIA H100 Tensor Core GPU και κάθε GPU με 80 GB μνήμη HBM3), επιτυγχάνοντας σχεδόν γραμμική κλιμάκωση της απόδοσης και τελικά επιτρέποντας ταχύτερο χρόνο εκπαίδευσης.
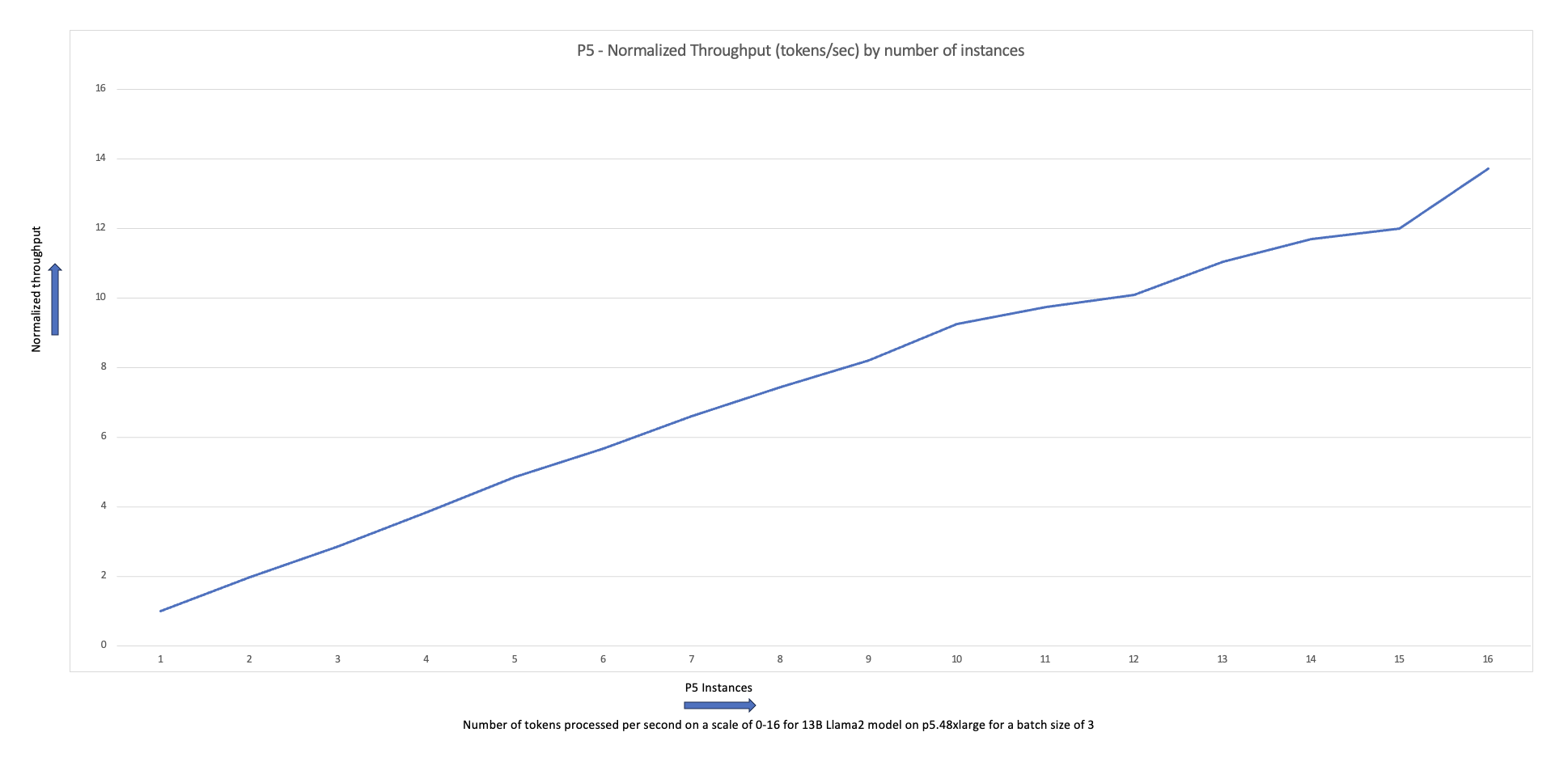
Το παρακάτω διάγραμμα κλιμάκωσης δείχνει ότι οι παρουσίες p5.48xlarge προσφέρουν απόδοση κλιμάκωσης 87% με τη λεπτή ρύθμιση του FSDP Llama2 σε μια διαμόρφωση συμπλέγματος 16 κόμβων.
Προκλήσεις της κατάρτισης LLM
Οι επιχειρήσεις υιοθετούν όλο και περισσότερο LLM για μια σειρά εργασιών, συμπεριλαμβανομένων των εικονικών βοηθών, της μετάφρασης, της δημιουργίας περιεχομένου και της όρασης υπολογιστή, για να βελτιώσουν την αποτελεσματικότητα και την ακρίβεια σε μια ποικιλία εφαρμογών.
Ωστόσο, η εκπαίδευση ή η τελειοποίηση αυτών των μεγάλων μοντέλων για μια προσαρμοσμένη περίπτωση χρήσης απαιτεί μεγάλο όγκο δεδομένων και υπολογιστική ισχύ, γεγονός που προσθέτει στη συνολική μηχανική πολυπλοκότητα της στοίβας ML. Αυτό οφείλεται επίσης στην περιορισμένη διαθέσιμη μνήμη σε μια μεμονωμένη GPU, η οποία περιορίζει το μέγεθος του μοντέλου που μπορεί να εκπαιδευτεί και επίσης περιορίζει το μέγεθος παρτίδας ανά GPU που χρησιμοποιείται κατά τη διάρκεια της εκπαίδευσης.
Για την αντιμετώπιση αυτής της πρόκλησης, διάφορες τεχνικές παραλληλισμού μοντέλων όπως π.χ DeepSpeed ZeRO και PyTorch FSDP δημιουργήθηκαν για να σας επιτρέψουν να ξεπεράσετε αυτό το εμπόδιο περιορισμένης μνήμης GPU. Αυτό γίνεται με την υιοθέτηση μιας τεχνικής παράλληλων δεδομένων, όπου κάθε επιταχυντής κρατά μόνο ένα κομμάτι (α θραύσμα αγγείου) ενός αντιγράφου μοντέλου αντί για ολόκληρο το αντίγραφο του μοντέλου, το οποίο μειώνει δραματικά το αποτύπωμα μνήμης της εργασίας εκπαίδευσης.
