Στούντιο Amazon SageMaker παρέχει μια πλήρως διαχειριζόμενη λύση για τους επιστήμονες δεδομένων για τη διαδραστική κατασκευή, εκπαίδευση και ανάπτυξη μοντέλων μηχανικής μάθησης (ML). Κατά τη διαδικασία της επεξεργασίας των καθηκόντων τους ML, οι επιστήμονες δεδομένων ξεκινούν συνήθως τη ροή εργασίας τους ανακαλύπτοντας σχετικές πηγές δεδομένων και συνδέοντάς τους με αυτές. Στη συνέχεια χρησιμοποιούν την SQL για να εξερευνήσουν, να αναλύσουν, να οπτικοποιήσουν και να ενσωματώσουν δεδομένα από διάφορες πηγές προτού τα χρησιμοποιήσουν στην εκπαίδευση και τα συμπεράσματά τους σε ML. Προηγουμένως, οι επιστήμονες δεδομένων συχνά βρίσκονταν να χρησιμοποιούν πολλαπλά εργαλεία για να υποστηρίξουν την SQL στη ροή εργασίας τους, γεγονός που εμπόδιζε την παραγωγικότητα.
Είμαστε στην ευχάριστη θέση να ανακοινώσουμε ότι οι φορητοί υπολογιστές JupyterLab στο SageMaker Studio διαθέτουν πλέον ενσωματωμένη υποστήριξη για SQL. Οι επιστήμονες δεδομένων μπορούν τώρα:
- Συνδεθείτε σε δημοφιλείς υπηρεσίες δεδομένων, συμπεριλαμβανομένων Αμαζόν Αθηνά, Amazon RedShift, Amazon DataZone, και Snowflake απευθείας μέσα στα σημειωματάρια
- Περιήγηση και αναζήτηση για βάσεις δεδομένων, σχήματα, πίνακες και προβολές και προεπισκόπηση δεδομένων στη διεπαφή του σημειωματάριου
- Αναμείξτε κώδικα SQL και Python στο ίδιο σημειωματάριο για αποτελεσματική εξερεύνηση και μετατροπή δεδομένων για χρήση σε έργα ML
- Χρησιμοποιήστε χαρακτηριστικά παραγωγικότητας προγραμματιστών, όπως ολοκλήρωση εντολών SQL, βοήθεια μορφοποίησης κώδικα και επισήμανση σύνταξης για να επιταχύνετε την ανάπτυξη κώδικα και να βελτιώσετε τη συνολική παραγωγικότητα προγραμματιστή
Επιπλέον, οι διαχειριστές μπορούν να διαχειρίζονται με ασφάλεια τις συνδέσεις σε αυτές τις υπηρεσίες δεδομένων, επιτρέποντας στους επιστήμονες δεδομένων να έχουν πρόσβαση σε εξουσιοδοτημένα δεδομένα χωρίς να απαιτείται η μη αυτόματη διαχείριση των διαπιστευτηρίων.
Σε αυτήν την ανάρτηση, σας καθοδηγούμε στη ρύθμιση αυτής της δυνατότητας στο SageMaker Studio και σας καθοδηγούμε σε διάφορες δυνατότητες αυτής της δυνατότητας. Στη συνέχεια, δείχνουμε πώς μπορείτε να βελτιώσετε την εμπειρία SQL στο notebook χρησιμοποιώντας τις δυνατότητες Text-to-SQL που παρέχονται από προηγμένα μοντέλα μεγάλων γλωσσών (LLM) για τη σύνταξη σύνθετων ερωτημάτων SQL χρησιμοποιώντας κείμενο φυσικής γλώσσας ως είσοδο. Τέλος, για να επιτρέψουμε σε ένα ευρύτερο κοινό χρηστών να δημιουργήσει ερωτήματα SQL από την εισαγωγή φυσικής γλώσσας στα σημειωματάρια τους, σας δείχνουμε πώς να αναπτύξετε αυτά τα μοντέλα Text-to-SQL χρησιμοποιώντας Amazon Sage Maker καταληκτικά σημεία.
Επισκόπηση λύσεων
Με την ενσωμάτωση SQL του φορητού υπολογιστή SageMaker Studio JupyterLab, μπορείτε πλέον να συνδεθείτε σε δημοφιλείς πηγές δεδομένων όπως το Snowflake, το Athena, το Amazon Redshift και το Amazon DataZone. Αυτή η νέα δυνατότητα σάς δίνει τη δυνατότητα να εκτελείτε διάφορες λειτουργίες.
Για παράδειγμα, μπορείτε να εξερευνήσετε οπτικά πηγές δεδομένων όπως βάσεις δεδομένων, πίνακες και σχήματα απευθείας από το οικοσύστημά σας JupyterLab. Εάν τα περιβάλλοντα του φορητού υπολογιστή σας εκτελούνται σε SageMaker Distribution 1.6 ή νεότερη έκδοση, αναζητήστε ένα νέο γραφικό στοιχείο στην αριστερή πλευρά της διεπαφής του JupyterLab. Αυτή η προσθήκη βελτιώνει την προσβασιμότητα και τη διαχείριση δεδομένων στο περιβάλλον ανάπτυξης σας.
Εάν δεν βρίσκεστε αυτήν τη στιγμή στο προτεινόμενο SageMaker Distribution (1.5 ή χαμηλότερο) ή σε προσαρμοσμένο περιβάλλον, ανατρέξτε στο παράρτημα για περισσότερες πληροφορίες.
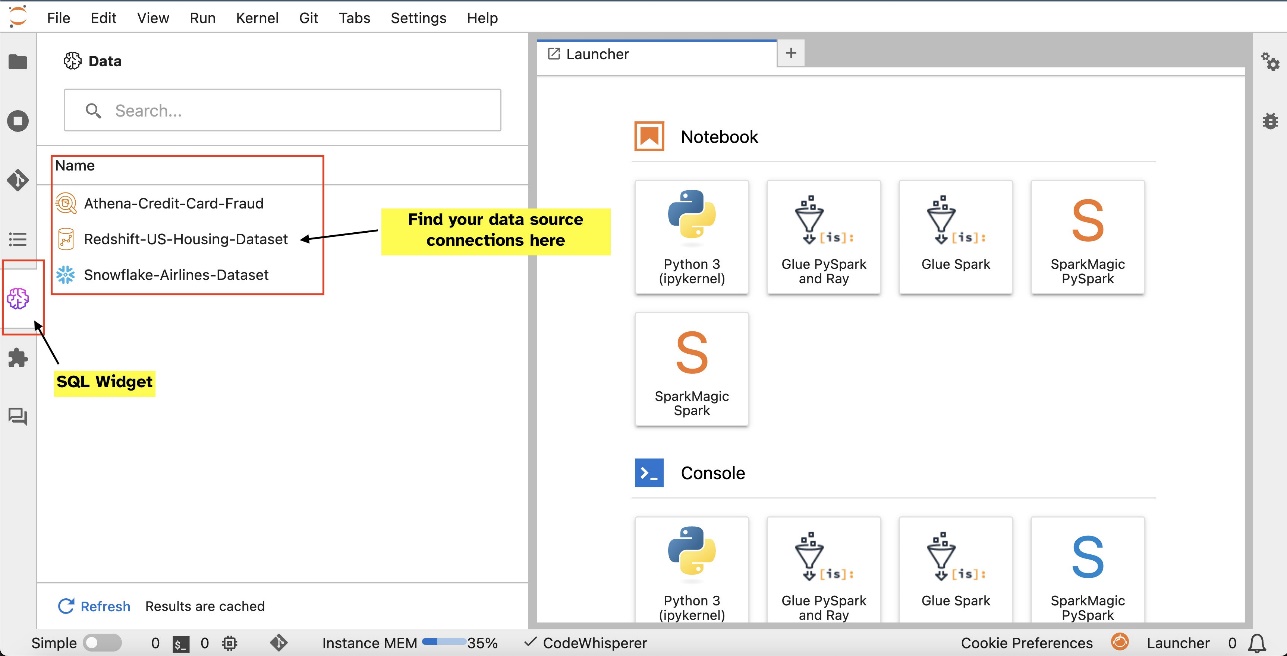
Αφού ρυθμίσετε τις συνδέσεις (που απεικονίζεται στην επόμενη ενότητα), μπορείτε να παραθέσετε συνδέσεις δεδομένων, να περιηγηθείτε σε βάσεις δεδομένων και πίνακες και να επιθεωρήσετε σχήματα.
