
Εικόνα από συγγραφέα
Η εποπτεία είναι μια υποκατηγορία μηχανικής εκμάθησης στην οποία ο υπολογιστής μαθαίνει από το επισημασμένο σύνολο δεδομένων που περιέχει τόσο την είσοδο όσο και τη σωστή έξοδο. Προσπαθεί να βρει τη συνάρτηση αντιστοίχισης που συσχετίζει την είσοδο (x) με την έξοδο (y). Μπορείτε να το σκεφτείτε σαν να διδάξετε τον μικρότερο αδελφό ή την αδελφή σας πώς να αναγνωρίζει διαφορετικά ζώα. Θα τους δείξετε μερικές εικόνες (x) και θα τους πείτε πώς ονομάζεται το κάθε ζώο (y). Μετά από κάποιο χρονικό διάστημα, θα μάθουν τις διαφορές και θα μπορούν να αναγνωρίσουν σωστά τη νέα εικόνα. Αυτή είναι η βασική διαίσθηση πίσω από την εποπτευόμενη μάθηση. Πριν προχωρήσουμε, ας ρίξουμε μια πιο βαθιά ματιά στη λειτουργία του.
Πώς λειτουργεί η εποπτευόμενη μάθηση;
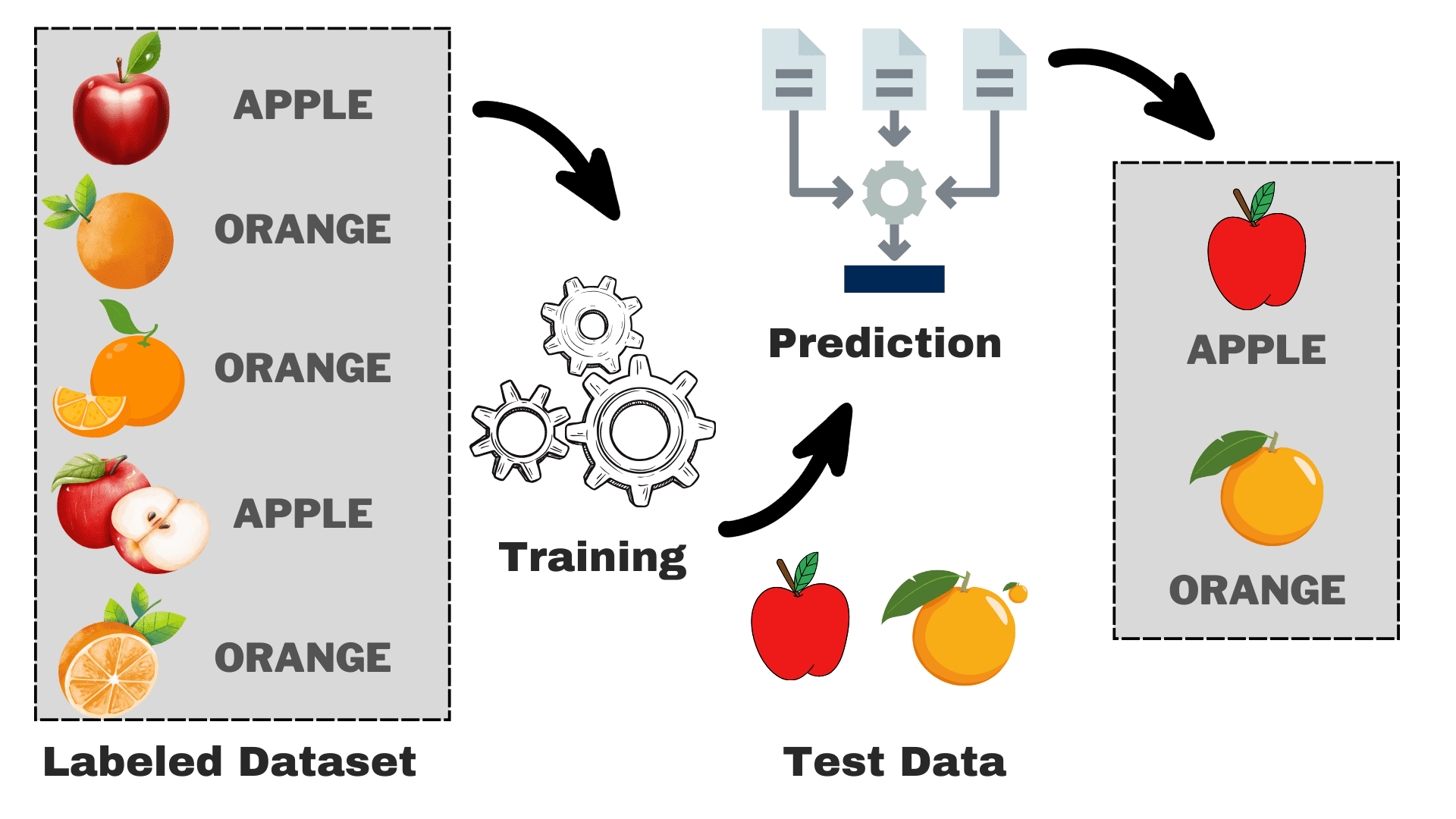
Εικόνα από συγγραφέα
Ας υποθέσουμε ότι θέλετε να δημιουργήσετε ένα μοντέλο που μπορεί να διαφοροποιήσει τα μήλα από τα πορτοκάλια με βάση ορισμένα χαρακτηριστικά. Μπορούμε να αναλύσουμε τη διαδικασία στις ακόλουθες εργασίες:
- Συλλογή δεδομένων: Συγκεντρώστε ένα σύνολο δεδομένων με εικόνες μήλων και πορτοκαλιών και κάθε εικόνα επισημαίνεται είτε ως "μήλο" ή "πορτοκάλι".
