Τα βασικά μοντέλα (FM) είναι μεγάλα μοντέλα μηχανικής μάθησης (ML) που εκπαιδεύονται σε ένα ευρύ φάσμα μη επισημασμένων και γενικευμένων συνόλων δεδομένων. Τα FM, όπως υποδηλώνει το όνομα, παρέχουν τη βάση για τη δημιουργία πιο εξειδικευμένων εφαρμογών κατάντη και είναι μοναδικά στην προσαρμοστικότητά τους. Μπορούν να εκτελέσουν ένα ευρύ φάσμα διαφορετικών εργασιών, όπως επεξεργασία φυσικής γλώσσας, ταξινόμηση εικόνων, πρόβλεψη τάσεων, ανάλυση συναισθήματος και απάντηση σε ερωτήσεις. Αυτή η κλίμακα και η προσαρμοστικότητα γενικής χρήσης είναι αυτά που κάνουν τα FM διαφορετικά από τα παραδοσιακά μοντέλα ML. Τα FM είναι πολυτροπικά. Λειτουργούν με διαφορετικούς τύπους δεδομένων όπως κείμενο, βίντεο, ήχος και εικόνες. Τα μοντέλα μεγάλων γλωσσών (LLM) είναι ένας τύπος FM και είναι προεκπαιδευμένα σε τεράστιες ποσότητες δεδομένων κειμένου και συνήθως έχουν εφαρμογές όπως δημιουργία κειμένου, έξυπνα chatbots ή σύνοψη.
Η ροή δεδομένων διευκολύνει τη συνεχή ροή ποικίλων και ενημερωμένων πληροφοριών, ενισχύοντας την ικανότητα των μοντέλων να προσαρμόζονται και να παράγουν πιο ακριβή, σχετικά με τα συμφραζόμενα αποτελέσματα. Αυτή η δυναμική ενοποίηση δεδομένων ροής επιτρέπει γενετική AI εφαρμογές για να ανταποκρίνονται άμεσα στις μεταβαλλόμενες συνθήκες, βελτιώνοντας την προσαρμοστικότητά τους και τη συνολική τους απόδοση σε διάφορες εργασίες.
Για να το καταλάβετε καλύτερα αυτό, φανταστείτε ένα chatbot που βοηθά τους ταξιδιώτες να κάνουν κράτηση για το ταξίδι τους. Σε αυτό το σενάριο, το chatbot χρειάζεται πρόσβαση σε πραγματικό χρόνο στο απόθεμα αεροπορικών εταιρειών, την κατάσταση πτήσης, το απόθεμα ξενοδοχείου, τις τελευταίες αλλαγές τιμών και πολλά άλλα. Αυτά τα δεδομένα προέρχονται συνήθως από τρίτα μέρη και οι προγραμματιστές πρέπει να βρουν έναν τρόπο να απορροφήσουν αυτά τα δεδομένα και να επεξεργαστούν τις αλλαγές δεδομένων καθώς συμβαίνουν.
Η επεξεργασία παρτίδων δεν ταιριάζει καλύτερα σε αυτό το σενάριο. Όταν τα δεδομένα αλλάζουν γρήγορα, η ομαδική επεξεργασία τους μπορεί να έχει ως αποτέλεσμα τη χρήση παλιών δεδομένων από το chatbot, παρέχοντας ανακριβείς πληροφορίες στον πελάτη, γεγονός που επηρεάζει τη συνολική εμπειρία του πελάτη. Η επεξεργασία ροής, ωστόσο, μπορεί να επιτρέψει στο chatbot να έχει πρόσβαση σε δεδομένα σε πραγματικό χρόνο και να προσαρμόζεται στις αλλαγές στη διαθεσιμότητα και την τιμή, παρέχοντας την καλύτερη καθοδήγηση στον πελάτη και βελτιώνοντας την εμπειρία του πελάτη.
Ένα άλλο παράδειγμα είναι μια λύση παρατηρητικότητας και παρακολούθησης που βασίζεται σε AI, όπου τα FM παρακολουθούν τις εσωτερικές μετρήσεις ενός συστήματος σε πραγματικό χρόνο και παράγουν ειδοποιήσεις. Όταν το μοντέλο εντοπίσει μια ανωμαλία ή μια ανώμαλη μετρική τιμή, θα πρέπει να παράγει αμέσως μια ειδοποίηση και να ειδοποιήσει τον χειριστή. Ωστόσο, η αξία τέτοιων σημαντικών δεδομένων μειώνεται σημαντικά με την πάροδο του χρόνου. Αυτές οι ειδοποιήσεις θα πρέπει ιδανικά να λαμβάνονται εντός δευτερολέπτων ή ακόμα και ενώ συμβαίνουν. Εάν οι φορείς εκμετάλλευσης λάβουν αυτές τις ειδοποιήσεις λίγα λεπτά ή ώρες μετά την πραγματοποίησή τους, μια τέτοια πληροφορία δεν είναι εφαρμόσιμη και δυνητικά έχει χάσει την αξία της. Μπορείτε να βρείτε παρόμοιες περιπτώσεις χρήσης σε άλλους κλάδους όπως το λιανικό εμπόριο, η αυτοκινητοβιομηχανία, η ενέργεια και η χρηματοπιστωτική βιομηχανία.
Σε αυτήν την ανάρτηση, συζητάμε γιατί η ροή δεδομένων είναι ένα κρίσιμο συστατικό των γενετικών εφαρμογών AI λόγω της φύσης της σε πραγματικό χρόνο. Συζητάμε την αξία των υπηρεσιών ροής δεδομένων AWS όπως π.χ Amazon Managed Streaming για το Apache Kafka (Amazon MSK), Ροές δεδομένων Amazon Kinesis, Διαχειριζόμενη υπηρεσία Amazon για Apache Flink, να Firehose δεδομένων Amazon Kinesis στη δημιουργία γενετικών εφαρμογών AI.
Εκμάθηση εντός πλαισίου
Τα LLM εκπαιδεύονται με δεδομένα σημείου-σε-χρόνου και δεν έχουν εγγενή ικανότητα πρόσβασης σε νέα δεδομένα κατά τον χρόνο συμπερασμάτων. Καθώς εμφανίζονται νέα δεδομένα, θα πρέπει να προσαρμόζετε ή να εκπαιδεύετε συνεχώς το μοντέλο. Αυτή δεν είναι μόνο μια δαπανηρή λειτουργία, αλλά και πολύ περιοριστική στην πράξη, επειδή ο ρυθμός δημιουργίας νέων δεδομένων υπερισχύει κατά πολύ της ταχύτητας της μικρορύθμισης. Επιπλέον, οι LLM στερούνται κατανόησης από τα συμφραζόμενα και βασίζονται αποκλειστικά στα δεδομένα εκπαίδευσής τους και ως εκ τούτου είναι επιρρεπείς σε παραισθήσεις. Αυτό σημαίνει ότι μπορούν να δημιουργήσουν μια ρευστή, συνεκτική και συντακτικά εύρωστη αλλά ουσιαστικά λανθασμένη απόκριση. Επίσης στερούνται συνάφειας, εξατομίκευσης και πλαισίου.