Αυτή η ανάρτηση δείχνει πώς μπορείτε να χρησιμοποιήσετε το PyTorch FSDP για να τελειοποιήσετε το μοντέλο Llama2 χρησιμοποιώντας το Amazon EKS. Αυτό το επιτυγχάνουμε μειώνοντας την ικανότητα υπολογισμού και GPU για να ανταποκριθούμε στις απαιτήσεις του μοντέλου.
Επισκόπηση FSDP
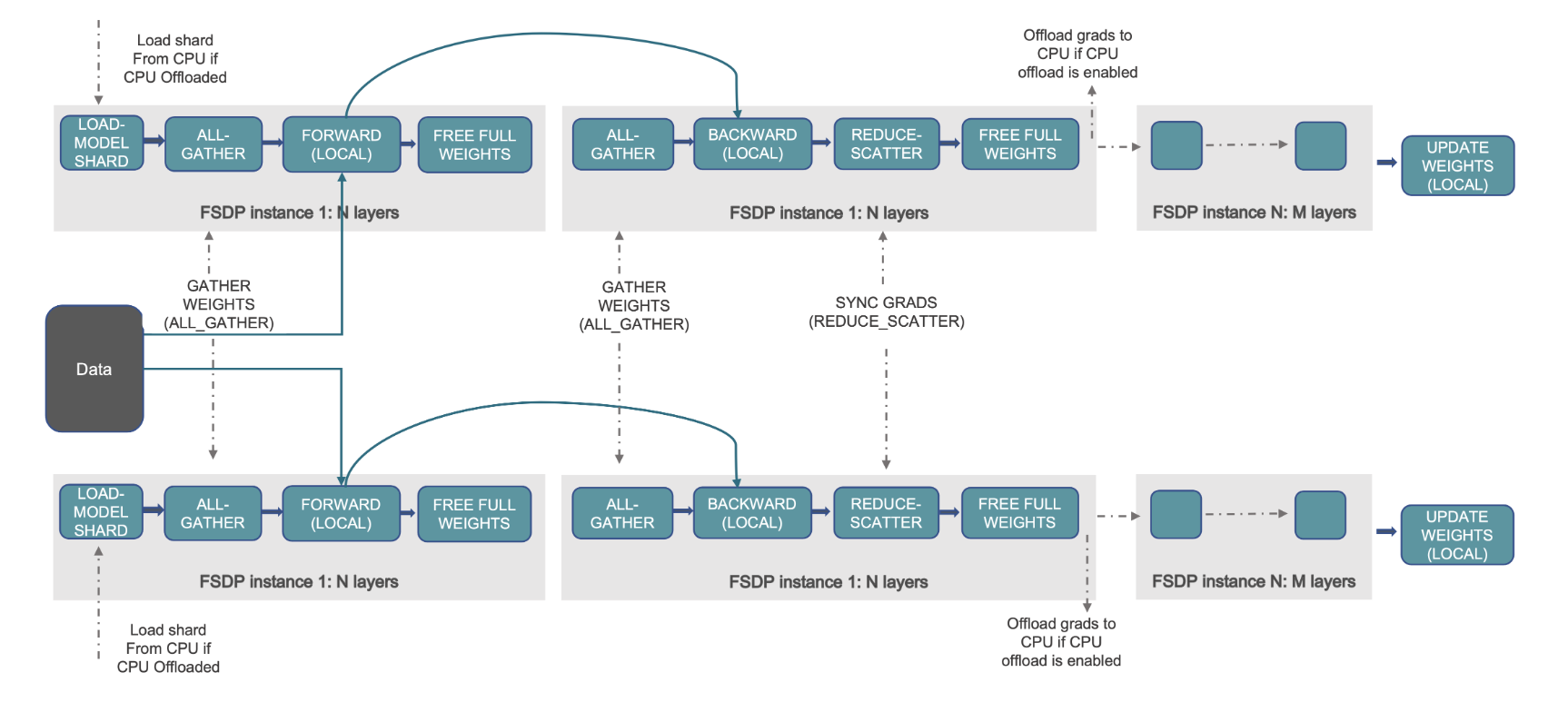
Στην εκπαίδευση PyTorch DDP, κάθε GPU (αναφέρεται ως α εργάτης στο πλαίσιο του PyTorch) διατηρεί ένα πλήρες αντίγραφο του μοντέλου, συμπεριλαμβανομένων των βαρών του μοντέλου, των διαβαθμίσεων και των καταστάσεων βελτιστοποίησης. Κάθε εργαζόμενος επεξεργάζεται μια παρτίδα δεδομένων και, στο τέλος του οπισθοδρομικού πάσου, χρησιμοποιεί ένα μειώνω πλήρως λειτουργία για τον συγχρονισμό των κλίσεων σε διαφορετικούς εργαζόμενους.
Η ύπαρξη ενός αντιγράφου του μοντέλου σε κάθε GPU περιορίζει το μέγεθος του μοντέλου που μπορεί να προσαρμοστεί σε μια ροή εργασίας DDP. Το FSDP βοηθά να ξεπεραστεί αυτός ο περιορισμός μοιράζοντας τις παραμέτρους του μοντέλου, τις καταστάσεις βελτιστοποίησης και τις κλίσεις μεταξύ των παράλληλων εργαζομένων δεδομένων, διατηρώντας παράλληλα την απλότητα του παραλληλισμού δεδομένων.
Αυτό φαίνεται στο ακόλουθο διάγραμμα, όπου στην περίπτωση του DDP, κάθε GPU διατηρεί ένα πλήρες αντίγραφο της κατάστασης του μοντέλου, συμπεριλαμβανομένης της κατάστασης βελτιστοποίησης (OS), των κλίσεων (G) και των παραμέτρων (P): M(OS + G + Ρ). Στο FSDP, κάθε GPU περιέχει μόνο ένα τμήμα της κατάστασης του μοντέλου, συμπεριλαμβανομένης της κατάστασης βελτιστοποίησης (OS), των κλίσεων (G) και των παραμέτρων (P): M (OS + G + P). Η χρήση του FSDP οδηγεί σε σημαντικά μικρότερο αποτύπωμα μνήμης GPU σε σύγκριση με το DDP σε όλους τους εργαζόμενους, επιτρέποντας την εκπαίδευση πολύ μεγάλων μοντέλων ή τη χρήση μεγαλύτερων μεγεθών παρτίδας για εργασίες εκπαίδευσης.