- Επιλογή μοντέλου: Πρέπει να επιλέξουμε τον σωστό ταξινομητή εδώ που είναι συχνά γνωστός ως ο σωστός εποπτευόμενος αλγόριθμος μηχανικής εκμάθησης για την εργασία σας. Είναι ακριβώς σαν να επιλέγεις τα σωστά γυαλιά που θα σε βοηθήσουν να δεις καλύτερα
- Εκπαίδευση του μοντέλου: Τώρα, τροφοδοτείτε τον αλγόριθμο με τις επισημασμένες εικόνες μήλων και πορτοκαλιών. Ο αλγόριθμος κοιτάζει αυτές τις εικόνες και μαθαίνει να αναγνωρίζει τις διαφορές, όπως το χρώμα, το σχήμα και το μέγεθος των μήλων και των πορτοκαλιών.
- Αξιολόγηση και δοκιμή: Για να ελέγξουμε αν το μοντέλο σας λειτουργεί σωστά, θα τροφοδοτήσουμε μερικές εικόνες που δεν έχουν δει και θα συγκρίνουμε τις προβλέψεις με τις πραγματικές.
Η εποπτευόμενη μάθηση μπορεί να χωριστεί σε δύο βασικούς τύπους:
Ταξινόμηση
Στις εργασίες ταξινόμησης, ο πρωταρχικός στόχος είναι να εκχωρηθούν σημεία δεδομένων σε συγκεκριμένες κατηγορίες από ένα σύνολο διακριτών κλάσεων. Όταν υπάρχουν μόνο δύο πιθανά αποτελέσματα, όπως "ναι" ή "όχι", "ανεπιθύμητη αλληλογραφία" ή "μη ανεπιθύμητη", "αποδεκτή" ή "απορρίφθηκε", αναφέρεται ως δυαδική ταξινόμηση. Ωστόσο, όταν εμπλέκονται περισσότερες από δύο κατηγορίες ή τάξεις, όπως η βαθμολόγηση των μαθητών με βάση τους βαθμούς τους (π.χ., A, B, C, D, F), γίνεται παράδειγμα ενός προβλήματος πολλαπλών ταξινομήσεων.
