Για τις σύγχρονες εταιρείες που ασχολούνται με τεράστιους όγκους εγγράφων όπως συμβάσεις, τιμολόγια, βιογραφικά και αναφορές, η αποτελεσματική επεξεργασία και ανάκτηση σχετικών δεδομένων είναι κρίσιμη για τη διατήρηση ενός ανταγωνιστικού πλεονεκτήματος. Ωστόσο, οι παραδοσιακές μέθοδοι αποθήκευσης και αναζήτησης εγγράφων μπορεί να είναι χρονοβόρες και συχνά οδηγούν σε μεγάλη προσπάθεια εύρεσης ενός συγκεκριμένου εγγράφου, ειδικά όταν περιλαμβάνουν χειρόγραφο. Τι θα γινόταν αν υπήρχε τρόπος να επεξεργάζεστε έγγραφα με έξυπνο τρόπο και να τα κάνετε με δυνατότητα αναζήτησης με υψηλή ακρίβεια;
Αυτό γίνεται δυνατό με Textract Amazon, την υπηρεσία Έξυπνης Επεξεργασίας Εγγράφων της AWS, σε συνδυασμό με τις δυνατότητες γρήγορης αναζήτησης του Opensearch. Σε αυτήν την ανάρτηση, θα σας ταξιδέψουμε για να δημιουργήσετε και να αναπτύξετε γρήγορα μια λύση ευρετηρίασης αναζήτησης εγγράφων που βοηθά τον οργανισμό σας να αξιοποιεί καλύτερα και να εξάγει πληροφορίες από έγγραφα.
Είτε βρίσκεστε στο τμήμα Ανθρώπινου Δυναμικού και αναζητάτε συγκεκριμένες ρήτρες στις συμβάσεις εργαζομένων είτε ως οικονομικός αναλυτής που εξετάζει ένα βουνό από τιμολόγια για να εξάγει δεδομένα πληρωμών, αυτή η λύση είναι προσαρμοσμένη για να σας δίνει τη δυνατότητα να έχετε πρόσβαση στις πληροφορίες που χρειάζεστε με πρωτοφανή ταχύτητα και ακρίβεια.
Με την προτεινόμενη λύση, τα έγγραφά σας απορροφώνται αυτόματα, το περιεχόμενό τους αναλύεται και στη συνέχεια καταχωρείται σε ευρετήριο σε ένα ευρετήριο OpenSearch υψηλής απόκρισης και κλιμάκωσης.
Θα καλύψουμε πώς τεχνολογίες όπως το Amazon Textract, AWS Lambda, Απλή υπηρεσία αποθήκευσης Amazon (Amazon S3), και Amazon OpenSearch Service μπορεί να ενσωματωθεί σε μια ροή εργασίας που επεξεργάζεται απρόσκοπτα έγγραφα. Στη συνέχεια, βυθιζόμαστε στην ευρετηρίαση αυτών των δεδομένων στο OpenSearch και δείχνουμε τις δυνατότητες αναζήτησης που είναι διαθέσιμες στα χέρια σας.
Είτε ο οργανισμός σας κάνει τα πρώτα βήματα στην εποχή του ψηφιακού μετασχηματισμού είτε είναι ένας καθιερωμένος γίγαντας που επιδιώκει να στροβιλίσει την ανάκτηση πληροφοριών, αυτός ο οδηγός είναι η πυξίδα σας για την πλοήγηση στις ευκαιρίες που προσφέρουν το AWS Intelligent Document Processing και το OpenSearch.
Η εκτέλεση που χρησιμοποιείται σε αυτήν την ανάρτηση χρησιμοποιεί το Κατασκευές CDK IDP του Amazon Textract – Στοιχεία AWS Cloud Development Kit (CDK) για τον καθορισμό της υποδομής για ροές εργασίας Έξυπνης Επεξεργασίας Εγγράφων (IDP) – τα οποία σας επιτρέπουν να δημιουργήσετε προσαρμόσιμες ροές εργασίας IDP για συγκεκριμένες περιπτώσεις. Οι κατασκευές και τα δείγματα του CDK IDP είναι μια συλλογή στοιχείων που επιτρέπουν τον ορισμό των διαδικασιών IDP στο AWS και δημοσιεύονται στο GitHub. Οι κύριες έννοιες που χρησιμοποιούνται είναι το AWS Κιτ ανάπτυξης cloud (CDK) κατασκευάζει, το πραγματικό Στοίβες CDK και Λειτουργίες βημάτων AWS. Το εργαστήριο Χρησιμοποιήστε τη μηχανική εκμάθηση για να αυτοματοποιήσετε και να επεξεργαστείτε έγγραφα σε κλίμακα είναι ένα καλό σημείο εκκίνησης για να μάθετε περισσότερα σχετικά με την προσαρμογή των ροών εργασίας και τη χρήση των άλλων δειγμάτων ροών εργασίας ως βάση για τις δικές σας.
Επισκόπηση λύσεων
Σε αυτή τη λύση, εστιάζουμε στην ευρετηρίαση εγγράφων σε ευρετήριο OpenSearch για γρήγορη αναζήτηση και ανάκτηση πληροφοριών και εγγράφων. Τα έγγραφα σε μορφή PDF, TIFF, JPEG ή PNG τοποθετούνται σε μια υπηρεσία απλής αποθήκευσης της Amazon (Amazon S3) κουβά και στη συνέχεια καταχωρήθηκε στο OpenSearch χρησιμοποιώντας αυτήν τη ροή εργασίας Βήμα Λειτουργίες.
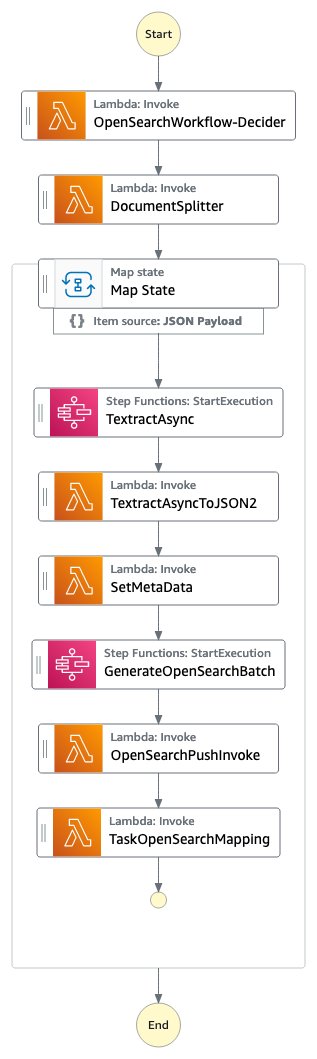
Σχήμα 1: Η ροή εργασιών OpenSearch με λειτουργίες Step
Η OpenSearchWorkflow-Decider κοιτάζει το έγγραφο και επαληθεύει ότι το έγγραφο είναι ένας από τους υποστηριζόμενους τύπους mime (PDF, TIFF, PNG ή JPEG). Αποτελείται από ένα AWS Lambda λειτουργία.
Η DocumentSplitter δημιουργεί το μέγιστο κομμάτι 2500 σελίδων από έγγραφα. Αυτό σημαίνει ότι παρόλο που το Amazon Textract υποστηρίζει έγγραφα έως και 3000 σελίδων, μπορείτε να μεταβιβάσετε έγγραφα με πολλές περισσότερες σελίδες και η διαδικασία εξακολουθεί να λειτουργεί καλά και τοποθετεί τις σελίδες στο OpenSearch και δημιουργεί σωστούς αριθμούς σελίδων. ο DocumentSplitter υλοποιείται ως συνάρτηση AWS Lambda.
Η Κατάσταση χάρτη επεξεργάζεται κάθε κομμάτι παράλληλα.
Η TexttractAsync η εργασία καλεί το Amazon Textract χρησιμοποιώντας το ασύγχρονο Διεπαφή προγραμματισμού εφαρμογών (API) που ακολουθεί βέλτιστες πρακτικές με την υπηρεσία απλής ειδοποίησης Amazon (Amazon SNS) ειδοποιήσεις και OutputConfig για να αποθηκεύσετε την έξοδο Amazon Textract JSON σε έναν κάδο πελάτη Amazon S3. Αποτελείται από δύο λειτουργίες Amazon Lambda: μία για την υποβολή του εγγράφου για επεξεργασία και μία για την ενεργοποίηση στην ειδοποίηση Amazon SNS.
Επειδή η TexttractAsyΗ εργασία nc μπορεί να παράγει πολλαπλά σελιδοποιημένα αρχεία εξόδου, το TextractAsyncToJSON2 διαδικασία τα συνδυάζει σε ένα αρχείο JSON.
Το πλαίσιο των Λειτουργιών Βήματος εμπλουτίζεται με πληροφορίες που θα πρέπει επίσης να αναζητηθούν στο ευρετήριο OpenSearch στο SetMetaData βήμα. Το δείγμα υλοποίησης προσθέτει ORIGIN_FILE_NAME, START_PAGE_NUMBER, να ORIGIN_FILE_URI. Μπορείτε να προσθέσετε οποιαδήποτε πληροφορία για να εμπλουτίσετε την εμπειρία αναζήτησης, όπως πληροφορίες από άλλα συστήματα υποστήριξης, συγκεκριμένα αναγνωριστικά ή πληροφορίες ταξινόμησης.
Η GenerateOpenSearchBatch παίρνει το παραγόμενο αποτέλεσμα JSON του Amazon Textract, το συνδυάζει με τις πληροφορίες από το περιβάλλον που έχει οριστεί από το SetMetaData και προετοιμάζει ένα αρχείο που είναι βελτιστοποιημένο για μαζική εισαγωγή στο OpenSearch.