Αυτό, ωστόσο, έχει το κόστος της αύξησης των γενικών εξόδων επικοινωνίας, η οποία μετριάζεται μέσω βελτιστοποιήσεων FSDP, όπως οι επικαλυπτόμενες διαδικασίες επικοινωνίας και υπολογισμού με χαρακτηριστικά όπως προανάκληση. Για πιο λεπτομερείς πληροφορίες, ανατρέξτε στο Ξεκινώντας με το Fully Sharded Data Parallel (FSDP).
Το FSDP προσφέρει διάφορες παραμέτρους που σας επιτρέπουν να ρυθμίσετε την απόδοση και την αποδοτικότητα των εργασιών εκπαίδευσης σας. Μερικά από τα βασικά χαρακτηριστικά και δυνατότητες του FSDP περιλαμβάνουν:
- Πολιτική περιτύλιξης μετασχηματιστή
- Ευέλικτη μικτή ακρίβεια
- Σημείο ελέγχου ενεργοποίησης
- Διάφορες στρατηγικές διαμοιρασμού που ταιριάζουν σε διαφορετικές ταχύτητες δικτύου και τοπολογίες συμπλέγματος:
- FULL_SHARD – Παράμετροι, διαβαθμίσεις και καταστάσεις βελτιστοποίησης μοντέλου Shard
- HYBRID_SHARD – Πλήρες θραύσμα εντός ενός κόμβου DDP σε όλους τους κόμβους. υποστηρίζει μια ευέλικτη ομάδα διαμοιρασμού για ένα πλήρες αντίγραφο του μοντέλου (HSDP)
- SHARD_GRAD_OP – Διαβαθμίσεις μόνο θραυσμάτων και καταστάσεις βελτιστοποίησης
- NO_SHARD – Παρόμοιο με το DDP
Για περισσότερες πληροφορίες σχετικά με το FSDP, ανατρέξτε στο Αποτελεσματική Εκπαίδευση Μεγάλης Κλίμακας με Pytorch FSDP και AWS.
Το παρακάτω σχήμα δείχνει πώς λειτουργεί το FSDP για δύο παράλληλες διεργασίες δεδομένων.
Επισκόπηση λύσεων
Σε αυτήν την ανάρτηση, δημιουργήσαμε ένα σύμπλεγμα υπολογιστών χρησιμοποιώντας το Amazon EKS, το οποίο είναι μια διαχειριζόμενη υπηρεσία για την εκτέλεση του Kubernetes στο AWS Cloud και στα κέντρα δεδομένων εσωτερικού χώρου. Πολλοί πελάτες αγκαλιάζουν το Amazon EKS για να τρέξουν φόρτους εργασίας AI/ML που βασίζονται στο Kubernetes, εκμεταλλευόμενοι την απόδοση, την επεκτασιμότητα, την αξιοπιστία και τη διαθεσιμότητά του, καθώς και τις ενσωματώσεις του με δίκτυα AWS, ασφάλεια και άλλες υπηρεσίες.
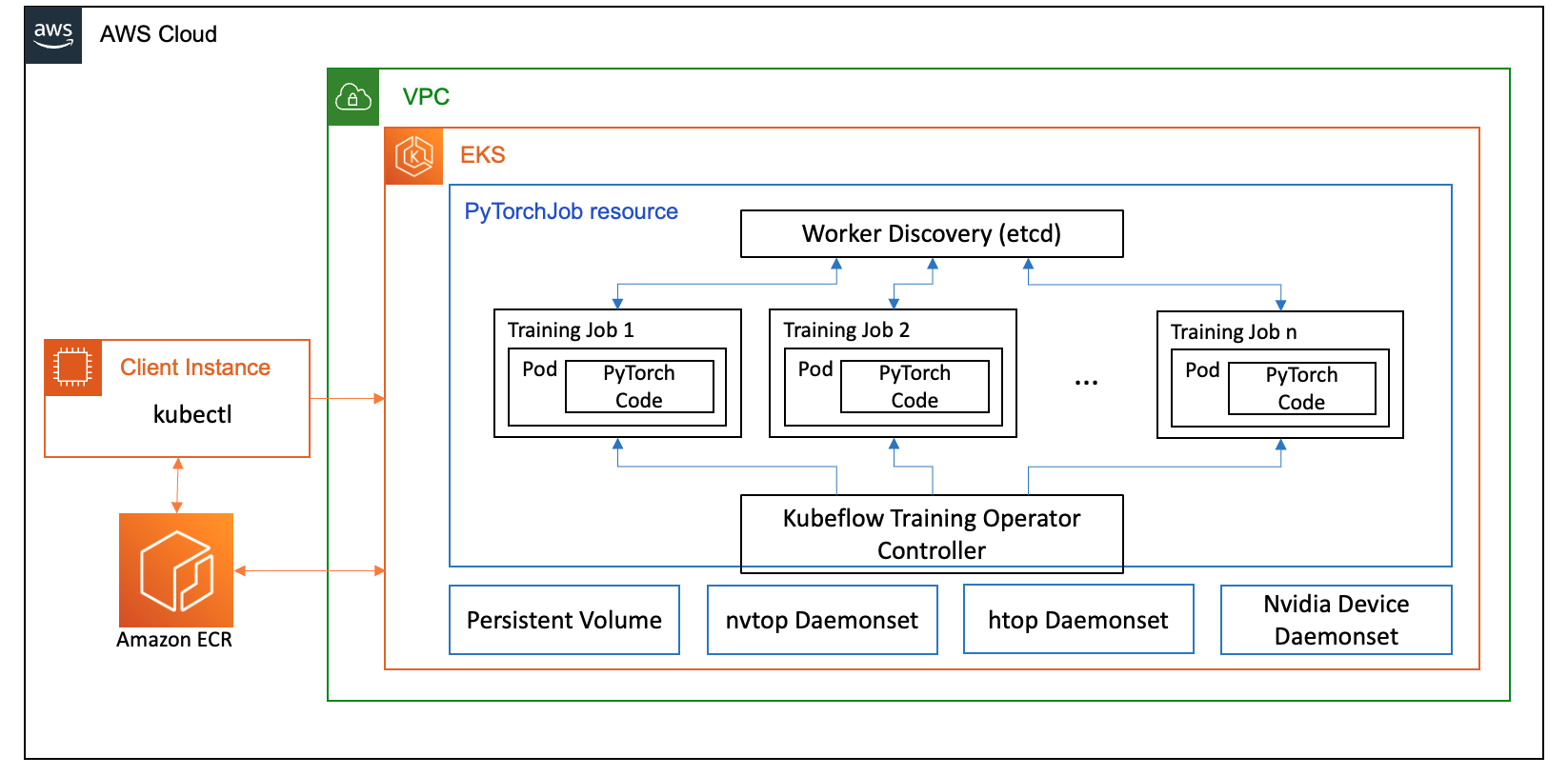
Για την περίπτωση χρήσης FSDP, χρησιμοποιούμε το Εκπαιδευτικός χειριστής Kubeflow στο Amazon EKS, το οποίο είναι ένα εγγενές έργο Kubernetes που διευκολύνει τη λεπτομερή ρύθμιση και την κλιμάκωση κατανεμημένη εκπαίδευση για μοντέλα ML. Υποστηρίζει διάφορα πλαίσια ML, συμπεριλαμβανομένου του PyTorch, το οποίο μπορείτε να χρησιμοποιήσετε για να αναπτύξετε και να διαχειριστείτε εργασίες εκπαίδευσης PyTorch σε κλίμακα.