Τα LLM, ωστόσο, έχουν την ικανότητα να μάθουν από τα δεδομένα που λαμβάνουν από το πλαίσιο για να ανταποκρίνονται με μεγαλύτερη ακρίβεια χωρίς να τροποποιούν τα βάρη του μοντέλου. Αυτό ονομάζεται μάθηση εντός πλαισίου, και μπορεί να χρησιμοποιηθεί για την παραγωγή εξατομικευμένων απαντήσεων ή την παροχή ακριβούς απάντησης στο πλαίσιο των πολιτικών του οργανισμού.
Για παράδειγμα, σε ένα chatbot, τα συμβάντα δεδομένων θα μπορούσαν να σχετίζονται με ένα απόθεμα πτήσεων και ξενοδοχείων ή αλλαγές τιμών που λαμβάνονται συνεχώς σε μια μηχανή αποθήκευσης ροής. Επιπλέον, τα συμβάντα δεδομένων φιλτράρονται, εμπλουτίζονται και μετατρέπονται σε αναλώσιμη μορφή χρησιμοποιώντας έναν επεξεργαστή ροής. Το αποτέλεσμα διατίθεται στην εφαρμογή ερωτώντας το πιο πρόσφατο στιγμιότυπο. Το στιγμιότυπο ενημερώνεται συνεχώς μέσω της επεξεργασίας ροής. Επομένως, τα ενημερωμένα δεδομένα παρέχονται στο πλαίσιο μιας προτροπής χρήστη στο μοντέλο. Αυτό επιτρέπει στο μοντέλο να προσαρμοστεί στις πιο πρόσφατες αλλαγές στην τιμή και τη διαθεσιμότητα. Το παρακάτω διάγραμμα απεικονίζει μια βασική ροή εργασιών μάθησης εντός πλαισίου.
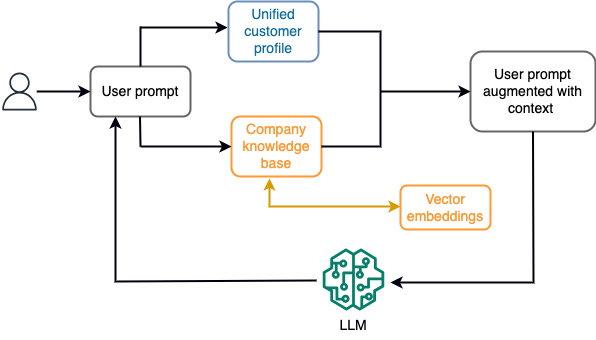
Μια ευρέως χρησιμοποιούμενη προσέγγιση μάθησης εντός πλαισίου είναι η χρήση μιας τεχνικής που ονομάζεται Augmented Generation (RAG). Στο RAG, παρέχετε τις σχετικές πληροφορίες, όπως οι πιο σχετικές πολιτικές και τα αρχεία πελατών μαζί με την ερώτηση χρήστη στο μήνυμα προτροπής. Με αυτόν τον τρόπο, το LLM δημιουργεί μια απάντηση στην ερώτηση του χρήστη χρησιμοποιώντας πρόσθετες πληροφορίες που παρέχονται ως πλαίσιο. Για να μάθετε περισσότερα σχετικά με το RAG, ανατρέξτε στο Απάντηση ερωτήσεων με χρήση του Retrieval Augmented Generation με μοντέλα θεμελίωσης στο Amazon SageMaker JumpStart.
Μια γενετική εφαρμογή τεχνητής νοημοσύνης που βασίζεται σε RAG μπορεί να παράγει μόνο γενικές απαντήσεις με βάση τα δεδομένα εκπαίδευσης και τα σχετικά έγγραφα στη βάση γνώσεων. Αυτή η λύση υπολείπεται όταν αναμένεται μια εξατομικευμένη απόκριση σχεδόν σε πραγματικό χρόνο από την εφαρμογή. Για παράδειγμα, ένα ταξιδιωτικό chatbot αναμένεται να λάβει υπόψη τις τρέχουσες κρατήσεις του χρήστη, το διαθέσιμο απόθεμα ξενοδοχείων και πτήσεων και πολλά άλλα. Επιπλέον, τα σχετικά προσωπικά δεδομένα πελατών (κοινώς γνωστά ως το ενοποιημένο προφίλ πελάτη) υπόκειται συνήθως σε αλλαγές. Εάν χρησιμοποιείται μια διαδικασία δέσμης για την ενημέρωση της βάσης δεδομένων προφίλ χρήστη της γενετικής τεχνητής νοημοσύνης, ο πελάτης μπορεί να λάβει δυσαρεστημένες απαντήσεις με βάση παλιά δεδομένα.
Σε αυτήν την ανάρτηση, συζητάμε την εφαρμογή της επεξεργασίας ροής για τη βελτίωση μιας λύσης RAG που χρησιμοποιείται για τη δημιουργία πρακτόρων απάντησης ερωτήσεων με πλαίσιο από την πρόσβαση σε πραγματικό χρόνο σε ενοποιημένα προφίλ πελατών και οργανωτική βάση γνώσεων.
Ενημερώσεις προφίλ πελατών σχεδόν σε πραγματικό χρόνο
Τα αρχεία πελατών συνήθως διανέμονται σε καταστήματα δεδομένων σε έναν οργανισμό. Για να παρέχει η δημιουργική εφαρμογή τεχνητής νοημοσύνης σας ένα σχετικό, ακριβές και ενημερωμένο προφίλ πελάτη, είναι ζωτικής σημασίας να δημιουργήσετε αγωγούς δεδομένων ροής που μπορούν να πραγματοποιούν ανάλυση ταυτότητας και συνάθροιση προφίλ σε κατανεμημένους χώρους αποθήκευσης δεδομένων. Οι εργασίες ροής απορροφούν συνεχώς νέα δεδομένα για συγχρονισμό μεταξύ συστημάτων και μπορούν να εκτελούν πιο αποτελεσματικά τον εμπλουτισμό, τους μετασχηματισμούς, τις ενώσεις και τις συναθροίσεις στα παράθυρα του χρόνου. Τα συμβάντα λήψης δεδομένων αλλαγής (CDC) περιέχουν πληροφορίες σχετικά με την εγγραφή προέλευσης, τις ενημερώσεις και τα μεταδεδομένα, όπως την ώρα, την προέλευση, την ταξινόμηση (εισαγωγή, ενημέρωση ή διαγραφή) και τον εκκινητή της αλλαγής.