Οπισθοδρόμηση
Για προβλήματα παλινδρόμησης, προσπαθείτε να προβλέψετε μια συνεχή αριθμητική τιμή. Για παράδειγμα, μπορεί να σας ενδιαφέρει να προβλέψετε τις τελικές βαθμολογίες σας στις εξετάσεις με βάση τις προηγούμενες επιδόσεις σας στην τάξη. Οι προβλεπόμενες βαθμολογίες μπορούν να εκτείνονται σε οποιαδήποτε τιμή εντός ενός συγκεκριμένου εύρους, συνήθως από 0 έως 100 στην περίπτωσή μας.
Τώρα, έχουμε μια βασική κατανόηση της συνολικής διαδικασίας. Θα εξερευνήσουμε τους δημοφιλείς αλγόριθμους εποπτευόμενης μηχανικής εκμάθησης, τη χρήση τους και τον τρόπο λειτουργίας τους:
1. Γραμμική παλινδρόμηση
Όπως υποδηλώνει το όνομα, χρησιμοποιείται για εργασίες παλινδρόμησης όπως η πρόβλεψη τιμών μετοχών, η πρόβλεψη της θερμοκρασίας, η εκτίμηση της πιθανότητας εξέλιξης της νόσου κ.λπ. Προσπαθούμε να προβλέψουμε τον στόχο (εξαρτημένη μεταβλητή) χρησιμοποιώντας το σύνολο ετικετών (ανεξάρτητες μεταβλητές). Υποθέτει ότι έχουμε μια γραμμική σχέση μεταξύ των χαρακτηριστικών εισόδου μας και της ετικέτας. Η κεντρική ιδέα περιστρέφεται γύρω από την πρόβλεψη της καλύτερης γραμμής για τα σημεία δεδομένων μας ελαχιστοποιώντας το σφάλμα μεταξύ των πραγματικών και των προβλεπόμενων τιμών μας. Αυτή η γραμμή αντιπροσωπεύεται από την εξίσωση:
Που,
- Y Προβλεπόμενη έξοδος.
- X = Χαρακτηριστικό εισόδου ή πίνακας χαρακτηριστικών σε πολλαπλή γραμμική παλινδρόμηση
- b0 = Τομή (όπου η γραμμή διασχίζει τον άξονα Υ).
- b1 = Κλίση ή συντελεστής που καθορίζει την κλίση της γραμμής.
Υπολογίζει την κλίση της γραμμής (βάρος) και την τομή της (προκατάληψη). Αυτή η γραμμή μπορεί να χρησιμοποιηθεί περαιτέρω για να κάνει προβλέψεις. Αν και είναι το απλούστερο και χρήσιμο μοντέλο για την ανάπτυξη των βασικών γραμμών, είναι πολύ ευαίσθητο σε ακραίες τιμές που μπορεί να επηρεάσουν τη θέση της γραμμής.