Στο OpenSearchPushInvoke, αυτό το αρχείο ομαδικής εισαγωγής αποστέλλεται στο ευρετήριο OpenSearch και είναι διαθέσιμο για αναζήτηση. Αυτή η λειτουργία AWS Lambda συνδέεται με το aws-lambda-opensearch κατασκευή από το Λύσεις AWS βιβλιοθήκη που χρησιμοποιεί τα στιγμιότυπα m6g.large.search, OpenSearch έκδοση 2.7 και διαμόρφωσε την υπηρεσία Amazon Elastic Block (Amazon EBS) μέγεθος όγκου σε γενική χρήση 2 (GP2) με 200 GB. Μπορείτε να αλλάξετε τη διαμόρφωση OpenSearch σύμφωνα με τις απαιτήσεις σας.
Ο τελικός TaskOpenSearchMapping Το βήμα καθαρίζει το πλαίσιο, το οποίο διαφορετικά θα μπορούσε να υπερβαίνει το Ποσόστωση Λειτουργιών Βήματος of Μέγιστο μέγεθος εισόδου ή εξόδου για μια εργασία, κατάσταση ή εκτέλεση.
Προϋποθέσεις
Για να αναπτύξετε τα δείγματα, χρειάζεστε έναν λογαριασμό AWS, το AWS Cloud Development Kit (AWS CDK), απαιτείται τρέχουσα έκδοση Python και Docker. Χρειάζεστε δικαιώματα για την ανάπτυξη προτύπων AWS CloudFormation, πιέστε το Μητρώο εμπορευματοκιβωτίων Amazon Elastic (Amazon ECR), δημιουργία Διαχείριση ταυτότητας και πρόσβασης Amazon ρόλοι (AWS IAM), λειτουργίες Amazon Lambda, κάδοι Amazon S3, Λειτουργίες Βήματος Amazon, σύμπλεγμα OpenSearch Amazon και ένα Amazon Cognito ομάδα χρηστών. Βεβαιωθείτε ότι σας Το περιβάλλον AWS CLI έχει ρυθμιστεί με τις ανάλογες άδειες.
Μπορείτε επίσης να περιστρέψετε α AWS Cloud9 παράδειγμα με προεγκατεστημένα τα AWS CDK, Python και Docker για την έναρξη της ανάπτυξης.
Walkthrough
Ανάπτυξη
- Αφού ρυθμίσετε τις προϋποθέσεις, πρέπει πρώτα να κλωνοποιήσετε το αποθετήριο:
- Στη συνέχεια, cd στο φάκελο αποθετηρίου και εγκαταστήστε τις εξαρτήσεις:
- Αναπτύξτε τη στοίβα OpenSearchWorkflow:
Η ανάπτυξη διαρκεί περίπου 25 λεπτά με τις προεπιλεγμένες ρυθμίσεις διαμόρφωσης από τα δείγματα GitHub και δημιουργεί μια ροή εργασίας Step Functions, η οποία καλείται όταν ένα έγγραφο τοποθετείται σε κάδο/πρόθεμα Amazon S3 και στη συνέχεια υποβάλλεται σε επεξεργασία μέχρι να ευρετηριαστεί το περιεχόμενο του εγγράφου σε ένα σύμπλεγμα OpenSearch.
Ακολουθεί ένα δείγμα εξόδου που περιλαμβάνει χρήσιμους συνδέσμους και πληροφορίες που δημιουργούνται απόcdk deploy OpenSearchWorkflowεντολή:
Αυτές οι πληροφορίες είναι επίσης διαθέσιμες στην Κονσόλα AWS CloudFormation.
Όταν ένα νέο έγγραφο τοποθετείται κάτω από το OpenSearchWorkflow.DocumentUploadLocation, ξεκινά μια νέα ροή εργασίας Step Functions για αυτό το έγγραφο.
Για να ελέγξετε την κατάσταση αυτού του εγγράφου, το OpenSearchWorkflow.StepFunctionFlowLink παρέχει έναν σύνδεσμο προς τη λίστα των εκτελέσεων StepFunction στην Κονσόλα διαχείρισης AWS, εμφανίζοντας την κατάσταση της επεξεργασίας εγγράφων για κάθε έγγραφο που αποστέλλεται στο Amazon S3. Το φροντιστήριο Προβολή και εντοπισμός σφαλμάτων εκτελέσεων στην κονσόλα Step Functions παρέχει μια επισκόπηση των στοιχείων και των προβολών στην Κονσόλα AWS.
Δοκιμές
- Πρώτη δοκιμή χρησιμοποιώντας ένα δείγμα αρχείου.
- Αφού επιλέξετε τη σύνδεση με τη ροή εργασίας StepFunction ή ανοίξετε την Κονσόλα διαχείρισης AWS και μεταβείτε στη σελίδα υπηρεσίας Βήμα Λειτουργίες, μπορείτε να δείτε τις διάφορες επικλήσεις ροής εργασιών.
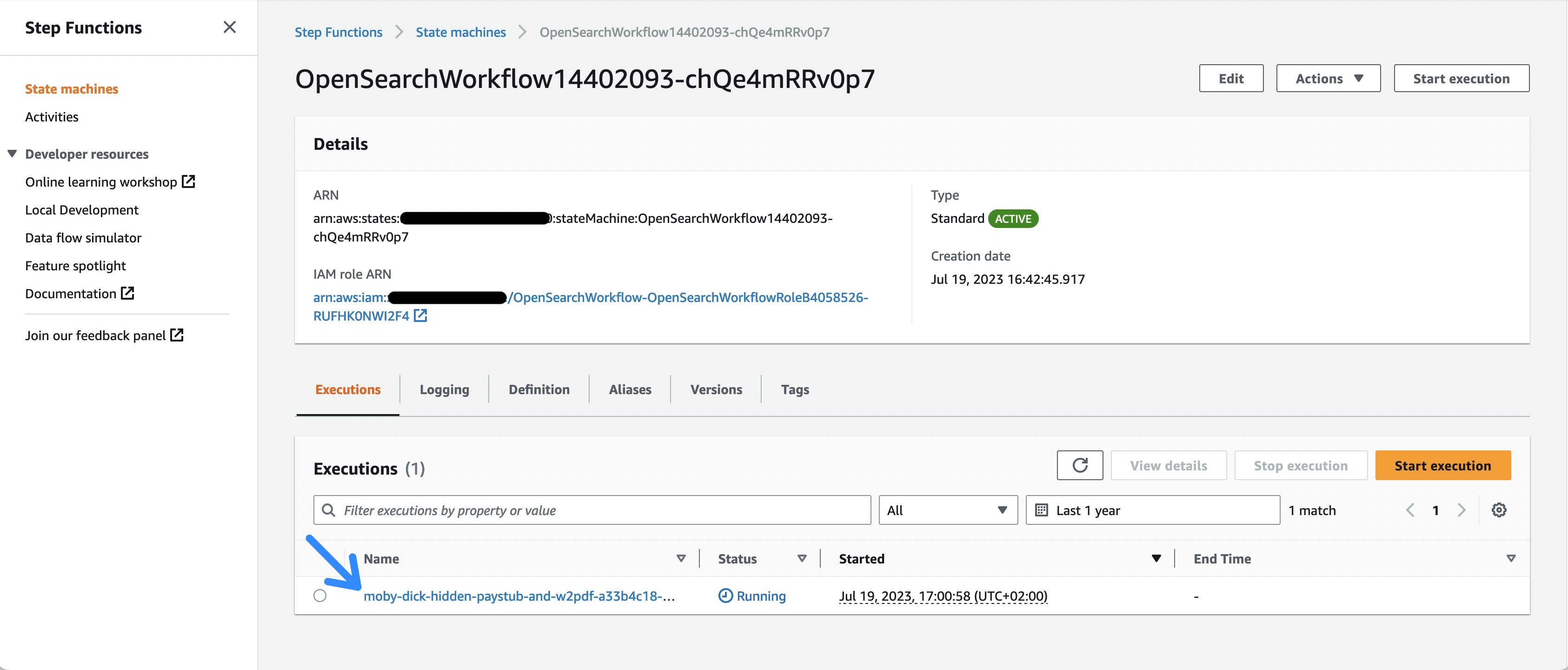
Εικόνα 2: Η λίστα εκτελέσεων Step Functions
- Ρίξτε μια ματιά στο τρέχον δείγμα εκτέλεσης εγγράφου, όπου μπορείτε να παρακολουθήσετε την εκτέλεση των επιμέρους εργασιών ροής εργασίας.