Χρησιμοποιώντας τον προσαρμοσμένο πόρο PyTorchJob του Kubeflow Training Operator, εκτελούμε εκπαιδευτικές εργασίες στο Kubernetes με διαμορφώσιμο αριθμό αντιγράφων εργαζομένων που μας επιτρέπει να βελτιστοποιούμε τη χρήση των πόρων.
Τα παρακάτω είναι μερικά στοιχεία του εκπαιδευτικού χειριστή που παίζουν ρόλο στην περίπτωση χρήσης μικρορύθμισης Llama2:
- Ένας κεντρικός ελεγκτής Kubernetes που ενορχηστρώνει κατανεμημένες εργασίες εκπαίδευσης για το PyTorch.
- Το PyTorchJob, ένας προσαρμοσμένος πόρος Kubernetes για το PyTorch, που παρέχεται από τον Εκπαιδευτικό Διαχειριστή Kubeflow, για τον καθορισμό και την ανάπτυξη εργασιών εκπαίδευσης Llama2 στο Kubernetes.
- etcd, που σχετίζεται με την υλοποίηση του μηχανισμού ραντεβού για τον συντονισμό της κατανεμημένης εκπαίδευσης των μοντέλων PyTorch. Αυτό
etcdΟ διακομιστής, ως μέρος της διαδικασίας του ραντεβού, διευκολύνει τον συντονισμό και τον συγχρονισμό των συμμετεχόντων εργαζομένων κατά τη διάρκεια της κατανεμημένης εκπαίδευσης.
Το παρακάτω διάγραμμα απεικονίζει την αρχιτεκτονική λύσεων.
Οι περισσότερες λεπτομέρειες θα αφαιρεθούν από τα σενάρια αυτοματισμού που χρησιμοποιούμε για την εκτέλεση του παραδείγματος Llama2.
Χρησιμοποιούμε τις ακόλουθες αναφορές κώδικα σε αυτήν την περίπτωση χρήσης:
Τι είναι το Llama2;
Το Llama2 είναι ένα LLM προεκπαιδευμένο σε 2 τρισεκατομμύρια μάρκες κειμένου και κώδικα. Είναι ένα από τα μεγαλύτερα και πιο ισχυρά LLM που είναι διαθέσιμα σήμερα. Μπορείτε να χρησιμοποιήσετε το Llama2 για μια ποικιλία εργασιών, συμπεριλαμβανομένης της επεξεργασίας φυσικής γλώσσας (NLP), της δημιουργίας κειμένου και της μετάφρασης. Για περισσότερες πληροφορίες, ανατρέξτε στο Ξεκινώντας με το Llama.
Το Llama2 διατίθεται σε τρία διαφορετικά μεγέθη μοντέλων:
- Λάμα2-70β – Αυτό είναι το μεγαλύτερο μοντέλο Llama2, με 70 δισεκατομμύρια παραμέτρους. Είναι το πιο ισχυρό μοντέλο Llama2 και μπορεί να χρησιμοποιηθεί για τις πιο απαιτητικές εργασίες.
- Λάμα2-13β – Πρόκειται για ένα μεσαίου μεγέθους μοντέλο Llama2, με 13 δισεκατομμύρια παραμέτρους. Είναι μια καλή ισορροπία μεταξύ απόδοσης και αποδοτικότητας και μπορεί να χρησιμοποιηθεί για μια ποικιλία εργασιών.
- Λάμα2-7β – Αυτό είναι το μικρότερο μοντέλο Llama2, με 7 δισεκατομμύρια παραμέτρους. Είναι το πιο αποτελεσματικό μοντέλο Llama2 και μπορεί να χρησιμοποιηθεί για εργασίες που δεν απαιτούν το υψηλότερο επίπεδο απόδοσης.
Αυτή η ανάρτηση σάς δίνει τη δυνατότητα να ρυθμίσετε με ακρίβεια όλα αυτά τα μοντέλα στο Amazon EKS. Για να παρέχουμε μια απλή και αναπαραγώγιμη εμπειρία δημιουργίας ενός συμπλέγματος EKS και εκτέλεσης εργασιών FSDP σε αυτό, χρησιμοποιούμε το αυς-ντο-εκς έργο. Το παράδειγμα θα λειτουργήσει επίσης με ένα προϋπάρχον σύμπλεγμα EKS.
Μια αναλυτική παρουσίαση σε σενάριο είναι διαθέσιμη στο GitHub για μια ασυνήθιστη εμπειρία. Στις επόμενες ενότητες, εξηγούμε τη διαδικασία από άκρο σε άκρο με περισσότερες λεπτομέρειες.
Παροχή της υποδομής λύσης
Για τα πειράματα που περιγράφονται σε αυτήν την ανάρτηση, χρησιμοποιούμε συμπλέγματα με κόμβους p4de (A100 GPU) και p5 (H100 GPU).
Σύμπλεγμα με p4de.24xμεγάλους κόμβους
Για το σύμπλεγμα μας με κόμβους p4de, χρησιμοποιούμε τα ακόλουθα eks-gpu-p4de-odcr.yaml γραφή:
Χρησιμοποιώντας εκκτλ και το προηγούμενο μανιφέστο συμπλέγματος, δημιουργούμε ένα σύμπλεγμα με κόμβους p4de:
Σύμπλεγμα με p5.48xμεγάλους κόμβους
Ένα πρότυπο εδαφικής μορφής για ένα σύμπλεγμα EKS με κόμβους P5 βρίσκεται παρακάτω GitHub repo.
