Έχει σημειωθεί τεράστια πρόοδος στον τομέα της κατανεμημένης βαθιάς εκμάθησης για μεγάλα γλωσσικά μοντέλα (LLM), ειδικά μετά την κυκλοφορία του ChatGPT τον Δεκέμβριο του 2022. Τα LLM συνεχίζουν να αυξάνονται σε μέγεθος με δισεκατομμύρια ή και τρισεκατομμύρια παραμέτρους, και συχνά δεν το κάνουν χωρούν σε μία συσκευή επιτάχυνσης όπως η GPU ή ακόμα και σε έναν κόμβο όπως ml.p5.32xlarge λόγω περιορισμών μνήμης. Οι πελάτες που εκπαιδεύουν LLM συχνά πρέπει να κατανέμουν τον φόρτο εργασίας τους σε εκατοντάδες ή και χιλιάδες GPU. Η ενεργοποίηση της εκπαίδευσης σε τέτοια κλίμακα παραμένει μια πρόκληση στην κατανεμημένη εκπαίδευση και η αποτελεσματική εκπαίδευση σε ένα τόσο μεγάλο σύστημα είναι ένα άλλο εξίσου σημαντικό πρόβλημα. Τα τελευταία χρόνια, η κατανεμημένη κοινότητα εκπαίδευσης εισήγαγε τον τρισδιάστατο παραλληλισμό (παραλληλισμός δεδομένων, παραλληλισμός αγωγών και παραλληλισμός τανυστών) και άλλες τεχνικές (όπως ο παραλληλισμός ακολουθιών και ο παραλληλισμός ειδικών) για την αντιμετώπιση τέτοιων προκλήσεων.
Τον Δεκέμβριο του 2023, η Amazon ανακοίνωσε την κυκλοφορία του Παράλληλη βιβλιοθήκη μοντέλων SageMaker 2.0 (SMP), το οποίο επιτυγχάνει κορυφαία απόδοση στην εκπαίδευση μεγάλων μοντέλων, μαζί με το Το SageMaker διένειμε τη βιβλιοθήκη παραλληλισμού δεδομένων (SMDDP). Αυτή η έκδοση είναι μια σημαντική ενημέρωση από το 1.x: Το SMP είναι πλέον ενσωματωμένο στο PyTorch ανοιχτού κώδικα Πλήρως Sharded Data Parallel (FSDP) API, το οποίο σας επιτρέπει να χρησιμοποιείτε μια οικεία διεπαφή κατά την εκπαίδευση μεγάλων μοντέλων και είναι συμβατό με Μετασχηματιστής Κινητήρας (TE), ξεκλειδώνοντας τεχνικές παραλληλισμού τανυστών παράλληλα με το FSDP για πρώτη φορά. Για να μάθετε περισσότερα σχετικά με την έκδοση, ανατρέξτε στο Η παράλληλη βιβλιοθήκη μοντέλων του Amazon SageMaker τώρα επιταχύνει τους φόρτους εργασίας PyTorch FSDP έως και 20%.
Σε αυτήν την ανάρτηση, εξερευνούμε τα οφέλη απόδοσης Amazon Sage Maker (συμπεριλαμβανομένων των SMP και SMDDP) και πώς μπορείτε να χρησιμοποιήσετε τη βιβλιοθήκη για να εκπαιδεύσετε μεγάλα μοντέλα αποτελεσματικά στο SageMaker. Δείχνουμε την απόδοση του SageMaker με σημεία αναφοράς σε ml.p4d.24x μεγάλα συμπλέγματα έως και 128 παρουσίες και FSDP μικτή ακρίβεια με bfloat16 για το μοντέλο Llama 2. Ξεκινάμε με μια επίδειξη σχεδόν γραμμικής απόδοσης κλιμάκωσης για το SageMaker, ακολουθούμενη από ανάλυση των συνεισφορών από κάθε χαρακτηριστικό για βέλτιστη απόδοση και τελειώνουμε με αποτελεσματική εκπαίδευση με διάφορα μήκη ακολουθίας έως 32,768 μέσω παραλληλισμού τανυστών.