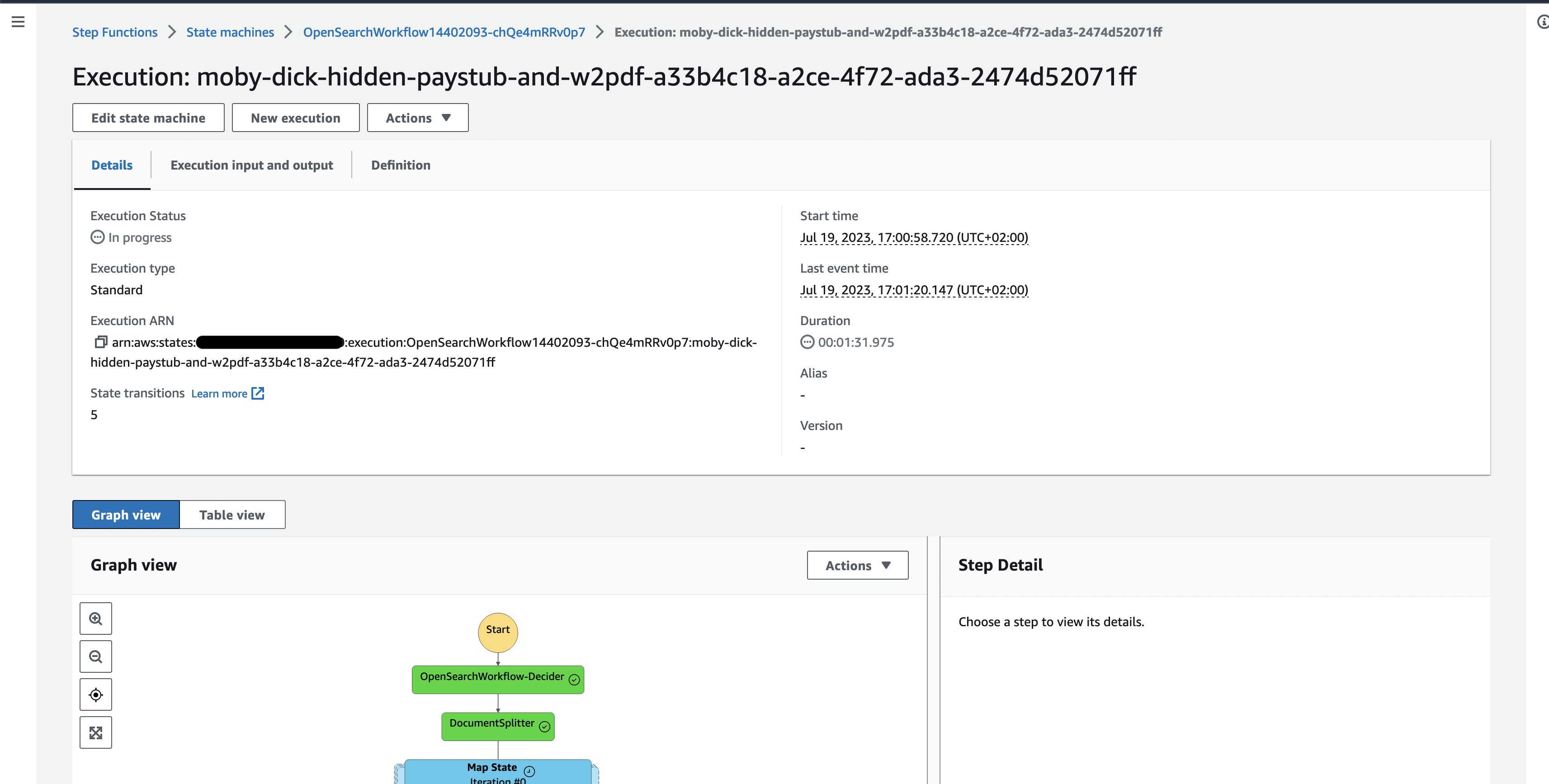
Εικόνα 3: Ένα έγγραφο Βήμα Λειτουργίες εκτέλεση ροής εργασίας
Αναζήτηση
Μόλις ολοκληρωθεί η διαδικασία, μπορούμε να επικυρώσουμε ότι το έγγραφο έχει ευρετηριαστεί στο ευρετήριο OpenSearch.
- Για να γίνει αυτό, πρώτα δημιουργούμε έναν χρήστη Amazon Cognito. Το Amazon Cognito χρησιμοποιείται για τον έλεγχο ταυτότητας των χρηστών έναντι του ευρετηρίου OpenSearch. Επιλέξτε τον σύνδεσμο στην έξοδο από την ανάπτυξη του cdk (ή δείτε το AWS CloudFormation έξοδο στην κονσόλα διαχείρισης AWS) με το όνομα OpenSearchWorkflow.CognitoUserPoolLink.
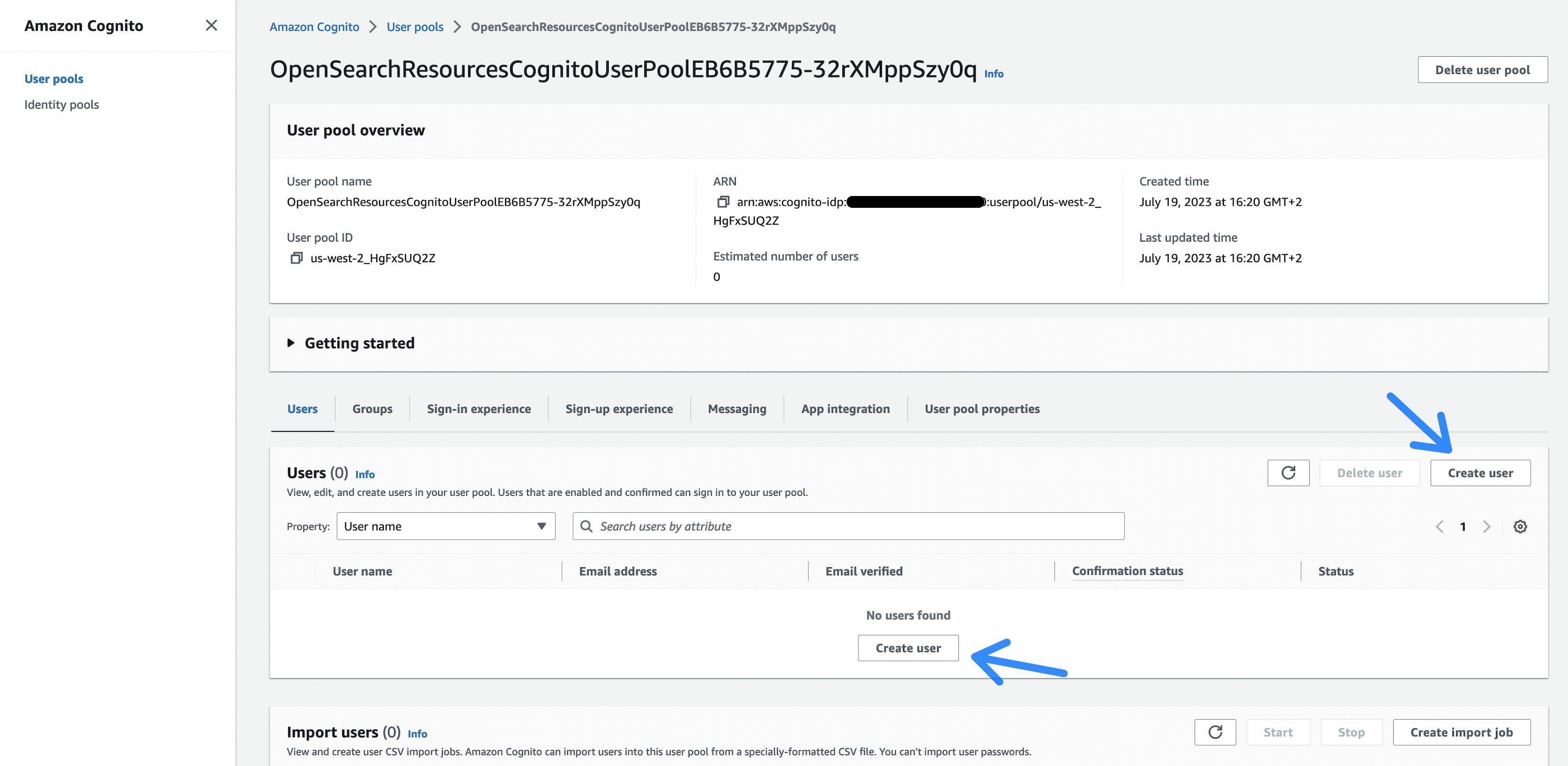
Εικόνα 4: Η ομάδα χρηστών Cognito
- Στη συνέχεια, επιλέξτε το Δημιουργία χρήστη κουμπί, το οποίο σας κατευθύνει σε μια σελίδα για να εισαγάγετε ένα όνομα χρήστη και έναν κωδικό πρόσβασης για πρόσβαση στον Πίνακα ελέγχου OpenSearch.