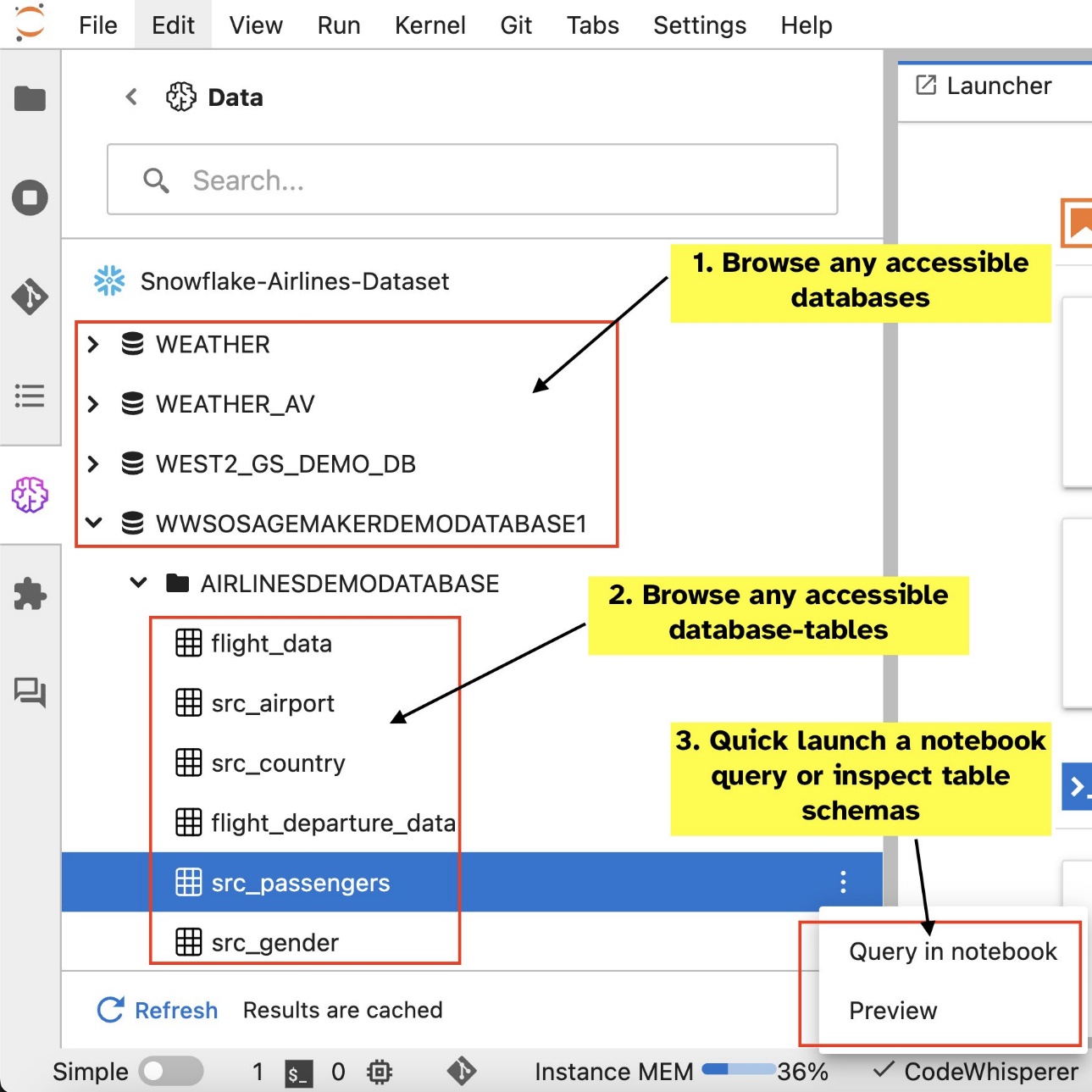
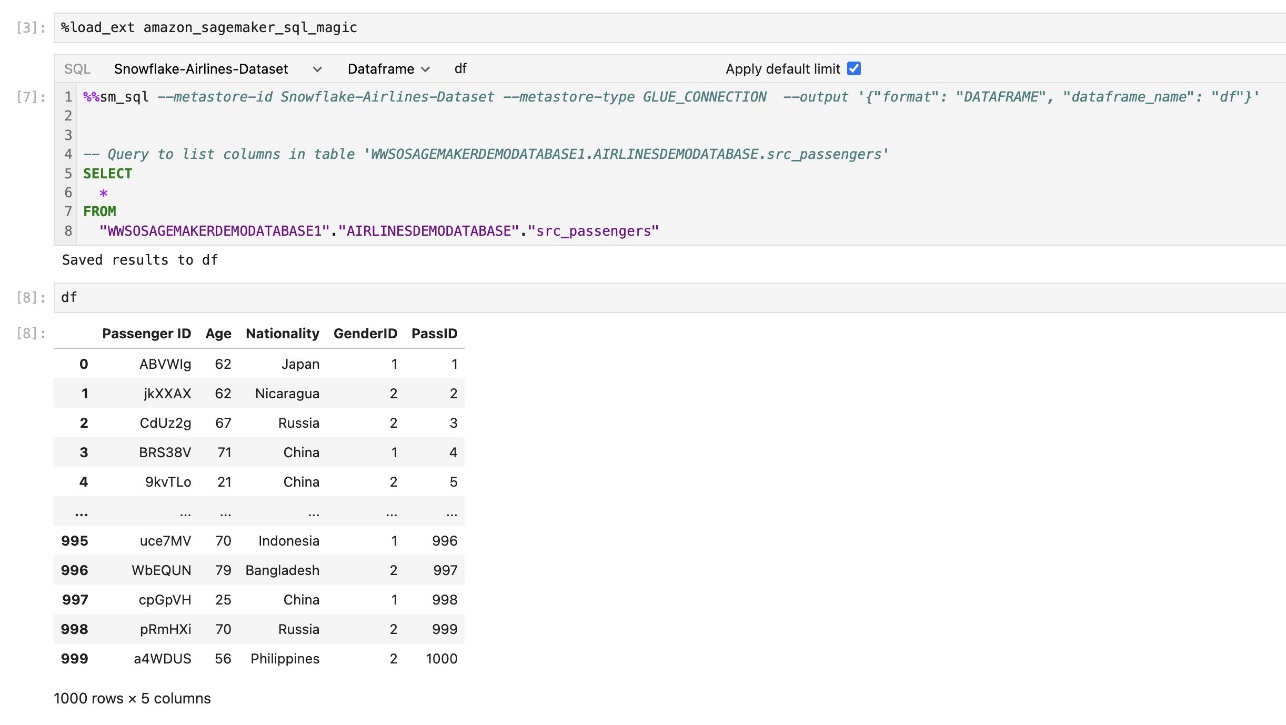
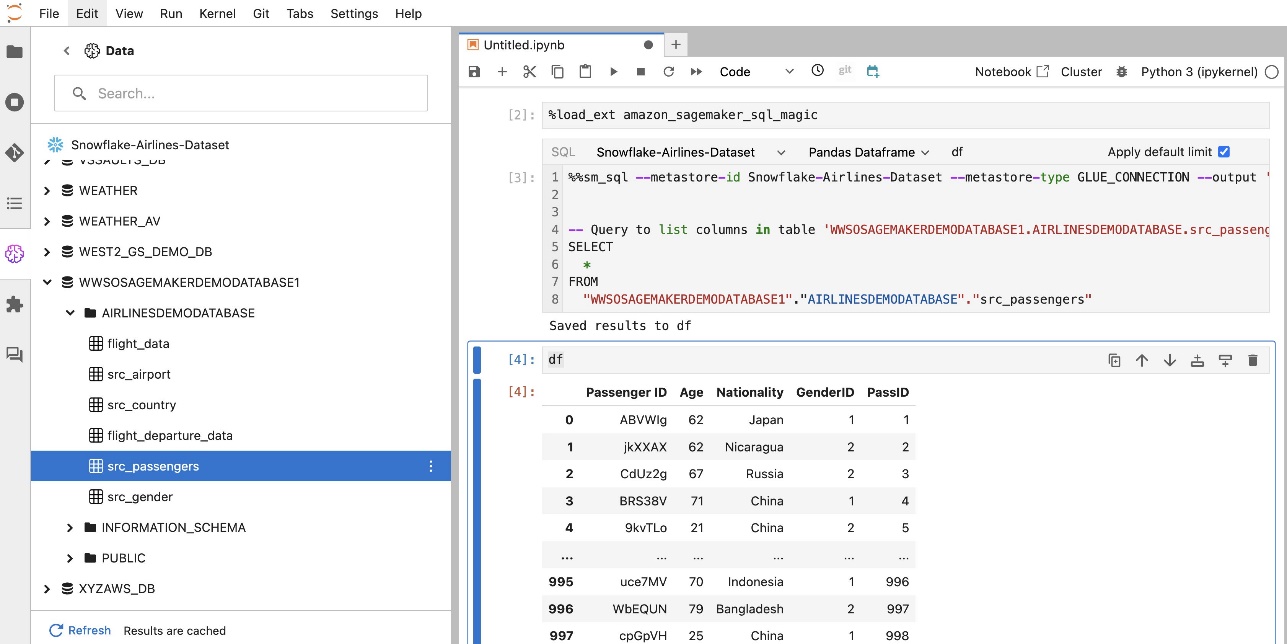
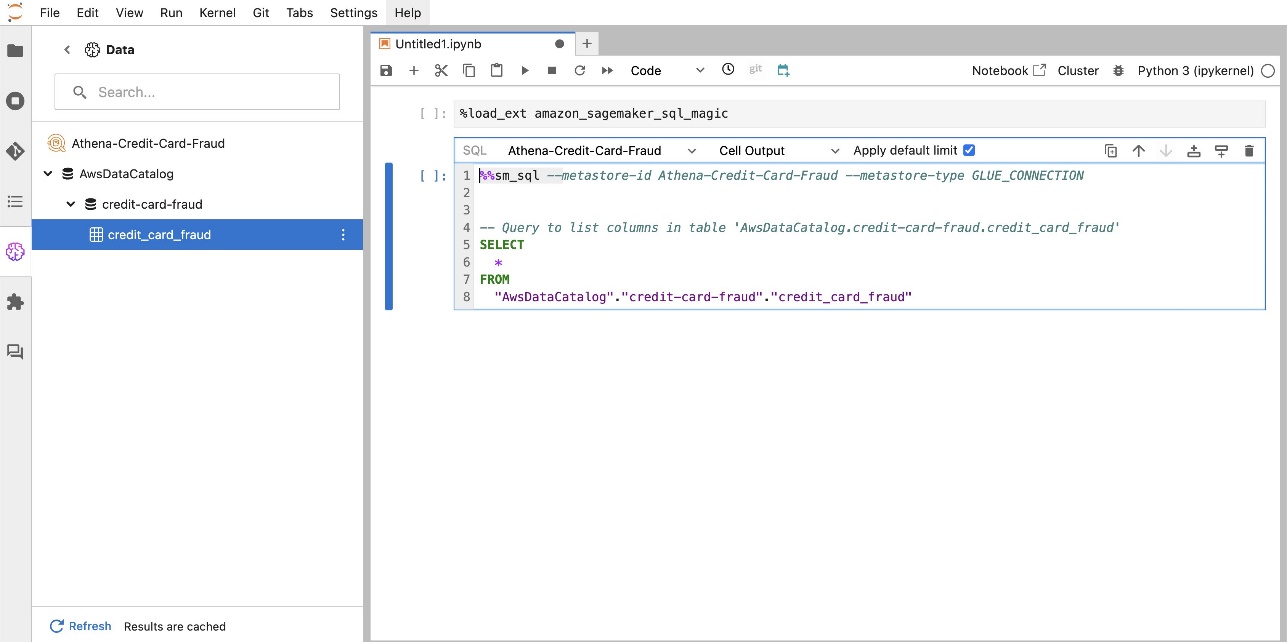
Η ενσωματωμένη επέκταση SQL του SageMaker Studio JupyterLab σάς δίνει επίσης τη δυνατότητα να εκτελείτε ερωτήματα SQL απευθείας από ένα σημειωματάριο. Τα σημειωματάρια Jupyter μπορούν να κάνουν διαφοροποίηση μεταξύ κώδικα SQL και Python χρησιμοποιώντας το %%sm_sql μαγική εντολή, η οποία πρέπει να τοποθετηθεί στην κορυφή οποιουδήποτε κελιού που περιέχει κώδικα SQL. Αυτή η εντολή σηματοδοτεί στο JupyterLab ότι οι ακόλουθες οδηγίες είναι εντολές SQL και όχι κώδικας Python. Η έξοδος ενός ερωτήματος μπορεί να εμφανιστεί απευθείας μέσα στο σημειωματάριο, διευκολύνοντας την απρόσκοπτη ενσωμάτωση των ροών εργασίας SQL και Python στην ανάλυση των δεδομένων σας.
Η έξοδος ενός ερωτήματος μπορεί να εμφανιστεί οπτικά ως πίνακες HTML, όπως φαίνεται στο παρακάτω στιγμιότυπο οθόνης.

Μπορούν επίσης να γραφτούν σε α pandas DataFrame.
Προϋποθέσεις
Βεβαιωθείτε ότι πληροίτε τις ακόλουθες προϋποθέσεις για να χρησιμοποιήσετε την εμπειρία SQL notebook SageMaker Studio:
- SageMaker Studio V2 – Βεβαιωθείτε ότι χρησιμοποιείτε την πιο ενημερωμένη έκδοση του Τομέας SageMaker Studio και προφίλ χρηστών. Εάν βρίσκεστε αυτήν τη στιγμή στο SageMaker Studio Classic, ανατρέξτε στο Μετανάστευση από το Amazon SageMaker Studio Classic.
- IAM ρόλο – Το SageMaker απαιτεί ένα Διαχείριση ταυτότητας και πρόσβασης AWS ρόλος (IAM) που θα εκχωρηθεί σε έναν τομέα SageMaker Studio ή προφίλ χρήστη για την αποτελεσματική διαχείριση των δικαιωμάτων. Ενδέχεται να απαιτείται ενημέρωση ρόλου εκτέλεσης για την εισαγωγή δεδομένων και τη δυνατότητα εκτέλεσης SQL. Το ακόλουθο παράδειγμα πολιτικής επιτρέπει στους χρήστες να παραχωρούν, να παραθέτουν και να εκτελούν Κόλλα AWS, Αθήνα, Απλή υπηρεσία αποθήκευσης Amazon (Amazon S3), Διευθυντής μυστικών AWSκαι πόροι Amazon Redshift:
- Χώρος JupyterLab – Χρειάζεστε πρόσβαση στο ενημερωμένο SageMaker Studio και JupyterLab Space με SageMaker Distribution v1.6 ή νεότερες εκδόσεις εικόνας. Εάν χρησιμοποιείτε προσαρμοσμένες εικόνες για JupyterLab Spaces ή παλαιότερες εκδόσεις του SageMaker Distribution (έκδοση 1.5 ή παλαιότερη), ανατρέξτε στο παράρτημα για οδηγίες εγκατάστασης των απαραίτητων πακέτων και λειτουργικών μονάδων για να ενεργοποιήσετε αυτήν τη δυνατότητα στα περιβάλλοντά σας. Για να μάθετε περισσότερα σχετικά με το SageMaker Studio JupyterLab Spaces, ανατρέξτε στο Αυξήστε την παραγωγικότητα στο Amazon SageMaker Studio: Παρουσιάζοντας το JupyterLab Spaces και τα δημιουργικά εργαλεία AI.