Σχεδόν γραμμική κλιμάκωση με το SageMaker
Για να μειωθεί ο συνολικός χρόνος εκπαίδευσης για τα μοντέλα LLM, η διατήρηση της υψηλής απόδοσης κατά την κλιμάκωση σε μεγάλα συμπλέγματα (χιλιάδες GPU) είναι κρίσιμη δεδομένης της επιβάρυνσης επικοινωνίας μεταξύ κόμβων. Σε αυτήν την ανάρτηση, επιδεικνύουμε ισχυρές και σχεδόν γραμμικές αποδόσεις κλιμάκωσης (με τη μεταβολή του αριθμού των GPU για ένα σταθερό συνολικό μέγεθος προβλήματος) σε περιπτώσεις p4d που επικαλούνται τόσο SMP όσο και SMDDP.
Σε αυτήν την ενότητα, παρουσιάζουμε την σχεδόν γραμμική απόδοση κλιμάκωσης του SMP. Εδώ εκπαιδεύουμε μοντέλα Llama 2 διαφόρων μεγεθών (παράμετροι 7B, 13B και 70B) χρησιμοποιώντας ένα σταθερό μήκος ακολουθίας 4,096, το backend SMDDP για συλλογική επικοινωνία, με δυνατότητα TE, ένα παγκόσμιο μέγεθος παρτίδας 4 εκατομμυρίων, με 16 έως 128 κόμβους p4d . Ο παρακάτω πίνακας συνοψίζει τη βέλτιστη διαμόρφωση και τις επιδόσεις εκπαίδευσης (μοντέλο TFLOP ανά δευτερόλεπτο).
| Μέγεθος μοντέλου | Αριθμός κόμβων | TFLOP* | sdp* | tp* | εκφόρτωση* | Αποτελεσματικότητα κλιμάκωσης |
| 7B | 16 | 136.76 | 32 | 1 | N | 100.0% |
| 32 | 132.65 | 64 | 1 | N | 97.0% | |
| 64 | 125.31 | 64 | 1 | N | 91.6% | |
| 128 | 115.01 | 64 | 1 | N | 84.1% | |
| 13B | 16 | 141.43 | 32 | 1 | Y | 100.0% |
| 32 | 139.46 | 256 | 1 | N | 98.6% | |
| 64 | 132.17 | 128 | 1 | N | 93.5% | |
| 128 | 120.75 | 128 | 1 | N | 85.4% | |
| 70B | 32 | 154.33 | 256 | 1 | Y | 100.0% |
| 64 | 149.60 | 256 | 1 | N | 96.9% | |
| 128 | 136.52 | 64 | 2 | N | 88.5% |
*Στο δεδομένο μέγεθος μοντέλου, μήκος ακολουθίας και αριθμό κόμβων, δείχνουμε την παγκόσμια βέλτιστη απόδοση και διαμορφώσεις μετά την εξερεύνηση διαφόρων συνδυασμών εκφόρτωσης sdp, tp και ενεργοποίησης.
Ο προηγούμενος πίνακας συνοψίζει τους βέλτιστους αριθμούς απόδοσης που υπόκεινται σε βαθμό μοιρασμένων παραλλήλων δεδομένων (sdp) (συνήθως χρησιμοποιώντας υβριδικό διαμοιρασμό FSDP αντί για πλήρη διαμοιρασμό, με περισσότερες λεπτομέρειες στην επόμενη ενότητα), βαθμός παράλληλου τανυστή (tp) και αλλαγές στην τιμή εκφόρτωσης ενεργοποίησης. επιδεικνύοντας μια σχεδόν γραμμική κλίμακα για το SMP μαζί με το SMDDP. Για παράδειγμα, δεδομένου του μεγέθους μοντέλου Llama 2 7B και του μήκους ακολουθίας 4,096, συνολικά επιτυγχάνει αποδοτικότητες κλιμάκωσης 97.0%, 91.6% και 84.1% (σε σχέση με 16 κόμβους) στους 32, 64 και 128 κόμβους, αντίστοιχα. Οι αποδόσεις κλιμάκωσης είναι σταθερές σε διαφορετικά μεγέθη μοντέλων και αυξάνονται ελαφρώς καθώς το μέγεθος του μοντέλου μεγαλώνει.