Το παρακάτω διάγραμμα απεικονίζει ένα παράδειγμα ροής εργασίας για απορρόφηση ροής CDC και επεξεργασία για ενοποιημένα προφίλ πελατών.

Σε αυτήν την ενότητα, συζητάμε τα κύρια στοιχεία ενός μοτίβου ροής CDC που απαιτούνται για την υποστήριξη γενετικών εφαρμογών AI που βασίζονται σε RAG.
Απορρόφηση ροής CDC
Ο αντιγραφέας CDC είναι μια διαδικασία που συλλέγει αλλαγές δεδομένων από ένα σύστημα προέλευσης (συνήθως διαβάζοντας αρχεία καταγραφής συναλλαγών ή binlogs) και εγγράφει συμβάντα CDC με την ίδια ακριβώς σειρά που συνέβησαν σε μια ροή δεδομένων ροής ή ένα θέμα. Αυτό περιλαμβάνει μια σύλληψη βάσει ημερολογίου με εργαλεία όπως π.χ Υπηρεσία μετεγκατάστασης βάσης δεδομένων AWS (AWS DMS) ή συνδέσεις ανοιχτού κώδικα, όπως Debezium για Apache Kafka. Το Apache Kafka Connect είναι μέρος του περιβάλλοντος Apache Kafka, επιτρέποντας την απορρόφηση δεδομένων από διάφορες πηγές και την παράδοση σε διάφορους προορισμούς. Μπορείτε να εκτελέσετε την υποδοχή σύνδεσης Apache Kafka Amazon MSK Connect μέσα σε λίγα λεπτά χωρίς να ανησυχείτε για τη διαμόρφωση, τη ρύθμιση και τη λειτουργία ενός συμπλέγματος Apache Kafka. Χρειάζεται μόνο να ανεβάσετε τον μεταγλωττισμένο κώδικα της εφαρμογής σύνδεσης στο Απλή υπηρεσία αποθήκευσης Amazon (Amazon S3) και ρυθμίστε την εφαρμογή σύνδεσης με τη συγκεκριμένη διαμόρφωση του φόρτου εργασίας σας.
Υπάρχουν επίσης άλλες μέθοδοι για την καταγραφή αλλαγών δεδομένων. Για παράδειγμα, Amazon DynamoDB παρέχει μια δυνατότητα ροής δεδομένων CDC Ροές Amazon DynamoDB ή Kinesis Data Streams. Το Amazon S3 παρέχει ένα έναυσμα για την επίκληση ενός AWS Lambda λειτουργία όταν αποθηκεύεται ένα νέο έγγραφο.
Αποθήκευση ροής
Η αποθήκευση ροής λειτουργεί ως ενδιάμεσο buffer για την αποθήκευση συμβάντων CDC πριν από την επεξεργασία τους. Η αποθήκευση ροής παρέχει αξιόπιστη αποθήκευση για δεδομένα ροής. Από τη σχεδίασή του, είναι εξαιρετικά διαθέσιμο και ανθεκτικό σε αστοχίες υλικού ή κόμβων και διατηρεί τη σειρά των συμβάντων όπως είναι γραμμένα. Η αποθήκευση ροής μπορεί να αποθηκεύσει συμβάντα δεδομένων είτε μόνιμα είτε για μια καθορισμένη χρονική περίοδο. Αυτό επιτρέπει στους επεξεργαστές ροής να διαβάζουν από μέρος της ροής εάν υπάρχει αποτυχία ή χρειάζεται εκ νέου επεξεργασία. Το Kinesis Data Streams είναι μια υπηρεσία ροής δεδομένων χωρίς διακομιστή που καθιστά εύκολη τη λήψη, επεξεργασία και αποθήκευση ροών δεδομένων σε κλίμακα. Το Amazon MSK είναι μια πλήρως διαχειριζόμενη, εξαιρετικά διαθέσιμη και ασφαλής υπηρεσία που παρέχεται από την AWS για την εκτέλεση του Apache Kafka.
Ροή επεξεργασίας
Τα συστήματα επεξεργασίας ροής θα πρέπει να σχεδιάζονται για παραλληλισμό ώστε να χειρίζονται υψηλή απόδοση δεδομένων. Θα πρέπει να διαχωρίσουν τη ροή εισόδου μεταξύ πολλαπλών εργασιών που εκτελούνται σε πολλούς κόμβους υπολογιστών. Οι εργασίες θα πρέπει να μπορούν να στέλνουν το αποτέλεσμα μιας λειτουργίας στην επόμενη μέσω του δικτύου, καθιστώντας δυνατή την παράλληλη επεξεργασία δεδομένων κατά την εκτέλεση λειτουργιών όπως συνδέσεις, φιλτράρισμα, εμπλουτισμός και συναθροίσεις. Οι εφαρμογές επεξεργασίας ροής θα πρέπει να μπορούν να επεξεργάζονται συμβάντα σε σχέση με τον χρόνο συμβάντος για χρήση, περιπτώσεις όπου τα συμβάντα θα μπορούσαν να φτάσουν καθυστερημένα ή ο σωστός υπολογισμός βασίζεται στη χρονική στιγμή που συμβαίνουν τα συμβάντα και όχι στον χρόνο του συστήματος. Για περισσότερες πληροφορίες, ανατρέξτε στο Έννοιες του χρόνου: Ώρα συμβάντος και χρόνος επεξεργασίας.
Οι διαδικασίες ροής παράγουν συνεχώς αποτελέσματα με τη μορφή συμβάντων δεδομένων που πρέπει να εξάγονται σε ένα σύστημα στόχο. Ένα σύστημα στόχος θα μπορούσε να είναι οποιοδήποτε σύστημα που μπορεί να ενσωματωθεί απευθείας στη διαδικασία ή μέσω αποθήκευσης ροής, όπως σε ενδιάμεσο. Ανάλογα με το πλαίσιο που επιλέγετε για την επεξεργασία ροής, θα έχετε διαφορετικές επιλογές για συστήματα προορισμού ανάλογα με τους διαθέσιμους συνδέσμους νεροχύτη. Εάν αποφασίσετε να γράψετε τα αποτελέσματα σε έναν ενδιάμεσο χώρο αποθήκευσης ροής, μπορείτε να δημιουργήσετε μια ξεχωριστή διαδικασία που διαβάζει συμβάντα και εφαρμόζει αλλαγές στο σύστημα προορισμού, όπως η εκτέλεση μιας σύνδεσης νεροχύτη Apache Kafka. Ανεξάρτητα από την επιλογή που θα επιλέξετε, τα δεδομένα CDC χρειάζονται επιπλέον χειρισμό λόγω της φύσης τους. Επειδή τα συμβάντα CDC φέρουν πληροφορίες σχετικά με ενημερώσεις ή διαγραφές, είναι σημαντικό να συγχωνεύονται στο σύστημα προορισμού με τη σωστή σειρά. Εάν οι αλλαγές εφαρμοστούν με λάθος σειρά, το σύστημα προορισμού θα είναι εκτός συγχρονισμού με την πηγή του.