- Διαπιστευτήρια πρόσβασης σε πηγή δεδομένων – Αυτή η λειτουργία φορητού υπολογιστή SageMaker Studio απαιτεί πρόσβαση με όνομα χρήστη και κωδικό πρόσβασης σε πηγές δεδομένων όπως το Snowflake και το Amazon Redshift. Δημιουργήστε πρόσβαση βάσει ονόματος χρήστη και κωδικού πρόσβασης σε αυτές τις πηγές δεδομένων, εάν δεν έχετε ήδη. Η πρόσβαση στο Snowflake που βασίζεται στο OAuth δεν είναι μια δυνατότητα που υποστηρίζεται από τη σύνταξη αυτού του άρθρου.
- Φόρτωση SQL magic – Προτού εκτελέσετε ερωτήματα SQL από ένα κελί φορητού υπολογιστή Jupyter, είναι απαραίτητο να φορτώσετε την επέκταση SQL magic. Χρησιμοποιήστε την εντολή
%load_ext amazon_sagemaker_sql_magicγια να ενεργοποιήσετε αυτήν τη δυνατότητα. Επιπλέον, μπορείτε να εκτελέσετε το%sm_sql?εντολή για προβολή μιας ολοκληρωμένης λίστας υποστηριζόμενων επιλογών για ερωτήματα από ένα κελί SQL. Αυτές οι επιλογές περιλαμβάνουν μεταξύ άλλων τον ορισμό ενός προεπιλεγμένου ορίου ερωτήματος 1,000, την εκτέλεση πλήρους εξαγωγής και την εισαγωγή παραμέτρων ερωτήματος. Αυτή η ρύθμιση επιτρέπει τον ευέλικτο και αποτελεσματικό χειρισμό δεδομένων SQL απευθείας μέσα στο περιβάλλον του φορητού υπολογιστή σας.
Δημιουργία συνδέσεων βάσης δεδομένων
Οι ενσωματωμένες δυνατότητες περιήγησης και εκτέλεσης SQL του SageMaker Studio ενισχύονται από τις συνδέσεις AWS Glue. Μια σύνδεση AWS Glue είναι ένα αντικείμενο AWS Glue Data Catalog που αποθηκεύει βασικά δεδομένα όπως διαπιστευτήρια σύνδεσης, συμβολοσειρές URI και πληροφορίες εικονικού ιδιωτικού νέφους (VPC) για συγκεκριμένες αποθήκες δεδομένων. Αυτές οι συνδέσεις χρησιμοποιούνται από ανιχνευτές AWS Glue, εργασίες και τερματικά σημεία ανάπτυξης για πρόσβαση σε διάφορους τύπους αποθηκών δεδομένων. Μπορείτε να χρησιμοποιήσετε αυτές τις συνδέσεις τόσο για δεδομένα προέλευσης όσο και για δεδομένα προορισμού, ακόμη και να επαναχρησιμοποιήσετε την ίδια σύνδεση σε πολλούς ανιχνευτές ή να εξαγάγετε, να μετασχηματίσετε και να φορτώσετε εργασίες (ETL).
Για να εξερευνήσετε πηγές δεδομένων SQL στο αριστερό τμήμα του SageMaker Studio, πρέπει πρώτα να δημιουργήσετε αντικείμενα σύνδεσης AWS Glue. Αυτές οι συνδέσεις διευκολύνουν την πρόσβαση σε διαφορετικές πηγές δεδομένων και σας επιτρέπουν να εξερευνήσετε τα σχηματικά στοιχεία δεδομένων τους.
Στις επόμενες ενότητες, προχωράμε στη διαδικασία δημιουργίας υποδοχών AWS Glue ειδικά για SQL. Αυτό θα σας επιτρέψει να αποκτήσετε πρόσβαση, να προβάλετε και να εξερευνήσετε σύνολα δεδομένων σε μια ποικιλία αποθηκών δεδομένων. Για πιο λεπτομερείς πληροφορίες σχετικά με τις συνδέσεις κόλλας AWS, ανατρέξτε στο Σύνδεση σε δεδομένα.
Δημιουργήστε μια σύνδεση AWS Glue
Ο μόνος τρόπος για να φέρετε πηγές δεδομένων στο SageMaker Studio είναι οι συνδέσεις AWS Glue. Πρέπει να δημιουργήσετε συνδέσεις κόλλας AWS με συγκεκριμένους τύπους σύνδεσης. Από τη στιγμή που γράφεται αυτό το άρθρο, ο μόνος υποστηριζόμενος μηχανισμός δημιουργίας αυτών των συνδέσεων είναι η χρήση του Διεπαφή γραμμής εντολών AWS (AWS CLI).
Ορισμός σύνδεσης αρχείο JSON
Όταν συνδέεστε σε διαφορετικές πηγές δεδομένων στο AWS Glue, πρέπει πρώτα να δημιουργήσετε ένα αρχείο JSON που καθορίζει τις ιδιότητες σύνδεσης—αναφέρεται ως αρχείο ορισμού σύνδεσης. Αυτό το αρχείο είναι ζωτικής σημασίας για τη δημιουργία μιας σύνδεσης AWS Glue και θα πρέπει να περιγράφει λεπτομερώς όλες τις απαραίτητες διαμορφώσεις για την πρόσβαση στην πηγή δεδομένων. Για βέλτιστες πρακτικές ασφάλειας, συνιστάται η χρήση του Secrets Manager για την ασφαλή αποθήκευση ευαίσθητων πληροφοριών, όπως κωδικών πρόσβασης. Εν τω μεταξύ, άλλες ιδιότητες σύνδεσης μπορούν να διαχειρίζονται απευθείας μέσω των συνδέσεων κόλλας AWS. Αυτή η προσέγγιση διασφαλίζει ότι τα ευαίσθητα διαπιστευτήρια προστατεύονται, ενώ παράλληλα κάνει τη διαμόρφωση της σύνδεσης προσβάσιμη και διαχειρίσιμη.
Το παρακάτω είναι ένα παράδειγμα ενός ορισμού σύνδεσης JSON:
Κατά τη ρύθμιση των συνδέσεων AWS Glue για τις πηγές δεδομένων σας, υπάρχουν μερικές σημαντικές οδηγίες που πρέπει να ακολουθήσετε για την παροχή λειτουργικότητας και ασφάλειας:
- Στραγγαλισμός ιδιοκτησιών - Μέσα στο
PythonPropertiesκλειδί, βεβαιωθείτε ότι όλες οι ιδιότητες είναι συμβολοσειρά ζεύγη κλειδιού-τιμής. Είναι σημαντικό να αποφύγετε σωστά τα διπλά εισαγωγικά χρησιμοποιώντας τον χαρακτήρα ανάστροφης κάθετο () όπου χρειάζεται. Αυτό βοηθά στη διατήρηση της σωστής μορφής και στην αποφυγή συντακτικών σφαλμάτων στο JSON σας. - Χειρισμός ευαίσθητων πληροφοριών – Παρόλο που είναι δυνατό να συμπεριληφθούν όλες οι ιδιότητες σύνδεσης μέσα
PythonProperties, συνιστάται να μην περιλαμβάνονται ευαίσθητες λεπτομέρειες όπως κωδικοί πρόσβασης απευθείας σε αυτές τις ιδιότητες. Αντίθετα, χρησιμοποιήστε το Secrets Manager για το χειρισμό ευαίσθητων πληροφοριών. Αυτή η προσέγγιση προστατεύει τα ευαίσθητα δεδομένα σας αποθηκεύοντάς τα σε ελεγχόμενο και κρυπτογραφημένο περιβάλλον, μακριά από τα κύρια αρχεία διαμόρφωσης.
Δημιουργήστε μια σύνδεση AWS Glue χρησιμοποιώντας το AWS CLI
Αφού συμπεριλάβετε όλα τα απαραίτητα πεδία στο αρχείο JSON ορισμού σύνδεσης, είστε έτοιμοι να δημιουργήσετε μια σύνδεση AWS Glue για την πηγή δεδομένων σας χρησιμοποιώντας το AWS CLI και την ακόλουθη εντολή:
Αυτή η εντολή ξεκινά μια νέα σύνδεση AWS Glue με βάση τις προδιαγραφές που περιγράφονται λεπτομερώς στο αρχείο JSON σας. Ακολουθεί μια γρήγορη ανάλυση των στοιχείων της εντολής:
- -περιοχή – Αυτό καθορίζει την περιοχή AWS όπου θα δημιουργηθεί η σύνδεσή σας AWS Glue. Είναι σημαντικό να επιλέξετε την περιοχή όπου βρίσκονται οι πηγές δεδομένων σας και άλλες υπηρεσίες για να ελαχιστοποιήσετε τον λανθάνοντα χρόνο και να συμμορφωθείτε με τις απαιτήσεις παραμονής δεδομένων.
- –cli-input-json file:///path/to/file/connection/definition/file.json – Αυτή η παράμετρος καθοδηγεί το AWS CLI να διαβάσει τη διαμόρφωση εισόδου από ένα τοπικό αρχείο που περιέχει τον ορισμό της σύνδεσής σας σε μορφή JSON.
Θα πρέπει να μπορείτε να δημιουργήσετε συνδέσεις AWS Glue με την προηγούμενη εντολή AWS CLI από το τερματικό σας στο Studio JupyterLab. Στο Αρχεία μενού, επιλέξτε Νέα και τερματικό.

Εάν η create-connection Η εντολή εκτελείται με επιτυχία, θα πρέπει να δείτε την πηγή δεδομένων σας να αναφέρεται στο παράθυρο του προγράμματος περιήγησης SQL. Εάν δεν βλέπετε την πηγή δεδομένων σας στη λίστα, επιλέξτε Φρεσκάρω για ενημέρωση της προσωρινής μνήμης.

Δημιουργήστε μια σύνδεση Snowflake
Σε αυτήν την ενότητα, εστιάζουμε στην ενσωμάτωση μιας πηγής δεδομένων Snowflake με το SageMaker Studio. Η δημιουργία λογαριασμών, βάσεων δεδομένων και αποθηκών Snowflake δεν εμπίπτει στο πεδίο εφαρμογής αυτής της ανάρτησης. Για να ξεκινήσετε με το Snowflake, ανατρέξτε στο Οδηγός χρήσης Snowflake. Σε αυτήν την ανάρτηση, επικεντρωνόμαστε στη δημιουργία ενός αρχείου JSON ορισμού Snowflake και στη δημιουργία μιας σύνδεσης πηγής δεδομένων Snowflake χρησιμοποιώντας AWS Glue.
Δημιουργήστε ένα μυστικό του Secrets Manager
Μπορείτε να συνδεθείτε στον λογαριασμό σας στο Snowflake είτε χρησιμοποιώντας αναγνωριστικό χρήστη και κωδικό πρόσβασης είτε χρησιμοποιώντας ιδιωτικά κλειδιά. Για να συνδεθείτε με αναγνωριστικό χρήστη και κωδικό πρόσβασης, πρέπει να αποθηκεύσετε με ασφάλεια τα διαπιστευτήριά σας στο Secrets Manager. Όπως αναφέρθηκε προηγουμένως, αν και είναι δυνατή η ενσωμάτωση αυτών των πληροφοριών στο PythonProperties, δεν συνιστάται η αποθήκευση ευαίσθητων πληροφοριών σε μορφή απλού κειμένου. Να βεβαιώνεστε πάντα ότι ο χειρισμός των ευαίσθητων δεδομένων γίνεται με ασφάλεια για την αποφυγή πιθανών κινδύνων ασφαλείας.