Μπορείτε να προσαρμόσετε το σύμπλεγμα μέσω του μεταβλητές.tf αρχείο και, στη συνέχεια, δημιουργήστε το μέσω του Terraform CLI:
Μπορείτε να επαληθεύσετε τη διαθεσιμότητα του συμπλέγματος εκτελώντας μια απλή εντολή kubectl:
Το σύμπλεγμα είναι υγιές εάν η έξοδος αυτής της εντολής εμφανίζει τον αναμενόμενο αριθμό κόμβων σε κατάσταση ετοιμότητας.
Αναπτύξτε προαπαιτούμενα
Για να τρέξουμε το FSDP στο Amazon EKS, χρησιμοποιούμε το PyTorchJob προσαρμοσμένος πόρος. Απαιτεί κλπ και Εκπαιδευτικός χειριστής Kubeflow ως προαπαιτούμενα.
Αναπτύξτε etcd με τον ακόλουθο κώδικα:
Αναπτύξτε το Kubeflow Training Operator με τον ακόλουθο κωδικό:
Δημιουργήστε και προωθήστε μια εικόνα κοντέινερ FSDP στο Amazon ECR
Χρησιμοποιήστε τον ακόλουθο κώδικα για να δημιουργήσετε μια εικόνα κοντέινερ FSDP και σπρώξτε την σε Μητρώο εμπορευματοκιβωτίων Amazon Elastic (Amazon ECR):
Δημιουργήστε το μανιφέστο FSDP PyTorchJob
Τοποθετήστε το Συμβολικό Hugging Face στο παρακάτω απόσπασμα πριν από την εκτέλεσή του:
Διαμορφώστε το PyTorchJob με .env αρχείο ή απευθείας στις μεταβλητές του περιβάλλοντος σας ως εξής:
Δημιουργήστε το μανιφέστο PyTorchJob χρησιμοποιώντας το πρότυπο fsdp και παράγω.sh script ή δημιουργήστε το απευθείας χρησιμοποιώντας το παρακάτω σενάριο:
Εκτελέστε το PyTorchJob
Εκτελέστε το PyTorchJob με τον ακόλουθο κώδικα:
Θα δείτε τον καθορισμένο αριθμό ομάδων εργασίας FDSP που έχουν δημιουργηθεί και, αφού τραβήξετε την εικόνα, θα εισέλθουν σε κατάσταση λειτουργίας.
Για να δείτε την κατάσταση του PyTorchJob, χρησιμοποιήστε τον ακόλουθο κώδικα:
Για να σταματήσετε το PyTorchJob, χρησιμοποιήστε τον ακόλουθο κώδικα:
Αφού ολοκληρωθεί μια εργασία, πρέπει να διαγραφεί πριν ξεκινήσει μια νέα εκτέλεση. Παρατηρήσαμε επίσης ότι η διαγραφή τουetcdpod και αφήνοντάς το να επανεκκινήσει πριν ξεκινήσει μια νέα εργασία βοηθά στην αποφυγή α RendezvousClosedError.
Κλιμακώστε το σύμπλεγμα
Μπορείτε να επαναλάβετε τα προηγούμενα βήματα δημιουργίας και εκτέλεσης εργασιών, ενώ μεταβάλλετε τον αριθμό και τον τύπο εμφάνισης των κόμβων εργαζομένων στο σύμπλεγμα. Αυτό σας δίνει τη δυνατότητα να δημιουργήσετε γραφήματα κλιμάκωσης όπως αυτό που παρουσιάστηκε προηγουμένως. Γενικά, θα πρέπει να δείτε μείωση του αποτυπώματος μνήμης GPU, μείωση του χρόνου εποχής και αύξηση της απόδοσης όταν προστίθενται περισσότεροι κόμβοι στο σύμπλεγμα. Το προηγούμενο γράφημα δημιουργήθηκε με τη διεξαγωγή πολλών πειραμάτων χρησιμοποιώντας μια ομάδα κόμβων p5 που ποικίλλει από 1 έως 16 κόμβους σε μέγεθος.
Παρατηρήστε τον φόρτο εργασίας εκπαίδευσης FSDP
Η παρατηρησιμότητα των παραγωγικών φόρτων εργασίας τεχνητής νοημοσύνης είναι σημαντική για να επιτρέψει την ορατότητα στις τρέχουσες εργασίες σας, καθώς και να βοηθήσει στη μεγιστοποίηση της χρήσης των υπολογιστικών σας πόρων. Σε αυτήν την ανάρτηση, χρησιμοποιούμε μερικά εγγενή και ανοιχτού κώδικα εργαλεία παρατηρητικότητας του Kubernetes για αυτόν τον σκοπό. Αυτά τα εργαλεία σάς δίνουν τη δυνατότητα να παρακολουθείτε σφάλματα, στατιστικά στοιχεία και συμπεριφορά μοντέλων, καθιστώντας την παρατηρησιμότητα της τεχνητής νοημοσύνης κρίσιμο μέρος κάθε περίπτωσης επιχειρηματικής χρήσης. Σε αυτή την ενότητα, δείχνουμε διάφορες προσεγγίσεις για την παρατήρηση εργασιών εκπαίδευσης FSDP.
Καταγραφή λοβών εργαζομένων
Στο πιο βασικό επίπεδο, πρέπει να μπορείτε να βλέπετε τα αρχεία καταγραφής των προπονητικών σας ομάδων. Αυτό μπορεί εύκολα να γίνει χρησιμοποιώντας τις εγγενείς εντολές του Kubernetes.
Αρχικά, ανακτήστε μια λίστα με ομάδες και εντοπίστε το όνομα αυτού για το οποίο θέλετε να δείτε αρχεία καταγραφής:
Στη συνέχεια, προβάλετε τα αρχεία καταγραφής για την επιλεγμένη ομάδα:

Μόνο ένας εργάτης (εκλεγμένος αρχηγός) αρχείο καταγραφής ομάδας θα παραθέτει τα συνολικά στατιστικά στοιχεία εργασίας. Το όνομα της εκλεγμένης ομάδας αρχηγού είναι διαθέσιμο στην αρχή κάθε αρχείου καταγραφής ομάδας εργαζομένων, που προσδιορίζεται από το κλειδί master_addr=.