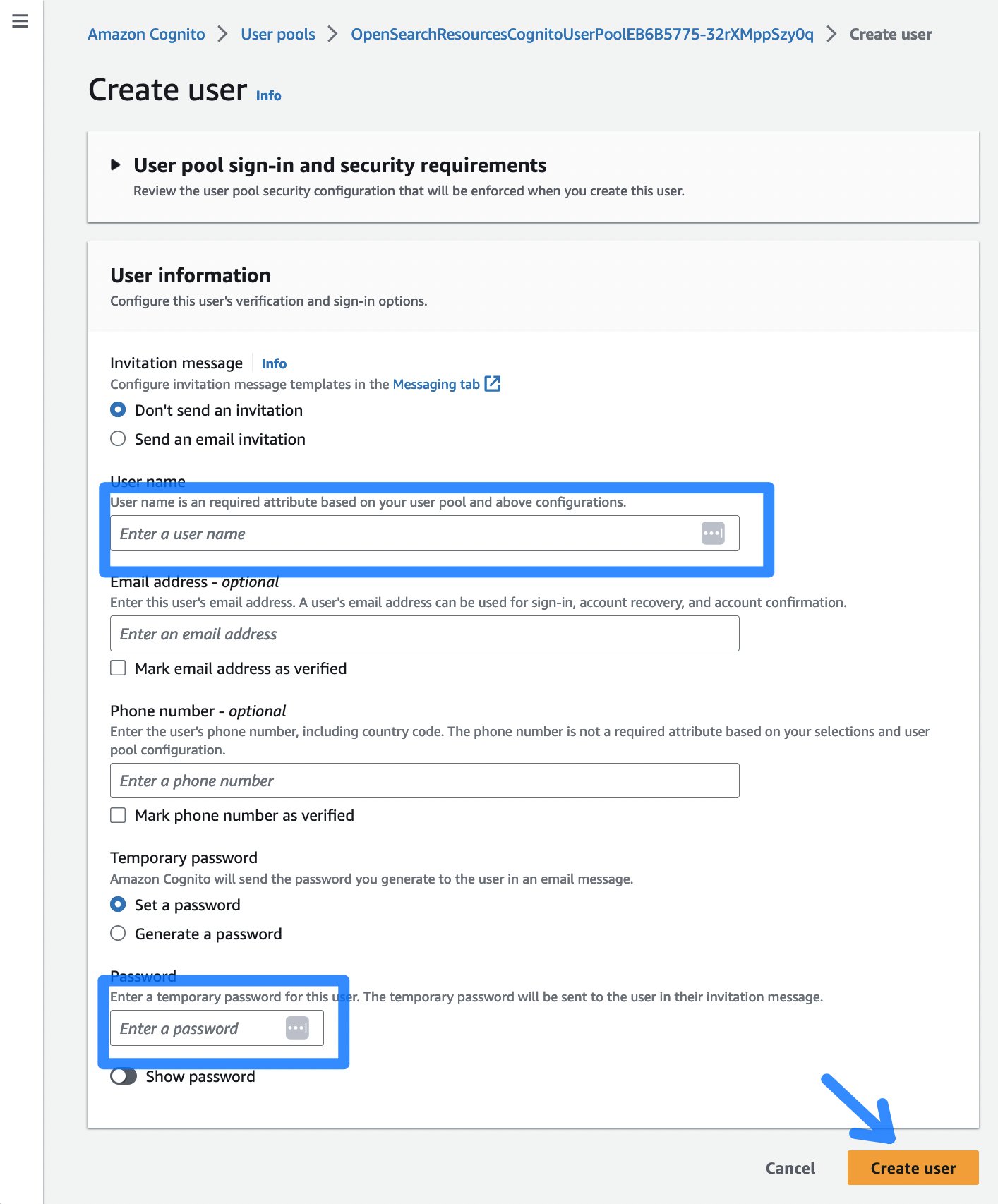
Εικόνα 5: Το παράθυρο διαλόγου Cognito Create χρήστη
- Μετά την επιλογή Δημιουργία χρήστη, μπορείτε να συνεχίσετε στον Πίνακα ελέγχου OpenSearch κάνοντας κλικ στο OpenSearchWorkflow.OpenSearchDashboard από την έξοδο ανάπτυξης CDK. Συνδεθείτε χρησιμοποιώντας το όνομα χρήστη και τον κωδικό πρόσβασης που δημιουργήσατε προηγουμένως. Την πρώτη φορά που συνδέεστε, πρέπει να αλλάξετε τον κωδικό πρόσβασης.
- Αφού συνδεθείτε στον Πίνακα ελέγχου OpenSearch, επιλέξτε το Διαχείριση στοίβας ενότητα, ακολουθούμενη από Μοτίβο ευρετηρίουs για να δημιουργήσετε ένα ευρετήριο αναζήτησης.
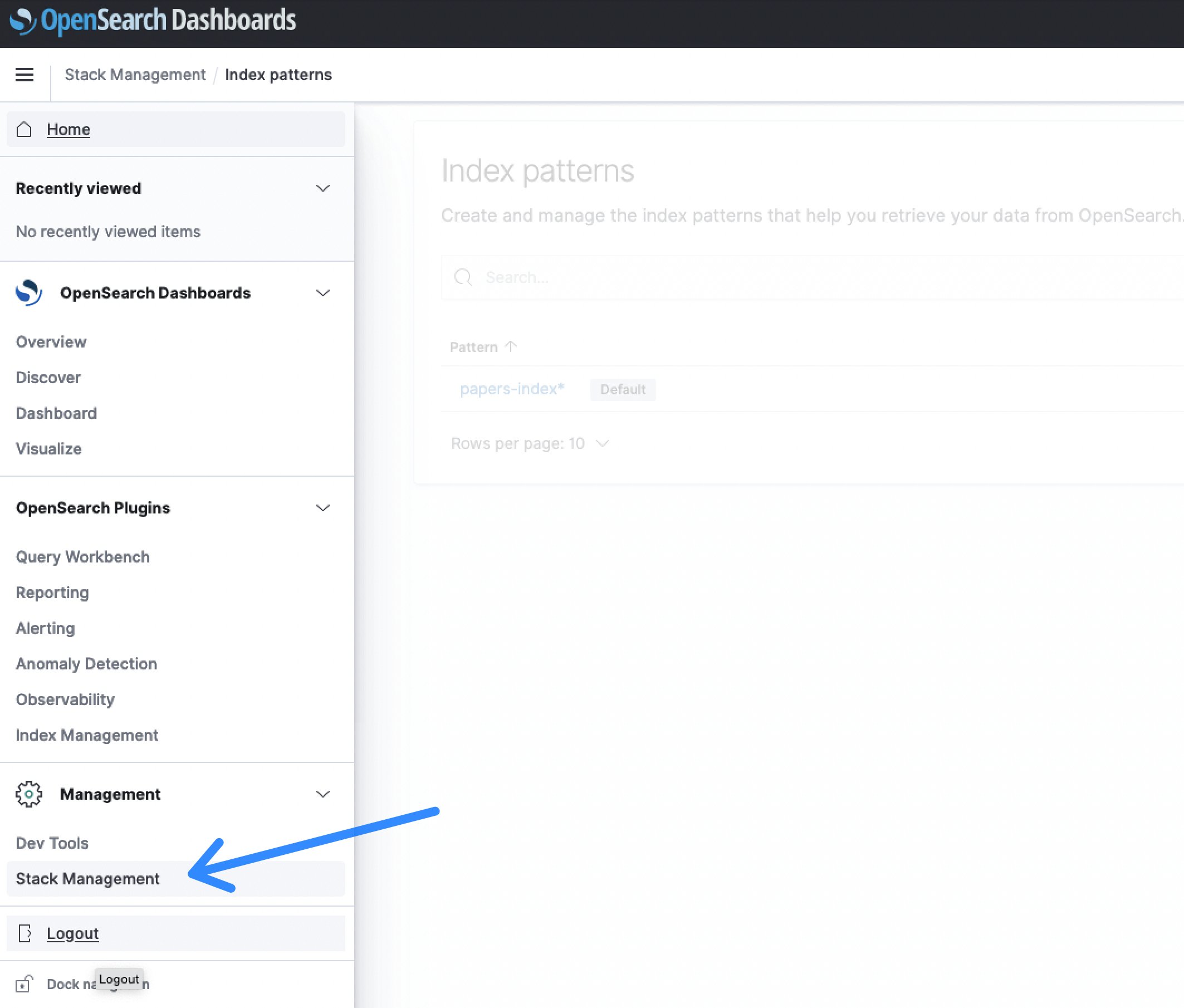
Εικόνα 6: Διαχείριση στοίβας πινάκων ελέγχου OpenSearch
Εικόνα 7: Επισκόπηση μοτίβων ευρετηρίου OpenSearch
- Το προεπιλεγμένο όνομα για το ευρετήριο είναι χαρτιά-ευρετήριο και ένα όνομα μοτίβου ευρετηρίου του χαρτιά-ευρετήριο* θα ταιριάζει με αυτό.

Εικόνα 8: Ορίστε το μοτίβο ευρετηρίου OpenSearch
- Μετά το κλικ Επόμενο βήμα, Επιλέξτε timestamp καθώς η Πεδίο χρόνου και Δημιουργία μοτίβου ευρετηρίου.
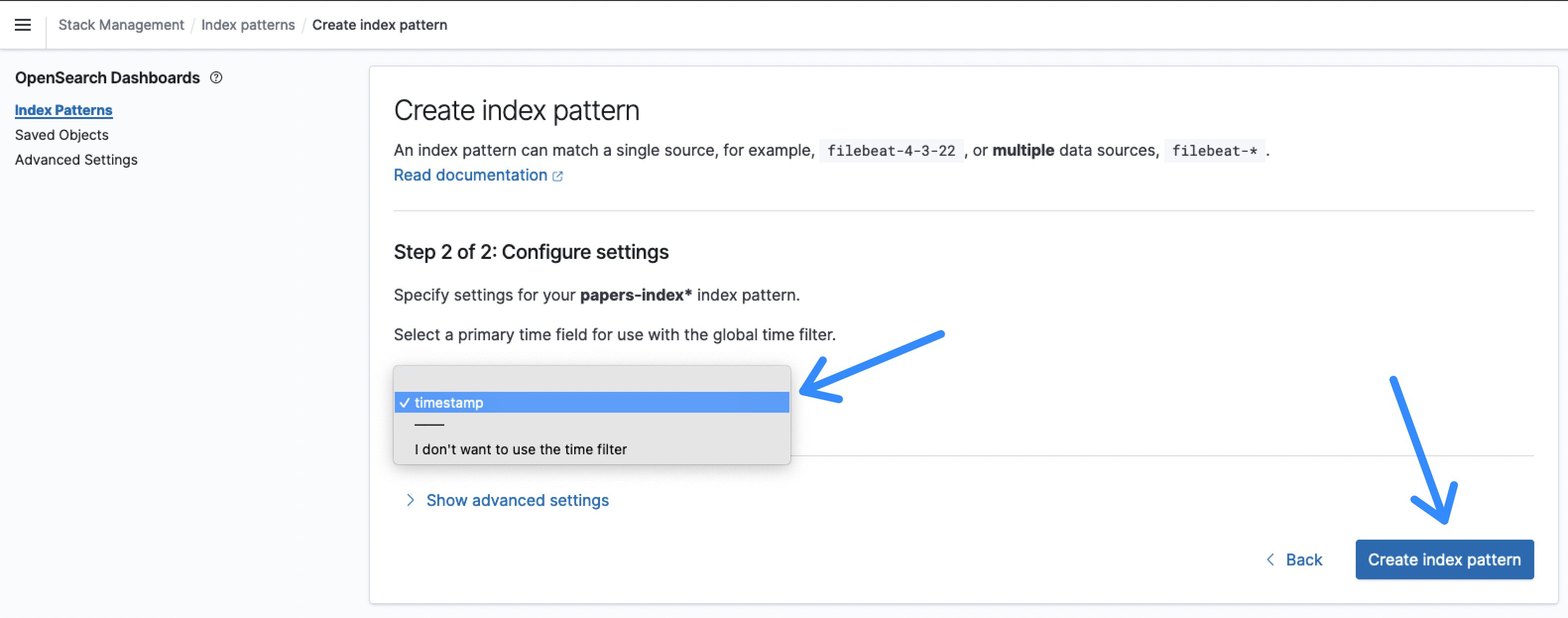
Εικόνα 9: Πεδίο χρόνου μοτίβου ευρετηρίου OpenSearch
- Τώρα, από το μενού, επιλέξτε Ανακαλύψτε.