Για να αποθηκεύσετε πληροφορίες στο Secrets Manager, ολοκληρώστε τα παρακάτω βήματα:
- Στην κονσόλα Secrets Manager, επιλέξτε Αποθηκεύστε ένα νέο μυστικό.
- Για Μυστικός τύπος, επιλέξτε Άλλο είδος μυστικού.
- Για το ζεύγος κλειδιού-τιμής, επιλέξτε Απλό κείμενο και εισάγετε τα εξής:
- Εισαγάγετε ένα όνομα για το μυστικό σας, όπως π.χ
sm-sql-snowflake-secret. - Αφήστε τις άλλες ρυθμίσεις ως προεπιλογές ή προσαρμόστε εάν απαιτείται.
- Δημιουργήστε το μυστικό.
Δημιουργήστε μια σύνδεση AWS Glue για Snowflake
Όπως αναφέρθηκε προηγουμένως, οι συνδέσεις AWS Glue είναι απαραίτητες για την πρόσβαση σε οποιαδήποτε σύνδεση από το SageMaker Studio. Μπορείτε να βρείτε μια λίστα με όλες οι υποστηριζόμενες ιδιότητες σύνδεσης για το Snowflake. Ακολουθεί ένα δείγμα ορισμού σύνδεσης JSON για Snowflake. Αντικαταστήστε τις τιμές κράτησης θέσης με τις κατάλληλες τιμές προτού το αποθηκεύσετε στο δίσκο:
Για να δημιουργήσετε ένα αντικείμενο σύνδεσης AWS Glue για την πηγή δεδομένων Snowflake, χρησιμοποιήστε την ακόλουθη εντολή:
Αυτή η εντολή δημιουργεί μια νέα σύνδεση προέλευσης δεδομένων Snowflake στο παράθυρο του προγράμματος περιήγησης SQL με δυνατότητα περιήγησης και μπορείτε να εκτελέσετε ερωτήματα SQL σε αυτήν από το κελί του σημειωματάριου JupyterLab.
Δημιουργήστε μια σύνδεση Amazon Redshift
Το Amazon Redshift είναι μια πλήρως διαχειριζόμενη υπηρεσία αποθήκης δεδομένων σε κλίμακα petabyte που απλοποιεί και μειώνει το κόστος ανάλυσης όλων των δεδομένων σας χρησιμοποιώντας την τυπική SQL. Η διαδικασία για τη δημιουργία μιας σύνδεσης Amazon Redshift αντικατοπτρίζει στενά τη διαδικασία για μια σύνδεση Snowflake.
Δημιουργήστε ένα μυστικό του Secrets Manager
Παρόμοια με τη ρύθμιση Snowflake, για να συνδεθείτε στο Amazon Redshift χρησιμοποιώντας αναγνωριστικό χρήστη και κωδικό πρόσβασης, πρέπει να αποθηκεύσετε με ασφάλεια τις μυστικές πληροφορίες στο Secrets Manager. Ολοκληρώστε τα παρακάτω βήματα:
- Στην κονσόλα Secrets Manager, επιλέξτε Αποθηκεύστε ένα νέο μυστικό.
- Για Μυστικός τύπος, επιλέξτε Διαπιστευτήρια για το σύμπλεγμα Amazon Redshift.
- Εισαγάγετε τα διαπιστευτήρια που χρησιμοποιούνται για τη σύνδεση για πρόσβαση στο Amazon Redshift ως πηγή δεδομένων.
- Επιλέξτε το σύμπλεγμα Redshift που σχετίζεται με τα μυστικά.
- Εισαγάγετε ένα όνομα για το μυστικό, όπως π.χ
sm-sql-redshift-secret. - Αφήστε τις άλλες ρυθμίσεις ως προεπιλογές ή προσαρμόστε εάν απαιτείται.
- Δημιουργήστε το μυστικό.
Ακολουθώντας αυτά τα βήματα, βεβαιωθείτε ότι ο χειρισμός των διαπιστευτηρίων σύνδεσής σας γίνεται με ασφάλεια, χρησιμοποιώντας τις ισχυρές δυνατότητες ασφαλείας του AWS για την αποτελεσματική διαχείριση ευαίσθητων δεδομένων.
Δημιουργήστε μια σύνδεση AWS Glue για το Amazon Redshift
Για να ρυθμίσετε μια σύνδεση με το Amazon Redshift χρησιμοποιώντας έναν ορισμό JSON, συμπληρώστε τα απαραίτητα πεδία και αποθηκεύστε την ακόλουθη διαμόρφωση JSON στο δίσκο:
Για να δημιουργήσετε ένα αντικείμενο σύνδεσης AWS Glue για την πηγή δεδομένων Redshift, χρησιμοποιήστε την ακόλουθη εντολή AWS CLI:
Αυτή η εντολή δημιουργεί μια σύνδεση στο AWS Glue που συνδέεται με την πηγή δεδομένων Redshift. Εάν η εντολή εκτελεστεί με επιτυχία, θα μπορείτε να δείτε την πηγή δεδομένων Redshift μέσα στο σημειωματάριο SageMaker Studio JupyterLab, έτοιμο για εκτέλεση ερωτημάτων SQL και ανάλυση δεδομένων.

Δημιουργήστε μια σύνδεση Athena
Το Athena είναι μια πλήρως διαχειριζόμενη υπηρεσία ερωτημάτων SQL από το AWS που επιτρέπει την ανάλυση των δεδομένων που είναι αποθηκευμένα στο Amazon S3 χρησιμοποιώντας τυπική SQL. Για να ρυθμίσετε μια σύνδεση Athena ως πηγή δεδομένων στο πρόγραμμα περιήγησης SQL του σημειωματάριου JupyterLab, πρέπει να δημιουργήσετε ένα δείγμα ορισμού σύνδεσης Athena JSON. Η ακόλουθη δομή JSON διαμορφώνει τις απαραίτητες λεπτομέρειες για τη σύνδεση με το Athena, προσδιορίζοντας τον κατάλογο δεδομένων, τον κατάλογο σταδίου S3 και την περιοχή:
Για να δημιουργήσετε ένα αντικείμενο σύνδεσης AWS Glue για την προέλευση δεδομένων Athena, χρησιμοποιήστε την ακόλουθη εντολή AWS CLI:
Εάν η εντολή είναι επιτυχής, θα μπορείτε να αποκτήσετε πρόσβαση στον κατάλογο και τους πίνακες δεδομένων Athena απευθείας από το πρόγραμμα περιήγησης SQL στο σημειωματάριό σας SageMaker Studio JupyterLab.
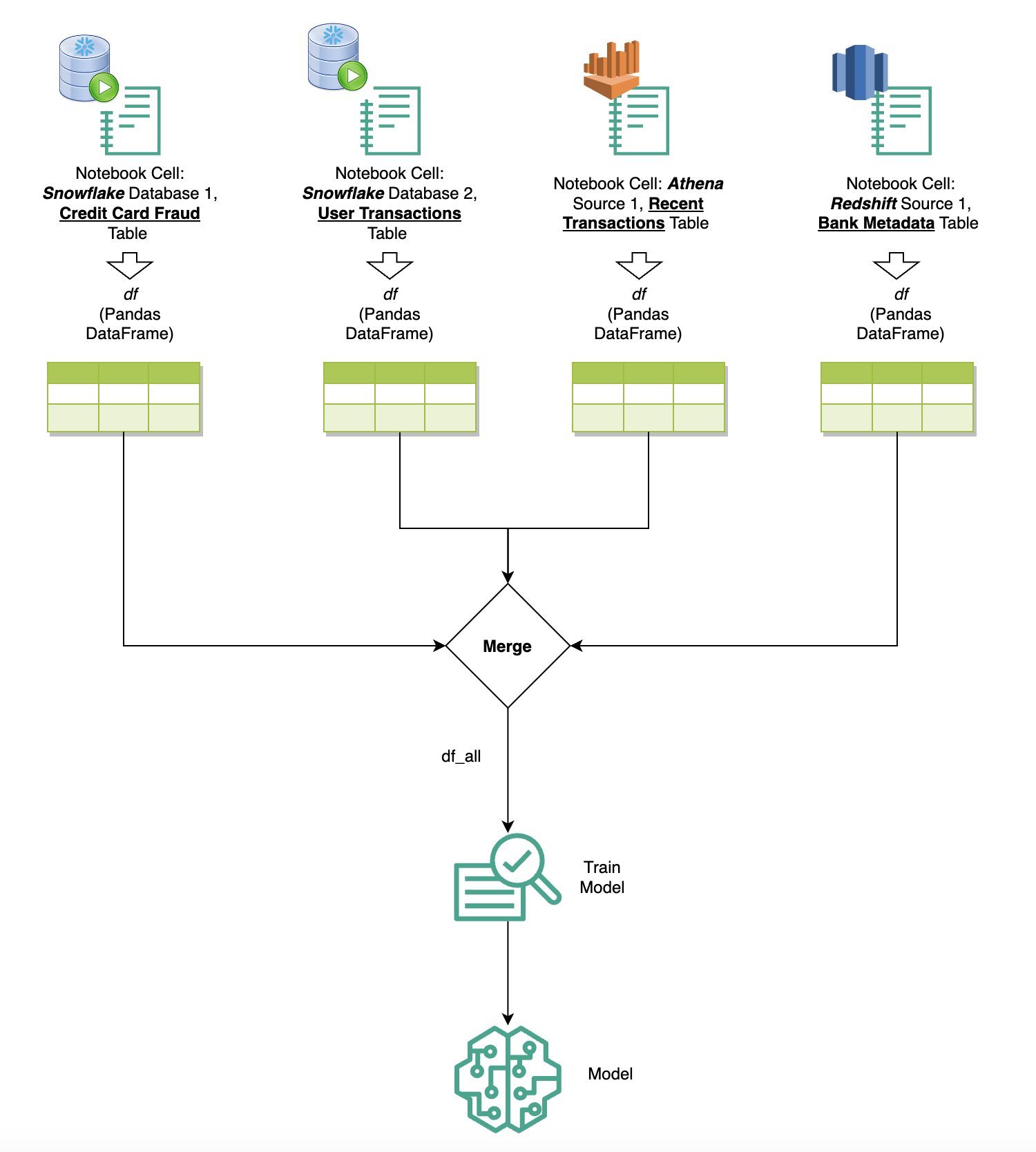
Ζητήστε δεδομένα από πολλές πηγές
Εάν έχετε ενσωματωμένες πολλές πηγές δεδομένων στο SageMaker Studio μέσω του ενσωματωμένου προγράμματος περιήγησης SQL και της δυνατότητας SQL του notebook, μπορείτε να εκτελέσετε γρήγορα ερωτήματα και να κάνετε εναλλαγή μεταξύ των backend της πηγής δεδομένων σε επόμενα κελιά ενός σημειωματάριου. Αυτή η δυνατότητα επιτρέπει την απρόσκοπτη μετάβαση μεταξύ διαφορετικών βάσεων δεδομένων ή πηγών δεδομένων κατά τη ροή εργασιών ανάλυσής σας.