Χρήση CPU
Οι κατανεμημένοι φόρτοι εργασίας εκπαίδευσης απαιτούν πόρους τόσο της CPU όσο και της GPU. Για να βελτιστοποιήσετε αυτούς τους φόρτους εργασίας, είναι σημαντικό να κατανοήσετε πώς χρησιμοποιούνται αυτοί οι πόροι. Ευτυχώς, είναι διαθέσιμα μερικά εξαιρετικά βοηθητικά προγράμματα ανοιχτού κώδικα που βοηθούν στην οπτικοποίηση της χρήσης της CPU και της GPU. Για να δείτε τη χρήση της CPU, μπορείτε να χρησιμοποιήσετεhtop. Εάν οι ομάδες εργασίας σας περιέχουν αυτό το βοηθητικό πρόγραμμα, μπορείτε να χρησιμοποιήσετε την παρακάτω εντολή για να ανοίξετε ένα κέλυφος σε μια ομάδα και στη συνέχεια να εκτελέσετεhtop.
Εναλλακτικά, μπορείτε να αναπτύξετε ένα htopdaemonsetόπως αυτό που παρέχεται στη συνέχεια GitHub repo.
Ηdaemonsetθα τρέξει ένα ελαφρύ htop pod σε κάθε κόμβο. Μπορείτε να εκτελέσετε εκτέλεση σε οποιοδήποτε από αυτά τα pods και να εκτελέσετε τοhtopεντολή:
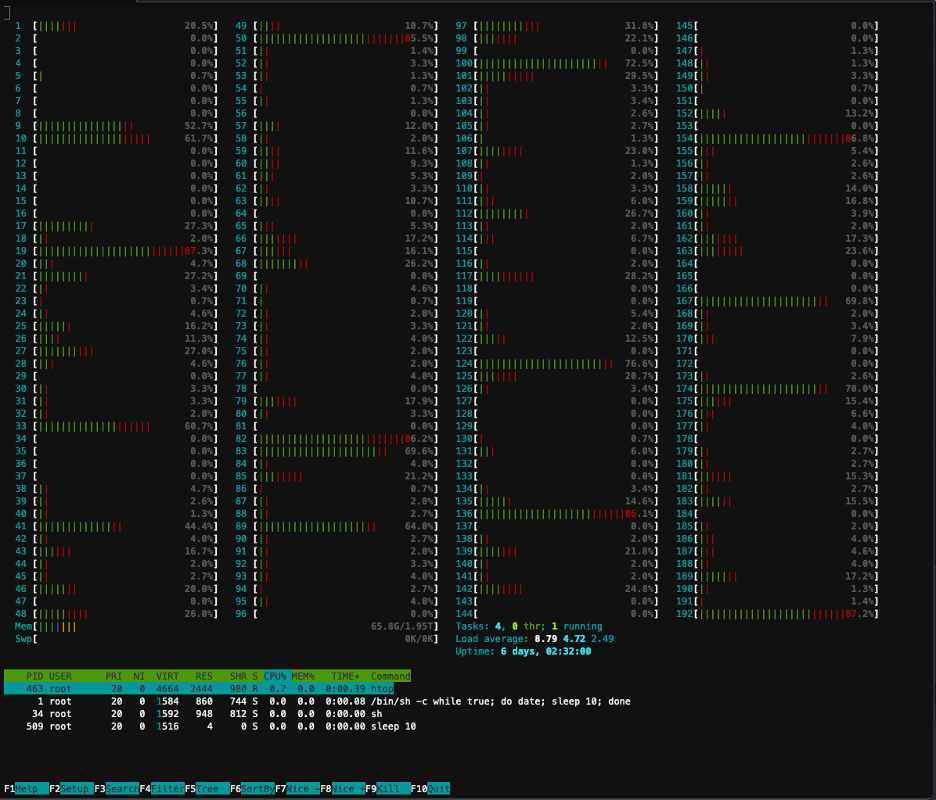
Το παρακάτω στιγμιότυπο οθόνης δείχνει τη χρήση της CPU σε έναν από τους κόμβους του συμπλέγματος. Σε αυτήν την περίπτωση, εξετάζουμε ένα παράδειγμα P5.48xlarge, το οποίο έχει 192 vCPU. Οι πυρήνες του επεξεργαστή είναι σε αδράνεια κατά τη λήψη των βαρών των μοντέλων και βλέπουμε αυξανόμενη χρήση ενώ τα βάρη των μοντέλων φορτώνονται στη μνήμη GPU.
Χρήση GPU
Εάν ηnvtopΤο βοηθητικό πρόγραμμα είναι διαθέσιμο στο pod σας, μπορείτε να το εκτελέσετε χρησιμοποιώντας παρακάτω και στη συνέχεια να το εκτελέσετεnvtop.
Εναλλακτικά, μπορείτε να αναπτύξετε ένα nvtopdaemonsetόπως αυτό που παρέχεται στη συνέχεια GitHub repo.
Αυτό θα τρέξει αnvtopλοβό σε κάθε κόμβο. Μπορείτε να εκτελέσετε εκτέλεση σε οποιοδήποτε από αυτά τα pod και να τρέξετεnvtop:
Το παρακάτω στιγμιότυπο οθόνης δείχνει τη χρήση της GPU σε έναν από τους κόμβους στο σύμπλεγμα εκπαίδευσης. Σε αυτήν την περίπτωση, εξετάζουμε ένα παράδειγμα P5.48xlarge, το οποίο διαθέτει 8 GPU NVIDIA H100. Οι GPU είναι σε αδράνεια κατά τη λήψη των βαρών του μοντέλου, στη συνέχεια η χρήση της μνήμης GPU αυξάνεται καθώς τα βάρη των μοντέλων φορτώνονται στη GPU και η χρήση της GPU αυξάνεται στο 100% ενώ βρίσκονται σε εξέλιξη οι επαναλήψεις εκπαίδευσης.

Ταμπλό Grafana
Τώρα που καταλαβαίνετε πώς λειτουργεί το σύστημά σας σε επίπεδο ομάδας και κόμβου, είναι επίσης σημαντικό να εξετάσετε τις μετρήσεις σε επίπεδο συμπλέγματος. Οι συγκεντρωτικές μετρήσεις χρήσης μπορούν να συλλεχθούν από την NVIDIA DCGM Exporter και την Prometheus και να οπτικοποιηθούν στο Grafana.