Το SMP και το SMDDP επιδεικνύουν επίσης παρόμοιες αποδόσεις κλιμάκωσης για άλλα μήκη ακολουθίας όπως 2,048 και 8,192.
Απόδοση παράλληλης βιβλιοθήκης μοντέλων SageMaker 2.0: Llama 2 70B
Τα μεγέθη μοντέλων συνέχισαν να αυξάνονται τα τελευταία χρόνια, μαζί με συχνές ενημερώσεις απόδοσης τελευταίας τεχνολογίας στην κοινότητα LLM. Σε αυτήν την ενότητα, παρουσιάζουμε την απόδοση στο SageMaker για το μοντέλο Llama 2 χρησιμοποιώντας σταθερό μέγεθος μοντέλου 70B, μήκος ακολουθίας 4,096 και συνολικό μέγεθος παρτίδας 4 εκατομμυρίων. Για σύγκριση με τη γενικά βέλτιστη διαμόρφωση και απόδοση του προηγούμενου πίνακα (με το backend SMDDP, συνήθως υβριδικό διαμοιρασμό FSDP και TE), ο ακόλουθος πίνακας επεκτείνεται σε άλλες βέλτιστες αποδόσεις (δυνητικά με παραλληλισμό τανυστή) με επιπλέον προδιαγραφές στο κατανεμημένο backend (NCCL και SMDDP). , στρατηγικές διαμοιρασμού FSDP (πλήρης διαμοιρασμός και υβριδικός διαμοιρασμός) και ενεργοποίηση TE ή όχι (προεπιλογή).
| Μέγεθος μοντέλου | Αριθμός κόμβων | TFLOPS | Διαμόρφωση TFLOPs #3 | Βελτίωση TFLOP σε σχέση με τη βασική γραμμή | ||||||||
| . | . | Πλήρης διαμοιρασμός NCCL: #0 | Πλήρης κοινή χρήση SMDDP: #1 | Υβριδικός διαμοιρασμός SMDDP: #2 | Υβριδικός διαμοιρασμός SMDDP με TE: #3 | sdp* | tp* | εκφόρτωση* | #0 → #1 | #1 → #2 | #2 → #3 | #0 → #3 |
| 70B | 32 | 150.82 | 149.90 | 150.05 | 154.33 | 256 | 1 | Y | -0.6% | 0.1% | 2.9% | 2.3% |
| 64 | 144.38 | 144.38 | 145.42 | 149.60 | 256 | 1 | N | 0.0% | 0.7% | 2.9% | 3.6% | |
| 128 | 68.53 | 103.06 | 130.66 | 136.52 | 64 | 2 | N | 50.4% | 26.8% | 4.5% | 99.2% | |
*Στο δεδομένο μέγεθος μοντέλου, μήκος ακολουθίας και αριθμό κόμβων, δείχνουμε τη γενικά βέλτιστη απόδοση και διαμόρφωση μετά την εξερεύνηση διαφόρων συνδυασμών εκφόρτωσης sdp, tp και ενεργοποίησης.