Μπορείτε να εκτελέσετε ερωτήματα σε μια διαφορετική συλλογή από backend πηγών δεδομένων και να μεταφέρετε τα αποτελέσματα απευθείας στον χώρο της Python για περαιτέρω ανάλυση ή οπτικοποίηση. Αυτό διευκολύνεται από το %%sm_sql Η μαγική εντολή είναι διαθέσιμη σε σημειωματάρια SageMaker Studio. Για να εξάγετε τα αποτελέσματα του ερωτήματός σας SQL σε ένα pandas DataFrame, υπάρχουν δύο επιλογές:
- Από τη γραμμή εργαλείων κελιών του φορητού υπολογιστή σας, επιλέξτε τον τύπο εξόδου Πλαίσιο δεδομένων και ονομάστε τη μεταβλητή DataFrame
- Προσθέστε την ακόλουθη παράμετρο στο δικό σας
%%sm_sqlεντολή:
Το παρακάτω διάγραμμα απεικονίζει αυτήν τη ροή εργασίας και δείχνει πώς μπορείτε να εκτελέσετε εύκολα ερωτήματα σε διάφορες πηγές σε επόμενα κελιά φορητού υπολογιστή, καθώς και να εκπαιδεύσετε ένα μοντέλο SageMaker χρησιμοποιώντας εργασίες εκπαίδευσης ή απευθείας μέσα στο σημειωματάριο χρησιμοποιώντας τοπικούς υπολογισμούς. Επιπλέον, το διάγραμμα υπογραμμίζει πώς η ενσωματωμένη SQL ενσωμάτωση του SageMaker Studio απλοποιεί τις διαδικασίες εξαγωγής και δημιουργίας απευθείας στο οικείο περιβάλλον ενός κελιού φορητού υπολογιστή JupyterLab.
Κείμενο σε SQL: Χρήση φυσικής γλώσσας για τη βελτίωση της σύνταξης ερωτημάτων
Η SQL είναι μια πολύπλοκη γλώσσα που απαιτεί κατανόηση βάσεων δεδομένων, πινάκων, συντακτικών και μεταδεδομένων. Σήμερα, η γενετική τεχνητή νοημοσύνη (AI) μπορεί να σας επιτρέψει να γράφετε σύνθετα ερωτήματα SQL χωρίς να απαιτείται εις βάθος εμπειρία SQL. Η πρόοδος των LLMs έχει επηρεάσει σημαντικά τη δημιουργία SQL που βασίζεται στην επεξεργασία φυσικής γλώσσας (NLP), επιτρέποντας τη δημιουργία ακριβών ερωτημάτων SQL από περιγραφές φυσικής γλώσσας - μια τεχνική που αναφέρεται ως Text-to-SQL. Ωστόσο, είναι σημαντικό να αναγνωρίσουμε τις εγγενείς διαφορές μεταξύ της ανθρώπινης γλώσσας και της SQL. Η ανθρώπινη γλώσσα μπορεί μερικές φορές να είναι διφορούμενη ή ανακριβής, ενώ η SQL είναι δομημένη, σαφής και ξεκάθαρη. Η γεφύρωση αυτού του χάσματος και η ακριβής μετατροπή της φυσικής γλώσσας σε ερωτήματα SQL μπορεί να αποτελέσει μια τρομερή πρόκληση. Όταν παρέχονται με τις κατάλληλες προτροπές, τα LLM μπορούν να συμβάλουν στη γεφύρωση αυτού του χάσματος κατανοώντας την πρόθεση πίσω από την ανθρώπινη γλώσσα και δημιουργώντας αντίστοιχα ακριβή ερωτήματα SQL.
Με την κυκλοφορία της δυνατότητας ερωτήματος SQL στο φορητό υπολογιστή SageMaker Studio, το SageMaker Studio διευκολύνει την επιθεώρηση βάσεων δεδομένων και σχημάτων, καθώς και τη σύνταξη, εκτέλεση και εντοπισμό σφαλμάτων ερωτημάτων SQL χωρίς ποτέ να φύγετε από το IDE του σημειωματάριου Jupyter. Αυτή η ενότητα διερευνά πώς οι δυνατότητες μετατροπής κειμένου σε SQL των προηγμένων LLM μπορούν να διευκολύνουν τη δημιουργία ερωτημάτων SQL με χρήση φυσικής γλώσσας στα σημειωματάρια Jupyter. Χρησιμοποιούμε το μοντέλο αιχμής Text-to-SQL defog/sqlcoder-7b-2 σε συνδυασμό με το Jupyter AI, έναν γενετικό βοηθό AI ειδικά σχεδιασμένο για φορητούς υπολογιστές Jupyter, για τη δημιουργία σύνθετων ερωτημάτων SQL από φυσική γλώσσα. Χρησιμοποιώντας αυτό το προηγμένο μοντέλο, μπορούμε αβίαστα και αποτελεσματικά να δημιουργήσουμε σύνθετα ερωτήματα SQL χρησιμοποιώντας φυσική γλώσσα, ενισχύοντας έτσι την εμπειρία μας SQL σε φορητούς υπολογιστές.
Δημιουργία πρωτοτύπων σημειωματάριου με χρήση του Hugging Face Hub
Για να ξεκινήσετε τη δημιουργία πρωτοτύπων, χρειάζεστε τα εξής:
- Κωδικός GitHub – Ο κωδικός που παρουσιάζεται σε αυτήν την ενότητα είναι διαθέσιμος παρακάτω GitHub repo και με αναφορά στο παράδειγμα σημειωματάριο.
- Χώρος JupyterLab – Η πρόσβαση σε χώρο SageMaker Studio JupyterLab που υποστηρίζεται από παρουσίες που βασίζονται σε GPU είναι απαραίτητη. Για το
defog/sqlcoder-7b-2μοντέλο, συνιστάται ένα μοντέλο παραμέτρων 7B, χρησιμοποιώντας μια παρουσία ml.g5.2xlarge. Εναλλακτικές όπωςdefog/sqlcoder-70b-alphένα ήdefog/sqlcoder-34b-alphaείναι επίσης βιώσιμα για μετατροπή φυσικής γλώσσας σε SQL, αλλά ενδέχεται να απαιτούνται μεγαλύτεροι τύποι παρουσιών για τη δημιουργία πρωτοτύπων. Βεβαιωθείτε ότι έχετε το όριο για να ξεκινήσετε μια παρουσία που υποστηρίζεται από GPU μεταβαίνοντας στην κονσόλα Service Quotas, αναζητώντας το SageMaker και αναζητώνταςStudio JupyterLab Apps running on <instance type>.
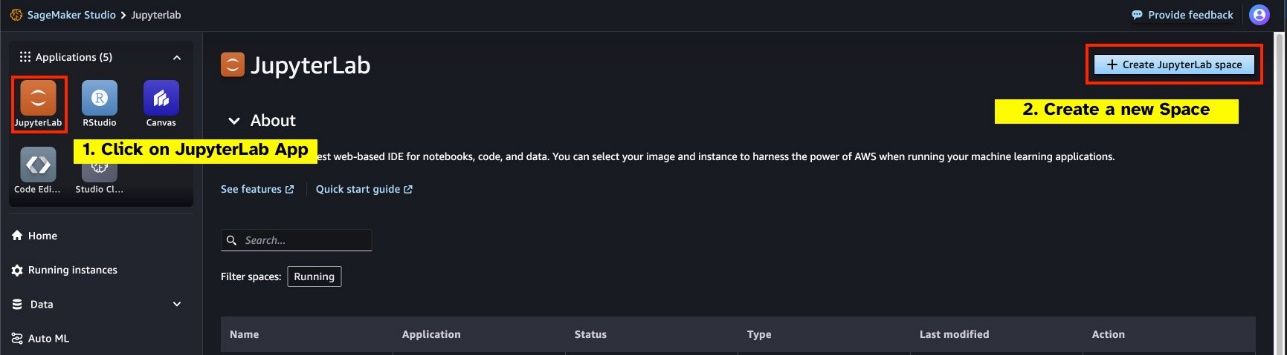
Εκκινήστε ένα νέο JupyterLab Space με υποστήριξη GPU από το SageMaker Studio σας. Συνιστάται η δημιουργία ενός νέου χώρου JupyterLab με τουλάχιστον 75 GB Κατάστημα Amazon Elastic Block Αποθηκευτικός χώρος (Amazon EBS) για μοντέλο παραμέτρων 7Β.

- Humbing Face Hub – Εάν ο τομέας SageMaker Studio σας έχει πρόσβαση σε λήψη μοντέλων από το Humbing Face Hub, μπορείτε να χρησιμοποιήσετε το
AutoModelForCausalLMτάξη από πρόσωπο αγκαλιάς/μετασχηματιστές για αυτόματη λήψη μοντέλων και καρφίτσωμα στις τοπικές GPU. Τα βάρη του μοντέλου θα αποθηκευτούν στην κρυφή μνήμη του τοπικού σας μηχανήματος. Δείτε τον παρακάτω κώδικα:
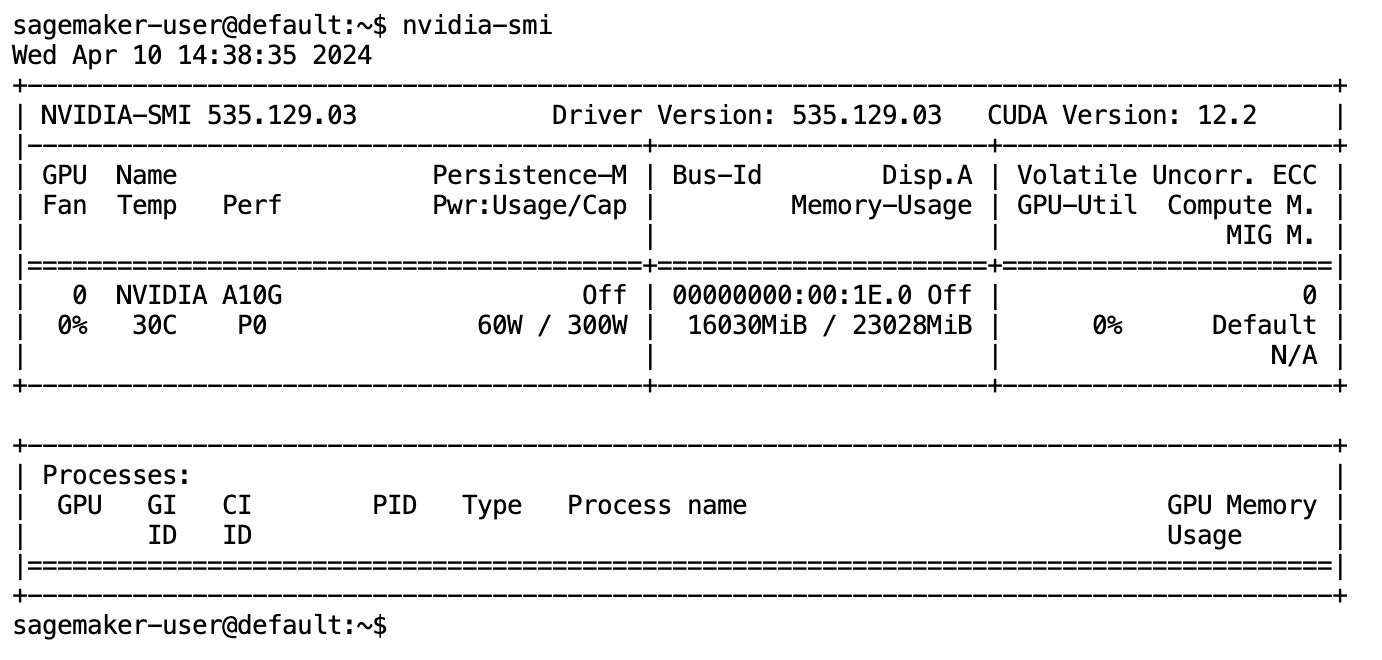
Αφού ολοκληρωθεί η λήψη και η φόρτωση του μοντέλου στη μνήμη, θα πρέπει να παρατηρήσετε μια αύξηση στη χρήση της GPU στον τοπικό σας υπολογιστή. Αυτό υποδηλώνει ότι το μοντέλο χρησιμοποιεί ενεργά τους πόρους της GPU για υπολογιστικές εργασίες. Μπορείτε να το επαληθεύσετε στον δικό σας χώρο JupyterLab εκτελώντας nvidia-smi (για μια εφάπαξ εμφάνιση) ή nvidia-smi —loop=1 (για επανάληψη κάθε δευτερόλεπτο) από το τερματικό σας στο JupyterLab.