Ένα παράδειγμα ανάπτυξης Prometheus-Grafana είναι διαθέσιμο παρακάτω GitHub repo.
Ένα παράδειγμα ανάπτυξης εξαγωγέα DCGM είναι διαθέσιμο παρακάτω GitHub repo.
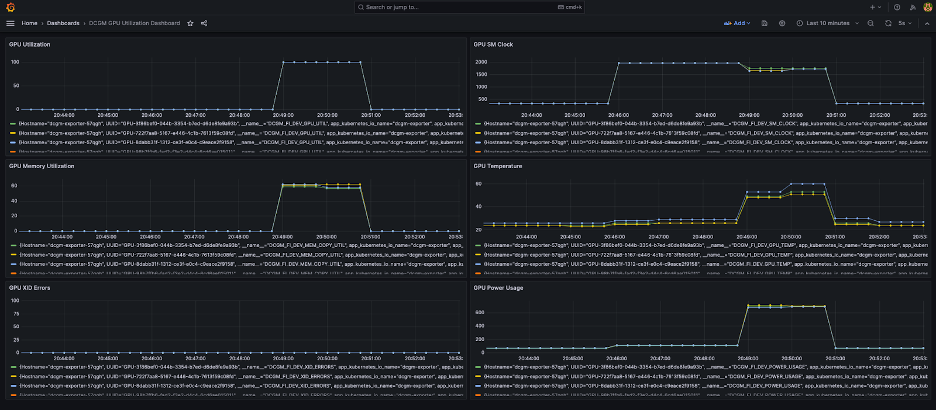
Ένας απλός πίνακας εργαλείων Grafana φαίνεται στο παρακάτω στιγμιότυπο οθόνης. Δημιουργήθηκε επιλέγοντας τις ακόλουθες μετρήσεις DCGM: DCGM_FI_DEV_GPU_UTIL, DCGM_FI_MEM_COPY_UTIL, DCGM_FI_DEV_XID_ERRORS, DCGM_FI_DEV_SM_CLOCK, DCGM_FI_DEV_GPU_TEMP, να DCGM_FI_DEV_POWER_USAGE. Το ταμπλό μπορεί να εισαχθεί στον Prometheus από GitHub.
Ο παρακάτω πίνακας εργαλείων δείχνει μια εκτέλεση μιας εργασίας εκπαίδευσης Llama2 7b μονής εποχής. Τα γραφήματα δείχνουν ότι καθώς αυξάνεται το ρολόι πολλαπλών επεξεργαστών ροής (SM), η κατανάλωση ενέργειας και η θερμοκρασία των GPU αυξάνονται επίσης, μαζί με τη χρήση της GPU και της μνήμης. Μπορείτε επίσης να δείτε ότι δεν υπήρχαν σφάλματα XID και οι GPU ήταν υγιείς κατά τη διάρκεια αυτής της εκτέλεσης.
Από τον Μάρτιο του 2024, η παρατηρησιμότητα GPU για EKS υποστηρίζεται εγγενώς στο CloudWatch Container Insights. Για να ενεργοποιήσετε αυτήν τη λειτουργία, απλώς αναπτύξτε το πρόσθετο CloudWatch Observability Add-on στο σύμπλεγμα EKS σας. Στη συνέχεια, θα μπορείτε να περιηγείστε σε μετρήσεις επιπέδου pod, κόμβου και συμπλέγματος μέσω προδιαμορφωμένων και προσαρμόσιμων πινάκων εργαλείων στο Container Insights.
εκκαθάριση
Εάν δημιουργήσατε το σύμπλεγμα χρησιμοποιώντας τα παραδείγματα που παρέχονται σε αυτό το ιστολόγιο, μπορείτε να εκτελέσετε τον ακόλουθο κώδικα για να διαγράψετε το σύμπλεγμα και τυχόν πόρους που σχετίζονται με αυτό, συμπεριλαμβανομένου του VPC:
Για eksctl:
Για εδάφους:
Προσεχείς δυνατότητες
Το FSDP αναμένεται να περιλαμβάνει μια δυνατότητα κοινής χρήσης ανά παράμετρο, με στόχο να βελτιώσει περαιτέρω το αποτύπωμα μνήμης ανά GPU. Επιπλέον, η συνεχής ανάπτυξη της υποστήριξης FP8 στοχεύει στη βελτίωση της απόδοσης του FSDP στις H100 GPU. Τέλος, όταν το FSDP είναι ενσωματωμένο μεtorch.compile, ελπίζουμε να δούμε πρόσθετες βελτιώσεις απόδοσης και ενεργοποίηση λειτουργιών όπως το επιλεκτικό σημείο ελέγχου ενεργοποίησης.
Συμπέρασμα
Σε αυτήν την ανάρτηση, συζητήσαμε πώς το FSDP μειώνει το αποτύπωμα μνήμης σε κάθε GPU, επιτρέποντας την εκπαίδευση μεγαλύτερων μοντέλων πιο αποτελεσματικά και επιτυγχάνοντας σχεδόν γραμμική κλίμακα στην απόδοση. Το αποδείξαμε αυτό μέσω μιας βήμα προς βήμα υλοποίησης της εκπαίδευσης ενός μοντέλου Llama2 χρησιμοποιώντας το Amazon EKS σε περιπτώσεις P4de και P5 και χρησιμοποιήσαμε εργαλεία παρατηρητικότητας όπως kubectl, htop, nvtop και dcgm για την παρακολούθηση αρχείων καταγραφής, καθώς και τη χρήση CPU και GPU.
Σας ενθαρρύνουμε να επωφεληθείτε από το PyTorch FSDP για τις δικές σας εργασίες εκπαίδευσης LLM. Ξεκινήστε στο aws-do-fsdp.
Σχετικά με τους Συγγραφείς
 Kanwaljit Khurmi είναι κύριος αρχιτέκτονας λύσεων AI/ML στην Amazon Web Services. Συνεργάζεται με πελάτες AWS για να παρέχει καθοδήγηση και τεχνική βοήθεια, βοηθώντας τους να βελτιώσουν την αξία των λύσεων μηχανικής εκμάθησης στο AWS. Η Kanwaljit ειδικεύεται στο να βοηθά πελάτες με εφαρμογές κοντέινερ, κατανεμημένων υπολογιστών και βαθιάς εκμάθησης.