Εικόνα 10: OpenSearch Discover
Στις περισσότερες περιπτώσεις, πρέπει να αλλάξετε το χρονικό διάστημα σύμφωνα με την τελευταία πρόσληψη. Η προεπιλογή είναι 15 λεπτά και συχνά δεν υπήρχε δραστηριότητα τα τελευταία 15 λεπτά. Σε αυτό το παράδειγμα, άλλαξε σε 15 ημέρες για να οπτικοποιηθεί η πρόσληψη.
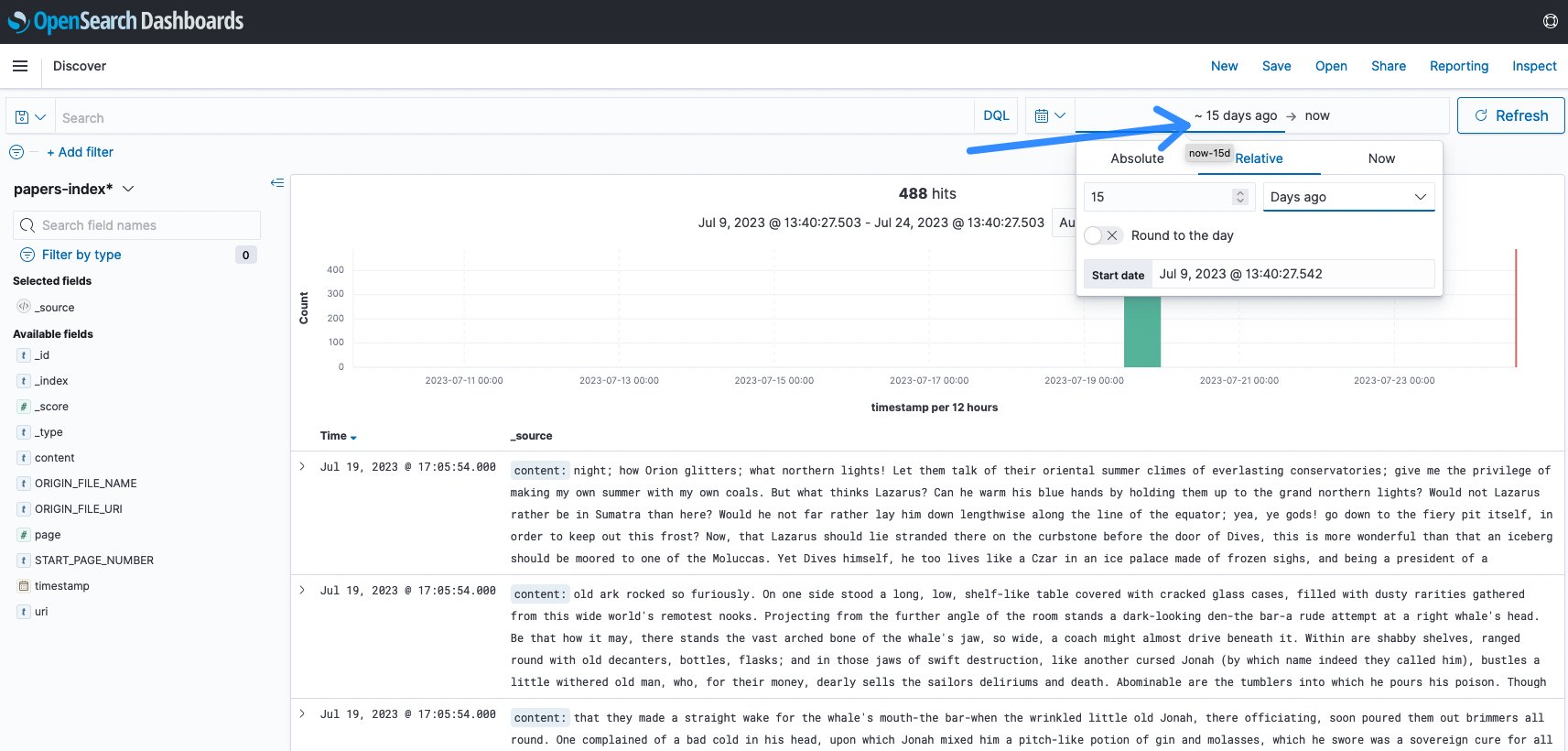
Εικόνα 11: Αλλαγή χρονικού διαστήματος OpenSearch
- Τώρα μπορείτε να ξεκινήσετε την αναζήτηση. Ένα μυθιστόρημα καταχωρήθηκε στο ευρετήριο, μπορείτε να αναζητήσετε οποιουσδήποτε όρους όπως πείτε με Ισμαήλ και δείτε τα αποτελέσματα.
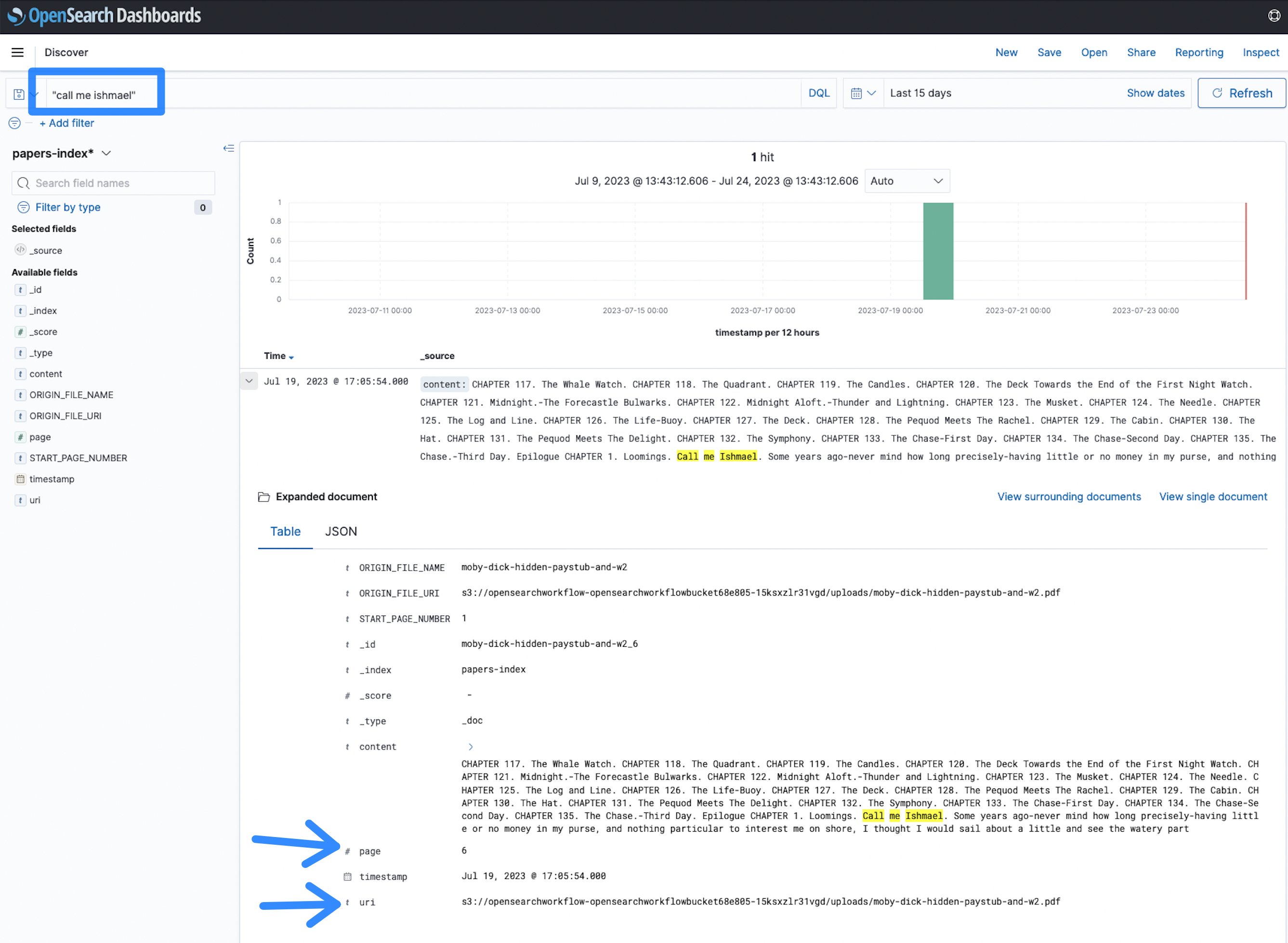
Εικόνα 12: Όρος αναζήτησης OpenSearch
Στην περίπτωση αυτή, ο όρος πείτε με Ισμαήλ εμφανίζεται στη σελίδα 6 του εγγράφου στο δεδομένο Uniform Resource Identifier (URI), το οποίο δείχνει τη θέση Amazon S3 του αρχείου. Αυτό καθιστά πιο γρήγορο τον εντοπισμό εγγράφων και την εύρεση πληροφοριών σε ένα μεγάλο σύνολο εγγράφων PDF, TIFF ή εικόνας, σε σύγκριση με τη μη αυτόματη παράβλεψή τους.