Τα μοντέλα μετατροπής κειμένου σε SQL υπερέχουν στην κατανόηση της πρόθεσης και του πλαισίου του αιτήματος ενός χρήστη, ακόμη και όταν η γλώσσα που χρησιμοποιείται είναι συνομιλητική ή διφορούμενη. Η διαδικασία περιλαμβάνει τη μετάφραση εισόδων φυσικής γλώσσας στα σωστά στοιχεία σχήματος βάσης δεδομένων, όπως ονόματα πινάκων, ονόματα στηλών και συνθήκες. Ωστόσο, ένα μη διαθέσιμο μοντέλο Text-to-SQL δεν θα γνωρίζει εγγενώς τη δομή της αποθήκης δεδομένων σας, τα συγκεκριμένα σχήματα βάσης δεδομένων ή δεν θα είναι σε θέση να ερμηνεύει με ακρίβεια το περιεχόμενο ενός πίνακα που βασίζεται αποκλειστικά σε ονόματα στηλών. Για να χρησιμοποιήσετε αποτελεσματικά αυτά τα μοντέλα για τη δημιουργία πρακτικών και αποτελεσματικών ερωτημάτων SQL από φυσική γλώσσα, είναι απαραίτητο να προσαρμόσετε το μοντέλο δημιουργίας κειμένου SQL στο συγκεκριμένο σχήμα βάσης δεδομένων της αποθήκης σας. Αυτή η προσαρμογή διευκολύνεται με τη χρήση του LLM ζητά. Το παρακάτω είναι ένα προτεινόμενο πρότυπο προτροπής για το μοντέλο defog/sqlcoder-7b-2 Text-to-SQL, χωρισμένο σε τέσσερα μέρη:
- Έργο – Αυτή η ενότητα θα πρέπει να προσδιορίζει μια εργασία υψηλού επιπέδου που πρέπει να πραγματοποιηθεί από το μοντέλο. Θα πρέπει να περιλαμβάνει τον τύπο του backend της βάσης δεδομένων (όπως Amazon RDS, PostgreSQL ή Amazon Redshift) για να ενημερώνει το μοντέλο για τυχόν λεπτές συντακτικές διαφορές που μπορεί να επηρεάσουν τη δημιουργία του τελικού ερωτήματος SQL.
- Οδηγίες – Αυτή η ενότητα θα πρέπει να καθορίζει τα όρια εργασιών και την επίγνωση του τομέα για το μοντέλο και μπορεί να περιλαμβάνει μερικά παραδείγματα που θα καθοδηγούν το μοντέλο στη δημιουργία λεπτομερώς συντονισμένων ερωτημάτων SQL.
- Σχήμα βάσης δεδομένων – Αυτή η ενότητα θα πρέπει να περιγράφει λεπτομερώς τα σχήματα της βάσης δεδομένων της αποθήκης σας, περιγράφοντας τις σχέσεις μεταξύ πινάκων και στηλών για να βοηθήσει το μοντέλο να κατανοήσει τη δομή της βάσης δεδομένων.
- Απάντηση – Αυτή η ενότητα προορίζεται για το μοντέλο για έξοδο της απόκρισης ερωτήματος SQL στην είσοδο φυσικής γλώσσας.
Ένα παράδειγμα του σχήματος της βάσης δεδομένων και της προτροπής που χρησιμοποιούνται σε αυτήν την ενότητα είναι διαθέσιμα στο Repo GitHub.
Η άμεση μηχανική δεν αφορά μόνο τη διαμόρφωση ερωτήσεων ή δηλώσεων. είναι μια τέχνη και επιστήμη με αποχρώσεις που επηρεάζει σημαντικά την ποιότητα των αλληλεπιδράσεων με ένα μοντέλο AI. Ο τρόπος με τον οποίο δημιουργείτε μια προτροπή μπορεί να επηρεάσει βαθιά τη φύση και τη χρησιμότητα της απόκρισης του AI. Αυτή η δεξιότητα είναι ζωτικής σημασίας για τη μεγιστοποίηση των δυνατοτήτων των αλληλεπιδράσεων τεχνητής νοημοσύνης, ειδικά σε σύνθετες εργασίες που απαιτούν εξειδικευμένη κατανόηση και λεπτομερείς απαντήσεις.
Είναι σημαντικό να έχετε την επιλογή να δημιουργήσετε και να δοκιμάσετε γρήγορα την απόκριση ενός μοντέλου για μια δεδομένη προτροπή και να βελτιστοποιήσετε το μήνυμα με βάση την απόκριση. Τα σημειωματάρια JupyterLab παρέχουν τη δυνατότητα λήψης άμεσων σχολίων για το μοντέλο από ένα μοντέλο που εκτελείται σε τοπικό υπολογισμό και βελτιστοποιούν την προτροπή και συντονίζουν περαιτέρω την απόκριση ενός μοντέλου ή αλλάζουν εντελώς ένα μοντέλο. Σε αυτήν την ανάρτηση, χρησιμοποιούμε έναν φορητό υπολογιστή SageMaker Studio JupyterLab που υποστηρίζεται από τη GPU NVIDIA A5.2G 10 GB της ml.g24xlarge για την εκτέλεση συμπερασμάτων μοντέλου Text-to-SQL στο φορητό υπολογιστή και τη διαδραστική δημιουργία της προτροπής του μοντέλου μας έως ότου η απόκριση του μοντέλου συντονιστεί επαρκώς ώστε να παρέχει αποκρίσεις που είναι άμεσα εκτελέσιμες στα κελιά SQL του JupyterLab. Για την εκτέλεση συμπερασμάτων μοντέλων και ταυτόχρονα ροή αποκρίσεων μοντέλου, χρησιμοποιούμε έναν συνδυασμό model.generate και TextIteratorStreamer όπως ορίζεται στον παρακάτω κώδικα:
Η έξοδος του μοντέλου μπορεί να διακοσμηθεί με μαγεία SageMaker SQL %%sm_sql ..., το οποίο επιτρέπει στο σημειωματάριο JupyterLab να αναγνωρίσει το κελί ως κελί SQL.
Φιλοξενήστε μοντέλα Text-to-SQL ως τελικά σημεία του SageMaker
Στο τέλος του σταδίου πρωτοτύπου, επιλέξαμε το προτιμώμενο Text-to-SQL LLM, μια αποτελεσματική μορφή προτροπής και έναν κατάλληλο τύπο παρουσίας για τη φιλοξενία του μοντέλου (είτε με μία GPU είτε με πολλές GPU). Το SageMaker διευκολύνει την κλιμακούμενη φιλοξενία προσαρμοσμένων μοντέλων μέσω της χρήσης των τελικών σημείων του SageMaker. Αυτά τα τελικά σημεία μπορούν να οριστούν σύμφωνα με συγκεκριμένα κριτήρια, επιτρέποντας την ανάπτυξη των LLM ως τελικών σημείων. Αυτή η δυνατότητα σάς δίνει τη δυνατότητα να κλιμακώσετε τη λύση σε ένα ευρύτερο κοινό, επιτρέποντας στους χρήστες να δημιουργούν ερωτήματα SQL από εισόδους φυσικής γλώσσας χρησιμοποιώντας προσαρμοσμένα φιλοξενούμενα LLM. Το παρακάτω διάγραμμα απεικονίζει αυτήν την αρχιτεκτονική.

Για να φιλοξενήσετε το LLM σας ως τελικό σημείο του SageMaker, δημιουργείτε πολλά τεχνουργήματα.
Το πρώτο τεχνούργημα είναι τα βάρη μοντέλων. Εξυπηρέτηση SageMaker Deep Java Library (DJL). Τα κοντέινερ σάς επιτρέπουν να ρυθμίζετε διαμορφώσεις μέσω ενός meta σερβίρισμα.ιδιοκτησίες αρχείο, το οποίο σας δίνει τη δυνατότητα να κατευθύνετε τον τρόπο προέλευσης των μοντέλων—είτε απευθείας από το Hugging Face Hub είτε κατεβάζοντας τεχνουργήματα μοντέλων από το Amazon S3. Αν διευκρινίσετε model_id=defog/sqlcoder-7b-2, Το DJL Serving θα επιχειρήσει να κατεβάσει απευθείας αυτό το μοντέλο από το Hugging Face Hub. Ωστόσο, ενδέχεται να επιβαρύνεστε με χρεώσεις εισόδου/εξόδου δικτύου κάθε φορά που το τελικό σημείο αναπτύσσεται ή κλιμακώνεται ελαστικά. Για να αποφύγετε αυτές τις χρεώσεις και πιθανώς να επιταχύνετε τη λήψη τεχνουργημάτων μοντέλων, συνιστάται να παραλείψετε τη χρήση model_id in serving.properties και αποθηκεύστε τα βάρη μοντέλων ως τεχνουργήματα S3 και προσδιορίστε τα μόνο με s3url=s3://path/to/model/bin.
Η αποθήκευση ενός μοντέλου (με το tokenizer του) στο δίσκο και η μεταφόρτωσή του στο Amazon S3 μπορεί να επιτευχθεί με λίγες μόνο γραμμές κώδικα:
Μπορείτε επίσης να χρησιμοποιήσετε ένα αρχείο προτροπής βάσης δεδομένων. Σε αυτήν τη ρύθμιση, η προτροπή της βάσης δεδομένων αποτελείται από Task, Instructions, Database Schema, να Answer sections. Για την τρέχουσα αρχιτεκτονική, εκχωρούμε ένα ξεχωριστό αρχείο προτροπής για κάθε σχήμα βάσης δεδομένων. Ωστόσο, υπάρχει ευελιξία να επεκταθεί αυτή η ρύθμιση ώστε να περιλαμβάνει πολλές βάσεις δεδομένων ανά αρχείο προτροπής, επιτρέποντας στο μοντέλο να εκτελεί σύνθετες συνδέσεις σε βάσεις δεδομένων στον ίδιο διακομιστή. Κατά τη διάρκεια του σταδίου δημιουργίας πρωτοτύπων, αποθηκεύουμε την προτροπή της βάσης δεδομένων ως αρχείο κειμένου με όνομα <Database-Glue-Connection-Name>.prompt, Όπου Database-Glue-Connection-Name αντιστοιχεί στο όνομα σύνδεσης που είναι ορατό στο περιβάλλον του JupyterLab. Για παράδειγμα, αυτή η ανάρτηση αναφέρεται σε μια σύνδεση Snowflake που ονομάζεται Airlines_Dataset, έτσι το αρχείο προτροπής της βάσης δεδομένων ονομάζεται Airlines_Dataset.prompt. Αυτό το αρχείο αποθηκεύεται στη συνέχεια στο Amazon S3 και στη συνέχεια διαβάζεται και αποθηκεύεται προσωρινά από τη λογική εξυπηρέτησης μοντέλων.
Επιπλέον, αυτή η αρχιτεκτονική επιτρέπει σε κάθε εξουσιοδοτημένο χρήστη αυτού του τελικού σημείου να ορίσει, να αποθηκεύσει και να δημιουργήσει φυσική γλώσσα σε ερωτήματα SQL χωρίς την ανάγκη πολλαπλών ανακατανομών του μοντέλου. Χρησιμοποιούμε τα παρακάτω παράδειγμα προτροπής βάσης δεδομένων για την επίδειξη της λειτουργικότητας Text-to-SQL.