Η πιο πρόσφατη έκδοση των SMP και SMDDP υποστηρίζει πολλαπλές δυνατότητες, όπως το εγγενές PyTorch FSDP, εκτεταμένο και πιο ευέλικτο υβριδικό διαμοιρασμό, ενσωμάτωση κινητήρα μετασχηματιστή, παραλληλισμό τανυστών και βελτιστοποιημένη συλλογική λειτουργία όλων των συλλεκτών. Για να κατανοήσουμε καλύτερα πώς το SageMaker επιτυγχάνει αποτελεσματική κατανεμημένη εκπαίδευση για LLMs, διερευνούμε τις αυξητικές συνεισφορές από το SMDDP και το ακόλουθο SMP βασικά χαρακτηριστικά:
- Βελτίωση SMDDP σε σχέση με το NCCL με πλήρη κοινή χρήση FSDP
- Αντικατάσταση του πλήρους διαμοιρασμού FSDP με υβριδικό διαμοιρασμό, το οποίο μειώνει το κόστος επικοινωνίας για τη βελτίωση της απόδοσης
- Μια περαιτέρω ώθηση στη διεκπεραίωση με TE, ακόμη και όταν ο παραλληλισμός τανυστών είναι απενεργοποιημένος
- Σε χαμηλότερες ρυθμίσεις πόρων, η εκφόρτωση ενεργοποίησης μπορεί να είναι σε θέση να ενεργοποιήσει την εκπαίδευση που διαφορετικά θα ήταν ανέφικτη ή πολύ αργή λόγω υψηλής πίεσης μνήμης
Πλήρης κοινή χρήση FSDP: Βελτίωση SMDDP μέσω NCCL
Όπως φαίνεται στον προηγούμενο πίνακα, όταν τα μοντέλα διαχωρίζονται πλήρως με FSDP, αν και οι ροές NCCL (TFLOPs #0) και SMDDP (TFLOPs #1) είναι συγκρίσιμες σε 32 ή 64 κόμβους, υπάρχει τεράστια βελτίωση 50.4% από NCCL σε SMDDP στους 128 κόμβους.
Σε μικρότερα μεγέθη μοντέλων, παρατηρούμε συνεπείς και σημαντικές βελτιώσεις με το SMDDP σε σχέση με το NCCL, ξεκινώντας από μικρότερα μεγέθη συμπλέγματος, επειδή το SMDDP είναι σε θέση να μετριάσει αποτελεσματικά τη συμφόρηση επικοινωνίας.
Υβριδικό διαμοιρασμό FSDP για μείωση του κόστους επικοινωνίας
Στο SMP 1.0, ξεκινήσαμε παραλληλισμός μοιρασμένων δεδομένων, μια τεχνική κατανεμημένης εκπαίδευσης που τροφοδοτείται από την Amazon in-house MiCS τεχνολογία. Στο SMP 2.0, εισάγουμε τον υβριδικό διαμοιρασμό SMP, μια επεκτάσιμη και πιο ευέλικτη τεχνική υβριδικού διαμοιρασμού που επιτρέπει στα μοντέλα να διαμοιράζονται σε ένα υποσύνολο GPU, αντί για όλες τις εκπαιδευτικές GPU, όπως συμβαίνει με τον πλήρη διαμοιρασμό FSDP. Είναι χρήσιμο για μοντέλα μεσαίου μεγέθους που δεν χρειάζεται να κατανεμηθούν σε ολόκληρο το σύμπλεγμα προκειμένου να ικανοποιηθούν οι περιορισμοί μνήμης ανά GPU. Αυτό οδηγεί σε συμπλέγματα να έχουν περισσότερα από ένα αντίγραφα μοντέλων και κάθε GPU να επικοινωνεί με λιγότερα peers κατά το χρόνο εκτέλεσης.
Ο υβριδικός διαμοιρασμός του SMP επιτρέπει την αποτελεσματική κοινή χρήση μοντέλων σε ένα ευρύτερο εύρος, από τον μικρότερο βαθμό θραύσματος χωρίς προβλήματα μνήμης έως το μέγεθος ολόκληρου του συμπλέγματος (που ισοδυναμεί με πλήρη διαμοιρασμό).