Apache Flash είναι ένα ισχυρό πλαίσιο επεξεργασίας ροής γνωστό για τη χαμηλή καθυστέρηση και τις δυνατότητες υψηλής απόδοσης. Υποστηρίζει επεξεργασία χρόνου συμβάντων, σημασιολογία επεξεργασίας ακριβώς μία φορά και υψηλή ανοχή σφαλμάτων. Επιπλέον, παρέχει εγγενή υποστήριξη για δεδομένα CDC μέσω μιας ειδικής δομής που ονομάζεται δυναμικούς πίνακες. Οι δυναμικοί πίνακες μιμούνται τους πίνακες της βάσης δεδομένων προέλευσης και παρέχουν μια στήλη αναπαράστασης των δεδομένων ροής. Τα δεδομένα στους δυναμικούς πίνακες αλλάζουν με κάθε συμβάν που υποβάλλεται σε επεξεργασία. Οι νέες εγγραφές μπορούν να προσαρτηθούν, να ενημερωθούν ή να διαγραφούν ανά πάσα στιγμή. Οι δυναμικοί πίνακες αφαιρούν την επιπλέον λογική που πρέπει να εφαρμόσετε για κάθε λειτουργία εγγραφής (εισαγωγή, ενημέρωση, διαγραφή) ξεχωριστά. Για περισσότερες πληροφορίες, ανατρέξτε στο Δυναμικοί πίνακες.
Με Διαχειριζόμενη υπηρεσία Amazon για Apache Flink, μπορείτε να εκτελέσετε εργασίες Apache Flink και να ενσωματωθείτε με άλλες υπηρεσίες AWS. Δεν υπάρχουν διακομιστές και συμπλέγματα για διαχείριση και δεν υπάρχει υποδομή υπολογισμού και αποθήκευσης για ρύθμιση.
Κόλλα AWS είναι μια πλήρως διαχειριζόμενη υπηρεσία εξαγωγής, μετασχηματισμού και φόρτωσης (ETL), που σημαίνει ότι το AWS χειρίζεται την παροχή, την κλιμάκωση και τη συντήρηση της υποδομής για εσάς. Αν και είναι κυρίως γνωστό για τις δυνατότητές του ETL, το AWS Glue μπορεί επίσης να χρησιμοποιηθεί για εφαρμογές ροής Spark. Το AWS Glue μπορεί να αλληλεπιδράσει με υπηρεσίες ροής δεδομένων όπως το Kinesis Data Streams και το Amazon MSK για την επεξεργασία και τη μετατροπή δεδομένων CDC. Το AWS Glue μπορεί επίσης να ενσωματωθεί απρόσκοπτα με άλλες υπηρεσίες AWS όπως το Lambda, Λειτουργίες βημάτων AWS, και DynamoDB, παρέχοντάς σας ένα ολοκληρωμένο οικοσύστημα για τη δημιουργία και τη διαχείριση αγωγών επεξεργασίας δεδομένων.
Ενιαίο προφίλ πελάτη
Η υπέρβαση της ενοποίησης του προφίλ του πελάτη σε μια ποικιλία συστημάτων πηγής απαιτεί την ανάπτυξη ισχυρών αγωγών δεδομένων. Χρειάζεστε σωλήνες δεδομένων που μπορούν να φέρουν και να συγχρονίσουν όλες τις εγγραφές σε ένα χώρο αποθήκευσης δεδομένων. Αυτό το κατάστημα δεδομένων παρέχει στον οργανισμό σας την ολιστική προβολή αρχείων πελατών που απαιτείται για τη λειτουργική αποτελεσματικότητα των γενετικών εφαρμογών AI που βασίζονται σε RAG. Για την κατασκευή ενός τέτοιου χώρου αποθήκευσης δεδομένων, ένα μη δομημένο χώρο αποθήκευσης δεδομένων θα ήταν καλύτερο.
Ένα γράφημα ταυτότητας είναι μια χρήσιμη δομή για τη δημιουργία ενός ενοποιημένου προφίλ πελάτη, επειδή ενοποιεί και ενσωματώνει δεδομένα πελατών από διάφορες πηγές, διασφαλίζει την ακρίβεια και την αφαίρεση των αντιγράφων δεδομένων, προσφέρει ενημερώσεις σε πραγματικό χρόνο, συνδέει πληροφορίες μεταξύ συστημάτων, επιτρέπει την εξατομίκευση, βελτιώνει την εμπειρία των πελατών και υποστηρίζει τη συμμόρφωση με τους κανονισμούς. Αυτό το ενοποιημένο προφίλ πελατών εξουσιοδοτεί τη δημιουργική εφαρμογή τεχνητής νοημοσύνης να κατανοεί και να αλληλεπιδρά αποτελεσματικά με τους πελάτες και να τηρεί τους κανονισμούς απορρήτου δεδομένων, ενισχύοντας τελικά τις εμπειρίες των πελατών και ωθώντας την επιχειρηματική ανάπτυξη. Μπορείτε να δημιουργήσετε τη λύση γραφήματος ταυτότητάς σας χρησιμοποιώντας Amazon Ποσειδώνας, μια γρήγορη, αξιόπιστη, πλήρως διαχειριζόμενη υπηρεσία βάσης δεδομένων γραφημάτων.
Το AWS παρέχει μερικές άλλες διαχειριζόμενες και χωρίς διακομιστή προσφορές υπηρεσιών αποθήκευσης NoSQL για μη δομημένα αντικείμενα κλειδιού-τιμής. Amazon DocumentDB (με συμβατότητα MongoDB) είναι μια γρήγορη, επεκτάσιμη, εξαιρετικά διαθέσιμη και πλήρως διαχειριζόμενη επιχείρηση βάση δεδομένων εγγράφων υπηρεσία που υποστηρίζει εγγενείς φόρτους εργασίας JSON. Το DynamoDB είναι μια πλήρως διαχειριζόμενη υπηρεσία βάσης δεδομένων NoSQL που παρέχει γρήγορη και προβλέψιμη απόδοση με απρόσκοπτη επεκτασιμότητα.