Στη συνέχεια, δημιουργείτε λογική υπηρεσίας προσαρμοσμένου μοντέλου. Σε αυτήν την ενότητα, περιγράφετε μια προσαρμοσμένη λογική συμπερασμάτων με το όνομα model.py. Αυτό το σενάριο έχει σχεδιαστεί για να βελτιστοποιεί την απόδοση και την ενοποίηση των υπηρεσιών Text-to-SQL:
- Καθορίστε τη λογική προσωρινής αποθήκευσης του αρχείου προτροπής της βάσης δεδομένων – Για να ελαχιστοποιήσουμε τον λανθάνοντα χρόνο, εφαρμόζουμε μια προσαρμοσμένη λογική για τη λήψη και την προσωρινή αποθήκευση αρχείων προτροπής της βάσης δεδομένων. Αυτός ο μηχανισμός διασφαλίζει ότι τα μηνύματα προτροπής είναι άμεσα διαθέσιμα, μειώνοντας τα γενικά έξοδα που σχετίζονται με συχνές λήψεις.
- Ορισμός προσαρμοσμένης λογικής συμπερασμάτων μοντέλου – Για τη βελτίωση της ταχύτητας συμπερασμάτων, το μοντέλο μετατροπής κειμένου σε SQL φορτώνεται σε μορφή ακριβείας float16 και στη συνέχεια μετατρέπεται σε μοντέλο DeepSpeed. Αυτό το βήμα επιτρέπει πιο αποτελεσματικούς υπολογισμούς. Επιπλέον, μέσα σε αυτή τη λογική, καθορίζετε ποιες παραμέτρους μπορούν να προσαρμόσουν οι χρήστες κατά τη διάρκεια κλήσεων εξαγωγής συμπερασμάτων για να προσαρμόσουν τη λειτουργικότητα σύμφωνα με τις ανάγκες τους.
- Ορίστε προσαρμοσμένη λογική εισόδου και εξόδου – Η δημιουργία σαφών και προσαρμοσμένων μορφών εισόδου/εξόδου είναι απαραίτητη για την ομαλή ενσωμάτωση με τις μεταγενέστερες εφαρμογές. Μια τέτοια εφαρμογή είναι η JupyterAI, την οποία θα συζητήσουμε στην επόμενη ενότητα.
Επιπλέον, συμπεριλαμβάνουμε α serving.properties αρχείο, το οποίο λειτουργεί ως καθολικό αρχείο διαμόρφωσης για μοντέλα που φιλοξενούνται χρησιμοποιώντας υπηρεσία DJL. Για περισσότερες πληροφορίες, ανατρέξτε στο Διαμορφώσεις και ρυθμίσεις.
Τέλος, μπορείτε επίσης να συμπεριλάβετε α requirements.txt αρχείο για να ορίσετε πρόσθετες μονάδες που απαιτούνται για την εξαγωγή συμπερασμάτων και να συσκευάσετε τα πάντα σε ένα tarball για ανάπτυξη.
Δείτε τον ακόλουθο κώδικα:
Ενσωματώστε το τελικό σημείο σας με τον βοηθό AI SageMaker Studio Jupyter
Jupyter AI είναι ένα εργαλείο ανοιχτού κώδικα που φέρνει τη γενετική τεχνητή νοημοσύνη στους φορητούς υπολογιστές Jupyter, προσφέροντας μια ισχυρή και φιλική προς τον χρήστη πλατφόρμα για την εξερεύνηση μοντέλων τεχνητής νοημοσύνης. Αυξάνει την παραγωγικότητα στα σημειωματάρια JupyterLab και Jupyter παρέχοντας λειτουργίες όπως το %%ai magic για τη δημιουργία μιας δημιουργικής παιδικής χαράς AI μέσα σε φορητούς υπολογιστές, μια εγγενή διεπαφή χρήστη συνομιλίας στο JupyterLab για αλληλεπίδραση με την τεχνητή νοημοσύνη ως βοηθός συνομιλίας και υποστήριξη για ένα ευρύ φάσμα LLM από οι πάροχοι όπως Amazon Titan, AI21, Anthropic, Cohere και Hugging Face ή διαχειριζόμενες υπηρεσίες όπως Θεμέλιο του Αμαζονίου και τα τελικά σημεία του SageMaker. Για αυτήν την ανάρτηση, χρησιμοποιούμε την ενσωμάτωση του Jupyter AI με τα τελικά σημεία του SageMaker για να φέρουμε τη δυνατότητα Text-to-SQL στα σημειωματάρια JupyterLab. Το εργαλείο Jupyter AI είναι προεγκατεστημένο σε όλα τα SageMaker Studio JupyterLab Spaces που υποστηρίζονται από Εικόνες SageMaker Distribution; Οι τελικοί χρήστες δεν απαιτείται να κάνουν πρόσθετες διαμορφώσεις για να αρχίσουν να χρησιμοποιούν την επέκταση Jupyter AI για ενσωμάτωση με ένα τελικό σημείο που φιλοξενείται στο SageMaker. Σε αυτήν την ενότητα, συζητάμε τους δύο τρόπους χρήσης του ενσωματωμένου εργαλείου Jupyter AI.
Jupyter AI μέσα σε ένα σημειωματάριο χρησιμοποιώντας μαγικά
Jupyter AI %%ai Η μαγική εντολή σάς επιτρέπει να μετατρέψετε τους φορητούς υπολογιστές SageMaker Studio JupyterLab σε ένα αναπαραγώγιμο περιβάλλον τεχνητής νοημοσύνης. Για να ξεκινήσετε να χρησιμοποιείτε τα AI magic, βεβαιωθείτε ότι έχετε φορτώσει την επέκταση jupyter_ai_magics για χρήση %%ai μαγεία, και επιπλέον φορτίο amazon_sagemaker_sql_magic να χρησιμοποιήσουν %%sm_sql μαγεία:
Για να εκτελέσετε μια κλήση στο τελικό σημείο του SageMaker από το σημειωματάριό σας χρησιμοποιώντας το %%ai μαγική εντολή, δώστε τις ακόλουθες παραμέτρους και δομήστε την εντολή ως εξής:
- –περιοχή-όνομα – Καθορίστε την περιοχή όπου αναπτύσσεται το τελικό σημείο σας. Αυτό διασφαλίζει ότι το αίτημα δρομολογείται στη σωστή γεωγραφική τοποθεσία.
- –αίτημα-σχήμα – Συμπεριλάβετε το σχήμα των δεδομένων εισόδου. Αυτό το σχήμα περιγράφει την αναμενόμενη μορφή και τους τύπους των δεδομένων εισόδου που χρειάζεται το μοντέλο σας για την επεξεργασία του αιτήματος.
- –απόκριση-διαδρομή – Καθορίστε τη διαδρομή μέσα στο αντικείμενο απόκρισης όπου βρίσκεται η έξοδος του μοντέλου σας. Αυτή η διαδρομή χρησιμοποιείται για την εξαγωγή των σχετικών δεδομένων από την απόκριση που επιστρέφεται από το μοντέλο σας.
- -f (προαιρετικό) - Αυτό είναι ένα μορφοποιητής εξόδου σημαία που υποδεικνύει τον τύπο της εξόδου που επιστρέφεται από το μοντέλο. Στο πλαίσιο ενός σημειωματάριου Jupyter, εάν η έξοδος είναι κώδικας, αυτή η σημαία θα πρέπει να ρυθμιστεί ανάλογα για να διαμορφώσει την έξοδο ως εκτελέσιμο κώδικα στην κορυφή ενός κελιού σημειωματάριου Jupyter, ακολουθούμενη από μια περιοχή εισαγωγής ελεύθερου κειμένου για αλληλεπίδραση με τον χρήστη.
Για παράδειγμα, η εντολή σε ένα κελί σημειωματάριου Jupyter μπορεί να μοιάζει με τον ακόλουθο κώδικα:
Παράθυρο συνομιλίας Jupyter AI
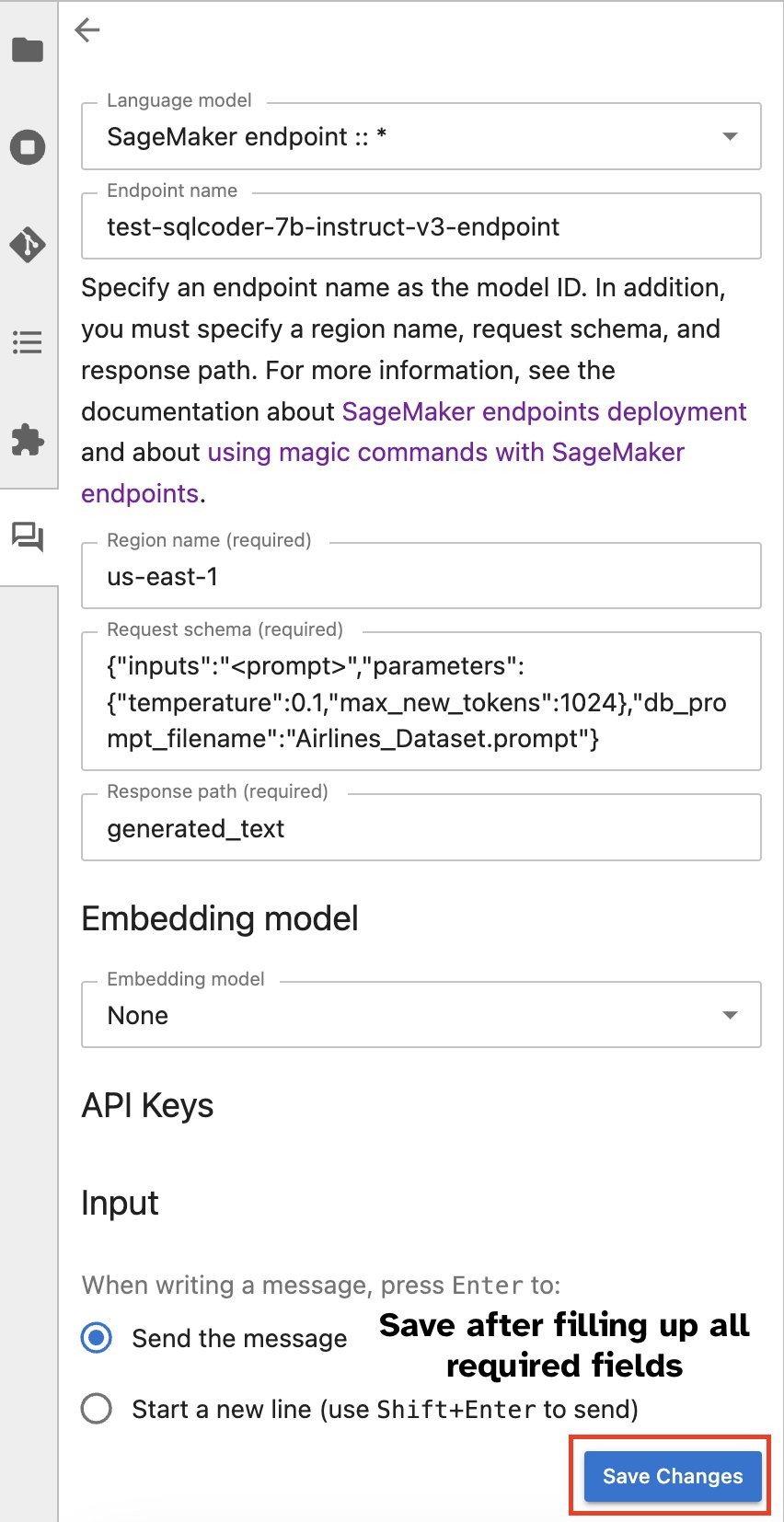
Εναλλακτικά, μπορείτε να αλληλεπιδράσετε με τα τελικά σημεία του SageMaker μέσω μιας ενσωματωμένης διεπαφής χρήστη, απλοποιώντας τη διαδικασία δημιουργίας ερωτημάτων ή τη συμμετοχή σε διάλογο. Πριν ξεκινήσετε να συνομιλείτε με το τελικό σημείο του SageMaker, διαμορφώστε τις σχετικές ρυθμίσεις στο Jupyter AI για το τελικό σημείο του SageMaker, όπως φαίνεται στο παρακάτω στιγμιότυπο οθόνης.
 |
 |
Συμπέρασμα
Το SageMaker Studio τώρα απλοποιεί και βελτιστοποιεί τη ροή εργασιών του data scientist ενσωματώνοντας την υποστήριξη SQL σε φορητούς υπολογιστές JupyterLab. Αυτό επιτρέπει στους επιστήμονες δεδομένων να επικεντρωθούν στα καθήκοντά τους χωρίς την ανάγκη διαχείρισης πολλαπλών εργαλείων. Επιπλέον, η νέα ενσωματωμένη ενσωμάτωση SQL στο SageMaker Studio επιτρέπει στα πρόσωπα δεδομένων να δημιουργούν αβίαστα ερωτήματα SQL χρησιμοποιώντας κείμενο φυσικής γλώσσας ως είσοδο, επιταχύνοντας έτσι τη ροή εργασίας τους.