Τρέξιμο σε κλίμακα
Προκειμένου να εκτιμηθεί η κλίμακα και η διάρκεια μιας διαδικασίας ευρετηρίασης, η υλοποίηση δοκιμάστηκε με 93,997 έγγραφα και ένα συνολικό άθροισμα 1,583,197 σελίδων (μέσος όρος 16.84 σελίδες/έγγραφο και το μεγαλύτερο αρχείο με 3755 σελίδες), τα οποία όλα ευρετηριάστηκαν στο OpenSearch. Η επεξεργασία όλων των αρχείων και η ευρετηρίασή τους στο OpenSearch χρειάστηκαν 5.5 ώρες στην ανατολική περιοχή των ΗΠΑ (N. Virginia – us-east-1) με χρήση προεπιλογής Ποσοστώσεις υπηρεσιών Amazon Textract. Το παρακάτω γράφημα δείχνει μια αρχική δοκιμή στις 18:00 ακολουθούμενη από την κύρια κατάποση στις 21:00 και όλα γίνονται στις 2:30.
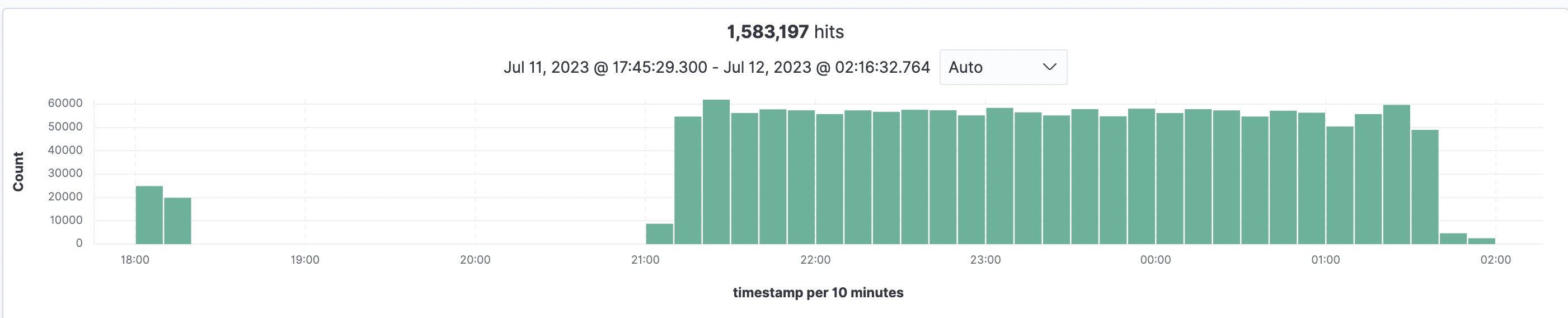
Εικόνα 13: Επισκόπηση ευρετηρίου OpenSearch
Για την επεξεργασία, το tcdk.SFEexecutionsStartThrottle ορίστηκε σε ένα executions_concurrency_threshold=550, που σημαίνει ότι οι ταυτόχρονες ροές εργασίας επεξεργασίας εγγράφων περιορίζονται στα 550 και τα επιπλέον αιτήματα βρίσκονται στην ουρά σε ένα Amazon SQS Ουρά Fist-In-First-Out (FIFO), η οποία στη συνέχεια αποστραγγίζεται όταν τελειώνουν οι τρέχουσες ροές εργασίας. Το όριο των 550 βασίζεται στην ποσόστωση Υπηρεσιών κειμένου των 600 στην περιοχή ΗΠΑ-ανατολή-1. Επομένως, το βάθος της ουράς και η ηλικία του παλαιότερου μηνύματος είναι μετρήσεις που αξίζει να παρακολουθούνται.
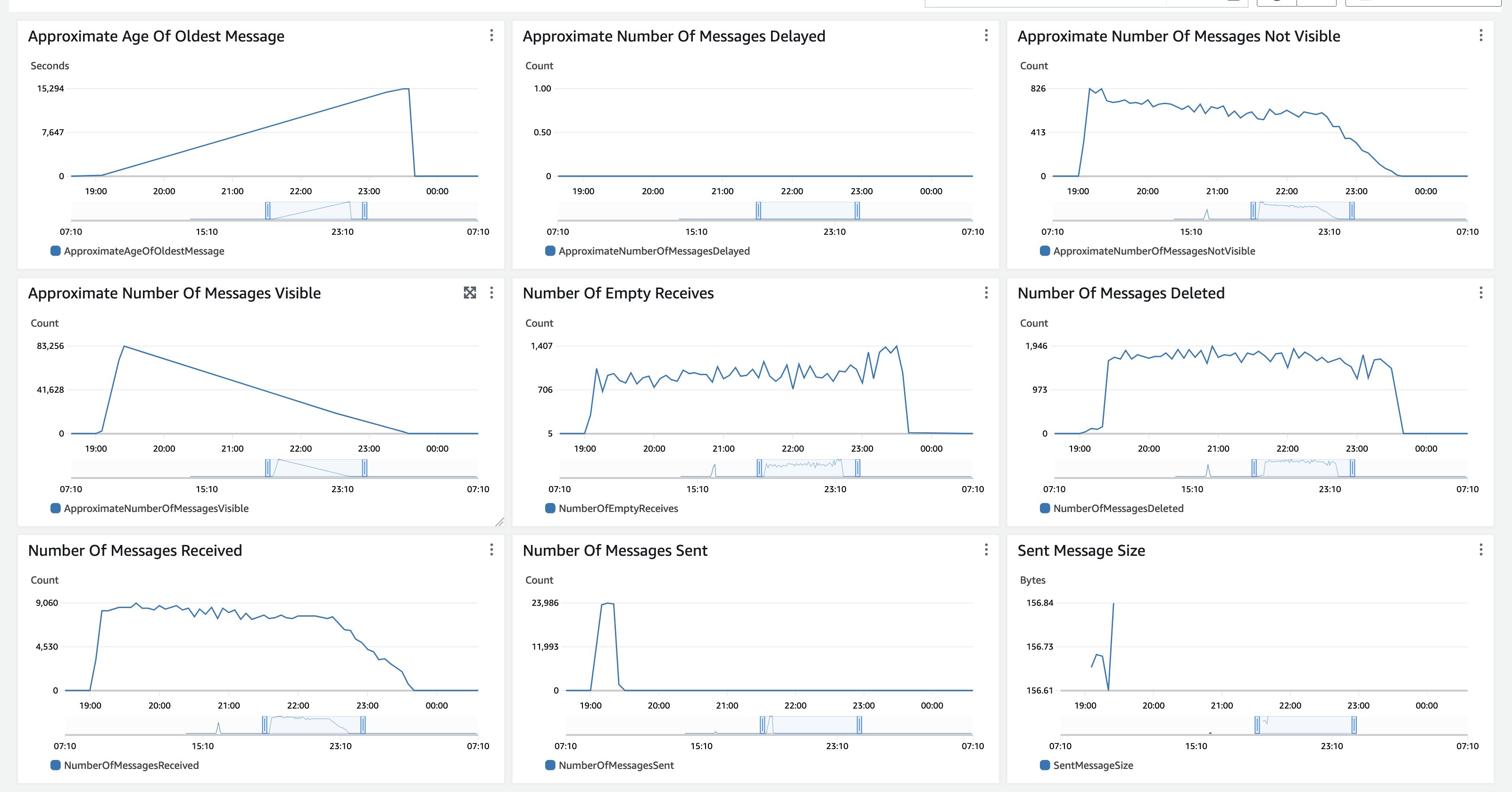
Εικόνα 14: Παρακολούθηση Amazon SQS
Σε αυτήν τη δοκιμή, όλα τα έγγραφα μεταφορτώθηκαν στο Amazon S3 ταυτόχρονα, επομένως το Κατά προσέγγιση αριθμός ορατών μηνυμάτων έχει μια απότομη αύξηση και στη συνέχεια μια αργή πτώση καθώς δεν λαμβάνονται νέα έγγραφα. ο Κατά προσέγγιση ηλικία του παλαιότερου μηνύματος αυξάνεται μέχρι να υποβληθούν σε επεξεργασία όλα τα μηνύματα. Το Amazon SQS MessageRetentionPeriod έχει οριστεί σε 14 ημέρες. Για πολύ μακροχρόνια εκκρεμότητα επεξεργασίας που θα μπορούσε να υπερβεί τις 14 ημέρες, ξεκινήστε με την επεξεργασία ενός μικρότερου υποσυνόλου αντιπροσωπευτικών εγγράφων και παρακολουθήστε τη διάρκεια της εκτέλεσης για να υπολογίσετε πόσα έγγραφα μπορείτε να διαβιβάσετε πριν ξεπεράσετε τις 14 ημέρες. Οι μετρήσεις Amazon SQS CloudWatch φαίνονται παρόμοιες για μια περίπτωση χρήσης επεξεργασίας μεγάλου συσσωρευμένου όγκου εγγράφων, τα οποία απορροφώνται αμέσως και υποβάλλονται σε πλήρη επεξεργασία. Εάν η περίπτωση χρήσης σας είναι μια σταθερή ροή εγγράφων, και οι δύο μετρήσεις, το Κατά προσέγγιση αριθμός ορατών μηνυμάτων και την Κατά προσέγγιση ηλικία του παλαιότερου μηνύματος θα είναι πιο γραμμικό. Μπορείτε επίσης να χρησιμοποιήσετε την παράμετρο κατωφλίου για να συνδυάσετε ένα σταθερό φορτίο με την ανεκτέλεστη επεξεργασία και να εκχωρήσετε χωρητικότητα ανάλογα με τις ανάγκες επεξεργασίας σας.