Ενημερώσεις οργανωσιακής βάσης γνώσεων σε σχεδόν πραγματικό χρόνο
Παρόμοια με τα αρχεία πελατών, τα εσωτερικά αποθετήρια γνώσης, όπως οι πολιτικές της εταιρείας και τα οργανωτικά έγγραφα, αποσιωπούνται σε όλα τα συστήματα αποθήκευσης. Αυτά είναι συνήθως μη δομημένα δεδομένα και ενημερώνονται με μη σταδιακό τρόπο. Η χρήση μη δομημένων δεδομένων για εφαρμογές τεχνητής νοημοσύνης είναι αποτελεσματική με τη χρήση διανυσματικών ενσωματώσεων, η οποία είναι μια τεχνική αναπαράστασης δεδομένων υψηλών διαστάσεων όπως αρχεία κειμένου, εικόνες και αρχεία ήχου ως πολυδιάστατα αριθμητικά.
Το AWS παρέχει πολλά διανυσματικές υπηρεσίες μηχανών, Όπως Amazon OpenSearch χωρίς διακομιστή, Amazon Kendra, να Amazon Aurora PostgreSQL-Compatible Edition με την επέκταση pgvector για την αποθήκευση διανυσματικών ενσωματώσεων. Οι εφαρμογές δημιουργίας τεχνητής νοημοσύνης μπορούν να βελτιώσουν την εμπειρία του χρήστη μετατρέποντας το μήνυμα προτροπής χρήστη σε διάνυσμα και να το χρησιμοποιήσουν για να υποβάλουν ερωτήματα στη μηχανή διανυσμάτων για να ανακτήσουν σχετικές πληροφορίες με βάση τα συμφραζόμενα. Τόσο η προτροπή όσο και τα διανυσματικά δεδομένα που ανακτώνται μεταβιβάζονται στη συνέχεια στο LLM για να λάβουν μια πιο ακριβή και εξατομικευμένη απάντηση.
Το παρακάτω διάγραμμα απεικονίζει ένα παράδειγμα ροής εργασίας επεξεργασίας ροής για ενσωματώσεις διανυσμάτων.
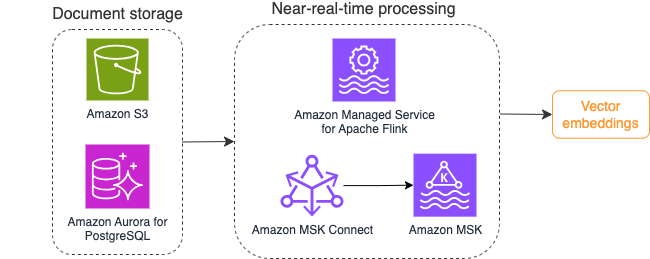
Τα περιεχόμενα της γνωσιακής βάσης πρέπει να μετατραπούν σε διανυσματικές ενσωματώσεις πριν εγγραφούν στο χώρο αποθήκευσης διανυσματικών δεδομένων. Θεμέλιο του Αμαζονίου or Amazon Sage Maker μπορεί να σας βοηθήσει να αποκτήσετε πρόσβαση στο μοντέλο της επιλογής σας και να αποκαλύψετε ένα ιδιωτικό τελικό σημείο για αυτήν τη μετατροπή. Επιπλέον, μπορείτε να χρησιμοποιήσετε βιβλιοθήκες όπως το LangChain για να ενσωματώσετε αυτά τα τελικά σημεία. Η δημιουργία μιας διαδικασίας δέσμης μπορεί να σας βοηθήσει να μετατρέψετε το περιεχόμενο της βάσης γνώσεών σας σε διανυσματικά δεδομένα και να το αποθηκεύσετε αρχικά σε μια διανυσματική βάση δεδομένων. Ωστόσο, πρέπει να βασιστείτε σε ένα διάστημα για την επανεπεξεργασία των εγγράφων για να συγχρονίσετε τη διανυσματική βάση δεδομένων σας με τις αλλαγές στο περιεχόμενο της βάσης γνώσεών σας. Με μεγάλο αριθμό εγγράφων, αυτή η διαδικασία μπορεί να είναι αναποτελεσματική. Μεταξύ αυτών των διαστημάτων, οι χρήστες της εφαρμογής τεχνητής νοημοσύνης που δημιουργούνται θα λαμβάνουν απαντήσεις σύμφωνα με το παλιό περιεχόμενο ή θα λαμβάνουν ανακριβή απάντηση επειδή το νέο περιεχόμενο δεν έχει ακόμη διανυσματοποιηθεί.
Η επεξεργασία ροής είναι μια ιδανική λύση για αυτές τις προκλήσεις. Αρχικά παράγει συμβάντα σύμφωνα με τα υπάρχοντα έγγραφα και παρακολουθεί περαιτέρω το σύστημα προέλευσης και δημιουργεί ένα συμβάν αλλαγής εγγράφου μόλις συμβούν. Αυτά τα συμβάντα μπορούν να αποθηκευτούν σε αποθηκευτικό χώρο ροής και να περιμένουν την επεξεργασία τους από μια εργασία ροής. Μια εργασία ροής διαβάζει αυτά τα συμβάντα, φορτώνει το περιεχόμενο του εγγράφου και μετατρέπει τα περιεχόμενα σε μια σειρά σχετικών σημείων λέξεων. Κάθε διακριτικό μετατρέπεται περαιτέρω σε διανυσματικά δεδομένα μέσω μιας κλήσης API σε ένα ενσωματωμένο FM. Τα αποτελέσματα αποστέλλονται για αποθήκευση στη διανυσματική αποθήκευση μέσω ενός χειριστή νεροχύτη.
Εάν χρησιμοποιείτε το Amazon S3 για την αποθήκευση των εγγράφων σας, μπορείτε να δημιουργήσετε μια αρχιτεκτονική πηγής συμβάντων με βάση τους κανόνες ενεργοποίησης αλλαγής αντικειμένων S3 για το Lambda. Μια συνάρτηση Lambda μπορεί να δημιουργήσει ένα συμβάν στην επιθυμητή μορφή και να το γράψει στο χώρο αποθήκευσης ροής.