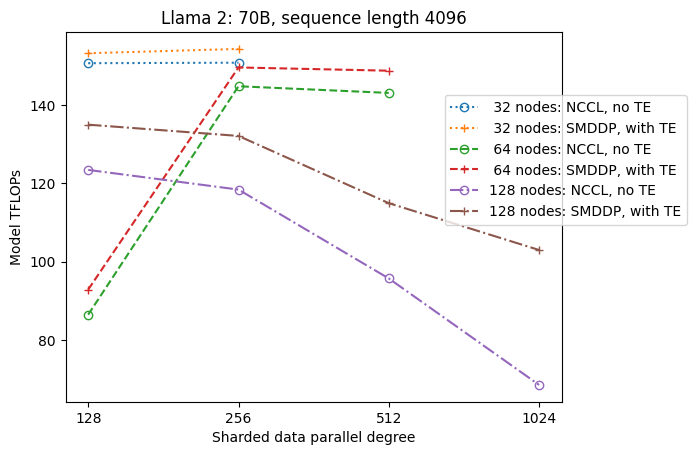
Το παρακάτω σχήμα απεικονίζει την εξάρτηση της απόδοσης από το sdp σε tp = 1 για απλότητα. Αν και δεν είναι απαραιτήτως η ίδια με τη βέλτιστη τιμή tp για τον πλήρη διαμοιρασμό NCCL ή SMDDP στον προηγούμενο πίνακα, οι αριθμοί είναι αρκετά κοντά. Επικυρώνει ξεκάθαρα την τιμή της μετάβασης από τον πλήρη διαμοιρασμό σε υβριδικό διαμοιρασμό σε ένα μεγάλο μέγεθος συμπλέγματος 128 κόμβων, το οποίο ισχύει τόσο για το NCCL όσο και για το SMDDP. Για μικρότερα μεγέθη μοντέλων, σημαντικές βελτιώσεις με το υβριδικό διαμοιρασμό ξεκινούν από μικρότερα μεγέθη συμπλέγματος και η διαφορά συνεχίζει να αυξάνεται με το μέγεθος του συμπλέγματος.
Βελτιώσεις με ΤΕ
Το TE έχει σχεδιαστεί για να επιταχύνει την εκπαίδευση LLM σε GPU της NVIDIA. Παρά το γεγονός ότι δεν χρησιμοποιείται το FP8 επειδή δεν υποστηρίζεται σε περιπτώσεις p4d, εξακολουθούμε να βλέπουμε σημαντική επιτάχυνση με το TE στο p4d.
Εκτός από το MiCS που έχει εκπαιδευτεί με το backend SMDDP, το TE εισάγει μια σταθερή ώθηση για την απόδοση σε όλα τα μεγέθη συμπλέγματος (η μόνη εξαίρεση είναι η πλήρης κοινή χρήση σε 128 κόμβους), ακόμη και όταν ο παραλληλισμός τανυστή είναι απενεργοποιημένος (ο βαθμός παράλληλου τανυστή είναι 1).
Για μικρότερα μεγέθη μοντέλων ή διάφορα μήκη ακολουθίας, η ενίσχυση TE είναι σταθερή και μη τετριμμένη, στην περιοχή περίπου 3–7.6%.
Εκφόρτωση ενεργοποίησης σε ρυθμίσεις χαμηλών πόρων
Σε ρυθμίσεις χαμηλών πόρων (δεδομένου ενός μικρού αριθμού κόμβων), το FSDP ενδέχεται να παρουσιάσει υψηλή πίεση μνήμης (ή ακόμα και έλλειψη μνήμης στη χειρότερη περίπτωση) όταν είναι ενεργοποιημένο το σημείο ελέγχου ενεργοποίησης. Για τέτοια σενάρια με συμφόρηση από τη μνήμη, η ενεργοποίηση της εκφόρτωσης ενεργοποίησης είναι δυνητικά μια επιλογή για τη βελτίωση της απόδοσης.
Για παράδειγμα, όπως είδαμε προηγουμένως, αν και το Llama 2 σε μέγεθος μοντέλου 13B και μήκος ακολουθίας 4,096 είναι σε θέση να εκπαιδεύεται βέλτιστα με τουλάχιστον 32 κόμβους με σημείο ελέγχου ενεργοποίησης και χωρίς εκφόρτωση ενεργοποίησης, επιτυγχάνει την καλύτερη απόδοση με εκφόρτωση ενεργοποίησης όταν περιορίζεται σε 16 κόμβους.