Μια άλλη μέτρηση που πρέπει να παρακολουθείτε είναι η υγεία του συμπλέγματος OpenSearch, το οποίο θα πρέπει να ρυθμίσετε σύμφωνα με το Λειτουργικές βέλτιστες πρακτικές για την υπηρεσία OpenSearch της Amazon. Η προεπιλεγμένη ανάπτυξη χρησιμοποιεί στιγμιότυπα m6g.large.search.
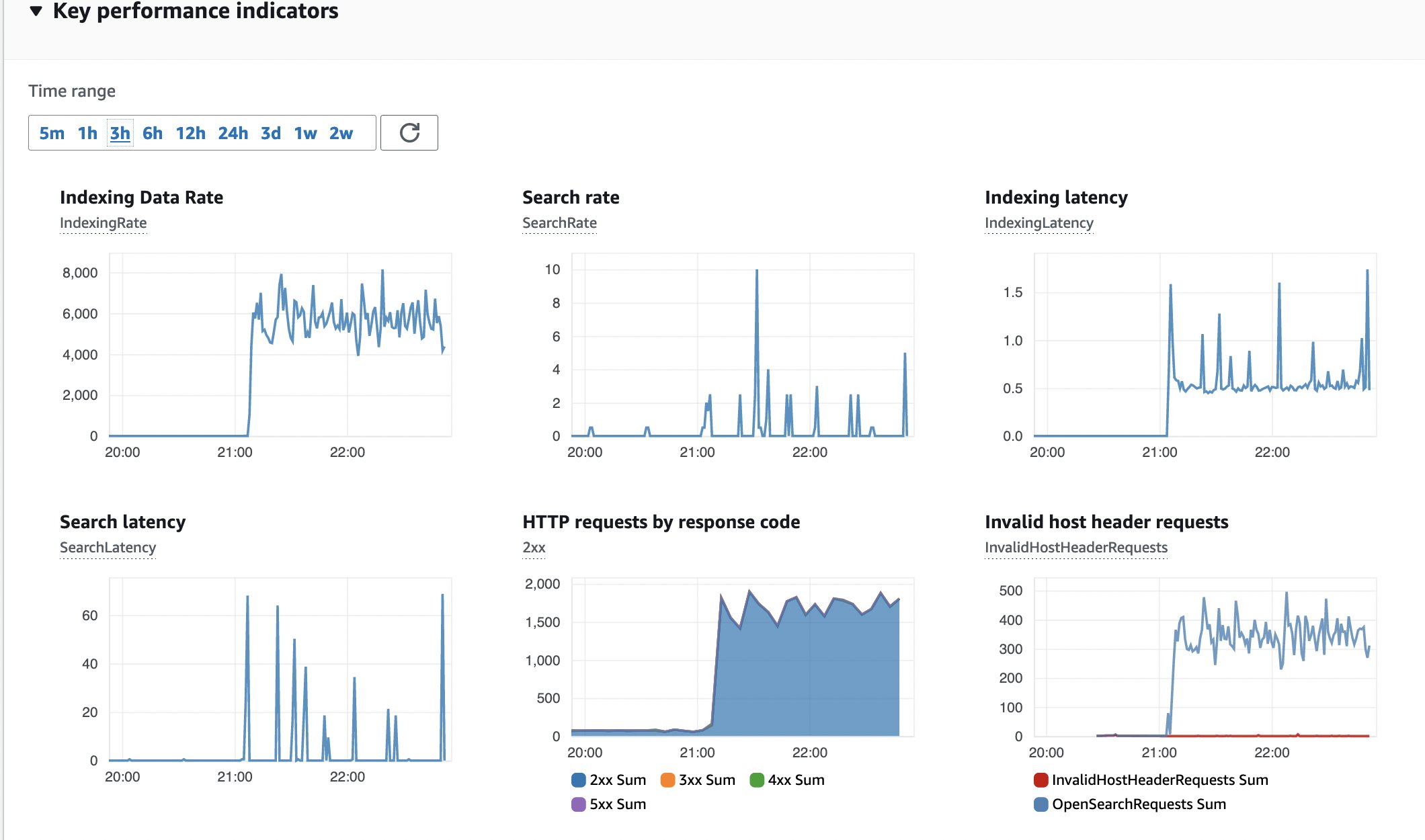
Εικόνα 15: Παρακολούθηση OpenSearch
Ακολουθεί ένα στιγμιότυπο των βασικών δεικτών απόδοσης (KPI) για το σύμπλεγμα OpenSearch. Χωρίς σφάλματα, σταθερός ρυθμός δεδομένων ευρετηρίασης και καθυστέρηση.
Οι εκτελέσεις ροής εργασιών του Step Functions δείχνουν την κατάσταση επεξεργασίας για κάθε μεμονωμένο έγγραφο. Αν δείτε εκτελέσεις μέσα Απέτυχε κατάσταση και, στη συνέχεια, επιλέξτε τις λεπτομέρειες. Μια καλή μέτρηση για παρακολούθηση είναι το AWS Αυτόματος πίνακας εργαλείων CloudWatch για τις Λειτουργίες Βήματος, το οποίο εκθέτει ορισμένα από τα Βήμα Λειτουργίες Μετρήσεις CloudWatch.
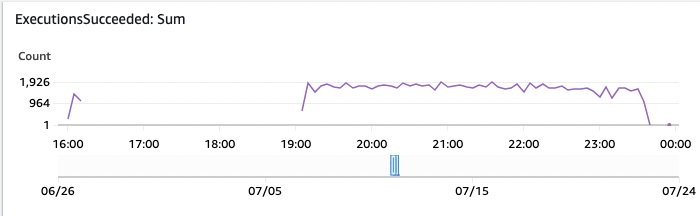
Εικόνα 16: Επιτυχείς εκτελέσεις παρακολούθησης συναρτήσεων βήματος
Σε αυτό το γράφημα του πίνακα ελέγχου AWS CloudWatch, βλέπετε τις επιτυχημένες εκτελέσεις Step Functions με την πάροδο του χρόνου.
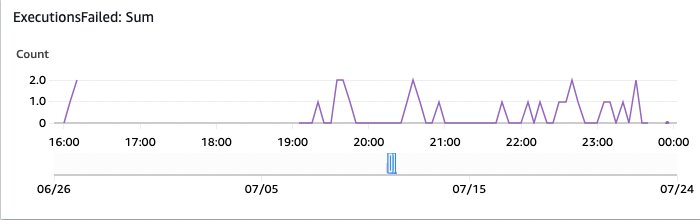
Εικόνα 17: Οι εκτελέσεις παρακολούθησης OpenSearch απέτυχαν
Και αυτό δείχνει τις αποτυχημένες εκτελέσεις. Αυτά αξίζει να διερευνηθούν μέσω της επισκόπησης των Βημάτων της Κονσόλας AWS.
Το παρακάτω στιγμιότυπο οθόνης δείχνει ένα παράδειγμα αποτυχίας εκτέλεσης λόγω του μεγέθους του αρχείου προέλευσης 0, κάτι που είναι λογικό επειδή το αρχείο δεν έχει περιεχόμενο και δεν ήταν δυνατή η επεξεργασία του. Είναι σημαντικό να φιλτράρετε τις αποτυχημένες διαδικασίες και να απεικονίζετε τις αποτυχίες, προκειμένου να επιστρέψετε στο έγγραφο προέλευσης και να επικυρώσετε τη βασική αιτία.