Μπορείτε επίσης να χρησιμοποιήσετε το Apache Flink για εκτέλεση ως εργασία ροής. Το Apache Flink παρέχει την εγγενή πηγή σύνδεσης FileSystem, η οποία μπορεί να ανακαλύψει υπάρχοντα αρχεία και να διαβάσει αρχικά το περιεχόμενό τους. Μετά από αυτό, μπορεί να παρακολουθεί συνεχώς το σύστημα αρχείων σας για νέα αρχεία και να καταγράφει το περιεχόμενό τους. Ο σύνδεσμος υποστηρίζει την ανάγνωση ενός συνόλου αρχείων από κατανεμημένα συστήματα αρχείων όπως το Amazon S3 ή το HDFS με μορφή απλού κειμένου, Avro, CSV, Parquet και άλλα, και παράγει μια εγγραφή ροής. Ως μια πλήρως διαχειριζόμενη υπηρεσία, η Managed Service for Apache Flink αφαιρεί το λειτουργικό κόστος ανάπτυξης και διατήρησης εργασιών Flink, επιτρέποντάς σας να εστιάσετε στη δημιουργία και την κλιμάκωση των εφαρμογών ροής σας. Με την απρόσκοπτη ενσωμάτωση στις υπηρεσίες ροής AWS, όπως το Amazon MSK ή το Kinesis Data Streams, παρέχει λειτουργίες όπως αυτόματη κλιμάκωση, ασφάλεια και ελαστικότητα, παρέχοντας αξιόπιστες και αποτελεσματικές εφαρμογές Flink για το χειρισμό δεδομένων ροής σε πραγματικό χρόνο.
Με βάση την προτίμησή σας για DevOps, μπορείτε να επιλέξετε μεταξύ Kinesis Data Streams ή Amazon MSK για την αποθήκευση των εγγραφών ροής. Το Kinesis Data Streams απλοποιεί την πολυπλοκότητα της δημιουργίας και της διαχείρισης προσαρμοσμένων εφαρμογών δεδομένων ροής, επιτρέποντάς σας να εστιάσετε στην εξαγωγή πληροφοριών από τα δεδομένα σας και όχι στη συντήρηση της υποδομής. Οι πελάτες που χρησιμοποιούν Apache Kafka συχνά επιλέγουν το Amazon MSK λόγω της απλότητας, της επεκτασιμότητας και της αξιοπιστίας του στην επίβλεψη των συμπλεγμάτων Apache Kafka εντός του περιβάλλοντος AWS. Ως μια πλήρως διαχειριζόμενη υπηρεσία, το Amazon MSK αναλαμβάνει τις λειτουργικές πολυπλοκότητες που σχετίζονται με την ανάπτυξη και τη διατήρηση συμπλεγμάτων Apache Kafka, επιτρέποντάς σας να επικεντρωθείτε στην κατασκευή και την επέκταση των εφαρμογών ροής σας.
Επειδή μια ενσωμάτωση RESTful API ταιριάζει στη φύση αυτής της διαδικασίας, χρειάζεστε ένα πλαίσιο που να υποστηρίζει ένα μοτίβο εμπλουτισμού κατάστασης μέσω κλήσεων RESTful API για να παρακολουθείτε τυχόν αποτυχίες και να προσπαθήσετε ξανά για το αίτημα που απέτυχε. Το Apache Flink και πάλι είναι ένα πλαίσιο που μπορεί να κάνει λειτουργίες κατάστασης σε ταχύτητα μνήμης. Για να κατανοήσετε τους καλύτερους τρόπους πραγματοποίησης κλήσεων API μέσω του Apache Flink, ανατρέξτε στο Κοινά μοτίβα εμπλουτισμού δεδομένων ροής στο Amazon Kinesis Data Analytics για το Apache Flink.
Το Apache Flink παρέχει εγγενείς συνδέσεις νεροχύτη για εγγραφή δεδομένων σε διανυσματικές αποθήκες δεδομένων όπως το Amazon Aurora για PostgreSQL με pgvector ή Amazon OpenSearch Service με VectorDB. Εναλλακτικά, μπορείτε να σκηνοθετήσετε την έξοδο της εργασίας Flink (διανυσματικά δεδομένα) σε ένα θέμα MSK ή σε μια ροή δεδομένων Kinesis. Η Υπηρεσία OpenSearch παρέχει υποστήριξη για εγγενή απορρόφηση από ροές δεδομένων Kinesis ή θέματα MSK. Για περισσότερες πληροφορίες, ανατρέξτε στο Παρουσιάζοντας το Amazon MSK ως πηγή για την Απορρόφηση OpenSearch του Amazon και Φόρτωση δεδομένων ροής από το Amazon Kinesis Data Streams.
Αναλύσεις σχολίων και τελειοποίηση
Είναι σημαντικό για τους διαχειριστές λειτουργίας δεδομένων και τους προγραμματιστές AI/ML να αποκτήσουν πληροφορίες σχετικά με την απόδοση της γενετικής εφαρμογής AI και των FM που χρησιμοποιούνται. Για να το επιτύχετε αυτό, πρέπει να δημιουργήσετε αγωγούς δεδομένων που υπολογίζουν σημαντικά δεδομένα βασικού δείκτη απόδοσης (KPI) με βάση τα σχόλια των χρηστών και την ποικιλία των αρχείων καταγραφής και των μετρήσεων της εφαρμογής. Αυτές οι πληροφορίες είναι χρήσιμες για τα ενδιαφερόμενα μέρη για να αποκτήσουν πληροφορίες σε πραγματικό χρόνο σχετικά με την απόδοση του FM, την εφαρμογή και τη συνολική ικανοποίηση των χρηστών σχετικά με την ποιότητα της υποστήριξης που λαμβάνουν από την αίτησή σας. Χρειάζεται επίσης να συλλέξετε και να αποθηκεύσετε το ιστορικό συνομιλιών για περαιτέρω βελτιστοποίηση των FM σας για να βελτιώσετε την ικανότητά τους να εκτελούν εργασίες συγκεκριμένου τομέα.
Αυτή η περίπτωση χρήσης ταιριάζει πολύ καλά στον τομέα ανάλυσης ροής. Η εφαρμογή σας θα πρέπει να αποθηκεύει κάθε συνομιλία σε αποθηκευτικό χώρο ροής. Η εφαρμογή σας μπορεί να προτρέψει τους χρήστες σχετικά με τη βαθμολογία τους για την ακρίβεια κάθε απάντησης και τη συνολική ικανοποίησή τους. Αυτά τα δεδομένα μπορούν να είναι σε μορφή δυαδικής επιλογής ή κείμενο ελεύθερης μορφής. Αυτά τα δεδομένα μπορούν να αποθηκευτούν σε μια ροή δεδομένων Kinesis ή ένα θέμα MSK και να υποβληθούν σε επεξεργασία για τη δημιουργία KPI σε πραγματικό χρόνο. Μπορείτε να βάλετε τα FM να λειτουργούν για την ανάλυση συναισθημάτων των χρηστών. Τα FM μπορούν να αναλύσουν κάθε απάντηση και να ορίσουν μια κατηγορία ικανοποίησης των χρηστών.