Ενεργοποιήστε την προπόνηση με μεγάλες ακολουθίες: Παραλληλισμός τανυστή SMP
Τα μεγαλύτερα μήκη ακολουθίας είναι επιθυμητά για μεγάλες συνομιλίες και το πλαίσιο, και προσελκύουν περισσότερη προσοχή στην κοινότητα LLM. Ως εκ τούτου, αναφέρουμε διάφορες διόδους μεγάλης ακολουθίας στον παρακάτω πίνακα. Ο πίνακας δείχνει τη βέλτιστη απόδοση για την προπόνηση Llama 2 στο SageMaker, με διάφορα μήκη ακολουθίας από 2,048 έως 32,768. Σε μήκος ακολουθίας 32,768, η εγγενής εκπαίδευση FSDP δεν είναι εφικτή με 32 κόμβους σε παγκόσμιο μέγεθος παρτίδας 4 εκατομμυρίων.
| . | . | . | TFLOPS | ||
| Μέγεθος μοντέλου | Μήκος ακολουθίας | Αριθμός κόμβων | Εγγενές FSDP και NCCL | SMP και SMDDP | Βελτίωση SMP |
| 7B | 2048 | 32 | 129.25 | 138.17 | 6.9% |
| 4096 | 32 | 124.38 | 132.65 | 6.6% | |
| 8192 | 32 | 115.25 | 123.11 | 6.8% | |
| 16384 | 32 | 100.73 | 109.11 | 8.3% | |
| 32768 | 32 | NA | 82.87 | . | |
| 13B | 2048 | 32 | 137.75 | 144.28 | 4.7% |
| 4096 | 32 | 133.30 | 139.46 | 4.6% | |
| 8192 | 32 | 125.04 | 130.08 | 4.0% | |
| 16384 | 32 | 111.58 | 117.01 | 4.9% | |
| 32768 | 32 | NA | 92.38 | . | |
| *: Μέγιστη | . | . | . | . | 8.3% |
| *: διάμεσος | . | . | . | . | 5.8% |
Όταν το μέγεθος του συμπλέγματος είναι μεγάλο και δίνεται ένα σταθερό συνολικό μέγεθος παρτίδας, κάποια εκπαίδευση μοντέλων μπορεί να μην είναι εφικτή με το εγγενές PyTorch FSDP, χωρίς υποστήριξη ενσωματωμένης διοχέτευσης ή παραλληλισμού τανυστών. Στον προηγούμενο πίνακα, δεδομένου ενός παγκόσμιου μεγέθους παρτίδας 4 εκατομμυρίων, 32 κόμβων και μήκους ακολουθίας 32,768, το πραγματικό μέγεθος παρτίδας ανά GPU είναι 0.5 (για παράδειγμα, tp = 2 με μέγεθος παρτίδας 1), το οποίο διαφορετικά θα ήταν ανέφικτο χωρίς την εισαγωγή παραλληλισμός τανυστών.
Συμπέρασμα
Σε αυτήν την ανάρτηση, επιδείξαμε αποτελεσματική εκπαίδευση LLM με SMP και SMDDP σε περιπτώσεις p4d, αποδίδοντας συνεισφορές σε πολλαπλά βασικά χαρακτηριστικά, όπως βελτίωση SMDDP μέσω NCCL, ευέλικτο υβριδικό διαμοιρασμό FSDP αντί για πλήρη διαμοιρασμό, ενσωμάτωση TE και επιτρέποντας τον παραλληλισμό τανυστών προς όφελος του μεγάλα μήκη ακολουθίας. Αφού δοκιμάστηκε σε ένα ευρύ φάσμα ρυθμίσεων με διάφορα μοντέλα, μεγέθη μοντέλων και μήκη ακολουθίας, παρουσιάζει ισχυρές σχεδόν γραμμικές αποδόσεις κλιμάκωσης, έως και 128 στιγμιότυπα p4d στο SageMaker. Συνοπτικά, το SageMaker συνεχίζει να είναι ένα ισχυρό εργαλείο για ερευνητές και επαγγελματίες LLM.