Kanwaljit Khurmi είναι κύριος αρχιτέκτονας λύσεων AI/ML στην Amazon Web Services. Συνεργάζεται με πελάτες AWS για να παρέχει καθοδήγηση και τεχνική βοήθεια, βοηθώντας τους να βελτιώσουν την αξία των λύσεων μηχανικής εκμάθησης στο AWS. Η Kanwaljit ειδικεύεται στο να βοηθά πελάτες με εφαρμογές κοντέινερ, κατανεμημένων υπολογιστών και βαθιάς εκμάθησης.
 Άλεξ Ιανκούλσκι είναι Κύριος Αρχιτέκτονας Λύσεων, Αυτοδιαχειριζόμενη Μηχανική Μάθηση στο AWS. Είναι ένας πλήρης μηχανικός λογισμικού και υποδομής που του αρέσει να κάνει βαθιά, πρακτική δουλειά. Στο ρόλο του, εστιάζει στο να βοηθά τους πελάτες με τη δημιουργία εμπορευματοκιβωτίων και την ενορχήστρωση φόρτου εργασίας ML και AI σε υπηρεσίες AWS που λειτουργούν με κοντέινερ. Είναι επίσης ο συγγραφέας του ανοιχτού κώδικα κάνει πλαίσιο και ένας καπετάνιος Docker που λατρεύει να εφαρμόζει τεχνολογίες εμπορευματοκιβωτίων για να επιταχύνει τον ρυθμό της καινοτομίας επιλύοντας παράλληλα τις μεγαλύτερες προκλήσεις του κόσμου.
Άλεξ Ιανκούλσκι είναι Κύριος Αρχιτέκτονας Λύσεων, Αυτοδιαχειριζόμενη Μηχανική Μάθηση στο AWS. Είναι ένας πλήρης μηχανικός λογισμικού και υποδομής που του αρέσει να κάνει βαθιά, πρακτική δουλειά. Στο ρόλο του, εστιάζει στο να βοηθά τους πελάτες με τη δημιουργία εμπορευματοκιβωτίων και την ενορχήστρωση φόρτου εργασίας ML και AI σε υπηρεσίες AWS που λειτουργούν με κοντέινερ. Είναι επίσης ο συγγραφέας του ανοιχτού κώδικα κάνει πλαίσιο και ένας καπετάνιος Docker που λατρεύει να εφαρμόζει τεχνολογίες εμπορευματοκιβωτίων για να επιταχύνει τον ρυθμό της καινοτομίας επιλύοντας παράλληλα τις μεγαλύτερες προκλήσεις του κόσμου.
 Άνα Σιμόες είναι Κύριος Ειδικός Μηχανικής Μάθησης, ML Frameworks στο AWS. Υποστηρίζει πελάτες που αναπτύσσουν AI, ML και γενετική τεχνητή νοημοσύνη σε μεγάλη κλίμακα στην υποδομή HPC στο cloud. Η Ana εστιάζει στην υποστήριξη των πελατών ώστε να επιτύχουν απόδοση τιμής για νέους φόρτους εργασίας και περιπτώσεις χρήσης για παραγωγική τεχνητή νοημοσύνη και μηχανική εκμάθηση.
Άνα Σιμόες είναι Κύριος Ειδικός Μηχανικής Μάθησης, ML Frameworks στο AWS. Υποστηρίζει πελάτες που αναπτύσσουν AI, ML και γενετική τεχνητή νοημοσύνη σε μεγάλη κλίμακα στην υποδομή HPC στο cloud. Η Ana εστιάζει στην υποστήριξη των πελατών ώστε να επιτύχουν απόδοση τιμής για νέους φόρτους εργασίας και περιπτώσεις χρήσης για παραγωγική τεχνητή νοημοσύνη και μηχανική εκμάθηση.
 Hamid Shojanazeri είναι Μηχανικός Συνεργάτης στην PyTorch που εργάζεται σε ανοιχτού κώδικα, βελτιστοποίηση μοντέλων υψηλής απόδοσης, κατανεμημένη εκπαίδευση (FSDP), και συμπέρασμα. Είναι ο συνδημιουργός του λάμα-συνταγή και συνεισφέρων σε TorchServe. Το κύριο ενδιαφέρον του είναι να βελτιώσει τη σχέση κόστους-αποτελεσματικότητας, καθιστώντας την τεχνητή νοημοσύνη πιο προσιτή στην ευρύτερη κοινότητα.
Hamid Shojanazeri είναι Μηχανικός Συνεργάτης στην PyTorch που εργάζεται σε ανοιχτού κώδικα, βελτιστοποίηση μοντέλων υψηλής απόδοσης, κατανεμημένη εκπαίδευση (FSDP), και συμπέρασμα. Είναι ο συνδημιουργός του λάμα-συνταγή και συνεισφέρων σε TorchServe. Το κύριο ενδιαφέρον του είναι να βελτιώσει τη σχέση κόστους-αποτελεσματικότητας, καθιστώντας την τεχνητή νοημοσύνη πιο προσιτή στην ευρύτερη κοινότητα.
 Λιγότερο Ράιτ είναι AI/Partner Engineer στο PyTorch. Εργάζεται σε πυρήνες Triton/CUDA (Accelerating Dequant με αποσύνθεση εργασίας SplitK) σελιδοποιημένα, ροής και κβαντισμένα βελτιστοποιητές. και PyTorch Distributed (PyTorch FSDP).
Λιγότερο Ράιτ είναι AI/Partner Engineer στο PyTorch. Εργάζεται σε πυρήνες Triton/CUDA (Accelerating Dequant με αποσύνθεση εργασίας SplitK) σελιδοποιημένα, ροής και κβαντισμένα βελτιστοποιητές. και PyTorch Distributed (PyTorch FSDP).
- SEO Powered Content & PR Distribution. Ενισχύστε σήμερα.
- PlatoData.Network Vertical Generative Ai. Ενδυναμώστε τον εαυτό σας. Πρόσβαση εδώ.
- PlatoAiStream. Web3 Intelligence. Ενισχύθηκε η γνώση. Πρόσβαση εδώ.
- PlatoESG. Ανθρακας, Cleantech, Ενέργεια, Περιβάλλον, Ηλιακός, Διαχείριση των αποβλήτων. Πρόσβαση εδώ.
- PlatoHealth. Ευφυΐα βιοτεχνολογίας και κλινικών δοκιμών. Πρόσβαση εδώ.
- πηγή: https://aws.amazon.com/blogs/machine-learning/scale-llms-with-pytorch-2-0-fsdp-on-amazon-eks-part-2/