Η αρχιτεκτονική του Apache Flink επιτρέπει τη σύνθετη συγκέντρωση δεδομένων σε παράθυρα χρόνου. Παρέχει επίσης υποστήριξη για ερωτήματα SQL μέσω ροής συμβάντων δεδομένων. Επομένως, χρησιμοποιώντας το Apache Flink, μπορείτε να αναλύσετε γρήγορα τις ακατέργαστες εισόδους χρηστών και να δημιουργήσετε KPI σε πραγματικό χρόνο γράφοντας γνωστά ερωτήματα SQL. Για περισσότερες πληροφορίες, ανατρέξτε στο Table API & SQL.
Με Διαχειριζόμενη υπηρεσία Amazon για το Apache Flink Studio, μπορείτε να δημιουργήσετε και να εκτελέσετε εφαρμογές επεξεργασίας ροής Apache Flink χρησιμοποιώντας τυπικές SQL, Python και Scala σε ένα διαδραστικό σημειωματάριο. Οι φορητοί υπολογιστές στούντιο τροφοδοτούνται από το Apache Zeppelin και χρησιμοποιούν το Apache Flink ως μηχανή επεξεργασίας ροής. Οι φορητοί υπολογιστές στούντιο συνδυάζουν απρόσκοπτα αυτές τις τεχνολογίες για να κάνουν τις προηγμένες αναλύσεις σε ροές δεδομένων προσβάσιμες σε προγραμματιστές όλων των συνόλων δεξιοτήτων. Με υποστήριξη για λειτουργίες που καθορίζονται από τον χρήστη (UDF), το Apache Flink επιτρέπει τη δημιουργία προσαρμοσμένων χειριστών για ενσωμάτωση με εξωτερικούς πόρους όπως τα FM για την εκτέλεση σύνθετων εργασιών όπως η ανάλυση συναισθήματος. Μπορείτε να χρησιμοποιήσετε UDF για να υπολογίσετε διάφορες μετρήσεις ή να εμπλουτίσετε τα ακατέργαστα δεδομένα των σχολίων των χρηστών με πρόσθετες πληροφορίες, όπως το συναίσθημα των χρηστών. Για να μάθετε περισσότερα σχετικά με αυτό το μοτίβο, ανατρέξτε στο Αντιμετωπίζοντας προληπτικά τις ανησυχίες των πελατών σε πραγματικό χρόνο με τα GenAI, Flink, Apache Kafka και Kinesis.
Με τη Managed Service για το Apache Flink Studio, μπορείτε να αναπτύξετε το σημειωματάριό σας στο Studio ως εργασία ροής με ένα κλικ. Μπορείτε να χρησιμοποιήσετε εγγενείς συνδέσεις νεροχύτη που παρέχονται από το Apache Flink για να στείλετε την έξοδο στον αποθηκευτικό χώρο της επιλογής σας ή να την τοποθετήσετε σε μια ροή δεδομένων Kinesis ή θέμα MSK. Amazon RedShift και η Υπηρεσία OpenSearch είναι και τα δύο ιδανικά για την αποθήκευση αναλυτικών δεδομένων. Και οι δύο μηχανές παρέχουν υποστήριξη εγγενούς απορρόφησης από την Kinesis Data Streams και το Amazon MSK μέσω ξεχωριστού αγωγού ροής σε λίμνη δεδομένων ή αποθήκη δεδομένων για ανάλυση.
Το Amazon Redshift χρησιμοποιεί SQL για την ανάλυση δομημένων και ημι-δομημένων δεδομένων σε αποθήκες δεδομένων και λίμνες δεδομένων, χρησιμοποιώντας υλικό σχεδιασμένο από AWS και μηχανική μάθηση για να προσφέρει την καλύτερη απόδοση τιμής σε κλίμακα. Η Υπηρεσία OpenSearch προσφέρει δυνατότητες οπτικοποίησης που υποστηρίζονται από τους πίνακες ελέγχου OpenSearch και το Kibana (εκδόσεις 1.5 έως 7.10).
Μπορείτε να χρησιμοποιήσετε το αποτέλεσμα μιας τέτοιας ανάλυσης σε συνδυασμό με δεδομένα προτροπής χρήστη για να ρυθμίσετε το FM όταν χρειάζεται. Το SageMaker είναι ο πιο απλός τρόπος για να ρυθμίσετε με ακρίβεια τα FM σας. Η χρήση του Amazon S3 με το SageMaker παρέχει μια ισχυρή και απρόσκοπτη ενσωμάτωση για την τελειοποίηση των μοντέλων σας. Το Amazon S3 χρησιμεύει ως μια επεκτάσιμη και ανθεκτική λύση αποθήκευσης αντικειμένων, επιτρέποντας την απλή αποθήκευση και ανάκτηση μεγάλων συνόλων δεδομένων, δεδομένων εκπαίδευσης και τεχνουργημάτων μοντέλων. Το SageMaker είναι μια πλήρως διαχειριζόμενη υπηρεσία ML που απλοποιεί ολόκληρο τον κύκλο ζωής της ML. Χρησιμοποιώντας το Amazon S3 ως backend αποθήκευσης για το SageMaker, μπορείτε να επωφεληθείτε από την επεκτασιμότητα, την αξιοπιστία και τη σχέση κόστους-αποτελεσματικότητας του Amazon S3, ενώ το ενσωματώνετε απρόσκοπτα με τις δυνατότητες εκπαίδευσης και ανάπτυξης του SageMaker. Αυτός ο συνδυασμός επιτρέπει την αποτελεσματική διαχείριση δεδομένων, διευκολύνει την ανάπτυξη συνεργατικών μοντέλων και διασφαλίζει ότι οι ροές εργασίας ML είναι απλοποιημένες και επεκτάσιμες, ενισχύοντας τελικά τη συνολική ευελιξία και απόδοση της διαδικασίας ML. Για περισσότερες πληροφορίες, ανατρέξτε στο Βελτιώστε το Falcon 7B και άλλα LLM στο Amazon SageMaker με @remote decorator.