Για να μάθετε περισσότερα, ανατρέξτε στο Βιβλιοθήκη παραλληλισμού μοντέλων SageMaker v2, ή επικοινωνήστε με την ομάδα SMP στο sm-model-parallel-feedback@amazon.com.
Ευχαριστίες
Θα θέλαμε να ευχαριστήσουμε τους Robert Van Dusen, Ben Snyder, Gautam Kumar και Luis Quintela για τα εποικοδομητικά σχόλια και τις συζητήσεις τους.
Σχετικά με τους Συγγραφείς

Xinle Sheila Liu είναι ένα SDE στο Amazon SageMaker. Στον ελεύθερο χρόνο της, της αρέσει το διάβασμα και τα υπαίθρια αθλήματα.
 Suhit Kodgule είναι Μηχανικός Ανάπτυξης Λογισμικού με την ομάδα Τεχνητής Νοημοσύνης AWS που εργάζεται σε πλαίσια βαθιάς μάθησης. Στον ελεύθερο χρόνο του, του αρέσει η πεζοπορία, τα ταξίδια και η μαγειρική.
Suhit Kodgule είναι Μηχανικός Ανάπτυξης Λογισμικού με την ομάδα Τεχνητής Νοημοσύνης AWS που εργάζεται σε πλαίσια βαθιάς μάθησης. Στον ελεύθερο χρόνο του, του αρέσει η πεζοπορία, τα ταξίδια και η μαγειρική.
 Βίκτορ Ζου είναι Μηχανικός Λογισμικού στο Distributed Deep Learning στο Amazon Web Services. Μπορείτε να τον βρείτε να απολαμβάνει πεζοπορία και επιτραπέζια παιχνίδια στην περιοχή SF Bay Area.
Βίκτορ Ζου είναι Μηχανικός Λογισμικού στο Distributed Deep Learning στο Amazon Web Services. Μπορείτε να τον βρείτε να απολαμβάνει πεζοπορία και επιτραπέζια παιχνίδια στην περιοχή SF Bay Area.
 Ντέρια Κάβνταρ εργάζεται ως μηχανικός λογισμικού στην AWS. Τα ενδιαφέροντά της περιλαμβάνουν τη βαθιά μάθηση και τη βελτιστοποίηση κατανεμημένης εκπαίδευσης.
Ντέρια Κάβνταρ εργάζεται ως μηχανικός λογισμικού στην AWS. Τα ενδιαφέροντά της περιλαμβάνουν τη βαθιά μάθηση και τη βελτιστοποίηση κατανεμημένης εκπαίδευσης.
 Teng Xu είναι Μηχανικός Ανάπτυξης Λογισμικού στην ομάδα Distributed Training στο AWS AI. Του αρέσει να διαβάζει.
Teng Xu είναι Μηχανικός Ανάπτυξης Λογισμικού στην ομάδα Distributed Training στο AWS AI. Του αρέσει να διαβάζει.
- SEO Powered Content & PR Distribution. Ενισχύστε σήμερα.
- PlatoData.Network Vertical Generative Ai. Ενδυναμώστε τον εαυτό σας. Πρόσβαση εδώ.
- PlatoAiStream. Web3 Intelligence. Ενισχύθηκε η γνώση. Πρόσβαση εδώ.
- PlatoESG. Ανθρακας, Cleantech, Ενέργεια, Περιβάλλον, Ηλιακός, Διαχείριση των αποβλήτων. Πρόσβαση εδώ.
- PlatoHealth. Ευφυΐα βιοτεχνολογίας και κλινικών δοκιμών. Πρόσβαση εδώ.
- πηγή: https://aws.amazon.com/blogs/machine-learning/distributed-training-and-efficient-scaling-with-the-amazon-sagemaker-model-parallel-and-data-parallel-libraries/