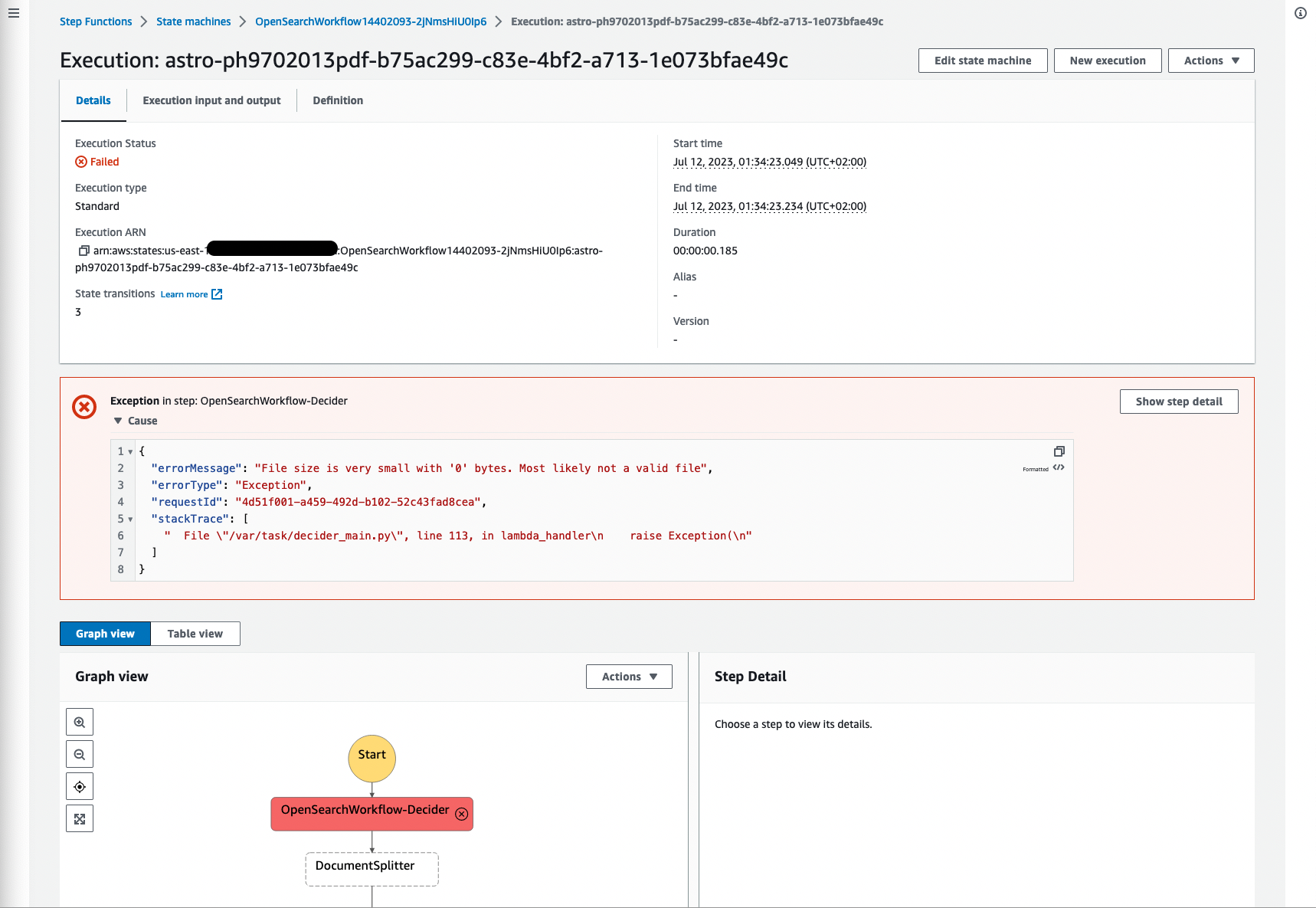
Εικόνα 18: Αποτυχία ροής εργασιών στις λειτουργίες βήματος
Άλλες αποτυχίες μπορεί να περιλαμβάνουν έγγραφα που δεν είναι τύπου mime: application/pdf, image/png, image/jpeg ή image/tiff επειδή άλλοι τύποι εγγράφων δεν υποστηρίζονται από το Amazon Textract.
Κόστος
Το συνολικό κόστος της απορρόφησης 1,583,278 σελίδων κατανεμήθηκε σε υπηρεσίες AWS που χρησιμοποιήθηκαν για την υλοποίηση. Η ακόλουθη λίστα χρησιμεύει ως κατά προσέγγιση αριθμοί, επειδή το πραγματικό κόστος και η διάρκεια επεξεργασίας ποικίλλουν ανάλογα με το μέγεθος των εγγράφων, τον αριθμό των σελίδων ανά έγγραφο, την πυκνότητα των πληροφοριών στα έγγραφα και την περιοχή AWS. Amazon DynamoDB κατανάλωνε 0.55 $, το Amazon S3 3.33 $, η υπηρεσία OpenSearch 14.71 $, το Step Functions 17.92 $, το AWS Lambda 28.95 $ και το Amazon Textract 1,849.97 $. Επίσης, λάβετε υπόψη ότι το αναπτυγμένο σύμπλεγμα υπηρεσίας Amazon OpenSearch Service χρεώνεται ανά ώρα και θα συγκεντρώσει υψηλότερο κόστος όταν εκτελείται σε μια χρονική περίοδο.
τροποποιήσεις
Πιθανότατα, θέλετε να τροποποιήσετε την υλοποίηση και να προσαρμόσετε για την περίπτωση χρήσης και τα έγγραφά σας. Το εργαστήριο Χρησιμοποιήστε τη μηχανική εκμάθηση για να αυτοματοποιήσετε και να επεξεργαστείτε έγγραφα σε κλίμακα παρουσιάζει μια καλή επισκόπηση σχετικά με τον τρόπο χειρισμού των πραγματικών ροών εργασίας, την αλλαγή της ροής και την προσθήκη νέων στοιχείων. Για να προσθέσετε προσαρμοσμένα πεδία στο ευρετήριο OpenSearch, ανατρέξτε στο SetMetaData εργασία στη ροή εργασίας χρησιμοποιώντας το set-manifest-meta-data-opensearch Η λειτουργία AWS Lambda για την προσθήκη μεταδεδομένων στο περιβάλλον, τα οποία θα προστεθούν ως πεδίο στο ευρετήριο OpenSearch. Οποιεσδήποτε πληροφορίες μεταδεδομένων θα γίνουν μέρος του ευρετηρίου.
Καθαρισμό
Διαγράψτε τους πόρους του παραδείγματος εάν δεν τους χρειάζεστε πλέον, για να αποφύγετε μελλοντικά έξοδα χρησιμοποιώντας την παρακάτω εντολή:
στο ίδιο περιβάλλον με το cdk deploy εντολή. Προσέξτε ότι αυτό αφαιρεί τα πάντα, συμπεριλαμβανομένου του συμπλέγματος OpenSearch και όλων των εγγράφων και του κάδου Amazon S3. Εάν θέλετε να διατηρήσετε αυτές τις πληροφορίες, δημιουργήστε αντίγραφα ασφαλείας του κάδου Amazon S3 και δημιουργήστε ένα στιγμιότυπο ευρετηρίου από το σύμπλεγμα OpenSearch. Εάν επεξεργαστήκατε πολλά αρχεία, τότε ίσως χρειαστεί να αδειάσετε τον κάδο Amazon S3 πρώτα χρησιμοποιώντας την Κονσόλα διαχείρισης AWS (δηλαδή, αφού δημιουργήσατε αντίγραφο ασφαλείας ή τα συγχρονίσετε σε διαφορετικό κάδο, εάν θέλετε να διατηρήσετε τις πληροφορίες), επειδή η λειτουργία εκκαθάρισης μπορεί να λήξει και στη συνέχεια να καταστρέψει τη στοίβα AWS CloudFormation.
Συμπέρασμα
Σε αυτήν την ανάρτηση, σας δείξαμε πώς να αναπτύξετε μια λύση πλήρους στοίβας για την εισαγωγή μεγάλου αριθμού εγγράφων σε ένα ευρετήριο OpenSearch, τα οποία είναι έτοιμα να χρησιμοποιηθούν για περιπτώσεις χρήσης αναζήτησης. Συζητήθηκαν τα επιμέρους στοιχεία της υλοποίησης καθώς και οι εκτιμήσεις κλιμάκωσης, το κόστος και οι επιλογές τροποποίησης. Όλος ο κώδικας είναι προσβάσιμος ως OpenSource στο GitHub ως Δείγματα CDK IDP και όπως Κατασκευές CDK IDP για να δημιουργήσετε τις δικές σας λύσεις από την αρχή. Ως επόμενο βήμα, μπορείτε να αρχίσετε να τροποποιείτε τη ροή εργασίας, να προσθέτετε πληροφορίες στα έγγραφα στο ευρετήριο αναζήτησης και να τα εξερευνάτε Εργαστήριο εκτοπισμένων. Σχολιάστε παρακάτω την εμπειρία και τις ιδέες σας για να επεκτείνετε την τρέχουσα λύση.
Σχετικά με το Συγγραφέας
 Μάρτιν Σάντ είναι Senior ML Product SA με την ομάδα Amazon Textract. Έχει πάνω από 20 χρόνια εμπειρίας σε τεχνολογίες που σχετίζονται με το Διαδίκτυο, μηχανικές και αρχιτεκτονικές λύσεις. Εντάχθηκε στην AWS το 2014, καθοδηγώντας αρχικά μερικούς από τους μεγαλύτερους πελάτες AWS στην πιο αποτελεσματική και κλιμακούμενη χρήση των υπηρεσιών AWS, και αργότερα επικεντρώθηκε στην AI/ML με έμφαση στην όραση υπολογιστών. Επί του παρόντος, έχει εμμονή με την εξαγωγή πληροφοριών από έγγραφα.
Μάρτιν Σάντ είναι Senior ML Product SA με την ομάδα Amazon Textract. Έχει πάνω από 20 χρόνια εμπειρίας σε τεχνολογίες που σχετίζονται με το Διαδίκτυο, μηχανικές και αρχιτεκτονικές λύσεις. Εντάχθηκε στην AWS το 2014, καθοδηγώντας αρχικά μερικούς από τους μεγαλύτερους πελάτες AWS στην πιο αποτελεσματική και κλιμακούμενη χρήση των υπηρεσιών AWS, και αργότερα επικεντρώθηκε στην AI/ML με έμφαση στην όραση υπολογιστών. Επί του παρόντος, έχει εμμονή με την εξαγωγή πληροφοριών από έγγραφα.
- SEO Powered Content & PR Distribution. Ενισχύστε σήμερα.
- PlatoData.Network Vertical Generative Ai. Ενδυναμώστε τον εαυτό σας. Πρόσβαση εδώ.
- PlatoAiStream. Web3 Intelligence. Ενισχύθηκε η γνώση. Πρόσβαση εδώ.
- PlatoESG. Αυτοκίνητο / EVs, Ανθρακας, Cleantech, Ενέργεια, Περιβάλλον, Ηλιακός, Διαχείριση των αποβλήτων. Πρόσβαση εδώ.
- PlatoHealth. Ευφυΐα βιοτεχνολογίας και κλινικών δοκιμών. Πρόσβαση εδώ.
- ChartPrime. Ανεβάστε το Trading Game σας με το ChartPrime. Πρόσβαση εδώ.
- BlockOffsets. Εκσυγχρονισμός της περιβαλλοντικής αντιστάθμισης ιδιοκτησίας. Πρόσβαση εδώ.
- πηγή: https://aws.amazon.com/blogs/machine-learning/implement-smart-document-search-index-with-amazon-textract-and-amazon-opensearch/