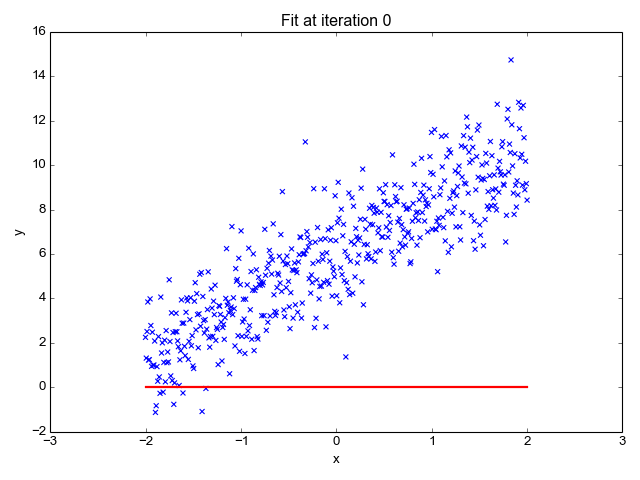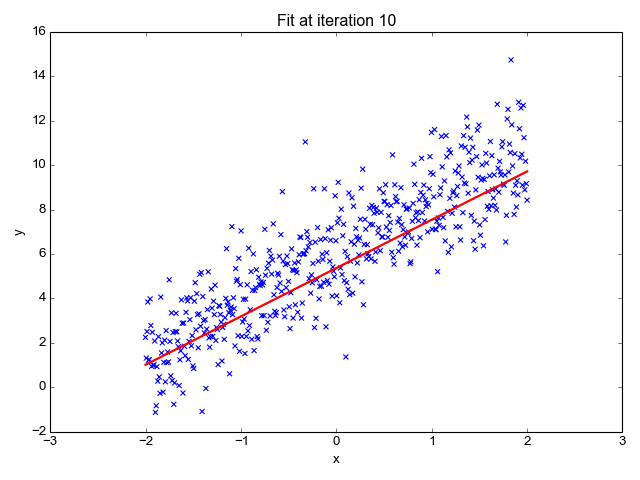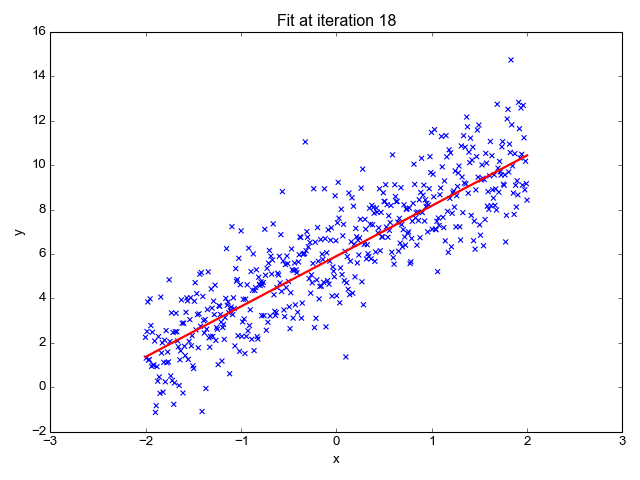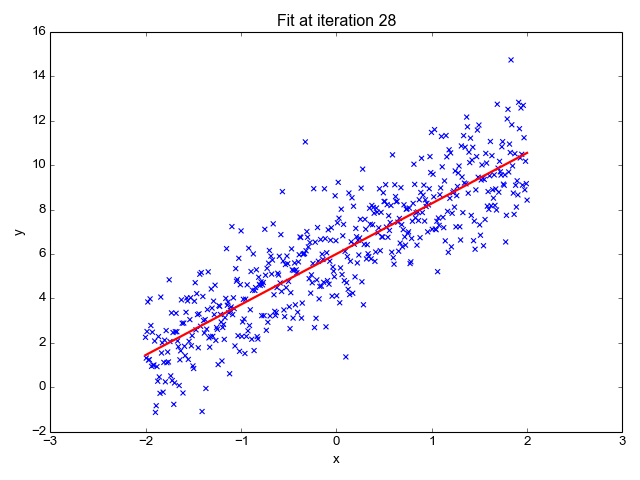
Gif ενεργοποιημένο Primo.ai
2. Logistic Regression
Αν και έχει παλινδρόμηση στο όνομά του, αλλά χρησιμοποιείται βασικά για προβλήματα δυαδικής ταξινόμησης. Προβλέπει την πιθανότητα θετικού αποτελέσματος (εξαρτημένη μεταβλητή) που κυμαίνεται από 0 έως 1. Ορίζοντας ένα όριο (συνήθως 0.5), ταξινομούμε τα σημεία δεδομένων: αυτά με πιθανότητα μεγαλύτερη από το όριο ανήκουν στη θετική κλάση, και αντίστροφα. Η λογιστική παλινδρόμηση υπολογίζει αυτή την πιθανότητα χρησιμοποιώντας τη σιγμοειδή συνάρτηση που εφαρμόζεται στον γραμμικό συνδυασμό των χαρακτηριστικών εισόδου που καθορίζεται ως:
Που,
- P(Y=1) = Πιθανότητα το σημείο δεδομένων να ανήκει στη θετική κλάση
- X1 ,… ,Xn = Χαρακτηριστικά εισόδου
- b0,….,bn = Βάρη εισόδου που μαθαίνει ο αλγόριθμος κατά τη διάρκεια της εκπαίδευσης
Αυτή η σιγμοειδής συνάρτηση έχει τη μορφή καμπύλης τύπου S που μετατρέπει οποιοδήποτε σημείο δεδομένων σε βαθμολογία πιθανότητας εντός του εύρους 0-1. Μπορείτε να δείτε το παρακάτω γράφημα για καλύτερη κατανόηση.