Σας ενθαρρύνουμε να εξερευνήσετε αυτές τις δυνατότητες στο SageMaker Studio. Για περισσότερες πληροφορίες, ανατρέξτε στο Προετοιμάστε δεδομένα με SQL στο Studio.
Παράρτημα
Ενεργοποιήστε το κελί SQL του προγράμματος περιήγησης SQL και του σημειωματάριου σε προσαρμοσμένα περιβάλλοντα
Εάν δεν χρησιμοποιείτε εικόνα διανομής SageMaker ή εικόνες διανομής 1.5 ή νεότερη έκδοση, εκτελέστε τις ακόλουθες εντολές για να ενεργοποιήσετε τη δυνατότητα περιήγησης SQL μέσα στο περιβάλλον του JupyterLab:
Μετακινήστε το γραφικό στοιχείο του προγράμματος περιήγησης SQL
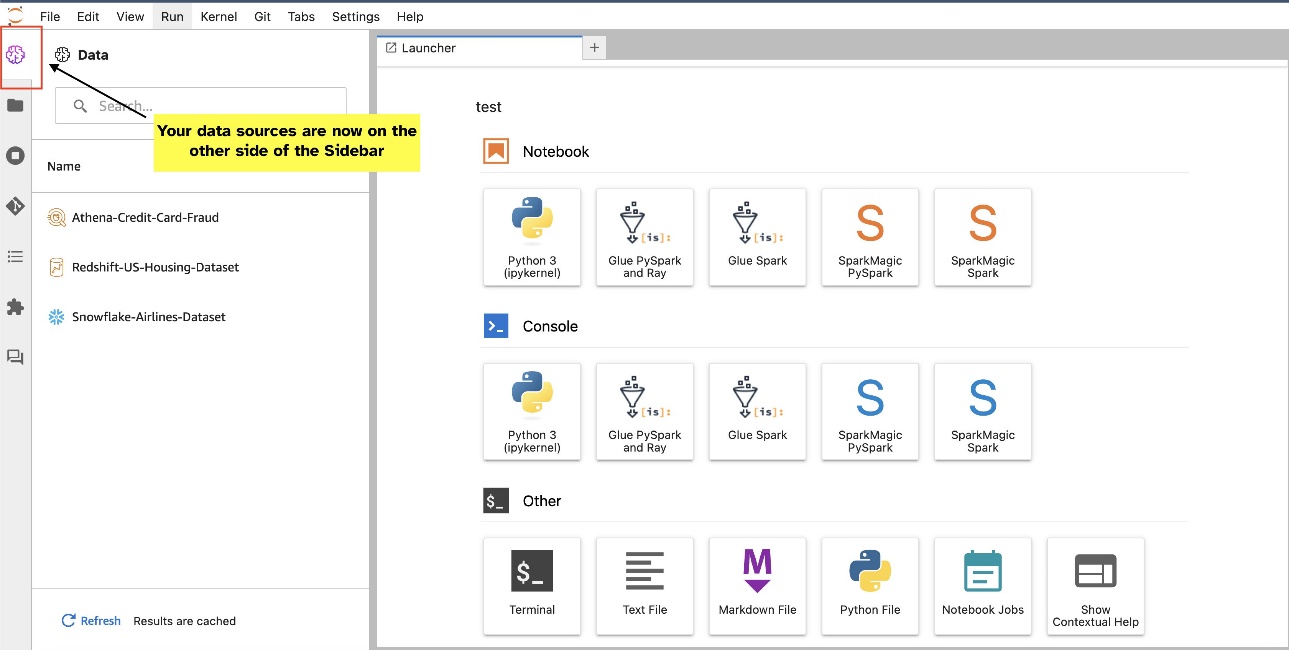
Τα γραφικά στοιχεία JupyterLab επιτρέπουν τη μετεγκατάσταση. Ανάλογα με την προτίμησή σας, μπορείτε να μετακινήσετε γραφικά στοιχεία σε κάθε πλευρά του παραθύρου γραφικών στοιχείων JupyterLab. Εάν προτιμάτε, μπορείτε να μετακινήσετε την κατεύθυνση του γραφικού στοιχείου SQL στην αντίθετη πλευρά (δεξιά προς τα αριστερά) της πλαϊνής γραμμής με ένα απλό δεξί κλικ στο εικονίδιο του γραφικού στοιχείου και επιλέγοντας Εναλλαγή πλευρικής γραμμής.
 |
 |
Σχετικά με τους συγγραφείς
 Pranav Murthy είναι AI/ML Specialist Solutions Architect στο AWS. Επικεντρώνεται στο να βοηθά τους πελάτες να δημιουργήσουν, να εκπαιδεύσουν, να αναπτύξουν και να μεταφέρουν φόρτους εργασίας μηχανικής εκμάθησης (ML) στο SageMaker. Προηγουμένως εργάστηκε στη βιομηχανία ημιαγωγών αναπτύσσοντας μοντέλα μεγάλης όρασης υπολογιστών (CV) και επεξεργασίας φυσικής γλώσσας (NLP) για τη βελτίωση των διαδικασιών ημιαγωγών χρησιμοποιώντας τεχνικές τελευταίας τεχνολογίας ML. Στον ελεύθερο χρόνο του, του αρέσει να παίζει σκάκι και να ταξιδεύει. Μπορείτε να βρείτε το Pranav στο LinkedIn.
Pranav Murthy είναι AI/ML Specialist Solutions Architect στο AWS. Επικεντρώνεται στο να βοηθά τους πελάτες να δημιουργήσουν, να εκπαιδεύσουν, να αναπτύξουν και να μεταφέρουν φόρτους εργασίας μηχανικής εκμάθησης (ML) στο SageMaker. Προηγουμένως εργάστηκε στη βιομηχανία ημιαγωγών αναπτύσσοντας μοντέλα μεγάλης όρασης υπολογιστών (CV) και επεξεργασίας φυσικής γλώσσας (NLP) για τη βελτίωση των διαδικασιών ημιαγωγών χρησιμοποιώντας τεχνικές τελευταίας τεχνολογίας ML. Στον ελεύθερο χρόνο του, του αρέσει να παίζει σκάκι και να ταξιδεύει. Μπορείτε να βρείτε το Pranav στο LinkedIn.
 Βαρούν Σαχ είναι Μηχανικός Λογισμικού που εργάζεται στο Amazon SageMaker Studio στο Amazon Web Services. Επικεντρώνεται στην κατασκευή διαδραστικών λύσεων ML που απλοποιούν την επεξεργασία δεδομένων και τα ταξίδια προετοιμασίας δεδομένων. Στον ελεύθερο χρόνο του, ο Varun απολαμβάνει υπαίθριες δραστηριότητες, όπως πεζοπορία και σκι, και είναι πάντα έτοιμος να ανακαλύψει νέα, συναρπαστικά μέρη.
Βαρούν Σαχ είναι Μηχανικός Λογισμικού που εργάζεται στο Amazon SageMaker Studio στο Amazon Web Services. Επικεντρώνεται στην κατασκευή διαδραστικών λύσεων ML που απλοποιούν την επεξεργασία δεδομένων και τα ταξίδια προετοιμασίας δεδομένων. Στον ελεύθερο χρόνο του, ο Varun απολαμβάνει υπαίθριες δραστηριότητες, όπως πεζοπορία και σκι, και είναι πάντα έτοιμος να ανακαλύψει νέα, συναρπαστικά μέρη.
 Σουμέντα Σουάμι είναι κύριος διευθυντής προϊόντων στο Amazon Web Services όπου ηγείται της ομάδας SageMaker Studio στην αποστολή της να αναπτύξει IDE επιλογής για την επιστήμη δεδομένων και τη μηχανική μάθηση. Έχει αφιερώσει τα τελευταία 15 χρόνια στη δημιουργία καταναλωτικών και επιχειρηματικών προϊόντων που βασίζονται στη Μηχανική Μάθηση.
Σουμέντα Σουάμι είναι κύριος διευθυντής προϊόντων στο Amazon Web Services όπου ηγείται της ομάδας SageMaker Studio στην αποστολή της να αναπτύξει IDE επιλογής για την επιστήμη δεδομένων και τη μηχανική μάθηση. Έχει αφιερώσει τα τελευταία 15 χρόνια στη δημιουργία καταναλωτικών και επιχειρηματικών προϊόντων που βασίζονται στη Μηχανική Μάθηση.
 Μπόσκο Αλμπουκέρκη είναι Sr. Partner Solutions Architect στην AWS και έχει πάνω από 20 χρόνια εμπειρίας σε συνεργασία με προϊόντα βάσεων δεδομένων και αναλυτικών στοιχείων από προμηθευτές εταιρικών βάσεων δεδομένων και παρόχους cloud. Έχει βοηθήσει εταιρείες τεχνολογίας να σχεδιάσουν και να εφαρμόσουν λύσεις και προϊόντα ανάλυσης δεδομένων.
Μπόσκο Αλμπουκέρκη είναι Sr. Partner Solutions Architect στην AWS και έχει πάνω από 20 χρόνια εμπειρίας σε συνεργασία με προϊόντα βάσεων δεδομένων και αναλυτικών στοιχείων από προμηθευτές εταιρικών βάσεων δεδομένων και παρόχους cloud. Έχει βοηθήσει εταιρείες τεχνολογίας να σχεδιάσουν και να εφαρμόσουν λύσεις και προϊόντα ανάλυσης δεδομένων.
- SEO Powered Content & PR Distribution. Ενισχύστε σήμερα.
- PlatoData.Network Vertical Generative Ai. Ενδυναμώστε τον εαυτό σας. Πρόσβαση εδώ.
- PlatoAiStream. Web3 Intelligence. Ενισχύθηκε η γνώση. Πρόσβαση εδώ.
- PlatoESG. Ανθρακας, Cleantech, Ενέργεια, Περιβάλλον, Ηλιακός, Διαχείριση των αποβλήτων. Πρόσβαση εδώ.
- PlatoHealth. Ευφυΐα βιοτεχνολογίας και κλινικών δοκιμών. Πρόσβαση εδώ.
- πηγή: https://aws.amazon.com/blogs/machine-learning/explore-data-with-ease-using-sql-and-text-to-sql-in-amazon-sagemaker-studio-jupyterlab-notebooks/