Με μια υποδοχή σύνδεσης νεροχύτη συστήματος αρχείων, οι εργασίες Apache Flink μπορούν να παραδίδουν δεδομένα στο Amazon S3 σε αρχεία ανοιχτής μορφής (όπως JSON, Avro, Parquet και άλλα) ως αντικείμενα δεδομένων. Εάν προτιμάτε να διαχειρίζεστε τη λίμνη δεδομένων σας χρησιμοποιώντας ένα πλαίσιο λίμνης δεδομένων συναλλαγών (όπως Apache Hudi, Apache Iceberg ή Delta Lake), όλα αυτά τα πλαίσια παρέχουν μια προσαρμοσμένη σύνδεση για το Apache Flink. Για περισσότερες λεπτομέρειες, ανατρέξτε στο Δημιουργήστε έναν αγωγό λίμνης χαμηλής καθυστέρησης από πηγή σε δεδομένα χρησιμοποιώντας το Amazon MSK Connect, το Apache Flink και το Apache Hudi.
Χαρακτηριστικά
Για μια γενετική εφαρμογή AI που βασίζεται σε ένα μοντέλο RAG, πρέπει να εξετάσετε το ενδεχόμενο να δημιουργήσετε δύο συστήματα αποθήκευσης δεδομένων και πρέπει να δημιουργήσετε λειτουργίες δεδομένων που να τις κρατούν ενημερωμένες με όλα τα συστήματα πηγής. Οι παραδοσιακές ομαδικές εργασίες δεν επαρκούν για την επεξεργασία του μεγέθους και της ποικιλομορφίας των δεδομένων που χρειάζεστε για να ενσωματώσετε με τη γενετική εφαρμογή τεχνητής νοημοσύνης. Καθυστερήσεις στην επεξεργασία των αλλαγών στα συστήματα πηγής οδηγούν σε ανακριβή απόκριση και μειώνουν την αποτελεσματικότητα της γενετικής εφαρμογής τεχνητής νοημοσύνης. Η ροή δεδομένων σάς δίνει τη δυνατότητα να λαμβάνετε δεδομένα από μια ποικιλία βάσεων δεδομένων σε διάφορα συστήματα. Σας επιτρέπει επίσης να μετασχηματίζετε, να εμπλουτίζετε, να ενώνετε και να συγκεντρώνετε δεδομένα σε πολλές πηγές αποτελεσματικά σε σχεδόν πραγματικό χρόνο. Η ροή δεδομένων παρέχει μια απλοποιημένη αρχιτεκτονική δεδομένων για τη συλλογή και τη μετατροπή των αντιδράσεων ή των σχολίων των χρηστών σε πραγματικό χρόνο σχετικά με τις απαντήσεις της εφαρμογής, βοηθώντας σας να παραδώσετε και να αποθηκεύσετε τα αποτελέσματα σε μια λίμνη δεδομένων για λεπτομερή ρύθμιση του μοντέλου. Η ροή δεδομένων σάς βοηθά επίσης να βελτιστοποιήσετε τις σωληνώσεις δεδομένων επεξεργάζοντας μόνο τα συμβάντα αλλαγής, επιτρέποντάς σας να ανταποκρίνεστε στις αλλαγές δεδομένων πιο γρήγορα και αποτελεσματικά.
Μάθετε περισσότερα σχετικά με Υπηρεσίες ροής δεδομένων AWS και ξεκινήστε να δημιουργείτε τη δική σας λύση ροής δεδομένων.
Σχετικά με τους Συγγραφείς
 Αλή Αλέμη είναι Streaming Specialist Solutions Architect στην AWS. Η Ali συμβουλεύει τους πελάτες της AWS σχετικά με τις βέλτιστες αρχιτεκτονικές πρακτικές και τους βοηθά να σχεδιάσουν συστήματα δεδομένων ανάλυσης σε πραγματικό χρόνο που είναι αξιόπιστα, ασφαλή, αποτελεσματικά και οικονομικά. Εργάζεται αντίστροφα από τις περιπτώσεις χρήσης των πελατών και σχεδιάζει λύσεις δεδομένων για να λύσει τα επιχειρηματικά τους προβλήματα. Πριν από την ένταξή του στην AWS, ο Ali υποστήριξε αρκετούς πελάτες του δημόσιου τομέα και συμβουλευτικούς εταίρους της AWS στο ταξίδι εκσυγχρονισμού των εφαρμογών τους και στη μετάβαση στο Cloud.
Αλή Αλέμη είναι Streaming Specialist Solutions Architect στην AWS. Η Ali συμβουλεύει τους πελάτες της AWS σχετικά με τις βέλτιστες αρχιτεκτονικές πρακτικές και τους βοηθά να σχεδιάσουν συστήματα δεδομένων ανάλυσης σε πραγματικό χρόνο που είναι αξιόπιστα, ασφαλή, αποτελεσματικά και οικονομικά. Εργάζεται αντίστροφα από τις περιπτώσεις χρήσης των πελατών και σχεδιάζει λύσεις δεδομένων για να λύσει τα επιχειρηματικά τους προβλήματα. Πριν από την ένταξή του στην AWS, ο Ali υποστήριξε αρκετούς πελάτες του δημόσιου τομέα και συμβουλευτικούς εταίρους της AWS στο ταξίδι εκσυγχρονισμού των εφαρμογών τους και στη μετάβαση στο Cloud.
 Imtiaz (Taz) Sayed είναι ο παγκόσμιος ηγέτης τεχνολογίας για το Analytics στο AWS. Του αρέσει να αλληλεπιδρά με την κοινότητα για όλα τα δεδομένα και τα αναλυτικά στοιχεία. Μπορεί να προσεγγιστεί μέσω LinkedIn.
Imtiaz (Taz) Sayed είναι ο παγκόσμιος ηγέτης τεχνολογίας για το Analytics στο AWS. Του αρέσει να αλληλεπιδρά με την κοινότητα για όλα τα δεδομένα και τα αναλυτικά στοιχεία. Μπορεί να προσεγγιστεί μέσω LinkedIn.
- SEO Powered Content & PR Distribution. Ενισχύστε σήμερα.
- PlatoData.Network Vertical Generative Ai. Ενδυναμώστε τον εαυτό σας. Πρόσβαση εδώ.
- PlatoAiStream. Web3 Intelligence. Ενισχύθηκε η γνώση. Πρόσβαση εδώ.
- PlatoESG. Ανθρακας, Cleantech, Ενέργεια, Περιβάλλον, Ηλιακός, Διαχείριση των αποβλήτων. Πρόσβαση εδώ.
- PlatoHealth. Ευφυΐα βιοτεχνολογίας και κλινικών δοκιμών. Πρόσβαση εδώ.
- πηγή: https://aws.amazon.com/blogs/big-data/exploring-real-time-streaming-for-generative-ai-applications/