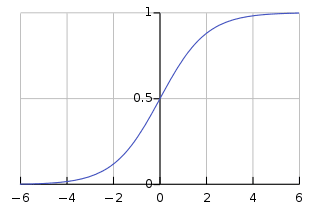
Η εικόνα είναι ενεργοποιημένη Wikipedia
Μια πιο κοντινή τιμή στο 1 υποδηλώνει μεγαλύτερη εμπιστοσύνη στο μοντέλο στην πρόβλεψή του. Ακριβώς όπως η γραμμική παλινδρόμηση, είναι γνωστή για την απλότητά της, αλλά δεν μπορούμε να εκτελέσουμε την ταξινόμηση πολλαπλών κλάσεων χωρίς τροποποίηση στον αρχικό αλγόριθμο.
3. Δέντρα απόφασης
Σε αντίθεση με τους δύο παραπάνω αλγόριθμους, τα δέντρα αποφάσεων μπορούν να χρησιμοποιηθούν τόσο για εργασίες ταξινόμησης όσο και για εργασίες παλινδρόμησης. Έχει μια ιεραρχική δομή όπως και τα διαγράμματα ροής. Σε κάθε κόμβο, λαμβάνεται μια απόφαση για τη διαδρομή με βάση ορισμένες τιμές χαρακτηριστικών. Η διαδικασία συνεχίζεται εκτός αν φτάσουμε στον τελευταίο κόμβο που απεικονίζει την τελική απόφαση. Εδώ είναι μερικές βασικές ορολογίες που πρέπει να γνωρίζετε:
- Ριζικός κόμβος: Ο επάνω κόμβος που περιέχει ολόκληρο το σύνολο δεδομένων ονομάζεται κόμβος ρίζας. Στη συνέχεια επιλέγουμε το καλύτερο χαρακτηριστικό χρησιμοποιώντας κάποιο αλγόριθμο για να χωρίσουμε το σύνολο δεδομένων σε 2 ή περισσότερα υποδέντρα.
- Εσωτερικοί κόμβοι: Κάθε εσωτερικός κόμβος αντιπροσωπεύει ένα συγκεκριμένο χαρακτηριστικό και έναν κανόνα απόφασης για να αποφασίσει την επόμενη δυνατή κατεύθυνση για ένα σημείο δεδομένων.
- Κόμβοι φύλλων: Οι τερματικοί κόμβοι που αντιπροσωπεύουν μια ετικέτα κλάσης αναφέρονται ως κόμβοι φύλλων.
Προβλέπει τις συνεχείς αριθμητικές τιμές για τις εργασίες παλινδρόμησης. Καθώς το μέγεθος του συνόλου δεδομένων μεγαλώνει, καταγράφει τον θόρυβο που οδηγεί σε υπερπροσαρμογή. Αυτό μπορεί να αντιμετωπιστεί με κλάδεμα του δέντρου αποφάσεων. Αφαιρούμε υποκαταστήματα που δεν βελτιώνουν σημαντικά την ακρίβεια των αποφάσεών μας. Αυτό βοηθά να κρατάμε το δέντρο μας εστιασμένο στους πιο σημαντικούς παράγοντες και το αποτρέπει από το να χαθεί στις λεπτομέρειες.
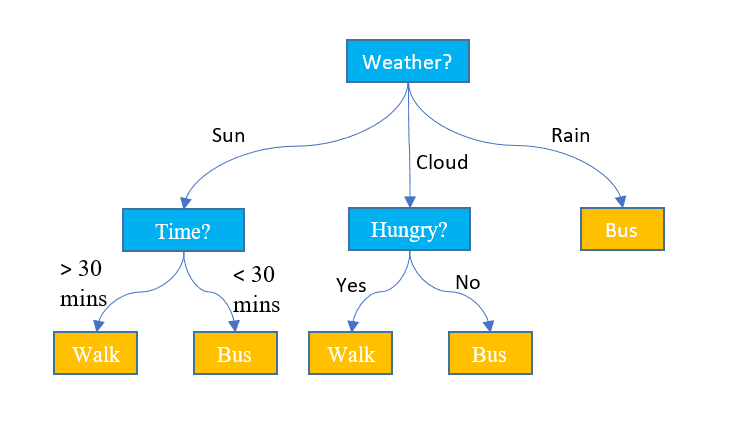
Εικόνα από Τζέικ Χόαρ στο Displayr
4. Τυχαίο Δάσος
Το τυχαίο δάσος μπορεί επίσης να χρησιμοποιηθεί τόσο για την ταξινόμηση όσο και για τις εργασίες παλινδρόμησης. Είναι μια ομάδα δέντρων αποφάσεων που συνεργάζονται για να κάνουν την τελική πρόβλεψη. Μπορείτε να το θεωρήσετε ως η επιτροπή εμπειρογνωμόνων που λαμβάνει μια συλλογική απόφαση. Εδώ είναι πώς λειτουργεί:
- Δειγματοληψία δεδομένων: Αντί να λαμβάνει ολόκληρο το σύνολο δεδομένων ταυτόχρονα, παίρνει τα τυχαία δείγματα μέσω μιας διαδικασίας που ονομάζεται bootstrapping ή bagging.
- Επιλογή χαρακτηριστικών: Για κάθε δέντρο απόφασης σε ένα τυχαίο δάσος, μόνο το τυχαίο υποσύνολο χαρακτηριστικών λαμβάνεται υπόψη για τη λήψη αποφάσεων αντί για το πλήρες σύνολο χαρακτηριστικών.
- Ψηφοφορία: Για ταξινόμηση, κάθε δέντρο απόφασης στο τυχαίο δάσος δίνει την ψήφο του και επιλέγεται η τάξη με τις υψηλότερες ψήφους. Για την παλινδρόμηση, υπολογίζουμε τον μέσο όρο των τιμών που λαμβάνονται από όλα τα δέντρα.
Αν και μειώνει την επίδραση της υπερπροσαρμογής που προκαλείται από μεμονωμένα δέντρα απόφασης, αλλά είναι υπολογιστικά ακριβό. Μια λέξη που θα διαβάζετε συχνά στη βιβλιογραφία είναι ότι το τυχαίο δάσος είναι μια μέθοδος εκμάθησης συνόλου, που σημαίνει ότι συνδυάζει πολλά μοντέλα για τη βελτίωση της συνολικής απόδοσης.
5. Υποστήριξη Vector Machines (SVM)
Χρησιμοποιείται κυρίως για προβλήματα ταξινόμησης, αλλά μπορεί να χειριστεί και εργασίες παλινδρόμησης. Προσπαθεί να βρει το καλύτερο υπερεπίπεδο που διαχωρίζει τις διακριτές τάξεις χρησιμοποιώντας τη στατιστική προσέγγιση, σε αντίθεση με την πιθανολογική προσέγγιση της λογιστικής παλινδρόμησης. Μπορούμε να χρησιμοποιήσουμε το γραμμικό SVM για τα γραμμικά διαχωρίσιμα δεδομένα. Ωστόσο, τα περισσότερα από τα δεδομένα του πραγματικού κόσμου είναι μη γραμμικά και χρησιμοποιούμε τα κόλπα του πυρήνα για να διαχωρίσουμε τις κλάσεις. Ας βουτήξουμε βαθιά στο πώς λειτουργεί:
- Επιλογή υπερπλάνου: Στη δυαδική ταξινόμηση, το SVM βρίσκει το καλύτερο υπερεπίπεδο (γραμμή 2-D) για να διαχωρίσει τις κατηγορίες ενώ μεγιστοποιεί το περιθώριο. Το περιθώριο είναι η απόσταση μεταξύ του υπερεπίπεδου και των πλησιέστερων σημείων δεδομένων στο υπερεπίπεδο.
- Κόλπο πυρήνα: Για γραμμικά αδιαχώριστα δεδομένα, χρησιμοποιούμε ένα τέχνασμα πυρήνα που αντιστοιχίζει τον αρχικό χώρο δεδομένων σε ένα χώρο υψηλών διαστάσεων όπου μπορούν να διαχωριστούν γραμμικά. Οι κοινοί πυρήνες περιλαμβάνουν γραμμικούς, πολυωνυμικούς, ακτινικής βάσης συνάρτηση (RBF) και σιγμοειδείς πυρήνες.
- Μεγιστοποίηση περιθωρίου: Το SVM προσπαθεί επίσης να βελτιώσει τη γενίκευση του μοντέλου αυξάνοντας το περιθώριο μεγιστοποίησης.
- Κατάταξη: Μόλις το μοντέλο εκπαιδευτεί, οι προβλέψεις μπορούν να γίνουν με βάση τη θέση τους σε σχέση με το υπερεπίπεδο.
Το SVM έχει επίσης μια παράμετρο που ονομάζεται C που ελέγχει την αντιστάθμιση μεταξύ της μεγιστοποίησης του περιθωρίου και της διατήρησης του σφάλματος ταξινόμησης στο ελάχιστο. Αν και μπορούν να χειριστούν καλά δεδομένα υψηλών διαστάσεων και μη γραμμικών, η επιλογή του σωστού πυρήνα και υπερπαραμέτρου δεν είναι τόσο εύκολη όσο φαίνεται.
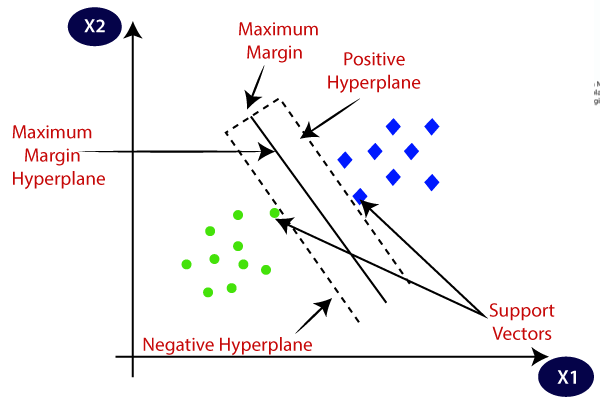
Η εικόνα είναι ενεργοποιημένη Javatpoint
6. k-Κοντινότεροι γείτονες (k-NN)
Ο K-NN είναι ο απλούστερος αλγόριθμος εποπτευόμενης μάθησης που χρησιμοποιείται κυρίως για εργασίες ταξινόμησης. Δεν κάνει υποθέσεις σχετικά με τα δεδομένα και εκχωρεί στο νέο σημείο δεδομένων μια κατηγορία βάσει της ομοιότητάς του με τα υπάρχοντα. Κατά τη διάρκεια της φάσης εκπαίδευσης, διατηρεί ολόκληρο το σύνολο δεδομένων ως σημείο αναφοράς. Στη συνέχεια υπολογίζει την απόσταση μεταξύ του νέου σημείου δεδομένων και όλων των υπαρχόντων σημείων χρησιμοποιώντας μια μέτρηση απόστασης (απόσταση Eucilinedain π.χ.). Με βάση αυτές τις αποστάσεις, προσδιορίζει τους K πλησιέστερους γείτονες σε αυτά τα σημεία δεδομένων. Στη συνέχεια μετράμε την εμφάνιση κάθε κλάσης στους K πλησιέστερους γείτονες και ορίζουμε την κλάση που εμφανίζεται πιο συχνά ως τελική πρόβλεψη.
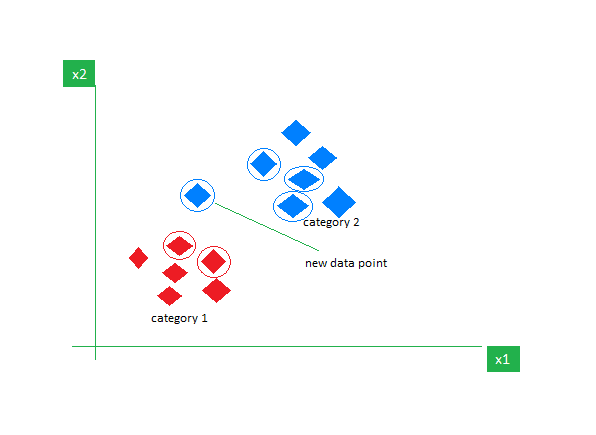
Η εικόνα είναι ενεργοποιημένη geeksforgeeks
Η επιλογή της σωστής τιμής του Κ απαιτεί πειραματισμό. Αν και είναι ανθεκτικό σε θορυβώδη δεδομένα, δεν είναι κατάλληλο για σύνολα δεδομένων υψηλών διαστάσεων και έχει υψηλό κόστος λόγω του υπολογισμού της απόστασης από όλα τα σημεία δεδομένων.
Καθώς ολοκληρώνω αυτό το άρθρο, θα ενθαρρύνω τους αναγνώστες να εξερευνήσουν περισσότερους αλγόριθμους και να προσπαθήσουν να τους εφαρμόσουν από την αρχή. Αυτό θα ενισχύσει την κατανόησή σας για το πώς λειτουργούν τα πράγματα κάτω από την κουκούλα. Ακολουθούν ορισμένοι πρόσθετοι πόροι που θα σας βοηθήσουν να ξεκινήσετε:
Kanwal Mehreen είναι ένας επίδοξος προγραμματιστής λογισμικού με έντονο ενδιαφέρον για την επιστήμη των δεδομένων και τις εφαρμογές της τεχνητής νοημοσύνης στην ιατρική. Το Kanwal επιλέχθηκε ως Μελετητής Γενιάς Google 2022 για την περιοχή APAC. Η Kanwal λατρεύει να μοιράζεται τεχνικές γνώσεις γράφοντας άρθρα για μοντέρνα θέματα και είναι παθιασμένος με τη βελτίωση της εκπροσώπησης των γυναικών στον κλάδο της τεχνολογίας.
- SEO Powered Content & PR Distribution. Ενισχύστε σήμερα.
- PlatoData.Network Vertical Generative Ai. Ενδυναμώστε τον εαυτό σας. Πρόσβαση εδώ.
- PlatoAiStream. Web3 Intelligence. Ενισχύθηκε η γνώση. Πρόσβαση εδώ.
- PlatoESG. Αυτοκίνητο / EVs, Ανθρακας, Cleantech, Ενέργεια, Περιβάλλον, Ηλιακός, Διαχείριση των αποβλήτων. Πρόσβαση εδώ.
- PlatoHealth. Ευφυΐα βιοτεχνολογίας και κλινικών δοκιμών. Πρόσβαση εδώ.
- ChartPrime. Ανεβάστε το Trading Game σας με το ChartPrime. Πρόσβαση εδώ.
- BlockOffsets. Εκσυγχρονισμός της περιβαλλοντικής αντιστάθμισης ιδιοκτησίας. Πρόσβαση εδώ.
- πηγή: https://www.kdnuggets.com/understanding-supervised-learning-theory-and-overview?utm_source=rss&utm_medium=rss&utm_campaign=understanding-supervised-learning-theory-and-overview

